↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Vision-language models like CLIP excel at zero-shot learning but struggle when fine-tuned for specific tasks due to “misalignment.” This happens because the model’s pre-training objectives differ from the downstream task’s goals and the training and testing data don’t match perfectly. This leads to poor performance, especially when dealing with new classes not seen during training.
This research tackles this problem by creating a causal model to understand the relationships between images, text descriptions, and class labels. They discover that irrelevant information interferes with the model’s ability to learn the correct connections. To fix this, they introduce a new method called Causality-Guided Semantic Decoupling and Classification (CDC). CDC separates different meanings within the data, allowing the model to focus on what truly matters for each task. Experiments across different datasets confirm that CDC consistently improves the model’s accuracy, especially for the challenging task of classifying new or unseen data.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on vision-language models because it identifies and addresses a critical misalignment issue hindering their effective adaptation to specific tasks. By introducing the Causality-Guided Semantic Decoupling and Classification (CDC) method, the research provides a novel approach to enhance model generalization and addresses the limitations of existing methods. The findings open new avenues for improving the performance of vision-language models, particularly in scenarios with limited data for prompt tuning. This work offers valuable insights for researchers aiming to build more robust and adaptable vision-language models that perform well on diverse downstream tasks.
Visual Insights#
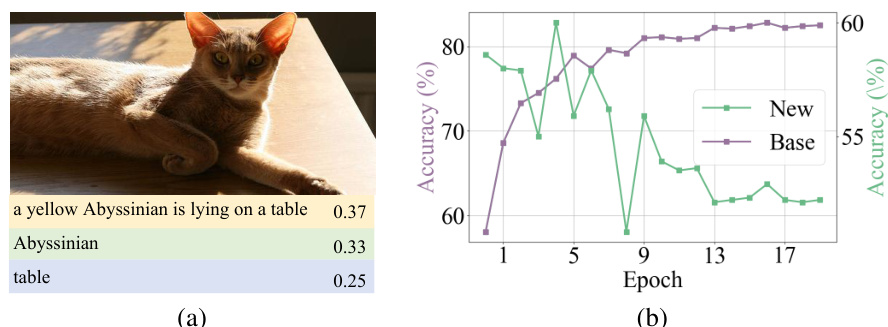
Figure 1(a) shows the cosine similarity between an image and different text descriptions in the embedding space of CLIP. It illustrates the task misalignment issue in CLIP. Figure 1(b) displays the accuracy trends of base and new classes during training epochs on the DTD dataset and shows the data misalignment in CLIP. The figure indicates that while the accuracy for base classes increases with more epochs, the accuracy for new classes decreases, illustrating the overfitting problem due to data misalignment.
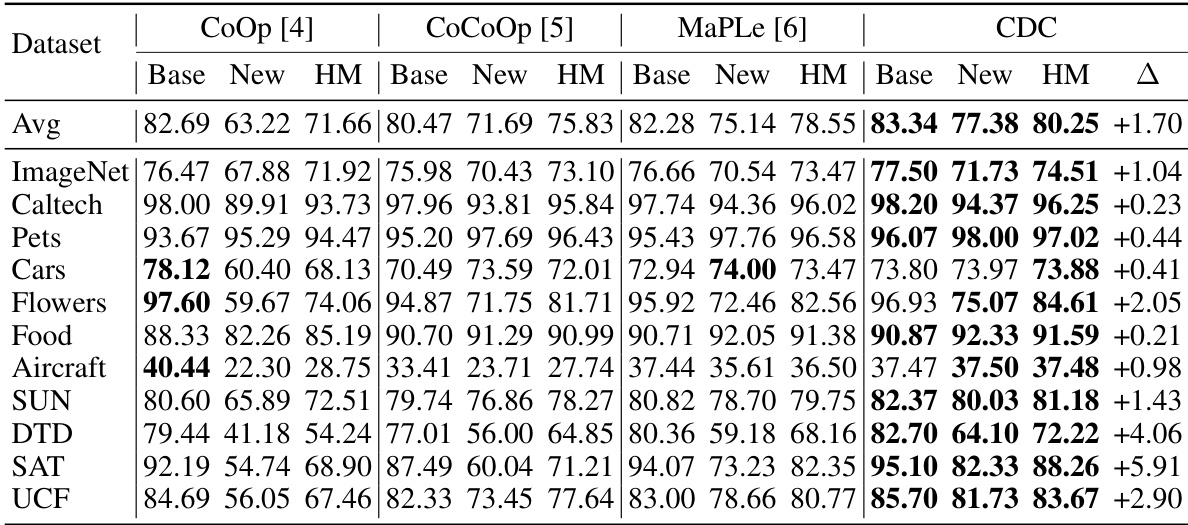
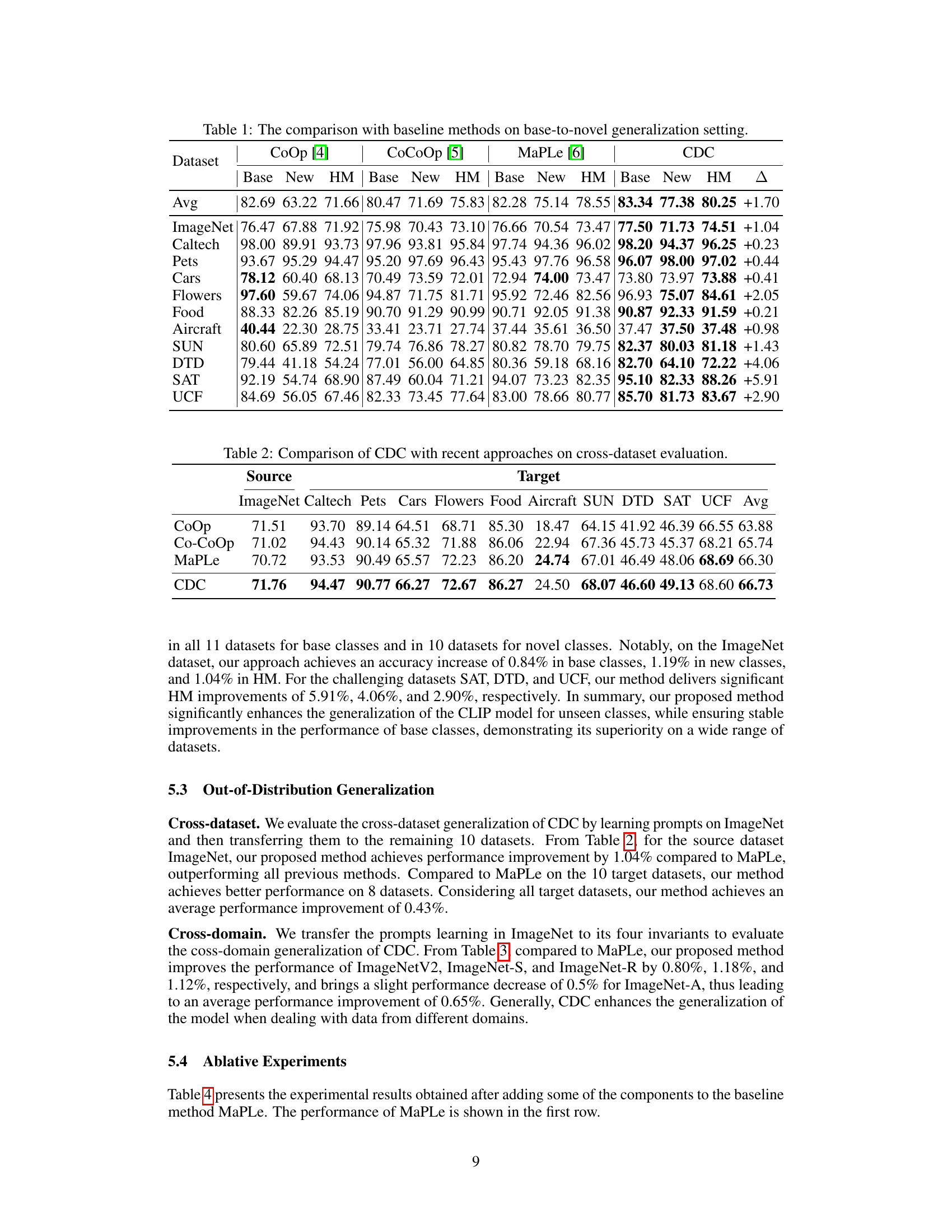
This table compares the performance of the proposed CDC method against three existing methods (CoOp, CoCoOp, and MaPLe) on eleven datasets in a base-to-novel generalization setting. For each dataset, the table shows the accuracy of the models on base classes (classes seen during training), novel classes (unseen classes), and the harmonic mean (HM) of the two accuracies. The final column (Δ) shows the improvement in HM achieved by CDC compared to the best performing baseline method. The average improvement across all datasets is also presented.
In-depth insights#
CLIP Misalignment#
The paper delves into the issue of CLIP misalignment, specifically focusing on the challenges encountered when adapting CLIP (Contrastive Language–Image Pre-training) for downstream tasks. It identifies a two-level misalignment: task misalignment (discrepancy between pre-training and task objectives) and data misalignment (inconsistency between training and testing data). While soft prompt tuning addresses task misalignment, data misalignment remains problematic, leading to overfitting on base classes and hindering generalization to new classes. The core contribution is the development of a Causal-Guided Semantic Decoupling and Classification (CDC) model, using structural causal modeling to isolate and mitigate the impact of task-irrelevant knowledge, improving CLIP’s performance across multiple datasets and tasks. The key insight lies in the proposed decoupling of semantics through diverse prompt templates, enabling more robust classification by focusing on relevant information and accounting for uncertainty using Dempster-Shafer evidence theory. Limitations discussed include computational costs associated with multiple template processing, though the authors demonstrate a marked improvement in downstream task performance despite these challenges.
Causal Model SCM#
The authors propose a Structural Causal Model (SCM) to analyze the misalignment issues in Vision-Language Model adaptation. This SCM is crucial because it moves beyond simple correlation analysis to explore causal relationships between variables such as pre-training data, generative factors (both task-relevant and irrelevant), image features, and model predictions. By visualizing these relationships in a causal graph, the SCM helps pinpoint how task-irrelevant knowledge interferes with accurate prediction, particularly impacting the model’s generalization ability to new classes. This causal understanding is key to developing their proposed Causality-Guided Semantic Decoupling and Classification (CDC) method, which targets the mitigation of confounding effects, leading to improved model performance in downstream tasks. The SCM thus serves as both a diagnostic tool for identifying the root cause of misalignment and a foundational framework for designing a more effective adaptation strategy.
CDC Method#
The core of the proposed approach is the CDC (Causality-Guided Semantic Decoupling and Classification) method, designed to address misalignment issues in Vision-Language models. CDC cleverly uses a Structural Causal Model (SCM) to dissect the causal relationships between images, task-relevant and -irrelevant semantics, and predicted labels. This framework reveals how task-irrelevant knowledge interferes with accurate predictions. The method tackles this interference using a two-pronged strategy: VSD (Visual-Language Dual Semantic Decoupling) and DSTC (Decoupled Semantic Trusted Classification). VSD introduces multiple prompt templates, each aiming to capture distinct semantic aspects, effectively decoupling task-relevant and -irrelevant information. DSTC then independently classifies based on each decoupled semantic, leveraging Dempster-Shafer theory to manage the uncertainty of these individual classifications. The final prediction is a result of fusing these individual classifications, creating a more robust and accurate result. CDC’s strength lies in its explicit handling of causality and uncertainty, leading to improved generalization performance, especially on new or unseen classes.
Generalization#
The concept of generalization is central to evaluating the success of any machine learning model, and in the context of vision-language models (VLMs), it refers to the model’s ability to perform well on unseen data or tasks. Strong generalization is crucial for real-world applicability, as models are rarely deployed on the exact same data they were trained on. The paper addresses generalization from two key angles: task generalization (adapting to new downstream tasks) and data generalization (handling novel image-text distributions unseen during pre-training). The authors highlight the misalignment between the pre-training objective and downstream tasks, as well as the data mismatch between the training and testing sets as critical impediments to good generalization. Their proposed Causal-Guided Semantic Decoupling and Classification (CDC) method tackles these issues by decoupling task-relevant from task-irrelevant information, thus improving the model’s ability to focus on what truly matters for the given task. The experimental results demonstrate improved generalization capabilities, particularly in handling new classes and out-of-distribution data, suggesting that CDC’s causal perspective offers a valuable and effective approach to improve generalization in VLMs.
Future Work#
Future research directions stemming from this work could explore more sophisticated causal inference methods beyond the front-door adjustment, potentially incorporating techniques like instrumental variables or mediation analysis to unravel the complex interplay of generative factors more effectively. Investigating alternative decoupling strategies for semantics within the visual and linguistic modalities would be valuable. This could involve exploring different architectures or training objectives tailored to capturing nuanced semantic distinctions. Extending CDC to a wider range of downstream tasks and vision-language models beyond CLIP would demonstrate its robustness and general applicability. The computational cost of CDC is a limitation, so research into more efficient implementations or approximation techniques is crucial for practical deployment. Finally, exploring how CDC can be integrated with or enhance other adaptation methods, such as parameter-efficient fine-tuning, would be a fruitful area of investigation.
More visual insights#
More on figures

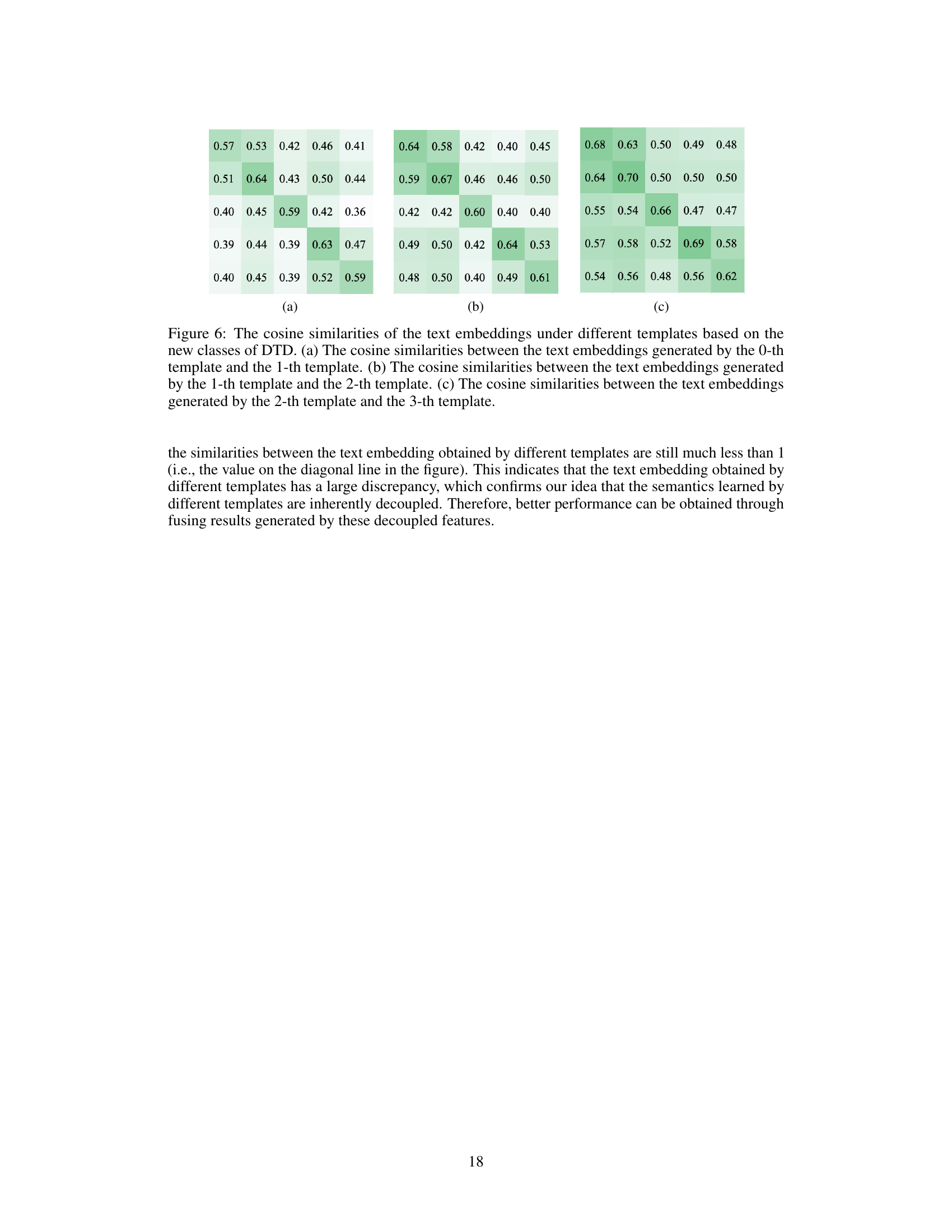
This figure shows three Structural Causal Models (SCMs) illustrating the causal relationships among variables during the pre-training and adaptation processes of CLIP. (a) shows the full model with observed variables X (image space), Y (true labels), Gr (task-relevant generative factors), and Gi (task-irrelevant generative factors), and unobserved variable D (pre-training data). (b) simplifies the model by focusing on the observed variables and highlighting the confounding effect of task-irrelevant generative factors Gi on the relationship between X and Y (predicted labels). (c) illustrates the proposed solution using the front-door adjustment. Here, S (task-relevant semantics) acts as an intermediate variable between X and Y, mitigating the influence of Gi.

This figure illustrates the architecture of the Causality-Guided Semantic Decoupling and Classification (CDC) framework. Multiple learnable text prompt templates (t1, t2, …, tM) are used, each with learnable tokens (p1, p2, …, pd), to decouple different semantic aspects of the input image. A hand-crafted prompt (t0) is also included. The image encoder and text encoder are frozen, and only the prompt tokens are trained. Different image augmentations are applied to each template. The outputs from each template are then fused to produce a final classification result. The losses used during training are shown: Lt-ce (trusted cross-entropy loss), Lde (diversity loss), and Lcon (consistency loss).

This figure demonstrates the two types of misalignment in CLIP adaptation. (a) shows task misalignment: CLIP struggles to focus on specific task-relevant semantics within image-text pairs, hindering accurate classification. (b) shows data misalignment: overfitting to training data (base classes) leads to poor generalization on unseen data (new classes), as observed in the DTD dataset’s accuracy trend across epochs.

This figure demonstrates two types of misalignment issues in CLIP model adaptation. (a) shows ’task misalignment.’ The cosine similarity between an image and its complete description is high, but similarity to individual components of that description is low, illustrating the challenge of selecting task-relevant features. (b) shows ‘data misalignment.’ It plots accuracy over epochs for base (seen in training) and new (unseen) classes on the DTD dataset, revealing overfitting to base classes and reduced performance on new classes.
More on tables
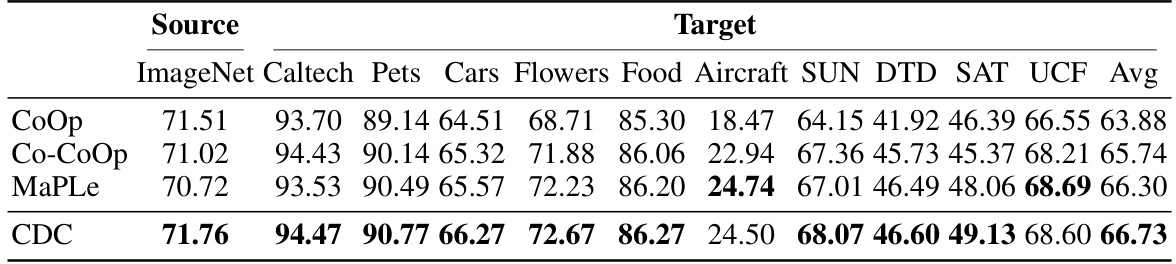
This table compares the performance of CDC against three other methods (CoOp, Co-CoOp, and MaPLe) on a cross-dataset evaluation. The source dataset is ImageNet, and the results show the average accuracy across ten target datasets (Caltech, Pets, Cars, Flowers, Food, Aircraft, SUN, DTD, SAT, and UCF). The table highlights CDC’s improved performance over other methods, particularly on challenging datasets, demonstrating its stronger generalization capability.
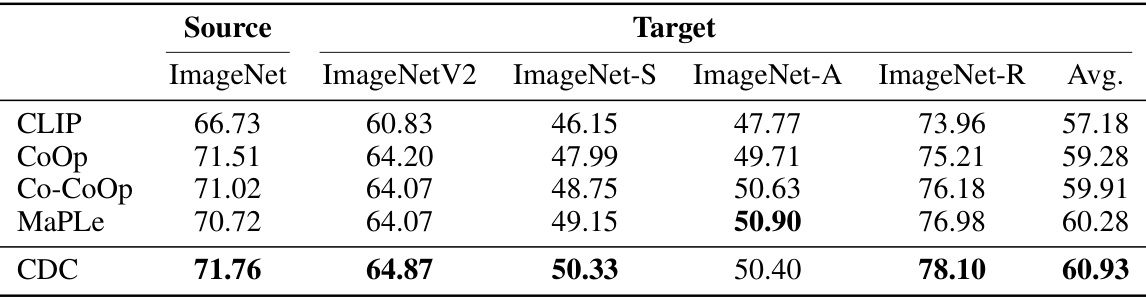
This table presents the results of the cross-domain generalization experiments. The source dataset is ImageNet, and the target datasets are ImageNetV2, ImageNet-S, ImageNet-A, and ImageNet-R, representing variations in image quality, naturalness, and context. The table compares the performance of various methods, including CLIP, CoOp, Co-CoOp, MaPLe, and the proposed CDC method, showcasing the average accuracy across the four target datasets. CDC demonstrates improved performance.

This table presents the ablation study results for the proposed CDC method. It shows the impact of different components (multiple templates, DSTC, and VSD) on the performance of the model in the base-to-new generalization setting. The results are measured by the accuracy on base and new classes, along with their harmonic mean (HM). It demonstrates the individual and combined effects of each component on the model’s ability to generalize.

This table shows the impact of the number of templates (M) on the performance of the model. As the number of templates increases, the model’s performance (measured in Base, New, and HM accuracy) improves, but the computational cost (Params and FPS) also increases significantly. This demonstrates a trade-off between model performance and computational resources.
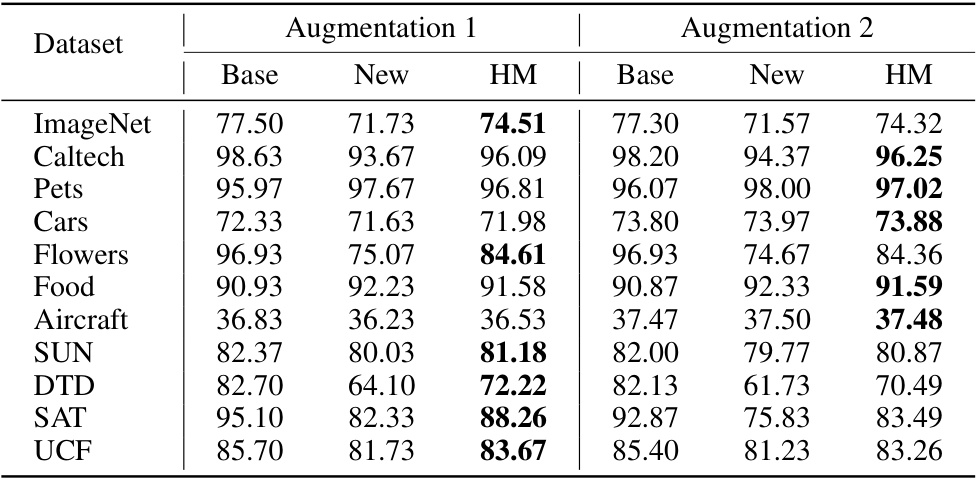
This table compares the performance of the model using two different sets of augmentation methods applied to images during training. Augmentation 1 uses a combination of common augmentation techniques, while Augmentation 2 adds an extra random crop operation to each augmentation set. The results show that using different sets of augmentation methods can impact the performance and the best augmentation strategy may vary for different datasets.

This table compares the classification performance of the proposed CDC method against individual semantic sets (S1-S4) across eleven different datasets. Each column S1 to S4 represents the performance obtained from a single template, representing decoupled semantic sets extracted using the Visual-Language Dual Semantic Decoupling (VSD) method. The CDC column shows the final classification results obtained by combining the predictions from all four semantic sets using the Decoupled Semantic Trusted Classification (DSTC) method. The table demonstrates that combining multiple semantic sets through DSTC consistently improves the classification performance compared to relying on any single semantic set.

This table presents the performance of the model with different augmentation methods in the base-to-new generalization setting. It compares two sets of augmentations, Augmentation 1 and Augmentation 2, across multiple datasets (ImageNet, Caltech, Pets, Cars, Flowers, Food, Aircraft, SUN, DTD, SAT, UCF). For each dataset and augmentation method, it shows the accuracy on base classes, new classes, and their harmonic mean (HM). The results highlight how different augmentation strategies impact the model’s ability to generalize to new classes.
Full paper#