↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Training large foundation models is computationally expensive, limiting their accessibility. This often prevents researchers from leveraging their power, especially in resource-constrained environments. Existing methods to reduce the computational burden include parameter-efficient fine-tuning. However, these still require significant resources.
This paper introduces LOFF-TA, a novel training scheme. Instead of fine-tuning the entire model, LOFF-TA caches feature embeddings from a frozen foundation model and trains a lightweight classifier on these embeddings. To address the limitation of not using image augmentations, LOFF-TA utilizes tensor augmentations applied directly to the cached embeddings. The results show that LOFF-TA achieves impressive speedups (up to 37x) and memory savings (up to 26x) while maintaining comparable performance, making foundation models more accessible to researchers with limited resources.
Key Takeaways#
Why does it matter?#
This paper is important because it offers a resource-efficient training method for large foundation models, making them accessible to researchers with limited computational resources. It introduces a novel approach that significantly speeds up training and reduces memory usage, while maintaining comparable performance. This opens doors for broader adoption of these models in various fields.
Visual Insights#
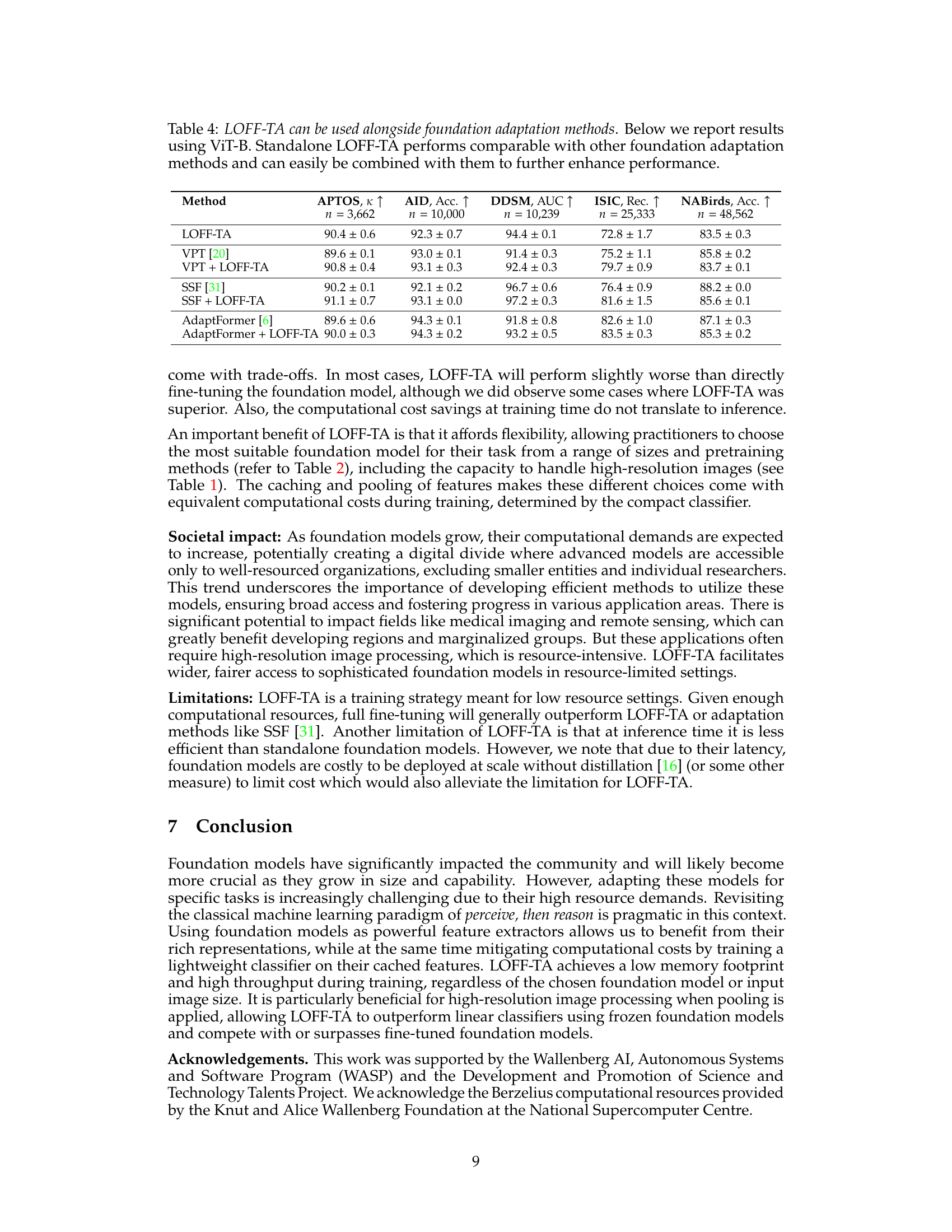
This figure illustrates the LOFF-TA framework. Training data is first processed by a pre-trained foundation model (like a Vision Transformer), and the resulting feature embeddings are cached. These embeddings, not the original images, are then used to train a smaller, more efficient classifier. Instead of applying typical data augmentation techniques to images (which would require storing many augmented image embeddings, increasing storage costs), tensor augmentations are applied directly to the cached feature embeddings. This method allows the use of much larger foundation models and high-resolution images without increasing computational demands.
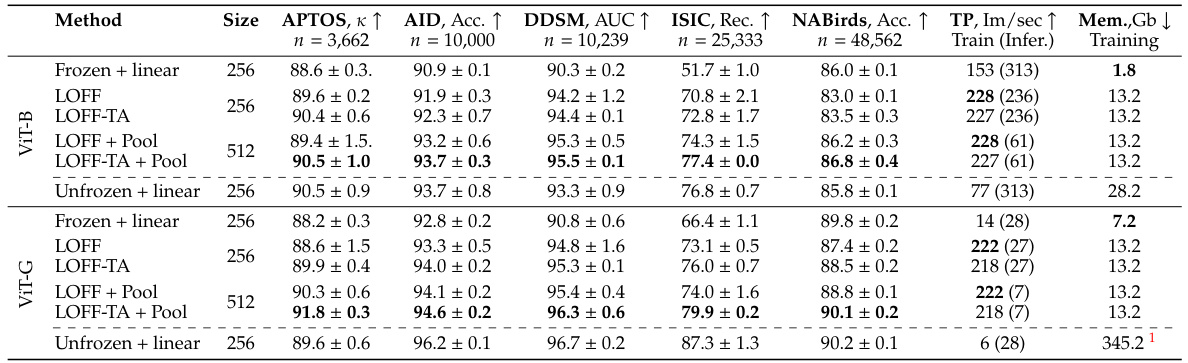
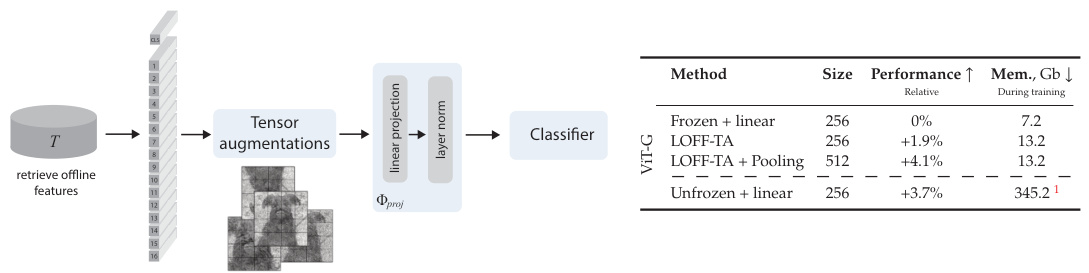
This table presents the main results of the experiments comparing the performance of LOFF and LOFF-TA against baselines (Frozen + linear and Unfrozen + linear). It shows the performance metrics (APTOS, AID, DDSM, ISIC, NABirds) for different model sizes (256 and 512) and with/without pooling and tensor augmentations. The baselines represent training a linear layer or a full linear classifier directly on images with standard augmentations, with the foundation model either frozen or unfrozen.
In-depth insights#
Offline Foundation#
The concept of “Offline Foundation” in the context of the research paper points towards a paradigm shift in how foundation models are utilized. Instead of directly fine-tuning these large, computationally expensive models, the core idea revolves around pre-processing training data using a frozen foundation model. This pre-processing step extracts and caches feature embeddings, which are then used to train a much smaller, more efficient classifier. This approach is significant because it decouples the computationally intensive part of using foundation models from the actual training process, thereby opening up their use in environments with limited resources. The benefits extend to training with high-resolution images without incurring massive computational overhead, a critical aspect in fields such as medical imaging. Further, by using tensor augmentations directly on the cached embeddings, the approach overcomes the limitations of traditional image augmentation methods in this context. The strategy offers a unique and resourceful way to leverage the power of foundation models without the constraints of computational resources and cost.
Tensor Augments#
The concept of “Tensor Augmentations” in the context of this research paper presents a novel approach to data augmentation within the framework of foundation models. Instead of augmenting the images themselves, which would be computationally expensive given the large size of foundation models and the substantial storage required, the authors propose augmenting the feature embeddings (tensors) extracted from a foundation model. This is a significant departure from traditional methods, offering a substantial advantage in efficiency. The key insight lies in the observation that spatial augmentations can be successfully applied to these tensor representations, mimicking the effects of common image augmentations. This method, LOFF-TA, leverages the power of standard augmentations without incurring the significant computational overhead of image augmentation, enabling faster and more memory-efficient training. While the effectiveness of tensor augmentations is demonstrated and compared to traditional image augmentations, the precise reasons behind its efficacy warrant further investigation. The authors speculate about the role of spatial information encoded within these tensors and the potential impact of disrupting that information as a means to boost robustness. Further experiments focusing on the type and choice of appropriate tensor augmentations for various tasks are required to better understand the full potential of this technique.
Efficient Training#
The concept of “Efficient Training” in the context of large foundation models is crucial. The paper introduces LOFF-TA, a method that significantly accelerates training by decoupling it from the resource-intensive foundation model. This is achieved by training a lightweight classifier on cached feature embeddings from the foundation model, leading to substantial speedups (up to 37x) and memory reduction (up to 26x). The innovation of using tensor augmentations on cached embeddings, instead of standard image augmentations, is key to this efficiency. This allows leveraging the power of large foundation models without incurring the cost of fine-tuning, which makes it especially suitable for resource-constrained environments and high-resolution images. The results show that LOFF-TA achieves comparable, and sometimes even better, performance than directly fine-tuning large models, underscoring its value as an efficient and effective training strategy.
High-Res Images#
The ability to effectively utilize foundation models with high-resolution images is a significant challenge due to the substantial computational resources required. This paper introduces a novel approach, LOFF-TA, which addresses this limitation by decoupling the training process from the resource-intensive foundation model. Instead of directly training on high-resolution images, LOFF-TA processes the images offline using a foundation model and stores the resulting feature embeddings. These embeddings, which retain essential spatial information from the original images, are then used to train a lightweight classifier. This strategy enables the use of arbitrarily large foundation models and high-resolution images without increasing compute costs. Furthermore, LOFF-TA introduces tensor augmentations, which are applied to the cached embeddings to address the challenge of storing augmented images. The results demonstrate that LOFF-TA achieves comparable or superior performance to directly fine-tuning foundation models while offering significant improvements in training speed and memory efficiency. This methodology thus opens the door for broader access to high-resolution image analysis using powerful foundation models, especially within resource-constrained environments. The effectiveness of this approach is further validated by the application to various image classification datasets, showcasing its general applicability and potential for advancement in high-resolution image analysis.
Future Directions#
Future research could explore more sophisticated tensor augmentation techniques, moving beyond simple spatial transformations to incorporate more complex operations that better capture the nuances of feature representations. Investigating alternative augmentation strategies, such as those inspired by generative models, could also yield improvements. A key area for future work is to deepen our understanding of the interplay between tensor augmentations and the underlying foundation model. This would involve investigating how different foundation models respond to various augmentation schemes and exploring ways to adapt augmentation strategies to specific model architectures. Finally, extending LOFF-TA to other modalities beyond images, such as audio and text, would significantly broaden its applicability and impact. Research could focus on developing effective tensor augmentations tailored to the unique characteristics of these different data types. This comprehensive approach would advance the capabilities of LOFF-TA and expand its potential contributions to various fields of machine learning.
More visual insights#
More on figures
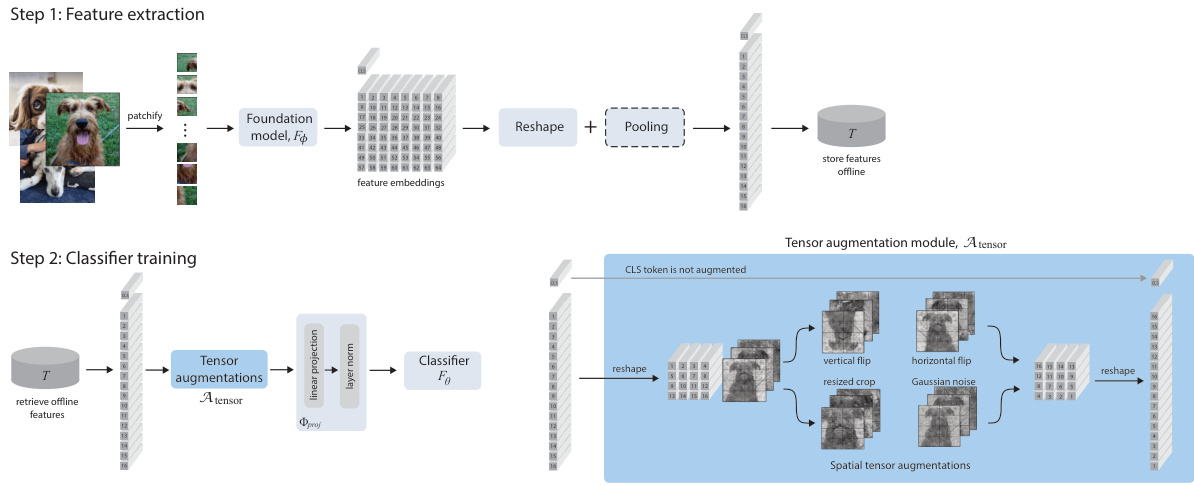
This figure illustrates the two-step process of LOFF-TA. In Step 1, training data is passed through a foundation model to extract features, which are then cached. Step 2 involves loading these cached features, applying tensor augmentations (flips, crops, noise), passing them through a projection and normalization layer, and finally training a lightweight classifier on the augmented features. An optional pooling step is shown, which reduces the spatial dimension of features to enable training with high-resolution images without increased compute.

This figure shows the results of a Centered Kernel Alignment (CKA) analysis to compare the representational similarities between different models. The left panel displays the representation similarity between classifiers trained using different methods on the Oxford-III-Pet dataset. The right panel shows the internal representational similarity of each classifier (trained using different methods) before and after fine-tuning. The results are intended to illustrate how the different training methods affect the learned feature representations of the classifiers.

This figure demonstrates the spatial consistency between images and their corresponding foundation model features. The similarity allows for informed choices in tensor augmentations. The example shows that if a vertical flip negatively affects a building facade in the image, it’s likely to have a similar negative impact when using that augmentation on the features. The experiment shows that LOFF-TA is more resilient to incorrect augmentation choices than a standard classifier trained on images.
More on tables
The table presents the main results of the experiments comparing different methods for training classifiers on features extracted from foundation models. It compares LOFF and LOFF-TA against baselines (Frozen+linear and Unfrozen+linear), considering different image sizes (256x256 and 512x512) and pooling strategies. Performance metrics (such as APTOS, AID, etc.) and computational resources (memory and training/inference speed) are reported for each method.

This table presents the ablation study results, showing the impact of each component of the LOFF-TA method on the performance. It systematically removes components (CLS, layer norm, Gaussian noise, spatial augmentation, trivial augmentation) to isolate their individual effects. Results are reported using DINOv2 as the foundation model and include a comparison with adding trivial augmentations. The experiment is conducted on Oxford-III Pet and Caltech-101 datasets.
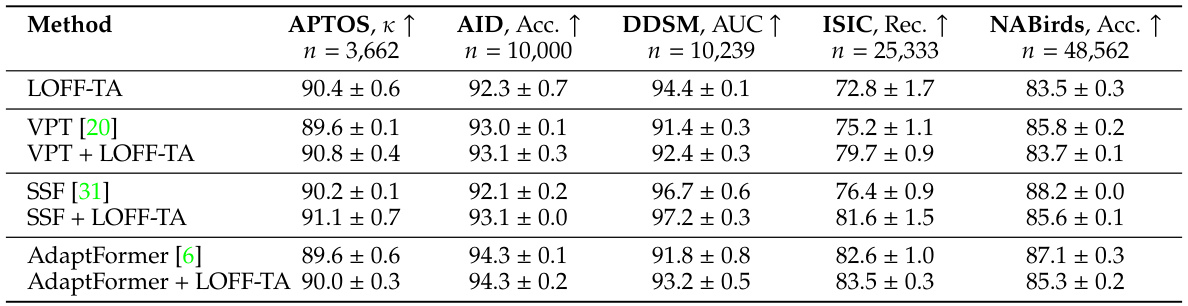
This table compares the performance of LOFF-TA with other foundation adaptation methods (VPT, SSF, AdaptFormer). It shows that LOFF-TA achieves competitive results on its own and that combining LOFF-TA with these other methods leads to further performance improvements across multiple datasets.

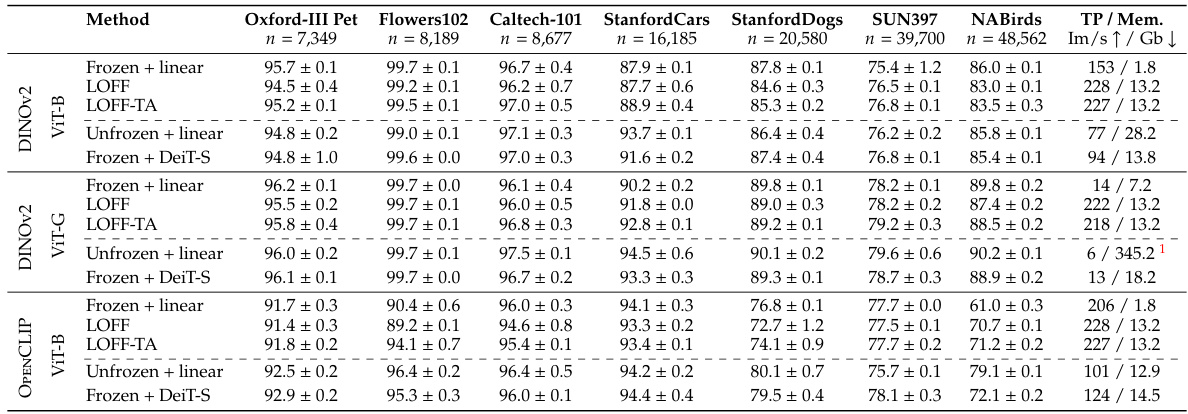
This table presents a detailed comparison of the performance of LOFF and LOFF-TA against several baseline models across seven standard image classification datasets. The results are broken down by method (LOFF, LOFF-TA, Frozen + linear, Unfrozen + linear, Frozen + DeiT-S), using features extracted from both OPENCLIP and DINOv2 models with 256x256 images. It shows performance metrics for each dataset and model, allowing for a comprehensive evaluation of the proposed methods.
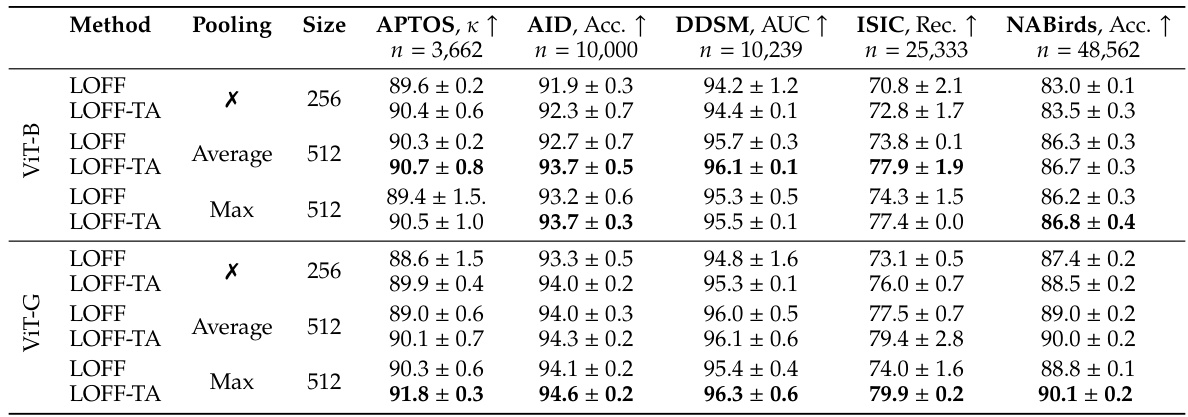
This table presents the main results of the LOFF and LOFF-TA methods, comparing them against baselines using DINOv2 ViT-B and ViT-G models. It shows the performance (using various metrics depending on the dataset), training speed (images per second), and GPU memory usage for different configurations: LOFF (no augmentations), LOFF-TA (with tensor augmentations), and two baselines (Frozen + linear and Unfrozen + linear). The table also explores the impact of pooling on features extracted from images of different resolutions (256x256 and 512x512).
Full paper#