↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Large Multimodal Models (LMMs) show promise in few-shot learning but struggle with many-shot in-context learning (ICL) due to context length limitations. This is especially challenging in the multimodal domain due to the high embedding costs of images. Existing methods often require fine-tuning or struggle with the efficiency of encoding many examples.
This work addresses these challenges by introducing Multimodal Task Vectors (MTV). MTVs are compact implicit representations of in-context examples, efficiently encoded within the LMM’s attention heads. The proposed method involves calculating mean activations of attention heads across multiple inference calls for the ICL examples. Then, it strategically selects attention head locations to store these activations, facilitating many-shot ICL. Experiments show that MTVs significantly improve the performance and scalability of LMMs, achieving better results than standard few-shot methods on several vision-language tasks, without requiring additional finetuning or context length.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with large multimodal models because it introduces a novel method to overcome the context length limitations that hinder many-shot in-context learning. The proposed Multimodal Task Vectors (MTV) method offers a significant advancement by compressing numerous in-context examples into fewer tokens, thus enabling efficient and scalable learning for complex vision-language tasks. This opens new avenues for research and significantly improves the performance of LMMs in various applications. The efficiency gains through the proposed approach also make the research attractive to researchers from a resource constraint viewpoint.
Visual Insights#

This figure illustrates the core idea of Multimodal Task Vectors (MTV). Instead of directly feeding many multimodal examples (images and text) into the Large Multimodal Model (LMM), which is limited by context length, the MTV method compresses these examples into a compact vector representation in the model’s activation space. During inference, this compact MTV vector is directly injected into the LMM’s activation space, bypassing the context length limitation. The figure visually depicts how multiple multimodal examples are compressed into MTV and how this MTV vector is used for downstream inference, resulting in predictions for new inputs.
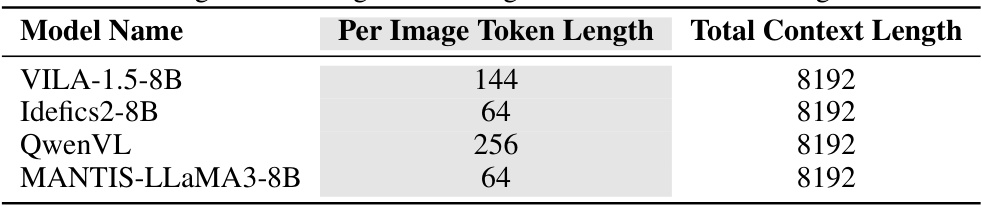
This table shows the number of tokens used to embed a single image and the total context length supported by four different large multimodal models: VILA-1.5-8B, Idefics2-8B, QwenVL, and MANTIS-LLaMA3-8B. The token length per image embedding varies significantly across the models, ranging from 64 tokens to 256 tokens. All models have a total context length of 8192 tokens.
In-depth insights#
MTV: Many-shot ICL#
The concept of “MTV: Many-shot ICL” introduces a novel approach to overcome the context length limitations in large multimodal models (LMMs) during in-context learning (ICL). Traditional ICL struggles with many examples due to the limited context window. MTV cleverly compresses numerous multimodal examples into compact “Multimodal Task Vectors” (MTVs) residing within the LMM’s attention heads. This compression allows LMMs to effectively process significantly more examples than previously possible without requiring model finetuning or modifications. The method involves calculating mean activations from multiple inference iterations and leveraging these to create compact representations for downstream inference, thus scaling ICL to a “many-shot” setting. This approach is particularly effective for vision-language tasks, where image embeddings are particularly demanding, and showcases strong empirical results across various benchmarks. However, the method’s performance might be affected by the quality of the initial ICL examples, making the selection of high-quality examples crucial. The success of MTV suggests a promising direction for improving ICL in LMMs and hints at the existence of compact implicit representations within the models themselves.
Attention Head Use#
The concept of ‘Attention Head Use’ in a multimodal context learning model is crucial. It explores how the model leverages different attention heads to process various modalities (e.g., text, images). Effective attention head usage is key to successful multimodal learning, enabling the model to relate and integrate information from different sources. The research likely investigates the model’s internal representation of information across attention heads, possibly revealing task-specific patterns in their activation. Analyzing ‘Attention Head Use’ could show which heads are most sensitive to specific modalities or aspects of tasks, leading to insights into the model’s reasoning process. This analysis may also reveal redundancy or inefficiency in attention head allocation, providing directions for model optimization and improved performance. Ultimately, understanding ‘Attention Head Use’ offers valuable insights into the model’s inner workings and its ability to learn complex multimodal relationships.
MTV Generalization#
The concept of “MTV Generalization” in the context of multimodal task vectors centers on the ability of these compact representations to transfer knowledge across different tasks. Instead of training separate MTVs for each task, the goal is to learn a generalized MTV that can effectively perform on similar but unseen tasks. This suggests an implicit representation capable of capturing underlying task features rather than task-specific details. The success of this approach would signify a major step towards efficient multimodal few-shot learning, as it reduces the need for extensive fine-tuning or retraining for each new task. Generalization is evaluated by testing the performance of an MTV trained on one dataset or set of tasks on a different, similar dataset, with the degree of successful generalization highlighting the robustness and capacity for broader application of the proposed method.
Efficiency Gains#
Analyzing efficiency gains in the context of a research paper requires a nuanced understanding of the presented methods and their computational cost. A section on efficiency gains would ideally quantify improvements in runtime, memory usage, or other relevant resources. Key metrics such as time complexity (big O notation), memory footprint, and the scalability of the method with increasing data size are essential. The analysis should also consider the trade-off between computational cost and model performance. Specific comparisons to existing methods are crucial, demonstrating whether the new approach provides superior efficiency while maintaining or exceeding the accuracy of alternatives. The paper should also discuss the generalizability of the efficiency gains across different hardware, datasets, and task scales. Experimental setup details, including hardware specifications and the number of runs, are vital for validating reproducibility. Furthermore, discussion of any limitations concerning the observed efficiency gains is necessary, ensuring transparency and highlighting areas for future optimization. Ultimately, a well-structured analysis of efficiency gains needs to provide concrete evidence of improvements, along with a thorough consideration of the context and any limitations.
Future Work#
Future research directions stemming from this work on Multimodal Task Vectors (MTVs) could explore several promising avenues. Improving MTV efficiency is crucial; while MTVs demonstrate effectiveness, reducing computational costs for both extraction and inference would broaden their applicability. Investigating the sensitivity of MTVs to various factors, such as the number of shots, iteration counts, and the quality of examples, warrants further investigation to optimize performance and understand the limitations. Exploring alternative methods for selecting attention head locations and improving the robustness of MTVs to noisy or incomplete data are also important. Extending the application of MTVs to different LMM architectures and exploring their synergy with other techniques, such as prompt engineering or parameter-efficient fine-tuning, could lead to more powerful and versatile multimodal models. Finally, thorough evaluation across a wider range of multimodal tasks and datasets is essential to assess the generalizability and robustness of the MTV approach, ultimately paving the way for broader adoption in real-world applications.
More visual insights#
More on figures

This figure illustrates the three steps of the proposed Multimodal Task Vectors (MTV) method. First, it shows how mean activations are calculated from the last token of multiple inference iterations on a set of many-shot multimodal examples. Second, it demonstrates how attention head locations are selected to best align with the downstream task using an adapted REINFORCE algorithm. Finally, it depicts how these mean activations are directly replaced into the selected attention head locations during downstream inference, enabling many-shot in-context learning without being limited by context length.
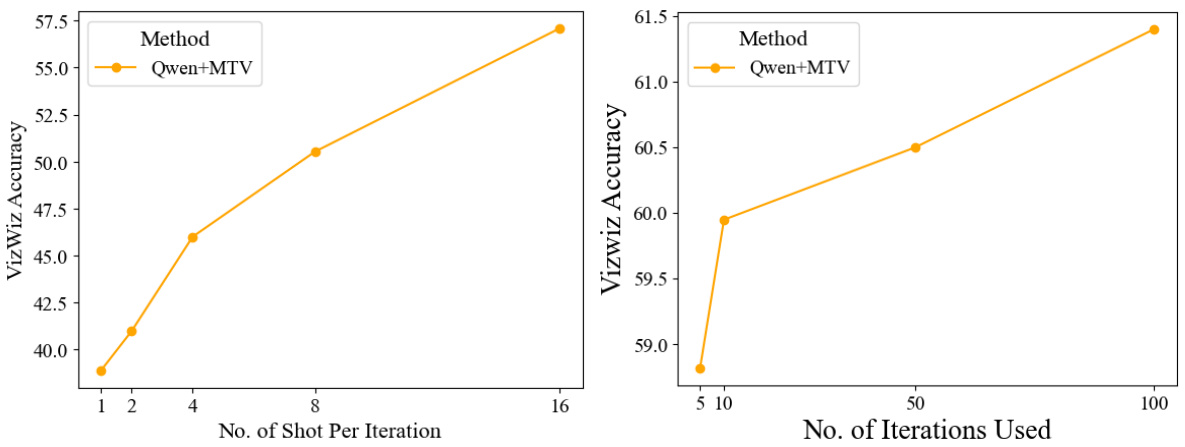
This figure shows the impact of the number of shots per iteration and the number of iterations on the performance of the Qwen-MTV model on the VizWiz dataset. The left panel shows that increasing the number of shots per iteration up to 16 improves performance, after which performance plateaus. The right panel shows that increasing the number of iterations up to 100 also improves performance, after which performance again plateaus. This demonstrates that MTV can effectively scale with more examples.
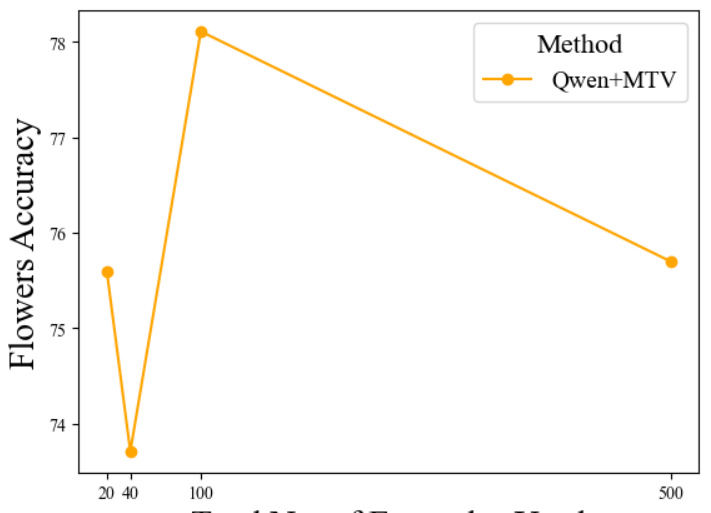
This figure shows the impact of two hyperparameters on the performance of the proposed MTV method. The left panel shows how the number of shots per iteration affects accuracy, while keeping the total number of iterations constant at 100. The right panel illustrates the effect of varying the number of iterations while keeping the shots per iteration fixed at 4. The results demonstrate that MTV’s performance scales with both the number of shots and iterations.

This figure illustrates the three steps of the proposed Multimodal Task Vectors (MTV) method. It addresses the context length limitation in large multimodal models (LMMs) by encoding many shots into fewer tokens. Step 1 calculates the mean activations of the attention heads for the last token of the input examples across multiple inference iterations. Step 2 identifies optimal attention head locations within the model for storing the mean activations, which form the MTV. Finally, Step 3 replaces the original activations in the identified locations with the MTV for downstream inference. This allows the model to effectively utilize many shots without exceeding its context length.
More on tables
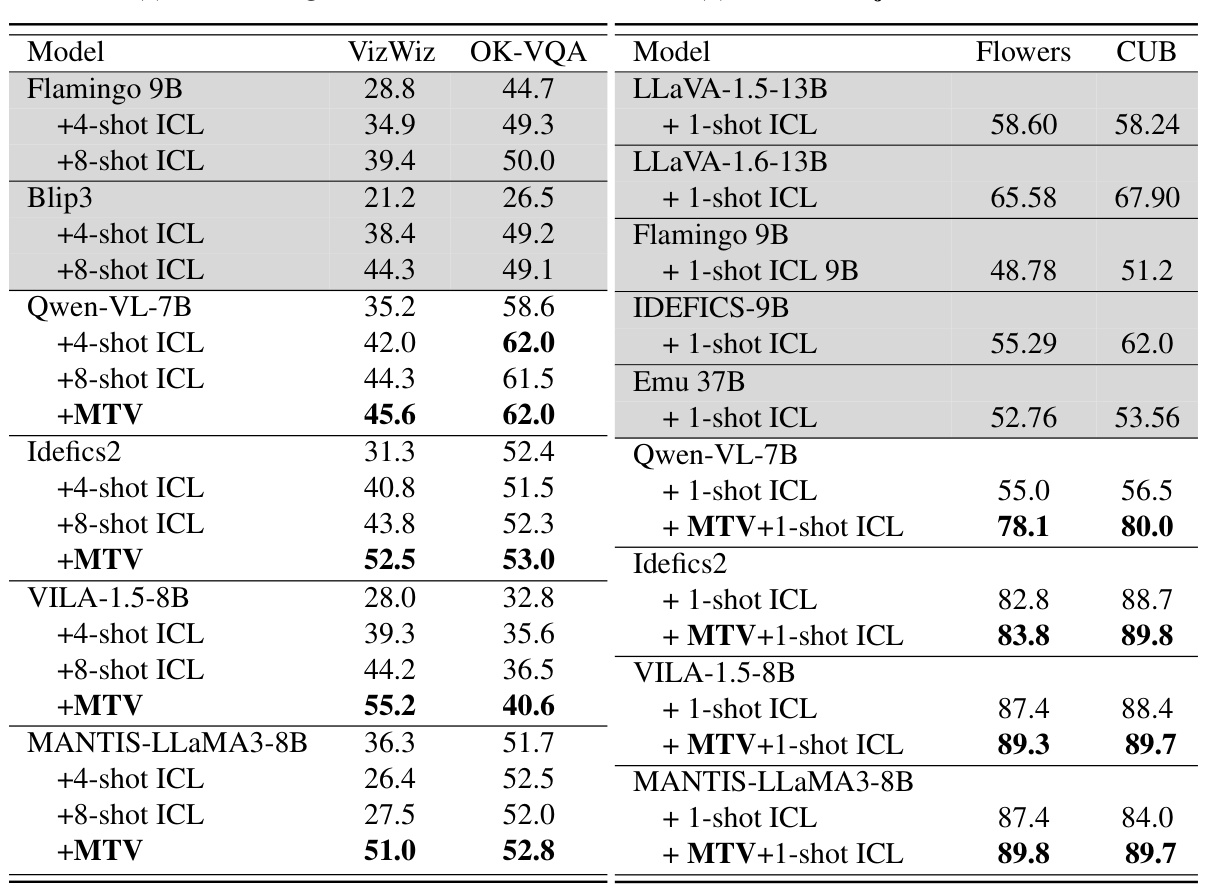
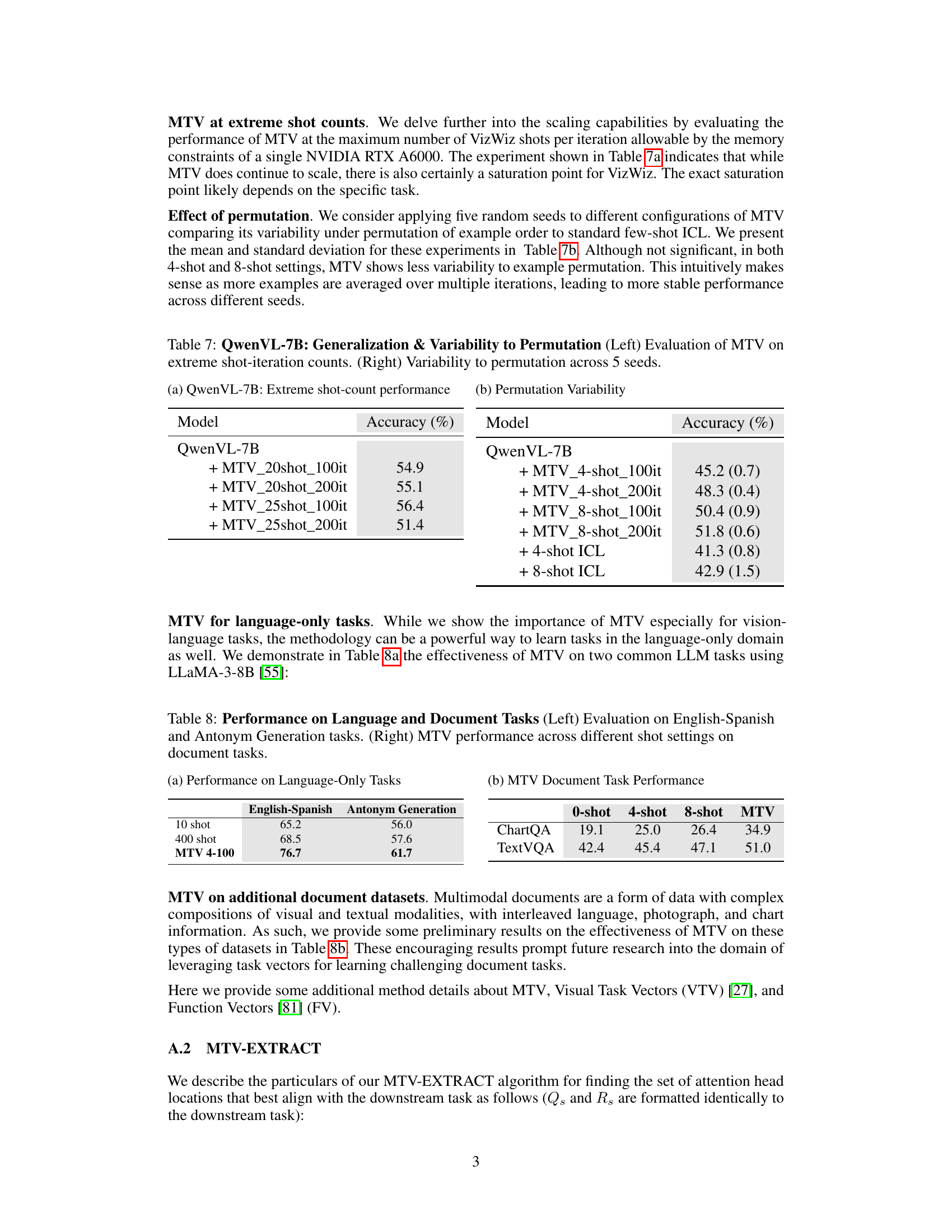
This table presents the results of the Multimodal Task Vector (MTV) method and compares it with several baseline models on two types of tasks: Visual Question Answering (VQA) and object classification. The left half shows the performance on three different VQA datasets (VizWiz, OK-VQA), while the right half shows the results for object classification on two datasets (Flowers, CUB). The table compares the performance of MTV with different numbers of shots in in-context learning (ICL) and a zero-shot setting. The baselines are shown in gray for easy comparison. Each row represents a different model, while the columns indicate the datasets and the performance metrics.
This table presents the performance comparison of the proposed Multimodal Task Vectors (MTV) method against several baseline models on two different types of tasks: Visual Question Answering (VQA) and object classification. The left half shows the results for three VQA datasets (VizWiz, OK-VQA), comparing the performance of different models (Flamingo, BLIP, QwenVL, Idefics, ViLA) with and without the MTV method and varying numbers of shots in in-context learning (ICL). The right half shows results for object classification datasets (Flowers, CUB), again comparing MTV against several models with and without ICL, demonstrating MTV’s ability to scale to many shots and generalize to unseen tasks.

This table presents the performance comparison of Multimodal Task Vectors (MTV) against various baselines on two different types of tasks: Visual Question Answering (VQA) and object classification. The left side shows the results for three different VQA datasets (VizWiz, OK-VQA), comparing MTV’s performance against several models including 4-shot, 8-shot ICL and zero-shot. The right side presents the results for object classification datasets (Flowers, CUB), again showing a comparison against different models using MTV and few-shot ICL methods. The baselines are highlighted in gray for easier comparison.

This table presents a comparison of the maximum GPU memory usage and runtime per 100 iterations for different methods: 0-shot, 4-shot, 8-shot, 16-shot ICL, and the proposed MTV method with 400 shots. It demonstrates that MTV, despite encoding significantly more examples (400), achieves lower memory usage and runtime than the other ICL methods.

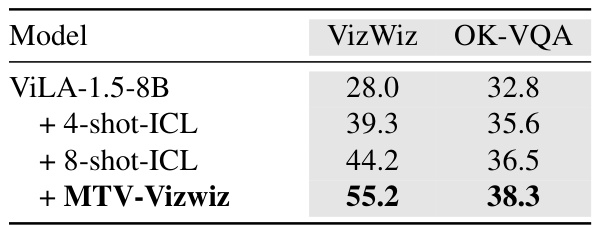
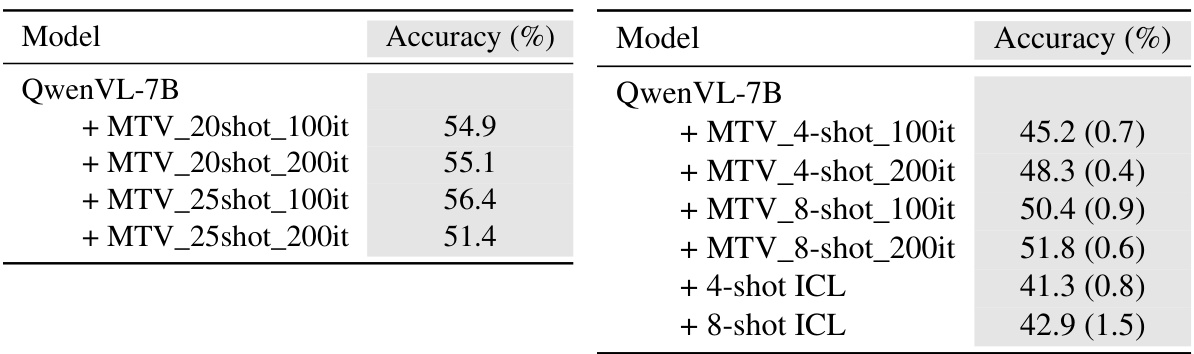
This table presents a comparison of different experimental setups to highlight the impact of shot quality and the robustness of MTV to noisy examples. It shows how accuracy changes with the number of in-context learning (ICL) shots used, demonstrating the diminishing returns of simply increasing the number of shots. It also shows that using higher quality shots improves the effectiveness of MTV, and demonstrates the relative stability of the MTV approach compared to standard ICL when noisy data is included.
This table presents the results of the Multimodal Task Vector (MTV) method compared to baselines (shown in gray) on various vision and language tasks. The left side shows results on Visual Question Answering (VQA) datasets (VizWiz and OK-VQA), while the right side shows results on object classification datasets (Flowers and CUB). For each dataset and model, multiple baselines and MTV methods are compared, demonstrating the effectiveness of the MTV approach in improving accuracy across different tasks.

This table presents the results of the Multimodal Task Vector (MTV) method and several baselines on various vision-and-language tasks. The left side shows results for Visual Question Answering (VQA) on three different datasets (VizWiz, OK-VQA), comparing MTV’s performance against baseline methods (few-shot ICL) and other models like Flamingo. The right side shows results for object classification on the Flowers and CUB datasets, again comparing MTV to baselines. Gray shading indicates baseline performance for comparison.
This table presents the results of the Multimodal Task Vector (MTV) method and compares it to various baselines (few-shot ICL methods) on two different types of tasks: Visual Question Answering (VQA) and Object Classification. The left side shows the performance of MTV on three different VQA datasets (VizWiz, OK-VQA), while the right side shows the performance on two object classification datasets (Flowers, CUB). The results are presented for different models and different numbers of shots used in the baseline few-shot ICL methods. The grayed-out rows represent the baseline results without MTV.

This table presents the results of applying the Multimodal Task Vector (MTV) method and standard few-shot in-context learning (ICL) to language-only tasks. The left side shows the performance on English-Spanish translation and antonym generation tasks, while the right side shows the performance on document tasks using different numbers of shots (0-shot, 4-shot, 8-shot, and MTV 4-100). The results demonstrate the effectiveness of MTV in improving performance on these tasks compared to traditional few-shot ICL.

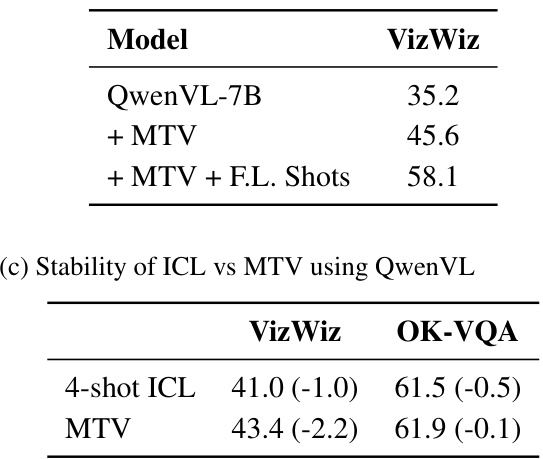
This table presents the performance of Multimodal Task Vectors (MTV) on document-related tasks, comparing it against various few-shot settings (0-shot, 4-shot, 8-shot) for two specific tasks: ChartQA and TextVQA. The results highlight MTV’s ability to improve performance compared to standard few-shot methods by encoding many-shot examples implicitly in the model’s activations.
Full paper#