↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Language Models (LLMs) are increasingly used for complex tasks requiring multiple calls, advanced prompting, and structured data. However, existing systems for programming and executing such applications are inefficient. This is because existing systems struggle with the non-deterministic nature of LLMs, resulting in tedious programming and redundant computations. They also lack effective mechanisms for reusing intermediate computational results, leading to wasted resources.
SGLang addresses these limitations by introducing a novel system for efficient execution of complex LLM programs. It features a frontend language simplifying programming with primitives for generation and parallelism, and a runtime that accelerates execution using several novel optimizations. These optimizations include RadixAttention for KV cache reuse and compressed finite state machines for structured output decoding. Empirical results demonstrate that SGLang achieves significant performance improvements, offering higher throughput and lower latency than state-of-the-art systems across various tasks.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large language models (LLMs) as it introduces SGLang, a novel system that significantly improves the efficiency of LLM program execution. Its impact lies in simplifying the programming of complex LLM applications and accelerating their execution through optimizations. This opens new avenues for developing advanced prompting techniques and agentic workflows, pushing the boundaries of LLM applications.
Visual Insights#
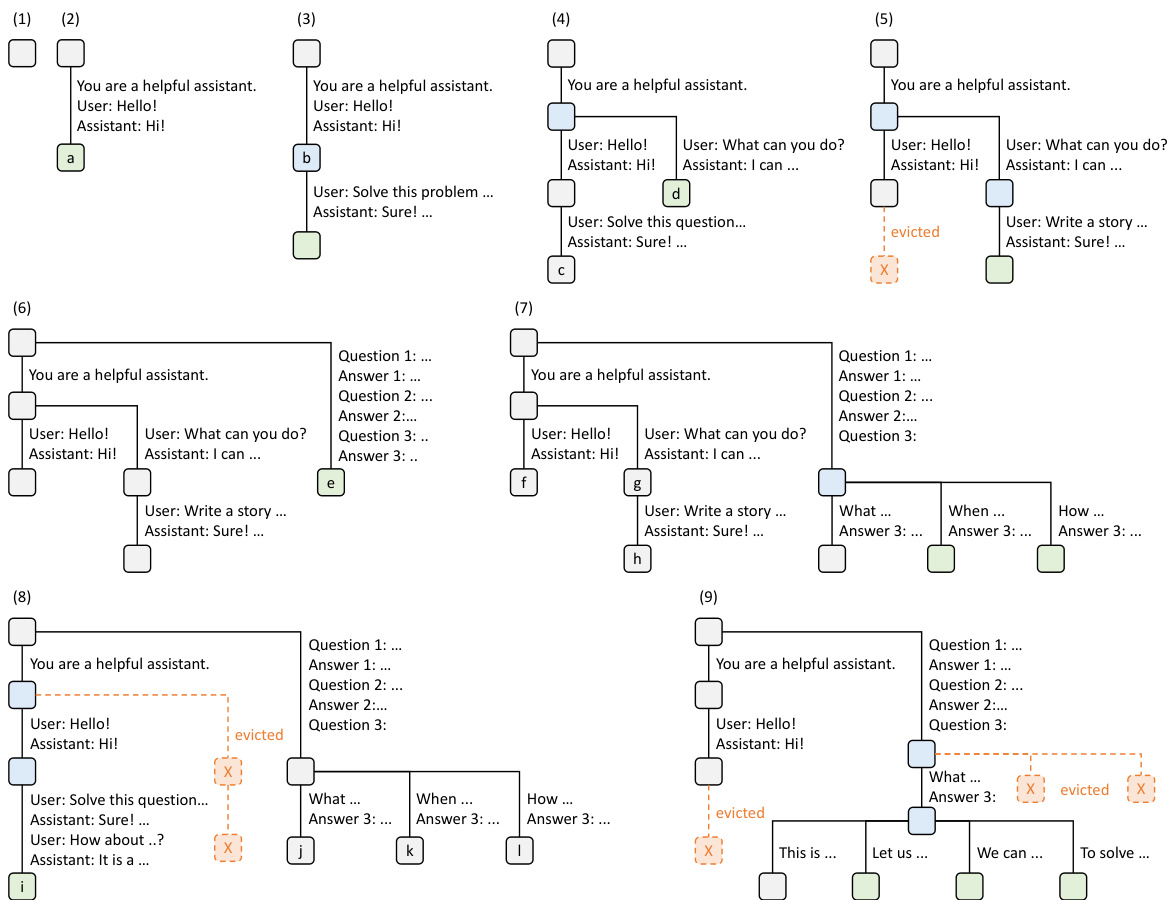
This figure visualizes how RadixAttention, a KV cache reuse technique, dynamically manages the cache using a radix tree and LRU eviction. Nine snapshots illustrate the tree’s evolution as it processes various requests (chat sessions, few-shot learning, self-consistency sampling). Node colors indicate their state (green: new, blue: accessed, red: evicted). The figure shows how the system reuses cached prefixes and evicts least recently used nodes to optimize memory usage.

This table compares three different programming systems for large language models (LLMs): LMQL, Guidance, and SGLang. For each system, it lists the syntax used, the language primitives provided (functions for interacting with LLMs), and the runtime backends supported (the underlying infrastructure used to execute the LLM calls). This helps illustrate the differences in ease of use, features, and performance capabilities of each system.
In-depth insights#
SGLang:Efficient Execution#
The paper introduces SGLang, a novel system designed for the efficient execution of complex Language Model (LM) programs. SGLang addresses the limitations of existing systems by offering a streamlined programming model and a high-performance runtime environment. The programming model simplifies the development of LM programs by providing primitives for generation, parallelism control, and integration with existing Python libraries, thus enhancing code readability and reducing development time. The runtime component accelerates execution through several key optimizations. RadixAttention, a novel technique, enables efficient reuse of the KV cache across multiple LLM calls by leveraging a radix tree data structure. This significantly reduces redundant computations and improves throughput. Furthermore, SGLang incorporates compressed finite-state machines for faster structured output decoding, effectively optimizing the decoding process for constrained formats such as JSON. Finally, API speculative execution is introduced to optimize the execution of programs using API-only models like OpenAI’s GPT-4, thus mitigating the cost and latency associated with multiple API calls. The experiments demonstrate that SGLang achieves substantial performance gains, showcasing improvements in throughput and latency compared to state-of-the-art baselines across various tasks and models.
RadixAttention:KV Cache#
RadixAttention is a novel technique for efficiently reusing the Key-Value (KV) cache in large language model (LLM) programs. Traditional inference engines discard the KV cache after each request, leading to redundant computation. RadixAttention addresses this inefficiency by storing the KV cache in a radix tree, a space-efficient data structure that allows for rapid lookup of shared prefixes among multiple requests. This enables the reuse of KV cache entries across different LLM calls that share a common prefix, significantly improving throughput. The system incorporates an LRU (Least Recently Used) eviction policy to manage the cache efficiently, and it’s designed to work well with other techniques like continuous batching and tensor parallelism. Furthermore, a cache-aware scheduling policy optimizes the order in which requests are processed, maximizing cache hit rates. The results demonstrate that RadixAttention achieves substantial speed improvements compared to existing approaches, showcasing its potential for enhancing the performance of LLM-based applications.
Compressed FSM Decoding#
Compressed FSM decoding is a technique to accelerate the decoding process in large language models (LLMs) when the output is constrained to a specific format, such as JSON. Traditional methods decode one token at a time, checking against the constraints at each step. Compressed FSMs optimize this by representing the constraints as a finite state machine (FSM) and then compressing the FSM to reduce the number of transitions. This allows the decoder to potentially decode multiple tokens at once if the constraints allow it. The key benefit is a significant increase in decoding speed as it reduces redundant computations. However, challenges exist. Converting regular expressions into FSMs and then compressing them effectively requires careful design to balance compression with maintaining constraint accuracy. Handling tokenization differences between the LLM’s internal representation and the FSM’s character-based representation is also crucial to ensure the accuracy of the decoding process. This method offers a substantial speed-up, but its effectiveness depends heavily on the characteristics of the output format and the quality of the FSM compression. Further work is needed to handle edge cases and potentially explore more sophisticated compression algorithms to maximize the benefits of this technique.
API Speculative Execution#
API speculative execution, a technique designed to optimize the execution of programs utilizing multiple API calls to large language models (LLMs), addresses the inherent latency of external API requests. By speculatively executing subsequent API calls based on predictions from earlier responses, SGLang aims to reduce overall latency and cost. This approach necessitates careful prompt engineering and potentially incorporates mechanisms for rollback if the speculative predictions prove inaccurate. Careful consideration of error handling and managing potential inconsistencies in responses becomes critical, making this a sophisticated optimization method that balances the risk of incorrect speculation against the potential performance gains. The effectiveness of this approach will heavily depend on the predictability of the LLM and the robustness of the speculative execution strategy, emphasizing the need for advanced techniques like efficient caching and reliable prediction mechanisms to improve its effectiveness. Moreover, its applicability is primarily limited to systems designed to handle multi-call LLM workflows, highlighting its specialized nature within the broader context of LLM program execution.
Future Work & Limits#
The research paper’s “Future Work & Limits” section would ideally delve into several key areas. Extending the system to handle additional modalities beyond text and images (e.g., audio, video) is crucial for broader applicability. Improving RadixAttention’s efficiency by optimizing across multiple memory levels (DRAM, disk) and incorporating fuzzy semantic matching is vital. The system’s current limitations, particularly with regard to handling complex control flow in programs and its reliance on relatively basic programming primitives, would need comprehensive discussion. Future work should also investigate how to more effectively address the challenges of distorted probability distributions introduced by constrained decoding and explore the development of higher-level primitives and potentially a compiler to enable more advanced optimization techniques. Finally, a thorough exploration of the system’s scalability and the impact of different hardware architectures is necessary. Addressing these issues will pave the way for a more robust and versatile system capable of handling a wider array of LLM programs.
More visual insights#
More on figures

The figure demonstrates how a normal FSM and a compressed FSM process the decoding of a regular expression. In a normal FSM, the decoding process is done token by token, which is less efficient. In a compressed FSM, multiple tokens can be decoded at once, leading to faster decoding. This is achieved by compressing adjacent singular-transition edges in the FSM into a single edge. The figure shows the decoding process for both normal and compressed FSMs for the regular expression {‘summary’:’. The compressed FSM reduces the number of steps needed to decode the regular expression.

This figure presents a comparison of normalized latency across various large language model (LLM) workloads and different systems (SGLang, vLLM, Guidance, LMQL). Lower latency values indicate better performance. The workloads include MMLU, ReAct Agents, Generative Agents, Tree of Thought, Skeleton of Thought, LLM Judge, HellaSwag, JSON Decoding, Multi-Turn Chat (short and long), DSPy RAG Pipeline. The chart allows for a direct visual comparison of the latency achieved by each system for each specific task.
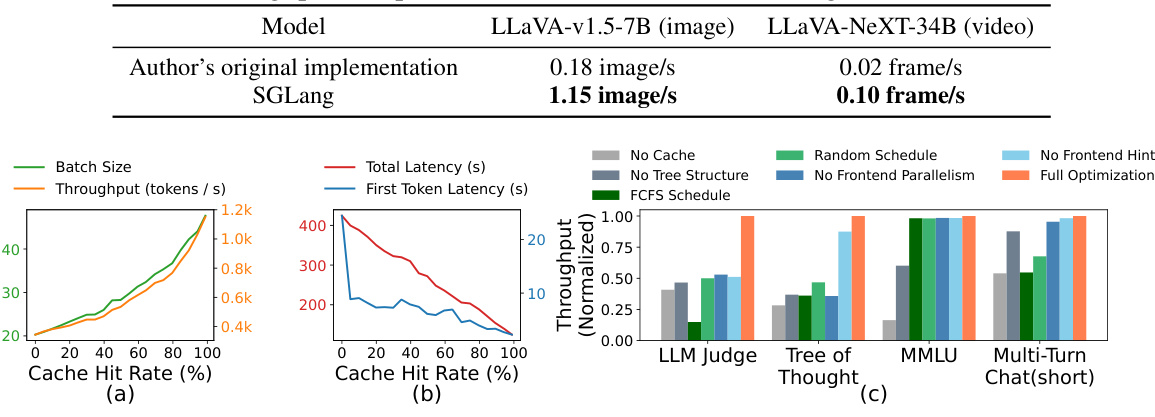
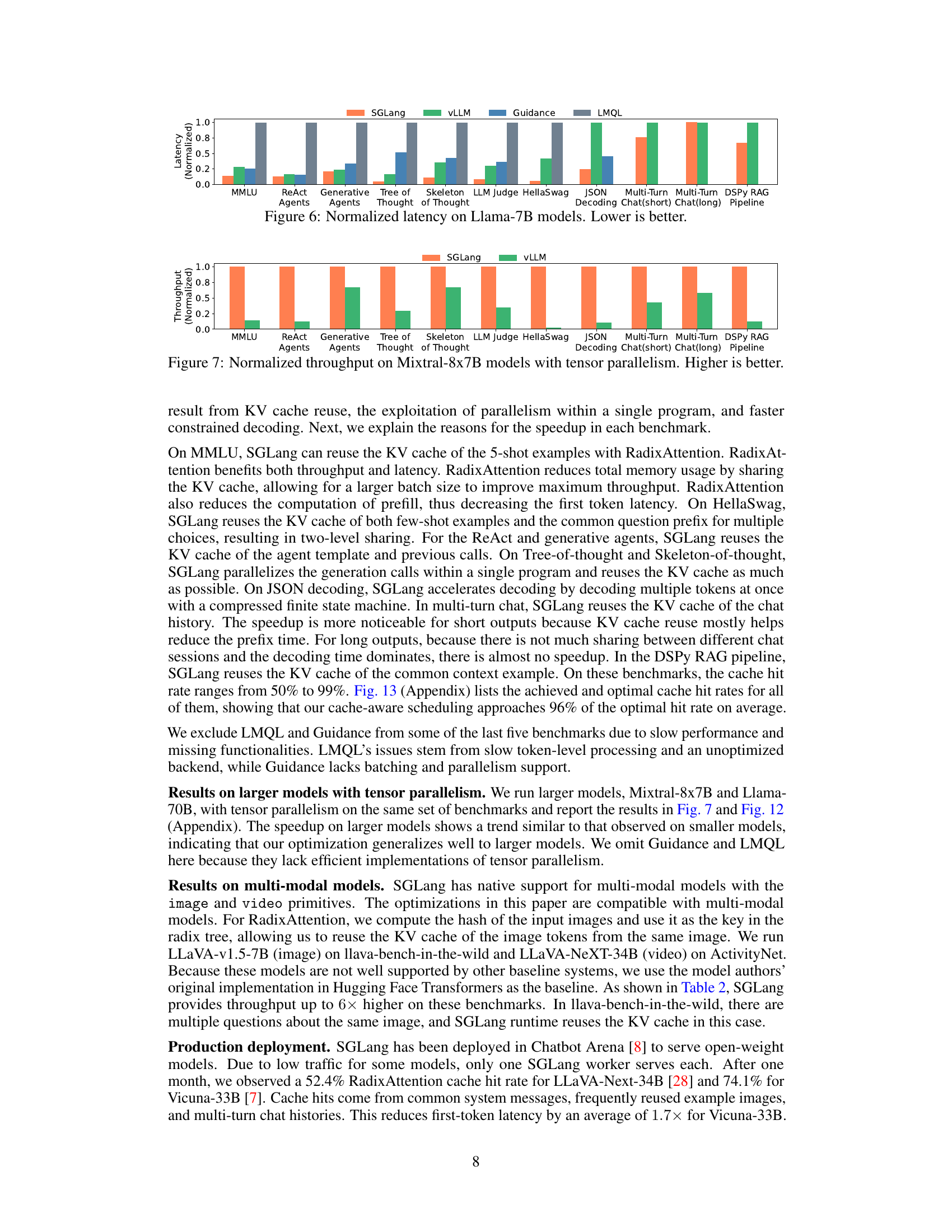
Figure 8 shows the results of ablation studies conducted to analyze the impact of different components of RadixAttention on the overall performance. Specifically, (a) and (b) illustrate the relationship between cache hit rate and various performance metrics (first-token latency, total latency, batch size, and throughput) for the tree-of-thought benchmark. These graphs demonstrate that higher cache hit rates lead to better performance. (c) shows the impact of individual components of RadixAttention. It compares the full RadixAttention system against various settings where components (such as the cache itself, tree-structure, scheduling policy, and frontend parallelism) are selectively disabled. This helps isolate the individual contributions of each part and shows the importance of having each for optimal performance.
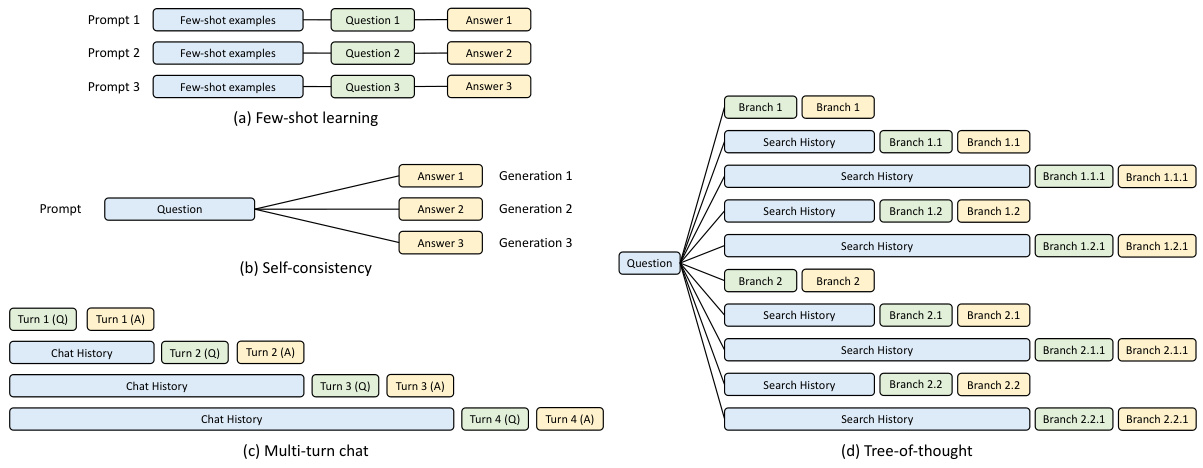
This figure illustrates how different types of LLM programs share common parts of their prompts to reduce redundant computations by reusing the KV cache. It shows examples of few-shot learning, self-consistency, multi-turn chat, and tree-of-thought prompting, highlighting the shareable and non-shareable parts of each prompt structure. Shareable parts (blue boxes) represent common elements that can be reused across multiple calls, reducing computation and memory usage, while the non-shareable parts (yellow boxes) represent unique outputs or components specific to each prompt.
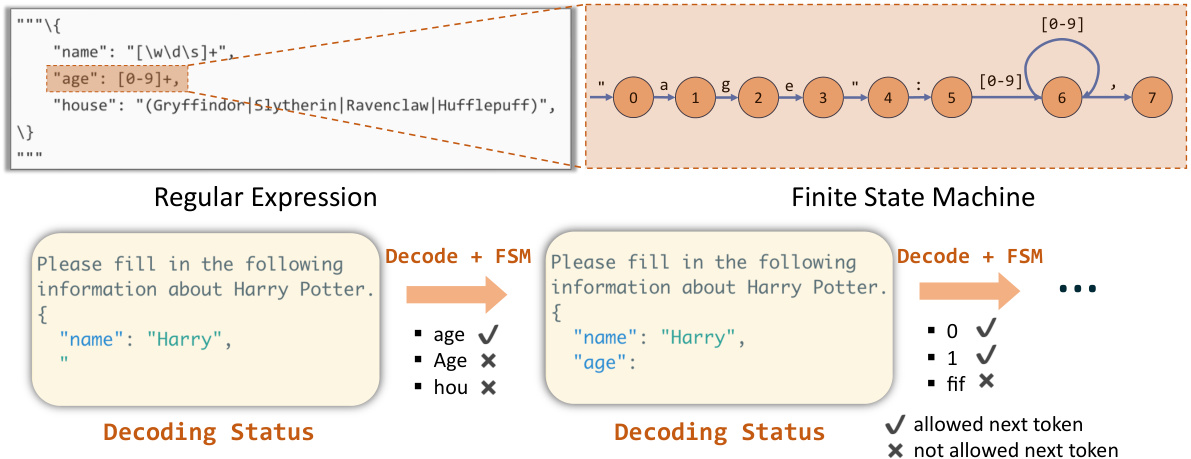
This figure illustrates how a regular expression is converted into a Finite State Machine (FSM) and how that FSM is used to guide the decoding process of a language model. The FSM is a graph where nodes represent states and edges represent transitions, with each transition labeled with a string or character. The decoding process starts at an initial state and proceeds through transitions, appending strings to form the final output. This process is constrained by the FSM, as invalid transitions are blocked, ensuring the output conforms to the specified regular expression.
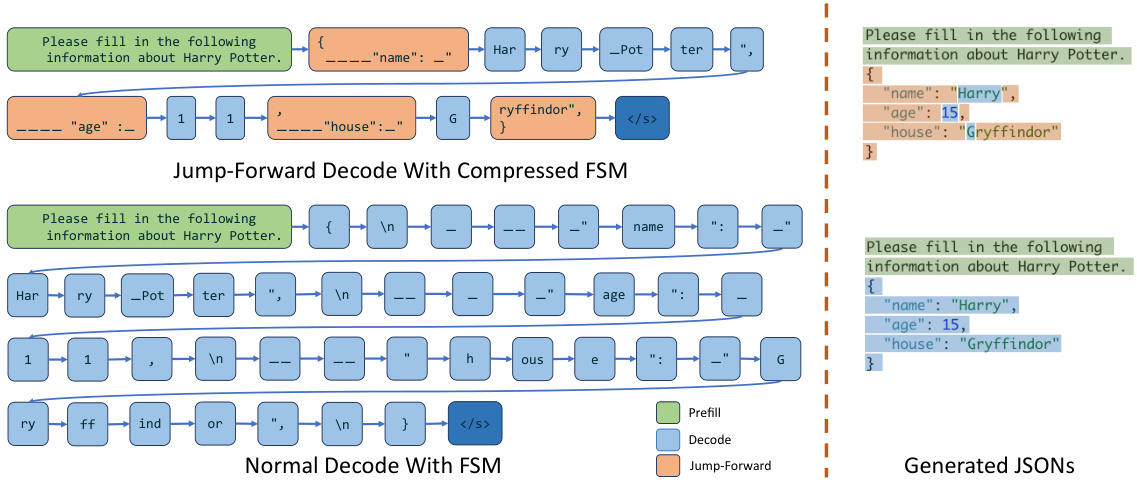
This figure compares the decoding process between the compressed FSM and the normal FSM in order to illustrate the efficiency improvements achieved by the compressed FSM. The left side shows how the compressed FSM speeds up the decoding process by jumping multiple states at once. The right side shows the resulting JSON output from both methods, highlighting the identical results despite the difference in the decoding processes.
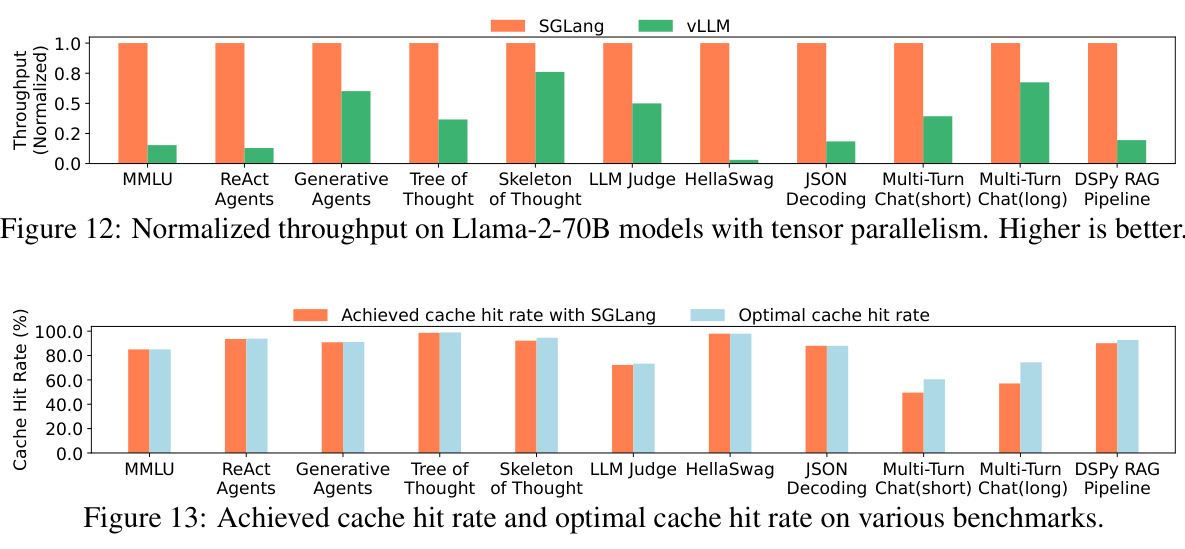
This figure compares the normalized throughput of SGLang and vLLM on Llama-2-70B models across various benchmarks when tensor parallelism is used. The benchmarks include MMLU, ReAct agents, generative agents, tree-of-thought, skeleton-of-thought, LLM judge, HellaSwag, JSON decoding, multi-turn chat (short and long), and DSPy RAG pipeline. Higher bars indicate better performance, showing SGLang’s superior throughput in most cases.
This figure illustrates how KV cache can be shared among different program calls. It shows four examples: few-shot learning, self-consistency, multi-turn chat, and tree-of-thought. In each example, the shareable (reusable) parts of the prompts are highlighted in blue, while non-shareable (non-reusable) parts are shown in green and yellow. The figure highlights the opportunities for KV cache reuse within different LLM program structures.
Full paper#