↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Video salient object ranking (VSOR) aims to dynamically prioritize objects’ visual attraction in a scene over time, but remains underexplored. Existing methods struggle to effectively model temporal saliency due to limitations in capturing instance-wise motion and jointly optimizing spatial-temporal cues. They often focus on global inter-frame contrast, neglecting instance-level motion dynamics.
This paper introduces a novel graph-based model addressing these limitations. It simultaneously explores multi-scale spatial contrasts and intra-/inter-instance temporal correlations, explicitly modeling the motion of each instance. By unifying spatial and temporal cues in a single graph, it achieves superior performance compared to previous stage-wise methods, demonstrating the superiority of a joint optimization approach. A novel video retargeting method based on VSOR further highlights the practical application of this work.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and video processing due to its novel approach to video salient object ranking. It proposes a unified spatial-temporal graph model which outperforms existing methods and opens up new avenues for video retargeting and related applications. The joint optimization of spatial and temporal cues, along with the introduction of motion-aware features, significantly improves the accuracy and efficiency of video saliency analysis, offering valuable insights for future research.
Visual Insights#

This figure compares the visual results of the proposed method with other state-of-the-art methods for video salient object ranking. It shows that previous methods (Liu’s and Lin’s) tend to focus on objects with prominent static saliency cues, while the proposed method emphasizes instance-wise temporal correlations, resulting in more accurate results, especially for objects with significant motion.
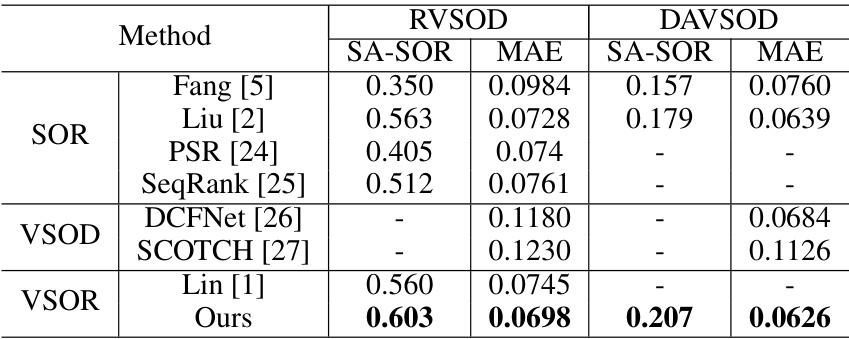
This table presents a quantitative comparison of the proposed VSOR method against several state-of-the-art methods on two datasets, RVSOD and DAVSOD. The performance is evaluated using two metrics: SA-SOR (higher is better) which reflects both segmentation and ranking quality, and MAE (lower is better) which measures the accuracy of segmentation. The table highlights the superior performance of the proposed method across both datasets and metrics.
In-depth insights#
Motion-Aware Graph#
A motion-aware graph for video salient object ranking represents a significant advancement in computer vision. It addresses the limitations of previous methods by explicitly modeling the motion of individual objects across frames, rather than relying solely on global inter-frame comparisons. This is crucial because human attention is strongly drawn to movement. The graph structure allows for the simultaneous consideration of both spatial and temporal information, capturing multi-scale spatial contrasts and intra-/inter-instance temporal correlations. This integrated approach leads to more robust and accurate saliency estimations, outperforming methods that treat spatial and temporal cues in a sequential or isolated manner. The joint optimization of spatial and temporal cues within the graph further enhances the model’s ability to dynamically adapt to changes in saliency, resulting in superior video salient object ranking performance. The innovative approach of comparing features within the same spatial region across adjacent frames efficiently captures instance-wise motion saliency without requiring explicit object tracking, a significant practical advantage. This model’s effectiveness is demonstrated through extensive experiments, highlighting its potential applications in various video-related tasks.
Spatial-Temporal Fusion#
The heading ‘Spatial-Temporal Fusion’ suggests a crucial step in processing spatiotemporal data, likely from a video. This fusion likely involves combining spatial features (e.g., object locations, appearances) with temporal features (e.g., motion trajectories, temporal context) to create a richer representation. A naive approach might simply concatenate spatial and temporal features; however, a more sophisticated method would likely involve a joint learning process. This might use a graph neural network (GNN) or another model to learn interactions between spatial and temporal information. The effectiveness of the fusion hinges on how well the model captures dependencies between spatial and temporal aspects, perhaps by modelling attention or relationships across frames. Successful fusion would lead to a more accurate and robust understanding of the scene’s dynamics over time, improving downstream tasks like object ranking or video summarization. A key challenge in spatial-temporal fusion lies in handling the varying scales and resolutions of spatial and temporal information. An effective fusion method needs to manage the complexity inherent in the interplay of these different scales and be computationally efficient. The final representation resulting from the fusion process likely serves as input for further processing steps such as saliency ranking, object detection, or video event recognition.
Video Retargeting#
The application of video salient object ranking (VSOR) to video retargeting presents a novel approach. Instead of relying on global saliency maps, the method leverages instance-level saliency rankings to determine optimal cropping regions. This allows for more accurate preservation of important semantic content while mitigating background interference. Instance-wise saliency scores guide the selection of a saliency centroid and determine cropping parameters. A simple yet effective method that uses these rankings, combined with techniques like LOESS to reduce visual artifacts from camera shake, ensures better temporal consistency. The proposed method outperforms existing retargeting techniques that either lack instance-level granularity or fail to adequately address temporal coherence, offering superior visual quality and improved user experience. The key advantage lies in its ability to intelligently adapt to varying degrees of saliency across objects within a frame, maintaining more meaningful content in the resized video. This approach opens new possibilities for developing more sophisticated and user-friendly video adaptation tools.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a video salient object ranking model, this might involve removing different modules, such as the spatial correlation modeling, temporal correlation modeling, or the motion-aware temporal fusion mechanisms. By evaluating the performance of the model after each ablation, researchers can quantify the impact of each component. A well-designed ablation study will isolate the effect of each module, providing clear evidence of its necessity and effectiveness. Analyzing the results could reveal, for instance, that removing motion-aware cues leads to a significant drop in ranking accuracy, thus highlighting the crucial role of motion perception in accurately prioritizing salient objects. Conversely, a minimal performance decrease after removing a particular component could indicate redundancy or a less critical role. Ultimately, a strong ablation study provides conclusive evidence supporting the design choices and demonstrating the model’s effectiveness.
Limitations#
A critical analysis of the ‘Limitations’ section of a research paper necessitates a nuanced understanding of its role. It’s not merely a list of shortcomings, but an opportunity to showcase intellectual honesty and foresight. A strong ‘Limitations’ section should acknowledge methodological constraints, such as dataset biases or the scope of the experimental design, that may affect the generalizability of the results. It needs to address algorithmic limitations, explaining any simplifying assumptions made or inherent weaknesses in the proposed approach. Moreover, the discussion should be forward-looking, proposing future research directions that could address the identified shortcomings and thus improve the presented work. Ultimately, a robust ‘Limitations’ section enhances the paper’s credibility and demonstrates the authors’ comprehensive understanding of their own contributions and their potential boundaries.
More visual insights#
More on figures

This figure shows the overall architecture of the proposed VSOR model. It consists of three main stages: 1) Instance feature extraction, where an object detector identifies instances in each frame, and attention and position embeddings enhance instance features. 2) Spatial-temporal graph reasoning, where a graph neural network fuses spatial and temporal saliency cues from multiple scales. This stage includes spatial correlation modeling (considering interactions between instances, local and global contrasts), and temporal correlation modeling (capturing instance interactions and motion-aware contrast across adjacent frames). 3) Saliency score prediction, where a fully connected neural network predicts final saliency scores which are combined with instance segmentation results to produce a saliency ranking map. The figure illustrates the data flow and the interactions within each stage, highlighting the key components and their relationships.

This figure presents a qualitative comparison of the proposed method against other state-of-the-art (SOTA) video salient object ranking methods. It shows the results for four different video clips, each displayed with the input image, ground truth saliency masks, and the saliency masks produced by the different methods (Liu’s, Lin’s, and the proposed ‘Ours’). The color-coding in the ‘Salient Instance’ column indicates different salient objects, with the same color consistently used for the same object across different frames in a sequence. This visualization helps to demonstrate how the proposed method, unlike the others, handles the temporal dynamics of saliency more accurately.

This figure compares the visual results of the proposed method against three other state-of-the-art (SOTA) methods. Two example video clips are shown, and the results of each method are presented alongside the ground truth (GT). The figure visually demonstrates the improvements achieved by the authors’ model, particularly in accurately identifying and ranking salient objects that exhibit significant motion, such as a person walking. This contrasts with the other methods, which tend to overemphasize static objects.
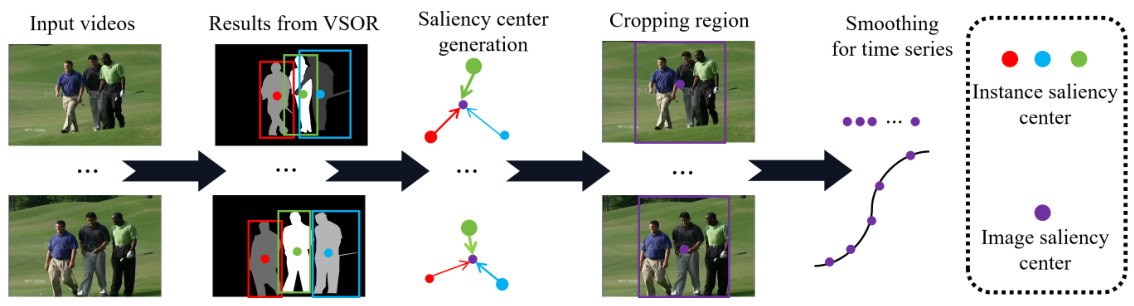
This figure illustrates the video retargeting method proposed in the paper. It shows a step-by-step process: 1. Input videos are processed; 2. The VSOR model generates instance-level saliency information (bounding boxes, masks, and ranking); 3. A saliency center is calculated based on the instance-level saliency; 4. A cropping region is determined using the saliency center; 5. Smoothing is applied for temporal consistency. The result is a retargeted video suitable for different aspect ratios.

This figure compares the results of three different video retargeting methods: seam carving, smartVideoCrop, and the proposed method from the paper. The goal is to show how each method handles resizing a video while maintaining the visual quality. The seam carving method (a) produces noticeable artifacts, especially shown in the yellow bounding box. The smartVideoCrop (b) method improves the results. (c) shows the results of the proposed method, aiming for a better result in terms of artifact reduction and preserving visual quality.
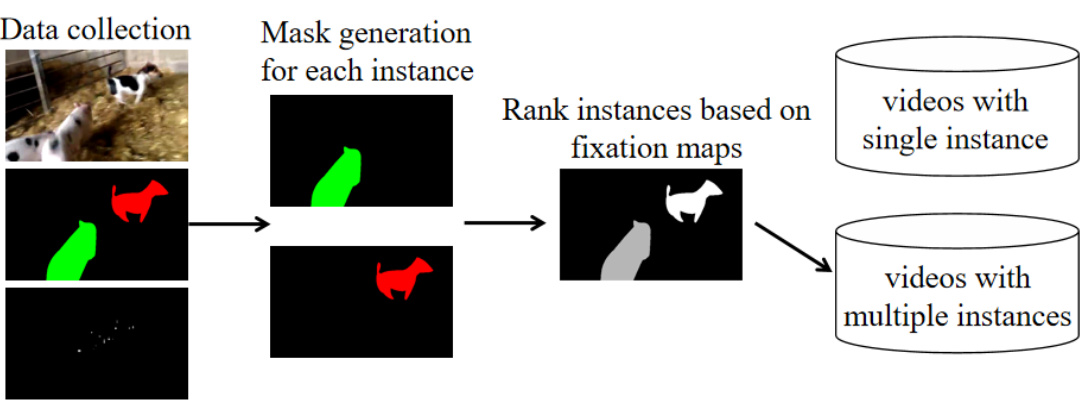
This flowchart illustrates the process of creating the dataset used in the paper. It starts with data collection, then proceeds to mask generation for each instance within the collected videos. Instance ranking is performed based on fixation maps, leading to the final separation of videos into two categories: those with single instances and those with multiple instances.

This figure shows a comparison of the proposed method with other state-of-the-art methods for video salient object ranking. It visually demonstrates the advantages of the proposed method in accurately identifying and ranking salient objects, especially those with rich motion cues but less static saliency. The comparison highlights the limitations of previous methods that mainly prioritize objects with prominent static cues, neglecting the importance of dynamic saliency.

This figure compares video retargeting results using two different methods: smart-video-crop [13] and the proposed method. The smart-video-crop method uses image-level saliency for cropping, which can lead to inaccurate results. The proposed method, on the other hand, uses instance-level saliency from the VSOR model, resulting in more accurate and visually appealing results. The red boxes highlight the cropped regions.
More on tables

This table presents the ablation study results for different temporal interaction methods in the proposed VSOR model. It compares the performance of the baseline model (without temporal features) against versions incorporating global temporal information (GTRM), instance-level temporal information (ITRM), and motion-aware temporal information (MTRM). Finally, it shows the results of combining all three types of temporal features in the unified model. The performance is evaluated using SA-SOR on both RVSOD and DAVSOD datasets.
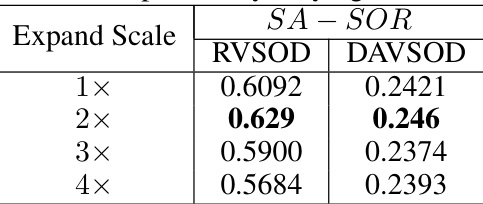
This table presents a quantitative comparison of the model’s performance on the RVSOD and DAVSOD datasets when varying the bounding box size used for motion-aware temporal relation modeling. The SA-SOR metric is used to evaluate the model’s ranking performance, with higher scores indicating better performance. The table shows that expanding the bounding box size by a factor of 2 yields the best results, suggesting an optimal balance between capturing motion information and avoiding excessive background noise.
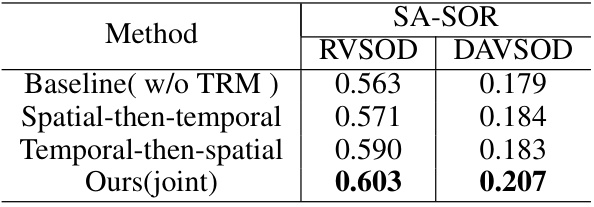
This table presents the ablation study on different strategies for fusing spatial and temporal features in the proposed VSOR model. The baseline is Liu’s model without temporal relationship modeling (TRM). Three different fusion strategies are compared: spatial-then-temporal, temporal-then-spatial, and the proposed joint fusion method. The results are evaluated using the SA-SOR metric on RVSOD and DAVSOD datasets. The table shows that the joint fusion method significantly outperforms the other two stage-wise fusion methods, demonstrating its superiority in effectively integrating spatial and temporal information for video salient object ranking.

This table presents a statistical analysis of the DAVSOD dataset used for video salient object ranking. It breaks down the number of scenes and images into categories based on the number of salient instances present in each video frame: semi-valid (some frames have one, others have multiple instances), valid (multiple salient instances), and invalid (only one salient instance). This categorization helps understand the dataset’s characteristics and its suitability for evaluating video salient object ranking models.

This table presents a quantitative comparison of the proposed VSOR model against several state-of-the-art methods on two video saliency ranking datasets (RVSOD and DAVSOD). The performance is evaluated using two metrics: SA-SOR (which measures both ranking and segmentation quality, with higher scores being better) and MAE (which measures segmentation accuracy, with lower scores being better). The table shows that the proposed method outperforms other methods on both metrics across datasets, highlighting its effectiveness in video salient object ranking. Note that results for Lin’s method are only provided for RVSOD due to the method not being publicly available.
Full paper#



















