↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Vision-Language Models (VLMs) are usually trained under either generative or discriminative paradigms. Generative training enables VLMs to handle complex tasks but suffers from issues like hallucinations and weak object discrimination. Discriminative training excels in zero-shot tasks but struggles with complex scenarios. This creates a need for a unified approach.
This paper proposes Sugar, a unified training framework that integrates the strengths of both paradigms. Sugar introduces structure-induced training that emphasizes semantic relationships between interleaved image-text sequences. It uses dynamic time warping for sequence alignment and a novel kernel for fine-grained semantic differentiation. Experiments show Sugar achieves state-of-the-art results across multiple generative and discriminative tasks, highlighting its effectiveness in balancing both paradigms.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multimodal learning and large language models. It presents a novel unified training framework that bridges the gap between generative and discriminative paradigms, offering significant improvements in various tasks. This work opens new avenues for research in improving the performance and capabilities of MLLMs, particularly in complex scenarios requiring both generative and discriminative abilities. It’s highly relevant to the current trend of developing more sophisticated and robust multimodal models.
Visual Insights#

This figure shows two plots. Plot (a) demonstrates the accuracy of a multimodal large language model (MLLM) on the WebQA dataset when the relevant image-text pair is placed at different positions within a sequence. It reveals that the accuracy tends to be lower when the relevant pair is not at the beginning or the end. Plot (b) presents the accuracy of various types of questions in the MMVP-VLM benchmark, showing how the model’s performance enhances after incorporating discriminative training. These plots highlight the challenges faced by generative models in performing discriminative tasks and the benefits of the proposed unified generative-discriminative training.

This table compares the performance of the proposed Sugar model against eleven state-of-the-art models across eleven different visual-language benchmarks. The benchmarks assess a range of capabilities, including visual question answering, visual reasoning, and multimodal understanding. The table highlights the best and second-best performing models for each benchmark, showing Sugar’s performance relative to existing methods and indicating where it achieves state-of-the-art results.
In-depth insights#
Unified Multimodal Training#
A unified multimodal training approach in large language models (LLMs) seeks to harmonize generative and discriminative training paradigms. Traditional generative training excels at complex tasks but suffers from issues like hallucinations and weak object discrimination, while discriminative methods achieve strong zero-shot performance in image-text classification but struggle with nuanced, fine-grained semantics. A unified approach aims to leverage the strengths of both, enabling LLMs to perform well on both generative and discriminative tasks simultaneously. This might involve designing a training framework that integrates both types of loss functions, potentially using interleaved image-text sequences as input, thereby fostering a holistic understanding of multimodal data. A crucial element would be the development of techniques to effectively capture both global and fine-grained semantics, perhaps employing dynamic alignment mechanisms or specialized attention mechanisms. The success of such a unified approach hinges on its ability to mitigate the limitations of each individual paradigm, ultimately leading to a more robust and versatile multimodal LLM.
Structure-Induced Learning#
Structure-induced learning, in the context of multimodal large language models, presents a powerful paradigm shift. Instead of relying solely on sequential processing of image and text data, it explicitly models the relationships between different input modalities, leveraging their interconnectedness to improve learning. This approach goes beyond simply concatenating inputs; it actively constructs a structured representation that captures global semantics and nuanced details. Dynamic time warping is frequently utilized to align image and text sequences, finding correspondences across different temporal scales, thus enhancing the model’s ability to discern subtle similarities and differences. A key advantage lies in its capacity to bridge the gap between generative and discriminative training, often by incorporating both types of loss functions within the model’s optimization process. The results often demonstrate superior performance on tasks involving complex semantic relationships, such as fine-grained retrieval or multimodal reasoning tasks that benefit from incorporating both global and detailed semantic information. Ultimately, structure-induced learning offers a more robust and efficient way for multimodal LLMs to extract knowledge from complex inputs.
Dynamic Time Warping#
Dynamic Time Warping (DTW) is a powerful algorithm for measuring similarity between time series that may vary in speed or length. Its core strength lies in its ability to handle non-linear alignments, unlike simpler methods that require strict temporal correspondence. In the context of multi-modal learning, DTW’s flexibility is crucial. It allows for the comparison of image and text sequences, which may have differing lengths and paces. By dynamically aligning these sequences, DTW helps identify semantic correspondences even when there’s temporal misalignment. This is particularly important when analyzing interleaved image-text sequences, where the algorithm can match visual and textual elements that convey similar meanings despite differences in their respective positions in the sequence. DTW’s robustness to noise and variations in speed makes it a suitable choice for real-world applications. This allows for more accurate representations and stronger connections between the modalities, which improves the performance of the multi-modal models being used.
Triple Kernel Fusion#
A Triple Kernel Fusion approach in a multimodal large language model (MLLM) would likely involve combining the strengths of three different kernel methods to improve semantic representation and discrimination. Each kernel might leverage a unique modality or feature space, such as visual features (e.g., from a vision transformer), textual embeddings (e.g., from a language model), and cross-modal relationships. The fusion strategy would be crucial, potentially employing techniques like weighted averaging or concatenation to integrate the outputs of the individual kernels. This approach could enhance the model’s ability to capture both global context and fine-grained details, potentially improving performance in tasks requiring both discriminative (e.g., retrieval) and generative (e.g., generation) capabilities. Success would depend on the selection of appropriate kernels and the development of a robust fusion mechanism that leverages the complementary information from each kernel without introducing negative interference or computational overhead. Careful consideration of the kernel parameters would also be needed to avoid overfitting or biases that could negatively impact the model’s overall effectiveness.
Future Research#
Future research directions stemming from this unified generative and discriminative training approach for multi-modal large language models are plentiful. Improving the efficiency of the dynamic time warping (DTW) framework is key, as it currently adds computational overhead. Exploring alternative alignment methods could reduce this burden while retaining semantic accuracy. Investigating different kernel designs beyond the proposed triple kernel to capture more nuanced semantic differences and incorporate diverse pre-trained models is crucial. Further exploration is needed into handling hallucinations effectively, possibly by incorporating stronger constraints during training or leveraging external knowledge bases for verification. The synergistic effects between generative and discriminative tasks warrant more in-depth study, potentially through more advanced joint training strategies. Finally, testing the approach on more complex, real-world tasks will be essential to verify its generalization capabilities and robustness. Investigating and mitigating potential bias within the models is also a significant area for future investigation.
More visual insights#
More on figures

This figure illustrates the Sugar framework, a novel approach that integrates generative and discriminative training for multimodal large language models (MLLMs). It shows how the model processes interleaved image-text sequences, employing dynamic sequence alignment to capture global semantics and a novel kernel for fine-grained semantic differentiation. The framework balances generative and discriminative tasks by using both a generative loss (Lg) and a discriminative loss (Ld). The discriminative loss is calculated based on the similarity between the predicted similarity of two input sequences and their actual similarity. The generative loss is based on the text generation performance. This unified approach aims to leverage the strengths of both generative and discriminative training paradigms, ultimately improving the performance of MLLMs on various tasks.
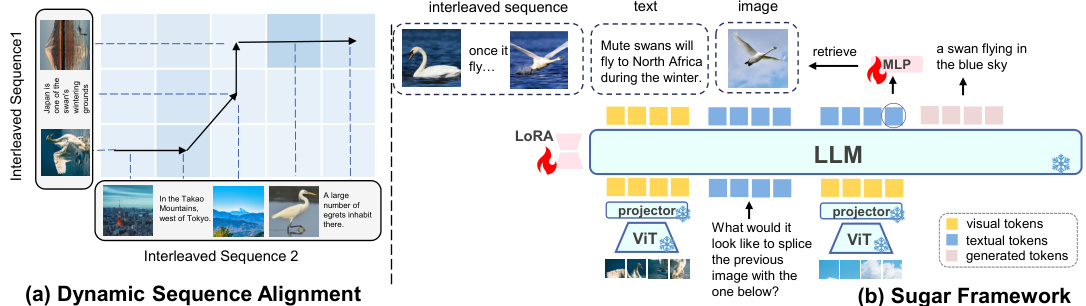
This figure illustrates the core components of the proposed Sugar framework. (a) shows the dynamic sequence alignment, where semantically related segments from two interleaved image-text sequences are connected, allowing for comparison and similarity calculation. The arrows show the direction of the temporal alignment. (b) provides an overview of the Sugar framework itself, highlighting its capability for both multi-modal generation and retrieval. The framework takes interleaved sequences as input, processes them using a language model (LLM) augmented with LoRA, and uses two projectors to handle visual and textual tokens separately, resulting in generated tokens or retrieval outputs.
This figure illustrates the Sugar framework, which combines generative and discriminative training to improve the performance of multi-modal large language models. It shows how interleaved image-text sequences are used as input, and how a structure-induced training strategy imposes semantic relationships between the input samples and the model’s hidden state. This enhances the model’s ability to capture global semantics and distinguish fine-grained semantics using dynamic sequence alignment and a novel kernel. The framework balances generative and discriminative tasks, resulting in improved performance on both types of tasks.

This figure shows a sample question from the WebQA dataset, which involves identifying a relevant image-text pair among several distractors. The question asks whether the Atlanta Hawks wore red uniforms during the 2015 NBA season. The figure highlights several image-text pairs, and the correct one is labeled as ‘useful’. The goal is to illustrate the challenge of capturing global semantics in long sequences, as the performance of LLMs on this task varies depending on the position of the relevant pair in the sequence.

This figure shows two plots demonstrating the shortcomings of current vision-language models (VLMs). Plot (a) shows the accuracy of a question-answering model, varying the position of the correct image-text pair within a sequence of candidates. It reveals that current generative models struggle with centrally located information. Plot (b) demonstrates the performance of VLMs on a fine-grained retrieval task, showing that generative models struggle with distinguishing between visually similar images.

This figure illustrates the Sugar framework, a novel approach that unifies generative and discriminative training for multi-modal large language models (MLLMs). It shows how the model integrates both generative and discriminative losses (Lg and Ld), leveraging dynamic sequence alignment within the Dynamic Time Warping framework and a novel triple kernel for fine-grained semantic differentiation. The framework takes interleaved image-text sequences as input, explicitly imposing semantic relationships between samples and the MLLM’s hidden states to enhance the model’s ability to capture global semantics and distinguish fine-grained details. This unified approach aims to overcome limitations of both generative and discriminative paradigms alone, achieving synergistic improvements in both generative and discriminative tasks.

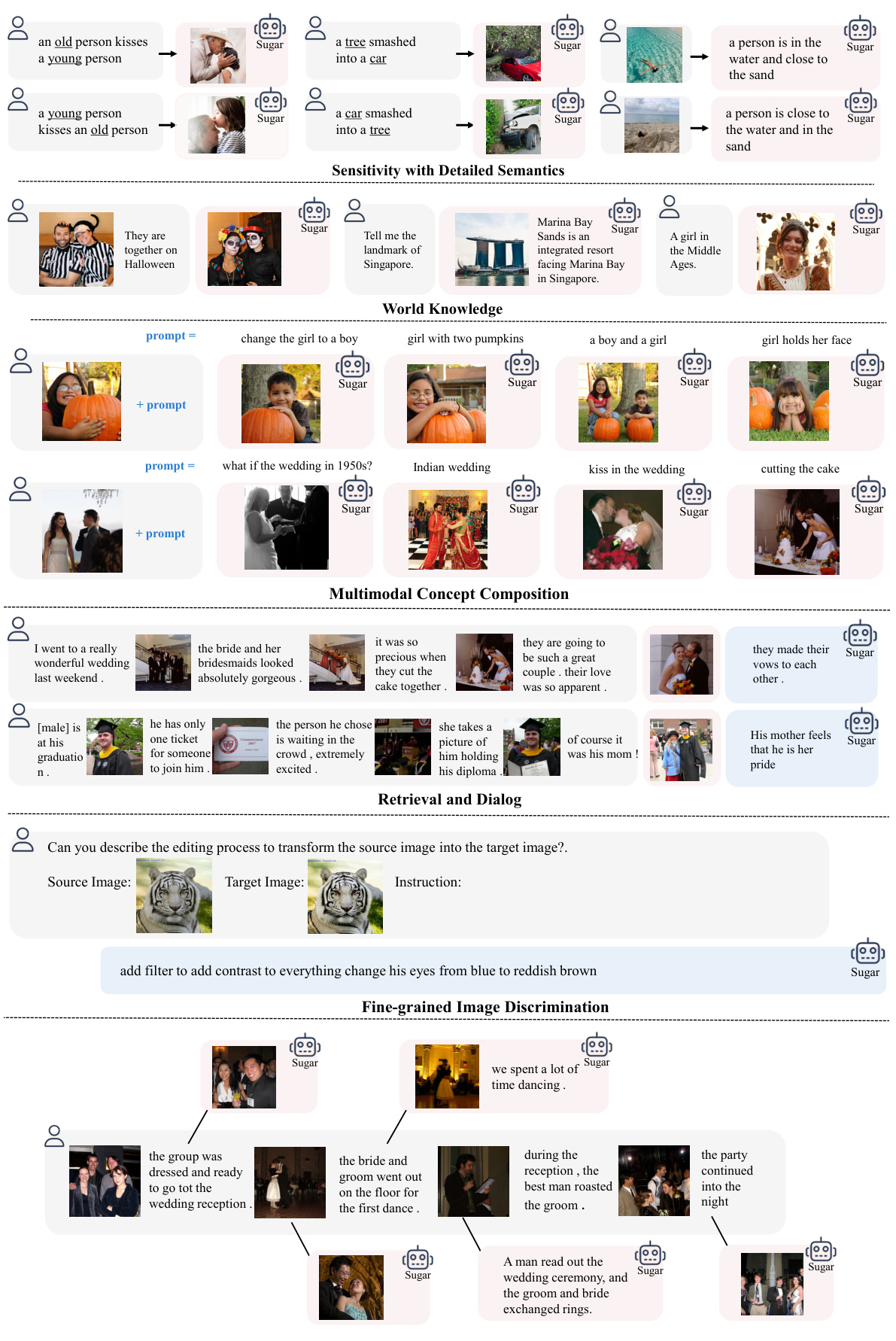
This figure showcases several examples of the model’s performance on various image-text tasks. The examples are categorized into four groups: Sensitivity with Detailed Semantics, World Knowledge, Multimodal Concept Composition, and Fine-grained Image Discrimination. Each example shows the input prompt (image and/or text), the model’s output (generated text or retrieved results), and a visual indicator (pink for retrieval, blue for generation). The figure demonstrates the model’s ability to handle various complexities in image-text understanding, including detailed semantics, world knowledge, and compositional reasoning. More examples are available in Appendix F.2.

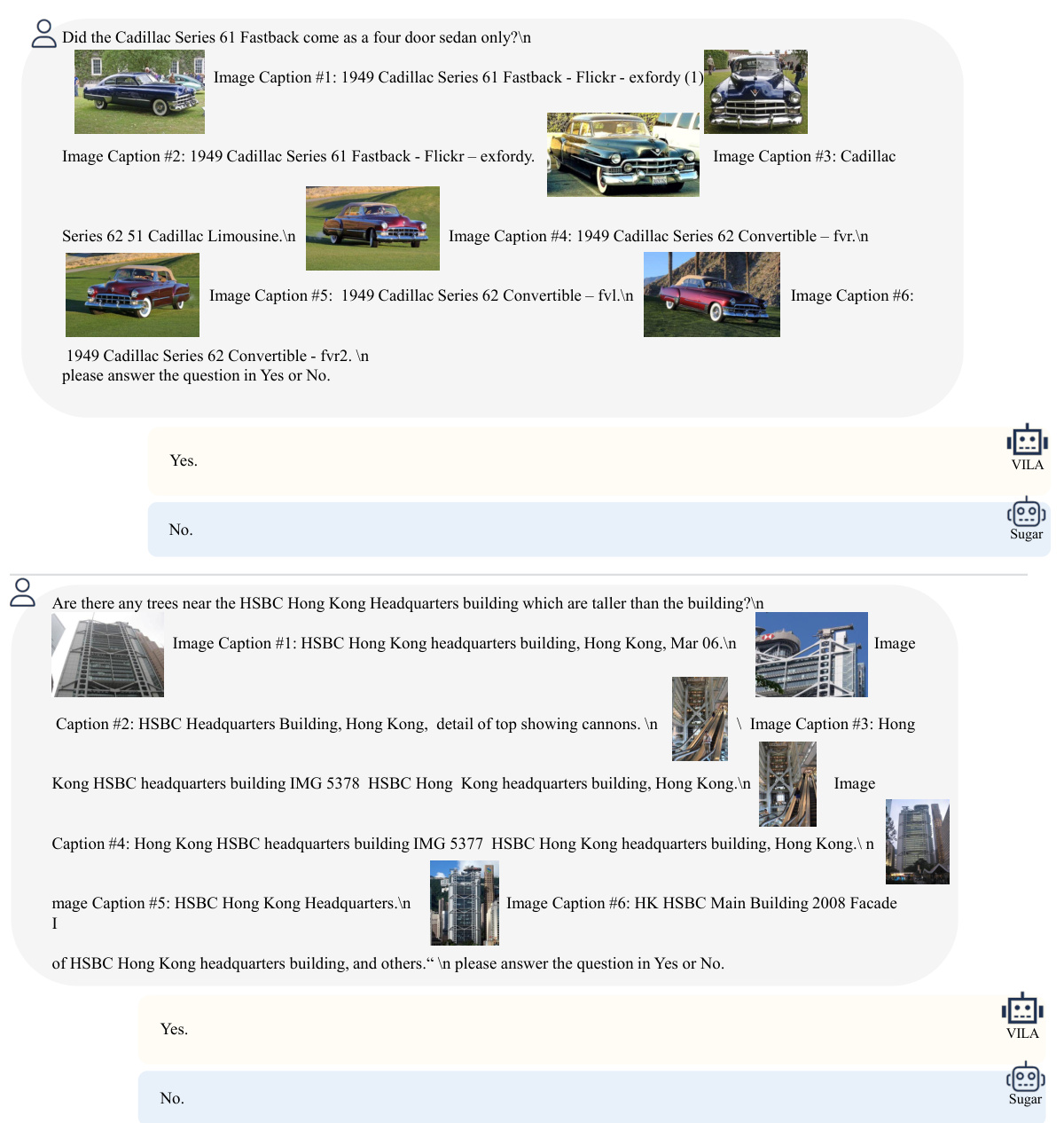
This figure showcases Sugar’s ability to distinguish subtle differences between similar images and pinpoint detailed objects and their attributes. It presents several examples where Sugar’s responses are more precise and accurate compared to the responses of another model (VILA), highlighting Sugar’s enhanced capacity for fine-grained visual analysis and discrimination.

This figure shows several examples where Sugar is used to identify subtle differences between images. The examples demonstrate Sugar’s superior ability to pinpoint precise differences, unlike VILA which may provide more general descriptions of the image contents. The improved accuracy in detailed object identification and attribute recognition is highlighted.

This figure illustrates the Sugar framework, which unifies generative and discriminative training for multi-modal large language models (MLLMs). It shows how interleaved image-text sequences are processed by the MLLM, with a structure-induced training strategy imposing semantic relationships between input samples and the hidden state. This approach aims to enhance the MLLM’s ability to capture global semantics, distinguish fine-grained semantics, and balance generative and discriminative tasks. The figure depicts the input interleaved sequences, dynamic sequence alignment using a novel kernel, generative and discriminative losses (Lg and Ld), and the final generated tokens.
This figure illustrates the Sugar framework, which integrates generative and discriminative training paradigms. It shows how interleaved image-text sequences are processed by a Multimodal Large Language Model (MLLM) to achieve both generative and discriminative tasks. The framework uses a dynamic sequence alignment method, a novel kernel for fine-grained semantic differentiation, and a structure-induced training strategy that imposes semantic relationships between input samples and the MLLM’s hidden state. The goal is to balance generative capabilities (like text generation) and discriminative abilities (like image-text retrieval), addressing weaknesses of each approach in isolation. The resulting model is trained with both generative and discriminative losses.

This figure illustrates the proposed Sugar framework, which combines generative and discriminative training for multi-modal large language models. It shows how the model integrates interleaved image-text sequences, dynamic sequence alignment, and a novel kernel for fine-grained semantic differentiation. The framework aims to balance generative and discriminative tasks, leveraging the strengths of both paradigms to improve performance in various tasks.

This figure illustrates the proposed Sugar framework’s core components: dynamic sequence alignment and the overall architecture. (a) Dynamic Sequence Alignment shows how semantically similar parts of interleaved image-text sequences are aligned to capture global context and relationships. (b) Sugar Framework provides a high-level overview of the model’s architecture, showcasing how structure-induced training balances generative and discriminative tasks, enabling both generation and retrieval.

This figure illustrates the proposed Sugar framework, which combines generative and discriminative training for multi-modal large language models. The framework integrates both generative and discriminative losses, leveraging dynamic sequence alignment and a novel kernel for fine-grained semantic differentiation. The diagram depicts how the model processes interleaved image-text sequences, captures global and fine-grained semantics, and generates or retrieves outputs.

This figure illustrates the core methodology of the Sugar framework. Panel (a) shows the dynamic sequence alignment used to capture semantic relationships between interleaved image-text sequences. The alignment path highlights the similarities between corresponding parts of different sequences. Panel (b) provides a schematic overview of the Sugar framework, showing the integration of generative and discriminative training for vision-language modeling, using both generative and discriminative loss functions.

This figure shows two parts: (a) illustrates the dynamic sequence alignment method used by the Sugar framework to capture semantic relationships between input samples. Matched parts of the interleaved image-text sequences are connected by lines and arrows show the order of alignment. (b) presents an overview of the Sugar framework architecture, including the interleaved input sequence, visual and text token projections, the MLLM, and the generative and discriminative loss functions.

This figure illustrates the Sugar framework, which integrates generative and discriminative training. Interleaved image-text sequences are fed into a Multimodal Large Language Model (MLLM). A dynamic sequence alignment module, using a novel kernel, helps to capture global and fine-grained semantic relationships between the input sequences. The model then produces both generative (text generation) and discriminative (similarity prediction) outputs, with losses calculated for both aspects to guide training. The synergistic benefits are highlighted by the integrated approach, enhancing both generative and discriminative capabilities of the model.

This figure showcases several examples of the model’s performance on various image-text tasks. Each example is categorized into one of four task types: Sensitivity with Detailed Semantics, World Knowledge, Multimodal Concept Composition, and Fine-grained Image Discrimination. Each example shows the input image(s) and text, followed by the model’s response, indicated by a pink background for retrieval results and a blue background for generation results. The purpose is to visually demonstrate the model’s ability to handle a wide range of multimodal tasks with high accuracy and provide both generative and discriminative capabilities within a single model.

This figure shows two parts: (a) illustrates the Dynamic Sequence Alignment used to compute semantic relationships between different input samples. The alignment path between semantically similar parts of the two sequences is highlighted. (b) shows the overall framework of Sugar, which supports both multimodal generation and retrieval by incorporating a structure-induced constraint.

This figure illustrates the proposed Sugar framework. Panel (a) shows the dynamic sequence alignment method used to compute semantic relationships between interleaved image-text sequences. The alignment is represented by a path connecting semantically similar parts of the sequences. Panel (b) is a diagram of the overall Sugar framework, which combines a vision transformer (VIT), a large language model (LLM), and a retrieval module to perform both generation and retrieval tasks. The figure highlights how the structure-induced training strategy integrates generative and discriminative tasks within the MLLM.

This figure showcases several examples of the model’s performance on various image-text tasks. The examples are grouped into categories such as: Sensitivity with Detailed Semantics, World Knowledge, Multimodal Concept Composition, and Retrieval and Dialog. Each example shows the input prompt, the model’s output (generated text or retrieved results), and a visual representation of the input images. The pink background highlights retrieval tasks, showing the model’s ability to retrieve relevant information based on the prompt. The blue background shows generated results, which demonstrate the model’s capacity to generate accurate and coherent text. The appendix contains further examples not included in the main figure due to space constraints.

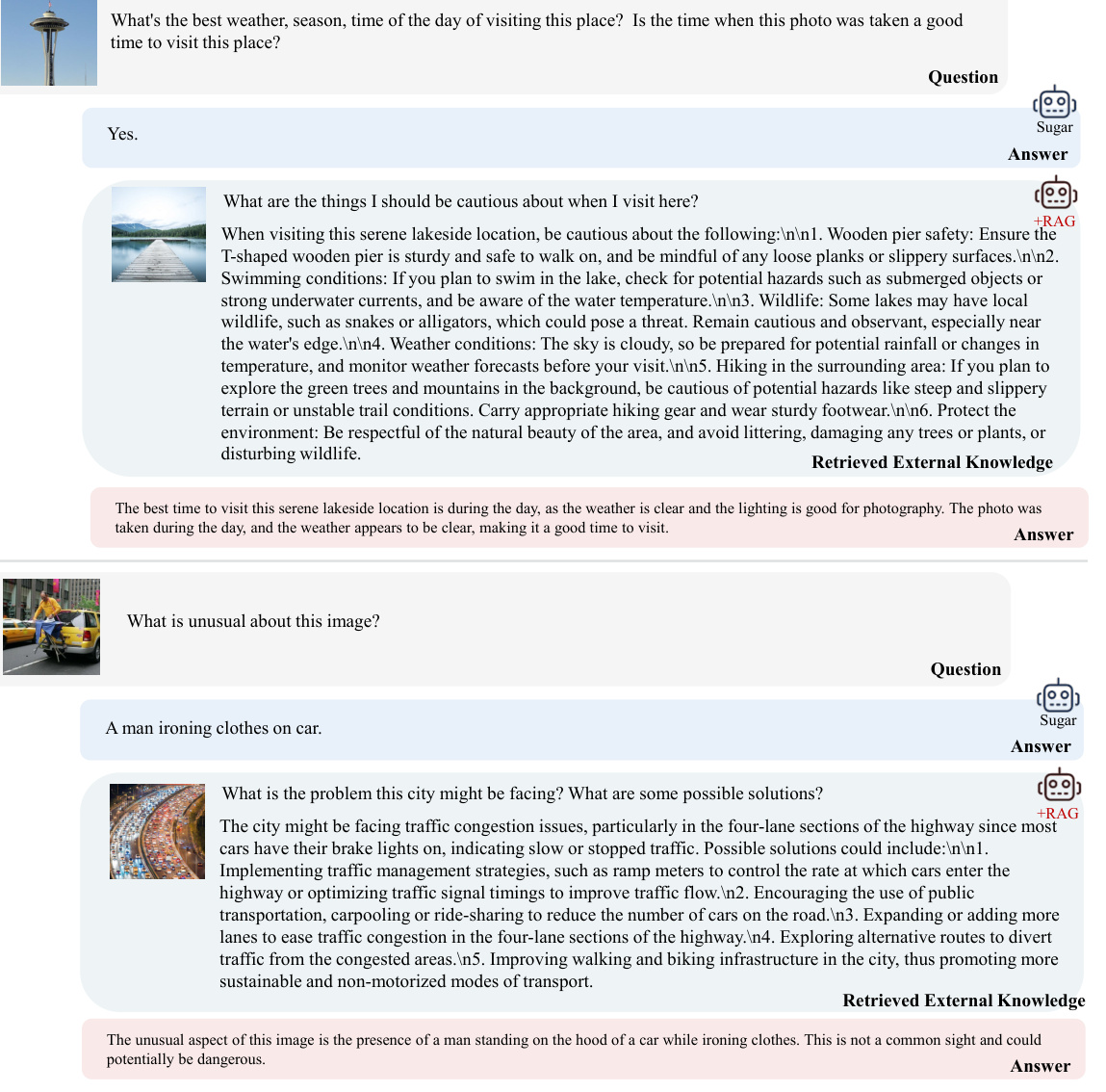
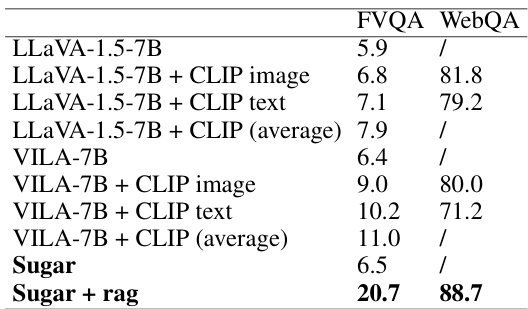
This figure shows more examples of retrieval-augmented generation. The examples demonstrate Sugar’s ability to generate more accurate and detailed answers by leveraging external knowledge retrieved from a knowledge base. Each example includes a question, an image, the answer provided by Sugar, and the external knowledge that informed Sugar’s answer. The examples illustrate that Sugar can better integrate information from both images and text, retrieving more relevant information for more effective question answering.

This figure illustrates the Sugar framework, which combines generative and discriminative training for multi-modal large language models. It shows how interleaved image-text sequences are fed into the model, and how both generative (Lg) and discriminative (Ld) losses are used to train the model. The Dynamic Sequence Alignment component is highlighted, showing how semantic relationships between input samples are used to induce structure on the model’s hidden states. A novel kernel is also mentioned, designed for fine-grained semantic differentiation. The overall aim is to bridge the gap between generative and discriminative training paradigms by leveraging the strengths of both.

This figure illustrates the Sugar framework, which integrates generative and discriminative training. The input is an interleaved sequence of image and text tokens. These are processed by a Multimodal Large Language Model (MLLM), which outputs both generated text tokens and hidden states. The hidden states are used to compute the discriminative loss, Ld, which measures the similarity between pairs of input sequences. A generative loss, Lg, based on the generated text, is also calculated. The final loss function is a weighted combination of Ld and Lg. This joint training strategy aims to leverage the strengths of both generative and discriminative paradigms, improving the model’s ability to capture global semantics, differentiate fine-grained semantics, and reduce hallucinations.

This figure illustrates the Sugar framework, which integrates generative and discriminative training paradigms. It shows how interleaved image-text sequences are fed into a Multimodal Large Language Model (MLLM). The model then uses a dynamic sequence alignment mechanism to capture global and fine-grained semantics and utilizes a novel triple kernel to enhance semantic differentiation. The framework outputs both generated text and predicted similarity scores, effectively balancing generative and discriminative tasks.

This figure illustrates the Sugar framework, which combines generative and discriminative training for multi-modal large language models. It shows how the model processes interleaved image-text sequences using dynamic sequence alignment and a novel kernel for fine-grained semantic differentiation. The framework aims to balance generative and discriminative tasks, leveraging the strengths of both paradigms to improve performance on a variety of tasks.

This figure shows the proposed Sugar framework’s dynamic sequence alignment and overall architecture. (a) illustrates how the model aligns semantically related parts of interleaved image-text sequences to capture global semantics. (b) depicts the framework’s ability to handle both generative and retrieval tasks simultaneously, using the aligned sequences as input for an MLLM.
This figure illustrates the proposed Sugar framework which consists of two parts: dynamic sequence alignment and Sugar framework. Dynamic sequence alignment shows how the model aligns semantically similar parts of two interleaved image-text sequences to capture the global semantics. Sugar framework shows how the model jointly trains generative and discriminative tasks to enhance the model’s ability to capture both global and detailed semantics.

This figure showcases several examples of the model’s performance on various image-text tasks, highlighting its capabilities in both retrieval and generation. The pink background indicates examples where the model successfully retrieved relevant information, while the blue background indicates examples where the model successfully generated text. The examples cover a range of complexities and demonstrate the model’s ability to handle both simple and complex scenarios.
More on tables
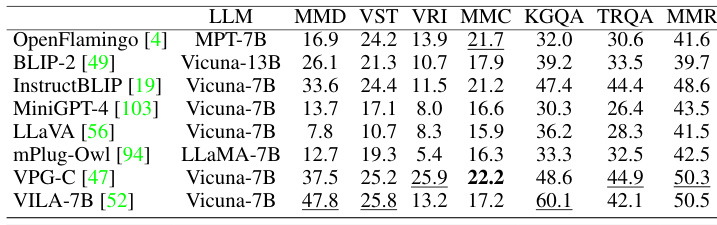
This table compares the performance of the proposed Sugar model against several state-of-the-art models on the DEMON benchmark. DEMON evaluates models’ ability to handle complicated multimodal comprehension tasks across various datasets and categories. The table shows the results for each model across seven categories with 29 sub-tasks, highlighting Sugar’s superior performance compared to VPG-C, the previous state-of-the-art model, across six out of seven categories.
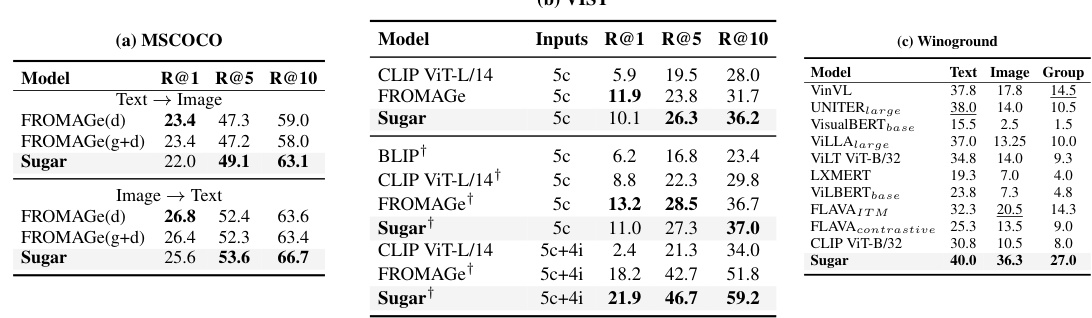
This table compares the performance of the proposed method, Sugar, against 10 other state-of-the-art models across 11 visual language benchmarks. The benchmarks assess various capabilities, including visual question answering, visual reasoning, and multimodal comprehension. The table highlights Sugar’s performance, indicating where it achieves the best or second-best results, using bold and underline formatting respectively. The asterisk (*) denotes benchmarks where training images are used during the model’s training phase. Abbreviations are used for brevity, and the full names of the benchmarks are given in the caption.
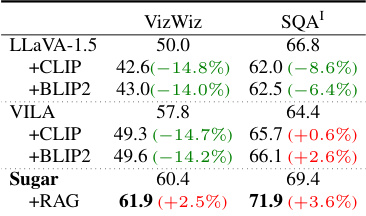
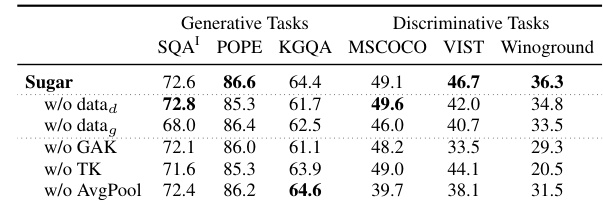
This table presents the results of two experiments: retrieval-augmented generation and ablation study. The retrieval-augmented generation experiment shows the improvement of performance in VizWiz and SQA tasks when incorporating retrieval. The ablation study investigates the impact of removing individual components (data for generative tasks, data for discriminative tasks, global alignment kernel, triple kernel, average pooling) on the performance of both generative and discriminative tasks. The results show that all components contribute positively to the model’s performance, highlighting the synergistic benefits of the unified approach.
This table compares the performance of the proposed method ‘Sugar’ against several state-of-the-art methods across eleven established visual-language benchmarks. Each benchmark assesses different aspects of visual-language understanding, such as visual question answering, image captioning, and multimodal reasoning. The best and second-best performing models are highlighted for each benchmark, showing Sugar’s competitive performance.

This table presents the accuracy of VILA and Sugar models on the WebQA dataset, where the position of the relevant image-text pair is varied. The index indicates the pair’s location in the sequence (1 being the first, 6 being the last). The results show Sugar consistently outperforming VILA, suggesting it’s less prone to positional bias in capturing global semantics.
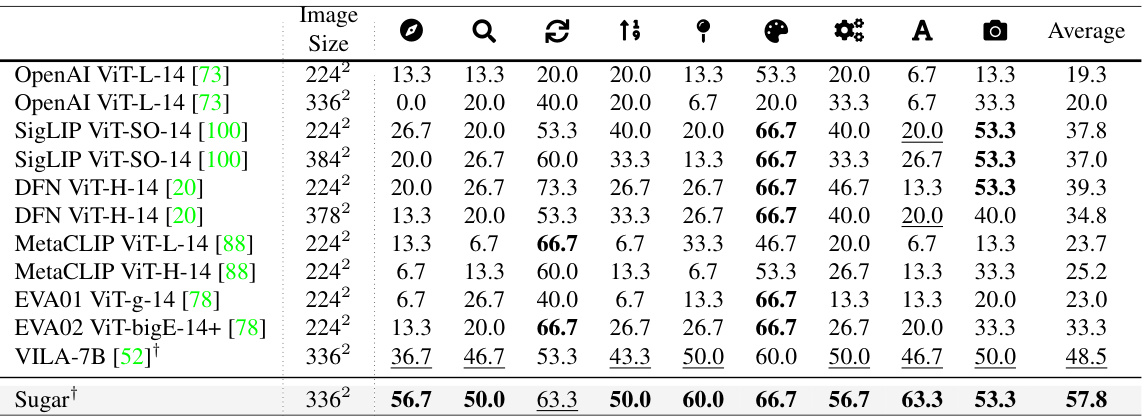
This table compares the performance of the proposed method, Sugar, against eleven state-of-the-art methods across 11 benchmark datasets for visual language tasks. The table shows the results for each method on various metrics like accuracy, recall@k and other relevant metrics for each benchmark. The best and second-best results are highlighted for each benchmark dataset to enable easy comparison.
This table compares the performance of the proposed model, Sugar, against 10 other state-of-the-art models across 11 visual language benchmarks. The benchmarks assess different aspects of vision-language understanding, including question answering, image captioning, and multimodal reasoning. The table shows the performance of each model on each benchmark, highlighting Sugar’s competitive performance, especially in tasks requiring fine-grained semantic distinctions. The asterisk (*) indicates models that were trained with access to the images in the datasets during training.
Full paper#



















