↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Multi-task learning (MTL) with Vision Transformers often suffers from suboptimal performance and low inference speed due to limitations in existing Mixture-of-Experts (MoE) and Low-Rank Adaptation (LoRA) approaches. These methods often struggle with balancing the optimization of MoE and the effectiveness of LoRA’s reparameterization.
The proposed Efficient Multi-Task Learning (EMTAL) framework addresses these issues. EMTAL introduces a novel MoEfied LoRA structure that decomposes the Transformer into low-rank MoEs, fine-tunes parameters with LoRA, and utilizes a Quality Retaining (QR) optimization mechanism to prevent performance degradation in well-trained tasks. A router fading strategy efficiently integrates learned parameters into the original Transformer for efficient inference. Extensive experiments show EMTAL outperforms state-of-the-art MTL approaches.
Key Takeaways#
Why does it matter?#
This paper is important because it presents EMTAL, a novel and efficient multi-task learning framework for Vision Transformers. It addresses the limitations of existing methods by introducing a MoEfied LoRA structure, a Quality Retaining optimization mechanism, and a router fading strategy. This work is relevant to the current trends in efficient multi-task learning and provides a new avenue for future research by demonstrating that efficient and effective multi-task learning is achievable by decomposing a pre-trained Vision Transformer and efficiently integrating the learned parameters back into the unified model.
Visual Insights#
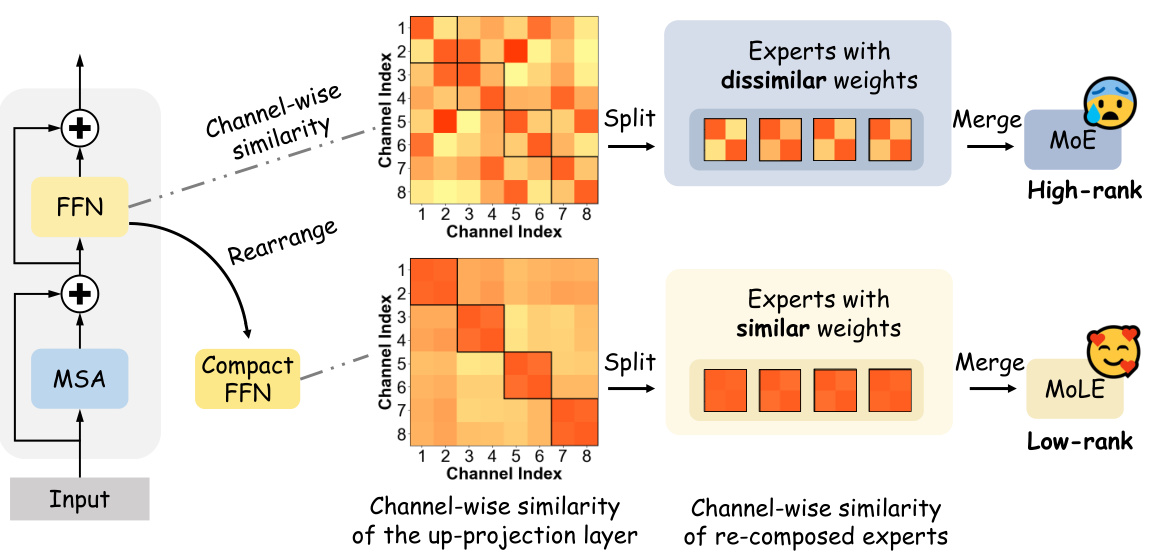
This figure illustrates two different ways of splitting the feed-forward network (FFN) layer into Mixture of Experts (MoE). The top half shows the traditional approach, which results in experts with dissimilar weights and a high-rank MoE. The bottom half shows the proposed MoEfied LoRA approach, which rearranges the channels to create experts with similar weights, resulting in a low-rank MoE better suited for integration with Low-Rank Adaptation (LoRA). This improves efficiency and effectiveness of multi-task learning.

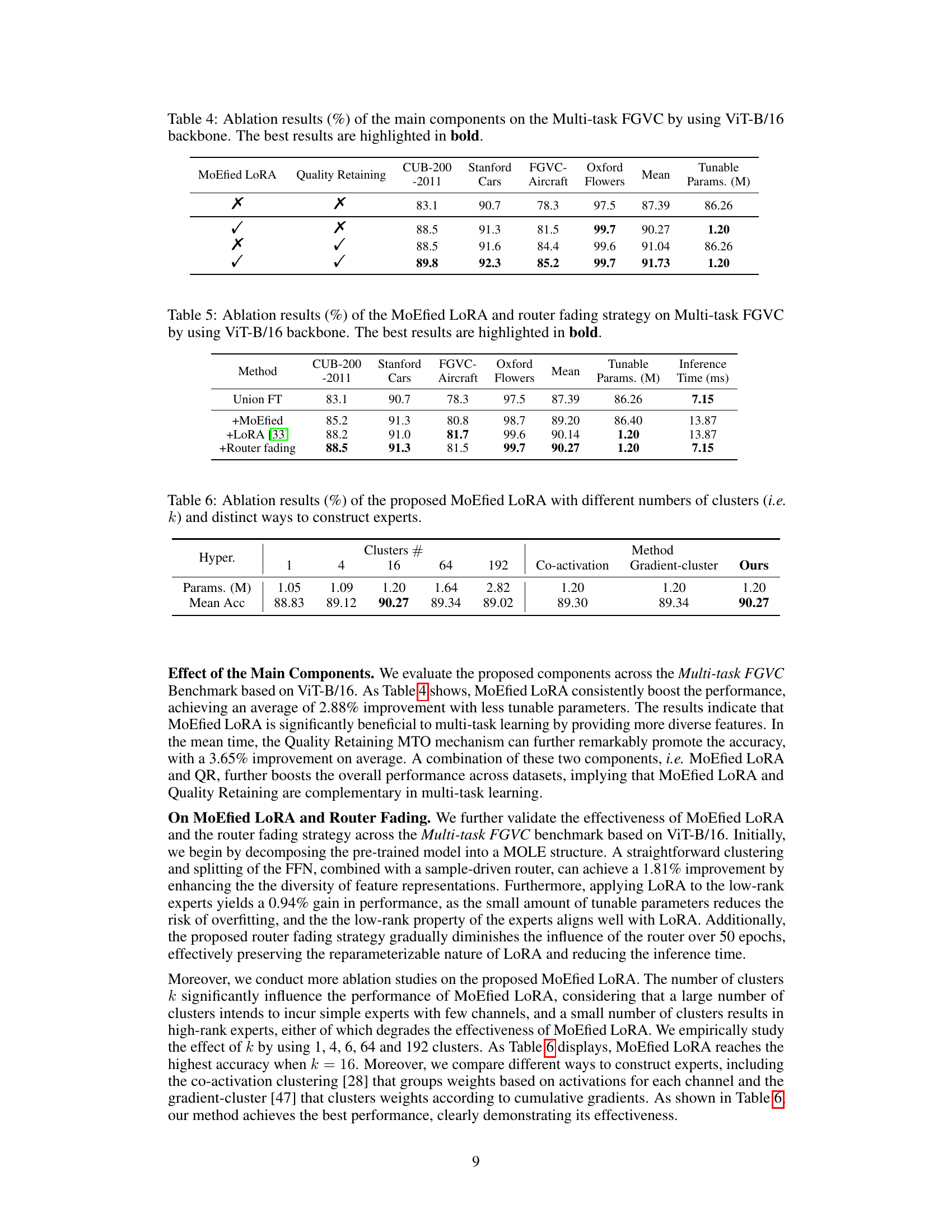
This table compares the performance of various multi-task learning (MTL) methods on the Multi-task FGVC benchmark using a Vision Transformer (ViT-B/16) model pre-trained on ImageNet-21K. It contrasts different baselines (separate and unified full fine-tuning) with several state-of-the-art gradient-based and loss-based MTL approaches, as well as other efficient multi-task learners. The key metric is top-1 accuracy across four fine-grained visual classification tasks (CUB-200-2011, Stanford Cars, FGVC-Aircraft, Oxford Flowers). The table also lists the number of tunable parameters and inference time for each method, showcasing the trade-off between accuracy and efficiency.
In-depth insights#
MoEfied LoRA Design#
The proposed “MoEfied LoRA” design represents a novel approach to multi-task learning within Vision Transformers. It cleverly combines the strengths of Mixture-of-Experts (MoE) and Low-Rank Adaptation (LoRA) in a way that addresses the limitations of prior methods. MoEfication decomposes the FFN layer into low-rank experts, based on clustering channels with similar weights, thus creating specialized experts suitable for LoRA’s efficient parameterization. This avoids the high-rank issues associated with previous MoE integrations. By employing LoRA on these low-rank experts, the approach maintains efficiency, enabling effective multi-task fine-tuning without a large number of additional parameters. The combination of MoE and LoRA in this manner is what makes this method novel and potentially more efficient.
Asynchronous MTL#
Asynchronous Multi-Task Learning (MTL) addresses the challenges posed by the inherent differences in convergence rates across multiple tasks. Standard MTL often suffers from performance degradation due to conflicting task gradients and varying loss scales, forcing tasks to learn at the same pace, which is inefficient. Asynchronous MTL tackles this issue by allowing tasks to learn independently at their own speeds. This approach acknowledges that some tasks may converge faster than others. By decoupling the learning processes, Asynchronous MTL prevents slower tasks from being hindered by faster ones, leading to better overall performance. However, careful consideration is needed to prevent faster-converging tasks from negatively affecting the learning of slower tasks. Techniques such as loss-weighting or gradient balancing may be employed to mitigate potential conflicts. Quality Retaining optimization is a notable technique that retains high-quality knowledge acquired during the training of faster-converging tasks. This approach leverages historical high-quality logits to maintain the performance of these tasks while other tasks continue to learn asynchronously. This method ultimately improves the efficiency and effectiveness of multi-task learning.
QR Optimization#
The QR (Quality Retaining) optimization strategy tackles the asynchronous nature of multi-task learning in vision transformers. It addresses the challenge of tasks converging at different rates, preventing well-trained tasks from degrading as others are still being optimized. QR achieves this by maintaining a knowledge bank of high-quality logits from early-converged tasks. These logits act as a regularization term, guiding the optimization process and preventing catastrophic forgetting. This method allows for a more natural and efficient asynchronous training process, resulting in improved overall performance compared to approaches that force synchronization or rely solely on gradient-based methods for balancing task optimization.
Router Fading#
The concept of ‘Router Fading’ in the context of multi-task learning with a Mixture-of-Experts (MoE) architecture is a clever strategy for efficient inference. It addresses the overhead associated with the routing mechanism in MoEs, which typically involves dynamically selecting experts for each input. By gradually diminishing the router’s influence during the final training epochs, the model seamlessly integrates the learned parameters from the experts into the original Transformer’s structure. This eliminates the need for a separate routing network during inference, resulting in a significant efficiency gain and a more compact model. The technique cleverly leverages the learned knowledge encoded in the router’s weights to smoothly transition to a unified model structure, avoiding abrupt changes or performance degradation. The success of router fading hinges on the quality and stability of the learned expert weights, highlighting the importance of the MoEfied LoRA structure and the Quality Retaining optimization in achieving this smooth transition. Router fading is a key innovation that bridges the gap between efficient training with MoE and efficient inference with a single, unified architecture.
Low-rank Experts#
The concept of “Low-rank Experts” in the context of multi-task learning with Vision Transformers suggests a method to create specialized, efficient components within a larger model. This approach likely involves decomposing a pre-trained transformer’s Feed-Forward Networks (FFNs) into smaller, low-rank matrices, which are then treated as individual “experts.” This decomposition aims to reduce computational costs and enhance the model’s ability to handle diverse tasks concurrently. Each expert would focus on a subset of the input data or specific task-related features, leading to improved efficiency and potentially better performance. The “low-rank” characteristic implies that these smaller matrices contain significantly fewer parameters than the original FFN, making them less demanding to train and more adaptable to new tasks. This is advantageous compared to larger, fully-connected layers in handling multiple tasks simultaneously. The effectiveness of this approach hinges on strategically grouping the original FFN weights into meaningful clusters, ensuring that each low-rank expert specializes in a coherent set of features. The resulting structure needs to be seamlessly integrated back into the original network architecture for efficient inference.
More visual insights#
More on figures

This figure compares three different approaches to multi-task learning: the conventional MoE approach, the LoRA Experts approach, and the proposed MoEfied LoRA approach. The conventional MoE approach uses multiple expert networks and a gating mechanism to dynamically select the most relevant experts for each input. The LoRA Experts approach uses unified low-rank adaptation modules to achieve parameter efficiency. The proposed MoEfied LoRA approach groups similar weights into specialized low-rank experts, enabling seamless integration with LoRA to create an efficient multi-task learner. It combines this with a router fading strategy to ensure both training and inference efficiency while substantially reducing storage overhead.

This figure illustrates the EMTAL framework’s five stages. It starts with a pre-trained Vision Transformer (a). The FFN layer is then decomposed into a Mixture of Low-rank Experts (MoE) using balanced k-means clustering (b). Low-Rank Adaptation (LoRA) is applied to these low-rank experts, forming the MoEfied LoRA (c). The Quality Retaining (QR) optimization method is applied during training to maintain the performance of well-trained tasks (d). Finally, a router fading strategy seamlessly integrates the learned parameters into the original transformer, enabling efficient inference without extra overhead (e).
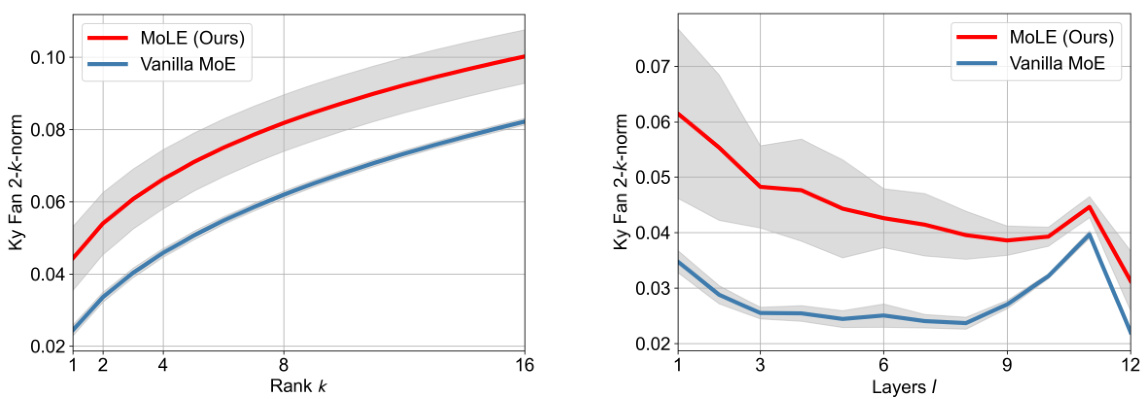
This figure compares the low-rank properties of experts generated using the vanilla MoE and the proposed MoLE method. The Ky Fan 2-k norm is used as a metric to measure the low-rank properties, with higher values indicating a stronger low-rank property. The left subplot shows how the low-rank properties vary across different ranks (k) for experts within a specific transformer block (block 4). The right subplot shows how these properties change across different layers (l) of the transformer for a fixed rank (k=1). The results demonstrate that the MoLE method consistently generates experts with stronger low-rank characteristics, especially in the lower layers of the transformer.
More on tables
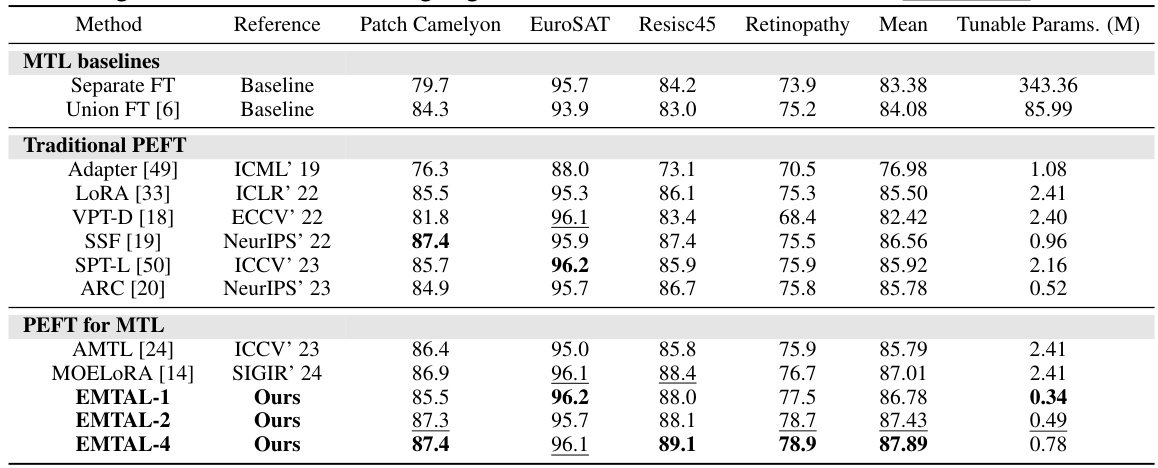
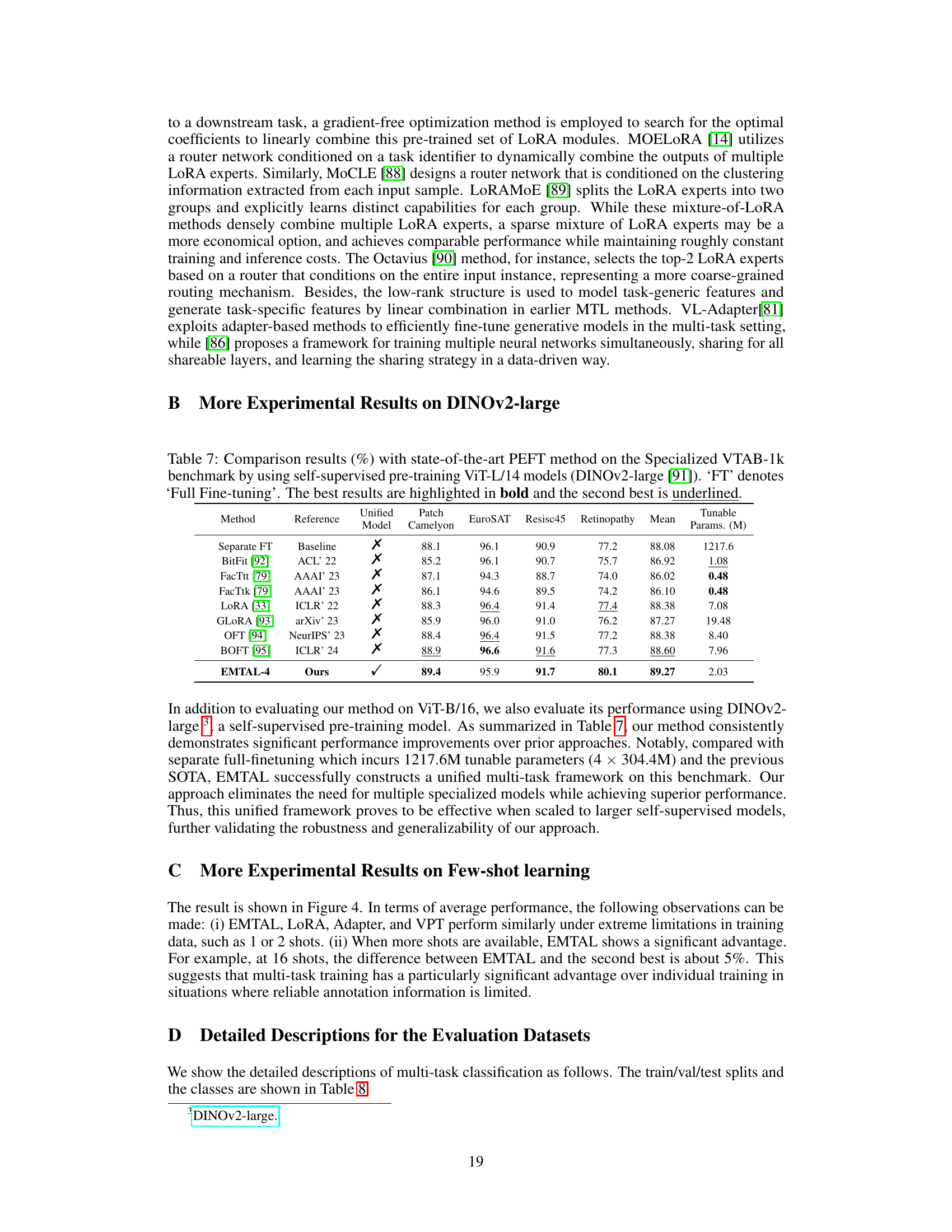
This table compares the performance of the proposed EMTAL method with several state-of-the-art parameter-efficient fine-tuning (PEFT) and multi-task learning (MTL) methods on the Specialized VTAB-1k benchmark. The results show the top-1 accuracy (%) for each method on four different tasks (Patch Camelyon, EuroSAT, Resisc45, Retinopathy), as well as the average performance across all tasks. The table also indicates whether each method uses a unified model and the number of tunable parameters (in millions). The best and second-best performing methods for each task are highlighted in bold and underlined respectively, indicating the superior performance of EMTAL across multiple tasks.

This table presents the performance comparison of the proposed EMTAL method against the baseline method (TaskPrompter-Base) on the NYUv2 dataset for four different tasks: semantic segmentation (Semseg mIoU), depth estimation (Depth RMSE), normal estimation (Normal mErr), and boundary detection (Boundary odsF). The results show that adding EMTAL to the baseline model improves performance across all four tasks, leading to a 1.57% average improvement.
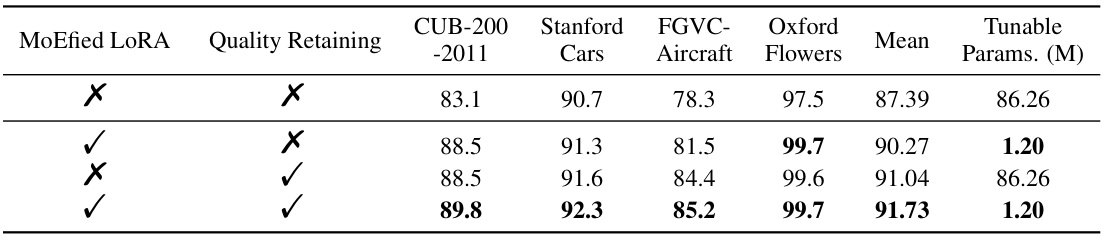
This table presents the ablation study results on the Multi-task FGVC benchmark using a ViT-B/16 backbone. It shows the impact of the two main components of the proposed EMTAL method: MoEfied LoRA and Quality Retaining. Each row represents a different combination of including or excluding these components. The table reports the top-1 accuracy for four datasets (CUB-200-2011, Stanford Cars, FGVC-Aircraft, Oxford Flowers) as well as the average performance across them. The number of tunable parameters is also shown, demonstrating the efficiency of the model. The results highlight that both components contribute to improved performance.
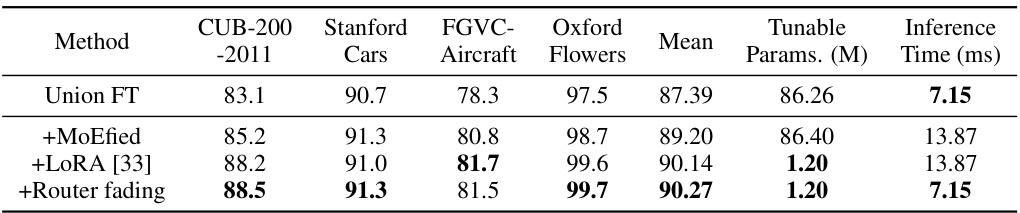
This table compares the performance of different multi-task learning methods on the Multi-task FGVC benchmark using a Vision Transformer (ViT-B/16) model pre-trained on ImageNet-21K. It contrasts several baselines (separate and union full fine-tuning, gradient-based and loss-based multi-task optimization methods), as well as other efficient multi-task learners. The table shows top-1 accuracy for each of four datasets (CUB-200-2011, Stanford Cars, FGVC-Aircraft, Oxford Flowers), the mean accuracy across all four datasets, the number of tunable parameters (in millions), and the inference time (in milliseconds). The best and second-best performing methods are highlighted.

This table presents the ablation study on the impact of different numbers of clusters (k) and expert construction methods on the performance of the proposed MoEfied LoRA. It shows that the optimal number of clusters is 16, resulting in the highest mean accuracy (90.27). The table also compares three different expert construction methods: co-activation, gradient-cluster, and the authors’ proposed method, with the latter achieving the best performance.

This table compares the performance of the proposed EMTAL method with other state-of-the-art Parameter-Efficient Fine-Tuning (PEFT) and Multi-Task Learning (MTL) methods on the Specialized VTAB-1k dataset. It uses a ViT-B/16 model pre-trained on ImageNet-21K. The table shows the top-1 accuracy for each method on four sub-tasks within VTAB-1k (Patch Camelyon, EuroSAT, Resisc45, and Retinopathy), along with the mean accuracy across all tasks and the number of tunable parameters (in millions). The best and second-best results for each task are highlighted in bold and underlined, respectively.
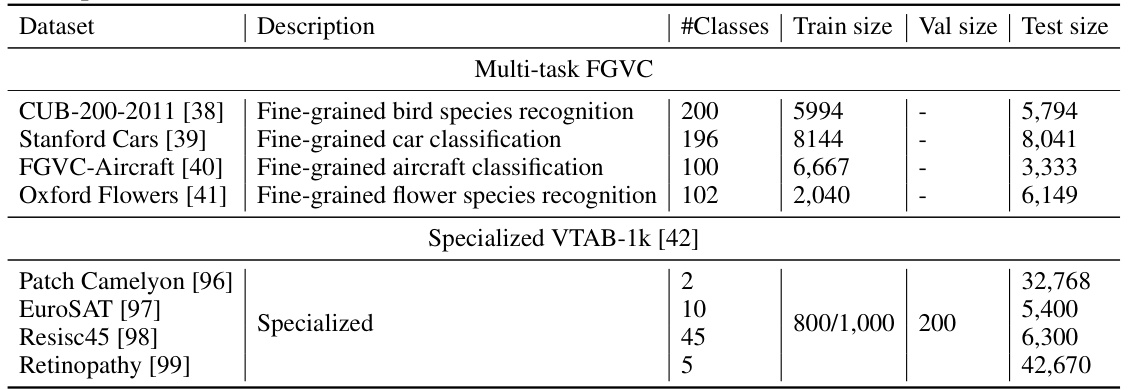
This table compares the top-1 accuracy of various multi-task learning methods on the Multi-task FGVC benchmark. It uses the ViT-B/16 model pre-trained on ImageNet-21K. The table categorizes methods into baseline, gradient-based MTO, loss-based MTO, and efficient multi-task learners. For each method, it presents the accuracy for each of the four datasets in the benchmark (CUB-200-2011, Stanford Cars, FGVC-Aircraft, Oxford Flowers), the mean accuracy across datasets, the number of tunable parameters (in millions), and the inference time (in milliseconds). The best and second-best results are highlighted.
Full paper#