↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large language models require efficient fine-tuning methods due to their immense parameter scale. While Low-Rank Adaptation (LoRA) methods are effective, they suffer from a fixed rank, neglecting the variable importance of matrices. Adaptive rank allocation methods, like AdaLoRA, dynamically allocate ranks but struggle with efficiency and limited rank space.
SalientLoRA addresses these issues by introducing a salience measurement and adaptive rank optimization. It measures the salience of ranks within a time-series, pruning low-salience ranks while retaining those with high significance. An adaptive adjustment of the time-series window enhances speed and stability. Experiments across various tasks show SalientLoRA outperforms existing methods, achieving significant improvements in both efficiency and effectiveness.
Key Takeaways#
Why does it matter?#
This paper is significant because it presents a novel approach to enhance the efficiency and effectiveness of parameter-efficient fine-tuning for large language models, addressing a critical challenge in the field. The proposed method improves upon existing techniques and offers a new avenue for research.
Visual Insights#
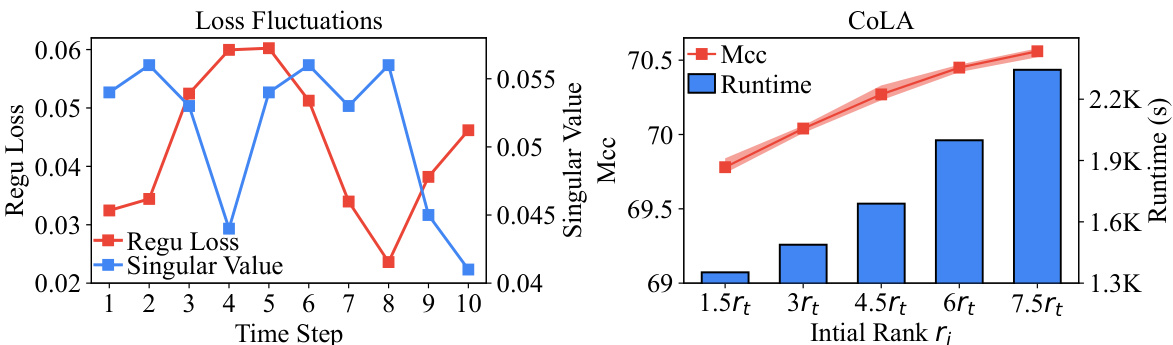
The left panel of Figure 1 shows the fluctuations of regularization loss and singular values over multiple time steps during the training process. This visualization highlights the instability and variability in these metrics, indicating that a fixed rank may not be optimal for capturing the dynamic importance of matrix elements. The right panel demonstrates the impact of increasing the initial rank (r_i) on both the performance (measured by Matthews Correlation Coefficient, MCC) and runtime of the AdaLoRA algorithm during fine-tuning. The results show that a larger initial rank generally leads to better performance but with significantly increased runtime.

This table presents the experimental results comparing SalientLoRA’s performance against other parameter-efficient fine-tuning methods (AdaLoRA, DoRA, LoRA, Adapter, AdapterFusion, SORA) on the GLUE benchmark. Results are shown for different parameter budgets and include multiple metrics (accuracy, Matthews correlation coefficient, Spearman correlation coefficient) relevant to the various GLUE tasks. Statistical significance (p-value < 0.05) is noted where SalientLoRA outperforms AdaLoRA and DoRA. The average performance across five runs with different random seeds is shown.
In-depth insights#
LoRA Rank Analysis#
LoRA Rank Analysis would delve into the optimal rank selection for Low-Rank Adaptation (LoRA) in fine-tuning large language models. It would likely explore the trade-off between model performance and computational efficiency, as higher ranks improve performance but increase the number of trainable parameters. A key aspect would be the development or evaluation of rank selection methods, potentially comparing fixed-rank approaches with adaptive methods. The analysis would consider the impact of rank on training stability and generalization. Furthermore, it would likely investigate how different tasks or model architectures might require different rank settings, emphasizing the need for task-adaptive or architecture-aware rank allocation. Finally, the analysis might explore the relationship between the rank and the singular value spectrum of the weight matrices being adapted, with the goal of identifying meaningful ways to assess and predict optimal ranks.
Salience-Based Tuning#
Salience-based tuning represents a novel approach to parameter-efficient fine-tuning of large language models. The core idea revolves around identifying and prioritizing the most influential parameters within the model’s weight matrices. Instead of uniformly adjusting all parameters, this method focuses on those with the highest impact on model performance, leading to significant improvements in both efficiency and effectiveness. This is achieved by measuring the ‘salience’ of each parameter, a metric that reflects its influence on the model’s output or loss function. Parameters deemed highly salient are tuned with greater emphasis, while less influential ones receive minimal or no adjustments. This selective tuning process has several benefits: reduced computational costs, faster convergence, and potentially enhanced generalization. However, the challenge lies in defining and accurately calculating the salience of each parameter. Different methods might be employed to measure salience, and it’s crucial that the chosen method is robust and can reliably identify the truly important parameters. Furthermore, the optimal strategy for weighting salient parameters during tuning needs to be determined. Further research may also focus on adapting the salience calculation to account for the dynamic nature of model behavior during training. Overall, salience-based tuning presents a promising path towards more efficient and effective large language model fine-tuning.
Adaptive Rank Allocation#
Adaptive rank allocation methods address limitations of fixed-rank parameter-efficient fine-tuning techniques like LoRA by dynamically adjusting the rank of the low-rank update matrix. This dynamic adjustment is crucial because the importance of different matrix elements varies during training. Methods like AdaLoRA leverage singular value decomposition (SVD) to assess importance and allocate ranks accordingly, but they often struggle to balance effectiveness and efficiency. A key challenge lies in accurately measuring the importance of ranks, which is often based on parameters’ minimal impact on the loss, neglecting the dominant role of singular values and training fluctuations. Future research should explore more robust methods of rank assessment that integrate insights from the time-series behavior of singular values and loss function. Integrating interdependencies between ranks within a time-series holds promise for more accurate and efficient rank allocation. Furthermore, adaptive adjustment of the time window for rank assessment offers a means to balance speed and training stability.
Efficiency Improvements#
This research paper focuses on enhancing the efficiency of parameter-efficient fine-tuning methods for large language models (LLMs). The core idea revolves around adaptively optimizing the rank allocation in Low-Rank Adaptation (LoRA), a popular parameter-efficient technique. Existing methods often suffer from limitations due to fixed ranks, neglecting the variable importance of matrices throughout the training process. The proposed SalientLoRA method directly addresses this by introducing a salience analysis to dynamically determine the optimal rank. This analysis considers correlations between singular values and prunes low-salience ranks, leading to improved fine-tuning performance. Furthermore, an adaptive time-series window mechanism improves training stability and speeds up rank allocation. Experimental results across multiple tasks demonstrate that SalientLoRA significantly outperforms state-of-the-art methods in terms of both accuracy and speed, showing considerable efficiency gains. The key contribution is a more nuanced approach to rank determination, moving beyond fixed rank allocation towards a data-driven, adaptive strategy.
Future Research#
Future research directions stemming from this work could explore several avenues. Extending SalientLoRA to other parameter-efficient fine-tuning methods beyond LoRA, such as Adapters or Prefix-tuning, would broaden its applicability and impact. Investigating the influence of different hyperparameter settings on SalientLoRA’s performance across diverse tasks and model architectures is crucial for optimizing its effectiveness. A deeper analysis into the interplay between the influence domain and orthogonality-aware singular value magnitudes within the salience measurement is needed to further refine the rank allocation strategy. Finally, applying SalientLoRA to even larger language models and exploring its scalability on resource-constrained settings would highlight its practical advantages and potential for widespread adoption.
More visual insights#
More on figures
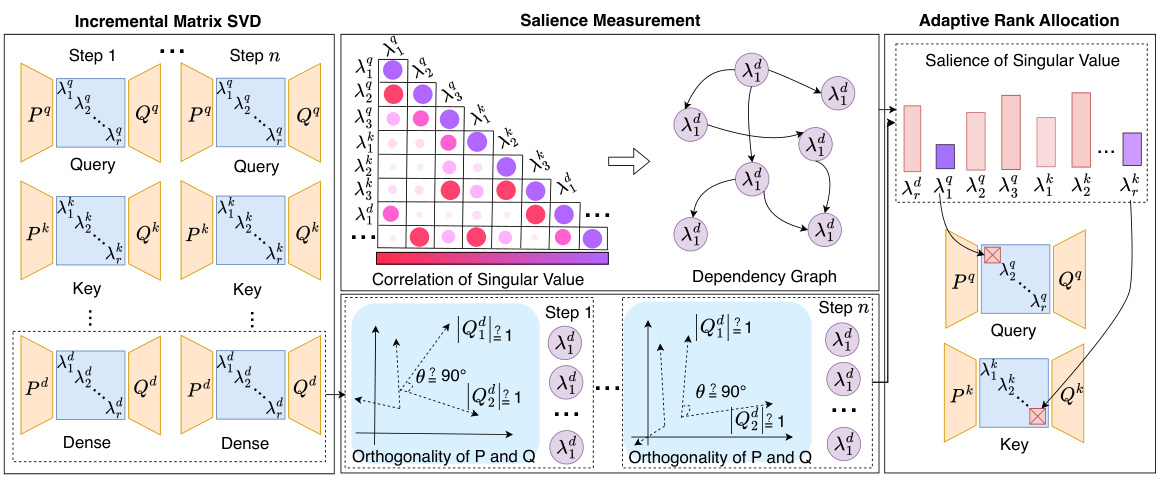
This figure illustrates the three main components of the SalientLoRA method: incremental matrix SVD, salience measurement, and adaptive rank allocation. The incremental matrix is first decomposed using SVD, enabling rank control. Then, salience is measured for each singular value considering both magnitude and its influence on other values within a time series. Finally, based on salience, less significant singular values are removed to optimize the rank.
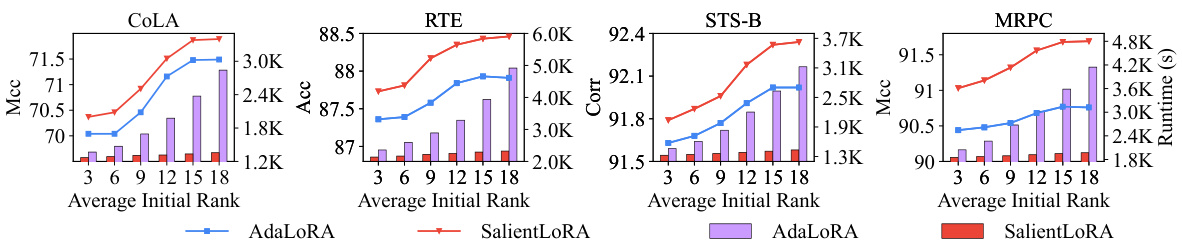
This figure compares AdaLoRA and SalientLoRA’s performance and runtime across four datasets (COLA, RTE, STS-B, MRPC) while increasing the average initial rank. The line graphs show that both methods improve performance as the initial rank increases, but SalientLoRA consistently outperforms AdaLoRA. Notably, the bar graphs highlight SalientLoRA’s significantly better runtime efficiency compared to AdaLoRA, even as the rank space expands.

This figure shows the impact of the hyperparameter λ on the fine-tuning performance across four different datasets (COLA, RTE, STS-B, and MRPC). The hyperparameter λ controls the balance between the contribution of orthogonality-aware singular value magnitudes and the influence domain in the salience measurement. The plots show that there’s an optimal value for λ around 0.7, where the performance is maximized for most datasets. Values of λ outside this range lead to decreased performance, indicating the importance of balancing these two components in the salience calculation for optimal results.

This figure illustrates the three main stages of the SalientLoRA method: 1) Incremental Matrix SVD: Decomposes the incremental matrix into three matrices (P, V, Q) using singular value decomposition. 2) Salience Measurement: Measures the salience of each singular value based on magnitude and influence within a time series. 3) Adaptive Rank Allocation: Uses the salience information to prune less important singular values, adapting the rank of the LoRA.
More on tables

This table presents the performance comparison between SalientLoRA and other parameter-efficient fine-tuning methods on the GLUE benchmark. It shows the average performance across eight datasets (CoLA, SST-2, MRPC, QQP, STS-B, MNLI, QNLI, RTE) for two different parameter settings, using various metrics (accuracy, Matthews Correlation Coefficient, Spearman’s Correlation Coefficient). The results demonstrate SalientLoRA’s superiority over other methods and its statistical significance.
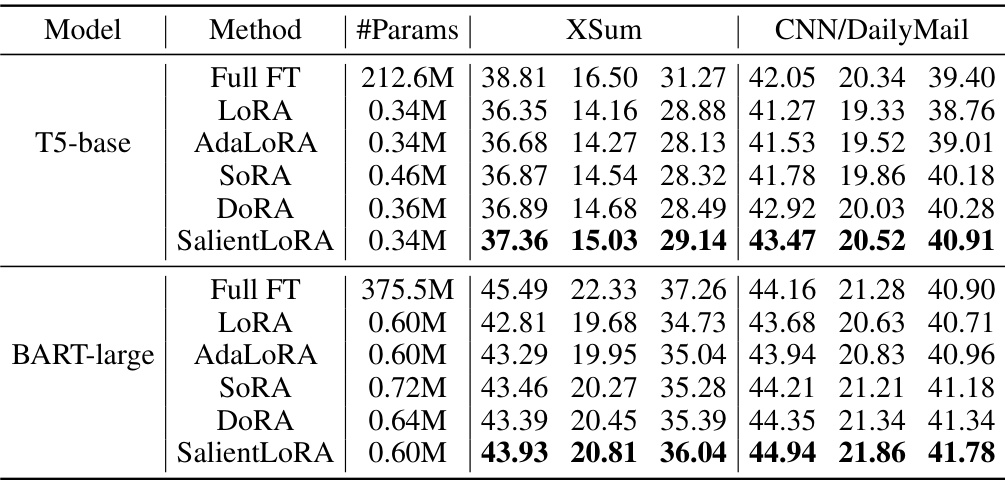
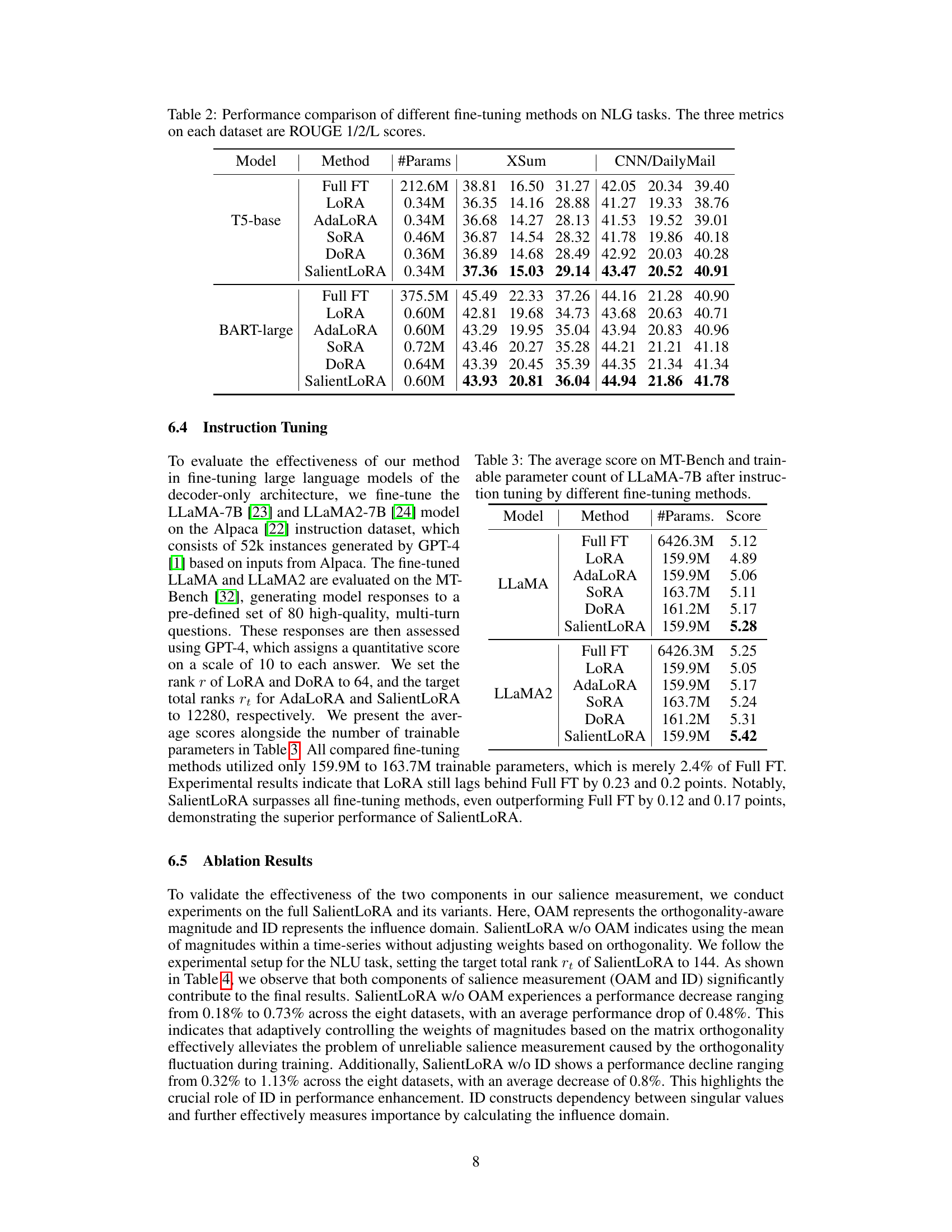
This table compares the performance of several parameter-efficient fine-tuning methods on two natural language generation (NLG) tasks: text summarization using the XSum and CNN/DailyMail datasets. The methods compared include Full Fine-Tuning (Full FT), LoRA, AdaLoRA, SoRA, DoRA, and SalientLoRA. The table shows the number of parameters used by each method and the ROUGE-1, ROUGE-2, and ROUGE-L scores achieved on each dataset. ROUGE scores are commonly used metrics to evaluate the quality of text summarization.
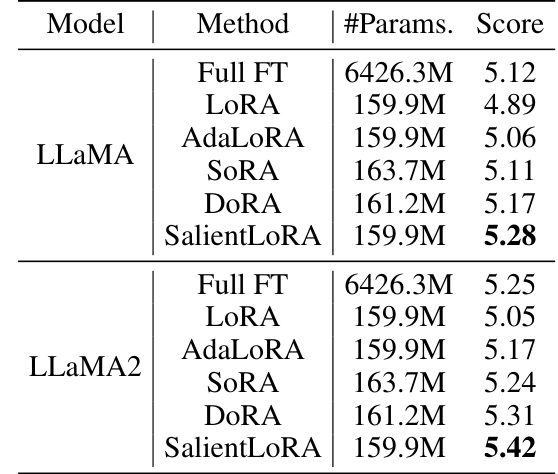
This table presents the performance comparison of different fine-tuning methods on the LLaMA-7B model for instruction tuning. The methods compared include Full Fine-tuning (Full FT), LoRA, AdaLoRA, SoRA, DoRA, and SalientLoRA. The table shows the number of trainable parameters used by each method and the average score achieved on the MT-Bench benchmark. SalientLoRA demonstrates the highest score among all methods.

This table presents the results of ablation experiments conducted to evaluate the impact of two key components in SalientLoRA’s salience measurement: orthogonality-aware singular value magnitudes (OAM) and the influence domain (ID). The table shows the performance of SalientLoRA with both components, with only OAM, and with only ID on eight datasets from the GLUE benchmark. The performance drop (↓) indicates the decrease in performance compared to the full SalientLoRA model, highlighting the contribution of each component to the overall performance.

This table presents a comparison of the performance of SalientLoRA against other parameter-efficient fine-tuning methods on the GLUE benchmark. Results are shown for different parameter budget sizes (number of parameters), demonstrating the impact on performance metrics (accuracy, Matthews correlation coefficient, Spearman correlation coefficient) across the eight GLUE datasets. Statistical significance (p-value < 0.05) is reported for the comparison between SalientLoRA and other methods.

This table shows the number of training, testing, and development samples for the XSum and CNN/DailyMail datasets used in the paper’s natural language generation experiments.

This table presents the results of experiments conducted to analyze the impact of hyperparameters β and γ on the performance of the SalientLoRA fine-tuning method. It shows the Matthews Correlation Coefficient (MCC) and accuracy (Acc) achieved on the CoLA and MRPC datasets, along with the corresponding fine-tuning time (Time), for various combinations of β and γ values. The results help determine optimal values for β and γ that balance performance and efficiency.

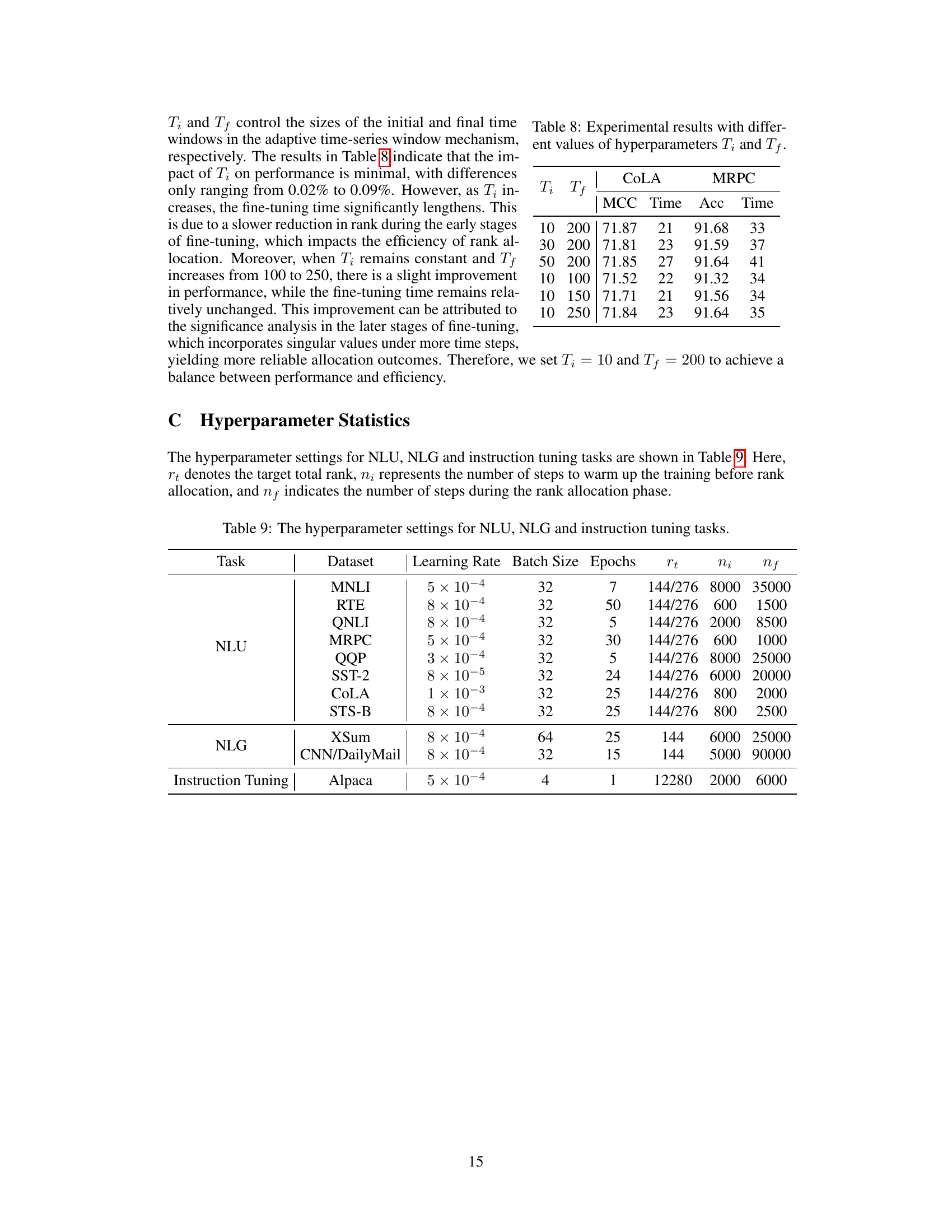
This table presents the results of experiments conducted to analyze the impact of varying the initial (Ti) and final (Tf) time window sizes on the performance of the SalientLoRA model. The experiments were performed on the CoLA and MRPC datasets, using a fixed target total rank (rt) of 144. The table shows the Matthews Correlation Coefficient (MCC) and accuracy (Acc) achieved, along with the corresponding fine-tuning times (Time) for each combination of Ti and Tf values.
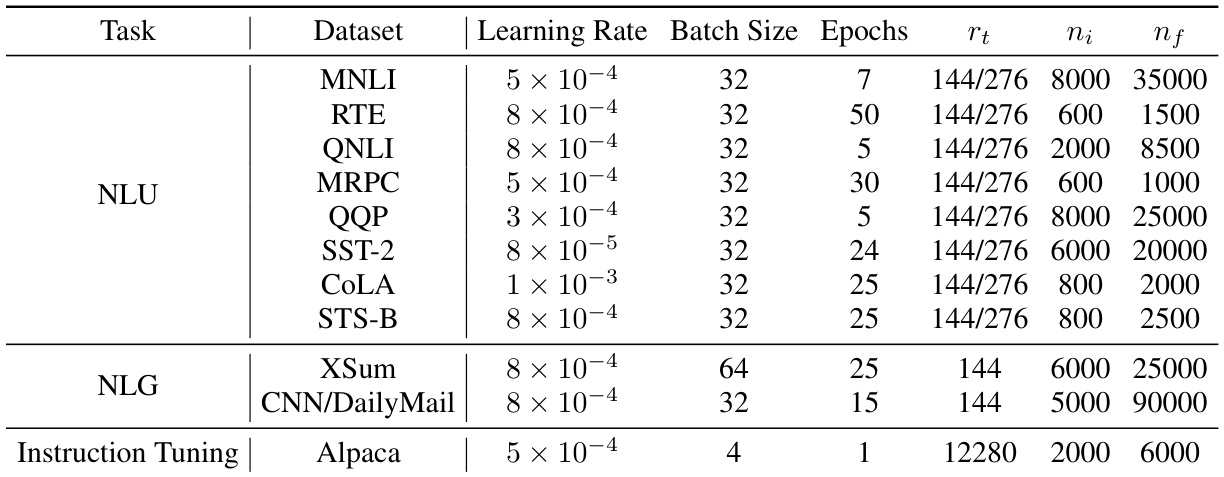
This table lists the hyperparameters used in the experiments for different tasks (NLU, NLG, and Instruction Tuning). It details the learning rate, batch size, number of epochs, target total rank (rt), warm-up steps (ni), and rank allocation steps (nf) used for each dataset in each task. The hyperparameters were chosen to optimize performance within each experimental setting.
Full paper#