↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Existing knowledge graph (KG) reasoning models struggle with generalizing across different KGs and reasoning settings. They often require separate training for each KG, hindering knowledge transfer and limiting their real-world applicability. This paper tackles this issue by focusing on creating a model capable of reasoning universally across various KGs. The core problem lies in the difficulty of representing unseen entities and relations consistently across different KGs. Previous methods tried to solve this using relational patterns or query-conditioned structures but faced limitations in transferability.
The researchers propose KG-ICL, a prompt-based KG foundation model that utilizes in-context learning. This approach uses a prompt graph centered on a query-related example fact, encoded with a unified tokenizer that handles entities and relations consistently across different KGs. Two message passing neural networks process these prompt graphs and perform KG reasoning. Evaluations on 43 diverse KGs demonstrate that KG-ICL significantly outperforms existing methods in both transductive and inductive settings, highlighting its impressive generalization ability and universal reasoning capabilities. The unified tokenizer is also a key contribution of this work.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the critical challenge of knowledge graph reasoning’s generalization and transferability limitations. By introducing a novel prompt-based KG foundation model, KG-ICL, it demonstrates superior performance across diverse KGs in various settings, thus opening new avenues for universal reasoning research and applications. This work directly addresses current research trends focusing on improving the generalization of knowledge graph models, offering significant advancements in the field.
Visual Insights#
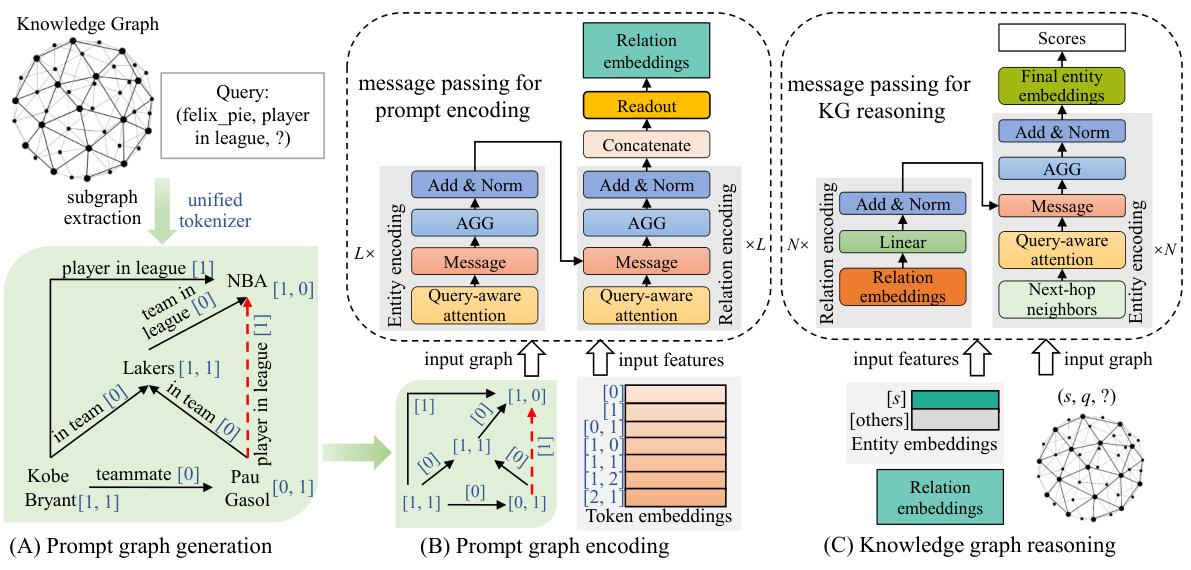
This figure illustrates the overall architecture of the KG-ICL model, which is a prompt-based KG foundation model for in-context reasoning. It consists of three main stages: (A) prompt graph generation, where a subgraph is extracted from the KG based on the query, and entities and relations are mapped to unified tokens; (B) prompt graph encoding, which uses a message-passing neural network to generate relation representation prompts from the prompt graph; (C) KG reasoning, which uses the prompt representations to initialize the KG and then scores the candidate entities based on their embeddings.
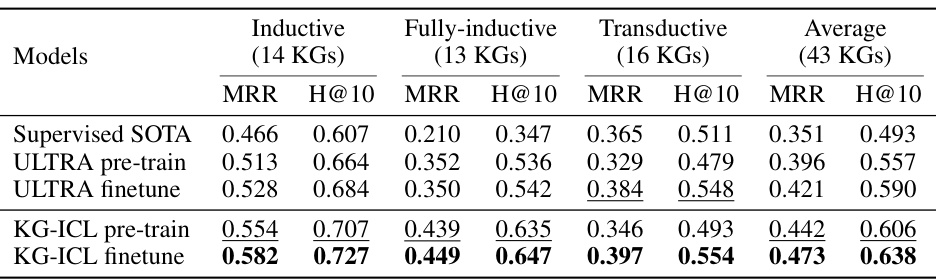
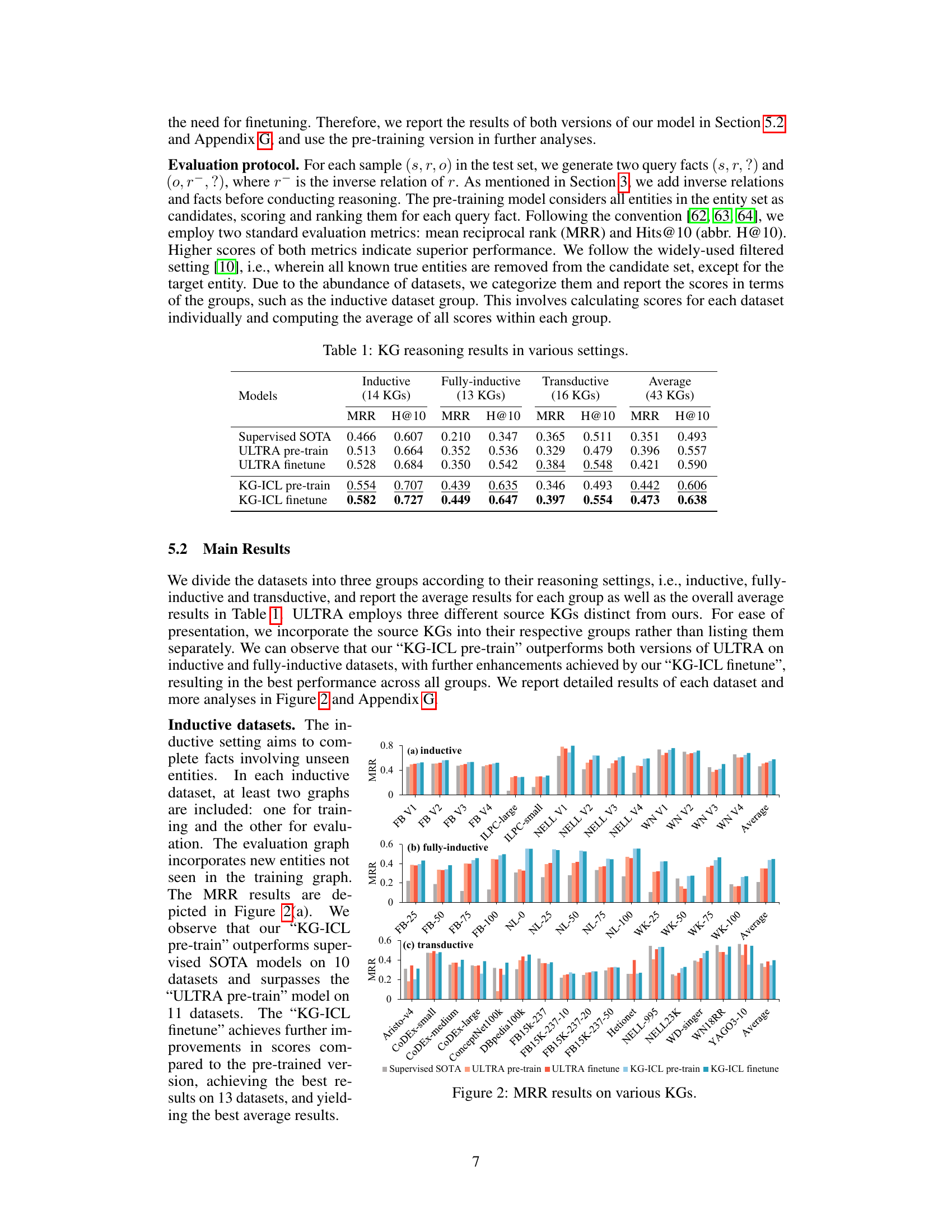
This table presents the performance of different KG reasoning models across three different reasoning settings: inductive, fully-inductive, and transductive. The results are measured using Mean Reciprocal Rank (MRR) and Hits@10 (H@10), reflecting the ranking accuracy of the model’s predictions. The table compares the performance of the proposed KG-ICL model (both pre-trained and fine-tuned versions) against supervised state-of-the-art (SOTA) models and the ULTRA model (both pre-trained and fine-tuned versions). The average performance across all 43 datasets is also shown.
In-depth insights#
Prompt-Based KG Reasoning#
Prompt-based KG reasoning represents a novel approach to knowledge graph reasoning, leveraging the power of in-context learning. By framing the reasoning task as a prompt, the model implicitly learns to identify relevant information within the KG, greatly enhancing its generalization abilities. This paradigm shift avoids the limitations of traditional KG embedding methods that struggle to handle unseen entities or relations. The use of prompt graphs, constructed from query-related examples, provides valuable contextual information to guide the reasoning process. This technique effectively bridges the gap between seen and unseen data, enabling more robust and universal reasoning capabilities. Unified tokenization further strengthens the model’s generalization ability by creating a consistent representation across diverse KGs. While the method shows remarkable potential for diverse KG reasoning tasks, it also necessitates further exploration to evaluate its scalability and robustness in handling extremely large KGs and complex reasoning patterns. Future research should also address potential biases within pre-training data and the impact of example selection on overall model performance.
Unified Tokenization#
Unified tokenization is a crucial technique for enabling knowledge graph (KG) models to generalize across diverse KGs. The core challenge lies in the variability of entity and relation vocabularies across different KGs. A unified tokenizer addresses this by mapping entities and relations to predefined tokens, effectively creating a shared language for representing knowledge across different KGs. This approach facilitates knowledge transfer and improves generalization capabilities, making the model applicable to various KGs without requiring extensive retraining for each. The unified tokenizer likely employs a mapping function that considers contextual information (such as entity types, relational paths, or other structural features) to enhance the discriminative power of the tokens. It’s also important that the unified tokens allow for the handling of unseen entities and relations which are encountered during inference and that the tokenizer is designed to be efficient and scalable so that it can operate on large KGs.
KG-ICL Architecture#
The KG-ICL architecture is likely a multi-stage pipeline designed for universal in-context reasoning on knowledge graphs. It would probably begin with prompt graph generation, constructing a subgraph around a query-relevant fact. This subgraph acts as context. A unified tokenizer would standardize the representation of entities and relations across different knowledge graphs. Next, a prompt encoder (likely a message passing neural network) processes the prompt graph to generate context-aware relation representations. Finally, a KG reasoner integrates these representations into reasoning on the target knowledge graph, potentially using another message passing network. The entire architecture aims for transferability and generalization by leveraging in-context learning, allowing the model to handle unseen entities, relations, and knowledge graphs without retraining. Key features are likely the use of prompt graphs, a unified tokenizer for cross-KG consistency, and separate encoding for prompts and KG reasoning.
Universal Reasoning#
Universal reasoning, in the context of knowledge graphs (KGs), signifies the ability of a model to perform logical inferences and answer queries across diverse KG structures and reasoning settings. This transcends the limitations of traditional KG reasoning methods, which often struggle with unseen entities, relations, or KG schemas. A universally reasoning model should demonstrate generalization abilities, handling novel situations without explicit retraining. This requires sophisticated techniques to represent and encode knowledge in a format that captures underlying relational patterns. Achieving this involves the careful design of model architectures capable of extracting implicit and explicit relationships, effectively leveraging contextual information to understand the query’s intent, and employing robust methods to accommodate variability in the input KGs. The key challenge is building models that are both data-efficient and transferable. In-context learning offers a potential pathway towards universal reasoning, enabling a model to learn from a few examples without requiring extensive fine-tuning. The capacity for a model to perform well on unseen data is crucial for its real-world applicability, as real-world KGs are constantly evolving and expanding.
Future Research#
The authors suggest several promising avenues for future research. Extending in-context reasoning to more complex and dynamic scenarios, such as personal knowledge graphs, is a key area. These dynamic environments present unique challenges that require further investigation. Another important direction is exploring the application of in-context reasoning to other knowledge-driven applications. This includes tasks like question answering and recommender systems, which could benefit significantly from the model’s ability to transfer knowledge effectively across diverse knowledge graphs. Finally, the authors acknowledge the need to carefully consider societal biases and unfairness that may arise from excessive reliance on pre-training data and a limited number of examples. Mitigation strategies, such as example selection techniques to avoid biases, will need to be developed. Improving scalability by incorporating strategies like pruning and parallelization is also highlighted as an area needing additional focus. The authors also note the potential for incorporating different message passing layers to further enhance performance and robustness.
More visual insights#
More on figures
This figure provides a visual overview of the KG-ICL model’s architecture and workflow. It details three main stages: (A) prompt graph generation from a query and KG, (B) prompt graph encoding using a message passing neural network (resulting in prompt representations), and (C) KG reasoning using the prompts to initialize KG entity and relation representations, followed by another message passing neural network to generate final entity embeddings and scores.
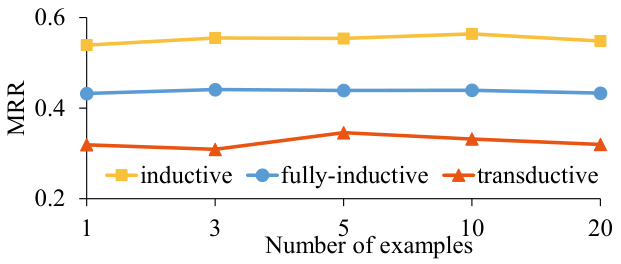
This figure shows the performance of the KG-ICL model on inductive, fully-inductive, and transductive datasets with varying numbers of examples used in the prompt. The x-axis represents the number of examples (1, 3, 5, 10, 20), and the y-axis represents the Mean Reciprocal Rank (MRR). The plot demonstrates the model’s robustness to the number of examples provided, with relatively stable performance across different reasoning settings. The slight fluctuations observed might be attributed to the introduction of noise with increased examples.

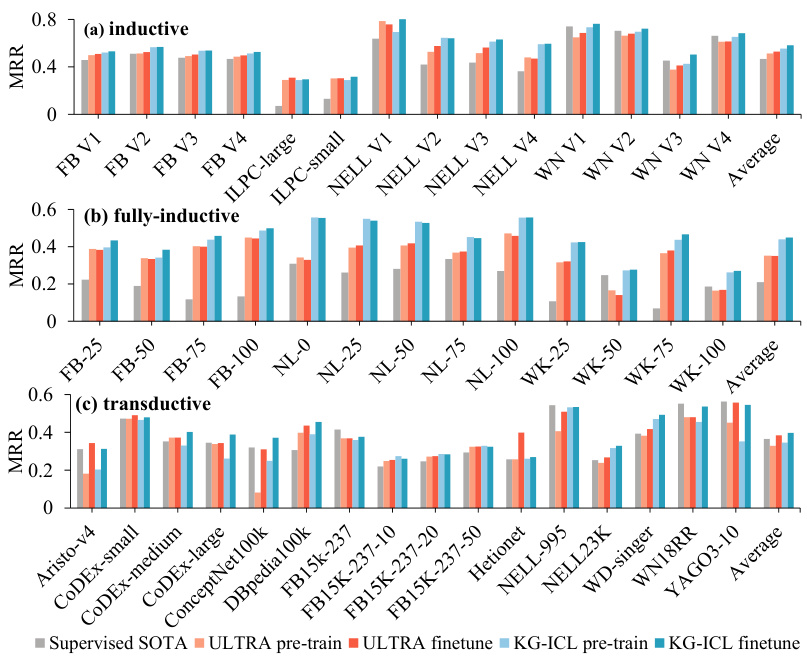
The bar chart visualizes the Mean Reciprocal Rank (MRR) achieved by different models (Supervised SOTA, ULTRA pre-train, ULTRA finetune, KG-ICL pre-train, KG-ICL finetune) across various Knowledge Graphs (KGs). The KGs are categorized into three groups: inductive, fully-inductive, and transductive, representing different KG reasoning settings. Each bar shows the average MRR across multiple KGs within each group, enabling a comparison of model performance under various conditions and settings. The figure demonstrates KG-ICL’s superior performance compared to the baselines.

This figure provides a high-level overview of the KG-ICL model’s architecture. It shows three main stages: prompt graph generation, prompt encoding, and KG reasoning. The prompt graph is generated from a sample fact related to the query, and its entities and relations are mapped to tokens for unified processing. The prompt encoding stage uses a message passing network to generate relation prompts, which initialize the KG reasoning stage. The KG reasoning stage uses another message passing network on the KG, leveraging the prompt information to finally score the candidate entities.
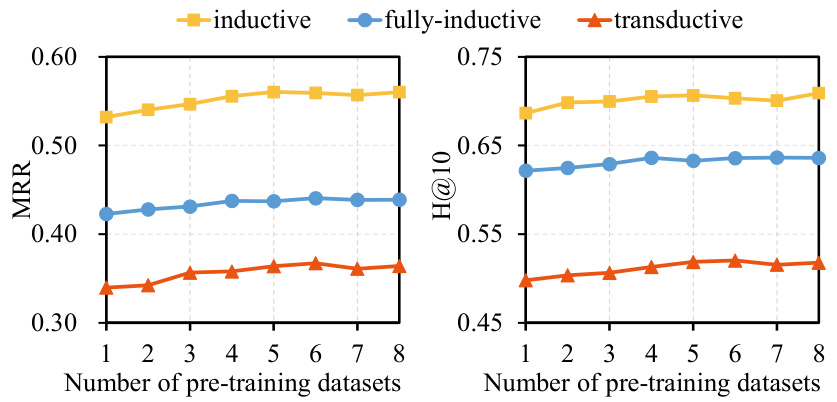
This figure shows the performance of the KG-ICL model on inductive, fully-inductive, and transductive datasets as the number of pre-training datasets increases. The x-axis represents the number of pre-training datasets used, while the y-axis shows the MRR (Mean Reciprocal Rank) and Hits@10 metrics. The results indicate that the model’s performance improves with the addition of more pre-training datasets across all three reasoning settings, demonstrating the benefit of increased data diversity in improving model generalization.
More on tables

This table presents the ablation study results for the proposed KG-ICL model. It shows the performance (MRR and H@10) of the intact model and three variants with different modules removed: (1) the prompt graph, (2) the unified tokenizer, and (3) using GraIL’s labeling instead of the proposed method. The results are broken down by reasoning setting (Inductive, Fully-inductive, Transductive), and overall average performance is reported. This demonstrates the importance of each component in the model’s overall effectiveness.

This table presents the Mean Reciprocal Rank (MRR) and Hits@10 (H@10) results for different prompt graph variants. The goal was to determine the optimal prompt graph design for in-context KG reasoning. The variants compared different methods of sampling nodes within the prompt graph, evaluating the impact of including only neighbors of the subject and object entities, as well as paths of different lengths (1-hop, 2-hop, 3-hop) between those entities. The ‘Neighbor & 3-hop path’ variant represents the model’s design used in the main experiments of the paper.

This table presents the results of KG reasoning experiments conducted across various settings, including inductive, fully-inductive, and transductive. It compares the performance of different models (Supervised SOTA, ULTRA pre-train, ULTRA finetune, KG-ICL pre-train, KG-ICL finetune) in terms of MRR (Mean Reciprocal Rank) and H@10 (Hits@10) metrics, providing insights into the effectiveness of the proposed KG-ICL model in different KG reasoning scenarios.

This table presents the Mean Reciprocal Rank (MRR) and Hits@10 (H@10) scores achieved by different KG reasoning models across various knowledge graph (KG) datasets. The datasets are grouped into three categories based on reasoning settings: inductive, fully-inductive, and transductive. The models evaluated include supervised state-of-the-art (SOTA) models, ULTRA (pre-train and finetune), and KG-ICL (pre-train and finetune). The results showcase the comparative performance of KG-ICL against baselines across diverse reasoning scenarios.
This table presents the Mean Reciprocal Rank (MRR) and Hits@10 scores achieved by different KG reasoning models across three categories of datasets: inductive, fully-inductive, and transductive. The models compared include supervised state-of-the-art (SOTA) models, ULTRA (pre-train and finetune), and the proposed KG-ICL model (pre-train and finetune). The average results across all 43 datasets are also shown.

This table presents the Mean Reciprocal Rank (MRR) and Hits@10 scores achieved by different models on 43 knowledge graphs (KGs). The KGs are categorized into three groups based on their reasoning settings: inductive, fully-inductive, and transductive. The table compares the performance of the proposed KG-ICL model and its variants (KG-ICL (NBFNet), KG-ICL pre-train, KG-ICL finetune) against supervised state-of-the-art (SOTA) models and ULTRA pre-training models. The results illustrate the performance of each model in different KG reasoning scenarios and overall performance across all KGs.
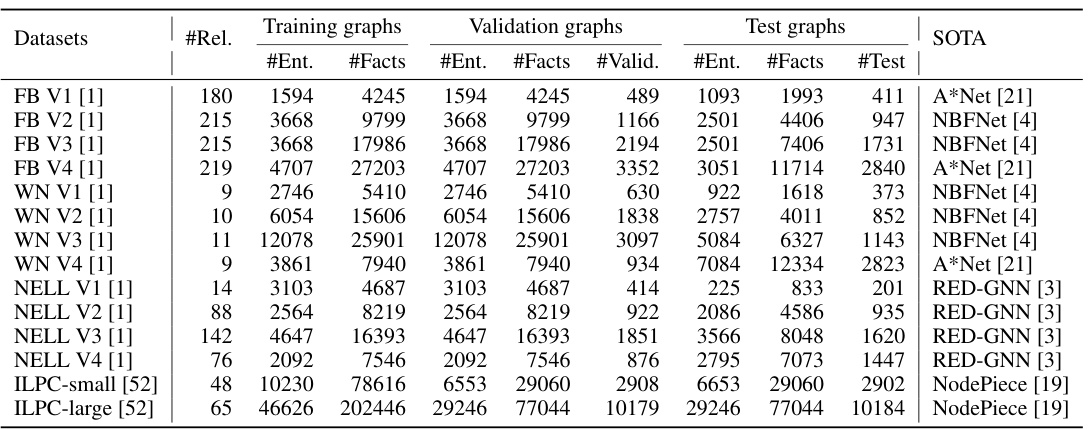
This table presents the results of KG reasoning experiments conducted using various models on different datasets, categorized by reasoning setting (inductive, fully-inductive, transductive, and average across all settings). For each setting and model, the Mean Reciprocal Rank (MRR) and Hits@10 metrics are reported. The table allows for a comparison of the performance of different models across various KG reasoning tasks.

This table presents the Mean Reciprocal Rank (MRR) and Hits@10 scores achieved by different models on various knowledge graph reasoning tasks. The models are categorized into supervised state-of-the-art models, ULTRA pre-train, ULTRA finetune, KG-ICL pre-train, and KG-ICL finetune. The results are further broken down by reasoning setting (inductive, fully inductive, and transductive) and show the average performance across all three settings. This allows for a comprehensive comparison of the proposed KG-ICL model to other methods in different reasoning scenarios.

This table presents the Mean Reciprocal Rank (MRR) and Hits@10 scores achieved by different models (Supervised SOTA, ULTRA pre-train, ULTRA finetune, KG-ICL pre-train, and KG-ICL finetune) across three different KG reasoning settings: inductive, fully-inductive, and transductive. Each setting represents a different level of challenge in terms of unseen entities and relations. The average performance across all three settings is also shown. This provides a comparison of the proposed KG-ICL model to state-of-the-art supervised methods and a pre-trained model.

This table presents the Mean Reciprocal Rank (MRR) and Hits@10 metrics for different KG reasoning models across three settings: inductive, fully-inductive, and transductive. It compares the performance of the proposed KG-ICL model (both pre-trained and fine-tuned versions) against supervised state-of-the-art models and the ULTRA model. The results are presented as averages across multiple knowledge graphs (KGs) within each setting, showcasing the model’s universal reasoning capabilities.

This table presents the performance of different KG reasoning models on various datasets categorized by their reasoning settings (inductive, fully-inductive, and transductive). It shows the Mean Reciprocal Rank (MRR) and Hits@10 scores for each model and dataset group, allowing comparison of the universal reasoning abilities across different scenarios and model types. The table includes results for Supervised SOTA (state-of-the-art supervised models), ULTRA (pre-train and finetune versions), and KG-ICL (pre-train and finetune versions).
Full paper#