↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Long-tailed data distributions, where some classes have far fewer samples than others, pose a significant challenge for training effective machine learning models. Existing solutions like re-balancing or manual data augmentation have limitations, including a limited search space and reliance on manually-designed strategies. This often leads to suboptimal model performance and increased development costs.
The proposed LLM-AutoDA framework uses large language models (LLMs) to overcome these issues. By automatically searching for and applying optimal augmentation strategies, LLM-AutoDA significantly improves model performance on standard long-tailed learning benchmarks. The framework’s iterative process, guided by performance feedback, continually refines the generated strategies, leading to more robust and effective data augmentation. This automated approach offers significant advantages in efficiency and adaptability compared to traditional methods.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the pervasive long-tailed distribution problem in machine learning. It introduces a novel framework that automates data augmentation using large language models, improving model performance and efficiency, which is highly relevant to many current research areas dealing with imbalanced datasets. It also opens up exciting avenues for future research exploring the synergy between LLMs and automated machine learning.
Visual Insights#
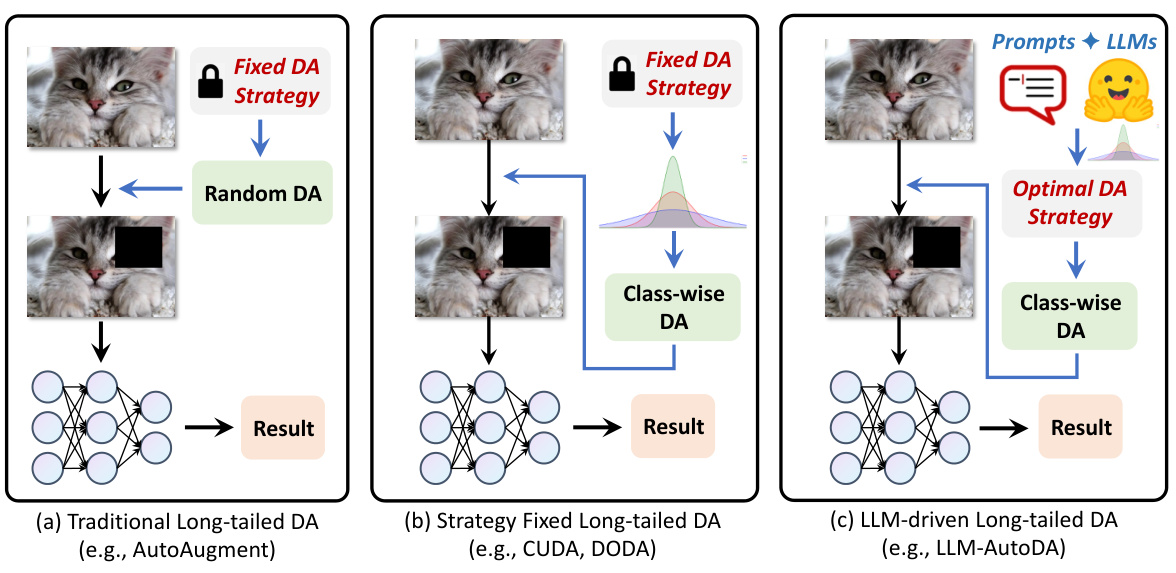
This figure illustrates three different paradigms for long-tailed data augmentation. (a) shows the traditional approach, where augmentations are randomly selected from a fixed set. (b) presents a strategy-fixed approach, where augmentations are selected based on the data distribution. (c) introduces the LLM-driven approach proposed in the paper, which leverages large language models to learn an optimal augmentation strategy.

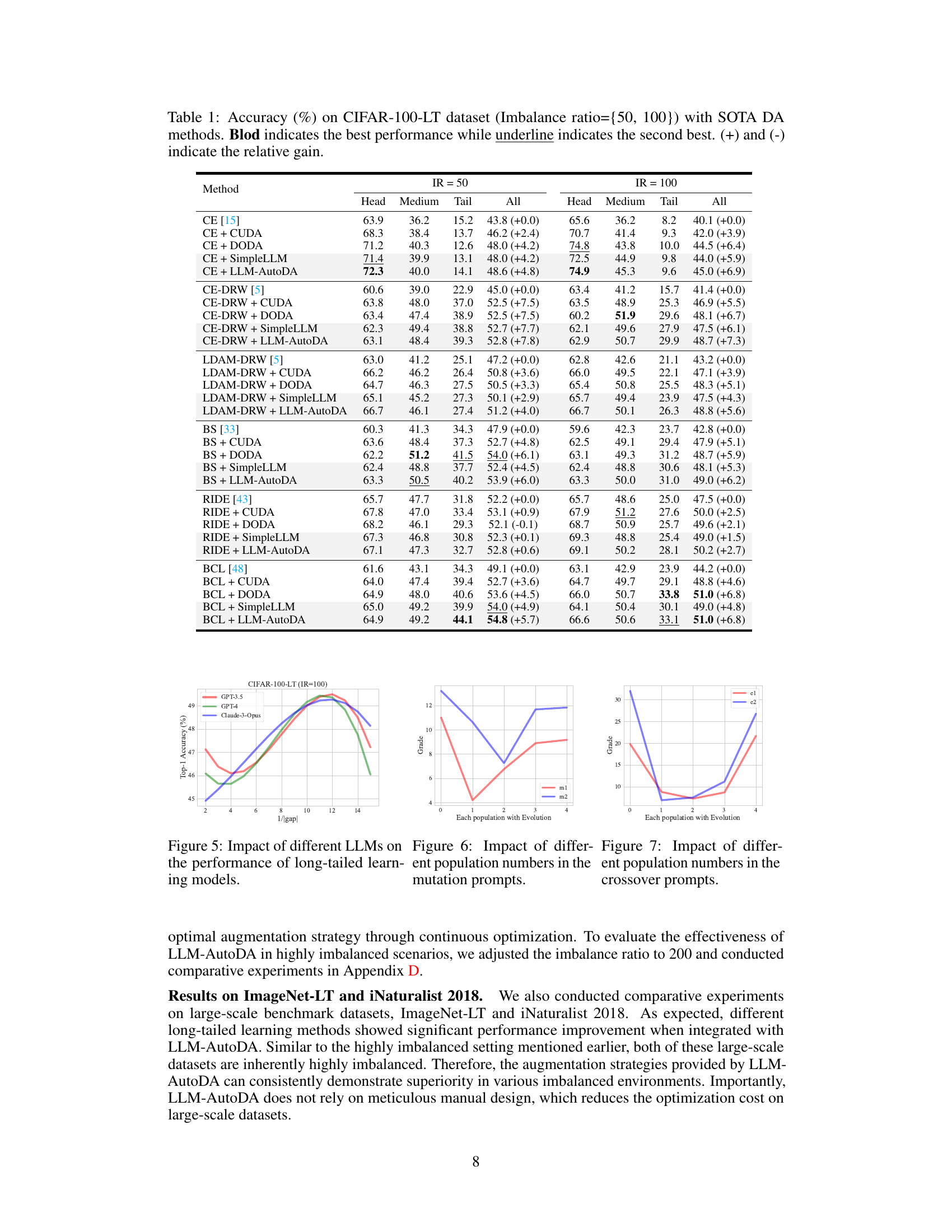
This table presents the Top-1 accuracy results on the CIFAR-100-LT dataset with an imbalance ratio of 50 and 100. It compares the performance of different baselines (CE, CE-DRW, LDAM-DRW, BS, RIDE, BCL) with and without several state-of-the-art data augmentation methods (CUDA, DODA, SimpleLLM, and LLM-AutoDA). The results are shown for the head, medium, tail, and all classes, indicating the effectiveness of each data augmentation strategy in handling class imbalance.
In-depth insights#
LLM-driven Augmentation#
LLM-driven data augmentation represents a significant paradigm shift in handling long-tailed learning challenges. By leveraging the power of large language models, this approach moves beyond manually designed augmentation strategies. LLMs can automatically generate diverse and optimized augmentation techniques tailored to the specific characteristics of imbalanced datasets. This automation not only saves significant time and effort but also allows exploration of a far wider range of augmentation strategies than previously possible. The dynamic adaptation of augmentation based on model performance, incorporated in many LLM-driven methods, further enhances effectiveness. However, challenges remain; the reliance on LLMs introduces potential biases and the need for careful prompt engineering, while the computational cost of using LLMs might be substantial. Further investigation into mitigating these limitations and exploring the full potential of this innovative approach is crucial for advancing long-tailed learning.
AutoML for LTL#
AutoML, aiming to automate machine learning pipeline optimization, presents a significant opportunity within the context of Long-Tailed Learning (LTL). LTL struggles with class imbalance, where some classes are vastly over-represented while others have few samples. AutoML can address this by automating the design of appropriate data augmentation strategies, loss functions, and sampling methods to balance the training data. This automation can discover solutions beyond the capabilities of human-designed approaches, possibly leading to improved performance and efficiency. However, AutoML for LTL faces challenges. The search space for optimal configurations explodes due to the intricate interaction of multiple hyperparameters. Successfully applying AutoML to LTL necessitates robust search algorithms and effective evaluation metrics that account for the unique complexities of imbalanced datasets. Furthermore, explainability remains a key concern: understanding why an AutoML system chose a particular configuration is crucial for ensuring fairness, building trust, and refining the methods. Research in this area is likely to focus on efficient search strategies, explainable AI techniques, and more effective evaluation criteria specific to LTL.
Long-tail DA Methods#
Long-tail data augmentation (DA) methods address the class imbalance problem inherent in long-tailed learning. Traditional DA techniques, such as random cropping and flipping, are insufficient as they don’t account for the scarcity of samples in tail classes. Effective long-tail DA methods focus on generating synthetic samples for these under-represented classes, often using techniques like class-specific augmentations, generative adversarial networks (GANs), or data resampling methods to balance the class distribution. The key challenge is finding the optimal balance between increasing diversity in tail classes and avoiding overfitting. Moreover, the choice of augmentation strategy significantly impacts the final model’s performance, requiring careful consideration of factors like class characteristics and available computational resources. Recent research leverages large language models (LLMs) to automate the search for optimal augmentation strategies, promising increased efficiency and effectiveness in handling long-tailed datasets. However, the automatic selection of appropriate augmentation strategies remains a research area of ongoing interest, with trade-offs between computational cost and achieved performance gains. Overall, the evolution of long-tail DA methods reflects a shift towards more sophisticated approaches that adapt to the unique characteristics of long-tailed distributions.
LLM Search Strategy#
An LLM search strategy for data augmentation in long-tailed learning would involve using a large language model (LLM) to generate diverse augmentation strategies. This approach would likely surpass traditional, manually designed methods by exploring a far broader search space. The LLM could be prompted with information on the dataset’s characteristics (e.g., class imbalance, image features) and potentially even the current model’s performance to generate relevant augmentations. A crucial aspect would be the evaluation and selection process. The generated augmentations need to be assessed, perhaps using metrics that quantify improvements in handling long-tailed distributions. A reinforcement learning framework might be ideal, where successful augmentations improve the model’s performance, thus guiding the LLM to generate more effective strategies in subsequent iterations. The LLM would essentially learn to generate optimal augmentations through this iterative feedback loop, potentially leading to significant advancements in long-tailed learning.
Future LTL Research#
Future research in long-tailed learning (LTL) should prioritize addressing remaining challenges in data augmentation. While LLM-AutoDA offers advancements, manually designed strategies still prove valuable. Investigating hybrid approaches, combining automatic and manual methods, may yield superior results. Another crucial area is exploring the generalizability of learned augmentation strategies. Current methods often excel on specific datasets but fail to generalize. Developing more robust strategies that adapt to diverse data distributions is key. Finally, deeper investigation into the interplay between LLMs and the underlying LTL models is needed. While LLMs assist in strategy generation, the optimal interaction and information exchange between them require further study. Understanding this connection will unlock the full potential of LLM-driven data augmentation and propel LTL towards even more effective solutions.
More visual insights#
More on figures

This figure illustrates the SimpleLLM framework, which uses prompts to guide a large language model (LLM) in generating data augmentation strategies. A non-parametric prompt is fed to the LLM, which then outputs an augmentation strategy. This strategy is subsequently applied to a long-tailed model for training. The process leverages the LLM’s capabilities to automatically create data augmentation strategies for improved performance in long-tailed learning scenarios.

LLM-AutoDA uses a two-module framework. First, an LLM-based augmentation strategy generation module uses prompt engineering to automatically generate augmentation strategies based on prior knowledge and store them in a repository. These strategies are evaluated by applying them to the original imbalanced data, creating an augmented dataset for training a long-tailed learning model. The performance on a validation set acts as a reward signal, updating the strategy generation model iteratively. This process continues until convergence or a computational budget is reached. The second module is a long-tailed learning training and evaluation module, which trains and evaluates the long-tailed learning model using the generated augmentation strategies.
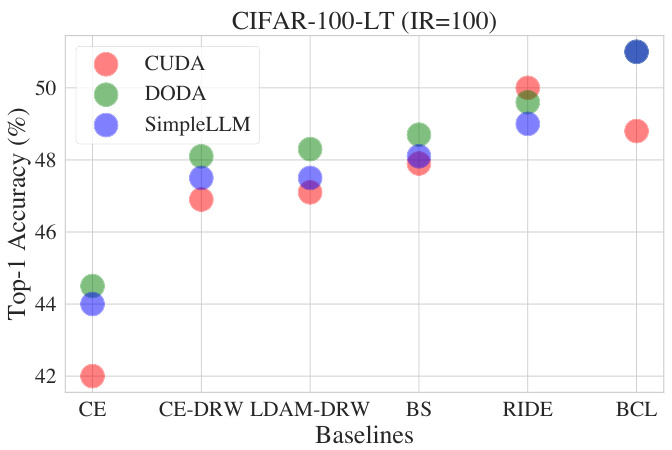
This figure compares the performance of different data augmentation methods (CUDA, DODA, and SimpleLLM) when combined with various long-tailed learning baselines on the CIFAR-100-LT dataset with an imbalance ratio of 100. It shows that SimpleLLM, despite its simplicity, achieves comparable results to the more sophisticated CUDA and DODA methods. This suggests that LLMs can be effective in generating data augmentation strategies for long-tailed learning.

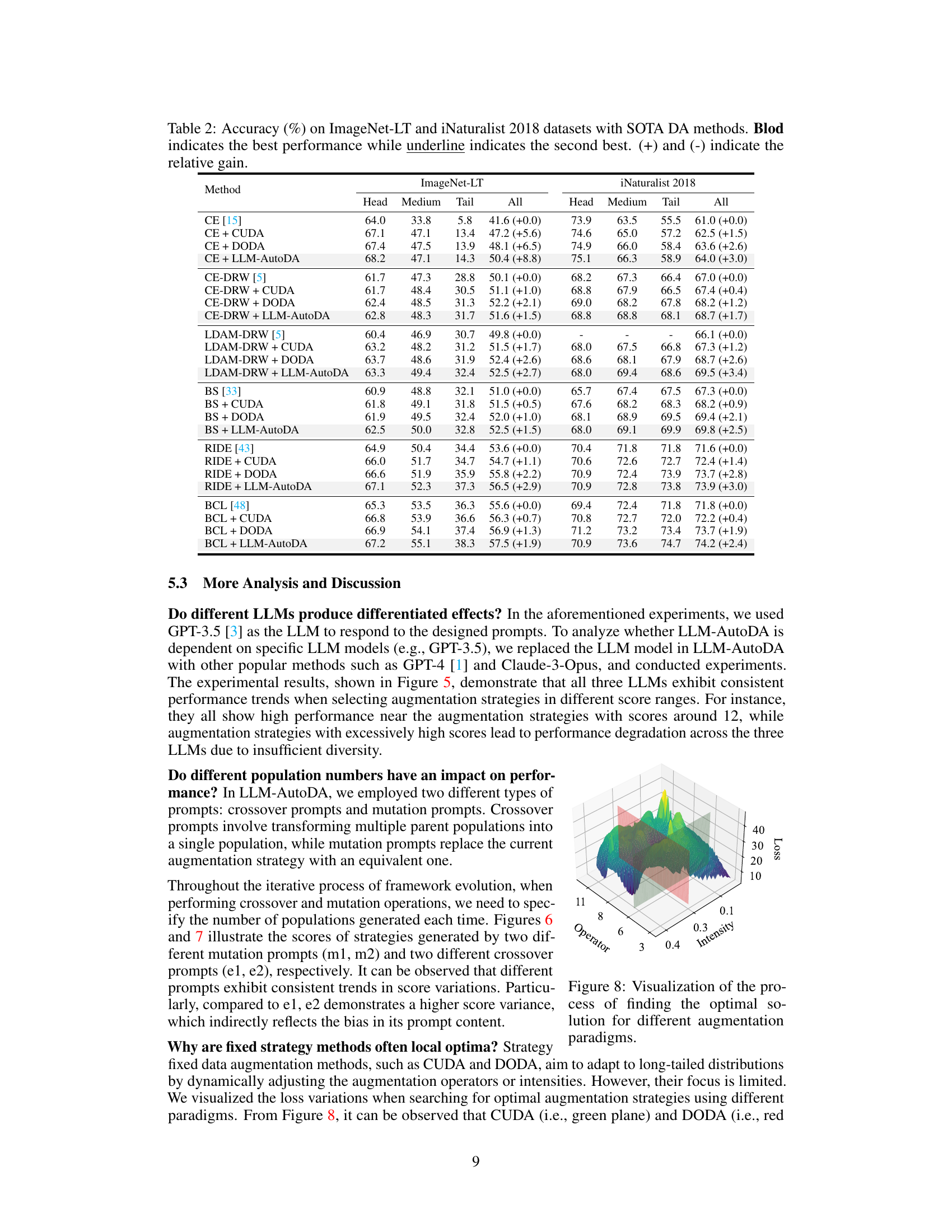
This figure shows the results of experiments comparing the performance of three different large language models (LLMs) in a long-tailed learning scenario. The x-axis represents the generation number in the evolutionary process, and the y-axis represents the Top-1 accuracy. The three LLMs used are GPT-3.5, GPT-4, and Claude-3-Opus. The figure demonstrates that each LLM exhibits a similar trend in performance, achieving high accuracy near the strategy with scores around 12, and showing performance degradation when using augmentation strategies with excessively high scores.
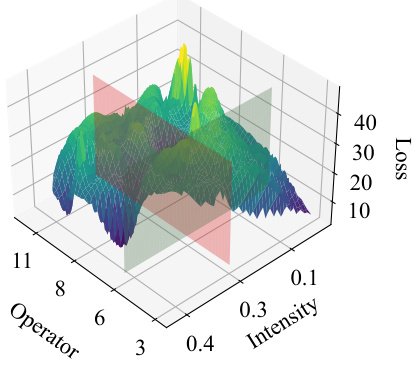
This figure visualizes the loss landscape for different data augmentation strategies. The x and y axes represent the augmentation operator and intensity, respectively, and the z-axis represents the loss. The figure shows that traditional fixed-strategy methods (like CUDA and DODA) search for optimal strategies only within a limited region (shown as the red and green planes), while LLM-AutoDA explores a larger search space and is able to find a global optimal solution (the lowest point on the surface).
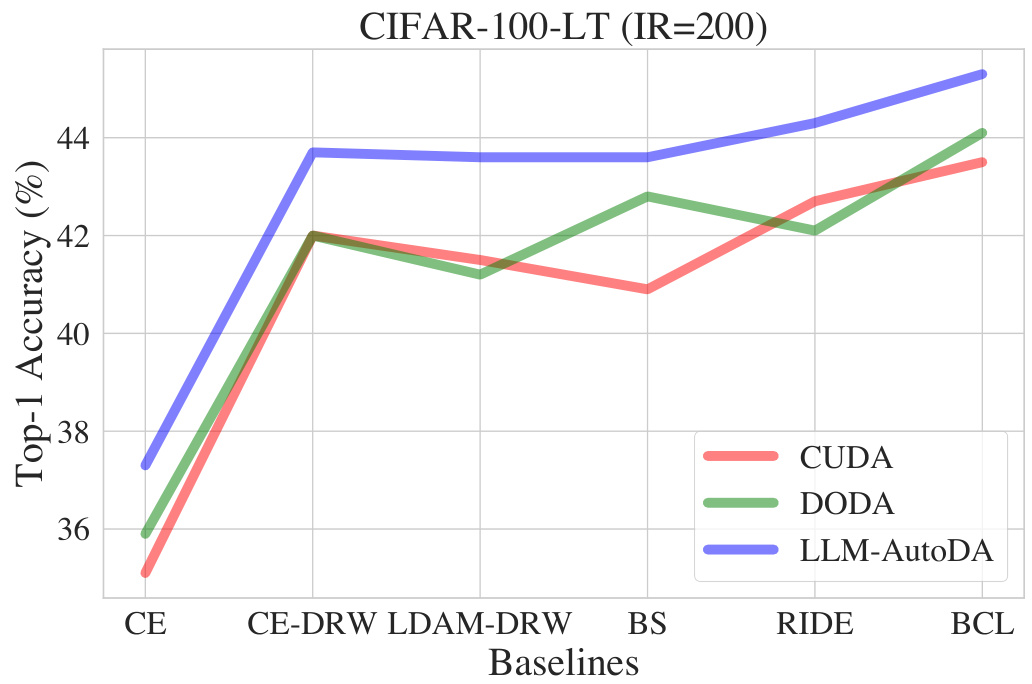
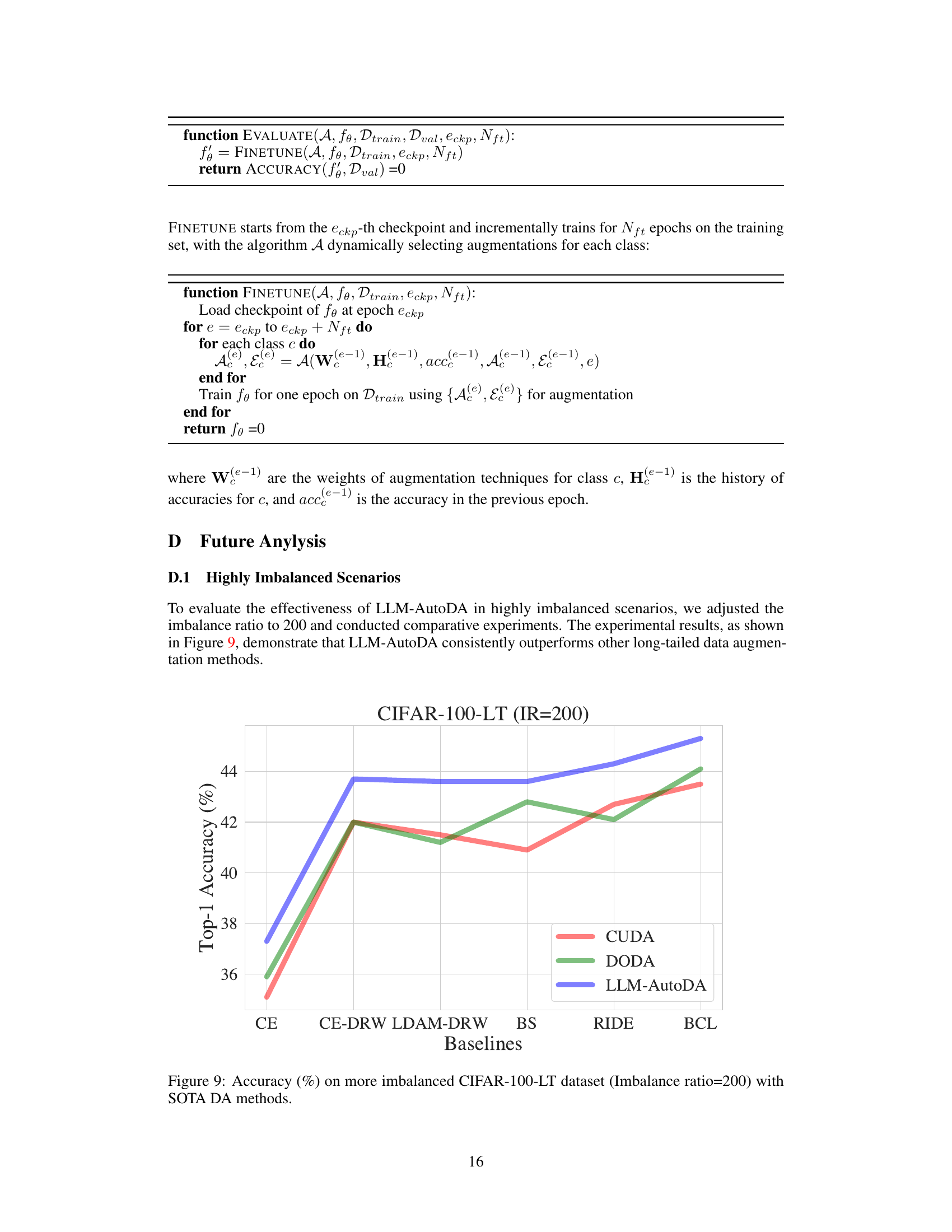
This figure compares the performance of different data augmentation methods on a highly imbalanced version of the CIFAR-100 dataset (imbalance ratio of 200). It shows Top-1 accuracy achieved by several long-tailed learning baselines (CE, CE-DRW, LDAM-DRW, BS, RIDE, and BCL) when combined with three data augmentation techniques: CUDA, DODA, and the proposed LLM-AutoDA. The results demonstrate LLM-AutoDA’s superior performance across various baselines, highlighting its effectiveness in addressing long-tailed problems with extreme class imbalance.
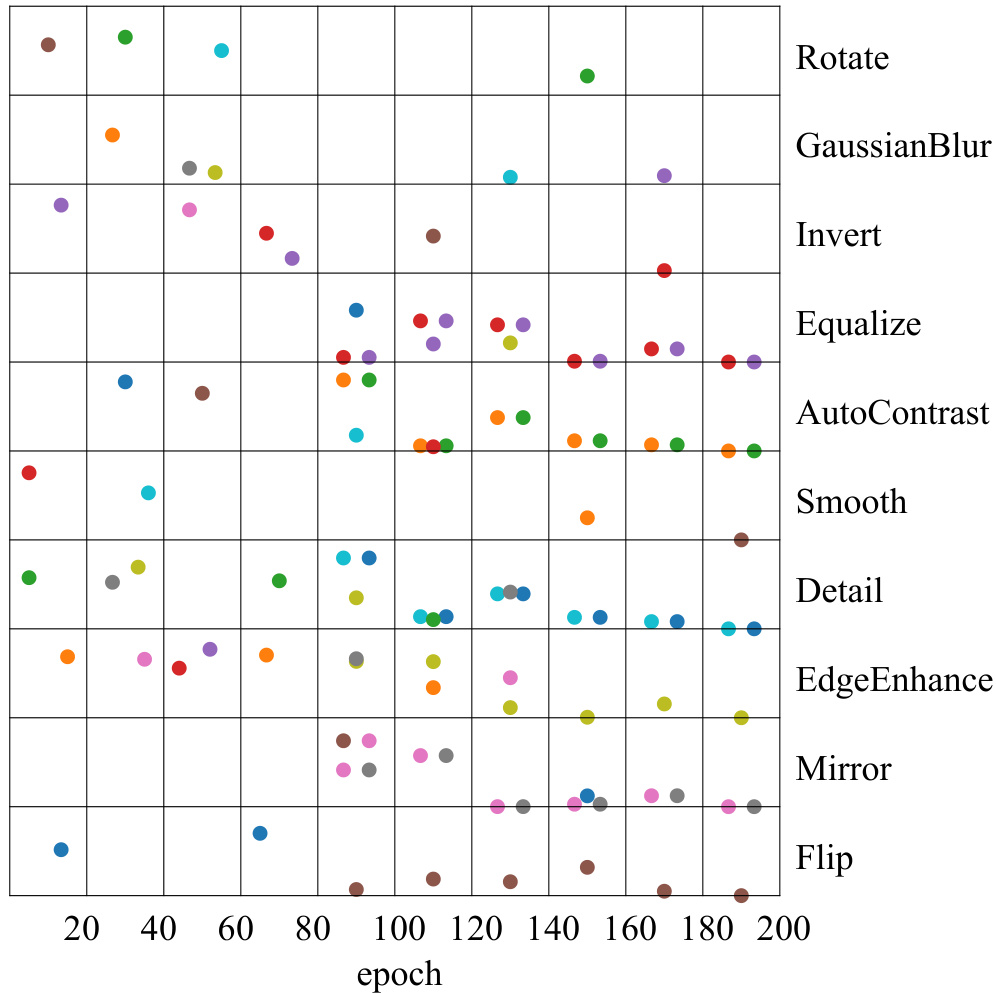
This figure visualizes how the selection of data augmentation strategies changes over training epochs. It shows the frequency with which different augmentation methods (Rotate, Gaussian Blur, Invert, etc.) are chosen and the intensity at which they’re applied. The data suggest that the model learns to prefer certain augmentation strategies over others as training progresses, demonstrating adaptation and learning within the augmentation strategy generation process.
More on tables
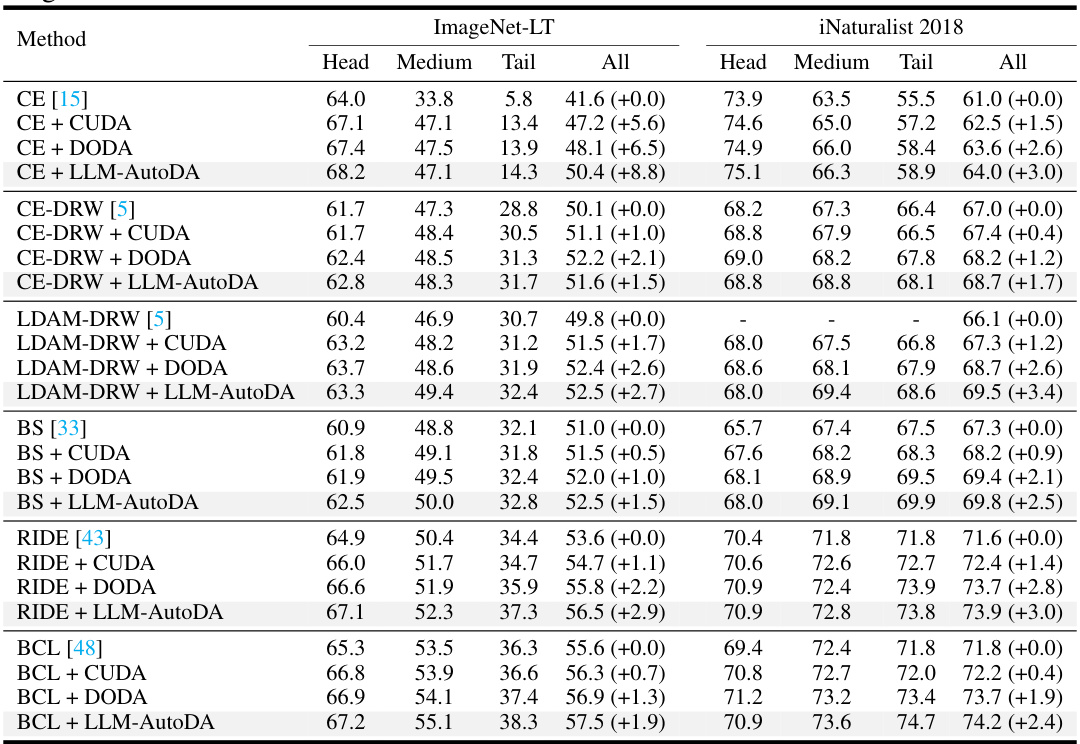
This table presents the classification accuracy results on the CIFAR-100-LT dataset with an imbalance ratio of 50 and 100. It compares the performance of the proposed LLM-AutoDA method against several state-of-the-art (SOTA) data augmentation (DA) methods and other re-balancing techniques. The accuracy is broken down by class (head, medium, tail) and overall, and the relative gain compared to a baseline is indicated.

This table presents the Top-1 accuracy results on the CIFAR-100-LT dataset (with imbalance ratios of 50 and 100) for different combinations of baseline methods and data augmentation strategies. It compares the performance of the proposed LLM-AutoDA with state-of-the-art (SOTA) data augmentation methods (CUDA and DODA) and various baseline long-tailed learning methods. The table shows the accuracy for each method across different class subsets (head, medium, and tail) and provides the overall accuracy. The relative gain (+) or loss (-) compared to the baseline is also indicated.
This table presents the Top-1 accuracy results on the CIFAR-100-LT dataset with imbalance ratios of 50 and 100. It compares the performance of the proposed LLM-AutoDA method against several state-of-the-art (SOTA) data augmentation methods and other re-balancing methods. The table shows the accuracy for head, medium, and tail classes, as well as the overall accuracy. The relative gain compared to the baseline is also shown, indicating the improvement achieved by each method.
Full paper#