↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Traditional causal discovery methods struggle with real-world applications due to the lack of well-defined, high-quality variables, often requiring expert knowledge to define relevant factors. This limitation hinders broader use in fields like analyzing user reviews or medical diagnosis.
The proposed COAT framework tackles this issue by integrating large language models (LLMs). LLMs process unstructured data (e.g., text reviews) to suggest high-level factors and their measurement criteria. A causal discovery algorithm identifies causal relationships between these factors, with feedback iteratively refining the LLM’s factor proposals. This approach demonstrates significant improvement over existing methods in various real-world case studies, showcasing the mutual benefits of LLMs and causal discovery.
Key Takeaways#
Why does it matter?#
This paper is crucial because it bridges the gap between causal discovery and large language models (LLMs). By using LLMs to propose high-level factors from unstructured data, it expands the applicability of causal discovery to real-world problems where high-quality variables are scarce. This opens exciting avenues for future research by integrating LLMs into various causal inference tasks.
Visual Insights#

This figure illustrates the COAT (Causal representation AssistanT) framework’s three stages: factor proposal, factor annotation, and causal discovery & feedback construction. In the factor proposal stage, an LLM (Large Language Model) proposes high-level factors (like size and aroma) relevant to apple ratings. These factors, along with annotation guidelines, are then used by another LLM in the factor annotation stage to structure the unstructured user reviews into a usable format. Finally, the causal discovery and feedback construction stage uses causal discovery (CD) algorithms to identify causal relationships between the proposed factors and the ratings. The system iteratively refines the proposed factors using feedback from the CD algorithm, improving the accuracy of the causal relationships discovered.

This table presents the quantitative results of causal relation extraction in the AppleGastronome benchmark. For various LLMs (GPT-4, GPT-3.5, Mistral-Large, etc.), it shows the performance of both direct LLM reasoning (PAIRWISE) and the COAT framework (COAT). The metrics used are Structural Hamming Distance (SHD), Structural Intervention Distance (SID), and the F1 score for pairwise causal relation accuracy. Lower SHD and SID values indicate better performance. Higher F1 scores indicate better accuracy in identifying the causal relationships.
In-depth insights#
Hidden World Unveiled#
The concept of a ‘Hidden World Unveiled’ in the context of research papers likely refers to the discovery of previously unknown or inaccessible information or patterns. This could involve several aspects. Novel methodologies might be employed to reveal hidden relationships within existing datasets. Advanced computational techniques, such as machine learning or causal inference, could unearth previously obscured insights. Unstructured data sources, such as text, images, or social media posts, could be analyzed to expose hidden patterns indicative of a hidden world of previously unknown meaning. The unveiling might also concern hidden causal relationships that explain the interactions between variables or the emergence of certain phenomena. This would represent a significant advance in understanding complex systems and could have important implications across various fields. Furthermore, the phrase suggests the impact of this discovery, emphasizing its transformative nature and the potential for breakthroughs in knowledge and applications. Therefore, the unveiling of this ‘hidden world’ is not just a technical feat but also a conceptual leap that can reshape our understanding of the world around us. The methods used would need to be sophisticated enough to handle noise and uncertainty inherent in many data sources, and the interpretation of findings would have to be nuanced and sensitive to potential biases in the data or the analytical approach.
LLM-CD Synergy#
LLM-CD synergy explores the powerful combination of Large Language Models (LLMs) and Causal Discovery (CD) methods. LLMs excel at processing and understanding unstructured data, extracting relevant information from sources like text or images, a task often challenging for traditional CD methods that require structured data. CD methods provide a framework for identifying causal relationships, but often need high-quality, well-defined variables. The synergy lies in how LLMs can pre-process and annotate unstructured data, generating high-level features and variables suitable for CD algorithms. This reduces the burden on human experts, expanding the applications of causal analysis to a wider range of complex datasets. However, challenges remain: LLMs can hallucinate information, requiring careful validation and post-processing. The reliability of LLM-based feature extraction also needs to be rigorously assessed. Further research should focus on developing methods to mitigate these limitations, potentially through incorporating feedback loops between the LLM and CD algorithm to iteratively refine feature extraction and improve the accuracy of causal inference. This integration is key to realizing the full potential of LLM-CD synergy, making causal analysis more accessible and applicable to real-world problems.
COAT Framework#
The COAT framework represents a novel approach to causal discovery, cleverly integrating large language models (LLMs) with traditional causal discovery algorithms. Its core strength lies in bridging the gap between readily available unstructured data and the need for high-quality, well-defined variables usually required by causal discovery methods. LLMs are leveraged to propose high-level factors, interpreting complex, unstructured data (like customer reviews), and suggesting relevant variables for analysis. This process is iterative; causal discovery algorithms provide feedback to refine the factors proposed by the LLM, creating a synergistic loop. The framework’s effectiveness is demonstrated through both synthetic simulations and real-world applications, indicating its robustness and reliability in extracting meaningful causal relationships from complex data. This is particularly valuable in contexts lacking pre-defined variables, enabling COAT to unlock valuable insights in domains where traditional methods are limited. The use of LLMs to propose high-level variables makes COAT innovative and practical. The mutually beneficial interaction between LLMs and causal discovery algorithms forms a key strength of the COAT framework.
Benchmark Analysis#
A robust benchmark analysis is crucial for evaluating the effectiveness of a novel causal discovery approach. It should involve diverse datasets representing various real-world scenarios, including both synthetic and real-world data. The synthetic data allows for controlled experimentation and ground truth verification, while real-world data assesses generalizability and practical applicability. Metrics for evaluation must be carefully chosen and clearly defined, encompassing both quantitative measures (e.g., precision, recall, F1-score for causal structure recovery) and qualitative aspects (e.g., interpretability and plausibility of discovered relationships). The analysis should compare the new method against existing state-of-the-art techniques, highlighting both strengths and weaknesses. Statistical significance should be rigorously established, using appropriate tests to account for variability. Finally, the analysis should discuss limitations and potential biases inherent in the benchmark datasets themselves, thus ensuring a comprehensive and unbiased evaluation.
Future of COAT#
The future of COAT hinges on addressing its current limitations and capitalizing on its strengths. Improving the LLM component is crucial; more sophisticated LLMs with enhanced causal reasoning capabilities and better control over hallucination are needed. This may involve fine-tuning LLMs on specific causal reasoning tasks or integrating techniques like chain-of-thought prompting to enhance their ability to propose meaningful, non-overlapping high-level variables. Addressing data limitations is also essential. COAT currently relies on specific data structures; future development could focus on making it more robust and adaptable to various data types and formats, including unstructured and heterogeneous data. Expanding the scope of COAT to encompass more complex causal inference problems, such as discovering complete causal graphs instead of just Markov blankets, will be a key area of future research. This would involve integrating more advanced causal discovery algorithms and potentially incorporating techniques for handling latent confounders and selection bias. Finally, rigorous theoretical analysis and exploration are needed to further enhance the reliability and theoretical guarantees of COAT, along with broader empirical validation on diverse real-world datasets to fully demonstrate its generalizability and effectiveness.
More visual insights#
More on figures

This figure illustrates the COAT (Causal representation AssistanT) framework. COAT uses LLMs to identify high-level factors influencing apple ratings from unstructured reviews, then uses a causal discovery (CD) algorithm to find relationships between factors. A feedback loop refines the process iteratively. The three stages are shown: (a) factor proposal by LLM, (b) factor annotation by LLM, and (c) causal discovery and feedback construction by the CD algorithm, enabling the LLM to improve factor identification.

This figure illustrates how COAT discovers latent variables using feedback from causal discovery. It shows four scenarios involving a target variable Y, an identified variable W, and a latent variable w. The scenarios illustrate how finding samples that are not well-explained by the current model (Y | X | h<t(X)) can help uncover latent causal relationships, particularly when w is a parent or child of Y, or when there are confounding relationships between W and w.
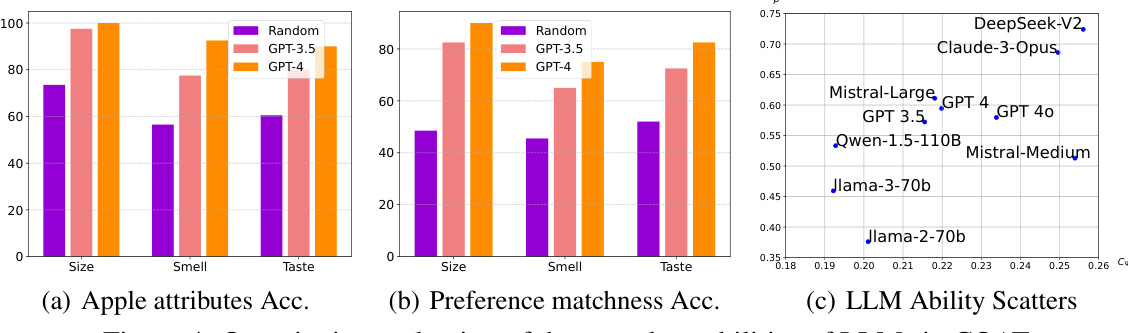
This figure quantitatively evaluates the causal capabilities of various Large Language Models (LLMs) within the COAT framework. It presents three subfigures. (a) shows the accuracy of Apple attributes prediction, comparing different LLMs and a random baseline. (b) displays the accuracy of preference matching, again comparing LLMs and a random baseline. (c) provides a scatter plot illustrating the relationship between the ‘perception score’ and ‘capacity score’ of each LLM, offering a visualization of their overall causal reasoning abilities within the COAT system.
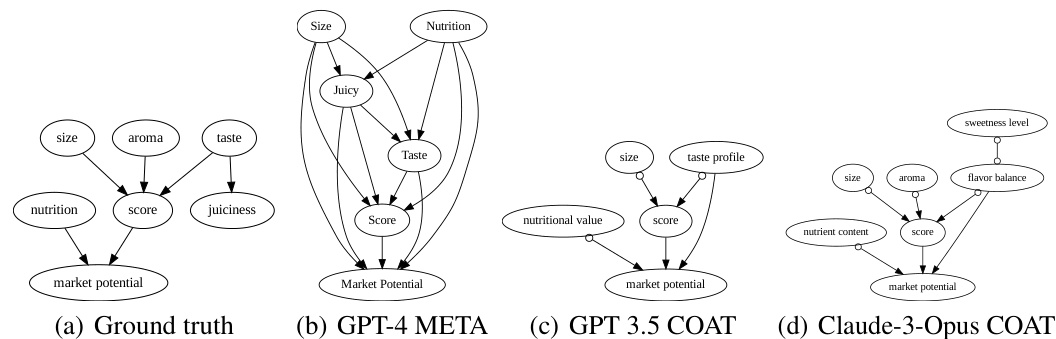
This figure compares causal graphs generated by different methods for analyzing apple ratings. The ‘ground truth’ shows the actual relationships between factors influencing the ratings. The ‘GPT-4 META’ graph shows the causal relationships identified by simply using a large language model (LLM). The ‘GPT-3.5 COAT’ and ‘Claude-3-Opus COAT’ graphs depict the results obtained using the Causal representation AssistanT (COAT) framework. COAT demonstrates improved accuracy and recall in identifying the true causal relationships, suggesting that the LLM-assisted approach is more effective than using LLMs alone.

This figure illustrates the COAT (Causal representation AssistanT) framework’s workflow for analyzing apple ratings. It highlights three stages: 1. Factor Proposal (a): An LLM analyzes reviews to suggest high-level factors influencing the ratings (e.g., size, smell). 2. Factor Annotation (b): Another LLM annotates the reviews based on the proposed factors. 3. Causal Discovery & Feedback (c): A causal discovery algorithm identifies causal relationships between the factors. Feedback is constructed from samples unexplained by current factors, iteratively refining the process. The goal is to uncover the Markov Blanket (a set of factors that explains the target variable - score)

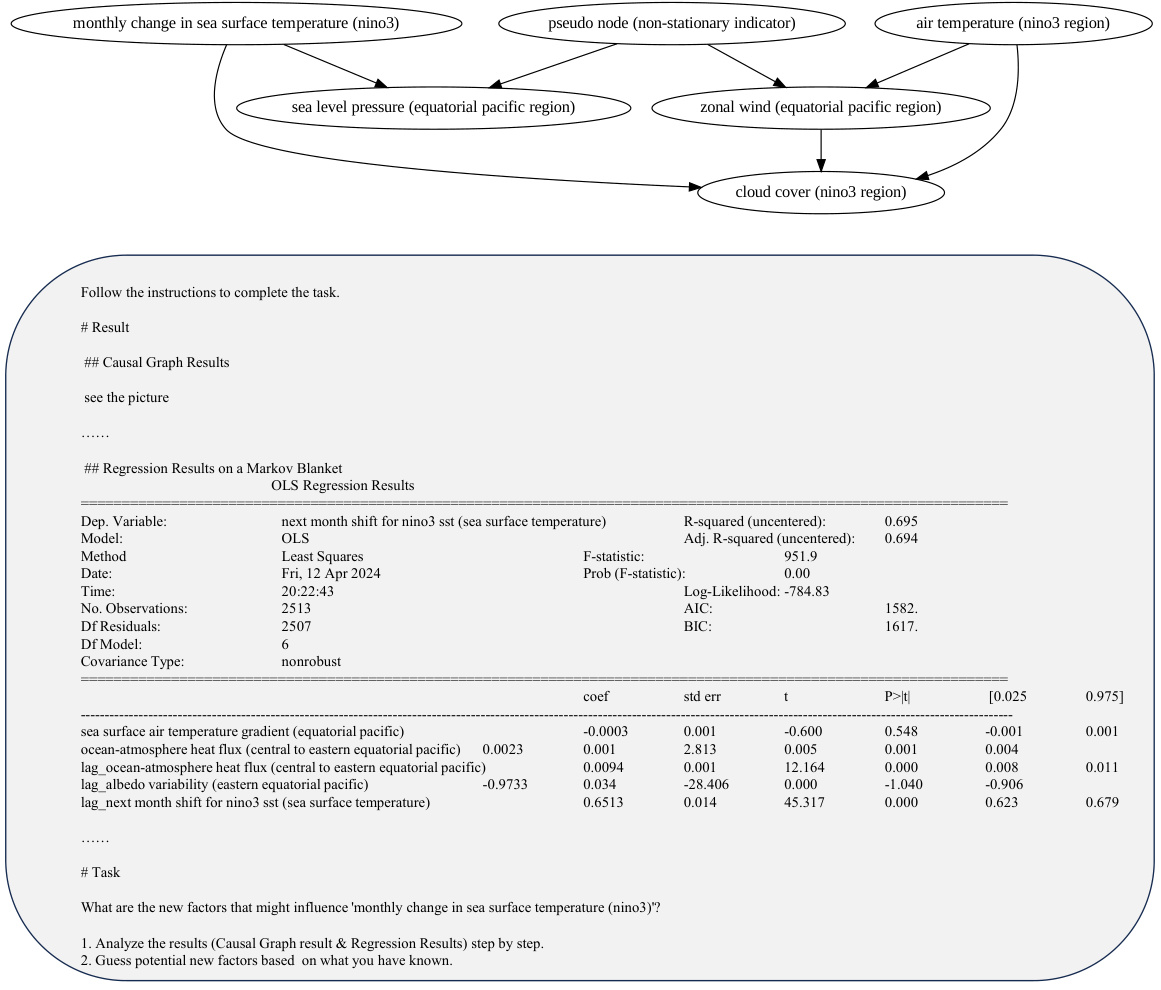
This figure shows a causal graph of climate factors related to ENSO (El Niño-Southern Oscillation). The graph illustrates the relationships between various factors like air temperature, cloud cover, soil moisture, sea level pressure, and wind components, and how they influence the change in sea surface temperature (SST) in the Nino3 region, a key indicator of ENSO events. The nodes are categorized into three regions: Equatorial Pacific Region, Nino3 Region, and South American Coastal Region. Different node shapes indicate whether the factor is stationary (circle) or non-stationary (diamond).

This figure illustrates the COAT (Causal representation AssistanT) framework. COAT uses LLMs (Large Language Models) and causal discovery algorithms to identify the factors influencing a target variable (apple ratings in this example). The process involves three steps: (a) Factor Proposal: LLMs analyze reviews to propose high-level factors. (b) Factor Annotation: LLMs annotate the unstructured reviews according to the defined factors. (c) Causal Discovery & Feedback: A causal discovery algorithm identifies causal relations between factors. If the ratings aren’t well-explained by existing factors, feedback is generated to refine the proposed factors iteratively. This iterative process refines the causal model and factor identification.

This figure illustrates the COAT (Causal representation AssistanT) framework. COAT uses LLMs (Large Language Models) to identify high-level factors influencing a target variable (apple ratings in this example). The LLMs propose factors, annotate data according to those factors, and then a causal discovery (CD) algorithm identifies causal relationships. The CD algorithm also provides feedback to the LLMs, which iteratively refines the proposed factors and helps discover more relevant causal relationships.

The figure illustrates the COAT (Causal representation AssistanT) framework. COAT uses LLMs (Large Language Models) to identify high-level factors relevant to a target variable (in this case, apple ratings). The LLMs propose potential factors, then annotate unstructured data (reviews) to create structured data, and finally, a causal discovery algorithm identifies causal relations between the factors. The process iteratively refines the factors through feedback between the LLMs and causal discovery.

This figure illustrates the COAT (Causal representation AssistanT) framework. It shows a three-stage process: 1. Factor Proposal: An LLM analyzes unstructured data (e.g., apple reviews) to suggest high-level factors relevant to the target variable (apple rating). 2. Factor Annotation: Another LLM annotates the data according to the proposed factors, converting unstructured text into structured data. 3. Causal Discovery & Feedback: A causal discovery algorithm identifies causal relationships between factors, and any unexplained ratings provide feedback to the LLM, iteratively refining the factor selection and annotation until a satisfactory Markov blanket is found. The feedback loop between the LLMs and the causal discovery algorithm is central to COAT’s iterative refinement.

This figure illustrates the COAT framework’s three main steps: factor proposal, factor annotation, and causal discovery & feedback construction. It uses the example of AppleGastronome ratings to show how LLMs are used to propose and annotate high-level factors from unstructured reviews, which are then used by causal discovery algorithms to find causal relationships. The process is iterative, with feedback from the causal discovery step used to refine the factor proposals. This iterative process helps to uncover the underlying causal mechanisms associated with the AppleGastronome ratings.

This figure illustrates the COAT (Causal representation AssistanT) framework’s workflow for analyzing apple rating scores. It shows three stages: 1) Factor Proposal: LLMs process reviews to suggest high-level factors (like size or aroma) and annotation guidelines. 2) Factor Annotation: Another LLM annotates reviews based on the proposed factors. 3) Causal Discovery & Feedback: A causal discovery algorithm identifies causal relations among factors and uses unexplained ratings to provide feedback for iterative LLM refinement, aiming to discover the complete Markov blanket.
This figure illustrates the COAT (Causal representation AssistanT) framework’s workflow for analyzing apple ratings. It shows three stages: 1) Factor Proposal: Using an LLM to propose relevant factors (size, aroma) from unstructured reviews; 2) Factor Annotation: Another LLM structures the reviews based on these factors; 3) Causal Discovery & Feedback Construction: A causal discovery algorithm identifies causal relationships and provides feedback to the initial LLM, iteratively refining factor selection and uncovering the underlying causal structure.

This figure illustrates the COAT (Causal representation AssistanT) framework’s workflow for analyzing apple ratings. It showcases the three main stages: Factor Proposal (LLM suggests high-level factors from reviews), Factor Annotation (another LLM structures the unstructured reviews based on those factors), and Causal Discovery & Feedback Construction (a causal discovery algorithm identifies causal relationships and provides feedback to refine the LLM’s factor proposals). The iterative process aims to identify the complete Markov blanket for the target variable (apple rating) by leveraging the strengths of LLMs and causal discovery algorithms.
This figure illustrates the COAT (Causal representation AssistanT) framework’s three stages: 1. Factor Proposal: An LLM processes reviews to suggest high-level factors influencing apple ratings and annotation guidelines. 2. Factor Annotation: Another LLM annotates reviews based on proposed factors. 3. Causal Discovery & Feedback: A causal discovery (CD) algorithm identifies causal relationships; unexplained ratings trigger feedback to refine the LLM’s factor proposals.
This figure illustrates the COAT (Causal representation AssistanT) framework’s three stages: First, an LLM proposes high-level factors related to apple ratings (size, smell, etc.) from user reviews, including annotation guidelines. Second, another LLM annotates the unstructured reviews using these factors. Finally, a causal discovery (CD) algorithm identifies causal relationships between the factors, and feedback from unexplained ratings refines the factor selection process, iteratively improving accuracy.
This figure illustrates the COAT (Causal representation AssistanT) framework’s workflow for analyzing apple ratings. It demonstrates a three-step process: 1) Factor Proposal (LLM proposes high-level factors from unstructured reviews), 2) Factor Annotation (LLM structures the unstructured reviews based on proposed factors), and 3) Causal Discovery & Feedback Construction (Causal Discovery algorithms identify causal relationships, and feedback refines factor proposals iteratively).
This figure illustrates the COAT (Causal representation AssistanT) framework’s three main steps: 1) Factor Proposal: An LLM analyzes user reviews to identify high-level factors influencing apple ratings. 2) Factor Annotation: Another LLM annotates the unstructured reviews based on the proposed factors. 3) Causal Discovery & Feedback Construction: A causal discovery (CD) algorithm identifies causal relationships between factors and provides feedback to the LLM to refine factor proposals iteratively.
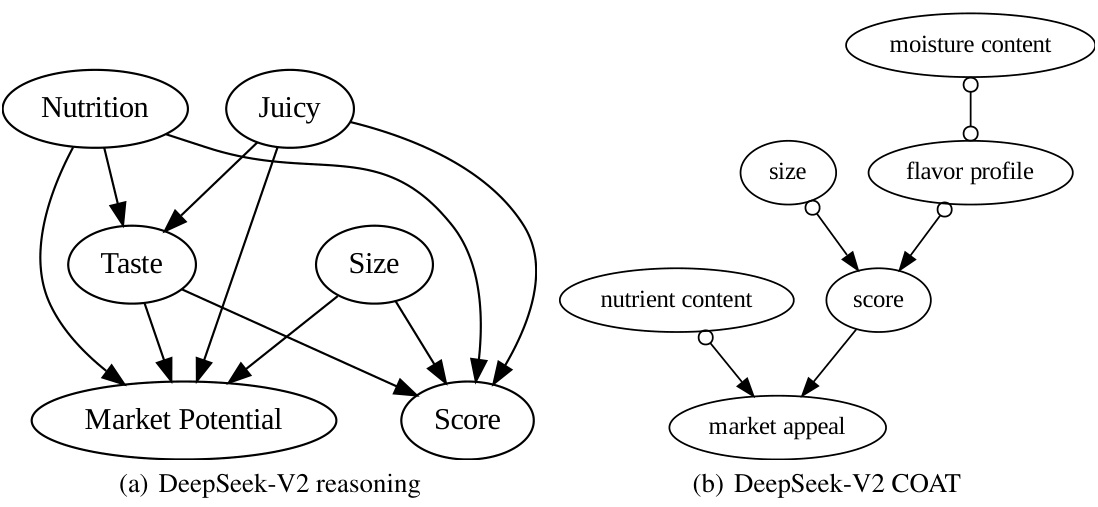
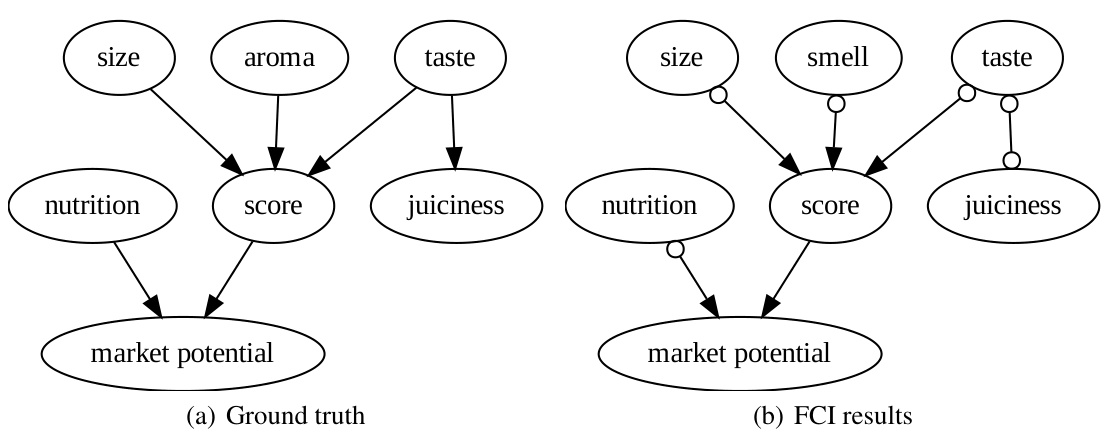
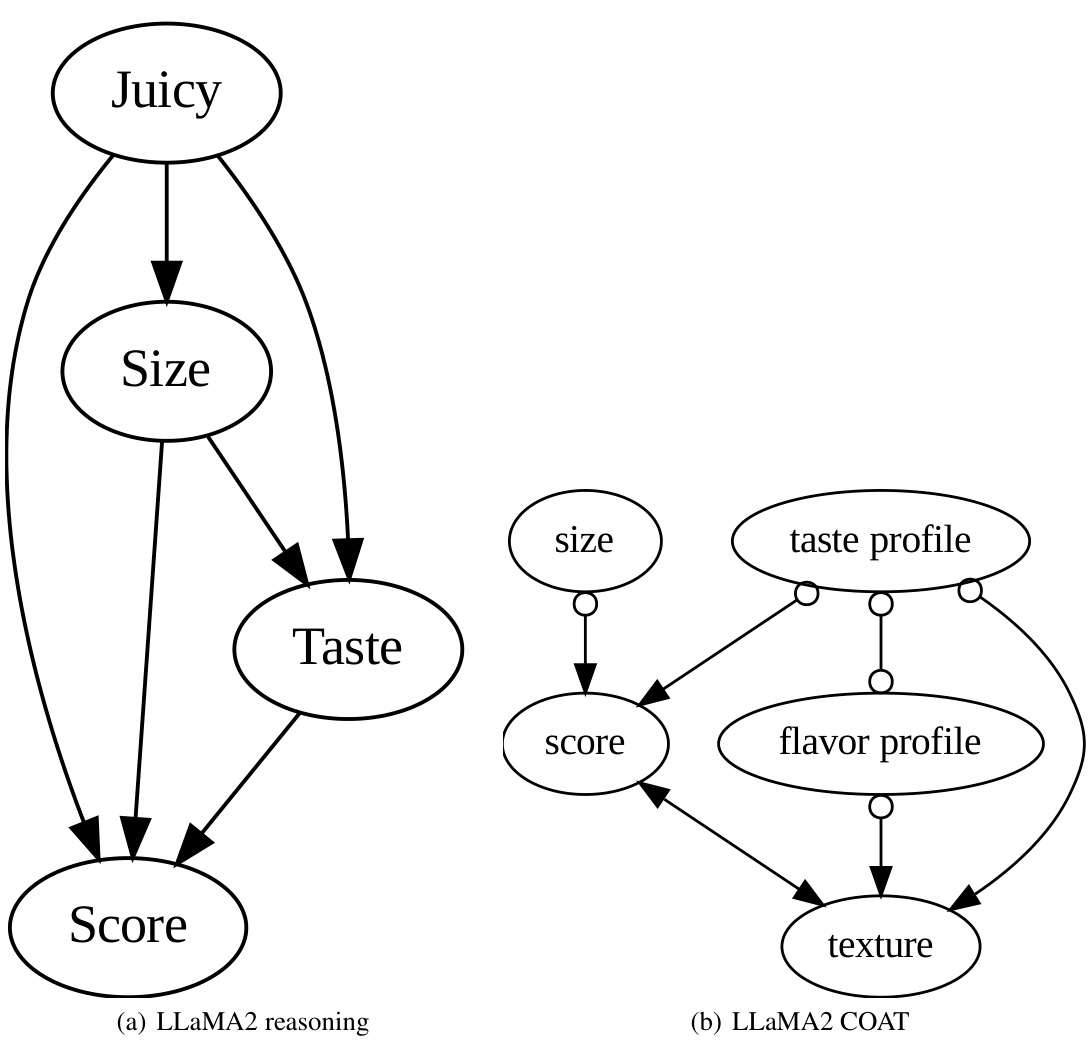
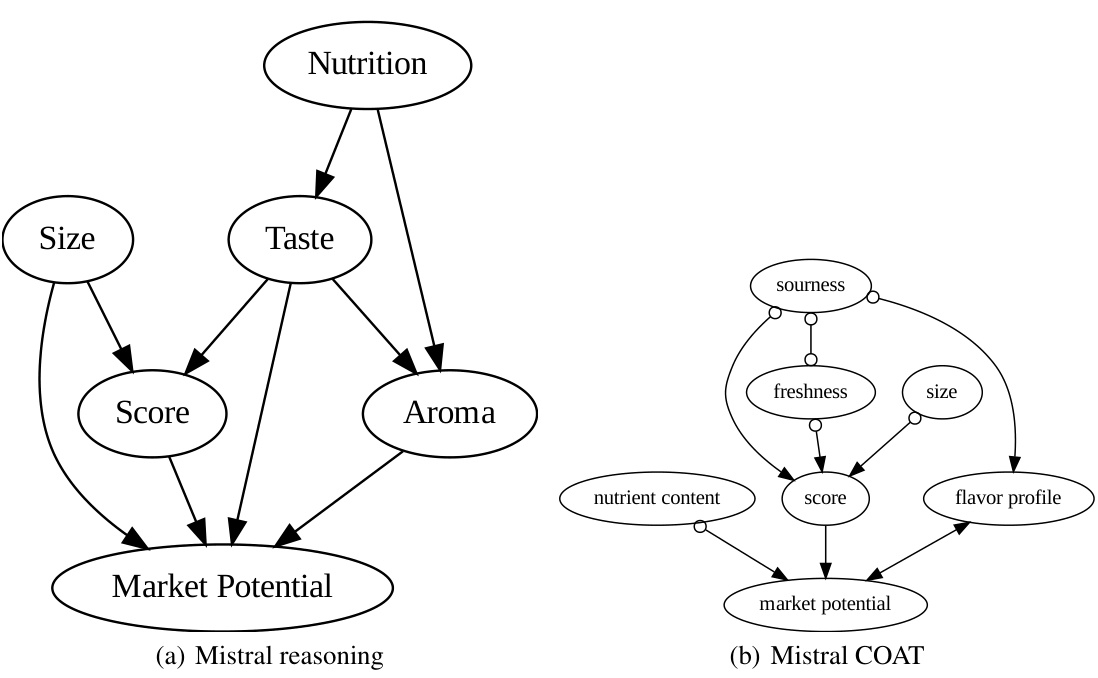
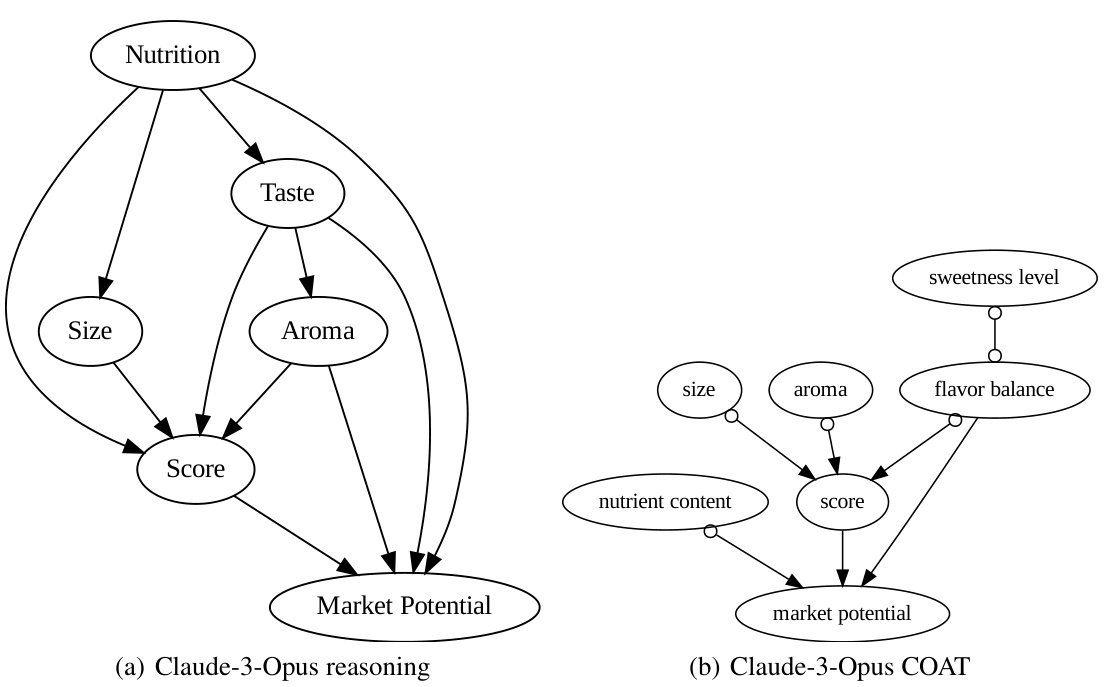
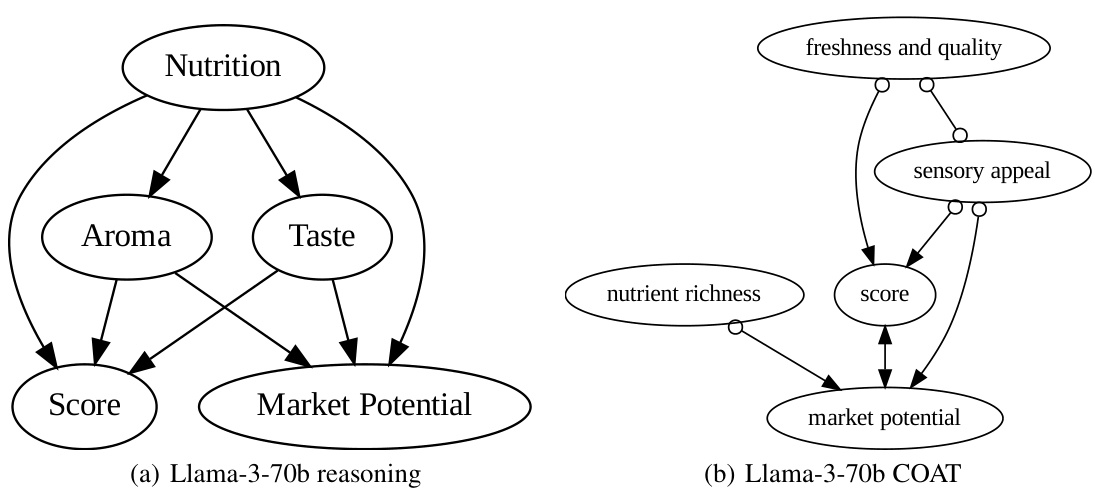
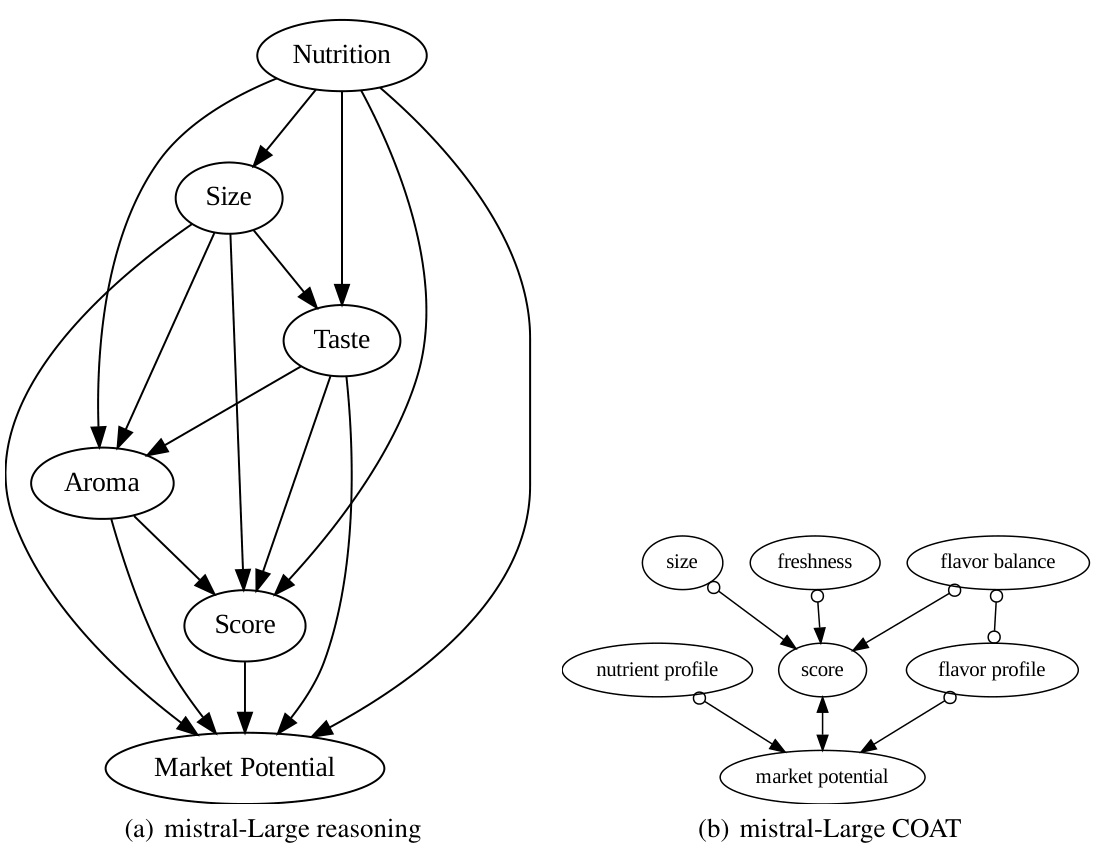
This figure compares the causal graphs discovered by directly using LLMs and by using the COAT framework, against the ground truth. The ground truth shows the correct causal relationships between factors like size, smell, taste, nutrition, juiciness and market potential that influence the apple rating scores. The ‘LLM reasoning’ graphs exhibit many false positive edges due to the limitations of directly using LLMs for causal inference. In contrast, COAT produces graphs that much more closely resemble the ground truth in terms of accuracy and recall, showing its effectiveness in uncovering accurate causal relationships. However, the limitations of the FCI algorithm used in COAT prevented it from recovering the direct causal relationship between ’taste’ and ‘juiciness’.
This figure illustrates the COAT (Causal representation AssistanT) framework. It demonstrates how COAT leverages LLMs to address the challenge of limited high-quality variables in real-world causal discovery. COAT uses LLMs to propose high-level factors from unstructured data, annotate data according to those factors, and then employs a causal discovery algorithm to identify causal relationships. Finally, it uses the causal discovery results to provide feedback to the LLMs to iteratively refine the process and uncover more accurate causal factors.
This figure illustrates the COAT (Causal representation AssistanT) framework. COAT uses LLMs (Large Language Models) to propose high-level factors from unstructured data (e.g., apple reviews), then annotates this data using another LLM, and finally employs a causal discovery (CD) algorithm to identify causal relationships between the factors and the target variable (apple rating score). A feedback loop is incorporated to refine the factor proposals based on the CD algorithm’s results, iteratively improving the model’s accuracy. The three steps are: (a) Factor Proposal, (b) Factor Annotation, (c) Causal Discovery & Feedback Construction.

This figure illustrates the COAT (Causal representation AssistanT) framework. COAT uses LLMs (Large Language Models) to identify high-level factors relevant to a target variable (in this case, apple ratings). The LLMs first propose potential factors, then annotate unstructured data (reviews) according to these factors. A causal discovery (CD) algorithm identifies causal relationships between the factors. The CD algorithm provides feedback to refine the factors proposed by the LLMs. This iterative process helps COAT to progressively build a more accurate representation of the causal mechanisms underlying the ratings.

This figure illustrates the COAT (Causal representation AssistanT) framework’s workflow for analyzing apple ratings. It shows three stages: 1) Factor Proposal: An LLM proposes high-level factors influencing the ratings based on unstructured reviews. 2) Factor Annotation: Another LLM annotates the reviews according to the proposed factors. 3) Causal Discovery & Feedback Construction: A causal discovery algorithm identifies causal relationships, and the results are used to refine the factors iteratively via feedback to the LLMs, leading to a refined Markov Blanket.

This figure illustrates the COAT framework’s three main steps for analyzing AppleGastronome ratings. First, an LLM proposes candidate factors (e.g., size, smell) based on the reviews. Second, another LLM annotates the reviews according to these factors. Finally, a causal discovery (CD) algorithm identifies causal relationships between the factors and provides feedback to the LLM to refine factor selection. This iterative process helps discover the Markov blanket (factors directly influencing the ratings).

This figure illustrates the COAT (Causal representation AssistanT) framework. COAT uses LLMs (Large Language Models) to identify high-level factors influencing a target variable (apple ratings in this example). The LLMs first propose candidate factors, then annotate data according to those factors. A causal discovery (CD) algorithm identifies causal relations, and any unexplained ratings provide feedback to refine the factors iteratively, improving the accuracy of the causal model.

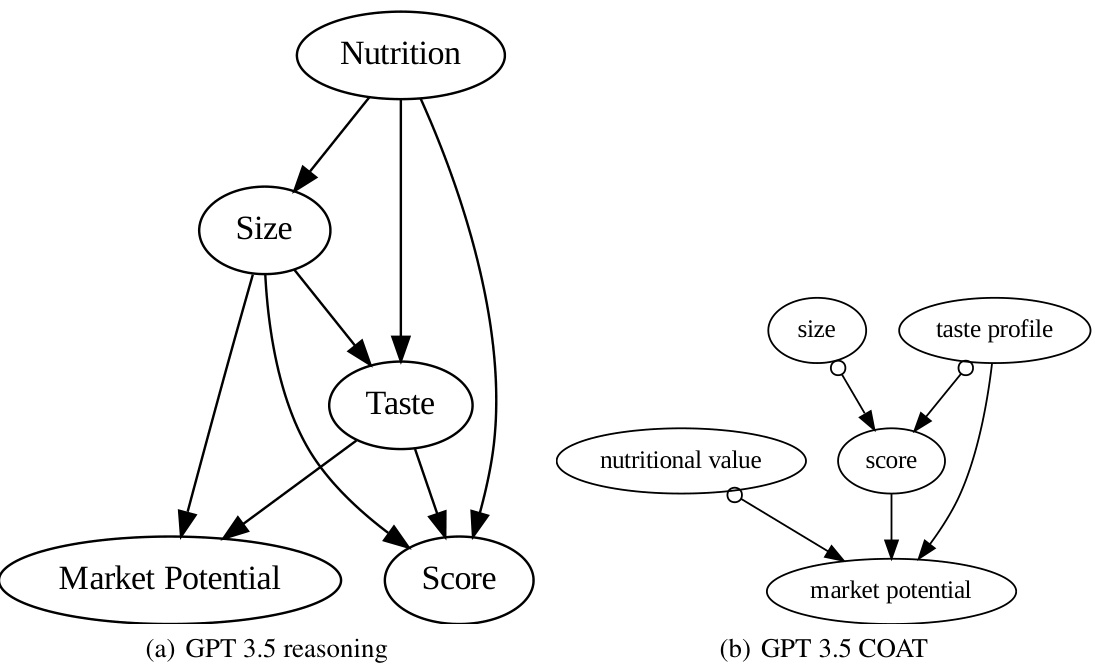
This figure compares the causal graphs discovered by directly using LLMs versus using the COAT framework, which integrates LLMs with causal discovery algorithms. The ground truth causal graph is shown alongside the results of two different methods. The key finding is that COAT, by iteratively refining factor proposals with feedback from causal discovery, yields significantly more accurate results. The limitations of the FCI (Fast Causal Inference) algorithm are highlighted in the discrepancies between the ground truth and COAT results.
This figure illustrates how COAT can discover latent variables (represented by ‘w’) in a causal graph. It shows three scenarios: 1) ‘w’ is a direct cause or effect of the target variable (‘Y’); 2) ‘w’ is a parent of ‘Y’ and also a child of a known variable (‘W’); and 3) ‘w’ is a spouse of ‘Y’, sharing a common child (‘W’). COAT uses hard-to-explain samples to identify these latent variables.
This figure illustrates the COAT (Causal representation AssistanT) framework. It demonstrates how COAT uses LLMs (Large Language Models) to propose high-level factors from unstructured data (like customer reviews), then annotates this data using another LLM, and finally employs a causal discovery (CD) algorithm to identify causal relationships. The process iteratively refines factor proposals through feedback loops between the LLMs and CD algorithm.

This figure illustrates the COAT (Causal representation AssistanT) framework’s three main steps: factor proposal, factor annotation, and causal discovery & feedback construction. It shows how LLMs are used to propose high-level factors from unstructured data (e.g., customer reviews), annotate this data to create structured features, and then how causal discovery algorithms are used to identify causal relationships. The feedback loop between causal discovery and the LLM ensures iterative refinement of the proposed factors until a comprehensive understanding of the causal structure is reached.
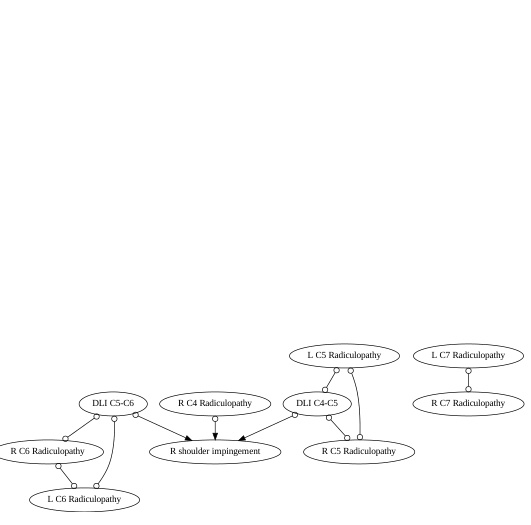
This figure illustrates the COAT (Causal representation AssistanT) framework’s workflow for analyzing apple ratings. It shows three main stages: 1) Factor Proposal: An LLM proposes high-level factors (e.g., size, smell) influencing the ratings from unstructured reviews. 2) Factor Annotation: Another LLM annotates the reviews according to the proposed factors. 3) Causal Discovery & Feedback Construction: A causal discovery (CD) algorithm identifies causal relationships between the factors, using the annotated data; feedback from the CD process refines the factor proposal iteratively.

This figure illustrates the COAT (Causal representation AssistanT) framework. COAT uses LLMs (Large Language Models) to propose high-level factors from unstructured data (e.g., customer reviews) and then uses a causal discovery algorithm to find causal relationships between those factors. The system iteratively refines the factor selection by providing feedback to the LLMs based on discrepancies between the causal model and the observed data. The three main stages are shown: factor proposal, factor annotation, and causal discovery & feedback.
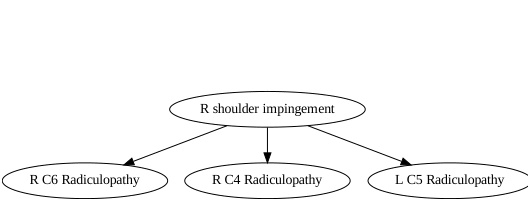
This figure illustrates how COAT can discover latent variables using feedback from the causal discovery process. It shows different scenarios where discovering hard-to-explain samples aids in uncovering latent variables that are either direct causes or effects of the target variable Y or are indirectly related to it through another identified variable.

The figure illustrates the COAT (Causal representation AssistanT) framework’s three steps: factor proposal using LLMs (Large Language Models) based on unstructured data (e.g., customer reviews); factor annotation using LLMs to transform the unstructured data into structured data; causal discovery and feedback construction using causal discovery (CD) algorithms to identify causal relationships and provide feedback to LLMs to refine factors.
This figure illustrates the COAT framework’s three-step process: 1. Factor proposal using an LLM to extract high-level factors from unstructured reviews. 2. Factor annotation using another LLM to transform unstructured reviews into structured data based on the proposed factors. 3. Causal discovery and feedback construction, using a causal discovery algorithm to identify causal relations among the identified factors and provide feedback to the LLM for iterative refinement.

This figure compares causal graphs generated by different methods applied to AppleGastronome data. The ground truth graph is shown alongside graphs produced by directly using LLMs (GPT-3.5 and GPT-4) for causal reasoning. It also shows the results of using the proposed COAT framework with these LLMs. The comparison highlights COAT’s effectiveness in accurately identifying causal relationships, with higher precision and recall than direct LLM reasoning. The limitations of the Fast Causal Inference (FCI) algorithm used in COAT are also noted.
This figure illustrates the COAT (Causal representation AssistanT) framework. COAT uses LLMs (Large Language Models) to propose high-level factors from unstructured data (like customer reviews of apples), annotates the data according to those factors, and then employs causal discovery (CD) algorithms to identify causal relationships between the factors. A feedback loop allows the LLMs to iteratively refine factor proposals based on the results of the causal discovery.
This figure compares the causal graphs discovered by directly using LLMs and by using the COAT framework in the AppleGastronome benchmark. The ground truth causal graph shows the expected relationships between different factors (size, aroma, taste, nutrition, juiciness, score, market potential). The graph generated by directly applying LLMs is noisy and has many false positive edges. In contrast, the COAT framework produces a more accurate causal graph with higher precision and recall. However, the COAT framework, due to using FCI algorithm limitations, fails to capture all the relations present in the ground truth, missing the direct relationship between ’taste’ and ‘juiciness’.

This figure illustrates the COAT (Causal representation AssistanT) framework for causal discovery using LLMs. The process is shown in three stages: (a) Factor Proposal: An LLM reads unstructured reviews and proposes high-level factors (e.g., apple size, smell) relevant to the rating score. (b) Factor Annotation: Another LLM annotates the unstructured reviews according to the proposed factors. (c) Causal Discovery & Feedback Construction: A causal discovery (CD) algorithm identifies causal relations among the annotated factors. The results are used to provide feedback to the LLM to iteratively refine factor proposals, improving the accuracy and completeness of causal discovery.

This figure shows the input data used for the Brain Tumor case study. The image data consists of MRI scans of the brain, divided into three categories: glioma, meningioma, and no tumor. Each row in the image contains 5 randomly selected examples from one of the three categories. This data is used as input to the COAT system for feature extraction and causal analysis.

This figure illustrates the COAT (Causal representation AssistanT) framework. The framework uses LLMs (Large Language Models) to propose high-level factors from unstructured data (such as customer reviews of apples), annotate this data, and then employs a causal discovery (CD) algorithm to identify causal relationships among the factors. A feedback loop is incorporated, where the CD algorithm’s results inform the LLM to refine factor proposals in iterative steps.
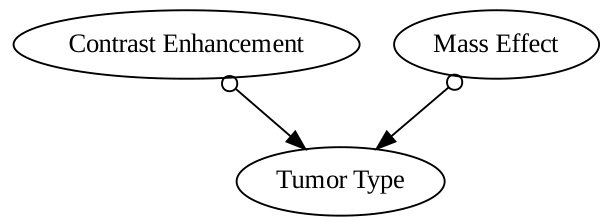
The figure shows the final causal graph obtained by the COAT algorithm for the brain tumor case study. The graph visually represents the causal relationships between factors related to tumor type. The nodes represent high-level factors such as contrast enhancement and mass effect, and the edges indicate the causal relationships between them. This graph is derived from the COAT algorithm’s analysis of MRI images. The study aims to understand the causal relationships between different factors to assist in brain tumor diagnosis.

This figure illustrates the COAT framework’s workflow for analyzing apple ratings. It shows three stages: 1. Factor Proposal (LLM proposes candidate factors like size and smell based on reviews), 2. Factor Annotation (another LLM structures the unstructured reviews based on the proposed factors), and 3. Causal Discovery & Feedback Construction (a causal discovery algorithm identifies causal relationships, providing feedback to the LLM to refine factor proposals iteratively).

This figure illustrates the COAT (Causal representation AssistanT) framework. COAT uses LLMs (Large Language Models) to identify high-level factors related to a target variable (apple ratings in this example). The LLMs propose potential factors and annotation guidelines. Another LLM then annotates the data based on these factors. Finally, a causal discovery (CD) algorithm identifies causal relationships between the factors, creating feedback for the LLMs to refine the factors iteratively.

This figure compares causal graphs generated by different methods for analyzing apple ratings. The ground truth graph shows the actual relationships between factors like size, aroma, taste, and score. The ‘GPT-4 META’ graph represents results from using a large language model (LLM) directly without the COAT framework, highlighting many incorrect connections. The ‘GPT-3.5 COAT’ graph shows results using the COAT framework, improving accuracy and capturing most of the true relationships. The ‘Claude-3-Opus COAT’ graph demonstrates the COAT framework’s robustness, as it also captures most of the true relationships. Note that the lack of an edge between ’taste’ and ‘juiciness’ in the COAT graphs is attributed to limitations in the FCI (Fast Causal Inference) algorithm.
The figure illustrates the COAT framework’s three stages for analyzing apple ratings. Stage 1 uses an LLM to propose candidate factors based on reviews. Stage 2 uses another LLM to annotate the unstructured review data. Stage 3 employs a causal discovery (CD) algorithm to identify causal relations, providing feedback for iterative refinement of proposed factors.

This figure illustrates the COAT framework’s three main steps: factor proposal, factor annotation, and causal discovery & feedback construction. In the factor proposal step, an LLM proposes high-level factors related to apple ratings from unstructured reviews. The factor annotation step uses another LLM to annotate the reviews based on these factors. Finally, a causal discovery algorithm identifies causal relationships between the factors, providing feedback to the LLM to improve the factor proposal iteratively. This iterative process helps refine the understanding of the causal relationships involved in determining apple ratings.
This figure illustrates the COAT (Causal representation AssistanT) framework’s workflow for analyzing AppleGastronome ratings. It details a three-step process: 1) Factor Proposal (LLM proposes high-level factors from reviews), 2) Factor Annotation (another LLM structures the unstructured reviews based on proposed factors), and 3) Causal Discovery & Feedback Construction (a causal discovery algorithm identifies causal relations, and feedback is provided to the LLM to iteratively refine the factors). The goal is to identify factors influencing the apple ratings, progressing through iterative refinement.

The figure illustrates the COAT (Causal representation AssistanT) framework’s workflow for analyzing apple rating scores. It shows three stages: 1) Factor Proposal: An LLM proposes high-level factors (e.g., size, smell) influencing the scores based on user reviews; 2) Factor Annotation: Another LLM annotates the reviews according to these factors; 3) Causal Discovery & Feedback: A causal discovery algorithm identifies causal relationships between factors, and feedback is provided to the LLM to iteratively refine the factors and improve the model’s accuracy in explaining the ratings. This iterative process aims to accurately reveal the factors impacting the apple ratings.

This figure shows a time series plot visualizing the target variable used in the ENSO case study, which is the monthly change in sea surface temperature (SST) in the Niño3 region. The plot displays the SST change over a long period, clearly showing the oscillatory pattern characteristic of El Niño-Southern Oscillation (ENSO) events. The positive values represent El Niño events (warming), and the negative values represent La Niña events (cooling). The oscillation pattern is visually apparent in the plot.
This figure illustrates the COAT framework’s three main steps: (a) Factor Proposal, where an LLM proposes high-level factors based on unstructured data; (b) Factor Annotation, where another LLM annotates the data according to those factors; (c) Causal Discovery & Feedback Construction, where a causal discovery algorithm identifies causal relationships and provides feedback to refine the factors iteratively. The framework aims to bridge the gap between unstructured data and causal discovery methods by leveraging LLMs.
This figure illustrates the COAT (Causal representation AssistanT) framework. It shows how COAT uses LLMs (Large Language Models) to identify high-level factors from unstructured data (such as customer reviews), annotates this data, employs causal discovery algorithms to find causal relationships, and then uses the results to provide feedback to the LLMs, iteratively refining the factor identification process. The goal is to identify the Markov Blanket of a target variable (in this case, apple ratings). The diagram highlights the three main steps: factor proposal, factor annotation, and causal discovery & feedback construction.

This figure illustrates the causal relationships between various climate factors and the change in sea surface temperature (SST) in the Nino3 region, a key indicator of El Niño-Southern Oscillation (ENSO) events. The graph, generated by the Causal representation AssistanT (COAT) framework, reveals both direct and indirect causal links among factors like cloud cover, air temperature, soil moisture, wind patterns, and sea level pressure, providing valuable insights into the complex dynamics of ENSO. The figure highlights both stationary and non-stationary factors and their influence on SST change.

This figure illustrates the COAT framework’s three main steps for analyzing apple ratings. First, an LLM proposes high-level factors (e.g., size, smell) from unstructured reviews. Second, another LLM annotates the reviews based on these factors. Finally, a causal discovery algorithm identifies causal relationships between the factors, and feedback is generated to refine the factor proposals iteratively.
More on tables
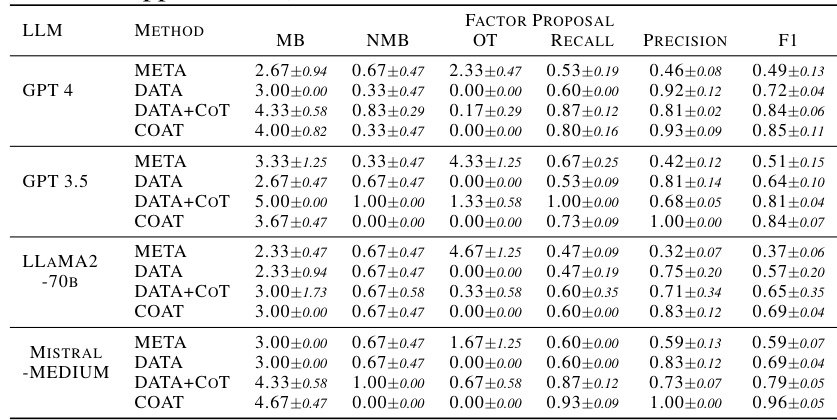
This table presents the complete results of the AppleGastronome benchmark, showing the performance of different methods (META, DATA, DATA+COT, and COAT) across various LLMs. The metrics used are MB (number of factors in the Markov blanket), NMB (number of undesired factors in the Markov blanket), OT (number of other unexpected factors), Recall, Precision, and F1-score. This provides a comprehensive comparison of the effectiveness of each approach in identifying relevant factors for predicting apple ratings.
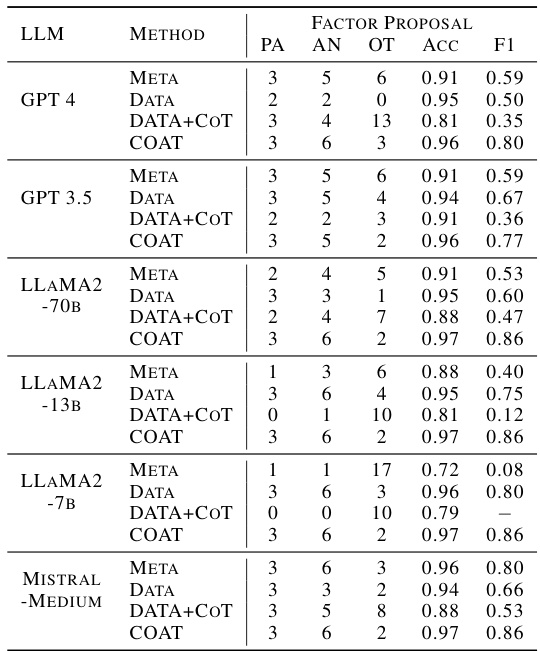
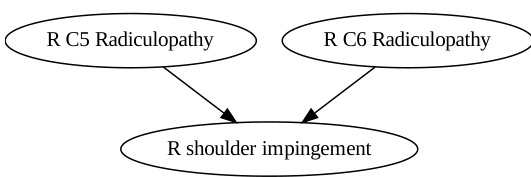
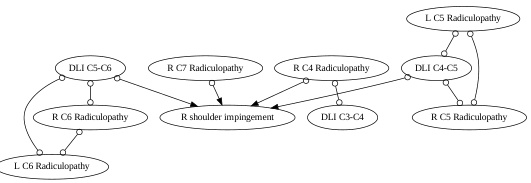
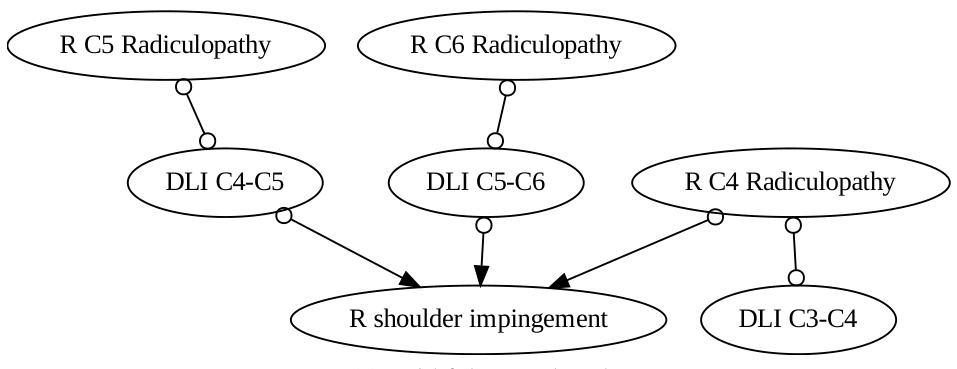
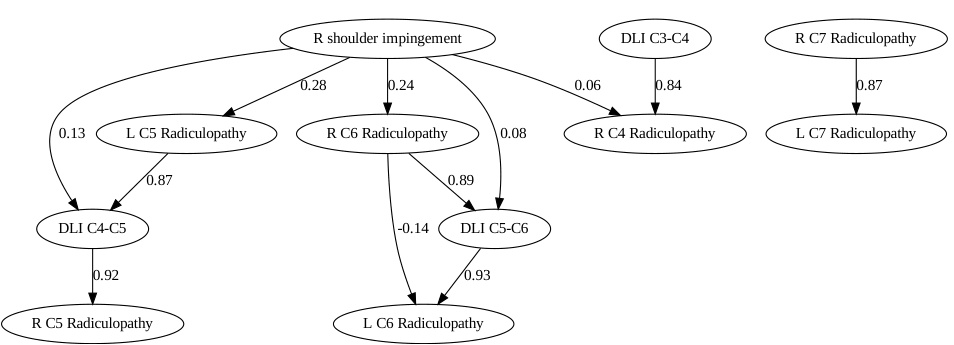
This table presents the results of causal discovery experiments on the Neuropathic dataset using different methods and LLMs. It compares the performance of different methods (META, DATA, DATA+COT, COAT) in identifying causal parents (PA), ancestors (AN), and other variables (OT) related to the target variable (right shoulder impingement). The accuracy and F1-score metrics evaluate the effectiveness of each method in recovering the causal ancestors. The table shows that COAT generally outperforms the baselines in recovering the causal ancestors.

This table presents the results of causal relation extraction experiments conducted on the AppleGastronome dataset using various LLMs and methods. The metrics used include Structural Hamming Distance (SHD), Structural Intervention Distance (SID), recall, precision and F1 score for pairwise causal relation extraction. The table shows that COAT generally outperforms the baseline of using LLMs directly for causal reasoning, indicating improved performance in uncovering causal relationships within the dataset.
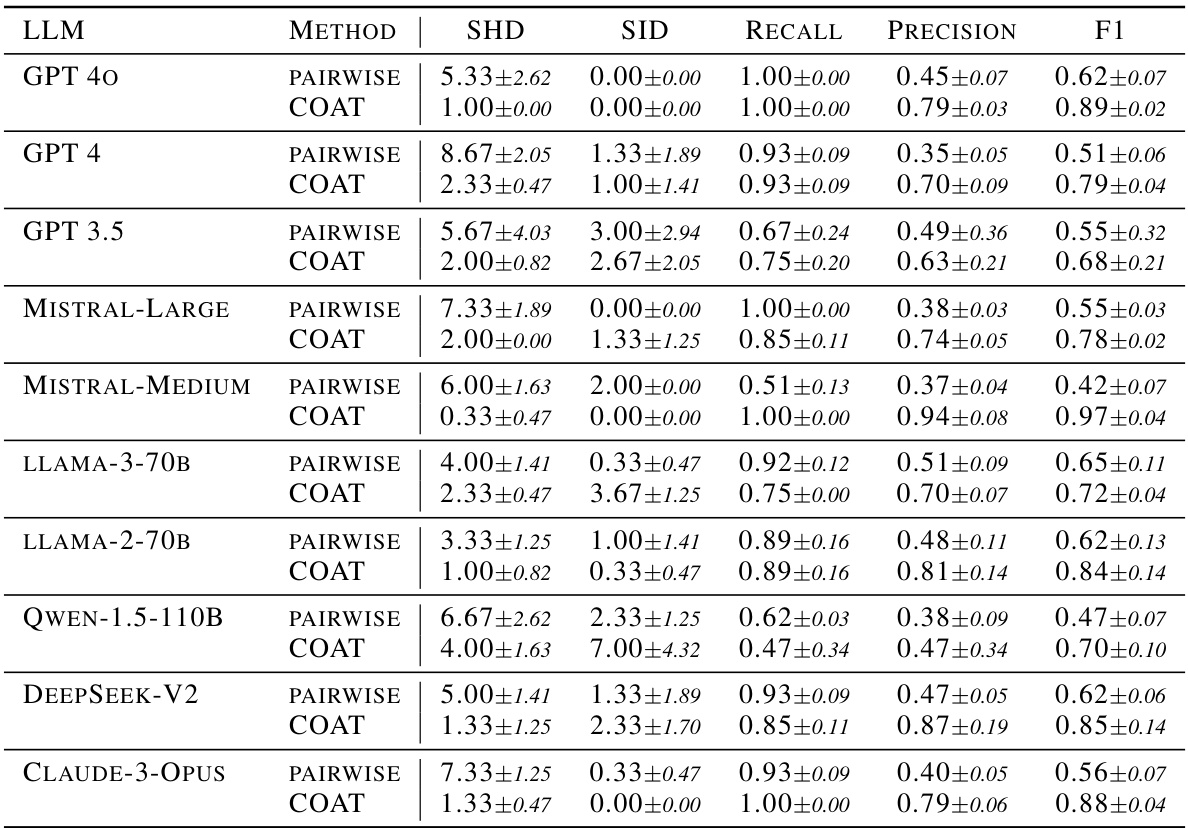
This table presents the results of causal relation extraction experiments conducted on the AppleGastronome dataset using different LLMs and methods (PAIRWISE and COAT). It shows the performance metrics for each LLM and method including Structural Hamming Distance (SHD), Structural Intervention Distance (SID), Recall, Precision, and F1-score. The results highlight the effectiveness of the COAT framework in achieving higher accuracy and F1 scores in uncovering causal relationships compared to directly using LLMs (PAIRWISE).

This table presents the results of independence tests performed to assess whether the annotation noises are independent from the annotated features and other noise sources within the AppleGastronome dataset. The tests are likely used to evaluate the quality and reliability of the LLM-based annotations. The p-values indicate the statistical significance of the relationships.
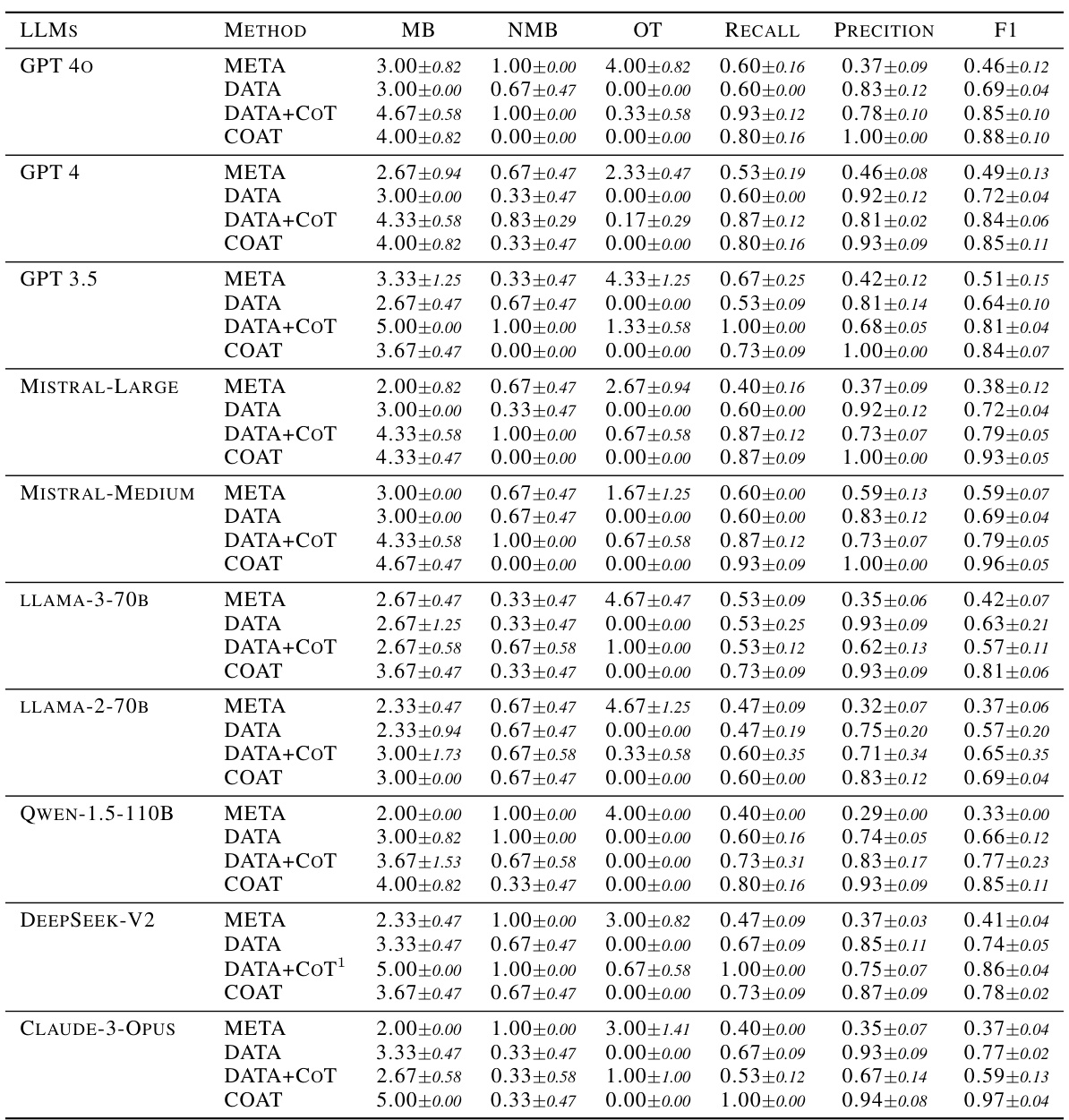
This table presents the complete results of the Apple Gastronome benchmark experiment. For various LLMs (GPT-4, GPT-3.5, Mistral-Large, Mistral-Medium, LLAMA-3-70B, LLAMA-2-70B, Qwen-1.5-110B, DeepSeek-V2, Claude-3-Opus), it shows the performance of different methods: META (zero-shot factor proposal), DATA (factor proposal given context), DATA+COT (one round of COAT), and COAT (multiple rounds of COAT with feedback). The results are presented as mean ± standard deviation across multiple runs for each metric: MB (number of Markov Blanket factors), NMB (number of non-Markov Blanket factors), OT (number of other factors), Recall, Precision, and F1-score.

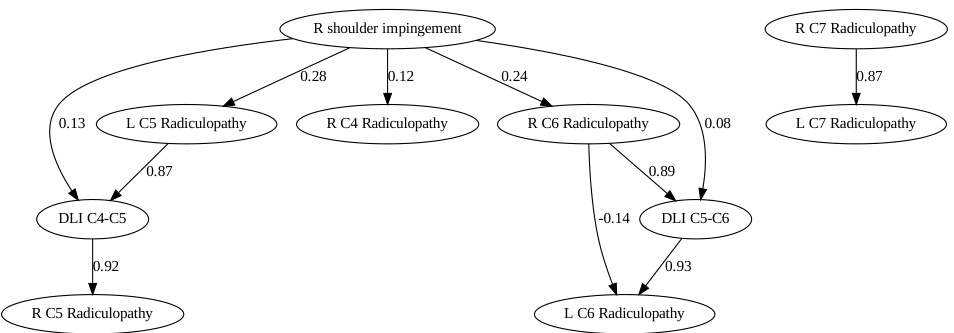
This table presents a comprehensive evaluation of the causal discovery performance of various Large Language Models (LLMs) across multiple rounds of the COAT framework. For each LLM, the table shows the perception score, capacity score, and mutual information I(y;x|hs) for each iteration (round). The perception score reflects the LLM’s ability to propose valid causal factors, the capacity score measures the reduction in uncertainty about the target variable given the identified factors, and the mutual information quantifies the remaining uncertainty.
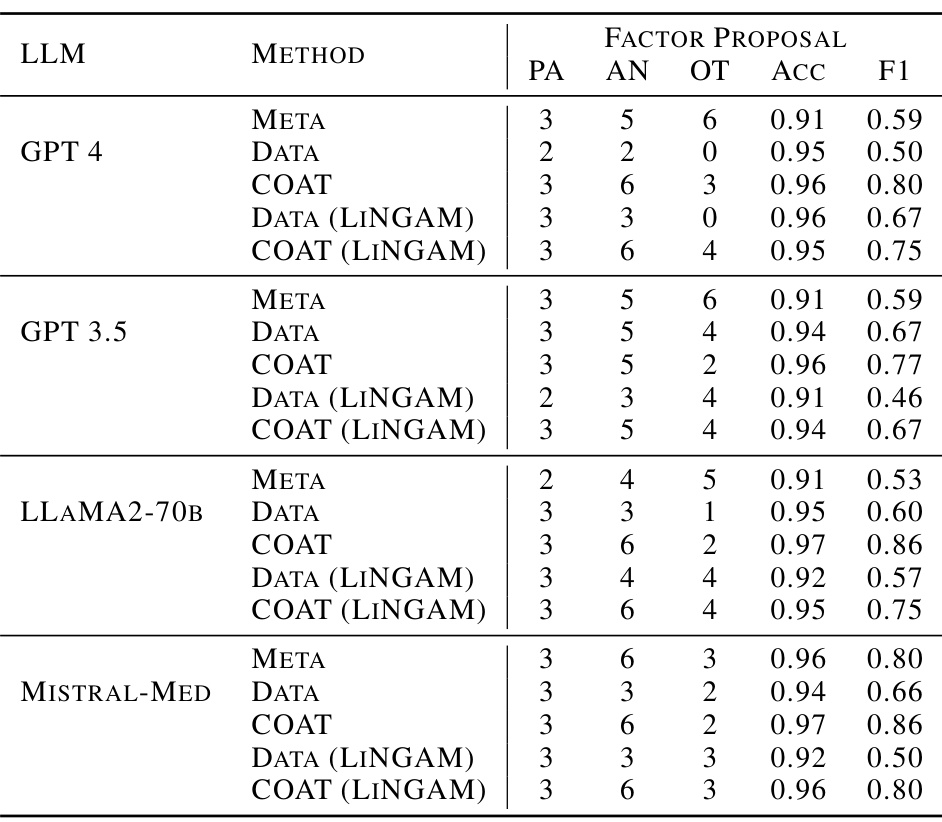
This table presents the results of causal discovery experiments using different causal discovery methods (including FCI and LiNGAM) in the Neuropathic dataset. It compares the performance of various methods in terms of accurately identifying parents (PA), ancestors (AN), and other variables (OT) related to the target variable (right shoulder impingement). The accuracy and F1-score metrics evaluate the effectiveness of the methods in recovering the causal ancestors.

This ablation study investigates the impact of modifying two hyperparameters in COAT, specifically the number of clusters used in the feedback mechanism and the size of the groups in the prompt. The results demonstrate that COAT’s performance is robust to these changes in hyperparameters, consistently outperforming baseline methods.

This table presents the ablation study results on the prompt template of COAT. Three different LLMs (GPT-4, GPT-3.5-TURBO, and Mistral-Medium) were evaluated using a modified prompt template. The results show the number of Markov blanket factors (MB), non-Markov blanket factors (NMB), and other factors (OT) identified by COAT, along with recall, precision, and F1 score. The results demonstrate the robustness of COAT to the choice of prompt templates.

This table summarizes the benchmark datasets used in the paper. For each dataset, it provides the type (synthetic or real-world), the source, the sample type (textual, image, or NetCDF), the sample size, and whether the ground truth is available.

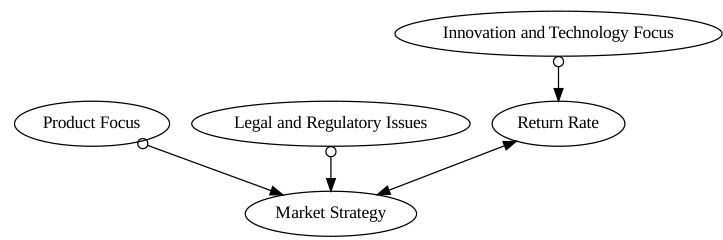
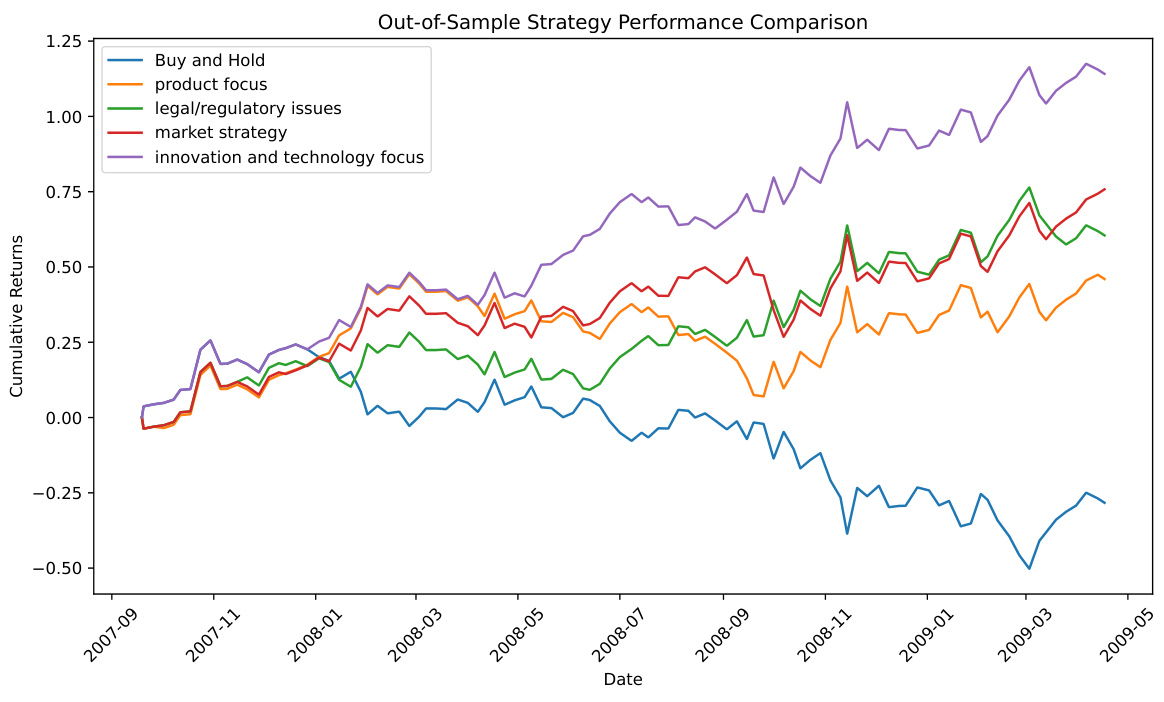
This table presents the performance evaluation of different trading strategies based on the factors identified by COAT in the Stock News case study. It shows key metrics for each factor (Buy and Hold, Product Focus, Legal/Regulatory Issues, Market Strategy, Innovation and Technology Focus), including Expected Return, Sharpe Ratio, T-Stat, Information Ratio, alpha, alpha T-stat, Max Loss, and Skew. These metrics provide a quantitative comparison of the risk-adjusted returns and overall performance of each factor’s trading strategy. The Innovation and Technology focus shows significantly higher returns and better risk-adjusted performance compared to other factors.
Full paper#



















