↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current vision-language model (VLM) based out-of-distribution (OOD) detection methods suffer from the issue of inaccurate foreground-background decomposition. This results in unreliable surrogate OOD features extracted from in-distribution (ID) data, thus limiting the performance of prompt tuning methods. The inaccurate features are especially problematic when the model has low confidence in its predictions on the ID data.
To overcome this limitation, this paper proposes a novel framework called Self-Calibrated Tuning (SCT). SCT introduces modulating factors to adaptively adjust the weight of OOD regularization based on sample uncertainty. This allows the model to focus on the classification task when dealing with uncertain ID data and effectively leverage the information from reliable OOD features extracted from high-confidence data. Extensive experiments show that SCT significantly improves the OOD detection performance compared to existing methods.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on out-of-distribution (OOD) detection, a critical challenge in deploying reliable machine learning models. It offers a novel approach to improve OOD detection performance using vision-language models (VLMs) by addressing the problem of spurious OOD features, thus opening new avenues for research and improvement in this active field. The self-calibrated tuning (SCT) framework offers a practical and effective solution, making this work highly relevant to a wide range of researchers.
Visual Insights#

This figure shows the imperfect foreground-background decomposition performed by CLIP, a vision-language model. The top row displays original images from ImageNet-1k, while the bottom row shows the ID-irrelevant context extracted by the fine-tuned CLIP model using 16-shot data. The colored patches represent the extracted context. The imperfect decomposition leads to many extracted features being ID-related, which negatively impacts OOD detection performance.

This table presents a comparison of various OOD detection methods on the ImageNet-1k dataset. It shows the performance (FPR95 and AUROC) of zero-shot methods, post-hoc methods, and prompt-tuning based methods. The table highlights the superior performance of certain methods (in bold) and indicates that prompt tuning methods generally perform better using few-shot data. Results marked with † indicate values taken from cited papers.
In-depth insights#
OOD Prompt Tuning#
OOD prompt tuning leverages the power of pre-trained vision-language models (VLMs) for out-of-distribution (OOD) detection. It refines the VLM’s ability to distinguish in-distribution (ID) data from unseen OOD examples by carefully tuning prompts. A core challenge is the scarcity of OOD data, making it difficult to train robust detectors. The method typically involves extracting features from ID samples which are considered irrelevant for correct classification and using these to regularize prompt training. However, imperfect foreground-background separation can introduce spurious features from ID data, hindering performance. This necessitates careful selection of these ‘surrogate’ OOD samples, or the development of methods, like self-calibration, to adjust the influence of regularization from samples with different levels of classification uncertainty. Self-calibration aims to mitigate the effect of unreliable surrogate OOD features improving overall performance and calibration. This innovative approach makes OOD prompt tuning a promising area for future research, focusing on further improvements in robust handling of limited and noisy data.
SCT Framework#
The Self-Calibrated Tuning (SCT) framework offers a novel approach to out-of-distribution (OOD) detection in vision-language models. SCT addresses the limitations of existing methods that rely on imperfect foreground-background decomposition by introducing modulating factors. These factors dynamically adjust the weight of OOD regularization during training based on prediction uncertainty. This adaptive approach ensures that the model prioritizes the classification task when dealing with uncertain ID data, preventing over-regularization from spurious OOD features. Conversely, when the model confidently classifies ID data, the focus shifts towards OOD regularization. This calibration leads to improved OOD detection performance, making it especially valuable for scenarios with only limited in-distribution (ID) data available. The framework’s effectiveness has been demonstrated experimentally, and its compatibility with many existing prompt-tuning methods further enhances its practicality and adaptability for different scenarios.
Uncertainty Calibration#
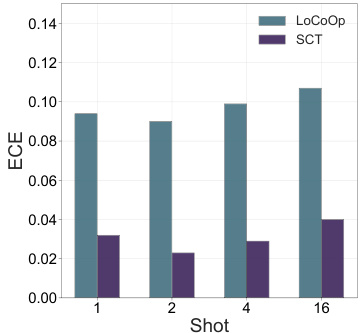
Uncertainty calibration in deep learning models focuses on improving the reliability of predicted probabilities. Well-calibrated models should produce probabilities that accurately reflect the model’s confidence in its predictions; a probability of 0.8 should mean the model is correct 80% of the time. Poor calibration can lead to overconfidence, where the model assigns high probabilities to incorrect predictions, or underconfidence, where probabilities are too low. Several techniques address this, such as temperature scaling, which adjusts the model’s output distribution, or isotonic regression, which calibrates probabilities post-hoc. The choice of calibration method depends on factors such as the model architecture, the dataset characteristics, and the downstream application. Effective calibration is crucial for safe and reliable deployment of machine learning systems, particularly in high-stakes domains like healthcare or autonomous driving, where accurate confidence estimates are essential for decision-making.
Ablation Experiments#
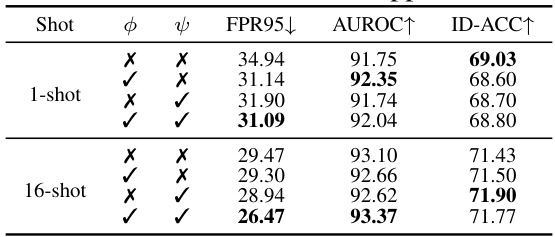
Ablation studies systematically remove components of a model or system to assess their individual contributions. In a machine learning context, this often involves removing or altering parts of the architecture (e.g., layers, modules), hyperparameters, data augmentation strategies, or training procedures. The goal is to understand precisely how each component affects the overall performance, helping isolate the most crucial elements and identify areas for improvement. Well-designed ablation experiments are essential for establishing causality, distinguishing between correlation and causation in performance changes. They provide strong evidence supporting claims about a model’s design choices, demonstrating that performance gains are due to specific design features, rather than other factors. A thorough ablation study strengthens the reliability and validity of the model by showing robustness to changes in different parts of the system. However, it is important to note that ablation studies don’t guarantee that a model is optimal, as they only evaluate the effect of removing components; other, perhaps better, architectures or designs may exist that haven’t been explored. Furthermore, interpreting ablation results requires careful consideration of the interactions between components; removal of one part might unexpectedly impact other components, complicating the interpretation. Finally, the scope of ablation studies should be carefully selected; attempting to ablate every possible component can be impractical and inefficient, so a focused approach, guided by prior hypotheses, is often most effective.
Future of OOD#
The future of out-of-distribution (OOD) detection hinges on addressing current limitations. More robust methods are needed to handle the inherent ambiguity in defining OOD, particularly in complex, high-dimensional data spaces. Improved calibration techniques are crucial to mitigate overconfidence and provide reliable uncertainty estimates. Developing more efficient algorithms will enable OOD detection in resource-constrained environments. Addressing the scarcity of labeled OOD data remains a critical challenge, requiring innovative approaches like semi-supervised and self-supervised learning. Future research should explore the integration of OOD detection with other crucial machine learning tasks, including active learning, model explainability, and continual learning, to foster more reliable and adaptable AI systems. Bridging the gap between research and real-world applications is paramount, requiring a shift towards more practical and robust solutions applicable in diverse domains.
More visual insights#
More on figures
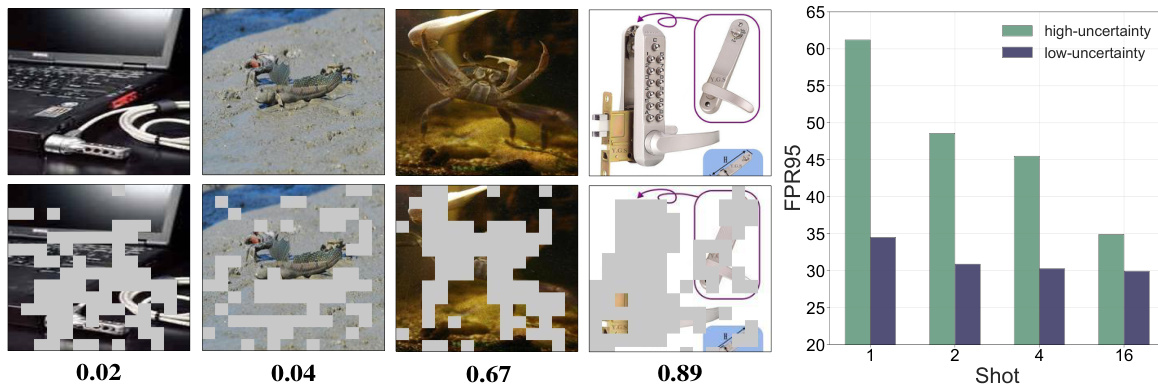
This figure empirically demonstrates the impact of the uncertainty of ID samples on OOD detection performance. The left and center panels show how extracted OOD features from ID data become less reliable as the uncertainty increases (indicated by prediction probabilities). The right panel shows the significantly worse OOD detection performance of the LoCoOp method as the uncertainty of the training ID data increases.

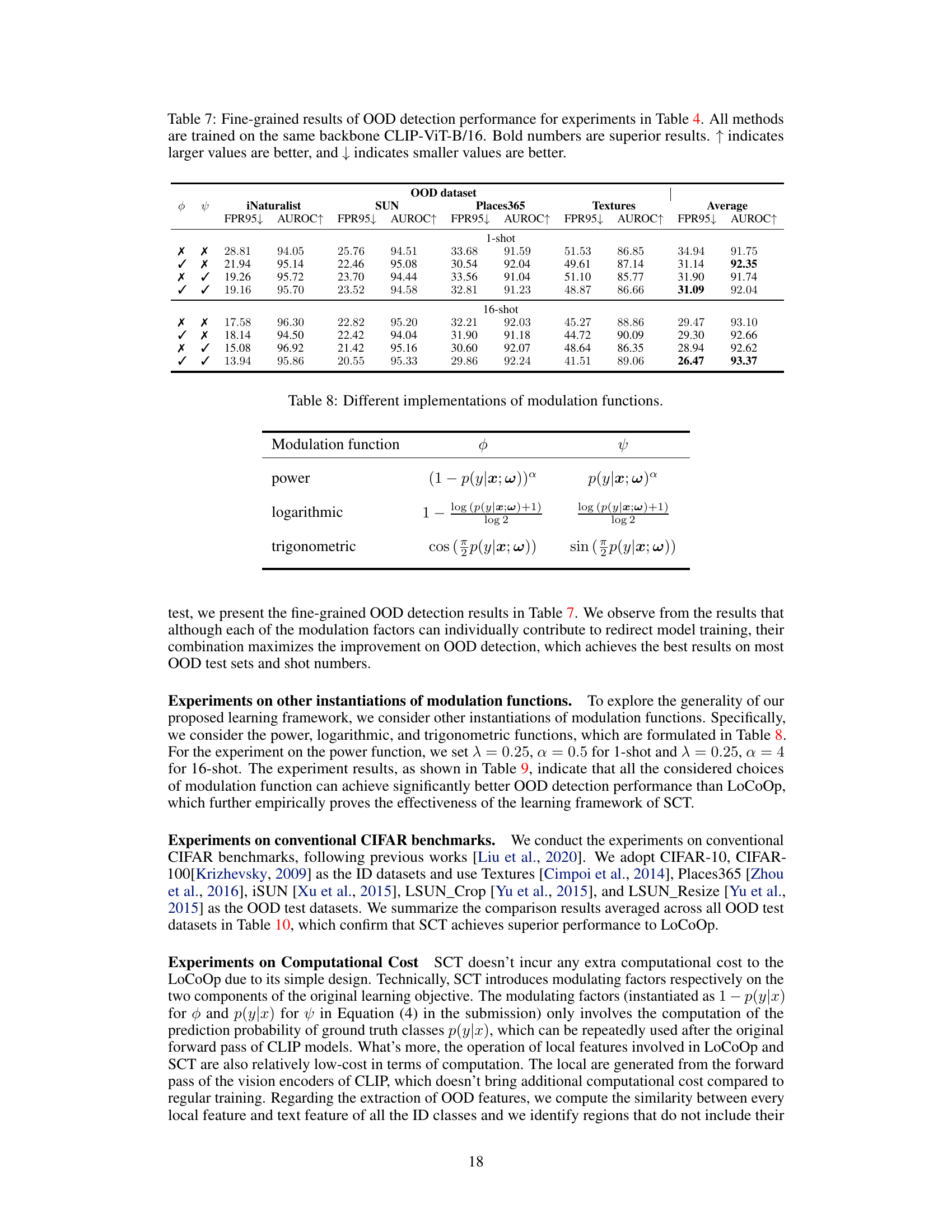
This figure presents the ablation study results to demonstrate the effectiveness of different components of the proposed Self-Calibrated Tuning (SCT) framework. Panel (a) shows the effect of varying the regularization weight (λ) on OOD detection performance. Panel (b) compares different OOD regularization functions (Entropy Maximization, MSP, Energy) used in SCT. Panel (c) shows the robustness of SCT across different CLIP architectures (ViT-B/16, ViT-B/32, RN50). Panel (d) evaluates the impact of different OOD feature extraction methods (Rank, Probability, Entropy) on SCT’s performance.
This figure shows the impact of uncertainty on OOD detection performance. The left and center panels illustrate that extracted OOD features from uncertain ID data are unreliable. The right panel shows that LoCoOp’s performance significantly decreases with increasing uncertainty in the ID data.

This figure shows the imperfect foreground-background decomposition performed by a CLIP model fine-tuned with the CoOp method using 16-shot data. The top row displays original images from ImageNet-1k, while the bottom row highlights the ID-irrelevant context extracted from those images. The colored patches represent the extracted features. The imperfect decomposition leads to many extracted features being ID-related rather than truly out-of-distribution (OOD), negatively impacting OOD detection performance.
More on tables

This table presents a comparison of various methods for out-of-distribution (OOD) detection on the ImageNet-1k dataset. It compares zero-shot methods (MCM, GL-MCM), post-hoc methods (MSP, ODIN, Energy, ReAct, MaxLogit), and prompt-tuning based methods (CoOp, LoCoOp, IDLike, NegPrompt, LSN, SCT). The results are reported in terms of False Positive Rate at 95% True Positive Rate (FPR95) and Area Under the ROC Curve (AUROC). The table shows the performance of each method under 1-shot and 16-shot training scenarios.
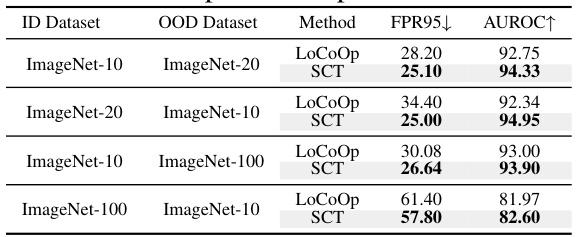
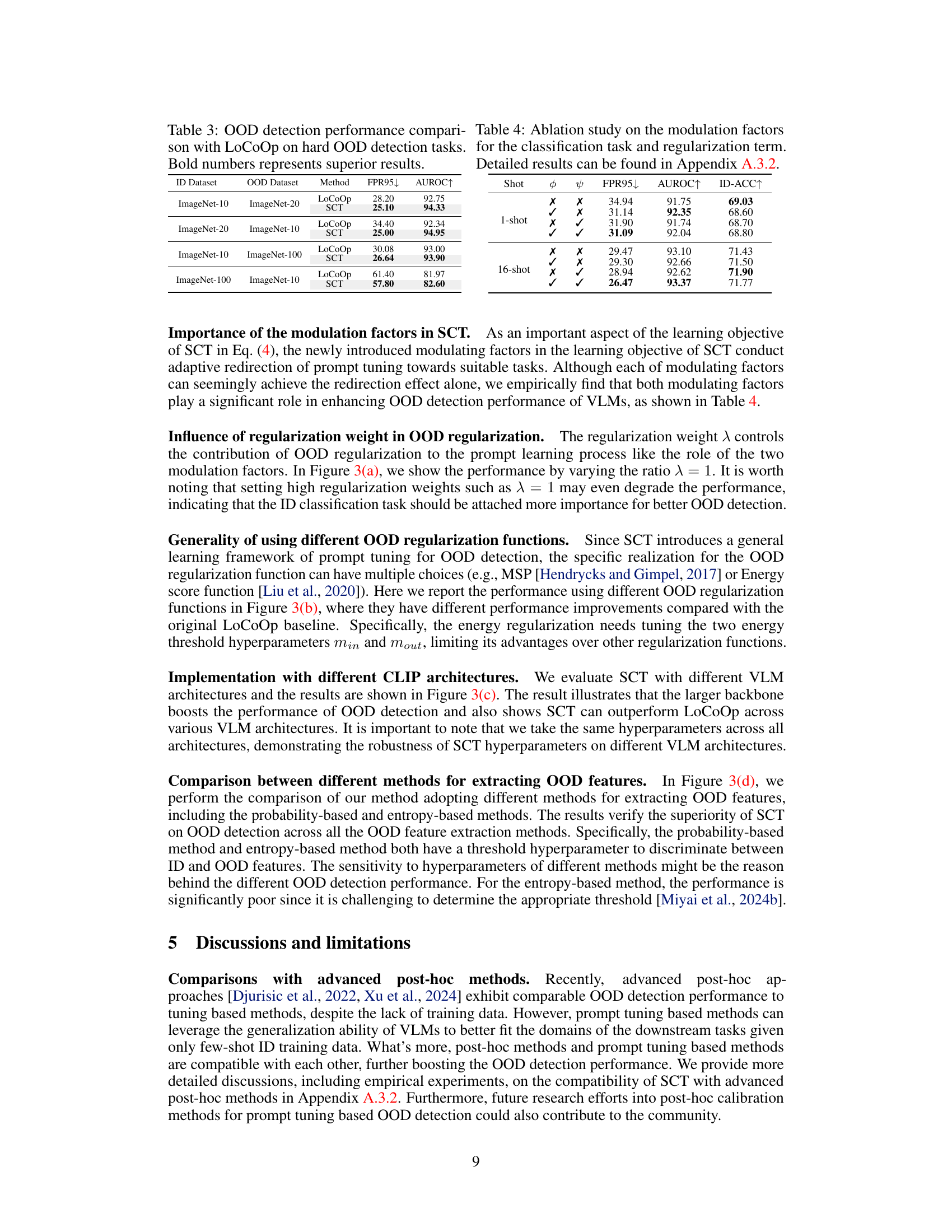
This table presents a comparison of the OOD detection performance between the proposed SCT method and the baseline LoCoOp method on four different hard OOD detection tasks. Each task involves a different combination of ImageNet subsets as ID and OOD datasets. The results are shown in terms of FPR95 and AUROC, with lower FPR95 and higher AUROC indicating better performance. The bold numbers highlight where SCT outperforms LoCoOp.
This table compares the performance of various OOD detection methods on the ImageNet-1k benchmark. It includes zero-shot methods, CLIP-based post-hoc methods, and prompt-tuning based methods. The results are presented in terms of FPR95 (False Positive Rate at 95% True Positive Rate) and AUROC (Area Under the Receiver Operating Characteristic curve), with lower FPR95 and higher AUROC indicating better performance. The table shows results for 1-shot and 16-shot settings for prompt-tuning based methods and averages across multiple trials.
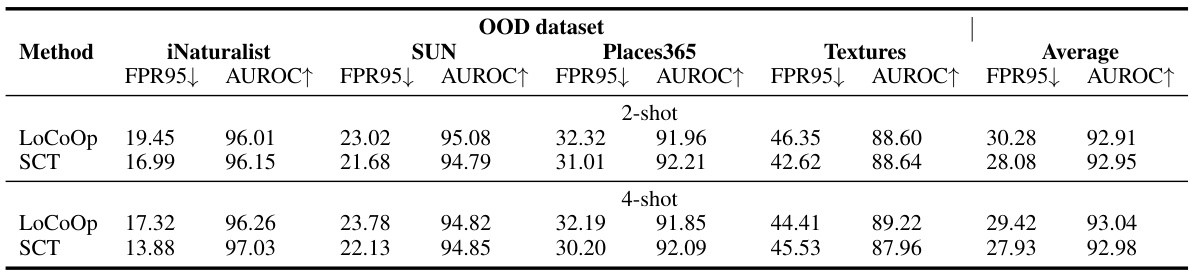
This table presents a comparison of various OOD detection methods on the ImageNet-1k benchmark. It includes zero-shot methods, post-hoc methods, and prompt tuning based methods. The table shows the FPR95 and AUROC metrics for each method across four different OOD datasets (iNaturalist, SUN, Places365, Textures), along with an average performance. Results for prompt tuning methods are averaged over multiple trials, with standard deviations reported.
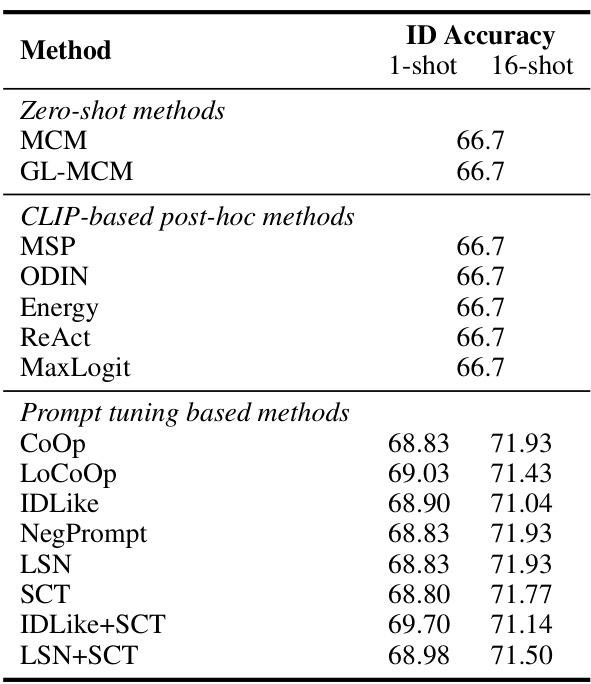
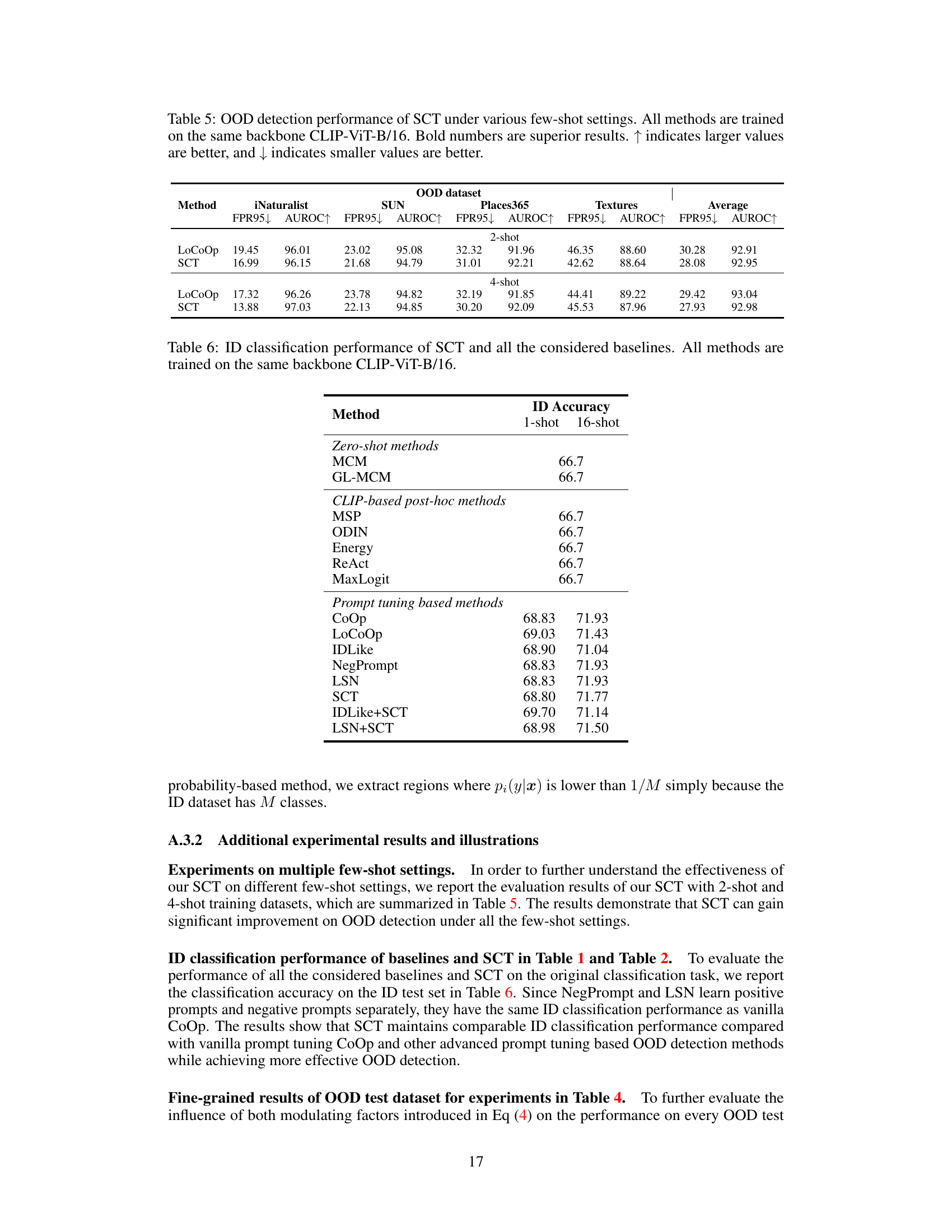
This table presents the in-distribution (ID) classification accuracy for various OOD detection methods, including the proposed SCT (Self-Calibrated Tuning) and several baselines (zero-shot methods, CLIP-based post-hoc methods, and prompt tuning based methods). The results are shown for both 1-shot and 16-shot training scenarios, demonstrating the impact of the number of training samples on the ID classification accuracy, while also allowing comparison of the proposed method’s performance with other OOD detection techniques.
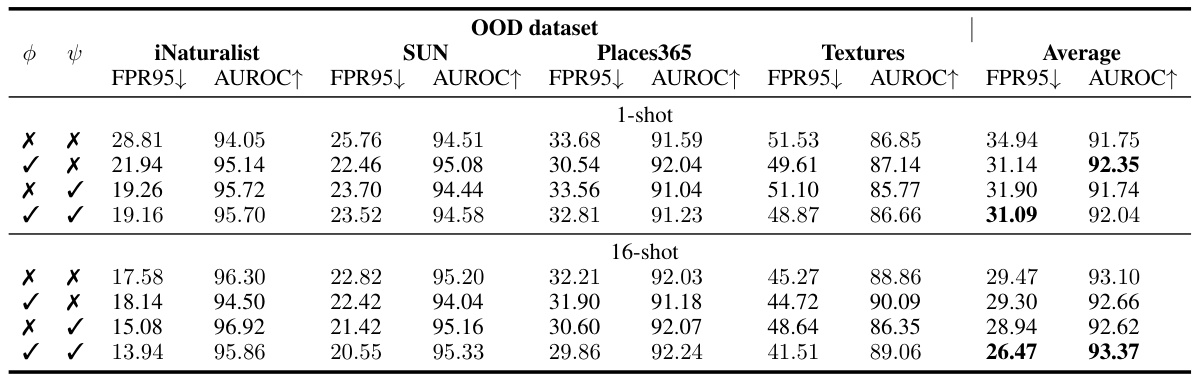
This table presents a comparison of various OOD detection methods on the ImageNet-1k dataset. It includes zero-shot methods, CLIP-based post-hoc methods, and prompt tuning-based methods. The results are presented for AUROC and FPR95 metrics, showing the performance of each method across multiple OOD datasets. The table also distinguishes between 1-shot and 16-shot settings for the prompt-tuning methods, highlighting the impact of the number of training samples on performance.

This table compares the performance of various OOD detection methods on the ImageNet-1k dataset. It includes zero-shot methods, CLIP-based post-hoc methods, and prompt tuning-based methods. The results are shown for multiple OOD datasets and are evaluated using AUROC and FPR95 metrics. Note that the prompt tuning methods utilize few-shot learning, and their results are averaged over multiple trials.
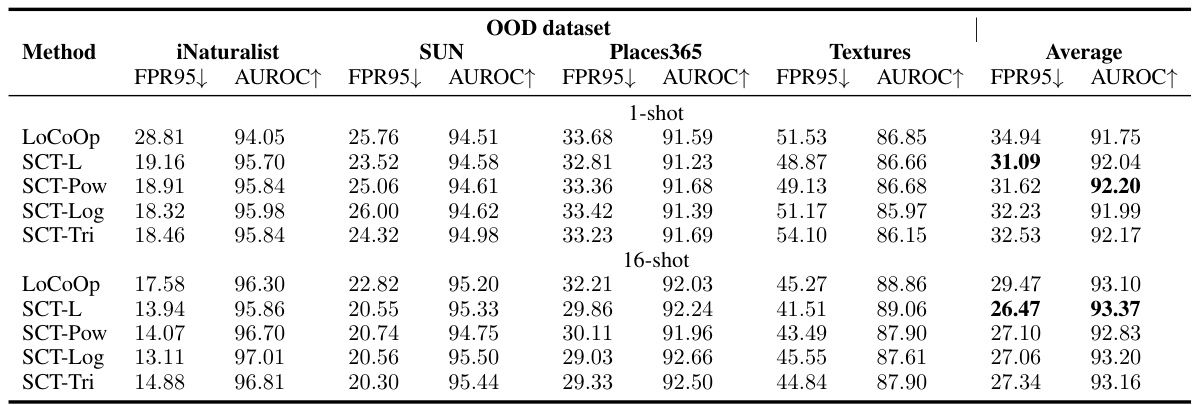
This table presents a comparison of various methods for out-of-distribution (OOD) detection on the ImageNet-1k dataset. It shows the performance (FPR95 and AUROC) of different methods, categorized into zero-shot methods, CLIP-based post-hoc methods, and prompt tuning-based methods. The results are broken down by OOD dataset (iNaturalist, SUN, Places365, Textures) and shot number (1-shot and 16-shot) for prompt-tuning methods, providing a comprehensive comparison of different approaches to OOD detection.

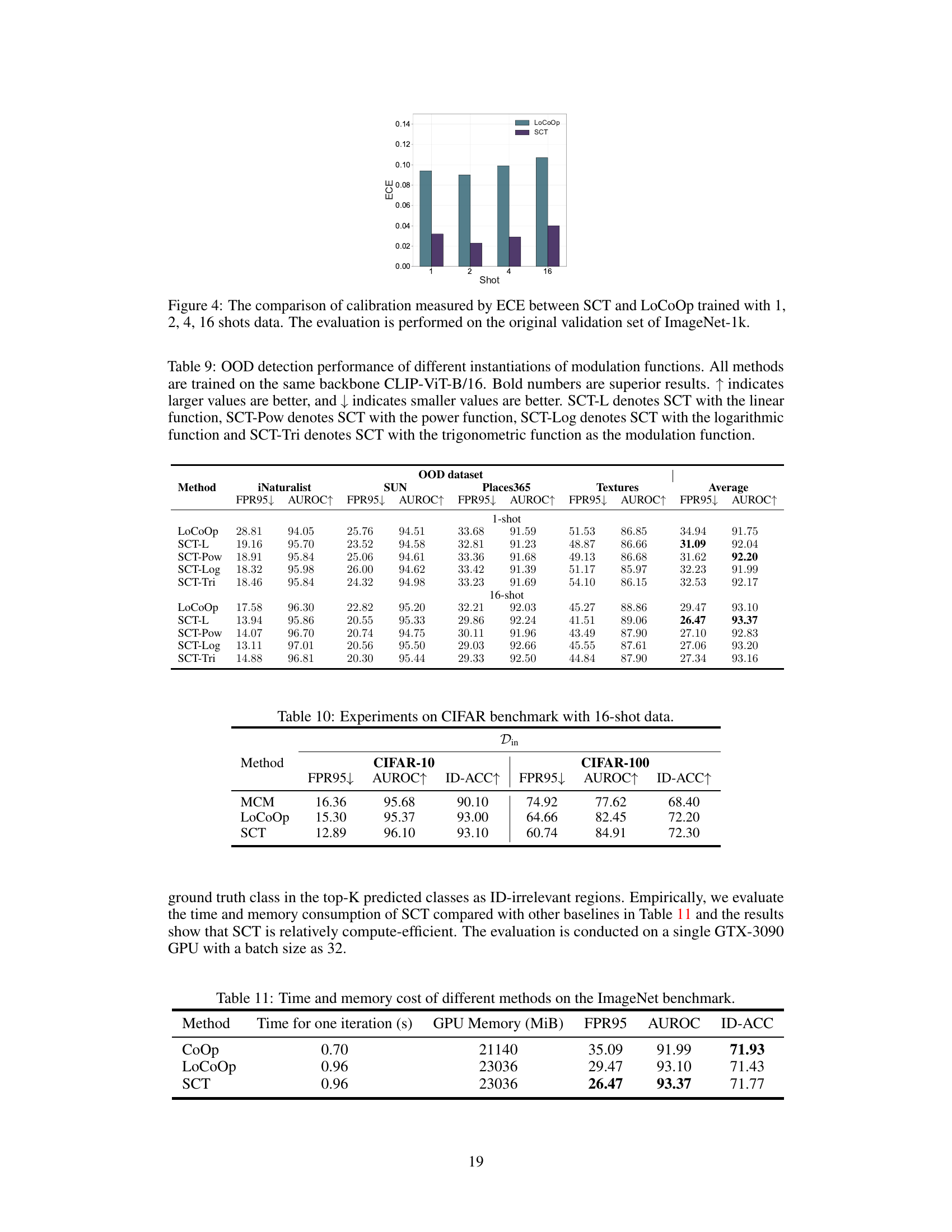
This table presents the results of experiments conducted on CIFAR-10 and CIFAR-100 datasets using 16-shot training data. It compares the performance of three OOD detection methods: MCM, LoCoOp, and the proposed SCT (Self-Calibrated Tuning). The metrics used for evaluation are FPR95 (False Positive Rate at 95% True Positive Rate), AUROC (Area Under the Receiver Operating Characteristic Curve), and ID-ACC (In-distribution accuracy). The table showcases the effectiveness of SCT in achieving better OOD detection performance compared to the baseline methods while maintaining comparable in-distribution accuracy.

This table compares the performance of various OOD detection methods on the ImageNet-1k dataset. It includes zero-shot methods (MCM, GL-MCM), post-hoc methods (MSP, ODIN, Energy, ReAct, MaxLogit), and prompt-tuning based methods (CoOp, LoCoOp, IDLike, NegPrompt, LSN, SCT). The results are reported in terms of FPR95 and AUROC for multiple OOD datasets (iNaturalist, SUN, Places365, Textures) with both 1-shot and 16-shot settings, showing the effectiveness of the SCT method.

This table presents the results of experiments conducted to evaluate the compatibility of the proposed Self-Calibrated Tuning (SCT) method with the NegLabel method. The experiment setup uses 16-shot data. The table shows the performance of NegLabel alone and NegLabel combined with SCT, using several metrics (FPR95, AUROC) across different OOD datasets (iNaturalist, SUN, Places365, Textures). The results demonstrate how combining SCT with other state-of-the-art OOD detection methods can enhance their overall performance.
Full paper#