↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Accurately estimating depth from 360-degree images is challenging due to the lack of suitable datasets and the differences in camera projections compared to traditional perspective images. Existing methods either fail to handle the unique distortions of 360-degree images or underperform due to limited training data. This necessitates the development of novel approaches that can effectively utilize available data and handle the inherent challenges of 360-degree imagery.
The proposed “Depth Anywhere” framework tackles this problem by employing a two-stage training pipeline. The first stage generates masks for invalid image regions (like sky or watermarks), while the second stage uses a semi-supervised learning approach. It leverages state-of-the-art perspective depth estimation models as teachers to generate pseudo labels for unlabeled 360-degree images via a six-face cube projection. This allows the efficient use of extensive unlabeled 360-degree data for training a robust 360-degree depth estimation model. The results demonstrate significant improvements in accuracy, particularly in zero-shot scenarios, showcasing the approach’s effectiveness and generalizability across various datasets and models.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in computer vision and 360-degree image processing. It directly addresses the critical shortage of labeled data in 360-degree depth estimation, a significant hurdle for the field’s advancement. The proposed method opens new avenues for leveraging unlabeled data and knowledge distillation, benefiting various applications in virtual reality, autonomous navigation, and immersive media.
Visual Insights#

This figure shows a qualitative comparison of depth estimation results on the Stanford2D3D dataset using different methods. The top row displays the RGB images, ground truth depth maps, and error maps generated by the BiFuse++ model. The middle row shows the depth maps produced by the BiFuse++ model and our proposed method. The bottom row displays the point clouds generated from the ground truth and estimated depth maps. The comparison illustrates the improved depth estimation accuracy achieved by incorporating our training pipeline, particularly in challenging areas.

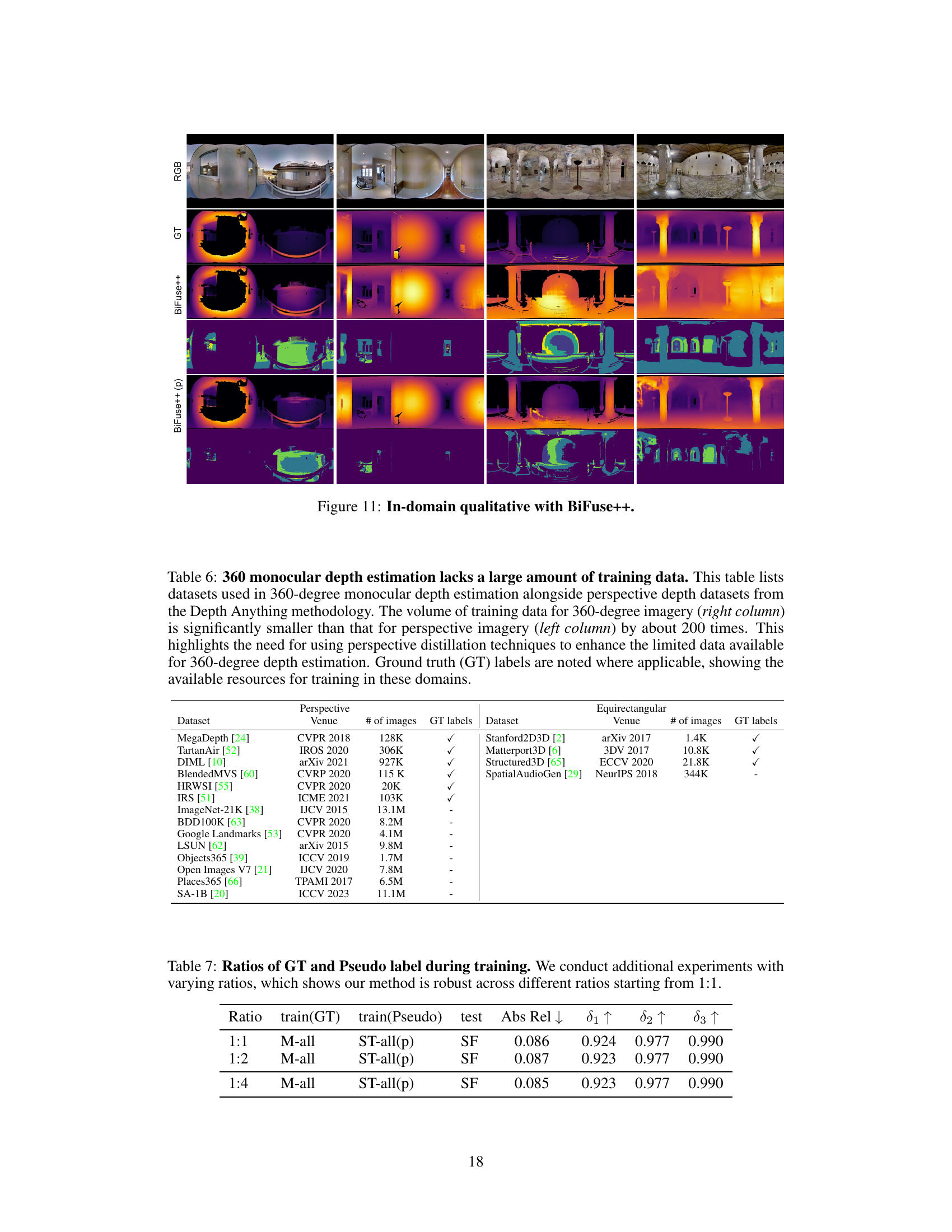
This table compares the amount of labeled and unlabeled data available for training 360-degree monocular depth estimation models versus perspective depth estimation models. It highlights the significant disparity in data availability, with perspective datasets having substantially more labeled and unlabeled data. This difference in data size underscores the challenge of training effective 360-degree depth estimation models and motivates the use of techniques like perspective distillation to leverage the abundance of perspective data.
In-depth insights#
360 Depth Distillation#
The concept of “360 Depth Distillation” presents a novel approach to depth estimation in 360-degree images by leveraging the power of pre-trained perspective-view depth models. This technique cleverly addresses the scarcity of labeled 360-degree data, a major hurdle in training accurate 360-degree depth estimation models. The core idea is to utilize these perspective models as teachers, transferring their knowledge to a 360-degree student model via pseudo-labels. This is achieved by projecting the 360-degree equirectangular image onto a cubemap, processing each face of the cubemap with a teacher model, and then projecting the resulting depth maps back to the original equirectangular format. This creates pseudo-ground-truth depth maps for the 360-degree student model. This method is particularly effective in a semi-supervised setting, combining both labeled and pseudo-labeled data to improve accuracy. This approach enables significant improvements in 360-degree depth estimation, especially in zero-shot scenarios, showcasing effective knowledge transfer and bridging the domain gap between perspective and omnidirectional imagery. Further research could explore alternative projection methods (beyond cubemaps) and more sophisticated distillation techniques to enhance performance and robustness.
Cube Projection Trick#
The “Cube Projection Trick” in 360-degree depth estimation is a clever technique to leverage the abundance of data and powerful models available for perspective imagery. It addresses the scarcity of labeled 360-degree data by projecting the equirectangular image onto the faces of a cube. This allows the use of perspective depth estimation models, which are significantly more advanced due to larger training datasets, to generate pseudo-labels for the 360-degree data. The method is efficient because it bypasses the need for expensive and time-consuming manual labeling of 360-degree depth maps. However, direct application of perspective models without further refinement leads to cube artifacts due to discontinuities at the cube faces. To mitigate this, the authors cleverly employ random rotation of the input 360-degree image before cube projection. This data augmentation approach creates a more diverse set of perspective views, strengthening the knowledge distillation and producing more robust depth estimates in the final 360-degree model.
Zero-Shot 360 Depth#
Zero-shot 360-degree depth estimation is a challenging problem due to the lack of labeled 360-degree imagery and the inherent differences between perspective and 360-degree camera projections. Existing methods often struggle, either failing entirely when applied to 360-degree images or producing inferior results due to data scarcity. A promising approach involves leveraging state-of-the-art perspective depth estimation models as teacher models. These models can generate pseudo-labels for unlabeled 360-degree data, effectively bridging the domain gap between different camera projections. This allows for efficient training of 360-degree depth models even in the absence of abundant labeled data. This technique requires robust data cleaning and preprocessing strategies to handle invalid regions in 360-degree images. The success of this approach depends heavily on the quality of pseudo labels generated by the teacher models and the ability of the training technique to generalize to unseen data. Significant improvements in accuracy can be achieved, especially in zero-shot scenarios, where models trained on one dataset generalize to another, highlighting the potential of this approach for real-world applications.
Unlabeled Data Power#
The concept of “Unlabeled Data Power” in the context of a research paper likely explores how leveraging vast amounts of unlabeled data can significantly improve model performance, especially in scenarios where labeled data is scarce or expensive to obtain. The core idea revolves around semi-supervised learning, where a model is trained using both labeled and unlabeled data. A common approach involves using a pre-trained model on labeled data (a “teacher” model) to generate pseudo-labels for the unlabeled data. This allows the model to learn from a much larger dataset, potentially improving its generalization and robustness. Effective data augmentation techniques, applied to both labeled and unlabeled data, are likely crucial to increase the diversity and amount of training examples and prevent overfitting. The paper likely demonstrates the effectiveness of this approach by showing improved accuracy and efficiency in depth estimation for 360-degree imagery, a domain typically challenged by a lack of sufficient labeled datasets. Key to the success of “Unlabeled Data Power” is the careful handling of pseudo-labels to reduce noise and error propagation. The paper probably highlights specific techniques used for noise reduction or the selection of high-confidence pseudo-labels.
Future 360 Research#
Future research in 360° computer vision should prioritize robustness and generalization. Current methods often struggle with inconsistencies in data quality and varied camera parameters. Addressing these limitations is crucial to unlock the full potential of 360° applications. This necessitates investigating advanced self-supervised learning techniques and exploring the use of foundation models for knowledge transfer across different data types and camera projections. Another vital area is improving efficiency, as processing 360° data is computationally expensive. Research into efficient architectures, algorithms, and data structures specifically designed for equirectangular or cubemap representations is needed. Finally, the development of comprehensive benchmark datasets with accurate depth and semantic labels is paramount for evaluating progress and driving further innovation. Synthetic data generation, combined with techniques for augmenting existing datasets, offers a viable approach to scale datasets and address the scarcity of labeled 360° data.
More visual insights#
More on figures
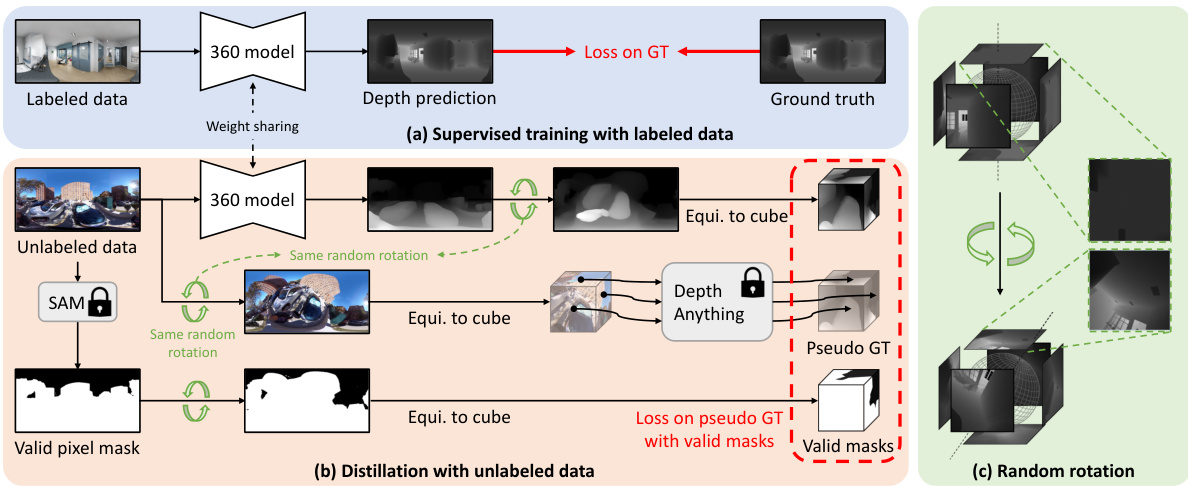
This figure illustrates the training pipeline of the proposed approach. It consists of two main stages: supervised training with labeled data and distillation with unlabeled data. The labeled data is used to train a 360-degree depth model using ground truth depth values. The unlabeled data is processed using a perspective depth estimation model (Depth Anything) to create pseudo labels. This process leverages a six-face cube projection technique to align the perspective and 360-degree views. To improve robustness, invalid regions (e.g., sky, watermarks) are masked out using Segment Anything before computing the loss on pseudo labels. Finally, random rotation is added as data augmentation to bridge the knowledge gap across different camera projections.

This figure shows examples of how the Grounded-Segment-Anything model is used to identify and mask out invalid regions (sky and watermarks) in unlabeled 360-degree images. These invalid regions are masked because they lack ground truth depth labels and can interfere with training. The approach uses text prompts (‘sky’ and ‘watermark’) to guide the segmentation process. The figure highlights the importance of this masking step for improving the accuracy of 360-degree depth estimation.

This figure shows a comparison of depth estimation results using different methods. The top row shows the input RGB images. Rows 2 and 3 show the pseudo ground truth and model predictions without random rotation, demonstrating the cube artifacts resulting from the scale misalignment between cube faces. Rows 4 and 5 show the results with random rotation applied before feeding images to the perspective model, resulting in better depth estimation. The last row shows our model’s predictions, highlighting the effectiveness of our approach in addressing the scale misalignment problem.

This figure shows the results of applying the proposed training pipeline to improve existing 360 monocular depth estimators. The top row displays the input RGB images from the Stanford2D3D dataset. The second row shows the ground truth depth maps for these images. The third row displays the depth maps generated by the BiFuse++ model, and the bottom row displays the depth maps generated by the BiFuse++ model after applying the proposed training pipeline. The figure demonstrates that the proposed training pipeline significantly improves the accuracy of depth estimation.

This figure shows the results of applying the proposed training pipeline to improve existing 360 monocular depth estimation models. The left side displays the input RGB image, ground truth depth map, and the depth predictions of a baseline model (BiFuse++) and its improved version after applying the training pipeline (BiFuse++(p)). The right side displays an error map illustrating the difference between the predicted depth and the ground truth depth. The results demonstrate significant improvements in depth estimation accuracy achieved by the proposed method, particularly in challenging zero-shot scenarios where models are trained on one dataset and tested on another.

This figure shows the improvement achieved by the proposed training pipeline. The pipeline is tested on the Stanford2D3D dataset in a zero-shot setting. The figure shows the input RGB image, the ground truth depth map, the depth map predicted by the BiFuse++ model, and the error map for BiFuse++. The pipeline is shown to significantly improve depth estimation.

This figure shows the improvement achieved by the proposed training pipeline. The pipeline uses a semi-supervised learning approach, combining labeled and unlabeled data. The example shown is a zero-shot setting where the model is tested on the Stanford2D3D dataset, demonstrating successful knowledge transfer and improved depth estimation accuracy. The images display input RGB images, ground truth depth maps, and the depth predictions from BiFuse++ both with and without the authors’ proposed training pipeline improvements. The difference in accuracy is clearly visible, highlighting the effectiveness of their method.

This figure shows the improvement achieved by applying the proposed training pipeline to enhance existing 360 monocular depth estimation models. The results are demonstrated using the Stanford2D3D dataset in a zero-shot setting. It visualizes the input RGB image, ground truth depth map, depth estimations from two baseline models (BiFuse++, UniFuse), and the improved depth maps obtained after using the proposed technique. The differences (error maps) between the ground truth and different model predictions are also displayed, highlighting the effectiveness of the proposed method.

This figure shows a comparison between ground truth depth maps, depth maps estimated using BiFuse++, and depth maps estimated using the proposed method on the Stanford2D3D dataset. The proposed method significantly improves the accuracy of depth estimation, particularly in challenging areas such as the edges of objects and areas with significant shadows. The improved accuracy is particularly notable in the zero-shot setting, where the model is tested on a dataset that it was not trained on.

This figure demonstrates the generalization capability of the model by visualizing point clouds generated from both images captured by the authors and images randomly sourced from the internet. The zero-shot performance on unseen data is showcased to highlight the model’s ability to generalize to diverse scenes and viewpoints.

This figure demonstrates the model’s ability to generalize to unseen data by visualizing point clouds generated from 360-degree images captured in various real-world environments. The results showcase the model’s performance in estimating depth and generating a 3D representation from various scenarios, illustrating its robustness and generalizability beyond the datasets used during training.
More on tables
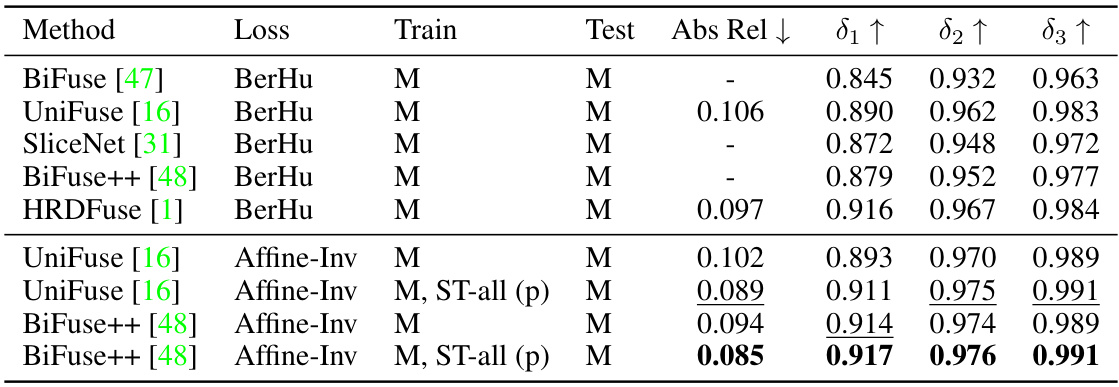
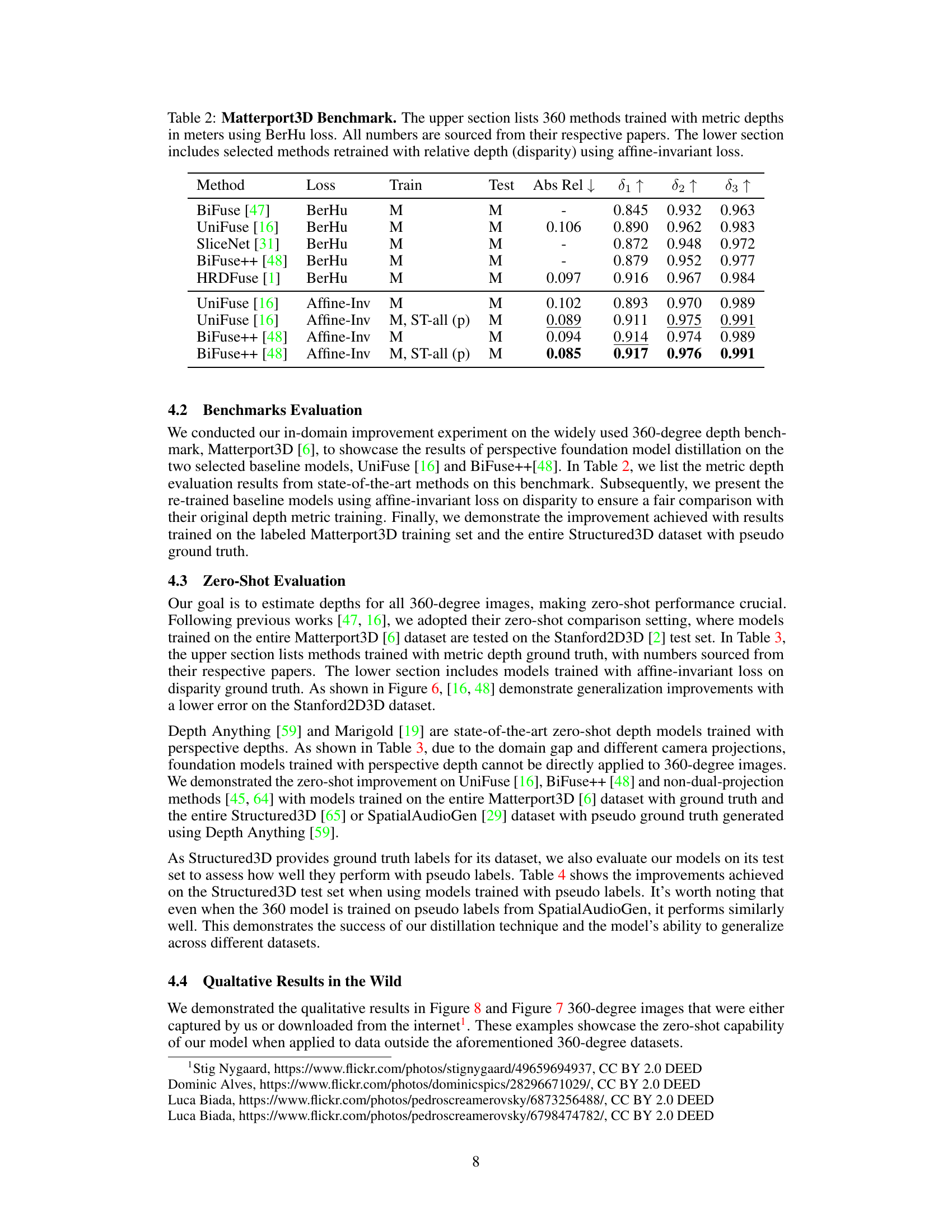
This table presents a comparison of different 360-degree depth estimation methods’ performance on the Matterport3D benchmark dataset. The upper part shows results using the BerHu loss function for metric depth (in meters), while the lower part shows results obtained by retraining selected models with the Affine-Invariant loss on relative depth (disparity). The metrics used for evaluation are Absolute Relative Error (Abs Rel), δ1, δ2, and δ3, representing the percentage of pixels within a certain range of the ground truth depth.
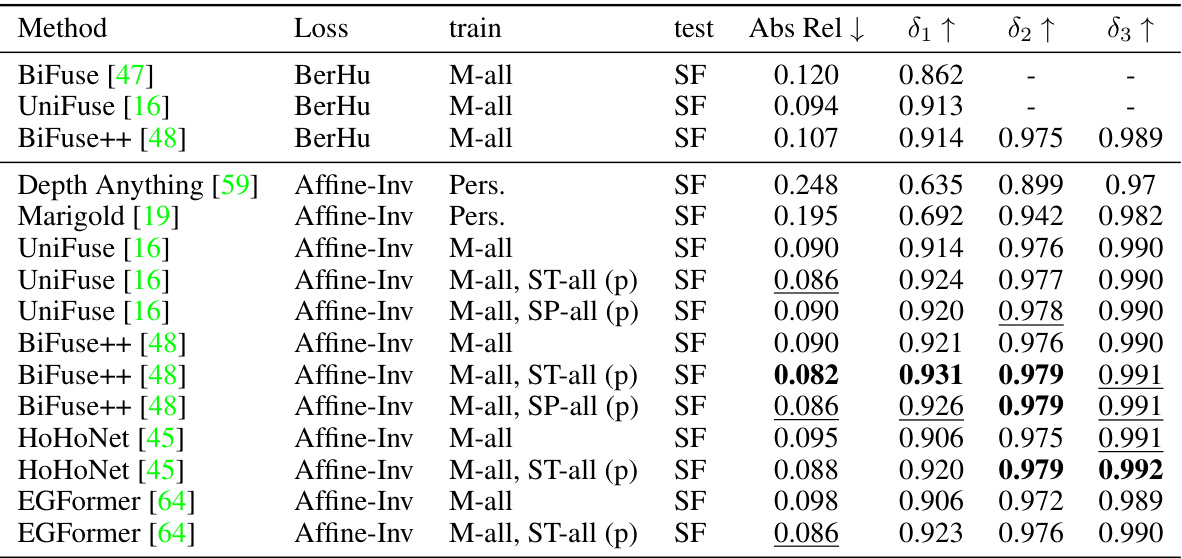
This table presents the results of a zero-shot evaluation on the Stanford2D3D dataset. Models were trained on the Matterport3D dataset and then evaluated on the Stanford2D3D dataset without further training. The table shows various metrics (Abs Rel, δ1, δ2, δ3) to compare the performance of different methods, including baselines and the proposed method with and without additional pseudo-labeled data from other datasets (ST-all (p), SP-all (p)). It demonstrates the effectiveness of the proposed training technique in generalizing to unseen data.

This table presents the results of zero-shot evaluation on the Stanford2D3D dataset. Models were initially trained on the full Matterport3D dataset and then tested on Stanford2D3D without further training. The table compares the performance of several 360-degree depth estimation methods (UniFuse, BiFuse++, HoHoNet, EGFormer) and shows improvements when using the proposed training approach with pseudo-labels generated from Depth Anything. Different loss functions (BerHu and Affine-Inv) and the use of additional datasets (Structured3D and SpatialAudioGen) for pseudo-label generation are also analyzed. The metrics used for evaluation include Absolute Relative error (AbsRel), δ1, δ2, and δ3.

This table shows the results of fine-tuning a model pre-trained on relative depth using the Matterport3D and Structured3D datasets. The fine-tuning is performed on the Stanford2D3D dataset for a single epoch using metric depth. The table presents several evaluation metrics, such as Mean Absolute Error (MAE), Absolute Relative Error (Abs Rel), Root Mean Squared Error (RMSE), Root Mean Squared Logarithmic Error (RMSElog), and δi metrics (δ1, δ2, δ3), to assess the model’s performance after fine-tuning.

This table compares the amount of labeled and unlabeled data available in popular 360-degree depth estimation datasets with that of perspective depth datasets used in the Depth Anything model. It highlights the significant disparity in data availability, with 360-degree datasets having considerably less labeled and unlabeled data than perspective datasets, thus motivating the use of the proposed method to leverage unlabeled data.

This table presents an ablation study on the ratio of ground truth to pseudo labels used during training. It shows the results of experiments conducted with ratios of 1:1, 1:2, and 1:4, evaluating the performance using Absolute Relative Error (AbsRel) and three other metrics (δ1, δ2, δ3). The results demonstrate the robustness of the proposed method across different ratios, with consistent performance starting from a 1:1 ratio.

This table compares the performance of two different projection methods (cube and tangent image) used in the proposed 360-degree depth estimation framework. The results demonstrate that both methods achieve similar accuracy, but the cube projection is preferred due to its wider field of view, which is beneficial for knowledge distillation during training.
Full paper#