↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current LLM unlearning methods face a challenge: effectively removing undesirable data influences while preserving the model’s original functionality. Existing approaches often fail to strike this balance, either insufficiently removing unwanted information or significantly degrading the model’s utility. This necessitates a novel approach to LLM unlearning that can strategically guide the unlearning process, addressing the inherent relationship between model weights and unlearning effectiveness.
The paper proposes WAGLE, a weight attribution-guided LLM unlearning framework, that systematically explores how model weights interact with unlearning processes. By strategically guiding the LLM unlearning across different types of unlearning methods and tasks, WAGLE unveils the interconnections between the ‘influence’ of weights and the ‘influence’ of data, which enables the model to forget and retain information effectively. Experiments demonstrate that WAGLE enhances unlearning performance across multiple unlearning methods and benchmark datasets, offering the first principled method for attributing and pinpointing influential weights in LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language model (LLM) unlearning due to its introduction of a novel weight attribution method that significantly improves unlearning effectiveness while maintaining model utility. This addresses a critical gap in current LLM unlearning techniques, which often struggle with a tradeoff between completely removing unwanted data influences and preserving the model’s original capabilities. The framework introduced, WAGLE, offers a principled approach to attributing weight influence and has been demonstrated across several unlearning tasks and LLM architectures. This work opens new avenues for research into modular LLM unlearning and other applications needing selective data removal.
Visual Insights#
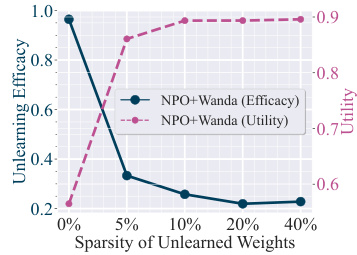
This figure shows the trade-off between unlearning efficacy and model utility when using different levels of weight sparsity in the NPO-based unlearning method. The x-axis represents the percentage of weights updated during the unlearning process (sparsity), achieved through the Wanda pruning method. The y-axis shows two metrics: unlearning efficacy and utility. As sparsity increases (more weights are pruned), unlearning efficacy initially improves but then sharply decreases. Meanwhile, utility shows the opposite trend generally increasing with sparsity, suggesting a trade-off between effectively removing unwanted knowledge and preserving the model’s overall functionality. This highlights the challenge of finding an optimal balance between removing undesirable data and preserving model utility, motivating the need for a more principled approach to weight selection in LLM unlearning, which the paper introduces.
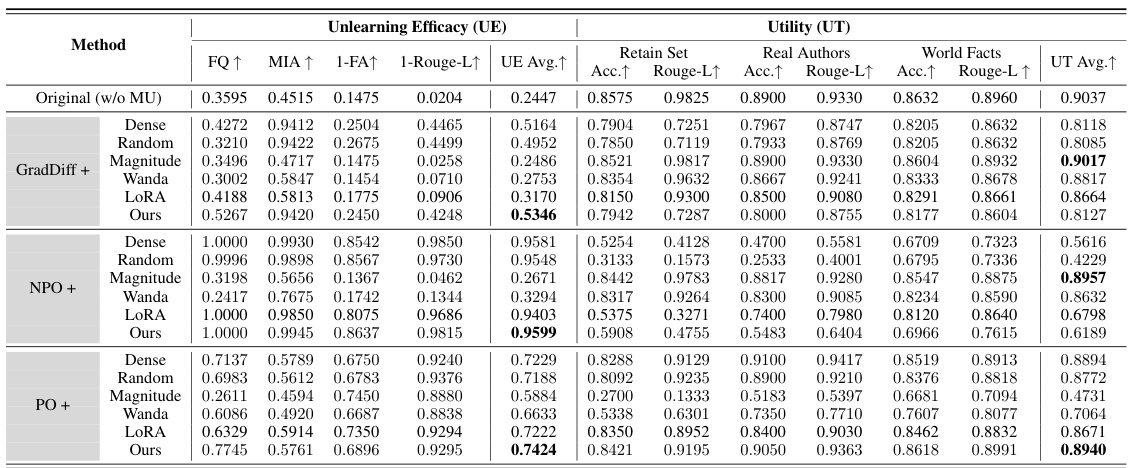
This table presents a comprehensive performance comparison of various LLM unlearning methods on the TOFU dataset using the LLaMA2-7B-chat model. It shows the unlearning efficacy (UE) and utility (UT) for different methods, including baseline techniques and the proposed WAGLE approach. UE is measured using multiple metrics (FQ, MIA, 1-FA, 1-Rouge-L) while UT considers model accuracy and Rouge-L scores on retain sets and subsets related to real authors and world facts. The table highlights the best performing method for each metric and overall average.
In-depth insights#
LLM Unlearning#
LLM unlearning tackles the crucial challenge of removing undesirable data influences from large language models (LLMs) without compromising their overall utility. Existing methods often focus on algorithmic efficiency, but a deeper understanding of the relationship between model weights and unlearning is needed. Weight attribution is key to identifying which weights are most responsible for the unwanted information, allowing for more targeted and effective unlearning. The weight attribution-guided framework is crucial for pinpointing influential weights while ensuring the desired knowledge remains. This approach enhances various unlearning methods and significantly improves unlearning performance across multiple benchmarks. The trade-off between forgetting unwanted data and retaining valuable knowledge is critical, requiring sophisticated techniques for effective and efficient LLM unlearning. Future research should explore weight attribution’s impact on robustness, modularity, and different LLM architectures, moving beyond current algorithmic-centric approaches.
Weight Attribution#
The concept of ‘Weight Attribution’ in the context of large language model (LLM) unlearning is crucial for enhancing the effectiveness and efficiency of the process. It involves systematically identifying and quantifying the influence of individual model weights on the unlearning objective. This moves beyond simpler techniques by directly pinpointing the weights most responsible for undesirable model capabilities, allowing for targeted intervention and a more modular approach to unlearning. By attributing influence to specific weights, rather than relying on broad modifications, the risk of harming useful model knowledge is significantly reduced. A principled method for weight attribution, as explored in the research, often involves a bi-level optimization (BLO) framework, which balances the goal of removing unwanted knowledge with the constraint of preserving the model’s overall functionality. The closed-form solution derived from this framework provides a practical and precise way to identify influential weights, opening up possibilities for efficient and targeted LLM unlearning strategies.
WAGLE Framework#
The WAGLE framework, a weight attribution-guided LLM unlearning approach, offers a novel solution to the challenge of effective and modular unlearning in large language models (LLMs). Instead of focusing solely on algorithmic designs, WAGLE leverages a bi-level optimization (BLO) perspective to attribute influence to individual model weights, identifying those most crucial for removing undesired information. This principled approach contrasts with previous methods lacking weight attribution, offering a more targeted and efficient unlearning process. By strategically guiding the unlearning across various methods and tasks, WAGLE effectively erases unwanted content while preserving the model’s utility, boosting unlearning performance across several benchmarks. The framework’s agostic nature allows for integration with existing algorithms, and its closed-form solution for weight attribution enhances both efficiency and explainability.
Empirical Results#
An effective ‘Empirical Results’ section would meticulously detail experimental setup, including datasets, models, evaluation metrics, and baseline methods. It should present results clearly, using tables and figures to showcase performance across various scenarios. Statistical significance should be rigorously addressed to ensure results aren’t due to chance. Crucially, the analysis should go beyond simple performance comparisons. It should explore trends, relationships, and limitations. A strong section would also discuss unexpected findings and how they inform future research. Qualitative analysis, offering insightful interpretations of results, complements quantitative data. Finally, the reproducibility of the experiments should be explicitly emphasized to support the validity and future utility of the research.
Future Work#
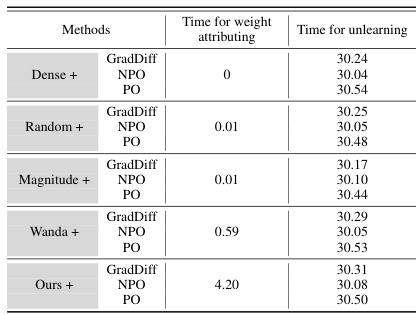
Future research directions stemming from this work could explore several promising avenues. Extending WAGLE’s applicability to a broader range of LLMs and unlearning methods is crucial to establish its generalizability and robustness. Investigating the influence of various hyperparameters, particularly the Hessian diagonal parameter (γ), and developing more efficient methods for its estimation would refine the weight attribution process. A deeper investigation into the model fingerprint of LLM unlearning, analyzing layer-wise sparsity and the influence of different LLM modules, promises insights into the modularity of LLMs and how it can be leveraged for effective modular unlearning. Finally, exploring the interaction between weight attribution, data privacy, and model robustness, developing more principled techniques that balance utility preservation with unlearning efficacy, is essential to address ethical concerns. Ultimately, future work will focus on refining weight attribution, creating more efficient and effective unlearning methods that strike a balance between unlearning accuracy and model preservation, and addressing the broader implications of this for AI safety and ethics.
More visual insights#
More on figures

This figure shows the performance of negative preference optimization (NPO) based unlearning on the TOFU dataset as the sparsity of unlearned weights changes. Sparsity is controlled using the Wanda LLM pruning method. The graph plots both unlearning efficacy and model utility. It demonstrates a trade-off: higher sparsity leads to better unlearning efficacy but reduces model utility. This highlights the challenge of finding an optimal subset of weights that balances efficacy and utility preservation during LLM unlearning, underscoring the need for a more principled approach to weight selection than simple pruning.
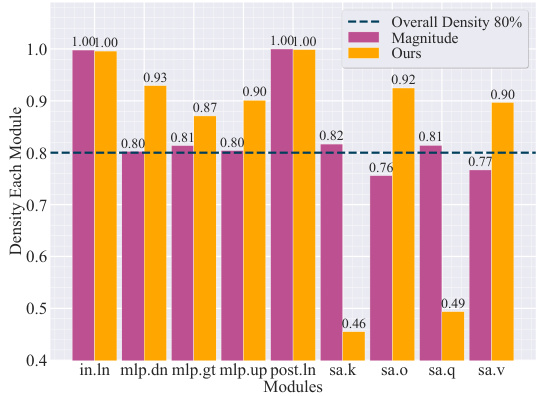
This figure shows the density of selected weights within each module of the LLaMA2-7B-chat large language model after fine-tuning on the TOFU dataset using a weight selection ratio of 80%. The modules include input layer (in), layer normalization (ln), multi-layer perceptron (MLP) components (dn, gt, up), post-attention layer (post), self-attention components (sa_q, sa_k, sa_v, sa_o). The comparison is made between weights selected based on their magnitude and the weights selected by the proposed WAGLE method. It highlights the different distributions of influential weights in each module of the model, showcasing how the WAGLE method’s weight attribution contrasts with magnitude-based selection.

This figure shows the relationship between unlearning efficacy and model utility as a function of the sparsity of unlearned weights. The experiment used the NPO (Negative Preference Optimization) unlearning method on the TOFU (Fictitious Unlearning) dataset. The sparsity was manipulated using the Wanda LLM pruning method. The results indicate a strong trade-off between unlearning efficacy and model utility, demonstrating that simply pruning weights is not an effective unlearning strategy. As the sparsity increases (meaning fewer weights are updated during unlearning), the unlearning efficacy sharply decreases, while the utility (measured as the model’s ability to perform well on the retained data) remains more stable. This suggests a need for more principled methods of selecting which weights to update during unlearning.

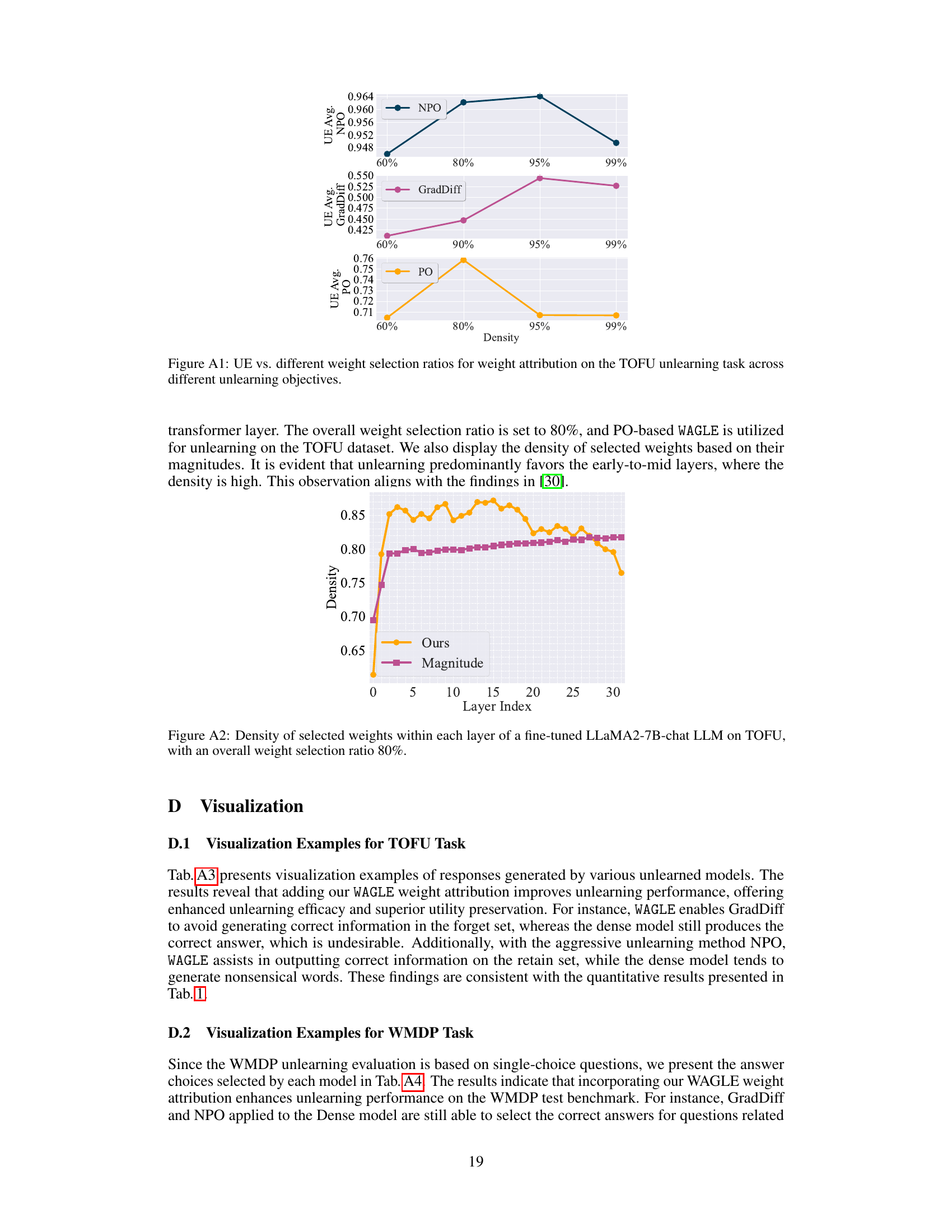
This figure displays the unlearning efficacy (UE) on the TOFU dataset for different weight selection ratios (60%, 80%, 95%, 99%) used in weight attribution. It shows three separate lines, one each for the NPO, GradDiff, and PO unlearning methods. The graph helps visualize how the average unlearning efficacy changes for each method depending on the percentage of weights updated during the process. This allows for an analysis of the optimal weight sparsity for different unlearning algorithms, revealing the trade-off between the unlearning efficacy and utility.

This figure shows the density of selected weights in each layer of a fine-tuned LLaMA2-7B-chat large language model (LLM) on the TOFU dataset. The overall weight selection ratio is 80%, meaning that only 80% of the weights were selected for unlearning. The figure compares the density of weights selected using the proposed WAGLE method with the density of weights selected based solely on their magnitudes. The comparison highlights how the method focuses more on selecting weights from certain layers (early-to-mid layers) while the magnitude based selection is less selective.
More on tables
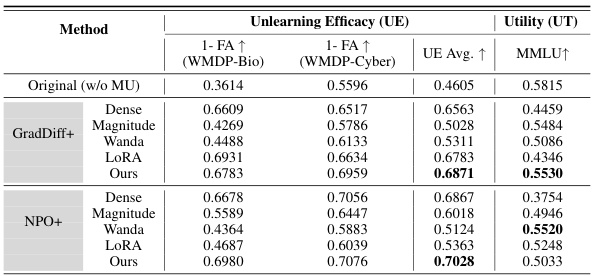
This table presents the results of LLM unlearning experiments conducted on the WMDP benchmark using the Zephyr-7B-beta model. It compares the performance of different unlearning methods (GradDiff and NPO), each combined with various weight selection techniques (Dense, Magnitude, Wanda, LoRA, and the proposed WAGLE). The table shows the unlearning efficacy (UE) measured by the forget accuracy (1-FA) on the WMDP-Bio and WMDP-Cyber subsets, as well as the utility (UT) preserved, measured by the accuracy on the MMLU dataset. The best average performance across all methods for both UE and UT is highlighted in bold.
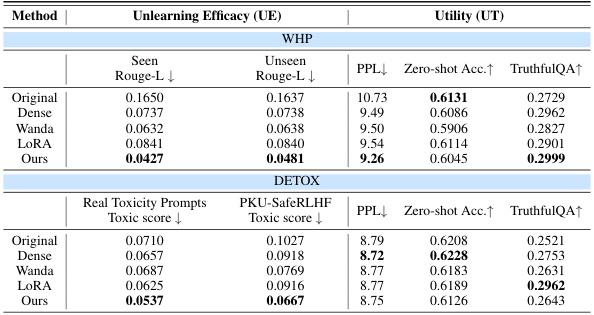
This table presents a comprehensive evaluation of various LLM unlearning methods on the TOFU benchmark using the LLaMA2-7B-chat model. It compares different unlearning approaches (GradDiff, NPO, PO) with and without the proposed WAGLE framework, as well as several baseline methods (dense, random, magnitude, Wanda, LoRA). The evaluation includes multiple metrics for both Unlearning Efficacy (UE) and Utility (UT), providing a thorough assessment of each method’s effectiveness in balancing forgetting undesired information with preserving the model’s overall performance.
This table presents a comprehensive performance comparison of various LLM unlearning methods on the TOFU dataset using the LLaMA2-7B-chat model. It evaluates both unlearning efficacy (UE) and utility retention (UT). UE is assessed using four metrics: Forget Quality (FQ), Membership Inference Attack (MIA), Forget Accuracy (1-FA), and Rouge-L recall (1-Rouge-L). UT is evaluated by Accuracy and Rouge-L recall on the retain set and on two subsets representing real authors and world facts. The table includes results for several baseline methods, providing a direct comparison against the proposed WAGLE approach and its integration with different unlearning algorithms (GradDiff, NPO, and PO).

This table presents a comprehensive performance comparison of various LLM unlearning methods on the TOFU dataset using the LLaMA2-7B-chat model. It compares different methods’ effectiveness in unlearning (UE) and maintaining model utility (UT), utilizing several metrics for both. The results are averaged over multiple trials, highlighting the best performing method for each metric.

This table presents a comprehensive evaluation of different LLM unlearning methods on the TOFU dataset using the LLaMA2-7B-chat model. It compares various techniques, including those incorporating the proposed WAGLE framework, across multiple metrics assessing both unlearning efficacy (UE) and utility preservation (UT). The metrics include Forget Quality (FQ), Membership Inference Attack (MIA), Forget Accuracy (1-FA), Rouge-L Recall (1-Rouge-L), and utility metrics based on accuracy and Rouge-L on retain sets representing real authors and world facts. The table highlights the best performing method on average across all metrics.

This table presents a comprehensive performance comparison of various LLM unlearning methods on the TOFU benchmark using the LLaMA2-7B-chat model. It evaluates both unlearning efficacy (UE) and utility retention (UT) across multiple metrics, including Forget Quality (FQ), Membership Inference Attack (MIA), Forget Accuracy (1-FA), Rouge-L Recall (1-Rouge-L), and utility metrics on retain sets (Real Authors and World Facts). Different weight selection strategies (Dense, Random, Magnitude, Wanda, LORA) are compared to the proposed WAGLE method integrated with various unlearning algorithms (GradDiff, NPO, PO). The table highlights the best average performance for both UE and UT.

This table presents a comprehensive evaluation of various LLM unlearning methods on the TOFU benchmark using the LLaMA2-7B-chat model. It compares different methods (GradDiff, NPO, PO) with and without the proposed WAGLE framework, and also includes baselines like random weight selection, magnitude-based pruning, Wanda pruning, and LoRA. The evaluation metrics include forget quality (FQ), membership inference attack (MIA), forget accuracy (1-FA), Rouge-L recall (1-Rouge-L), and utility metrics (accuracy and Rouge-L on retain set, real authors, and world facts). Higher values generally indicate better unlearning efficacy (UE) or utility preservation (UT).

This table presents a comprehensive performance comparison of various LLM unlearning methods on the TOFU benchmark using the LLaMA2-7B-chat model. It assesses both unlearning efficacy (UE) and utility preservation (UT) across multiple metrics, providing a detailed view of each method’s effectiveness in removing unwanted information while retaining the model’s original functionality. The table includes results for different weight selection strategies, allowing for a direct comparison of WAGLE against existing baselines.

This table presents a comprehensive evaluation of various LLM unlearning methods on the TOFU dataset using the LLaMA2-7B-chat model. It compares different methods (GradDiff, NPO, PO) with and without the WAGLE framework, as well as several baseline approaches (dense model, random, magnitude, Wanda, LORA). The metrics used evaluate both unlearning efficacy (forgetting undesirable information) and utility retention (preserving the model’s original capabilities). Results are averaged over six trials, highlighting the best average performance for each method and metric.
Full paper#