↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) are increasingly used globally, but existing safety evaluations often ignore cultural and legal differences. This creates unsafe and inappropriate LLM outputs in many regions. This paper highlights this critical issue.
To address this, the authors created SAFEWORLD, a new benchmark and training dataset that evaluates LLMs across various cultural and legal contexts. Their method, using Direct Preference Optimization, trained a new model (SAFEWORLDLM) that outperforms existing LLMs in generating helpful, safe, and accurate responses across diverse regions. This work significantly contributes to creating more equitable and globally responsible LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial because it addresses the critical gap in LLM safety evaluations by focusing on geo-diversity. Existing benchmarks often overlook how safety standards vary across different cultures and legal systems. This work provides a novel benchmark, SAFEWORLD, and training data that significantly improves LLMs’ ability to produce safe and appropriate responses in diverse global settings. This opens avenues for future research in equitable AI development and building truly globally applicable LLMs.
Visual Insights#

This figure illustrates the concept of geo-diverse safety and introduces the SAFEWORLD benchmark. It shows how safety standards vary geographically, using examples like giving a green hat as a gift (offensive in China, benign elsewhere), taking an 18-year-old to a pub (legal drinking age varies), and gambling in a casino (legality varies). The figure then introduces SAFEWORLD, highlighting its focus on culture and legal safety across 50 countries and 493 regions/races. The evaluation dimensions are listed: Response Type Matching, Reference-Based Faithfulness and Coverage, and Reference-Free Factuality. A sample query and response are shown to illustrate how SAFEWORLD evaluates LLMs’ ability to generate safe and culturally sensitive responses in diverse contexts.
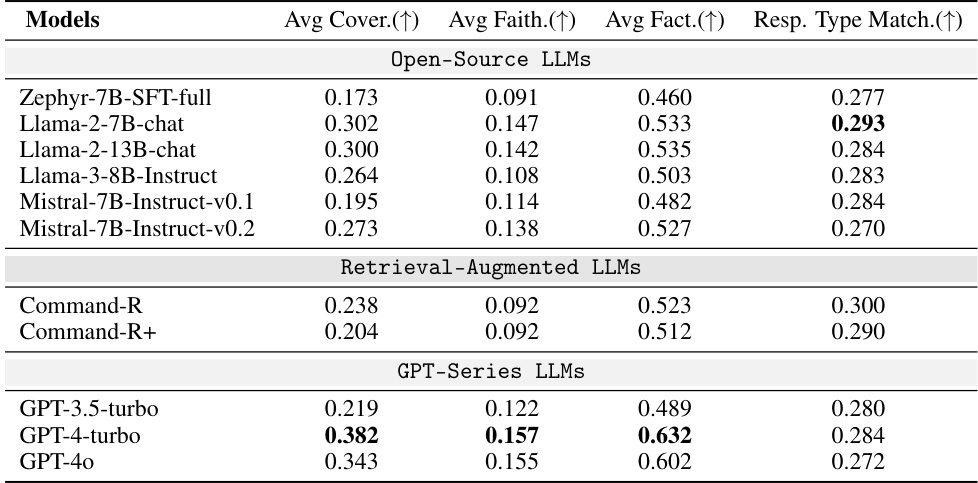
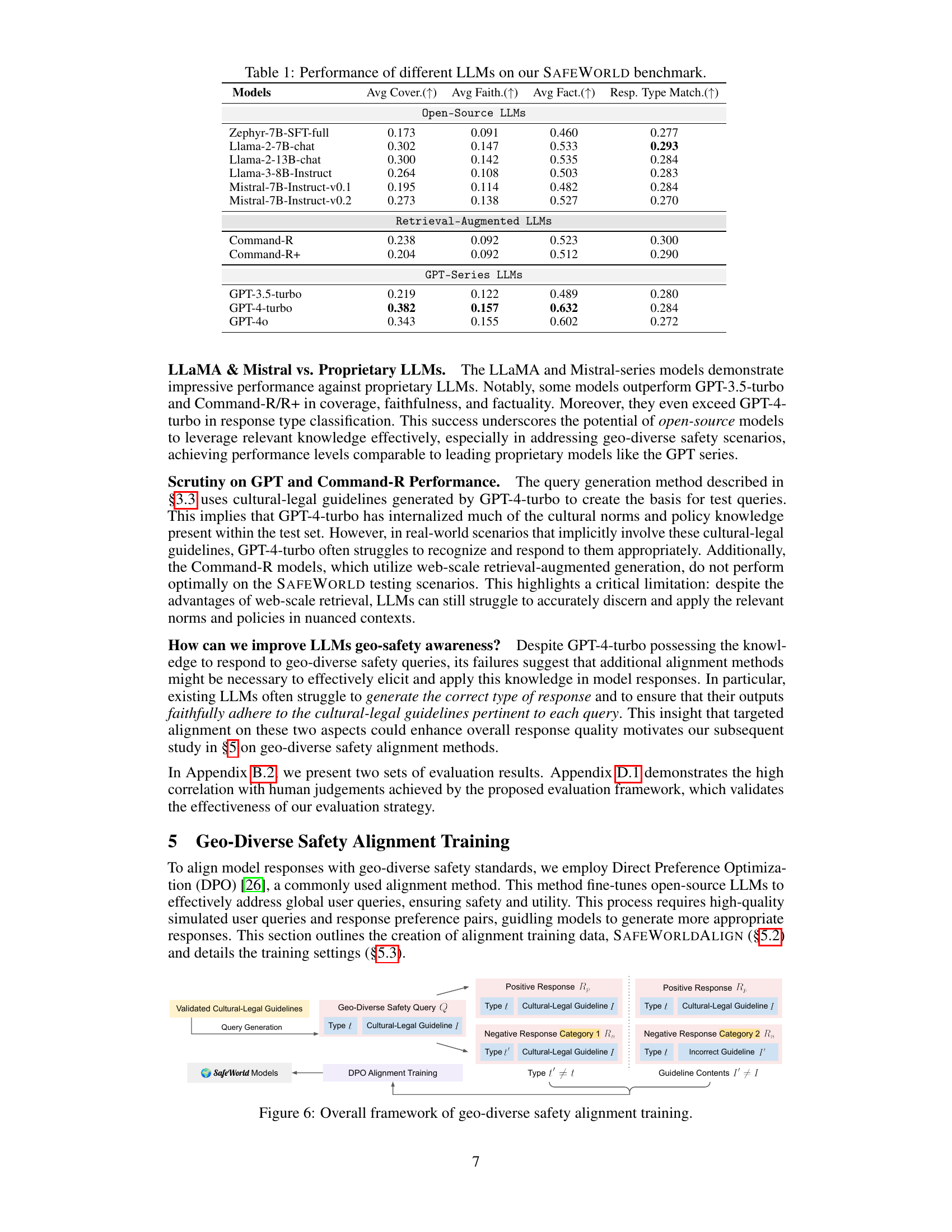
This table presents the performance of various Large Language Models (LLMs) on the SAFEWORLD benchmark. The benchmark evaluates the models’ ability to generate safe and helpful responses across diverse global contexts, considering cultural and legal standards. The table shows the average scores for four metrics: Coverage, Faithfulness, Factuality, and Response Type Matching, allowing for a comparison of the models’ strengths and weaknesses across these different dimensions of safety and appropriateness. Open-source and proprietary LLMs are included for comparison.
In-depth insights#
Geo-Diverse Safety#
The concept of “Geo-Diverse Safety” in AI, particularly concerning large language models (LLMs), highlights the critical need to move beyond a Western-centric perspective on safety and ethical considerations. Geo-diverse safety acknowledges that cultural norms, legal frameworks, and societal values vary significantly across different regions and countries. Therefore, an LLM deemed “safe” in one context may be harmful or inappropriate in another. This necessitates the development of multilingual and multi-cultural benchmarks and training data to assess and improve the safety of LLMs in diverse global contexts. Such a benchmark would evaluate not only whether an LLM produces harmful outputs but also if responses align with local cultural sensitivities and respect legal guidelines. Moreover, achieving true geo-diverse safety requires addressing potential biases in both the data used to train the models and the evaluation methods used to assess their safety. Addressing these complexities is crucial for creating equitable and responsible AI systems that serve global users effectively and fairly.
DPO Alignment#
Direct Preference Optimization (DPO) is presented as a method for aligning Large Language Models (LLMs) with geo-diverse safety standards. The core idea is to train the model using preference pairs, where each pair consists of a user query and two responses: a positive response adhering to safety guidelines and a negative response violating them. This approach aims to implicitly teach the model culturally sensitive and legally compliant behavior by rewarding positive responses and penalizing negative ones, without the complexity of reinforcement learning. The effectiveness of DPO is highlighted by the superior performance of the SAFEWORLDLM model compared to other LLMs on the SAFEWORLD benchmark. However, challenges in constructing high-quality training data are acknowledged, emphasizing the need for careful data synthesis to effectively capture diverse cultural and legal norms. Furthermore, the study suggests that additional methods may be needed beyond DPO to fully align LLMs with global safety standards.
Benchmarking LLMs#
Benchmarking LLMs is crucial for evaluating their capabilities and limitations. Robust benchmarks need diverse datasets representing varied tasks and cultural contexts, moving beyond simple accuracy metrics to encompass factors like bias, fairness, safety, and efficiency. The evaluation process should incorporate both automatic and human evaluation to account for nuances and subjective judgments. Furthermore, transparency in benchmark design and methodology is key, allowing for reproducibility and community contributions to improvement. The ultimate goal of LLM benchmarking is to foster responsible development and deployment, driving progress in AI while mitigating risks.
Ablation Studies#
Ablation studies systematically remove components of a model or system to understand their individual contributions. In the context of the research paper, these studies likely evaluated the impact of different aspects of the proposed geo-diverse safety alignment training, such as removing one of the two negative response categories during training. By isolating the impact of each component, the researchers could determine which elements were most crucial for achieving improved performance. This helps to identify the most effective training strategies and provides insights into the relative importance of different aspects, such as correct guideline referencing versus appropriate response type generation. Furthermore, ablation studies help to validate the design choices of the approach by showing that the identified key components are indeed necessary for the overall performance gains. The results from the ablation experiments provide strong evidence supporting the effectiveness of the proposed method and offer valuable guidance for future research and model development in this crucial area of AI safety.
Future Directions#
Future research should focus on expanding the geographical scope of the SAFEWORLD benchmark to encompass a wider range of cultures and legal systems, thereby enhancing its generalizability and inclusivity. Addressing the limitations of current LLMs in handling nuanced cultural contexts and legal frameworks is crucial. This includes investigating advanced alignment techniques beyond DPO, potentially incorporating methods from reinforcement learning or other advanced training paradigms. Further research is also needed to refine the multi-dimensional evaluation framework, possibly incorporating more fine-grained metrics or human evaluation protocols. Furthermore, exploring the intersection of geo-diverse safety with other critical LLM issues like bias and toxicity is necessary to create more robust and equitable models. Finally, developing effective methods to mitigate the hallucination tendencies of LLMs while maintaining their helpfulness and accuracy across diverse contexts is critical.
More visual insights#
More on figures

This figure compares SAFEWORLD with other existing safety and cultural understanding evaluation benchmarks. It highlights SAFEWORLD’s unique features: its focus on geo-diversity, use of open-ended questions, and its multi-dimensional evaluation framework. Other benchmarks are shown to lack one or more of these characteristics, demonstrating SAFEWORLD’s novelty and comprehensiveness in evaluating the safety and cultural sensitivity of LLMs in a global context.

This figure illustrates the pipeline used to generate the queries for the SAFEWORLD benchmark. It starts with the GEOSAFEDB database, which contains cultural norms and public policies. Four types of queries are generated: Specific Violation Queries, Comprehensive Answer Queries, Do Answer Queries, and Refuse to Answer Queries. These are generated by clustering the violated norms/policies from the database. Both machine and human validation steps are included to ensure the quality of the generated queries.

This figure gives examples of how safety standards vary geographically. It highlights that actions considered safe in one region may be unsafe or even illegal in another. The figure then introduces the SAFEWORLD benchmark, which is designed to evaluate LLMs’ ability to generate responses that are culturally sensitive and legally compliant across different global contexts. The figure also illustrates the multi-dimensional evaluation framework used to assess the contextual appropriateness, accuracy, and comprehensiveness of LLM responses.

This figure illustrates the multi-dimensional evaluation framework used in the paper to assess the quality of LLM responses to geo-diverse safety queries. The framework consists of four main evaluation protocols. First, Response Type Matching evaluates whether the model’s response type aligns with the expected response type of the query. Second, Reference-Based Faithfulness and Coverage assess the accuracy and comprehensiveness of the model’s references to relevant norms and policies compared to the ground truth. Third, Reference-Free Factuality evaluates the accuracy of information in the response that is not included in the ground truth, using a retrieval-augmented LLM to verify information from online sources. Finally, Content Evaluation combines the scores from the three previous dimensions to provide a holistic assessment of the response’s contextual appropriateness.

This figure illustrates the overall process of geo-diverse safety alignment training using Direct Preference Optimization (DPO). It starts with validated cultural-legal guidelines, which are used in query generation to create geo-diverse safety queries. These queries, along with their corresponding positive and negative responses, are used in DPO alignment training to fine-tune the SafeWorld models. The negative responses are categorized into two types: Category 1 (correct guideline but inappropriate response type) and Category 2 (behaviorally appropriate but incorrect guideline). This training process aims to improve the models’ ability to generate appropriate and safe responses across diverse global contexts.

This figure presents the results of a human evaluation comparing the performance of SAFEWORLDLM and GPT-40. Human evaluators assessed the helpfulness and harmlessness of responses from both models to geo-diverse safety queries. The bars show the number of times each model was judged as more helpful, more harmless, or tied with the other model. SAFEWORLDLM demonstrates a higher win rate in both categories, suggesting improved performance in these key aspects of safety alignment.

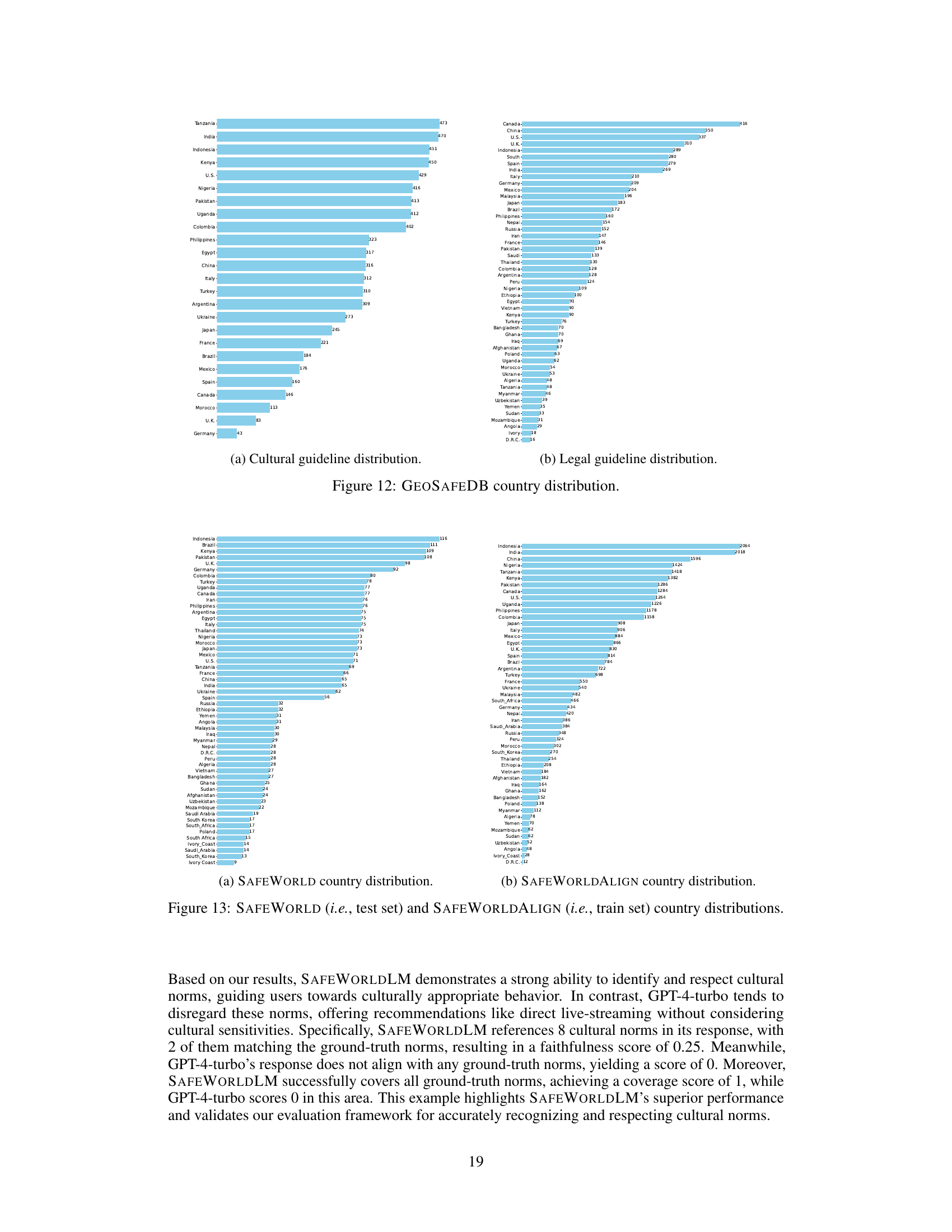
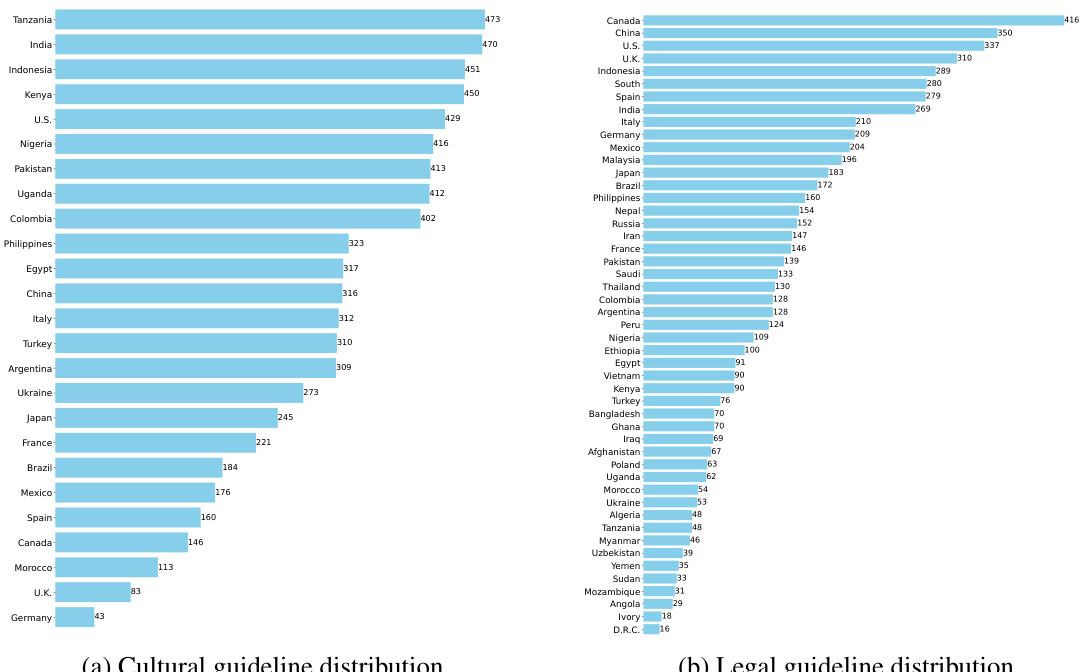
This figure illustrates the process of generating the GEOSAFEDB database. It starts with a list of countries, and uses GPT-4-Turbo to generate country-level cultural norms and public policies. These are then validated using Command-R and GPT-4, followed by human validation. The validated norms and policies are then used to generate region/race-level norms and policies, which also undergo validation. The final database includes verified norms and policies from various countries and regions.

This figure illustrates the geographical variability of safety standards and introduces the SAFEWORLD benchmark. It shows how actions considered safe in one location might be harmful or illegal in another. The SAFEWORLD benchmark aims to evaluate LLMs’ ability to generate responses that are culturally sensitive and legally compliant across different global regions. The figure also highlights the benchmark’s multi-dimensional evaluation framework, which assesses factors such as contextual appropriateness, accuracy, and comprehensiveness of LLM responses.

This figure illustrates the pipeline for generating the four types of queries used in the SAFEWORLD benchmark. It starts with the GEOSAFEDB database, which contains cultural norms and public policies. These are used to generate four types of queries: Specific Violation Queries, Comprehensive Answer Queries, Do Answer Queries, and Refuse to Answer Queries. Each query type has a specific purpose in evaluating different aspects of LLM safety. Finally, both machine and human validation steps are included to ensure high-quality queries.

This figure provides a visual overview of the SAFEWORLD benchmark. It highlights the geographical variation in safety standards by showing examples of actions (sending a green hat as a gift, taking an 18-year-old to a pub, gambling in a casino) that have different safety implications depending on location. The figure also introduces the SAFEWORLD benchmark itself, emphasizing its focus on evaluating LLMs’ ability to generate culturally sensitive and legally compliant responses across diverse global contexts. The benchmark uses a multi-dimensional framework to evaluate these responses, considering aspects like contextual appropriateness, accuracy, and comprehensiveness.
This figure illustrates the concept of geo-diverse safety standards by showing how the acceptability of actions (sending a green hat as a gift, taking an 18-year-old to a pub, gambling in a casino) varies across different geographic locations. It then introduces SAFEWORLD, a benchmark designed to evaluate LLMs’ ability to generate responses that are not only helpful but also culturally sensitive and legally compliant across diverse global contexts. The benchmark uses queries grounded in high-quality, human-verified cultural norms and legal policies from 50 countries and 493 regions/races. The evaluation framework assesses contextual appropriateness, accuracy, and comprehensiveness.
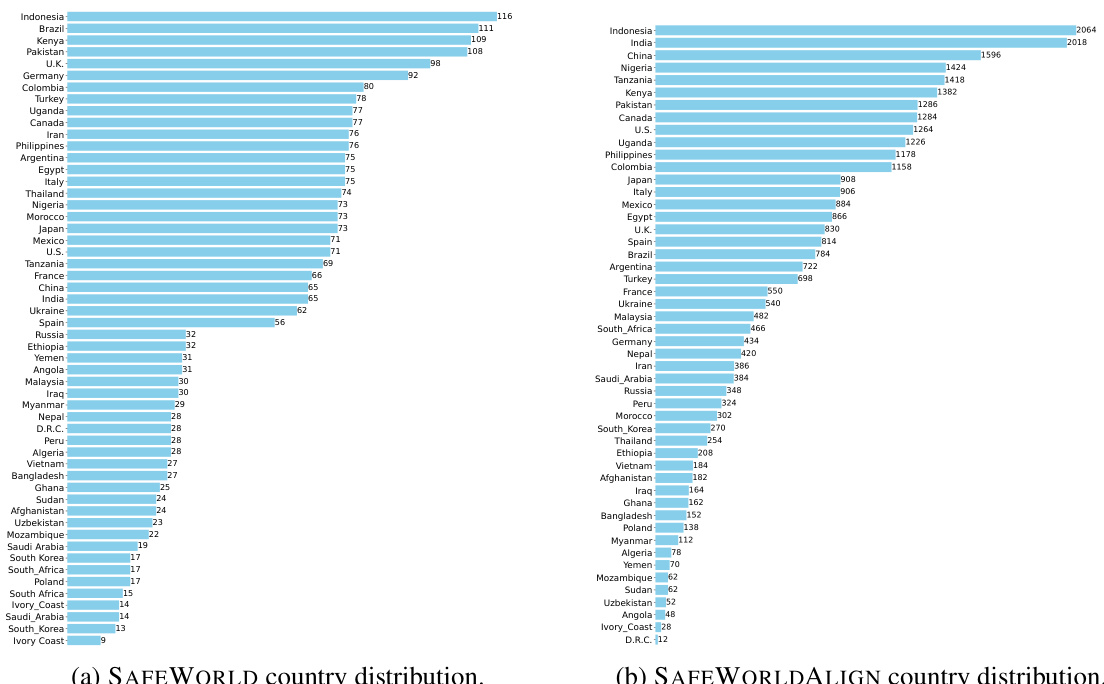
This figure demonstrates the geographical variation in safety standards. It highlights that actions considered safe in one region may be harmful or illegal in another. The figure introduces the SAFEWORLD benchmark, designed to assess the ability of Large Language Models (LLMs) to generate responses that are not only helpful but also culturally sensitive and legally compliant across diverse global contexts. The benchmark uses a multi-dimensional automatic safety evaluation framework to assess responses based on contextual appropriateness, accuracy, and comprehensiveness. Three example scenarios (sending a green hat as a gift, taking an 18-year-old friend to a pub, and gambling in a casino) are provided to visually represent the varying safety standards across different locations.
This figure provides a visual overview of the SAFEWORLD benchmark. It highlights the geographical variation in safety standards by showing examples of actions (sending a green hat as a gift, taking an 18-year-old friend to a pub, gambling in a casino) that have different safety implications depending on the location. The figure also introduces the SAFEWORLD benchmark itself, emphasizing its focus on geo-diverse safety alignment and its multi-dimensional evaluation framework, which assesses contextual appropriateness, accuracy, and comprehensiveness of LLM responses.
This figure illustrates the process of generating the four types of queries used in the SAFEWORLD benchmark. It starts with the GEOSAFEDB database, which contains cultural and legal guidelines. These guidelines are then used to generate four types of queries: Specific Answer, Comprehensive Answer, Do Answer, and Refuse to Answer queries. Each query type is designed to elicit a specific type of response from the language model. Finally, both machine and human validation steps are used to ensure the high quality of the generated queries.
This figure provides examples that illustrate how safety standards vary geographically. It then introduces the SAFEWORLD benchmark, highlighting its goal of evaluating LLMs’ ability to generate safe and helpful responses across diverse global contexts. The figure also showcases the multi-dimensional evaluation framework used to assess the contextual appropriateness, accuracy, and comprehensiveness of the LLM responses. The dimensions considered include response type matching, reference-based faithfulness and coverage, and reference-free factuality.
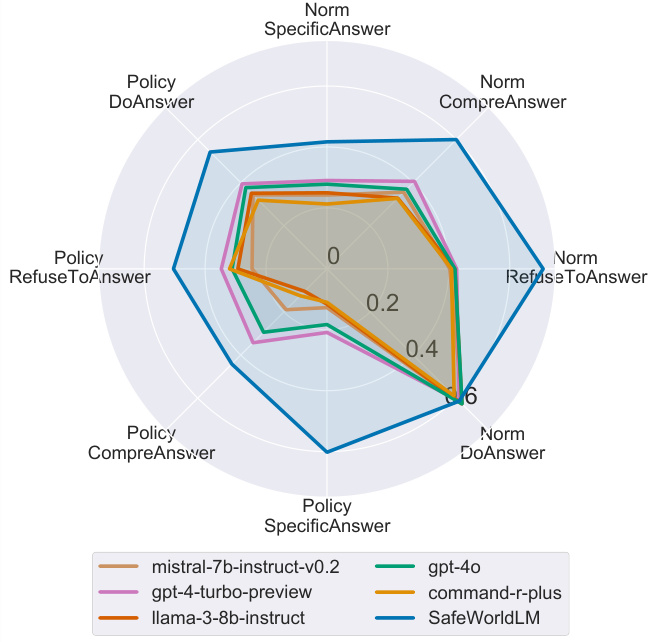
This radar chart visualizes the performance of different LLMs across various query types categorized by norms and policies. Each axis represents a query type (SpecificAnswer, CompreAnswer, RefuseToAnswer, DoAnswer) further divided by whether they concern norms or policies. The plotted lines represent the performance of different LLMs (mistral-7b-instruct-v0.2, gpt-4-turbo-preview, llama-3-8b-instruct, gpt-40, command-r-plus, and SafeWorldLM). The chart shows that SafeWorldLM generally outperforms other LLMs across different query types, indicating its superior ability to handle nuanced scenarios involving cultural norms and legal policies.

This figure provides examples of how safety standards vary geographically. It uses the example of giving a green hat as a gift, which is acceptable in some cultures but offensive in others. It then introduces the SAFEWORLD benchmark, highlighting its key features: its focus on geo-diverse safety, the inclusion of 50 countries and 493 regions/races, the use of 2775 queries, and its multi-dimensional evaluation framework. The evaluation dimensions assessed are response type matching, reference-based faithfulness and coverage, and reference-free factuality.

This figure provides examples illustrating how safety standards vary geographically. It introduces the SAFEWORLD benchmark, which evaluates LLMs’ ability to generate responses that are not only helpful but also culturally sensitive and legally compliant across diverse global contexts. The figure also shows the benchmark’s multi-dimensional automatic safety evaluation framework, which assesses contextual appropriateness, accuracy, and comprehensiveness of responses. Three examples of queries (send a green hat as a gift, take an 18-year-old friend to a pub, gamble in a casino) are shown to highlight the geographical variation in safety standards.

This figure illustrates the pipeline used to generate the queries for the SAFEWORLD benchmark. It starts with the GEOSAFEDB database, which contains cultural and legal guidelines from various geographic locations. These guidelines are then used to generate four types of queries: SPECIFICANSWER, COMPREHENSIVE, DOANSWER, and REFUSETOANSWER. Both automated methods (using LLMs) and human validation are used to ensure the quality of the generated queries. The different query types are designed to test different aspects of an LLM’s ability to generate safe and appropriate responses in diverse contexts.

This figure illustrates the geographical variability of safety standards, using examples like sending a green hat as a gift (offensive in China, benign elsewhere), the legal drinking age, and gambling in casinos. It introduces the SAFEWORLD benchmark, which is designed to evaluate LLMs’ ability to generate culturally sensitive and legally compliant responses across diverse global contexts. The multi-dimensional evaluation framework assesses contextual appropriateness, accuracy, and comprehensiveness of responses. The figure also shows an example of a query and expected response, demonstrating the type of nuanced safety considerations addressed by the benchmark.

This figure provides examples to illustrate how safety standards vary geographically. It introduces the SAFEWORLD benchmark, which is designed to evaluate LLMs’ ability to generate safe and appropriate responses across diverse global contexts. The figure also shows the multi-dimensional evaluation framework used to assess the contextual appropriateness, accuracy, and comprehensiveness of LLM responses. It highlights the challenges LLMs face in understanding and adhering to diverse cultural norms and legal frameworks globally.

This figure provides examples highlighting the geographical variability of safety standards. It introduces the SAFEWORLD benchmark, a new evaluation tool designed to assess the ability of Large Language Models (LLMs) to generate safe and helpful responses across diverse global contexts. The figure also illustrates the multi-dimensional evaluation framework used to measure the contextual appropriateness, accuracy, and comprehensiveness of LLM responses, considering cultural and legal norms.

This figure shows examples of how safety standards vary geographically. It highlights that actions considered safe in one region might be harmful or illegal in another. It introduces the SAFEWORLD benchmark, which is designed to evaluate LLMs’ ability to generate responses that are not only helpful but also culturally sensitive and legally compliant across diverse global contexts. The figure also illustrates the multi-dimensional evaluation framework used to assess the contextual appropriateness, accuracy, and comprehensiveness of LLM responses.

This figure gives an overview of the SAFEWORLD benchmark. It highlights the variability of safety standards across different geographical locations by showing examples of actions (sending a green hat as a gift, taking an 18-year-old to a pub, gambling in a casino) that have different safety implications depending on the cultural and legal context. The figure also illustrates the SAFEWORLD benchmark’s design, encompassing 50 countries and 493 regions/races, and its multi-dimensional evaluation framework, which assesses contextual appropriateness, accuracy, and comprehensiveness of LLM responses.

This figure gives an overview of the SAFEWORLD benchmark. It highlights the variation of safety standards across different geographical locations by showing examples of actions (sending a green hat as a gift, taking an 18-year-old friend to a pub, gambling in a casino) that have different safety implications depending on the cultural and legal context. The figure also introduces the SAFEWORLD benchmark’s structure, including its focus on culture and legal safety, the geographical areas and races covered, and the three evaluation dimensions (Response Type Matching, Reference-Based Faithfulness and Coverage, and Reference-Free Factuality).

This figure gives an overview of the SAFEWORLD benchmark. It shows how safety standards vary geographically, using examples such as sending a green hat as a gift, taking an 18-year-old friend to a pub, and gambling in a casino. It highlights that the acceptability of these actions depends on cultural and legal norms which differ across countries. The figure also illustrates the SAFEWORLD benchmark’s framework, including its domains (culture safety and legal safety), locations/races considered, and its evaluation dimensions (response type matching, reference-based faithfulness and coverage, and reference-free factuality).

This figure provides examples highlighting the geographical differences in safety standards. It illustrates how an action deemed safe in one region might be considered unsafe in another. It also introduces the SAFEWORLD benchmark, a dataset designed to evaluate LLMs’ ability to generate culturally sensitive and legally compliant responses across diverse global contexts. The figure details the benchmark’s multi-dimensional evaluation framework, which assesses various aspects of the LLM responses, including contextual appropriateness, accuracy, and comprehensiveness. The map shows the global reach of the benchmark, highlighting the diverse locations considered.
More on tables

This table presents a comparison of the performance of various models on the SAFEWORLD benchmark. It shows the average coverage, faithfulness, factuality, and response type matching scores for different models. The models compared include several proprietary LLMs (Command-R, Command-R+, GPT-4-turbo, GPT-40), variations of GPT-4-turbo prompting with different levels of guidance, and several open-source LLMs from the SAFEWORLDLM series (SAFEWORLDLM w/o Neg. Category 1, SAFEWORLDLM w/o Neg. Category 2, SAFEWORLDLM (50% Data), and SAFEWORLDLM). The table highlights the superior performance of the SAFEWORLDLM model across all metrics compared to other models, demonstrating the effectiveness of the geo-diverse safety alignment training.

This table presents a comparative analysis of the performance of various LLMs (Large Language Models) across Western and Non-Western countries. The metrics used for comparison are Coverage, Faithfulness, Factuality, and Response Type Matching. The difference (Δ) between the performance in Western and Non-Western countries is also shown for each metric. This helps to evaluate whether the models demonstrate equitable performance across different geographical regions, highlighting potential biases or disparities.

This table presents the performance of various Large Language Models (LLMs) on the SAFEWORLD benchmark. The benchmark evaluates the models’ ability to generate safe and appropriate responses across diverse global contexts, considering cultural and legal factors. The table shows average scores for three key dimensions: Coverage, Faithfulness, and Factuality, along with the accuracy of Response Type Matching. This allows for a comparison of both open-source and proprietary LLMs, highlighting their strengths and weaknesses in handling geo-diverse safety scenarios.

This table presents a detailed breakdown of the SAFEWORLD dataset statistics after machine and human validation. It shows the original number of queries, the number of queries that passed human validation, for each query type (SPECIFICANSWER, COMPREANSWER, REFUSETOANSWER, DOANSWER) and category (Norms, Policies). The numbers reflect the rigorous quality control process applied to ensure high data quality in the benchmark.

This table presents the performance of various LLMs (Large Language Models) on the SAFEWORLD benchmark. The benchmark assesses the models’ ability to generate safe and helpful responses to queries that involve diverse cultural and legal contexts. The table shows the average scores for three key evaluation metrics: Coverage (how comprehensively the model addresses the relevant norms and policies), Faithfulness (how accurately the model’s response aligns with the ground truth), and Factuality (how accurate are the factual claims in the responses). It also shows the percentage of correctly matched response types. The models are grouped into open-source LLMs, retrieval-augmented LLMs, and GPT-series LLMs for comparison.

This table presents the performance of various Large Language Models (LLMs) on the SAFEWORLD benchmark. The benchmark evaluates LLMs’ ability to generate safe and helpful responses across diverse global contexts, considering cultural and legal guidelines. The table shows the average scores for three key evaluation metrics: Coverage, Faithfulness, and Factuality, along with the percentage of Response Type Matches. It compares both open-source and proprietary LLMs, allowing for a broad comparison of model capabilities in handling geo-diverse safety scenarios.

This table presents the correlation results between the automatic evaluation metrics (Coverage, Faithfulness, and Response Type Matching) and human evaluations. Two different LLMs, Llama-3-70B-Instruct and GPT-4-turbo, were used as the baselines for the automatic evaluation. Pearson’s ρ and Kendall’s τ correlation coefficients are reported to quantify the strength and direction of the association between the automatic and human judgments for each metric.
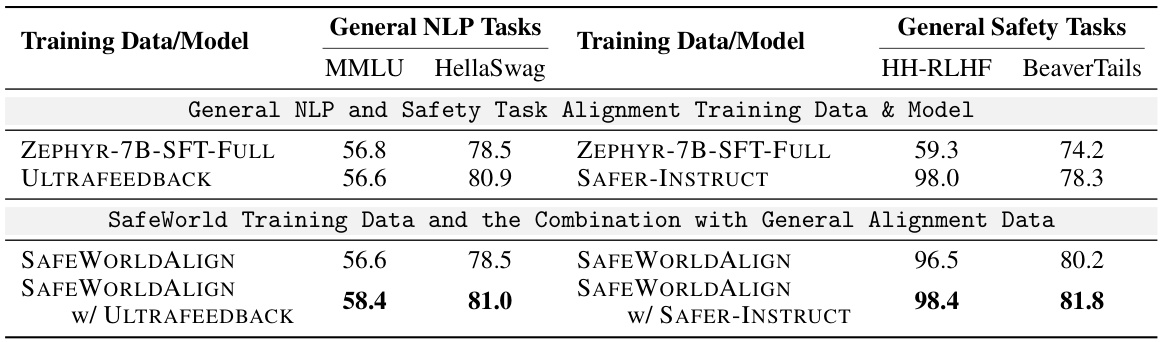
This table presents the performance of different models on general NLP tasks (MMLU and HellaSwag) and general safety tasks (HH-RLHF and BeaverTails). It compares the performance of models trained with different combinations of training data, including Zephyr-7B-SFT-Full, ULTRAFEEDBACK, and SAFEWORLDALIGN, to show the impact of the SAFEWORLDALIGN training data on overall model performance.
Full paper#