↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Generating high-resolution images poses challenges like increased semantic planning complexity and detail synthesis difficulties, alongside substantial training resource demands. Existing methods often suffer from instability, long inference times, and manual parameter adjustments.
UltraPixel uses a novel cascade diffusion model architecture to address these issues. It leverages semantic-rich representations from lower-resolution images to guide high-resolution generation, reducing complexity. Implicit neural representations enable continuous upscaling, and scale-aware normalization layers adapt to various resolutions. This leads to a highly resource-efficient model that shares the majority of parameters between low- and high-resolution processes, making it faster to train and use.
Key Takeaways#
Why does it matter?#
This paper is important because it presents UltraPixel, a novel and efficient method for generating high-quality ultra-high-resolution images. This addresses a critical need in various fields, including digital art, and pushes the boundaries of current T2I model capabilities. The resource-efficient design and state-of-the-art performance of UltraPixel are particularly relevant to researchers facing computational constraints or seeking improved efficiency. It also opens new avenues for research in cascade diffusion models, implicit neural representations, and high-resolution image synthesis.
Visual Insights#

This figure shows several example images generated by the UltraPixel model at different resolutions, ranging from 1536x2560 to 5120x5120 pixels. The images showcase the model’s ability to generate highly realistic and detailed images across a variety of subjects, including landscapes, portraits, and animals. The detail and photorealism in the images highlight the model’s capability for ultra-high resolution image generation.
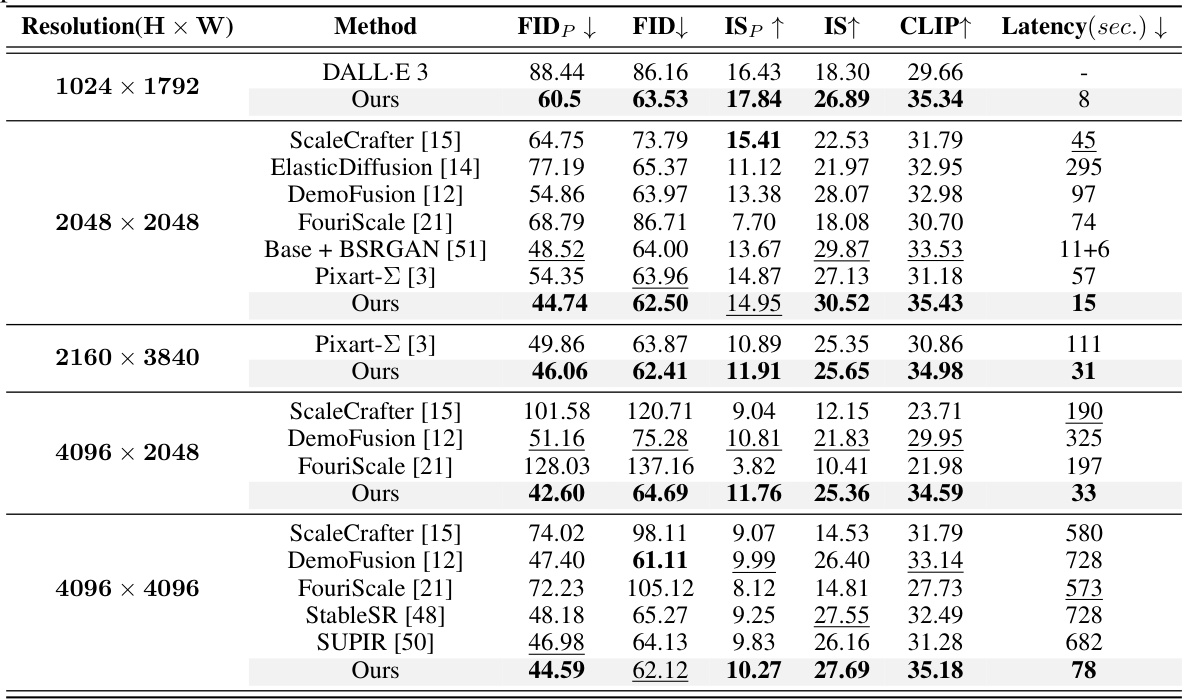
This table presents a quantitative comparison of UltraPixel’s performance against other state-of-the-art methods for high-resolution image generation. It evaluates across multiple resolutions (1024x1792, 2048x2048, 2160x3840, 4096x2048, 4096x4096), using metrics such as FID, FID-patch, IS, IS-patch, CLIP, and inference latency. The results demonstrate that UltraPixel achieves superior performance in terms of image quality and efficiency.
In-depth insights#
Cascade Diffusion#
Cascade diffusion models represent a significant advancement in generative modeling, particularly for high-resolution image synthesis. They achieve this by employing a hierarchical, multi-stage process, where lower-resolution outputs guide the generation of progressively higher-resolution images. This approach offers several key advantages: it reduces computational complexity, improves the quality and coherence of higher-resolution results by leveraging the semantic information captured in the earlier stages, and enables better control over the generation process. The cascade structure fosters efficiency as early stages handle the broad strokes of the image, leaving finer details for later stages, leading to faster training and inference times. However, careful design choices are crucial; the effective fusion of information across different resolution levels and managing potential distribution shifts between stages are important challenges. Successfully addressing these issues leads to models that generate visually stunning high-resolution images while maintaining computational feasibility. The choice of latent space representation and upsampling techniques are also critical factors influencing the overall performance and efficiency of a cascade diffusion model.
Semantic Guidance#
Semantic guidance in image generation leverages lower-resolution representations to inform and improve the creation of higher-resolution outputs. This approach is particularly useful for tackling the increased complexity of generating high-resolution images, where nuanced details and intricate structures are essential. By using lower-resolution outputs as a form of guidance, the model effectively reduces the computational burden of high-resolution generation and is less likely to suffer from artifacts that typically arise from the increased scale and detail. The lower-resolution guidance provides a strong semantic foundation—a roadmap, if you will—directing the generation process towards a more accurate and coherent high-resolution image. This is a significant advancement because it addresses a major computational hurdle in high-resolution image synthesis. The effectiveness of semantic guidance relies on the quality and information richness of the lower-resolution representations. If the initial low-resolution image lacks crucial details or suffers from errors, these flaws may propagate and negatively impact the final result. Therefore, careful selection and optimization of the lower-resolution generation stage is vital. Furthermore, effective fusion strategies for integrating lower-resolution guidance with the high-resolution generation process are necessary to ensure smooth and consistent scaling. In essence, semantic guidance represents a powerful strategy for navigating the complexities of high-resolution image generation by cleverly using pre-computed knowledge to guide the creation of more detailed and coherent visuals.
Resolution Scaling#
Resolution scaling in high-resolution image generation is a critical challenge, demanding efficient and effective methods. Approaches range from training-free techniques that modify existing models to training-based methods that learn specific high-resolution generators. Training-free methods offer speed but often compromise on quality and control, sometimes producing artifacts. Conversely, training-based methods, while potentially offering superior quality, require substantial computational resources and extensive training data. Implicit neural representations and cascaded diffusion models are promising techniques. Implicit representations allow continuous upscaling, dynamically adapting to diverse resolutions. Cascaded models process lower resolutions to provide semantic guidance for high-resolution details, improving efficiency. The choice between these approaches depends on the specific application’s need for speed vs. quality, along with available resources. Addressing distribution disparity across resolutions is another key aspect to consider. This often involves careful normalization or feature mapping techniques to ensure coherent and aesthetically pleasing results across all targeted resolutions. Ultimately, a successful resolution scaling approach balances computational efficiency with the fidelity and detail needed in the generated high-resolution images.
Efficiency Gains#
Analyzing efficiency gains in a research paper requires a multifaceted approach. Computational efficiency is paramount, often assessed by measuring training time, inference speed, and memory usage. The paper likely presents metrics quantifying these aspects, comparing the proposed method to existing state-of-the-art techniques. Parametric efficiency, another crucial factor, focuses on the model’s size, particularly the number of parameters. A smaller model translates to reduced computational costs and easier deployment. Data efficiency might be explored if the technique requires less training data than existing approaches, potentially lowering the resources needed for model development. Overall efficiency is a holistic measure encompassing all the aforementioned elements and potentially others specific to the paper’s methodology. It demonstrates the method’s effectiveness by achieving high-quality results while consuming minimal resources, leading to improvements in speed, cost, and scalability.
Future Research#
Future research directions stemming from this UltraPixel model could explore several promising avenues. Improving efficiency further is key; while UltraPixel boasts impressive speed, advancements in model compression and architectural optimization could lead to even faster generation times at higher resolutions. Enhancing the model’s capacity for diverse styles and artistic control would also be highly valuable. Integrating additional control mechanisms beyond simple edge maps, allowing users to specify artistic styles, color palettes, or even aspects of composition, could significantly increase the model’s versatility. Addressing potential biases present in the training data remains crucial; future work should focus on mitigating these biases and ensuring the model generates equitable and representative results. Finally, exploring applications in other domains is important; the high-quality image synthesis of UltraPixel opens opportunities in fields like medicine, scientific visualization, and advanced manufacturing which warrant further investigation.
More visual insights#
More on figures

This figure compares the feature distribution across various resolutions for Stable Cascade and the proposed UltraPixel model using t-SNE visualization. Stable Cascade shows scattered clusters, indicating significant distribution disparity across resolutions. In contrast, UltraPixel demonstrates a more continuous distribution, suggesting better consistency and adaptability across different resolutions. This improved feature distribution highlights UltraPixel’s ability to generate high-quality images at various resolutions efficiently.
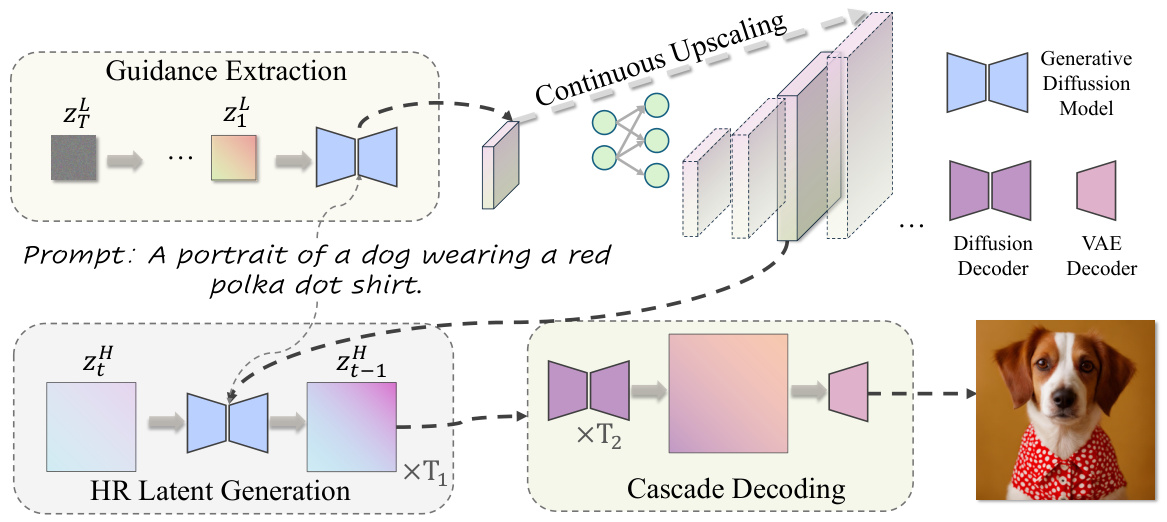
This figure illustrates the overall process of UltraPixel image generation. It starts by extracting guidance from a low-resolution image generated in earlier stages. This guidance is then upscaled using an implicit neural representation and integrated into the high-resolution generation branch to guide the creation of a high-resolution image. The process involves cascade decoding of the high-resolution latent representation, ultimately resulting in a photorealistic and detail-rich image.

This figure illustrates the continuous upscaling method used in UltraPixel. Low-resolution guidance tokens are first processed through a linear layer, then concatenated with learnable tokens and passed through a self-attention layer. The resulting tokens are processed through another set of linear layers. By inputting the target position (x, y) coordinates, the implicit neural representation (INR) generates upscaled guidance features that match the resolution of high-resolution features. This process allows the model to use low-resolution image information effectively at various resolutions during high-resolution image synthesis.
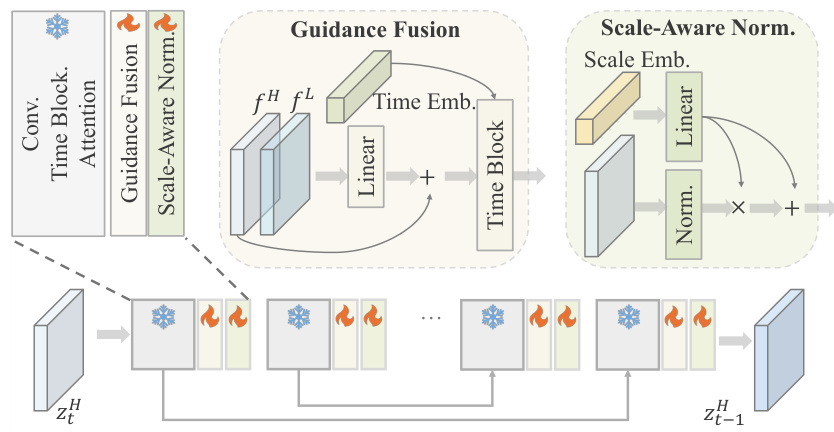
This figure details the architecture of the generative diffusion model used in UltraPixel. It shows the different components of the model, including the guidance fusion module, the scale-aware normalization layer, and the time embedding. The figure also shows how the different components of the model are connected together, and how the model processes the input image to generate a high-resolution image. The model uses a cascade decoding process, which means that it generates the image in multiple stages. In each stage, it uses the output of the previous stage as input to generate the next stage, which allows it to generate more realistic and detailed images. The model also uses a continuous upscaling process, which allows it to generate images at any resolution.
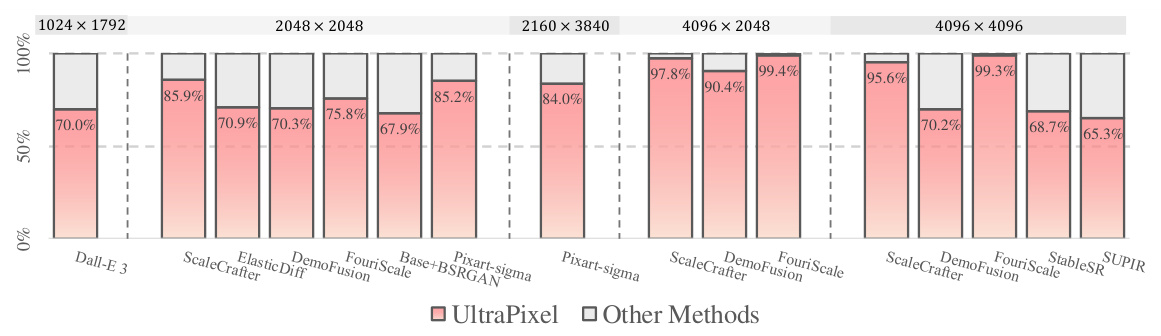
This figure presents a bar chart comparing the performance of UltraPixel against other state-of-the-art methods for generating high-resolution images at various resolutions (1024x1792, 2048x2048, 2160x3840, 4096x2048, and 4096x4096). The win rate is calculated using PickScore [25], a metric that measures the alignment of generated images with human preferences. UltraPixel consistently demonstrates higher win rates across all resolutions compared to the other methods, suggesting superior image quality and a greater ability to align with human aesthetic preferences.

This figure presents a visual comparison of image generation results between UltraPixel and other state-of-the-art methods across various resolutions. The comparison highlights UltraPixel’s superior ability to produce high-resolution images with enhanced detail and superior structural integrity, showcasing its advantage over existing methods that may suffer from artifacts or lack of fine detail.

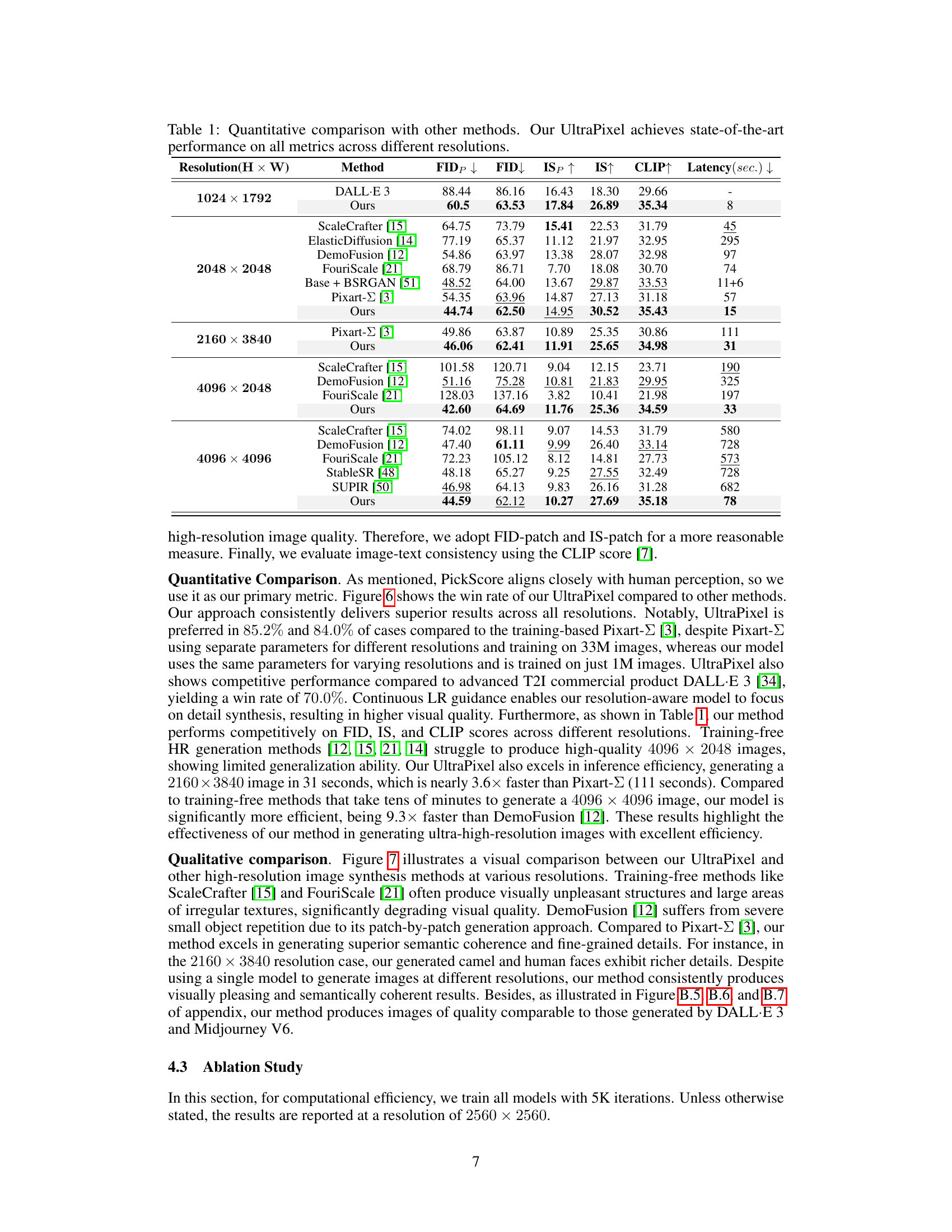
This figure demonstrates the effectiveness of low-resolution (LR) guidance in improving the quality of high-resolution (HR) image generation. It shows a comparison between generating HR images with and without LR guidance. The results show that using LR guidance leads to clearer structures, fine-grained details, and higher image quality.

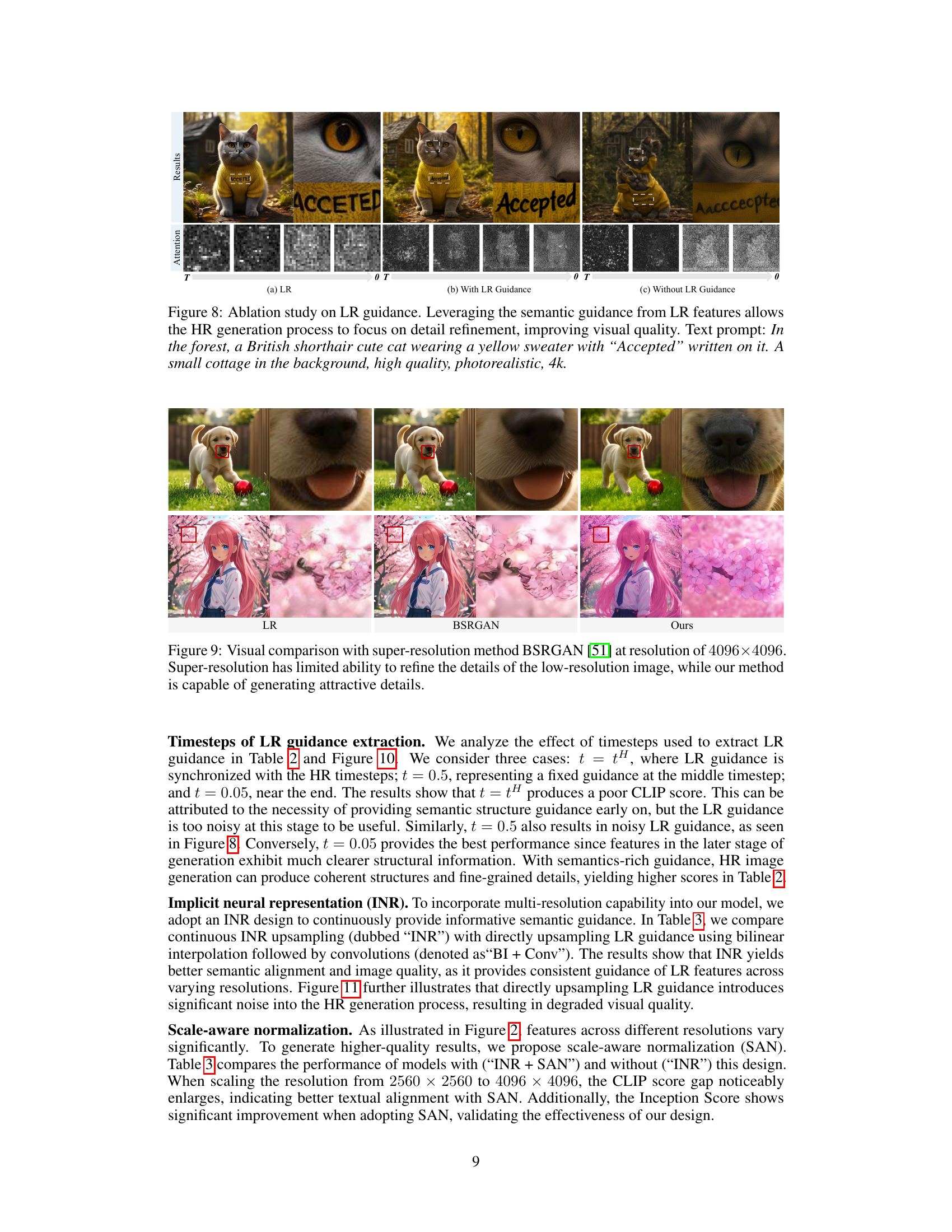
This figure compares the image generation results of the proposed UltraPixel method with those of the BSRGAN super-resolution method at a resolution of 4096 × 4096 pixels. Two example image pairs are shown: one of a puppy and another of an anime character. The comparison highlights UltraPixel’s ability to generate images with superior detail and clarity, compared to simply upscaling a lower-resolution image with BSRGAN.

This figure compares the results of high-resolution image generation with different guidance strategies. The left side shows the results when using low-resolution (LR) guidance at different time steps (t=tH, t=0.5, t=0.05) during the high-resolution (HR) generation process. The right side is the same as the left side, but with different prompts. By comparing the images, it shows that using low-resolution guidance at the time step t=0.05, semantic information is clearer.

This figure demonstrates the effectiveness of the implicit neural representation (INR) method used to continuously upscale the low-resolution guidance features to match the resolution of the high-resolution features. The top row shows the results without INR, where artifacts are more prominent at higher resolutions. The bottom row displays results with INR; more consistent detail is maintained across varying resolutions, showcasing the benefit of INR in generating higher-quality images.

This figure compares the reconstruction quality of StableCascade and SDXL on high-resolution images using their respective VAEs. It visually demonstrates how well each model reconstructs images after compression and decompression through the latent space. The comparison highlights the trade-off between compression ratio and reconstruction fidelity, showing StableCascade achieves higher compression but lower reconstruction quality compared to SDXL.

This figure compares the results of three methods in generating high-resolution images from a low-resolution input. The first column shows the low-resolution image. The second column shows the result after upsampling using the BSRGAN method. The third column shows the result obtained by the UltraPixel method proposed in the paper. Two example image pairs are shown: a log cabin scene and a close-up of a child’s face. The comparison highlights that the UltraPixel method is better at preserving and adding details compared to the BSRGAN method, which tends to produce somewhat blurry and less-detailed output.

This figure compares the results of the proposed UltraPixel method with two other generative diffusion-based super-resolution methods, StableSR and SUPIR, at a resolution of 4096x4096 pixels. The comparison demonstrates the superior detail and visual quality of UltraPixel compared to the other two methods, highlighting its ability to generate high-resolution images with enhanced detail and superior structures. The images illustrate that while the other methods increase resolution, they fail to add sufficient details, unlike UltraPixel which maintains a high level of detail and overall visual appeal.

This figure compares the image generation results of UltraPixel against other methods (ScaleCrafter, DemoFusion, FouriScale, Pixart-sigma) across different resolutions (2048x2048, 2160x3840, 4096x4096). It highlights the superior quality of images generated by UltraPixel, particularly in terms of detail richness and overall structure.

This figure compares the image generation results of UltraPixel with those from DALL-E 3, a leading commercial text-to-image model. The comparison is shown across various scenes, including landscapes, portraits, and wildlife. It highlights UltraPixel’s ability to generate high-quality and detailed images that are on par with the quality achieved by DALL-E 3.

This figure visually compares the image generation results of the proposed UltraPixel model with those of Midjourney V6, a leading commercial text-to-image generation model. The comparison focuses on images rendered at a resolution of 2048 x 2048 pixels. Three sets of paired images are presented, showcasing different subject matters: a person on skis in a snowy mountain landscape, a koala bear clinging to a tree, and a log cabin in a winter forest. The comparison aims to demonstrate the quality and detail achieved by the UltraPixel model relative to Midjourney V6.

This figure showcases the image generation capabilities of the UltraPixel model. It displays a variety of images generated at different resolutions, highlighting the model’s ability to produce highly photorealistic and detailed results across a range of image sizes.

This figure showcases the results of the UltraPixel model, demonstrating its ability to generate high-quality images at various resolutions, ranging from 1536x2560 to 5120x5120 pixels. The images depict a variety of subjects and styles, showcasing the model’s versatility and ability to capture fine details. The figure highlights the model’s ability to generate high-resolution images that are both photorealistic and detail-rich, exceeding the capabilities of many existing methods.

This figure shows several example images generated by the UltraPixel model at different resolutions, ranging from 1536x2560 to 5120x5120 pixels. The images demonstrate the model’s ability to generate high-quality, detailed images across a range of resolutions and aspect ratios. The images depict various subjects, including a peony flower, a woman’s portrait, a landscape scene, and two rabbits. The variety of subjects shows the model’s versatility.

This figure showcases the image generation capabilities of the UltraPixel model. It presents various example images generated at different resolutions (3840x5120, 2560x5120, 5120x3072, 4096x4096, 4096x2048, 2560x1536) to demonstrate the model’s ability to produce high-quality, detailed images across a range of scales. The images encompass diverse subjects, including a flower, a woman’s portrait, a landscape, a statue, a close-up of a woman’s eye, and rabbits. The appendix contains a list of the text prompts used for image generation.

This figure shows several example images generated by the UltraPixel model at different resolutions, showcasing its ability to produce high-quality, photorealistic images with fine details across a range of image sizes. The variety of subjects and styles highlights the model’s versatility.

This figure shows examples of images generated by the UltraPixel model at various resolutions, showcasing its ability to produce high-quality, photorealistic images with rich details. The different image sizes demonstrate the model’s scalability and performance across a range of resolutions.

This figure showcases example images generated by the UltraPixel model at various resolutions, demonstrating the model’s ability to produce high-quality, photorealistic images with rich details across different scales. The images depict a range of subjects and scenes, highlighting the model’s versatility and effectiveness.

This figure shows a collection of images generated by the UltraPixel model, showcasing its ability to produce photorealistic and highly detailed images at various resolutions, ranging from 1536 x 2560 to 5120 x 5120 pixels. The images demonstrate the model’s versatility across different subject matter and styles (portrait, landscape, animal, etc.). The varied aspect ratios further showcase the model’s adaptability.

This figure showcases the visual results generated by the UltraPixel model, demonstrating its capability to produce high-quality, photorealistic images at different resolutions, ranging from 1536x2560 to 5120x5120 pixels. Each image depicts a different subject (flower, woman, mountain scenery, statue, eyes, and rabbits), highlighting UltraPixel’s versatility and ability to capture fine details across varied styles and resolutions.

This figure showcases the visual results of the UltraPixel model, demonstrating its ability to generate high-quality images across a range of resolutions (from 1536x2560 to 5120x5120 pixels). The images depict diverse subjects, including a peony flower, a portrait of a woman, a landscape painting, and two rabbits. The high level of detail and photorealism achieved by the model is evident in each image.

This figure showcases sample images generated by the UltraPixel model at different resolutions, demonstrating its capability to produce high-quality, photorealistic results with rich details across various scales. The wide range of resolutions highlights the model’s versatility.

This figure showcases the visual results of the UltraPixel model. It presents eight different images generated at various resolutions, highlighting the model’s capacity for creating high-quality, detailed images across a wide range of sizes. The images illustrate different styles, including portraits, landscapes and animal close-ups, demonstrating the model’s versatility.

This figure shows examples of images generated by the UltraPixel model at different resolutions, ranging from 1536x2560 to 5120x5120 pixels. The images demonstrate the model’s ability to produce high-quality, detailed images across a wide range of sizes. The variety of subjects (flower, portrait, landscape) showcases the model’s versatility.
More on tables

This table presents an ablation study on the impact of different timesteps used to extract low-resolution (LR) guidance for high-resolution image generation. It compares the performance (CLIP score and Inception Score) at resolutions 2560x2560 and 4096x4096 using three different LR guidance extraction timesteps: synchronized with high-resolution timesteps (t=tH), a fixed middle timestep (t=0.5), and a timestep near the end (t=0.05). The results demonstrate that extracting LR guidance near the end of the process (t=0.05) yields superior performance compared to other timesteps.

This table compares the peak signal-to-noise ratio (PSNR), compression ratio, and the number of parameters between StableCascade and SDXL, two different models for image generation. It demonstrates that StableCascade achieves significantly higher compression with a slightly lower PSNR, indicating a trade-off between efficiency and reconstruction quality.

This table presents a quantitative comparison of UltraPixel’s performance against several other state-of-the-art methods for high-resolution image generation. Metrics include FID (Fréchet Inception Distance), a measure of image quality; IS (Inception Score), another measure of image quality; CLIP score, reflecting the alignment between image content and text prompt; and latency, the time taken to generate images. The comparison is done across multiple resolutions (1024x1792, 2048x2048, 2160x3840, 4096x2048, and 4096x4096), showing UltraPixel’s consistent superior performance.

This table presents a quantitative comparison of UltraPixel’s performance against other state-of-the-art methods for high-resolution image generation. Metrics include FID (Fréchet Inception Distance), FID-patch (FID calculated on image patches), IS (Inception Score), IS-patch (IS calculated on image patches), CLIP (Contrastive Language–Image Pre-training) score, and inference latency (in seconds). The comparison is conducted across multiple resolutions (1024x1792, 2048x2048, 2160x3840, 4096x2048, and 4096x4096), demonstrating UltraPixel’s superior performance and efficiency.
Full paper#