↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
3D Gaussian Splatting (3DGS) excels at novel view synthesis, offering fast rendering and high fidelity. However, the large number of Gaussians and their attributes demand efficient compression techniques. Existing methods often compress these individually, overlooking spatial dependencies. This leads to significant storage overhead and limits the scalability of 3DGS for large-scale scenes.
This paper proposes ContextGS, which uses an autoregressive model at the anchor level to tackle the spatial redundancy issue. Anchors are hierarchically divided into levels; coarser levels predict finer ones, leading to more efficient coding. The method also incorporates a hyperprior for effective compression of coarsest level anchors. ContextGS demonstrates remarkable compression ratios (up to 15x), faster rendering speeds, and improved rendering quality compared to previous state-of-the-art approaches.
Key Takeaways#
Why does it matter?#
This paper is significant because it introduces a novel compression technique for 3D Gaussian Splatting (3DGS), a cutting-edge method for novel view synthesis. By leveraging an autoregressive context model at the anchor level, ContextGS achieves a remarkable size reduction of up to 15 times compared to existing state-of-the-art methods, while maintaining or improving rendering quality and speed. This work is highly relevant to researchers in computer graphics, 3D visualization, and compression, offering a significant advancement in handling and processing large 3D datasets.
Visual Insights#

This figure illustrates the need for an autoregressive model at the anchor level for 3D Gaussian Splatting compression. It shows that even though Scaffold-GS reduces spatial redundancy, some still exists among anchors. ContextGS addresses this by using an autoregressive model and dividing anchors into levels, where coarser levels predict finer levels. The figure includes visualizations of a rendered image, anchor division into levels, cosine similarity between anchors, and bit savings achieved by ContextGS compared to Scaffold-GS.

This table presents a quantitative comparison of the proposed ContextGS method against several baseline and state-of-the-art 3DGS compression techniques. It shows PSNR, SSIM, LPIPS, and model size (in MB) for various datasets, highlighting the superior performance of ContextGS in terms of both compression ratio and rendering quality. Two variants of ContextGS are shown, representing a trade-off between compression and fidelity.
In-depth insights#
3DGS Compression#
3D Gaussian Splatting (3DGS) offers compelling speed and visual fidelity for novel view synthesis, but its large memory footprint due to numerous Gaussians is a significant limitation. Effective compression is thus crucial for practical applications. Existing methods mainly focus on individually compressing Gaussians, neglecting spatial redundancy. ContextGS tackles this by introducing an autoregressive context model at the anchor level, significantly improving compression efficiency. By hierarchically dividing anchors and predicting uncoded anchors based on already coded ones, ContextGS leverages spatial dependencies to reduce redundancy. Further enhancements include entropy coding and a low-dimensional hyperprior for efficient encoding. The effectiveness of this approach is demonstrated through substantial size reduction and comparable or improved rendering quality compared to existing methods, showcasing a significant advancement in 3DGS compression.
Anchor Level Context#
The concept of “Anchor Level Context” in 3D Gaussian Splatting (3DGS) compression involves a hierarchical approach to encoding scene geometry, leveraging spatial redundancy between anchors. Instead of compressing individual 3D Gaussians independently, anchors encapsulate the features of neighboring Gaussians, reducing redundancy and improving compression efficiency. The “level” aspect introduces a multi-scale representation, where coarser-level anchors predict finer-level anchors, using autoregressive modeling. This predictive nature significantly reduces the number of bits required, especially for regions with high similarity among anchors. The use of anchor-level context is a notable advancement over methods solely focusing on individual Gaussian compression, thus enabling substantial size reduction while maintaining high rendering quality. This multi-level, predictive approach is a key strength in achieving effective compression ratios and faster rendering speeds for 3DGS.
Autoregressive Modeling#
Autoregressive modeling, in the context of 3D Gaussian splatting compression, offers a powerful approach to reduce spatial redundancy. By leveraging the inherent dependencies between neighboring data points, this method predicts the properties of yet-uncoded anchors based on already processed ones. This is particularly effective for hierarchical anchor structures, where coarser-level anchors inform predictions for finer levels. The autoregressive approach significantly improves compression ratios by reducing the amount of information needing explicit encoding, leading to smaller file sizes without compromising rendering quality. Predictive power is enhanced further by incorporating contextual information from multiple anchor levels, creating a more nuanced and accurate representation of the scene. This method’s efficiency stems from its ability to exploit the statistical correlations present in the data, resulting in a more compact and efficient 3D model representation.
Entropy Coding#
Entropy coding, a cornerstone of data compression, aims to represent data using a number of bits proportional to its probability. In the context of 3D Gaussian splatting compression, efficient entropy coding is crucial due to the large number of Gaussians and their associated attributes. The choice of entropy coding method significantly impacts the compression ratio and reconstruction quality. The paper likely explores various entropy coding techniques, possibly comparing their performance in terms of compression efficiency and speed. The effectiveness of the chosen method depends on the statistical properties of the data, thus, adaptive methods that learn and adjust to the characteristics of the data may be favored for higher efficiency. Context modeling, by leveraging dependencies between data points, enables prediction and further reduces entropy, leading to better compression. The interplay between the autoregressive model and the chosen entropy coding strategy is a key factor to evaluate. Finally, the paper probably presents a quantitative analysis demonstrating improvements achieved by their proposed method in compression ratio and perceptual quality as compared to conventional methods. The careful selection of entropy coding is pivotal to achieving a balance between compression performance and computational efficiency.
Future Directions#
Future research could explore several promising avenues. Improving the autoregressive model’s efficiency is crucial, perhaps through more sophisticated context modeling or better quantization techniques. Exploring different anchor partitioning strategies beyond the hierarchical approach could unlock further compression gains. Investigating alternative neural representations beyond 3D Gaussians, while maintaining real-time rendering capabilities, is another key direction. Finally, extending the approach to handle dynamic scenes and more complex geometries represents a significant challenge and a rich area for future research. Addressing these aspects would enhance the method’s versatility and scalability.
More visual insights#
More on figures

This figure illustrates the data structure used in the proposed method and its comparison with the Scaffold-GS method. (a) shows how Scaffold-GS uses anchor points to capture common features of associated neural Gaussians, while (b) presents the proposed multi-level anchor division, where decoded anchors from coarser levels are used to predict finer-level anchors, thus reducing spatial redundancy and storage.
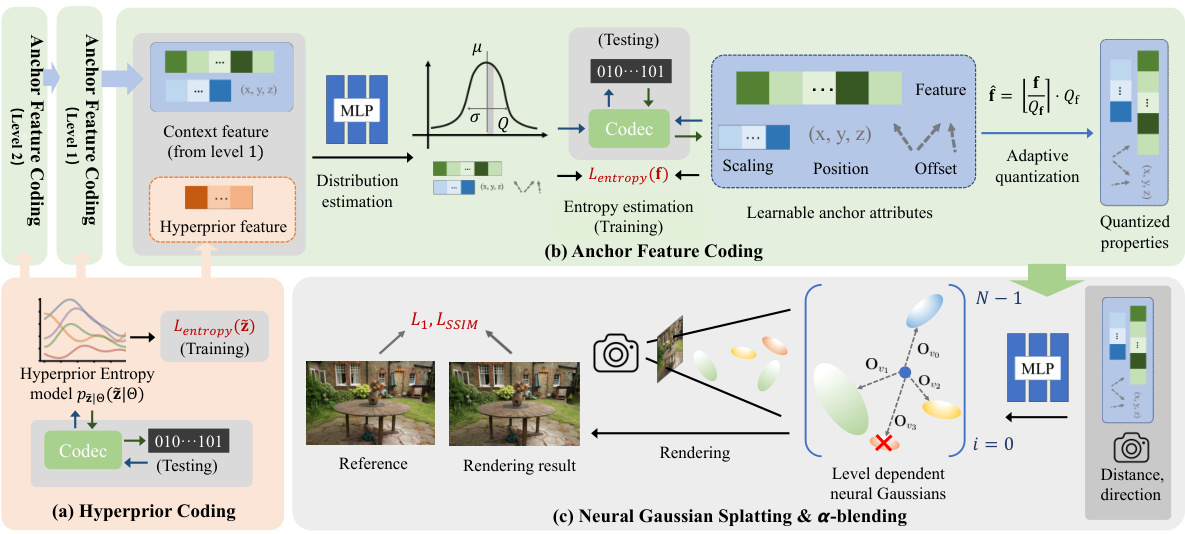
This figure illustrates the overall framework of the ContextGS method. It consists of three main parts: (a) Hyperprior coding, (b) Anchor feature coding, and (c) Neural Gaussian splatting & α-blending. The hyperprior coding stage uses a hyperprior model to predict and encode the properties of anchors. The anchor feature coding stage uses an autoregressive model, where decoded anchors from coarser levels are used to predict anchors at finer levels, and features are adaptively quantized for efficient entropy coding. Finally, the neural Gaussian splatting & α-blending stage renders the scene using the decoded anchor attributes and neural Gaussians.

This figure shows visual comparisons of novel view synthesis results between the proposed method (ContextGS) and several baselines (Scaffold-GS, HAC, Compact3DGS) on two datasets (BungeeNeRF and Tanks & Temples). For each scene, a reference image is presented alongside the reconstructions from each method. The PSNR (Peak Signal-to-Noise Ratio) and model size in MB are provided for quantitative comparison. The images highlight the visual quality and compression achieved by each method.
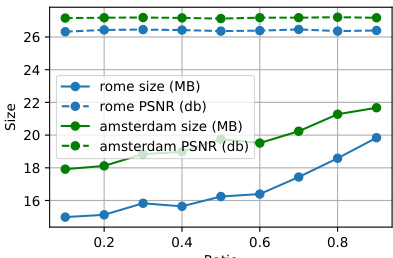
This figure shows the ablation study on the effect of different target ratios (τ) on the model’s performance. The x-axis represents the target ratio, and the y-axis shows the size (in MB) and PSNR (dB) for two different scenes (‘rome’ and ‘amsterdam’). The results indicate that PSNR remains relatively stable across different target ratios, while the size of the model changes. This experiment demonstrates the robustness and efficiency of the proposed model in handling varied target ratios, confirming the effectiveness of the proposed approach.
More on tables

This table presents an ablation study evaluating the impact of different components of the proposed ContextGS model on the BungeeNerf dataset. It compares the performance (size, PSNR, SSIM, LPIPS) of the full model against versions without the hyperprior (HP), without the context model (CM), and without both. The baseline, ‘Ours w/o HP w/o CM’, is essentially a Scaffold-GS model enhanced with entropy coding and masking loss.

This table presents the ablation study of the proposed method by removing the anchor level division and anchor reusing (forwarding) components. It shows the impact of these components on the model’s size (in MB), Peak Signal-to-Noise Ratio (PSNR), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS) metrics, evaluated using the BungeeNerf dataset. The results highlight the contribution of each component to the overall performance.

This table presents a quantitative comparison of the proposed method (ContextGS) against baselines on the ‘rome’ scene from the BungeeNerf dataset. It breaks down the storage cost into various components (hyperprior, position, features, scaling, offset, mask, and MLPs), providing the total storage cost in megabytes (MB) for each method. It also includes fidelity metrics (PSNR, SSIM) and encoding/decoding speeds in seconds (s) measured using an RTX3090 GPU.

This table presents a quantitative comparison of the proposed ContextGS method against several baseline and state-of-the-art 3DGS compression techniques across multiple datasets. Metrics include PSNR, SSIM, LPIPS, and model size (in MB). Two versions of ContextGS are shown, representing different compression ratios (low-rate and high-rate). The best and second-best results for each metric are highlighted.

This table presents a quantitative comparison of the proposed ContextGS method against several baseline and competing 3DGS compression techniques across multiple datasets. It shows PSNR, SSIM, LPIPS scores, and model size (in MB). Two versions of ContextGS are shown, representing a tradeoff between compression ratio and fidelity.
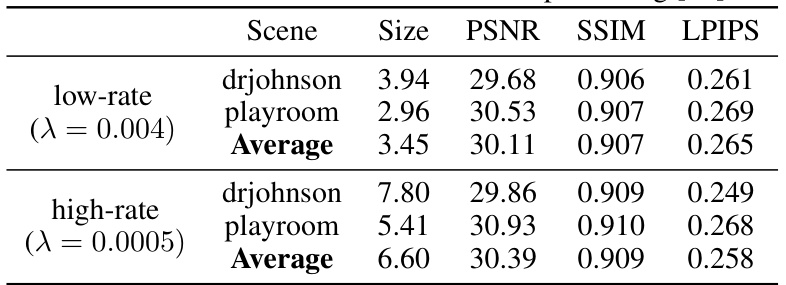
This table presents a quantitative evaluation of the proposed ContextGS method on the DeepBlending dataset. It shows the performance of the model at different compression ratios (low-rate and high-rate). The metrics used for evaluation are PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), and LPIPS (Learned Perceptual Image Patch Similarity). The results are broken down for two different scenes (drjohnson and playroom) and an average of the two is provided for each compression setting. This helps assess the impact of the compression rate on visual quality.

This table presents a quantitative evaluation of the proposed ContextGS method on the Tanks & Temples dataset [16]. It shows the performance for two different compression ratios (low-rate and high-rate), each with results broken down by scene (train and truck) and overall average. The metrics reported are the size of the compressed model (Size, in MB), Peak Signal-to-Noise Ratio (PSNR, in dB), Structural Similarity Index (SSIM), and Learned Perceptual Image Patch Similarity (LPIPS). This table allows for comparison of compression efficiency against perceptual quality across varying compression levels.

This table presents a quantitative comparison of the proposed ContextGS method against several baseline and state-of-the-art 3DGS compression techniques across multiple datasets. It compares PSNR, SSIM, LPIPS, and model size (in MB). Two versions of the ContextGS model are shown, representing different size/fidelity trade-offs. The best and second-best results for each metric are highlighted.
Full paper#



















