↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Weakly supervised learning trains models using imperfect labels, creating challenges for accurate performance evaluation. Traditional metrics like accuracy require ground truth labels, which are often expensive or unavailable in this setting. This limitation hinders the progress and wider application of weakly supervised learning. This paper tackles this problem by shifting the evaluation from the search for point estimates to deriving reliable performance bounds.
The researchers propose using Fréchet bounds to estimate these bounds. Their method efficiently calculates the upper and lower bounds on accuracy, precision, recall, and F1-score without using ground truth labels. They achieve this through scalable convex optimization, solving computational limitations of previous approaches. The paper presents a practical algorithm, quantifies uncertainty in estimations and demonstrates the approach’s robustness in high-dimensional scenarios, expanding the practical applicability of weakly supervised learning.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses a critical challenge in weakly supervised learning: evaluating model performance without ground truth labels. Its novel approach using Fréchet bounds offers a robust and computationally efficient solution, enabling more reliable model assessment and wider adoption of weakly supervised methods in various applications.
Visual Insights#
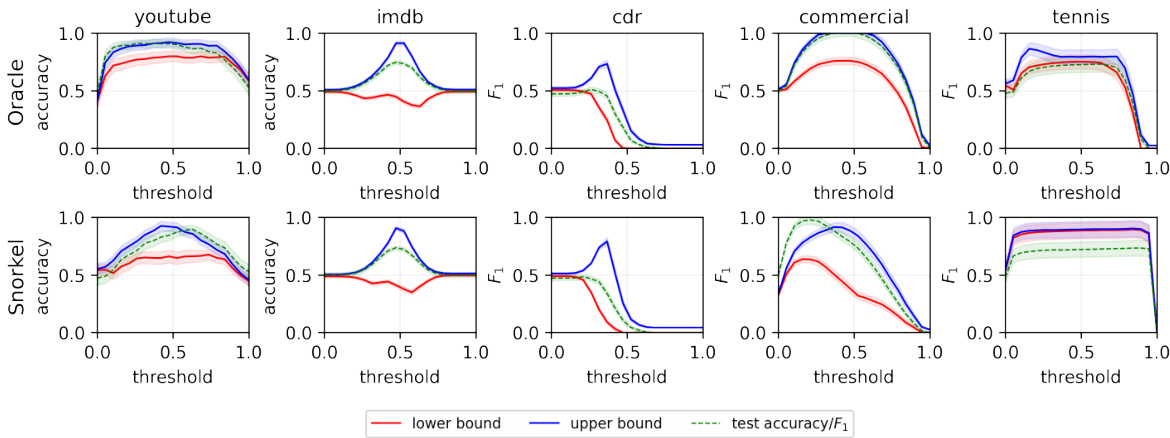
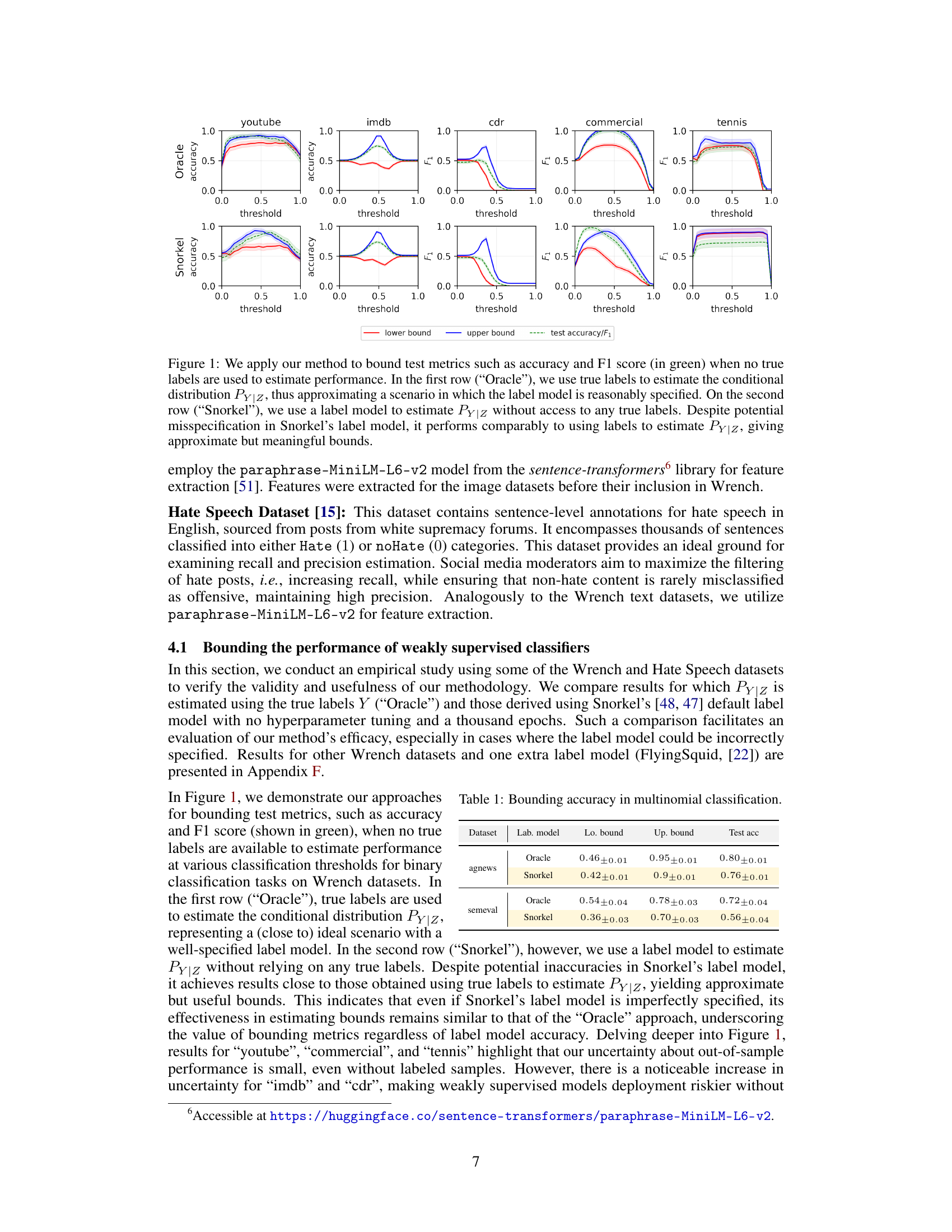
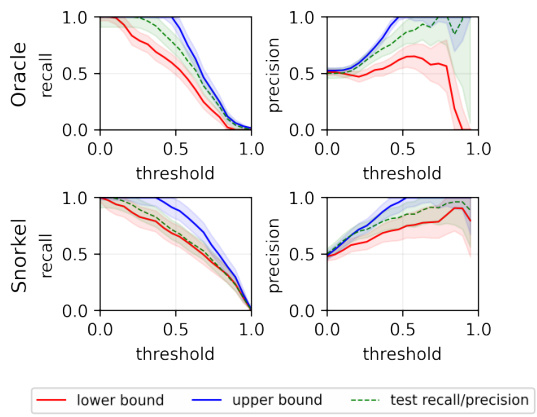
This figure compares the performance of the proposed method for estimating Fréchet bounds on test accuracy and F1-score in two scenarios: one where the true labels are available (‘Oracle’) and one where only a label model is available (‘Snorkel’). The results demonstrate that even with potential misspecification in the label model, the proposed method provides reasonably accurate bounds on the performance metrics, highlighting its applicability in weak supervision settings.
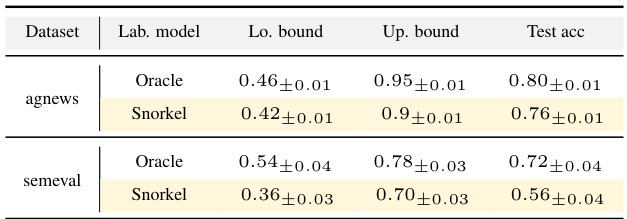
This table presents the results of bounding accuracy for multinomial classification using two different label models: Oracle (using true labels) and Snorkel (using a learned label model). The table shows the lower bound, upper bound, and test accuracy for each model on the agnews and semeval datasets. The results demonstrate that the proposed method can provide reasonable bounds on the performance of weakly supervised models, even when the label model is not perfectly specified.
In-depth insights#
Weak Supervision Eval#
Weak supervision, while offering advantages in reducing labeling costs, presents significant challenges for evaluation. Traditional metrics like accuracy are inapplicable due to the absence of true labels. The core problem in ‘Weak Supervision Eval’ lies in the need for novel approaches that can reliably quantify model performance without ground truth. This necessitates a shift from direct performance measurement to methods focusing on uncertainty quantification, possibly through techniques like partial identification or constructing confidence intervals around performance estimates. A promising direction would be to leverage the available weak labels to infer bounds on key metrics, rather than pinpoint a single value. Successfully addressing ‘Weak Supervision Eval’ will involve developing computationally efficient and statistically sound techniques capable of estimating those bounds. These techniques will be crucial for comparing models, selecting appropriate thresholds, and ultimately building confidence in the reliability of weakly-supervised systems. The development of such methods will be key to unlocking the full potential of weak supervision in real-world applications.
Fréchet Bounds#
The concept of Fréchet bounds is central to this research, offering a novel approach to evaluating weakly supervised models. Traditional evaluation metrics are inapplicable due to the absence of ground truth labels. The authors ingeniously frame model evaluation as a partial identification problem, leveraging Fréchet bounds to determine reliable performance bounds (accuracy, precision, recall, F1-score) without labeled data. This method addresses a critical limitation in weakly supervised learning by providing robust and computationally efficient estimations even with high-dimensional data. The approach’s efficacy is demonstrated empirically, highlighting its value in real-world scenarios where acquiring ground truth is impractical. While the reliance on assumptions about the data’s distribution warrants scrutiny, the theoretical justification and empirical validation firmly establish Fréchet bounds as a powerful tool in weakly supervised learning.
Model Perf. Bounds#
The heading ‘Model Perf. Bounds’ likely refers to a section detailing the estimation of model performance bounds using techniques that don’t rely on ground truth labels. This is particularly relevant in weakly supervised learning settings, where obtaining complete ground truth is costly or impossible. The methods described likely involve statistical techniques to determine upper and lower bounds for metrics like accuracy, precision, and recall. Partial identification and Fréchet bounds are potential approaches to rigorously quantify these bounds. The significance lies in enabling reliable model evaluation even without the traditional requirement of a fully labeled dataset, making weakly supervised learning more practical and trustworthy. Computational efficiency of the proposed methods is a vital factor as high-dimensional data is frequently involved in machine learning.
Method Limitations#
The method’s reliance on finite sets for Y and Z, while enabling efficient computation, restricts its applicability to problems like classification. Extending to continuous spaces requires tackling complex optimization challenges. The dependence on accurate marginal distribution estimates (Px,z, Py,z) introduces sensitivity to noise and potential misspecification. Robustness analysis regarding the impact of label model inaccuracies on bound estimation is crucial but limited in this work. The scalability to high-dimensional data (X) hinges on the computational efficiency of solving convex programs; however, the feasibility for extremely high dimensions requires further investigation. The assumption of bounded measurable function g also warrants careful consideration, as it could restrict the applicability to certain problems and the choice of g itself influences bound tightness.
Future Research#
Future research directions stemming from this work on weakly supervised learning performance evaluation could explore several promising avenues. Extending the Fréchet bound estimation to continuous label spaces would significantly broaden the applicability of the method. This requires overcoming theoretical challenges in the dual formulation and developing efficient algorithms for high-dimensional settings. Investigating the impact of label model misspecification on the accuracy of the estimated bounds is crucial for practical applications. Developing robust techniques that provide reliable bounds even under significant model misspecification would be valuable. Exploring different types of weak supervision signals beyond heuristics and pre-trained models, such as incorporating external knowledge bases or leveraging human-in-the-loop approaches could enhance the framework’s versatility and practical relevance. Finally, integrating the proposed evaluation methodology into existing weak supervision frameworks and developing user-friendly tools could make the approach accessible to a wider audience of practitioners and facilitate broader adoption of weakly supervised learning in real-world applications.
More visual insights#
More on figures
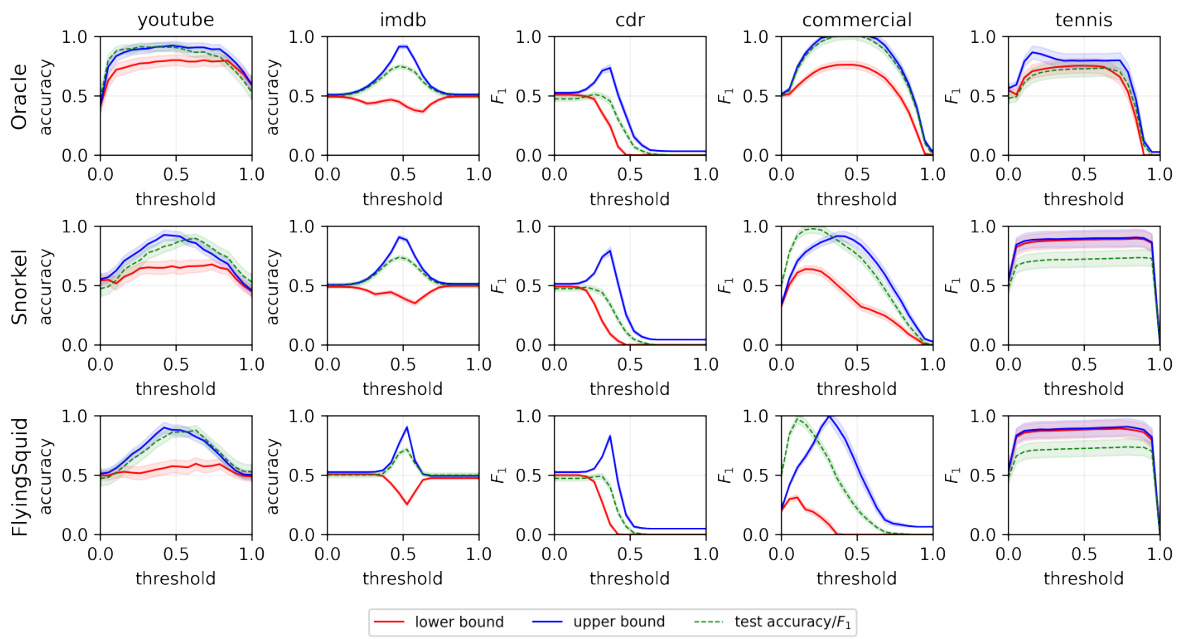
The figure shows the results of applying the proposed method to estimate the Fréchet bounds for accuracy and F1 score on several datasets. The first row uses true labels to estimate the conditional distribution, while the second row uses a label model. Despite potential misspecifications in the label model, the bounds are still reasonably accurate, demonstrating the robustness of the method.
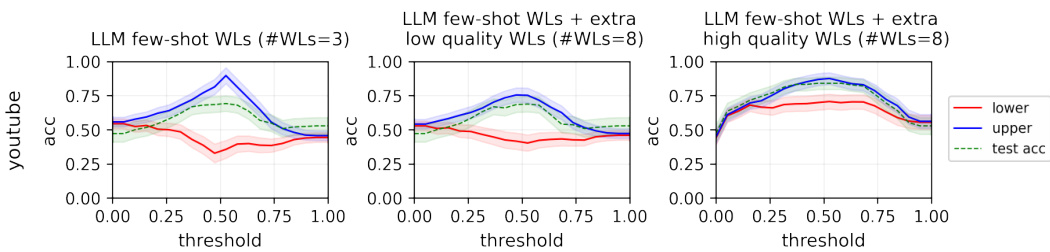
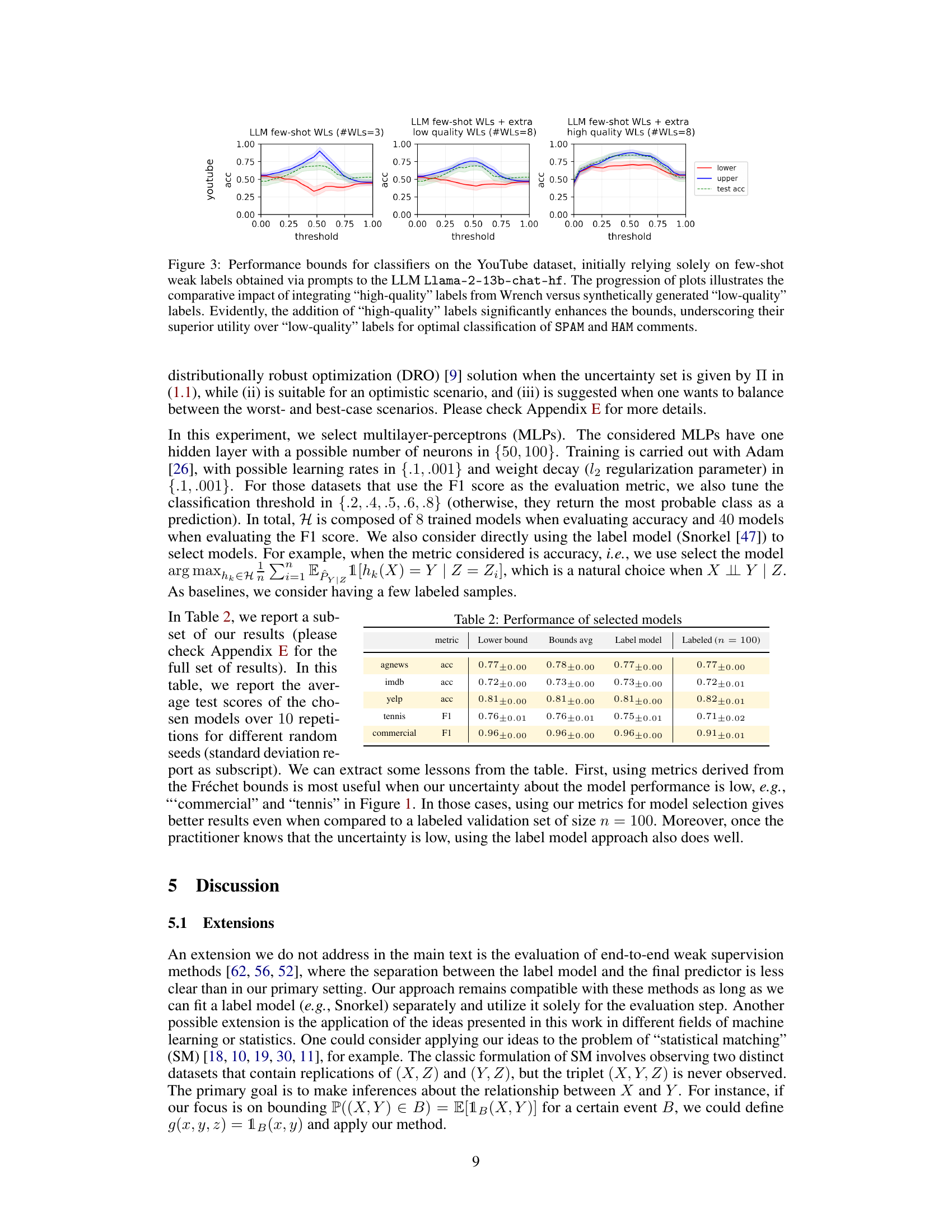
This figure shows the performance bounds for classifiers trained on the YouTube dataset using three different sets of weak labels: 1) only few-shot labels from the LLM Llama-2-13b-chat-hf, 2) few-shot labels + extra low-quality synthetic labels, and 3) few-shot labels + extra high-quality labels from the Wrench dataset. The figure demonstrates that adding high-quality labels significantly improves the accuracy of the performance bounds, highlighting their importance for reliable model evaluation.
The figure shows the effectiveness of the proposed method in estimating the bounds of test metrics (accuracy and F1 score) for various classification thresholds, even when true labels are unavailable. The ‘Oracle’ row uses true labels to estimate the conditional distribution, serving as a benchmark. The ‘Snorkel’ row uses a label model, demonstrating that even with potential model misspecification, the method provides meaningful bounds.
This figure shows the effectiveness of the proposed method in estimating the bounds of test accuracy and F1 score for different classification thresholds, even without access to ground truth labels. The top row uses true labels to estimate the conditional probability distribution PY|Z, serving as an ‘oracle’ baseline. The bottom row uses a label model to estimate PY|Z, simulating a realistic weak supervision scenario. The results demonstrate that the method produces meaningful and relatively accurate bounds even with label model misspecification.
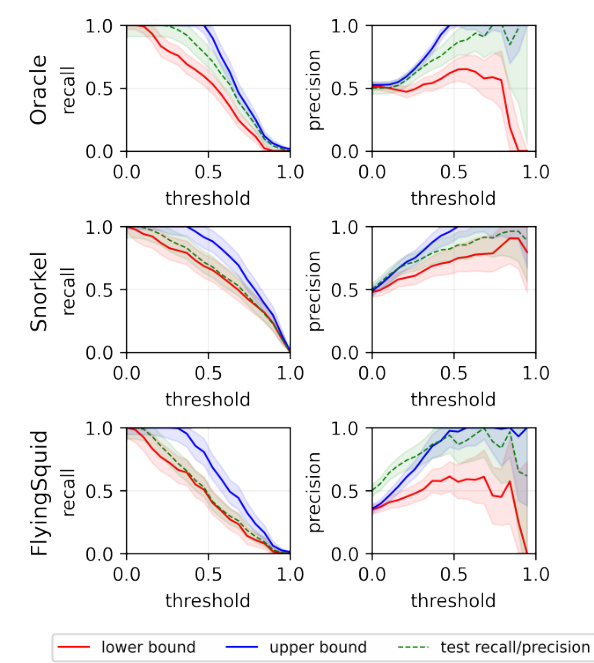
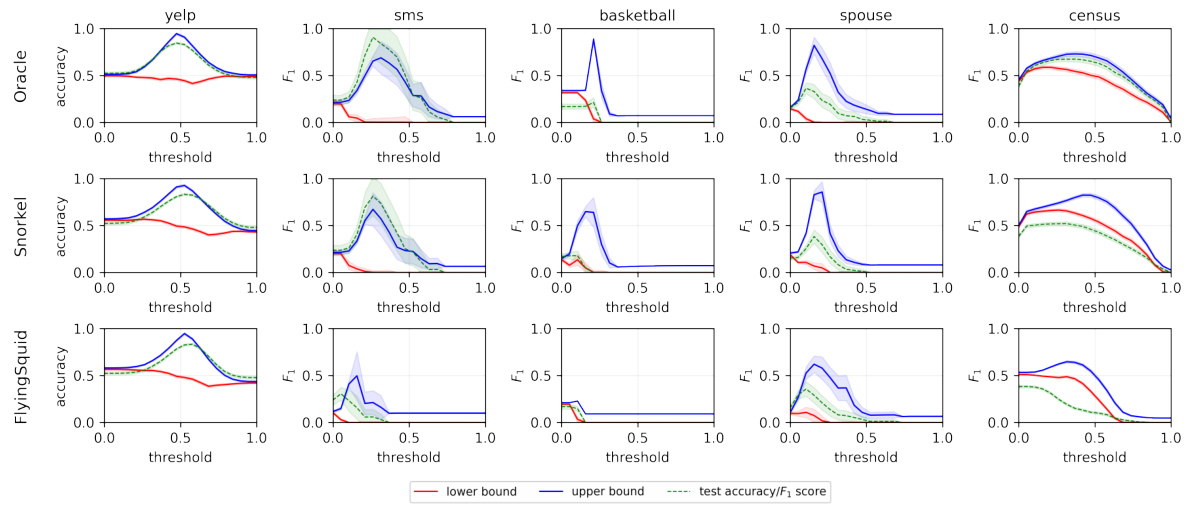
The figure shows the results of applying the proposed method to estimate the upper and lower bounds of accuracy and F1 score for several datasets. The first row uses true labels to estimate the conditional distribution of Y given Z (PY|Z). The second row uses Snorkel’s label model to estimate PY|Z, showing that the proposed approach provides reliable bounds even with a misspecified label model. The x-axis represents the classification threshold, and the y-axis represents the accuracy and F1 score.
More on tables
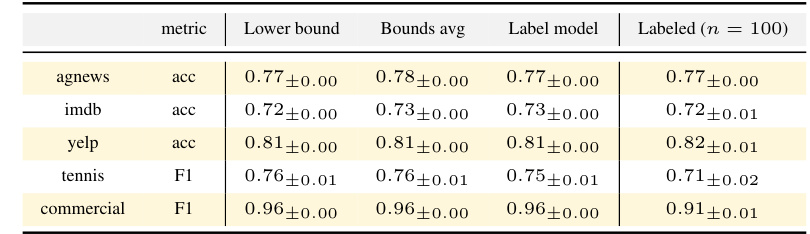
This table presents the performance of various models selected using different strategies: using the lower bound, average of bounds, label model, and a labeled dataset with 100 samples. The performance is measured using accuracy and F1 scores for different datasets (agnews, imdb, yelp, tennis, commercial). The results highlight that the proposed methods using Fréchet bounds perform better than the label model and are comparable to using a small labeled dataset.

This table presents the performance of different models on various datasets, comparing various metrics like accuracy and F1 score. It shows the lower and upper bounds of these metrics, the average of the bounds, results using only the label model, and results using a small set of labeled data (n = 10, 25, 50, 100). This helps to assess the impact of different model selection strategies on accuracy and F1 scores in the context of weak supervision.

This table presents the performance of various models selected using different strategies based on the Fréchet bounds. The models were evaluated on several datasets from the Wrench benchmark, measuring accuracy or F1 score, depending on the dataset. The results are compared against the performance of models selected using a traditional approach (label model) and models trained with a small set of labeled data (Labeled (n=10), Labeled (n=25), Labeled (n=50), Labeled (n=100)). The table demonstrates the effectiveness of using Fréchet bounds for model selection, especially when uncertainty around model performance is low.

This table presents the results of bounding accuracy for multinomial classification using three different label models: Oracle, Snorkel, and FlyingSquid. The Oracle model uses true labels, while Snorkel and FlyingSquid are weak supervision methods. The table shows the lower bound, upper bound, and test accuracy for each label model on four different datasets: agnews, trec, semeval, and chemprot. The results demonstrate the ability of the proposed method to estimate reliable performance bounds even without access to ground truth labels.
Full paper#