↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Many machine learning datasets suffer from label noise, where the assigned labels for images are incorrect, thereby degrading model performance. Existing methods to address this problem either require strong assumptions about the data or rely on memorization effects, limiting their applicability.
This paper proposes NoiseGPT, a novel method that uses multi-modal large language models (MLLMs) to detect and rectify noisy labels. It leverages the observation that clean and noisy examples exhibit different probability curvature patterns when processed by MLLMs. By designing a token-wise Mix-of-Feature (MoF) technique and an In-Context Discrepancy (ICD) measure, NoiseGPT identifies noisy labels and uses a zero-shot classifier to find better matching labels. Experiments show that NoiseGPT significantly improves classification accuracy on various benchmark datasets, demonstrating its effectiveness in addressing the challenges of label noise.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel approach to label noise detection and rectification using multi-modal large language models (MLLMs). This addresses a critical bottleneck in machine learning, where noisy labels significantly degrade model performance. The proposed method, NoiseGPT, leverages the unique properties of MLLMs to effectively identify and correct noisy labels, enhancing the quality of training datasets and improving the robustness of machine learning models. The zero-shot capability of NoiseGPT makes it scalable and applicable to various scenarios, opening new avenues for further research in the field of learning with noisy labels. It also mitigates the reliance on laborious manual labeling processes, which is crucial for real-world deployments of machine learning systems.
Visual Insights#

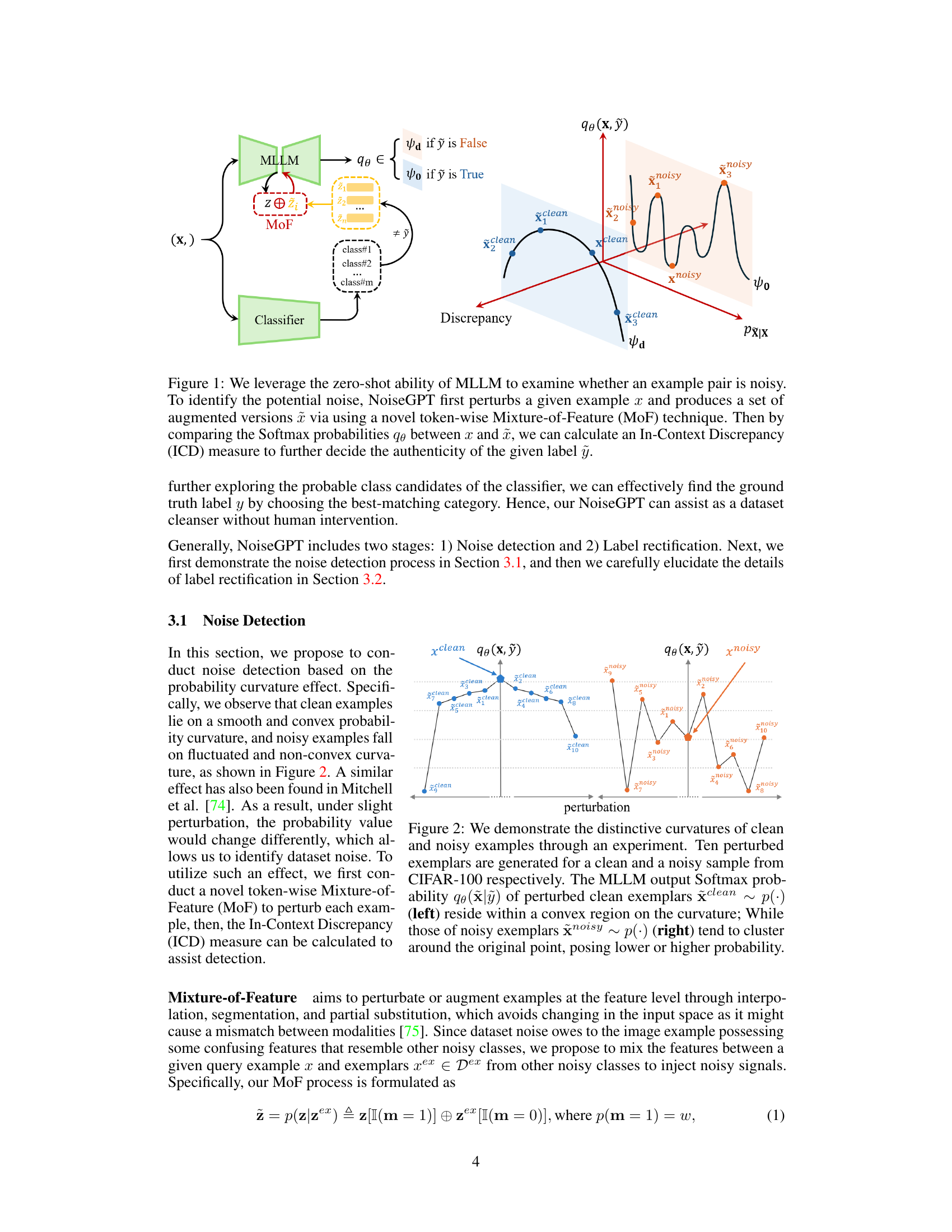
This figure illustrates the NoiseGPT framework for label noise detection and rectification. It shows how the model uses a Multimodal Large Language Model (MLLM) and a classifier in conjunction with a novel token-wise Mixture-of-Feature (MoF) technique to determine if an image-label pair is noisy. The process involves perturbing the input image, generating augmented versions, and comparing the MLLM’s softmax probabilities to calculate an In-Context Discrepancy (ICD) measure, which helps to identify noisy labels.
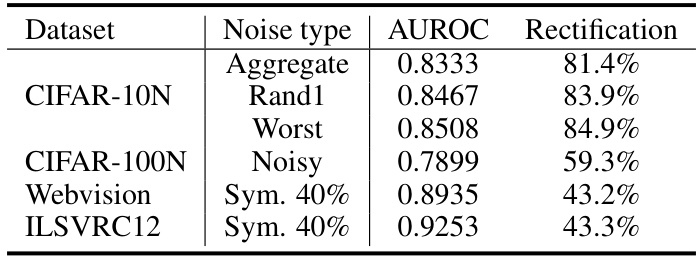
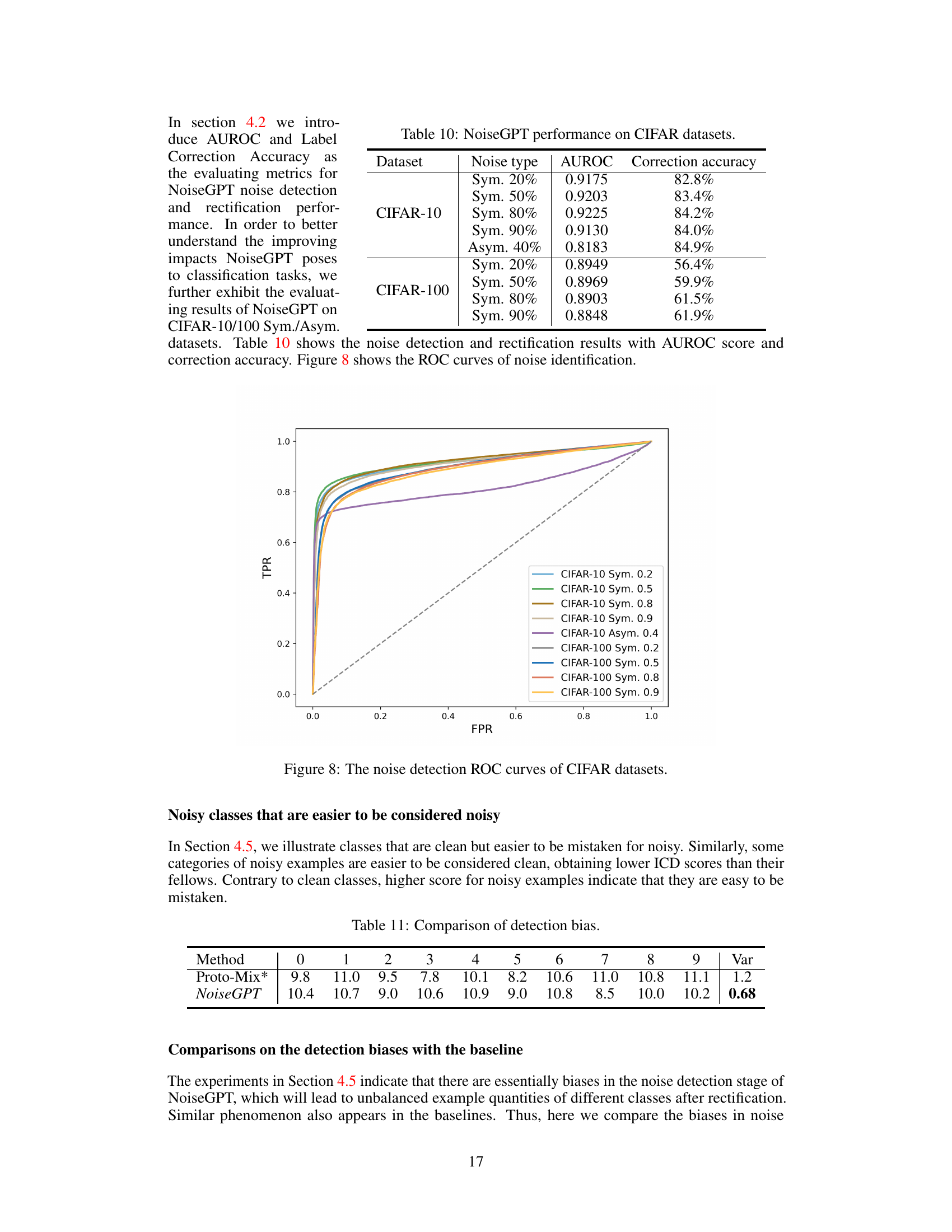
This table presents the performance of the NoiseGPT model in detecting and rectifying noisy labels. It shows the Area Under the Receiver Operating Characteristic curve (AUROC) score, which measures the model’s ability to distinguish between clean and noisy samples, and the rectification accuracy, which indicates the percentage of noisy labels that were correctly identified and corrected. The table includes results for several datasets with varying levels of noise, demonstrating the model’s effectiveness across different scenarios.
In-depth insights#
NoiseGPT: Overview#
NoiseGPT is a novel approach to label noise detection and rectification in machine learning datasets. It leverages the power of Multimodal Large Language Models (MLLMs) to identify noisy labels by observing a probability curvature effect. Clean examples exhibit smooth probability curves under perturbation, while noisy examples show erratic behavior. A key component is the token-wise Mix-of-Feature (MoF) technique, which perturbs input data in a way that preserves semantic meaning while enhancing the curvature effect. The resulting In-Context Discrepancy (ICD) measure enables NoiseGPT to distinguish clean from noisy data points effectively. NoiseGPT’s zero-shot capability is a major strength, eliminating the need for extensive dataset-specific training. Furthermore, its integration with existing label noise reduction methods further boosts classification performance. While effective, limitations include potential bias in detecting certain categories as noisy and computational costs associated with MLLM inference. Future improvements could focus on mitigating these biases and optimizing computational efficiency.
Curvature Effect#
The concept of “Curvature Effect” in the context of label noise detection using large language models (LLMs) is intriguing. It posits that the probability output of LLMs when presented with perturbed versions of clean and noisy data points will exhibit different curvature patterns. Clean data points tend to reside on smooth, convex curves, indicating consistent and predictable LLM responses to minor variations. In contrast, noisy examples result in fluctuating or non-convex curves, highlighting the model’s sensitivity to perturbations of noisy data. This difference in curvature provides a signal for identifying noisy samples. The effectiveness of this method hinges on the assumption that MLLMs are inherently optimized to recognize consistent patterns and are thus sensitive to inconsistencies introduced by label noise. The proposed token-wise Mix-of-Feature technique is a crucial component, generating these perturbed versions for comparison. While the curvature effect itself is an observation rather than a rigorously proven mathematical property, it offers an intuitive and potentially powerful technique for label noise detection. The practicality is further enhanced by the incorporation of a classifier for label rectification, utilizing the zero-shot capabilities of the model for proposing corrected labels.
MoF Technique#
The Mixture-of-Feature (MoF) technique, as described in the research paper, is a crucial preprocessing step designed to introduce controlled perturbations into input image data. Its primary goal is to generate a set of augmented image versions, each subtly different from the original, thereby revealing the underlying structure of the data and making it easier to differentiate between clean and noisy examples. The MoF process carefully avoids substantial alterations to the input image’s main features to avoid creating mismatches between the image and its corresponding text representation in the context of multi-modal language models. Instead, it focuses on injecting minor noisy signals to highlight subtle nuances and inconsistencies that might otherwise go unnoticed. By using a token-wise approach, MoF ensures a fine-grained perturbation of the input features, leading to a more precise evaluation of how robust a model’s predictions are under various conditions. The effectiveness of MoF in noise detection is a critical aspect of the paper’s approach, proving essential for distinguishing between clean and noisy examples based on the probability curvature observed from multi-modal language models.
ICL in NoiseGPT#
The effectiveness of NoiseGPT hinges on its innovative use of In-Context Learning (ICL). Instead of relying on extensive retraining, NoiseGPT leverages the pre-trained capabilities of Multimodal Large Language Models (MLLMs) to identify noisy labels. ICL allows NoiseGPT to adapt to new, unseen data without needing to adjust its internal parameters. This is crucial for real-world applications where datasets often contain significant label noise. The paper highlights how ICL enables the NoiseGPT model to function as a powerful ‘knowledge expert’ for evaluating the credibility of image-label pairs. This zero-shot ability dramatically reduces the need for manual intervention, thereby improving the efficiency and scalability of noise detection and rectification. However, the reliance on ICL also presents a limitation; the accuracy of NoiseGPT’s assessments is directly tied to the quality and robustness of the underlying MLLM. Therefore, future work might focus on mitigating the impact of potential biases or inconsistencies within the MLLM on NoiseGPT’s performance.
Future Works#
Future research directions stemming from this NoiseGPT study could explore improving the robustness of the probability curvature detection method. The sensitivity to hyperparameters like MoF weight and perturbation strength should be further investigated to enhance reliability across diverse datasets. Incorporating uncertainty quantification into the label rectification process would provide more nuanced handling of noisy data, especially for borderline cases. Investigating the transferability of NoiseGPT to other modalities such as audio or video would broaden its applicability. Additionally, a deeper exploration of the underlying reasons behind the differences in probability curvature between clean and noisy data is warranted, potentially leveraging techniques from explainable AI. Finally, combining NoiseGPT with state-of-the-art noisy label learning methods in a more sophisticated way may lead to even greater improvements in classification accuracy. These avenues will provide a more robust and widely applicable framework for addressing the ubiquitous challenge of noisy labels.
More visual insights#
More on figures

This figure shows the probability curvature of clean and noisy samples. The left panel shows the smooth, convex curvature of clean samples under perturbation, while the right panel illustrates the fluctuating, non-convex curvature of noisy samples. This difference in curvature is the basis for NoiseGPT’s noise detection method.

The figure shows the distribution of ICD scores for clean and noisy samples from six different datasets under perturbation. It visually demonstrates the effectiveness of the In-Context Discrepancy (ICD) measure in distinguishing between clean and noisy data based on the probability curvature effect. Higher ICD scores are associated with clean samples and lower scores with noisy samples.

This ROC curve figure visualizes the performance of NoiseGPT’s noise detection capabilities across six different noisy datasets: CIFAR-10N Aggregate, CIFAR-10N Rand1, CIFAR-10N Worst, CIFAR-100N Noisy, Webvision Sym. 40%, and ILSVRC12 Sym. 40%. The x-axis represents the false positive rate (FPR), and the y-axis represents the true positive rate (TPR). Each line corresponds to a specific dataset, showing the trade-off between correctly identifying noisy samples (TPR) and incorrectly labeling clean samples as noisy (FPR). A curve closer to the top-left corner indicates better performance, with an area under the curve (AUROC) score approaching 1. The dashed line represents a random classifier with an AUROC of 0.5.

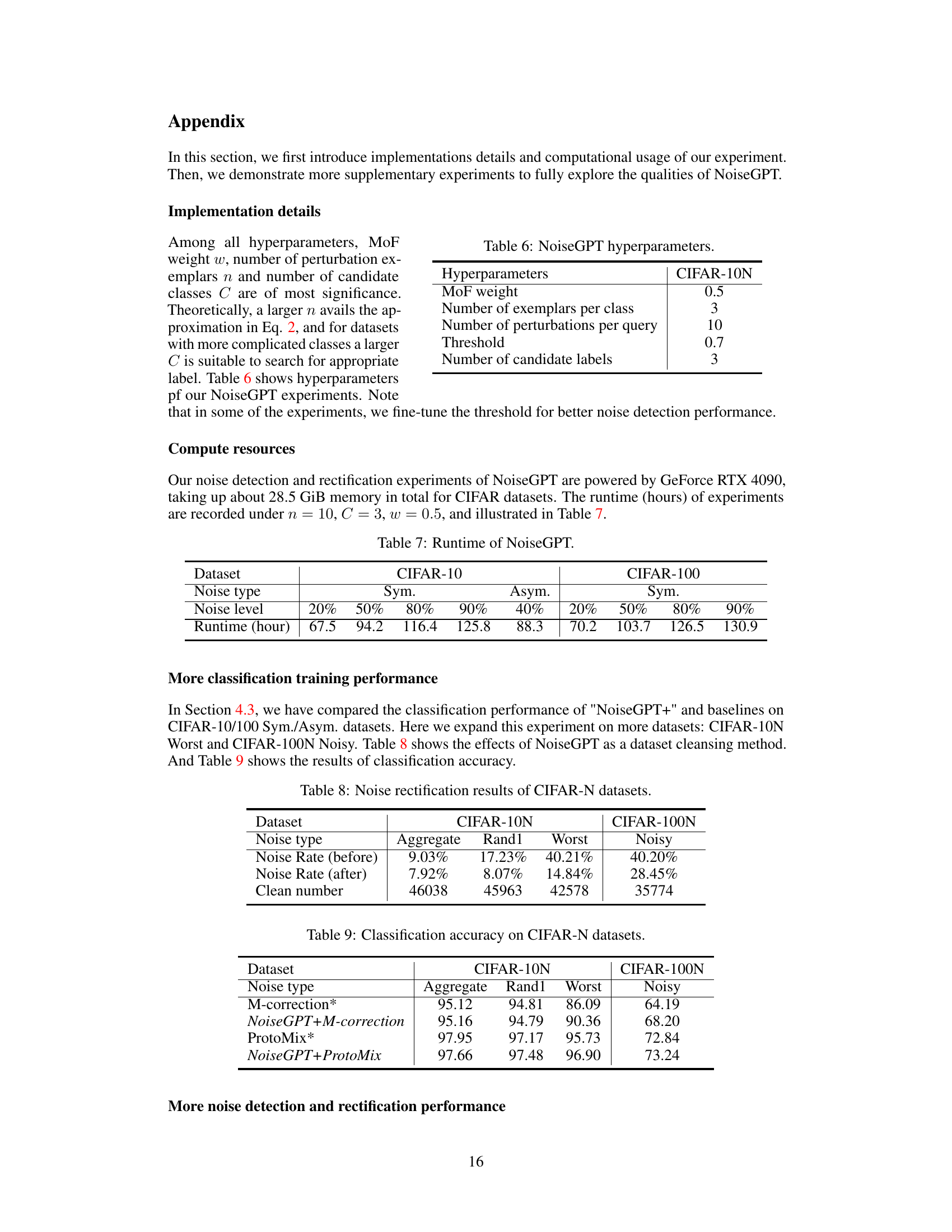
This figure shows the trend of noise rectification performance under a changing hyperparameter (number of perturbations) for CIFAR-10 and CIFAR-100 datasets with 80% symmetric noise. It demonstrates that increasing the number of perturbations initially improves accuracy but eventually plateaus, indicating a point of diminishing returns. The optimal number of perturbations balances computational cost and performance gains.
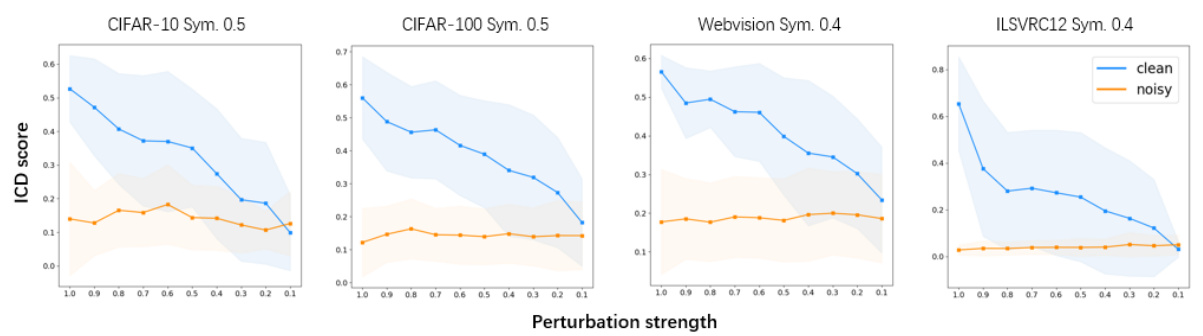
This figure shows the probability curvature for both clean and noisy examples under different perturbation strengths. The x-axis represents the perturbation strength (MoF weight w), while the y-axis represents the output probability. The curves demonstrate that clean examples exhibit a smooth, predictable curvature, while noisy examples show a fluctuating, less consistent pattern. This difference in curvature is a key observation that underpins NoiseGPT’s ability to distinguish between clean and noisy samples.
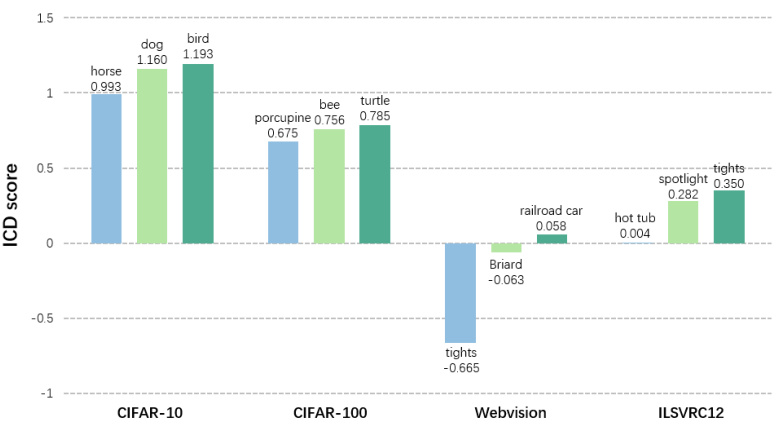
This figure shows the average ICD scores for clean categories that are frequently misclassified as noisy by the NoiseGPT model. The lower the ICD score, the more likely a clean category is to be misidentified. This visualization helps to understand the inherent biases within the model’s noise detection process, specifically highlighting categories where the probability curvature effect is less pronounced.

This ROC curve graph shows the performance of NoiseGPT’s noise detection capabilities across various noisy datasets. Each curve represents a different dataset (CIFAR-10 with symmetric noise at different levels, CIFAR-10 with asymmetric noise, and CIFAR-100 with symmetric noise at different levels). The x-axis represents the false positive rate (FPR), and the y-axis represents the true positive rate (TPR). The closer a curve is to the top-left corner, the better the model’s performance at distinguishing between clean and noisy samples. The dashed line represents the performance of a random classifier (AUROC = 0.5).
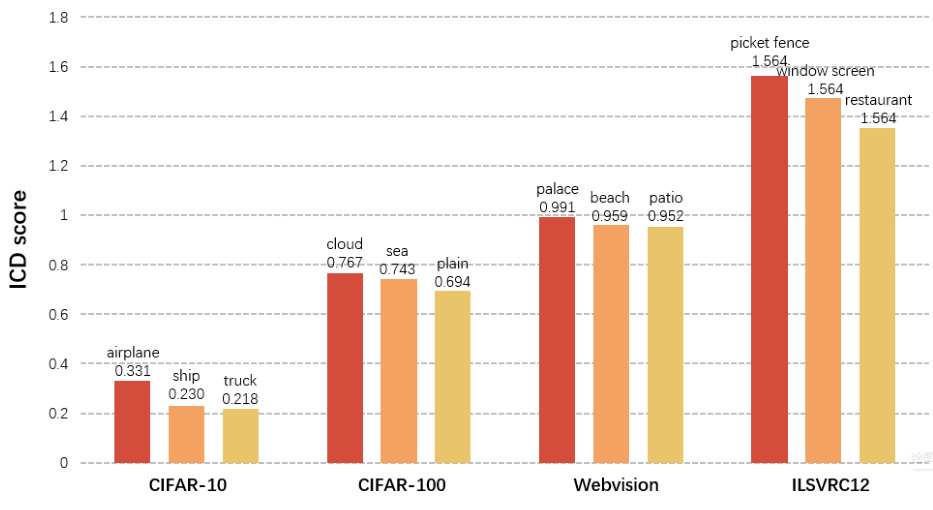
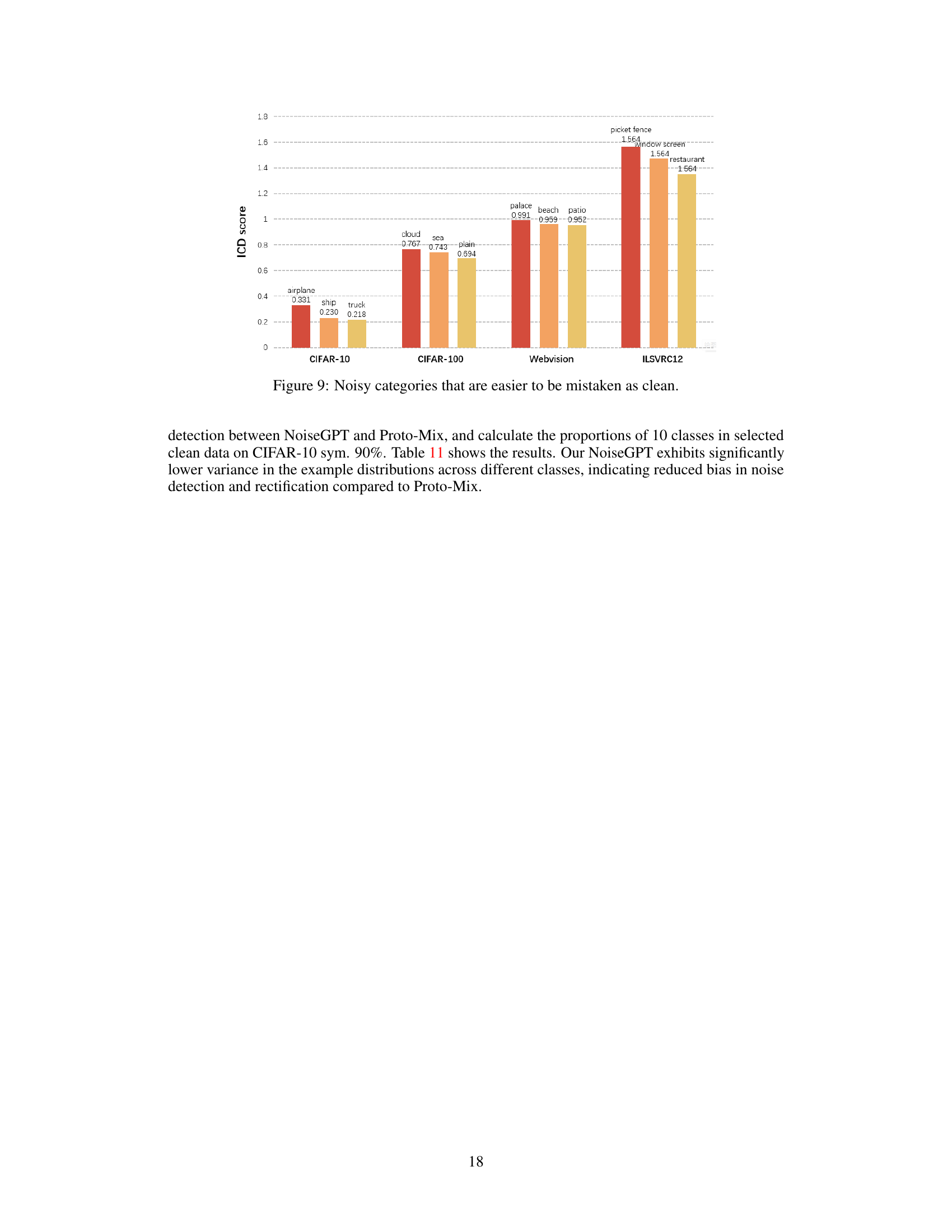
This figure shows the average ICD scores for noisy categories in four datasets: CIFAR-10, CIFAR-100, Webvision, and ILSVRC12. The higher the score, the more likely a noisy example from that category is to be mistaken as clean by the NoiseGPT model. It highlights the detection biases of NoiseGPT, showing that some noisy categories are more easily misclassified as clean than others.
More on tables
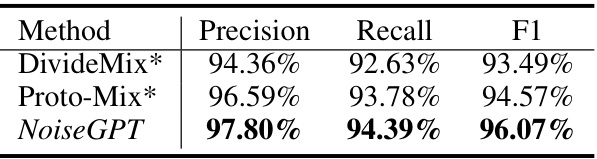
This table compares the detection performance of NoiseGPT with two baseline methods, DivideMix and Proto-Mix, using precision, recall, and F1-score as evaluation metrics. The results are based on the CIFAR-10 dataset with 80% symmetric noise. NoiseGPT outperforms both baselines in all three metrics, demonstrating its superior ability to detect noisy labels.

This table shows the noise reduction effects of NoiseGPT on CIFAR-10 and CIFAR-100 datasets with varying levels of symmetric and asymmetric noise. The improvement is substantial, particularly for CIFAR-10 datasets with high noise rates. The last row indicates the number of clean examples remaining after NoiseGPT’s rectification process.

This table presents the classification accuracy results on the Webvision dataset for various methods. It shows a comparison of different techniques, highlighting the improvement achieved by integrating NoiseGPT with DivideMix, resulting in the highest accuracy of 78.10%.
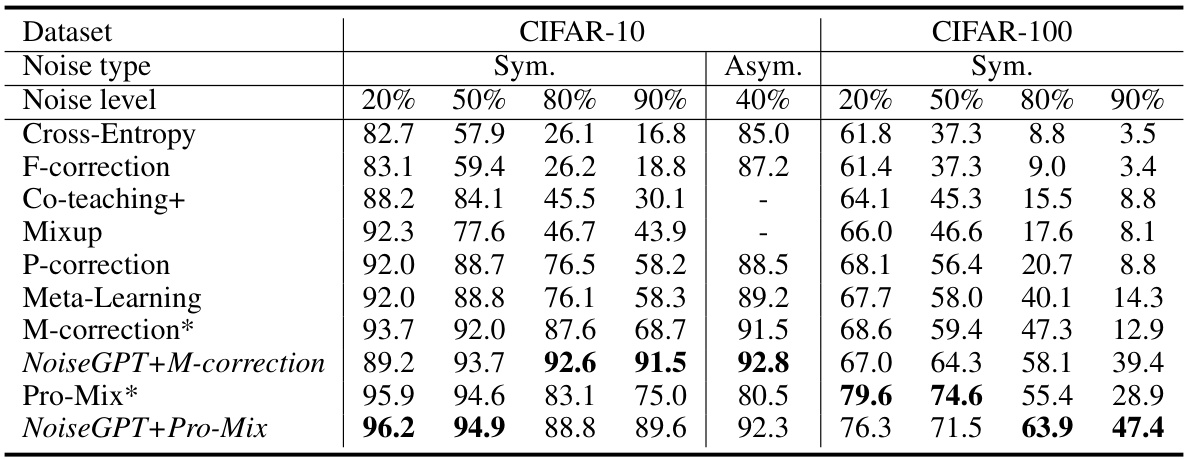
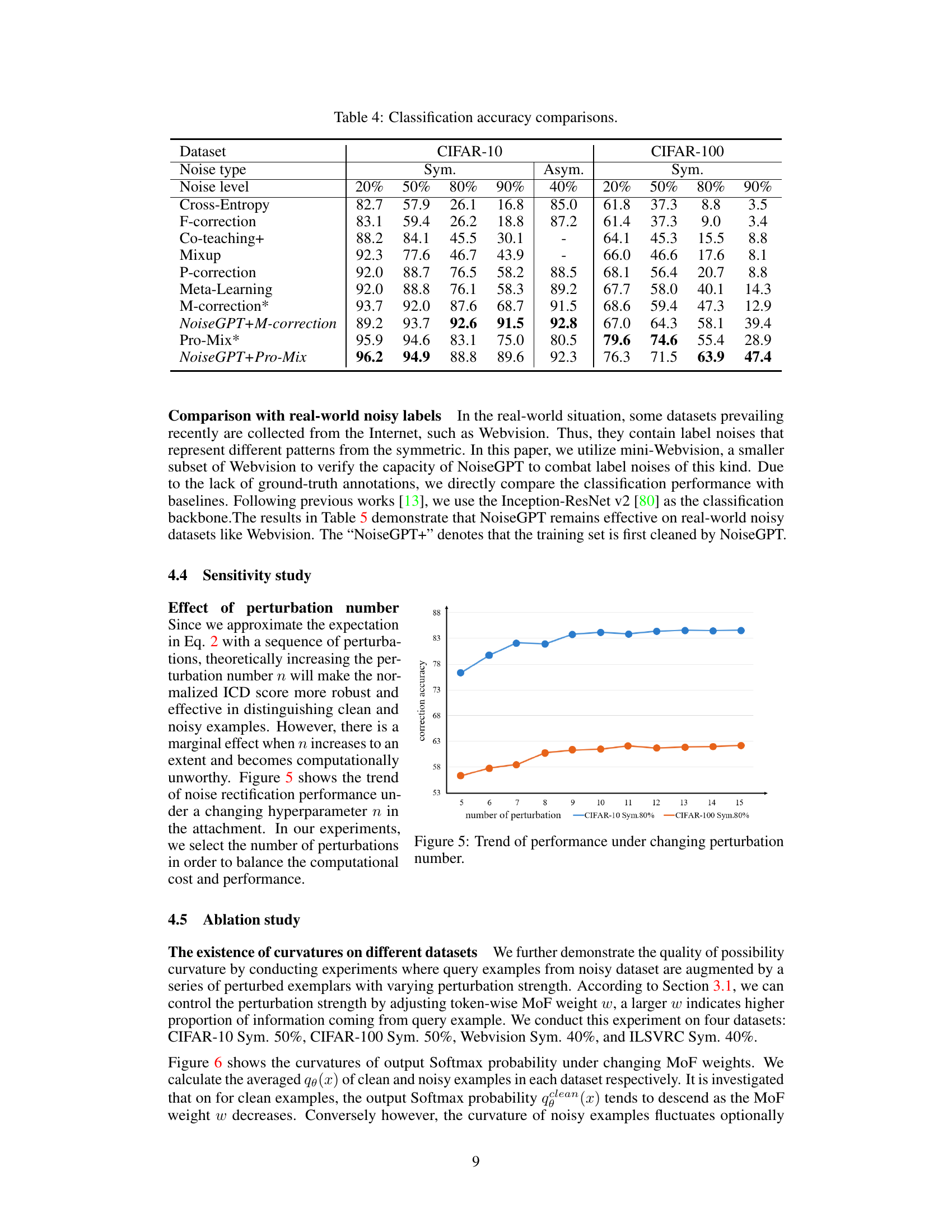
This table presents a comparison of classification accuracy achieved by various methods on CIFAR-10 and CIFAR-100 datasets with different noise levels (symmetric and asymmetric). It compares the performance of NoiseGPT integrated with other methods (NoiseGPT+M-correction and NoiseGPT+Pro-Mix) against baseline methods like Cross-Entropy, F-correction, Co-teaching+, Mixup, P-correction, Meta-Learning, M-correction, and Pro-Mix. The results show the impact of NoiseGPT on improving the classification accuracy in the presence of label noise.

This table lists the hyperparameters used in the NoiseGPT experiments. These parameters control various aspects of the model’s operation, including the mixing of features (MoF weight), the number of examples used for each class, the number of perturbations applied to each query, the threshold used for noise detection, and the number of candidate labels considered during label rectification.

This table shows the runtime in hours for NoiseGPT’s noise detection and rectification experiments on CIFAR-10 and CIFAR-100 datasets. Different noise types (symmetric and asymmetric) and levels (20%, 50%, 80%, 90%, and 40%) are considered. The table highlights the computational cost associated with different noise conditions and dataset sizes.

This table presents the noise reduction results achieved by NoiseGPT on CIFAR-10N and CIFAR-100N datasets. It shows the initial noise rate (before NoiseGPT), the noise rate after applying NoiseGPT, and the number of clean samples remaining after the noise reduction process for different noise types (Aggregate, Rand1, Worst for CIFAR-10N, and Noisy for CIFAR-100N).

This table presents the classification accuracy results on CIFAR-10N and CIFAR-100N datasets. It compares the performance of two classic noisy label learning methods (M-correction and ProtoMix) with and without the integration of NoiseGPT, demonstrating the effectiveness of NoiseGPT in improving classification accuracy when dealing with noisy labels.
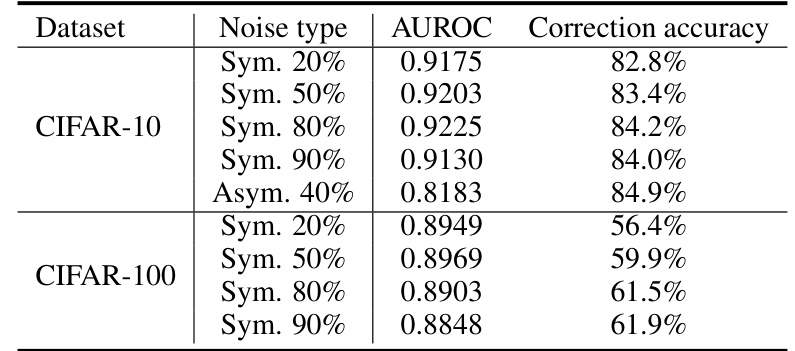
This table presents the performance of NoiseGPT on CIFAR-10 and CIFAR-100 datasets with various symmetric and asymmetric noise levels. For each dataset and noise type, it shows the Area Under the Receiver Operating Characteristic curve (AUROC) score for noise detection and the correction accuracy for label rectification. Higher AUROC values indicate better noise detection, and higher correction accuracy signifies more effective label rectification.

This table compares the detection biases of NoiseGPT and Proto-Mix*. It presents the average ICD scores for clean classes that are frequently mistaken as noisy, across 10 different classes, calculated for both methods. The variance (Var) column highlights a key finding: NoiseGPT exhibits significantly lower variance in ICD scores across different classes compared to Proto-Mix*, indicating a more balanced and less biased noise detection process. In other words, NoiseGPT is less likely to misidentify certain classes as noisy disproportionately compared to the baseline method.
Full paper#