↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Acquiring training data is critical for machine learning, but current methods often assume centralized access. This is problematic as data owners are increasingly resistant to indiscriminate data collection, leading to the development of data marketplaces. However, choosing the most valuable data points from a seller poses a significant challenge for buyers in such a market.
This research introduces DAVED (Data Acquisition via Experimental Design), a novel federated approach inspired by linear experimental design. DAVED directly optimizes data selection for test set prediction without needing labeled validation data. The method is shown to be highly scalable, computationally efficient, and cost-effective. Importantly, it avoids the overfitting problems associated with validation-based approaches and thus better addresses the unique challenges posed by decentralized data marketplaces.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in machine learning and data markets. It offers a novel, scalable, and federated approach to data acquisition, eliminating the need for labeled validation data and directly optimizing for test set prediction. This significantly advances the field by addressing the limitations of existing data valuation methods and opens new avenues for research into decentralized data marketplaces and efficient data acquisition techniques.
Visual Insights#
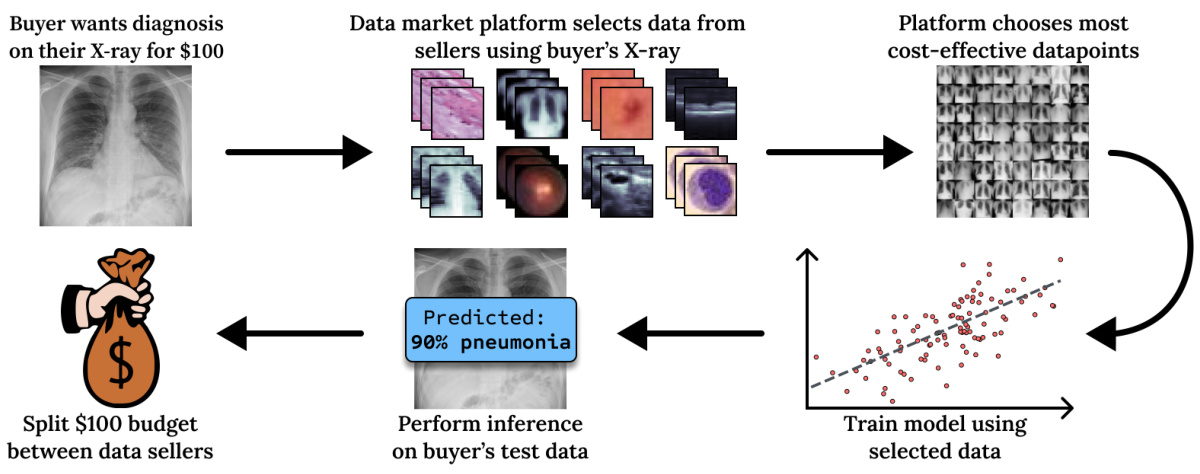
This figure illustrates the data marketplace approach used in the paper. A buyer submits a test query (e.g., an X-ray) and a budget. The platform, using the buyer’s query, selects the most relevant training data from various sellers. A model is then trained on this selected data, and the prediction is returned to the buyer. The key point is that DAVED directly optimizes for test performance without needing labeled validation data, making it cost-effective and suitable for decentralized markets.
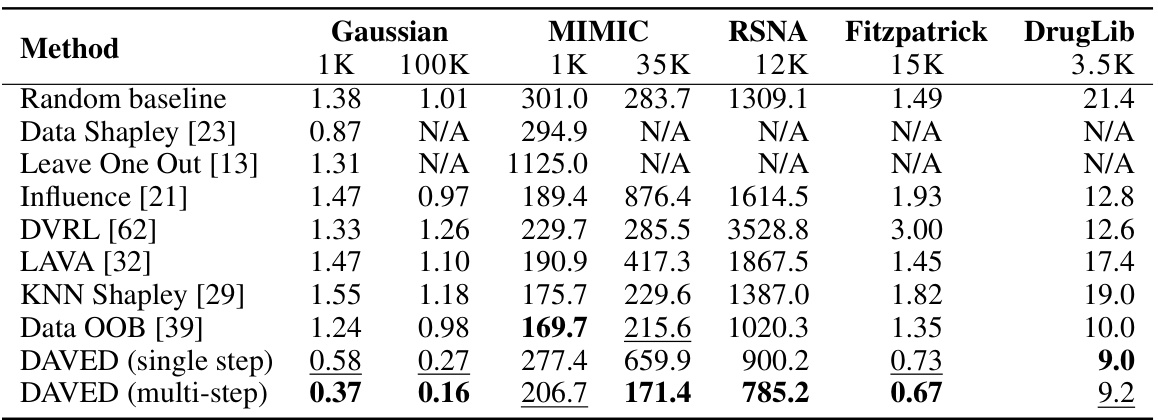
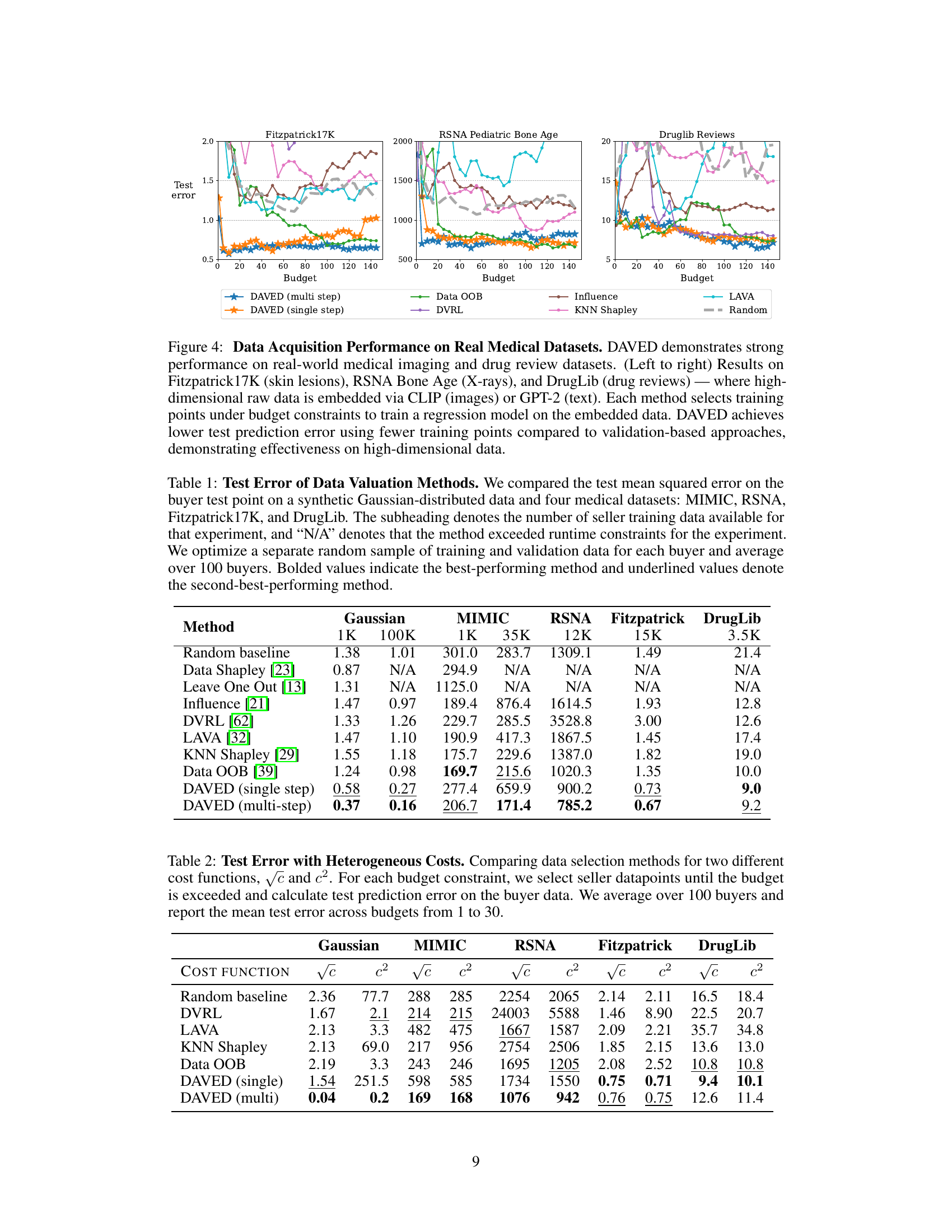
This table presents a comparison of the mean squared error achieved by different data valuation methods across various datasets (synthetic Gaussian, MIMIC, RSNA, Fitzpatrick, DrugLib) and varying amounts of seller training data (1k, 100k, 1k, 35k, 12k, 15k, 3.5k, respectively). The results are averaged over 100 buyer test points. The table highlights the relative performance of various methods, notably showing that DAVED consistently achieves the lowest mean squared error.
In-depth insights#
Federated Data Val.#
Federated Data Valuation presents a compelling approach to address the challenges of data acquisition in decentralized environments. The core idea is to leverage the power of federated learning, enabling data valuation and selection without requiring centralized access to sensitive datasets. This approach holds significant promise for protecting data privacy, a crucial consideration in various sectors like healthcare. By employing techniques like linear experimental design, the method directly optimizes the utility of data for downstream prediction tasks. This contrasts sharply with traditional methods that often rely on labeled validation datasets, introducing additional complexities and potential for overfitting. A key advantage lies in the direct estimation of data benefits, facilitating cost-effective data acquisition while remaining compatible with a decentralized market setting. While the paper addresses several crucial points, further exploration into the robustness of the method under various data distributions and computational efficiency aspects remains essential. The scalability and applicability across different domains and modalities should also be thoroughly investigated.
Experimental Design#
The core idea behind the experimental design in this research is to optimize data acquisition for machine learning models in a decentralized marketplace setting. Instead of relying on traditional validation-based methods, which are shown to overfit, the authors propose a federated approach inspired by linear experimental design. This approach directly optimizes the selection of training data for prediction on a test set, without requiring labeled validation data. The key is to estimate the benefit of acquiring each data point, making it compatible with the decentralized nature of data markets. The experimental design thus centers around efficiently selecting cost-effective data points to minimize prediction error, aligning closely with the buyer’s budget constraints in the marketplace scenario. The efficacy of this approach is demonstrated on several datasets, showcasing its adaptability to high dimensional data and the advantages over standard data valuation methods.
Validation-Free Method#
The concept of a ‘Validation-Free Method’ in data acquisition for machine learning presents a significant advancement, especially within the context of decentralized data marketplaces. Traditional data valuation techniques heavily rely on labeled validation datasets to estimate the value of training datapoints, which is often impractical, expensive, or impossible to obtain, particularly in scenarios involving sensitive or proprietary data. A validation-free approach directly tackles this limitation by optimizing data selection for prediction accuracy on unseen test data without the need for a separate validation set. This offers several key advantages: improved scalability, enhanced privacy protection (as sensitive data need not be shared), and increased applicability to data-scarce domains. By eliminating the reliance on validation data, the method becomes more robust and less susceptible to overfitting. However, validation-free methods might still necessitate assumptions about data distributions or model behavior which could limit their generalizability. The effectiveness of such an approach is crucial and requires careful analysis, particularly to determine how well it performs against traditional validation-based approaches, across different datasets and model complexities.
Scalable Data Acq.#
Scalable data acquisition in machine learning is crucial for leveraging large datasets effectively. The challenges lie in efficiently handling massive amounts of data, especially in decentralized settings. Federated learning techniques are essential, enabling training models across distributed datasets without directly accessing individual data points. Experimental design principles help to optimize the selection of data points, focusing on maximizing the value for specific prediction tasks while minimizing cost and preserving privacy. Algorithms should minimize storage needs and computational expense; this necessitates clever data representation and efficient optimization techniques such as gradient-based methods or approximation algorithms. Balancing cost and quality of data is another key challenge in such frameworks, demanding efficient selection strategies that consider varying prices and data quality from multiple sellers. A truly scalable solution must address these issues by incorporating efficient data filtering, parallel processing, and adaptive sampling techniques to maximize utility while complying with budget and privacy constraints.
Future Work#
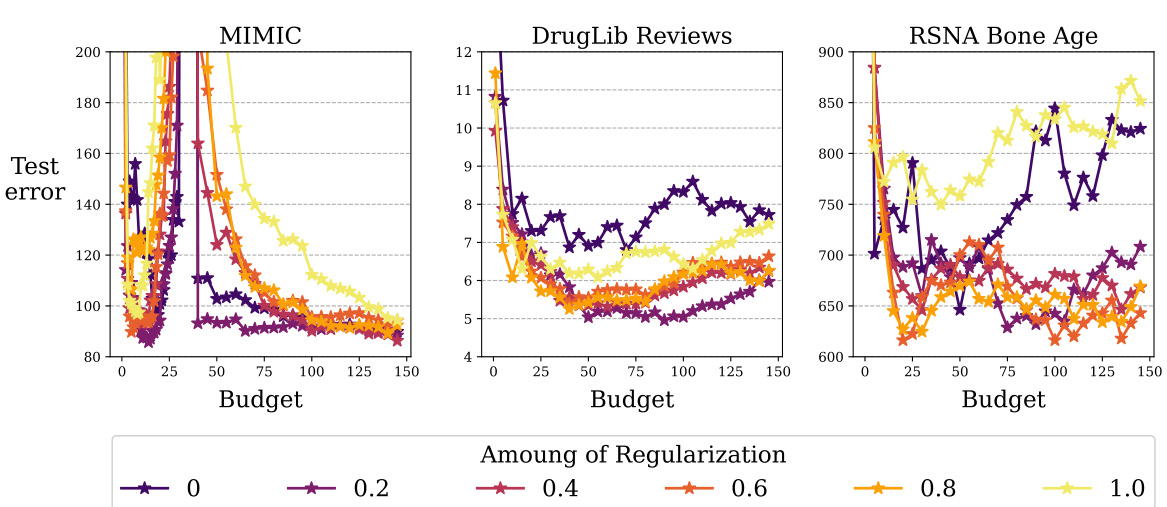
The paper’s ‘Future Work’ section would greatly benefit from exploring several key areas. Addressing the limitations of the linear approximation used in the core methodology is crucial for broader applicability. Investigating more sophisticated non-linear approaches, perhaps incorporating neural tangent kernels more effectively or exploring other model-agnostic techniques, would strengthen the approach’s robustness and scalability. Incorporating differential privacy mechanisms into the federated data acquisition process is essential for enhancing privacy guarantees, aligning with increasing societal concerns about data protection. The study could also benefit from a deeper investigation into theoretical guarantees beyond the provided minimax lower bound, focusing on tighter convergence rates or improved approximation bounds for the experimental design process. Finally, expanding the empirical evaluation to include a more diverse range of datasets and real-world scenarios across different application domains (beyond healthcare and medical imaging) would greatly increase the study’s impact and significance. These enhancements would lead to a more robust, principled, and impactful approach to decentralized data acquisition.
More visual insights#
More on figures
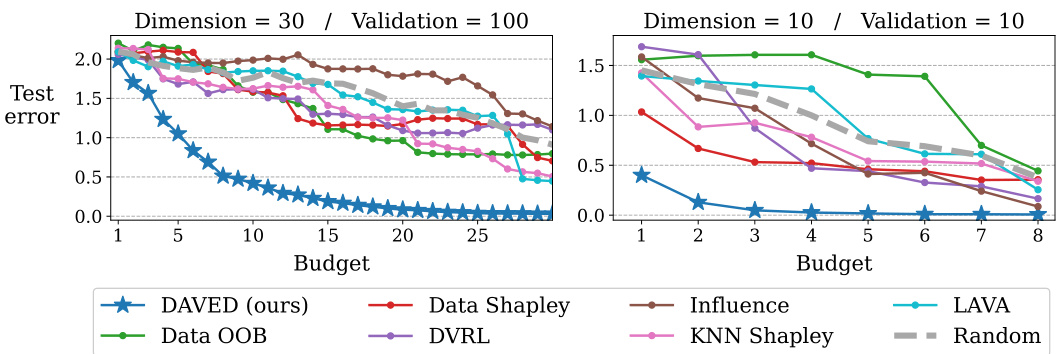
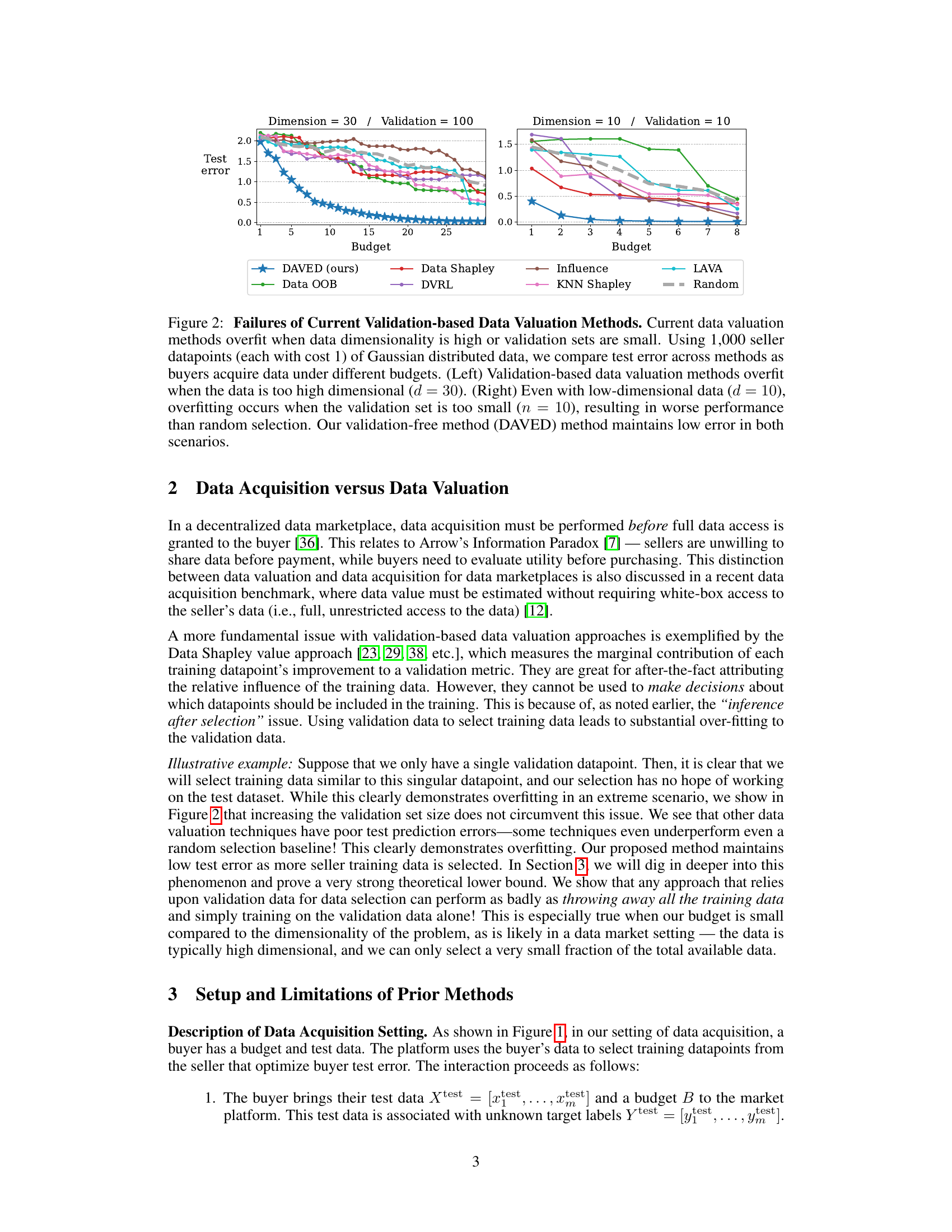
This figure compares the test error of several data valuation methods against the proposed DAVED method under different budget constraints and data dimensionality. The results show that validation-based methods suffer from overfitting when the data dimension is high or the validation set is small, resulting in higher test error compared to random selection. In contrast, DAVED consistently maintains a low test error regardless of the data dimensionality or validation set size.
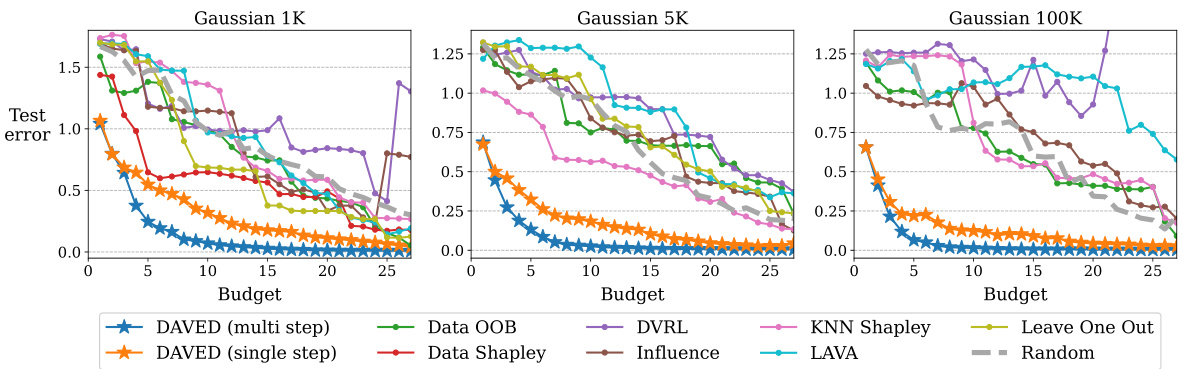
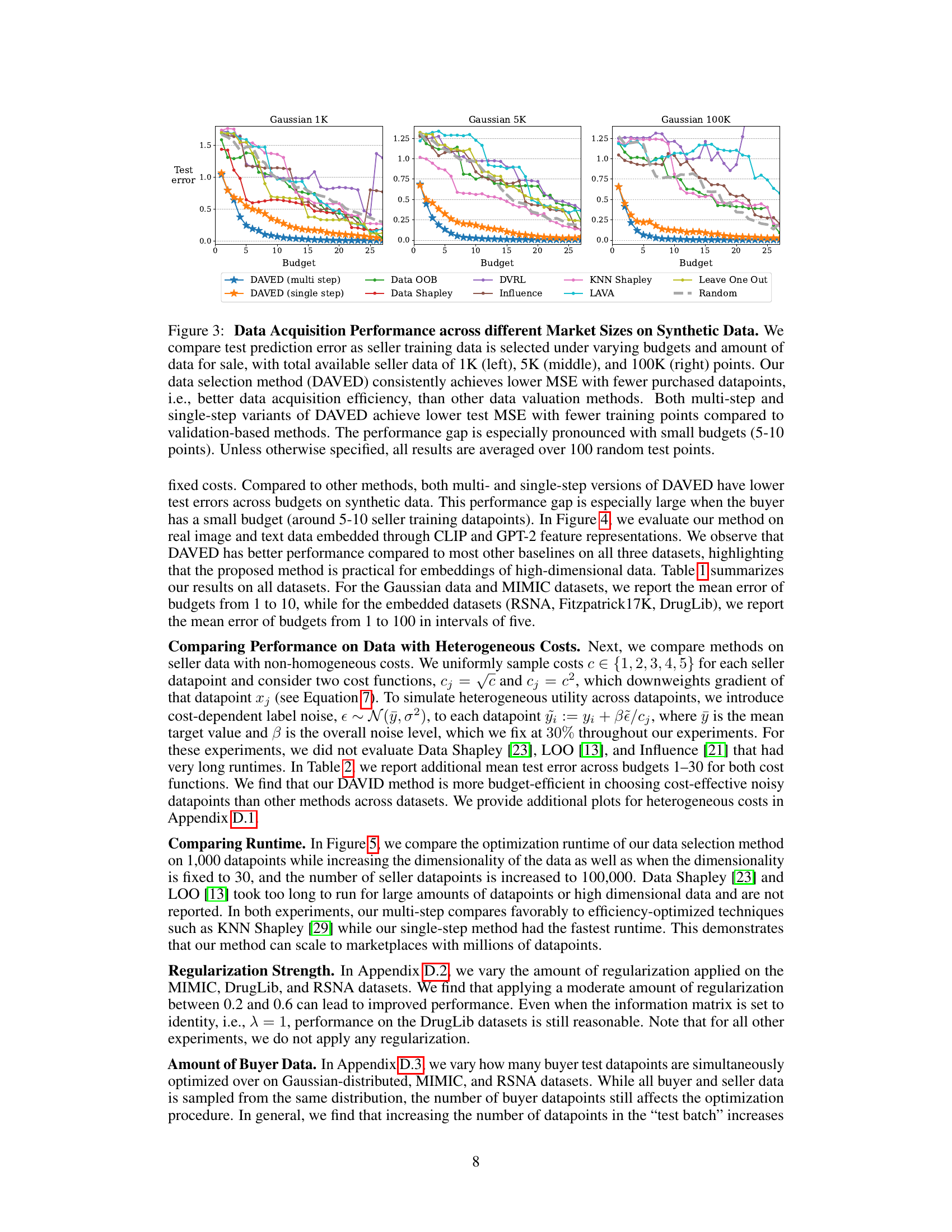
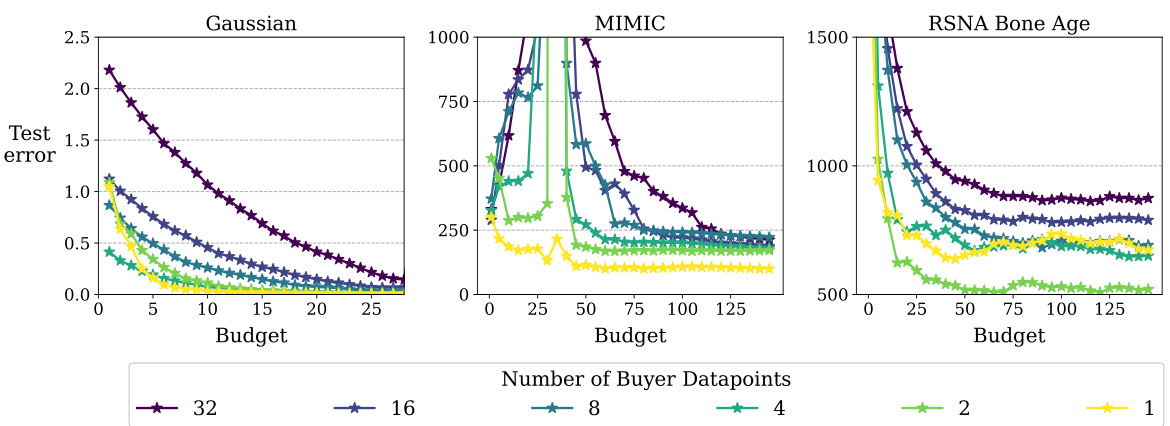
This figure compares the test prediction error of DAVED and other data valuation methods on synthetic data with varying amounts of seller training data and budgets. DAVED consistently outperforms other methods, particularly with smaller budgets, showing its effectiveness in efficiently acquiring data.
This figure compares the performance of DAVED (multi-step and single-step) and other data valuation methods (Data OOB, Data Shapley, DVRL, Influence, KNN Shapley, LAVA, Leave One Out, Random) in terms of test prediction error on synthetic data with varying sizes (1K, 5K, 100K datapoints) and budgets. DAVED consistently outperforms other methods, demonstrating its effectiveness in acquiring data efficiently and achieving lower prediction error.

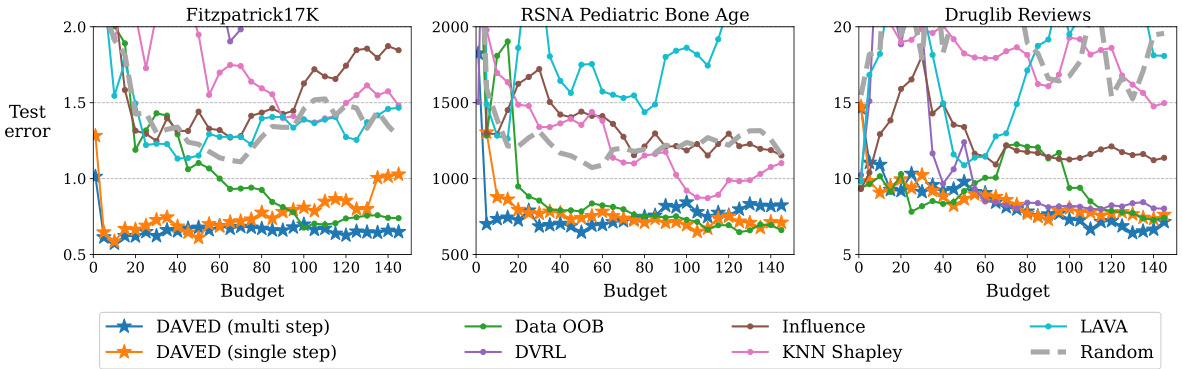
This figure compares the computational efficiency of DAVED with other data valuation methods. The left panel shows runtime scaling with data dimensionality, while the right panel shows runtime scaling with the amount of seller data. DAVED’s single-step variant is faster than other methods. DAVED’s multi-step variant is efficient and achieves better performance. The O(d) communication complexity makes DAVED suitable for decentralized settings.
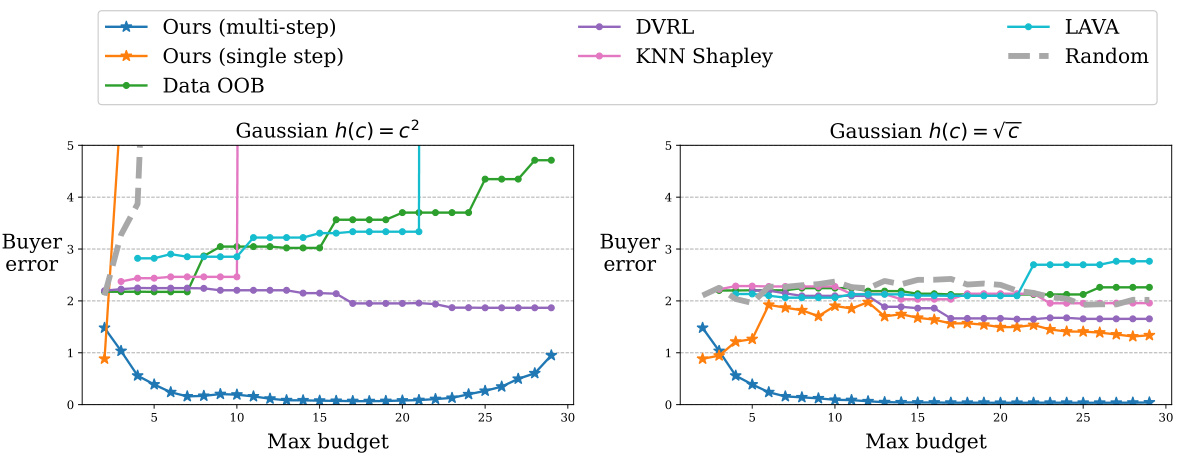
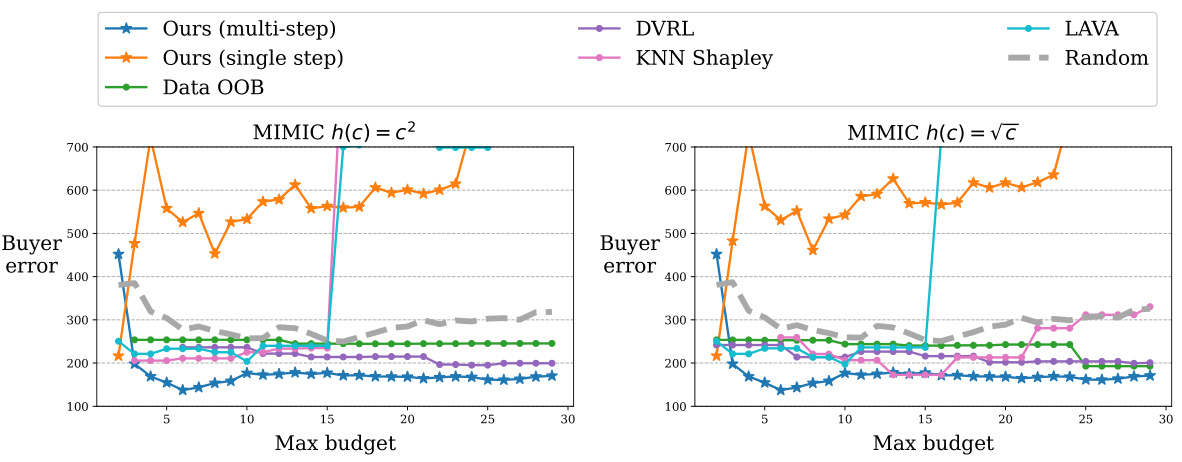
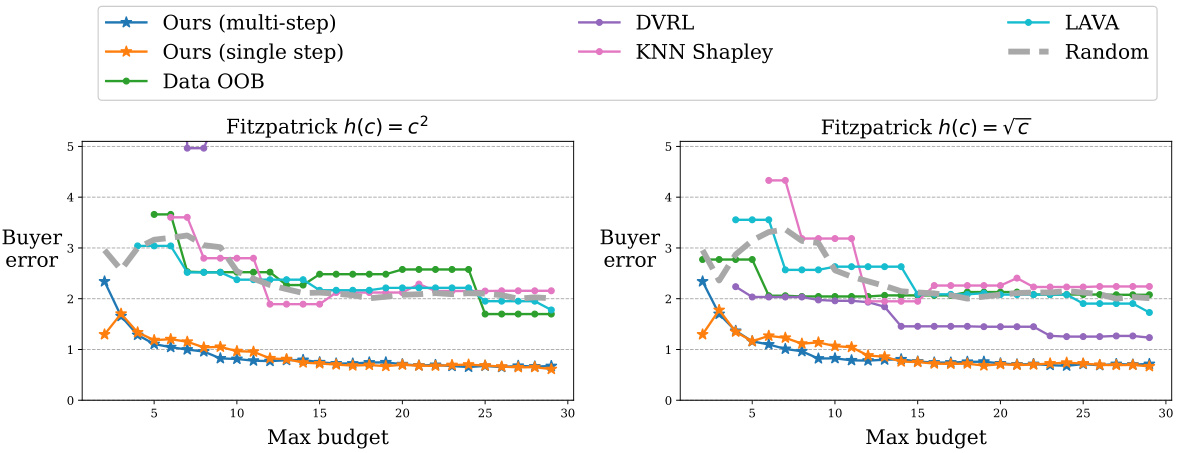
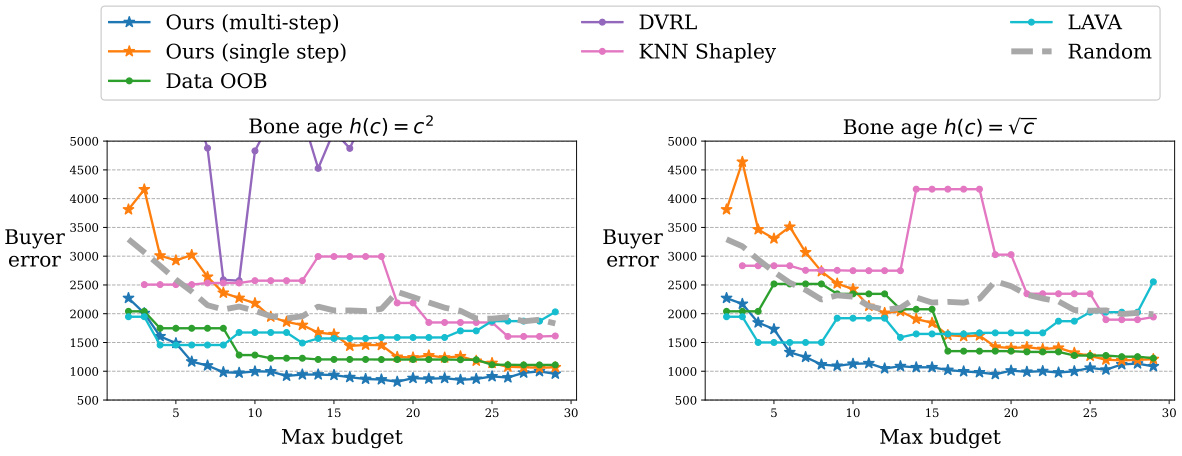
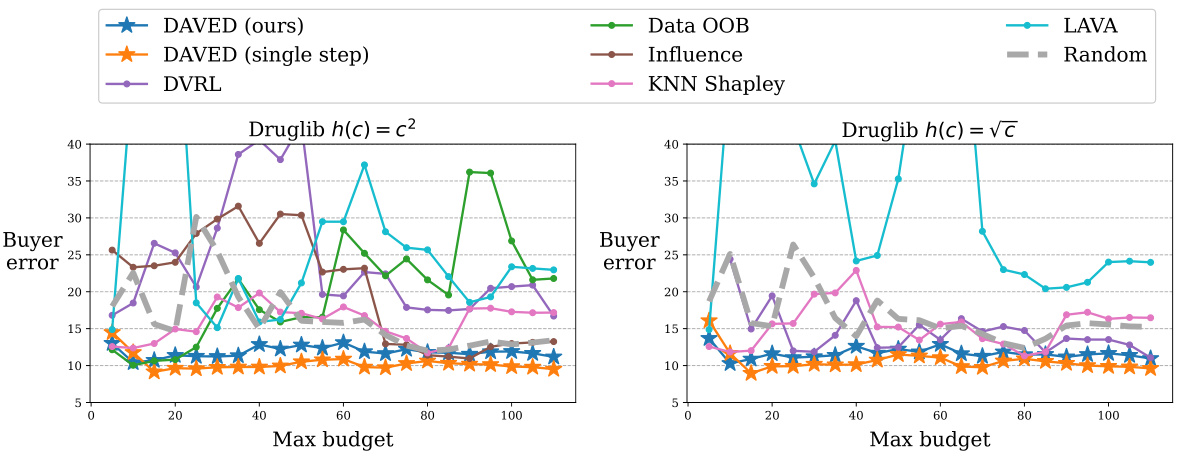
This figure compares the performance of DAVED and other data valuation methods on synthetic data with heterogeneous costs. The costs are randomly sampled and then transformed using two different cost functions (√c and c²). Label noise is inversely proportional to the cost, simulating that higher-cost data is of higher quality. The results show that DAVED consistently outperforms other methods across various budget levels, maintaining a low mean squared error (MSE).
This figure compares the test prediction error of DAVED and other data valuation methods on synthetic datasets with varying sizes (1K, 5K, and 100K data points). The results show that DAVED consistently achieves lower mean squared error (MSE) with fewer data points purchased, demonstrating better data acquisition efficiency. Both the multi-step and single-step versions of DAVED outperform other methods, especially when the budget is small (5-10 data points).
The figure compares the test prediction error of DAVED and other data valuation methods on synthetic data with varying amounts of seller training data and budgets. DAVED consistently outperforms other methods, especially with small budgets.
This figure compares the test prediction error of DAVED and other data valuation methods on synthetic datasets of varying sizes (1K, 5K, and 100K data points). It shows how DAVED consistently achieves lower mean squared error (MSE) with fewer purchased data points, demonstrating its superior data acquisition efficiency. The benefit of DAVED is more pronounced when the budget is limited. Results are averaged over 100 random test points.
This figure compares the performance of DAVED and other data valuation methods on synthetic data with varying amounts of seller data and budgets. It shows that DAVED consistently achieves lower mean squared error (MSE) with fewer data points purchased, demonstrating better data acquisition efficiency. The performance difference is particularly noticeable with smaller budgets.
The figure compares the test error of various data valuation methods against DAVED (the proposed method) under different budget constraints. It showcases how validation-based methods suffer from overfitting when the data dimensionality is high or the validation set is small, leading to poor performance compared to random selection. In contrast, DAVED maintains low error even in these challenging scenarios.
This figure compares the performance of DAVED and several other data valuation methods on synthetic data with varying amounts of data (1K, 5K, and 100K points) and budgets. The results show that DAVED consistently achieves lower mean squared error (MSE) with fewer data points purchased compared to other methods, highlighting its data acquisition efficiency. The performance difference is more pronounced when the budget is limited.
The figure compares the test prediction error of DAVED and other data valuation methods under various budgets and amounts of seller data for synthetic Gaussian data. It shows that DAVED consistently achieves lower mean squared error (MSE) with fewer purchased data points compared to other methods, especially when the budget is small. Both the single-step and multi-step variants of DAVED perform better.

The figure compares the performance of linear probing and full fine-tuning for BERT models on DrugLib reviews using data selected by DAVED and random selection. The results show that linear probing performs similarly to fine-tuning, validating the use of kernelized linear regression as a proxy for the training dynamics and supporting the choice of a linear modeling approach for data selection. Error bars represent the average test error over 100 random trials with different test reviews.
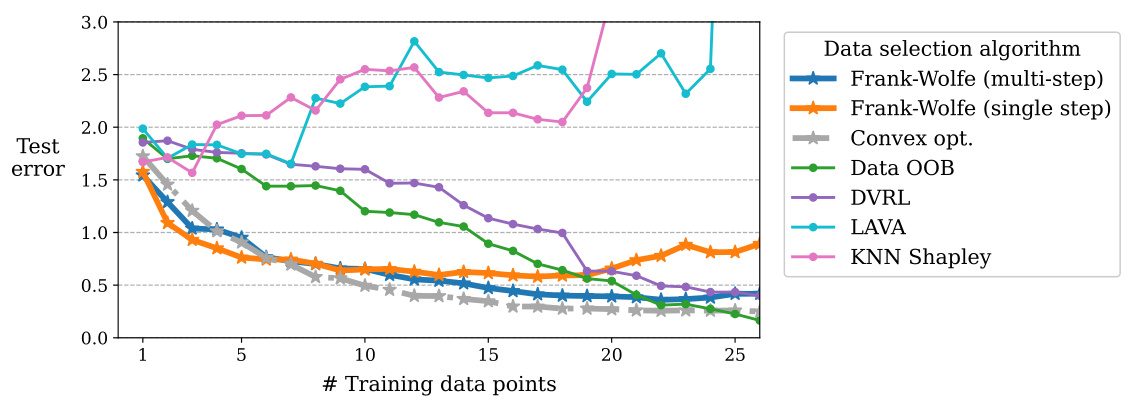
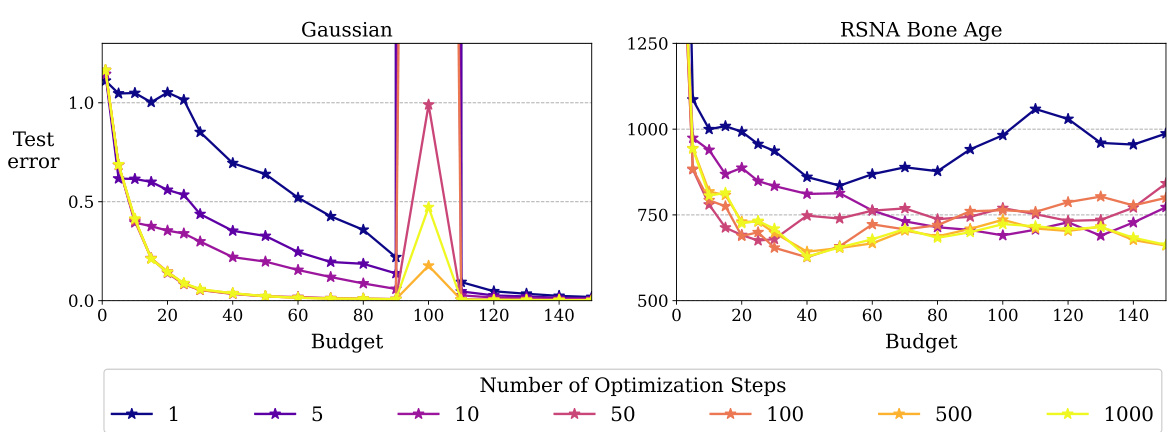
This figure compares the performance of DAVED’s iterative optimization method against a convex optimization solver. Both methods are applied to a data selection problem using 1000 data points sampled from a 30-dimensional Gaussian distribution. The results show that DAVED’s iterative approach achieves accuracy comparable to the convex solver, but with significantly faster optimization times. The comparison is done for both the multi-step and single-step variants of DAVED.
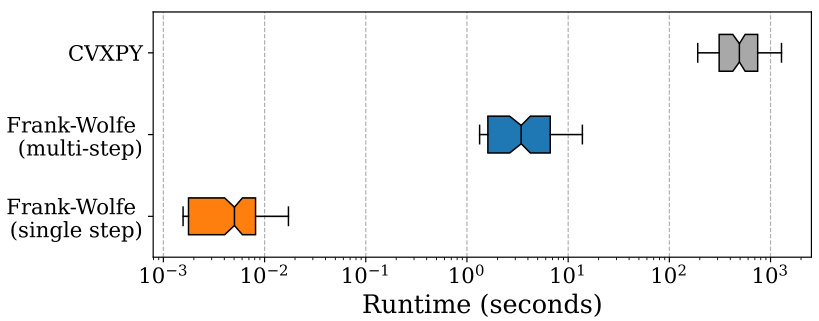
This figure compares the computational efficiency of DAVED with other data valuation methods. The left panel shows how runtime scales with increasing data dimensionality (number of features), while the right panel demonstrates runtime scaling with increasing amounts of seller data. DAVED, particularly its single-step version, shows significantly faster runtimes compared to other methods, making it suitable for decentralized settings with limited communication.
More on tables
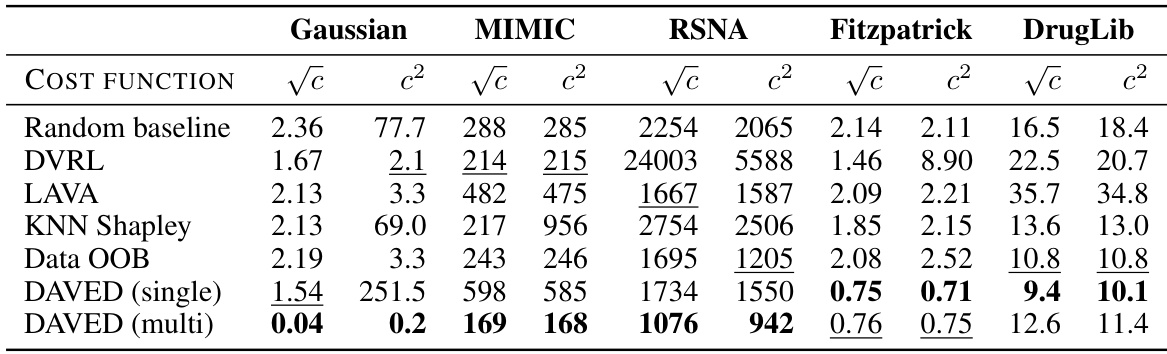
This table presents a comparison of the mean squared error (MSE) achieved by various data valuation methods on five datasets: synthetic Gaussian data and four real-world medical datasets (MIMIC, RSNA, Fitzpatrick17K, DrugLib). The table shows the average MSE over 100 buyer test points for different budget sizes. The results highlight the performance of DAVED (both single-step and multi-step variants) in comparison to existing methods, demonstrating its effectiveness in various settings.

This table compares the test mean squared error of several data valuation methods on various datasets, including synthetic Gaussian data and real medical datasets such as MIMIC-III, RSNA Pediatric Bone Age, Fitzpatrick17K, and DrugLib. It shows the performance of different methods under varying amounts of seller training data and highlights the best-performing method for each scenario.

This table compares the performance of different data valuation methods on various datasets in terms of the mean squared error (MSE). The datasets include a synthetic Gaussian dataset and four medical datasets (MIMIC, RSNA, Fitzpatrick17K, and DrugLib). The table reports the MSE for different budget sizes, highlighting the best-performing methods and illustrating the impact of data scarcity.

This table compares the performance of different data valuation methods (including DAVED) on various datasets (synthetic and medical). It reports the mean squared error (MSE) for different budget sizes. The table highlights the superior performance of DAVED across different datasets and budget sizes.
Full paper#