↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Adapting large-scale vision-language models for video recognition is challenging. Existing methods struggle to balance zero-shot generalization (performing well on unseen data) and close-set performance (high accuracy on seen data). Adding specialized parameters boosts close-set accuracy but hurts zero-shot performance. This creates a trade-off, hindering the development of truly robust video AI systems.
This paper introduces MoTE, a novel framework that overcomes this limitation. MoTE uses a mixture of temporal experts to learn multiple views of the data, improving generalization. Weight Merging Regularization helps the model effectively combine the knowledge learned by these experts, and Temporal Feature Modulation further refines the model’s ability to generalize. Through extensive experiments, MoTE achieves a superior balance between zero-shot and close-set accuracy, outperforming existing approaches on various datasets. This work provides a significant advancement in video knowledge transfer, paving the way for more robust and adaptable video AI systems.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on video recognition and knowledge transfer. It directly addresses the trade-off between generalization and specialization in adapting large-scale foundation models for video understanding. The proposed MoTE framework offers a novel solution, improving both zero-shot and close-set performance, which opens exciting new avenues for more robust and efficient video AI.
Visual Insights#

This figure provides a comparison of existing visual-language model (VLM) transfer methods for video recognition. Panel (a) shows a trade-off curve illustrating the relationship between zero-shot (generalization) and close-set (specialization) performance. Panel (b) demonstrates how the number of temporal layers impacts both zero-shot and close-set performance, with MoTE showing consistent improvement regardless of layer count. Panel (c) visually represents how MoTE aims to bridge the gap between generalized and specialized solutions, creating a reconciled feature space.

This table presents the results of an ablation study conducted to evaluate the impact of different components of the MoTE model on its performance. The study uses the ViT-L/14 network. It shows the performance of the baseline model (Text4Vis) and then progressively adds components of MoTE (temporal experts, weight merging regularization, MSE loss, and temporal feature modulation) to assess the effect of each component on the final performance, measured using Top-1 accuracy on Kinetics-400 and zero-shot accuracy on UCF101, HMDB, and Kinetics-600.
In-depth insights#
VLM Video Adaptation#
Adapting Vision-Language Models (VLMs) for video presents unique challenges due to the temporal dimension. Effective VLM video adaptation hinges on bridging the gap between the static nature of image-text data used for VLM pre-training and the dynamic, sequential information inherent in videos. This often involves incorporating additional modules to capture temporal dependencies, such as recurrent neural networks or transformers. A critical aspect is managing the trade-off between generalization (maintaining the VLM’s broad knowledge) and specialization (incorporating video-specific knowledge). Methods often employ techniques like prompt engineering, adapters, or temporal modules, but increasing specialization can hurt zero-shot performance. Successful adaptation strategies must carefully balance these competing needs, often employing regularization techniques to prevent overfitting to the limited video training data and enhance generalization. This is a rapidly evolving field with ongoing research exploring more efficient and effective approaches to unlock the full potential of VLMs for video understanding tasks.
MoTE Framework#
The MoTE framework, designed for visual-language to video knowledge transfer, tackles the inherent trade-off between generalization and specialization in existing methods. Its core innovation is a Mixture-of-Temporal-Experts architecture, where multiple experts learn diverse data bias views, promoting generalization. A crucial component is Weight Merging Regularization, which optimizes the merging of these experts, balancing specialization with the preservation of generalized knowledge. Temporal Feature Modulation further enhances generalization during inference by modulating the contribution of temporal features based on semantic association with test data. This multifaceted approach allows MoTE to achieve state-of-the-art results by successfully reconciling generalization and specialization, a significant advancement in video recognition models.
Expert Knowledge#
The concept of ‘Expert Knowledge’ in the context of a visual-language to video knowledge transfer model is crucial. It suggests the model learns specialized knowledge through distinct “experts”, each focusing on various aspects of video data. This specialization allows the model to capture diverse data bias views, leading to improved generalization. The idea is to create a balance between generalization (handling unseen data) and specialization (mastering specific video features). A key challenge is aggregating this diverse expert knowledge effectively, while avoiding overfitting. Mechanisms like weight merging and regularization become necessary to combine expert knowledge, achieving a unified model that excels in both zero-shot and close-set performance. The efficacy of this approach depends heavily on how effectively individual experts are trained and their knowledge integrated, demonstrating a refined balance between generalization and specialization within the model.
Generalization Tradeoffs#
The concept of “Generalization Tradeoffs” in the context of visual-language to video knowledge transfer is a crucial consideration. It highlights the inherent tension between a model’s ability to generalize to unseen data (zero-shot performance) and its capacity for specialization on a specific task (close-set performance). Adding specialized parameters often improves close-set accuracy but can hinder zero-shot generalization, resulting in a trade-off. The ideal scenario is to strike a balance, allowing for strong performance in both scenarios. This requires careful consideration of model architecture, training techniques (e.g., regularization), and potentially data augmentation strategies. Methods that successfully reconcile generalization and specialization are highly valuable because they offer robustness and adaptability to a broader range of video recognition tasks and applications, leading to more versatile and effective video understanding systems.
Future Work#
The authors acknowledge limitations and propose several avenues for future research. Extending the semantic space of the model beyond video category names is crucial, possibly using large language models to incorporate richer textual descriptions. They also plan to explore adapting the framework to other parameter types used in VLM adaptation, enhancing generalizability. Improving the efficiency of the model’s architecture, particularly in managing the computation cost associated with the mixture-of-experts, is another key area. Finally, exploring real-world applications of the refined framework, while addressing privacy and ethical considerations, represents a significant challenge and opportunity for future work.
More visual insights#
More on figures
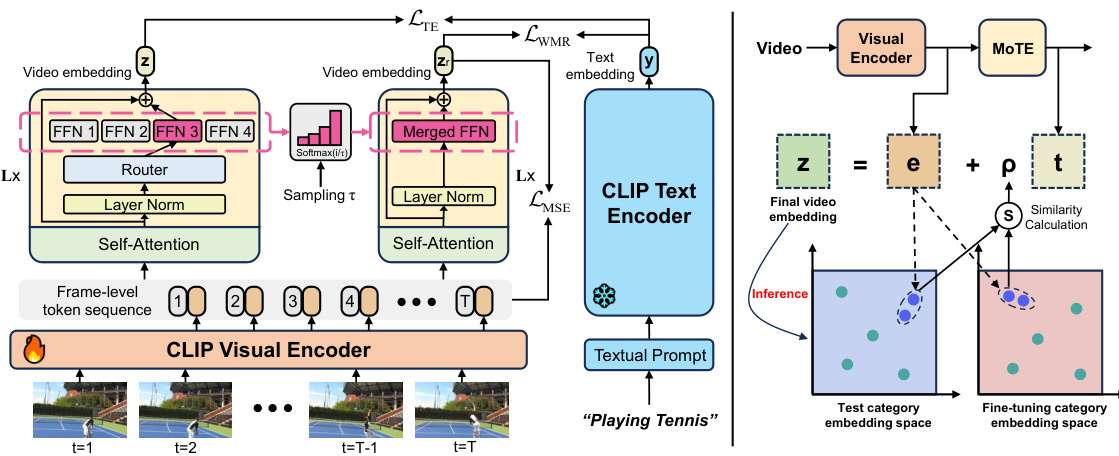
This figure illustrates the MoTE (Mixture-of-Temporal-Experts) framework for video recognition. The left side shows the process during training: frame-level features are extracted using a CLIP visual encoder; these are then fed to a router that assigns them to one of multiple temporal experts (FFNs) based on a multinomial distribution; the outputs of the experts are merged using a softmax function with temperature sampling; finally, the merged features are used for training. The right side demonstrates inference: a semantic association is calculated between features from fine-tuning and test data to modulate the temporal features before they’re used to produce the final video embedding. The overall goal is to reconcile generalization and specialization in VLM transfer for video recognition by creating a mixture of expert modules that can generalize well to new data while also specializing in the task at hand.
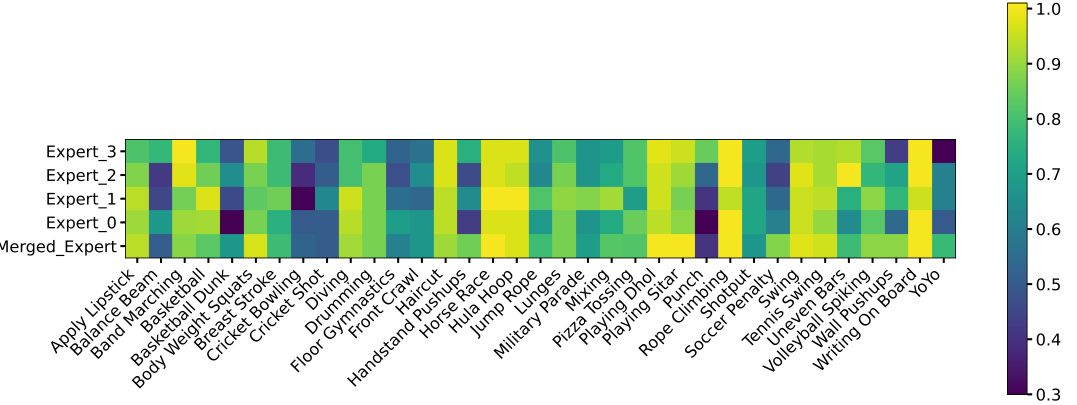
This figure shows the performance of each individual expert and the final merged model in terms of Top-1 accuracy on Kinetics-400 close-set, UCF101 zero-shot, and HMDB zero-shot video recognition tasks. It demonstrates that each expert learns distinct knowledge, leading to varying performance across different tasks. The merged model combines the strengths of all experts, resulting in improved performance compared to individual experts or a baseline CLIP model using mean pooling.

This figure presents four different designs for the temporal expert module used in the MoTE architecture. The standard Transformer Layer is shown on the left. The four variations (a) - (d) modify the feed-forward network (FFN) within the Transformer Layer. (a) keeps the FFN intact. (b) replaces the FFN with separate projection layers for both upward and downward paths, each with 4 experts and a router. (c) only replaces the upward projection path with experts. (d) only replaces the downward projection path with experts. The router is used to select an expert for each input.

This figure visualizes attention maps generated by the merged expert and two individual experts (Expert 0 and Expert 4) in the MoTE model. The top row shows the original RGB images, and the rows below show the corresponding attention maps, highlighting the regions of the image that each model focuses on. The purpose is to demonstrate that different experts focus on different aspects of the video frames, and that the merged expert integrates information from all experts. This visualization supports the claim that MoTE effectively combines the knowledge learned by individual experts to achieve better performance.
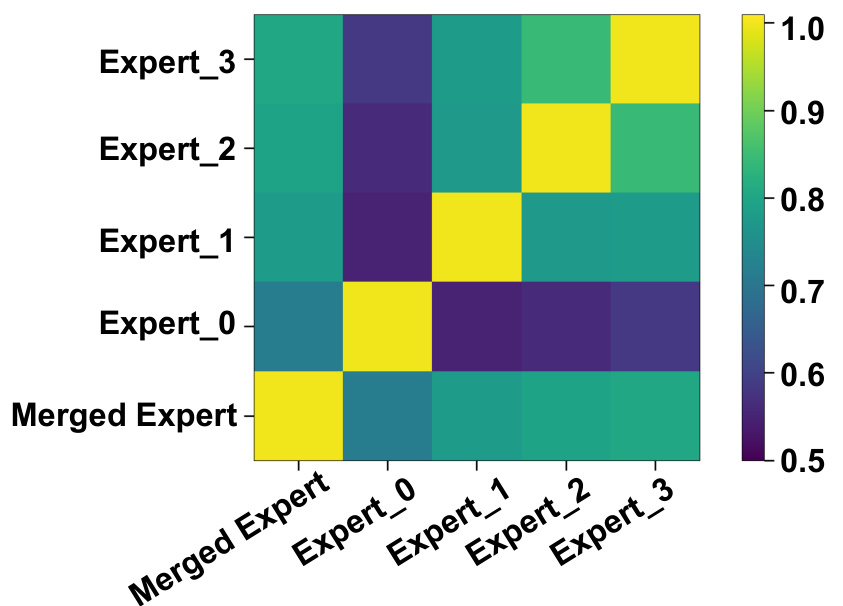
This figure displays a heatmap visualizing the cosine similarity between the feature representations of individual temporal experts (Expert_0, Expert_1, Expert_2, Expert_3) and the merged expert (the combined output of all experts) in the MoTE model. Each cell in the heatmap represents the average cosine similarity calculated across 100 randomly sampled videos from unseen categories of the Kinetics-600 dataset. Warmer colors (yellow) indicate higher similarity, signifying that the feature spaces are more alike. Cooler colors (purple) indicate lower similarity, suggesting greater differences in the learned representations between experts. The figure demonstrates that the merged expert’s feature representation incorporates features from all individual experts while maintaining distinct characteristics.
More on tables
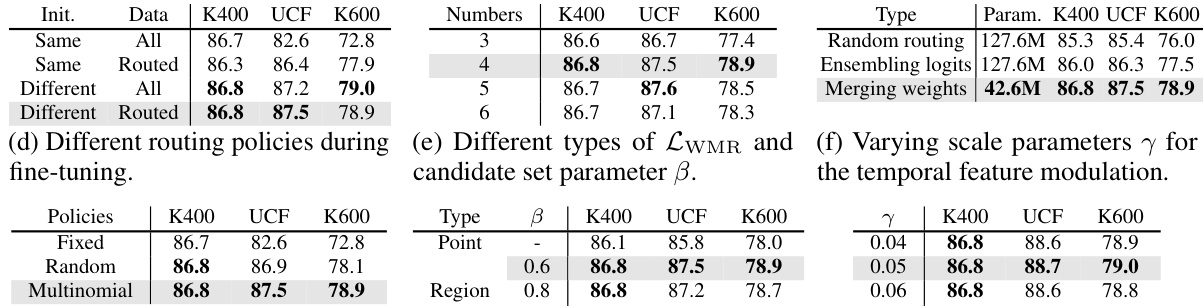
This table presents ablation study results focusing on the impact of different hyperparameters and design choices on the performance of the MoTE model. It shows the effect of various factors, such as initialization and training data distribution across experts, the number of temporal experts, knowledge aggregation methods, routing policies during fine-tuning, different types of Weight Merging Regularization, and different scale parameters for temporal feature modulation, on the model’s performance. The results are evaluated in terms of top-1 accuracy on the Kinetics-400 (K400) dataset for close-set evaluation, and on UCF-101 and K600 (split1) datasets for zero-shot evaluation. The table provides quantitative evidence to support the claims about MoTE’s design choices and their effects on performance.
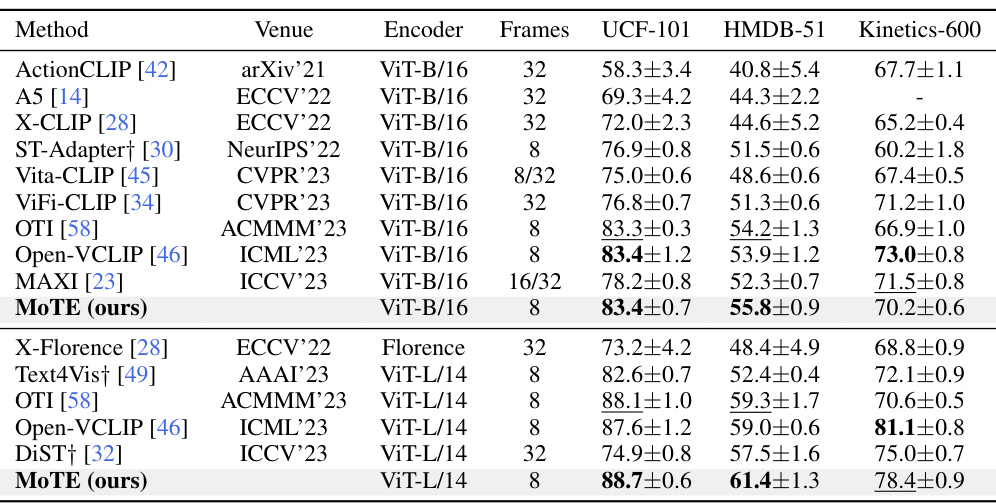
This table presents a comparison of the proposed MoTE model’s zero-shot video recognition performance against several state-of-the-art methods. The comparison is done across three benchmark datasets: UCF-101, HMDB-51, and Kinetics-600. The table shows the top-1 accuracy achieved by each method on each dataset, along with details like the encoder used (ViT-B/16 or ViT-L/14), the number of frames used as input, and whether the results were reproduced by the authors of the current paper.

This table compares the performance of MoTE against other state-of-the-art methods in video recognition. It shows both close-set (Kinetics-400) and zero-shot (UCF-101, HMDB-51, Kinetics-600) results. The ‘HMzs’ column represents the harmonic mean of the zero-shot results across the three datasets. The ‘Trade-off’ score balances both close-set and zero-shot performance, highlighting MoTE’s ability to perform well on both aspects simultaneously. The ‘Unified model’ column indicates whether the same model was used for both close-set and zero-shot evaluations, emphasizing MoTE’s unified approach.
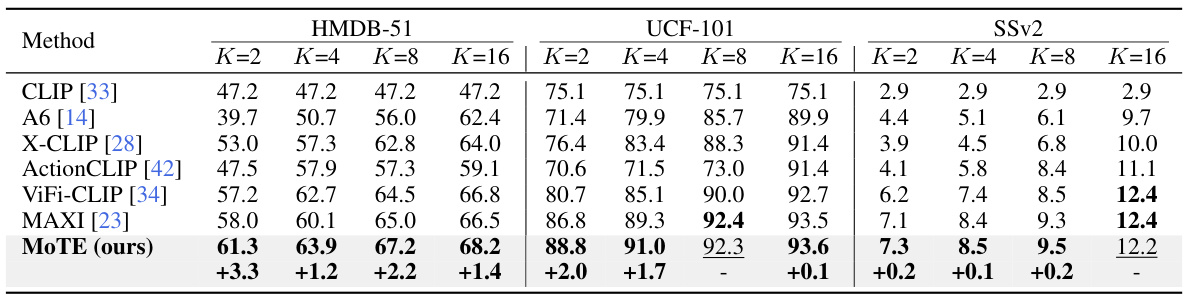
This table presents a comparison of few-shot video recognition performance between the proposed MoTE method and other state-of-the-art methods. The results are shown for different numbers of shots (K=2, 4, 8, 16) on three benchmark datasets: HMDB-51, UCF-101, and Something-Something V2 (SSv2). The table highlights the improvements achieved by MoTE compared to existing methods, particularly in terms of few-shot learning capability across various datasets.

This ablation study analyzes the impact of different components of the MoTE model on its performance. It uses the ViT-L/14 network and shows results for various metrics on the Kinetics-400, UCF-101, HMDB-51, and Kinetics-600 datasets, comparing a baseline (Text4Vis) against versions of MoTE with added components such as temporal experts, weight merging regularization (LWMR), mean squared error loss (LMSE), and temporal feature modulation. The table highlights the incremental performance improvements achieved by each component.

This table presents the results of ablation studies conducted to analyze different components of the MoTE model. It explores various architectural designs for the temporal expert, investigates the impact of changing the number of neighbors for temporal feature modulation, compares different types of weight merging regularization, examines the training costs, evaluates the model’s performance under different training scenarios, and assesses different temperature selection schemes.

This table presents an ablation study on the MoTE model using the ViT-L/14 network architecture. It systematically evaluates the contribution of different components of the MoTE framework to the overall performance, including temporal experts, weight merging regularization (LWMR), mean squared error (LMSE) loss, and temporal feature modulation. The results are shown in terms of Top-1 accuracy for zero-shot video recognition on the UCF-101, HMDB-51, and Kinetics-600 datasets, as well as close-set performance on the Kinetics-400 dataset. By comparing the performance with and without each component, the table quantifies the effectiveness of each component in improving both zero-shot generalization and close-set performance.
Full paper#



















