↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current latent-based image generative models use autoencoders to map images into a latent space. However, autoregressive models, despite using the same latent space, significantly underperform. This paper investigates this discrepancy, proposing that latent space stability is crucial for generative performance. Previous methods prioritized reconstructive quality, potentially neglecting generative aspects.
The paper introduces DiGIT, a new image tokenizer. DiGIT uses K-means clustering on latent features from a self-supervised learning model to create a stable and discrete latent space. Experiments show that using this new method within autoregressive models dramatically improves image understanding and generation, outperforming previous methods. This highlights the importance of latent space stability for generative modeling and opens new research avenues in image autoregressive model development.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in image generation and self-supervised learning. It challenges the common assumption that a latent space optimized for reconstruction is also ideal for generation. By demonstrating superior performance of an autoregressive model using a novel, stabilized latent space, the paper opens up new avenues for research in image autoregressive modeling and the interplay between different latent space optimization methods. The findings offer significant advancements in image generation, prompting exploration of improved latent space representations for other generative models.
Visual Insights#
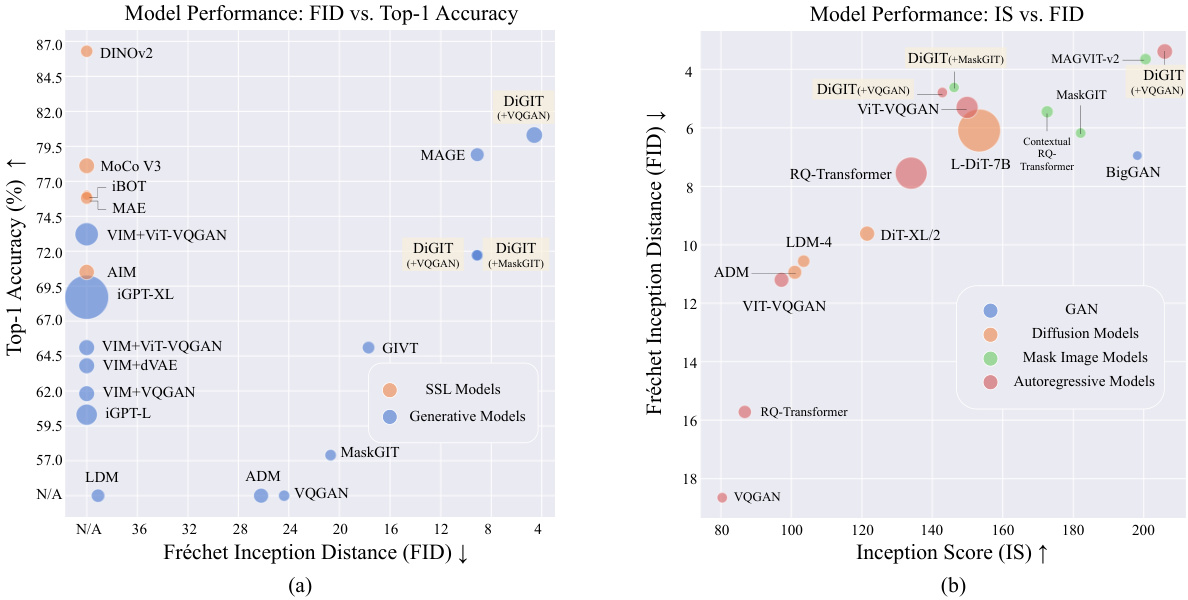
This figure compares different image generation models based on their performance in linear probing (measuring image understanding) and class-unconditional/conditional image generation. The size of each bubble corresponds to the number of model parameters. Subfigure (a) shows class-unconditional performance (FID and Top-1 Accuracy), and subfigure (b) shows class-conditional performance (FID and Inception Score). The key takeaway is that DiGIT achieves state-of-the-art (SOTA) results in both linear probing and image generation.

This table presents the results of an experiment designed to assess the stability of latent spaces generated by two different methods: VQ Token and Discriminative Token. The experiment introduces varying levels of noise (SNR) to image pixels and measures the impact on the latent spaces. The change in tokens (VQ Token change and Disc Token change) and the cosine similarity between the tokens before and after adding noise (VQ Token cos-sim and Disc Token cos-sim) are reported for each SNR level. Lower change values and higher cosine similarity values indicate greater stability.
In-depth insights#
Latent Space Stability#
The concept of “Latent Space Stability” is crucial for the success of image autoregressive models. The paper highlights that while latent diffusion models (LDMs) and masked image models (MIMs) achieve high-quality image generation, autoregressive models significantly lag behind. This is attributed to the instability of the latent space used by autoregressive models. An unstable latent space means that small perturbations in the pixel space can lead to large changes in the latent representation, causing errors to propagate during the autoregressive generation process. Conversely, the iterative nature of LDMs and MIMs allows for error correction, making them less susceptible to latent space instability. The paper suggests that optimizing for a stable latent space, rather than solely focusing on reconstruction quality, is key for improving autoregressive model performance. This insight is validated by proposing a new method that stabilizes the latent space using a discriminative self-supervised learning model. The resulting discrete image tokenizer then enables the autoregressive model to generate superior results. This is a key advancement as it bridges the performance gap between autoregressive and iterative image generative models.
DiGIT Tokenizer#
The DiGIT tokenizer represents a novel approach to image tokenization, departing from traditional autoencoder-based methods. Instead of relying on reconstruction-focused autoencoders like VQGAN, DiGIT leverages a discriminative self-supervised learning model (DINOv2) to generate discrete image tokens. This key difference leads to a more stable latent space, crucial for the success of autoregressive generative models. The stability is achieved by disentangling the encoder and decoder training, focusing initially on feature extraction and later on pixel reconstruction. This approach contrasts with iterative methods that correct for latent space instability during generation. By applying K-Means clustering on the learned features, DiGIT creates a codebook of discrete tokens, improving both image understanding and generation, demonstrating results that surpass those obtained by existing autoregressive models. The disentanglement of training and the use of a discriminative model are critical to the tokenizer’s effectiveness, demonstrating the value of a well-structured, stable latent space for autoregressive image generation.
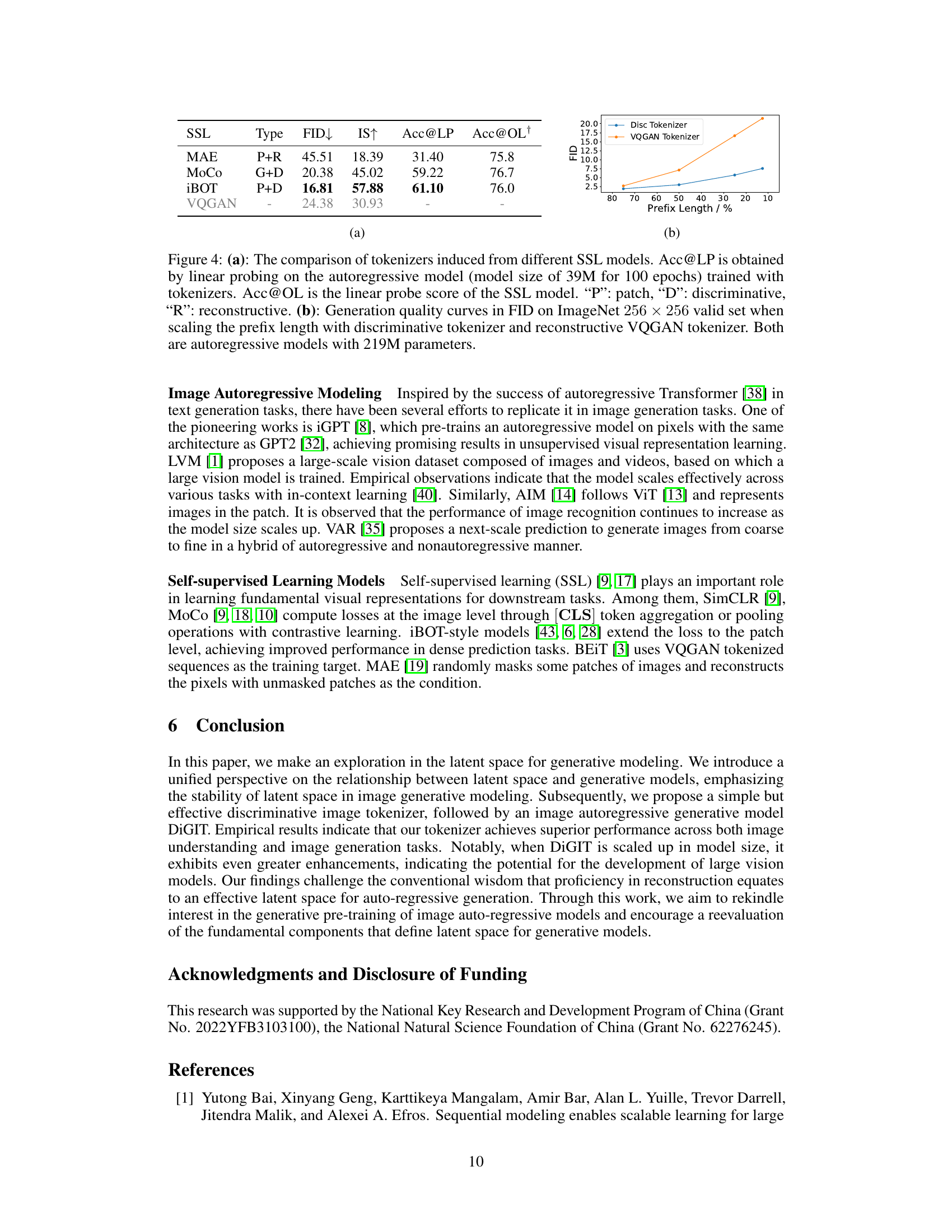
Autoregressive Modeling#
Autoregressive modeling, in the context of image generation, presents a compelling alternative to iterative methods. Unlike diffusion models that iteratively refine noisy images, autoregressive models predict the next pixel (or token) conditioned on the preceding ones, directly constructing the image. This approach has inherent advantages in terms of sample efficiency and theoretical simplicity. However, a major challenge lies in the stability of the latent space—the compressed representation of the image used for generation. A stable latent space is crucial for accurate autoregressive generation, as error propagation in sequential prediction can severely impact the quality of the resulting image. The research emphasizes the importance of stabilizing the latent space, suggesting that the success of autoregressive models depends heavily on addressing this stability issue. By using a novel method for image tokenization, DiGIT significantly improves the generation quality of autoregressive models, demonstrating the potential of this approach when coupled with an effective latent space management technique. The results highlight the importance of optimizing the latent space for image generation and showcase the power of autoregressive models when this optimization is successfully achieved.
Generative Performance#
Generative performance in image AI models is a crucial aspect, often evaluated through metrics like FID and Inception Score. Higher Inception Scores indicate more diverse and higher-quality generated images, while lower Fréchet Inception Distances (FID) show that generated images are closer to real images in terms of visual features. The paper highlights a significant discrepancy: although employing the same latent space, autoregressive models lag behind diffusion and masked image models in image generation. This suggests that merely optimizing a latent space for reconstruction isn’t sufficient for generative capabilities. Latent space stability emerges as a key factor; iterative models, like diffusion models, can correct errors from unstable latent representations, unlike the autoregressive approach. Therefore, methods focusing on stabilizing the latent space before applying autoregressive modeling, as the proposed method in the paper attempts to do, are likely to yield significant improvements in generative performance.
Future Directions#
Future research could explore several promising avenues. Improving the stability of the latent space is crucial, potentially through novel architectures or training methodologies beyond K-Means. Enhancing the scalability of the model to handle larger datasets and higher resolutions is a key challenge. Investigating alternative SSL models for tokenizer training could lead to further performance gains. Direct pixel prediction from the discrete tokens, bypassing intermediate VQGAN or MaskGIT stages, would greatly streamline the process and could unlock better autoregressive models. Finally, exploring different architectures (beyond Transformers) and assessing their compatibility with the proposed methods should be considered. This unified perspective on latent space stability has promising implications, warranting further exploration in both theoretical analysis and empirical evaluations.
More visual insights#
More on figures
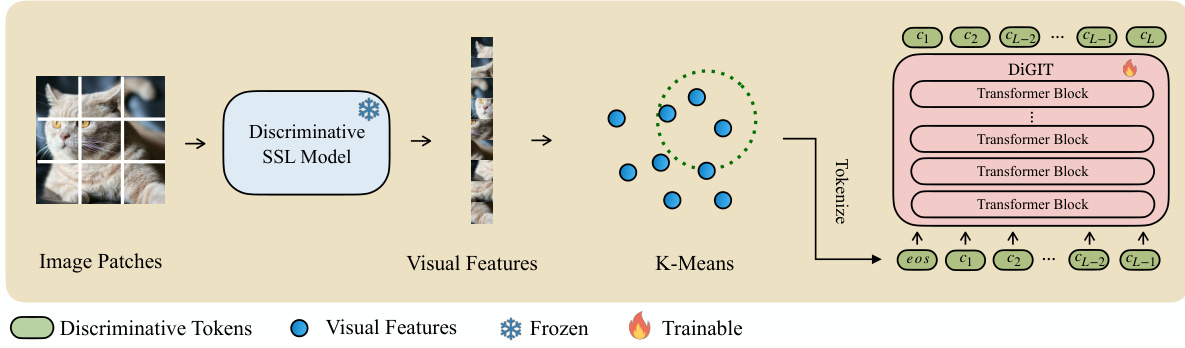
The figure illustrates the architecture of the DIGIT model. An image is divided into patches, which are fed into a frozen discriminative self-supervised learning (SSL) model, such as DINOv2. This model extracts visual features from each patch. These features are then clustered using K-Means, creating a codebook of discriminative tokens. The resulting tokens are then fed into the DIGIT autoregressive model. The DIGIT model is a transformer architecture containing multiple transformer blocks which utilizes the next-token prediction principle for generating an image from the sequence of tokens, starting with a beginning-of-sequence token. The model is trained in a way that the discriminative SSL model’s parameters are frozen, and the DiGIT transformer’s parameters are trainable.

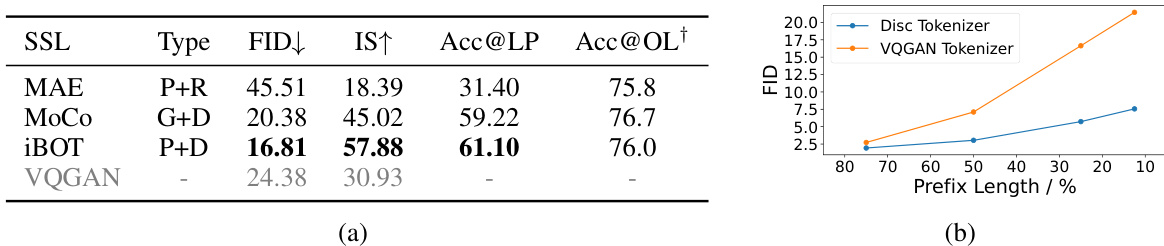
This figure shows the ablation study of DiGIT, a discriminative image tokenizer for autoregressive image generation. Part (a) displays the results of image generation experiments comparing various model configurations: the baseline VQ Tokenizer, the addition of the discriminative tokenizer, longer training (400 epochs), and scaling up the model size (732M). It demonstrates improvements in both FID (Fréchet Inception Distance) and IS (Inception Score) metrics as more advanced techniques are incorporated. Part (b) presents the results of a linear probe analysis on the pre-trained DiGIT-base model with different numbers of K-means clusters (8192, 4096, and 1024). It illustrates how the linear-probe accuracy changes across different transformer layers, suggesting an optimal number of clusters for improved image understanding.
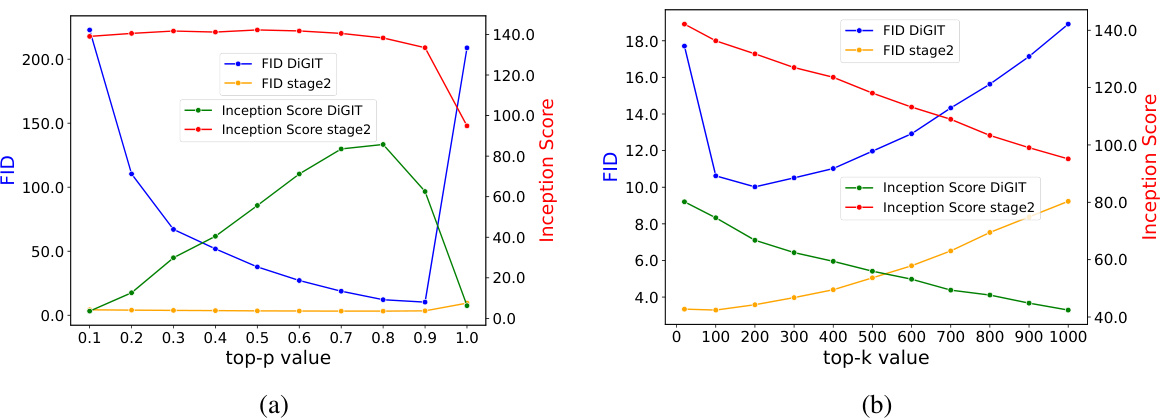
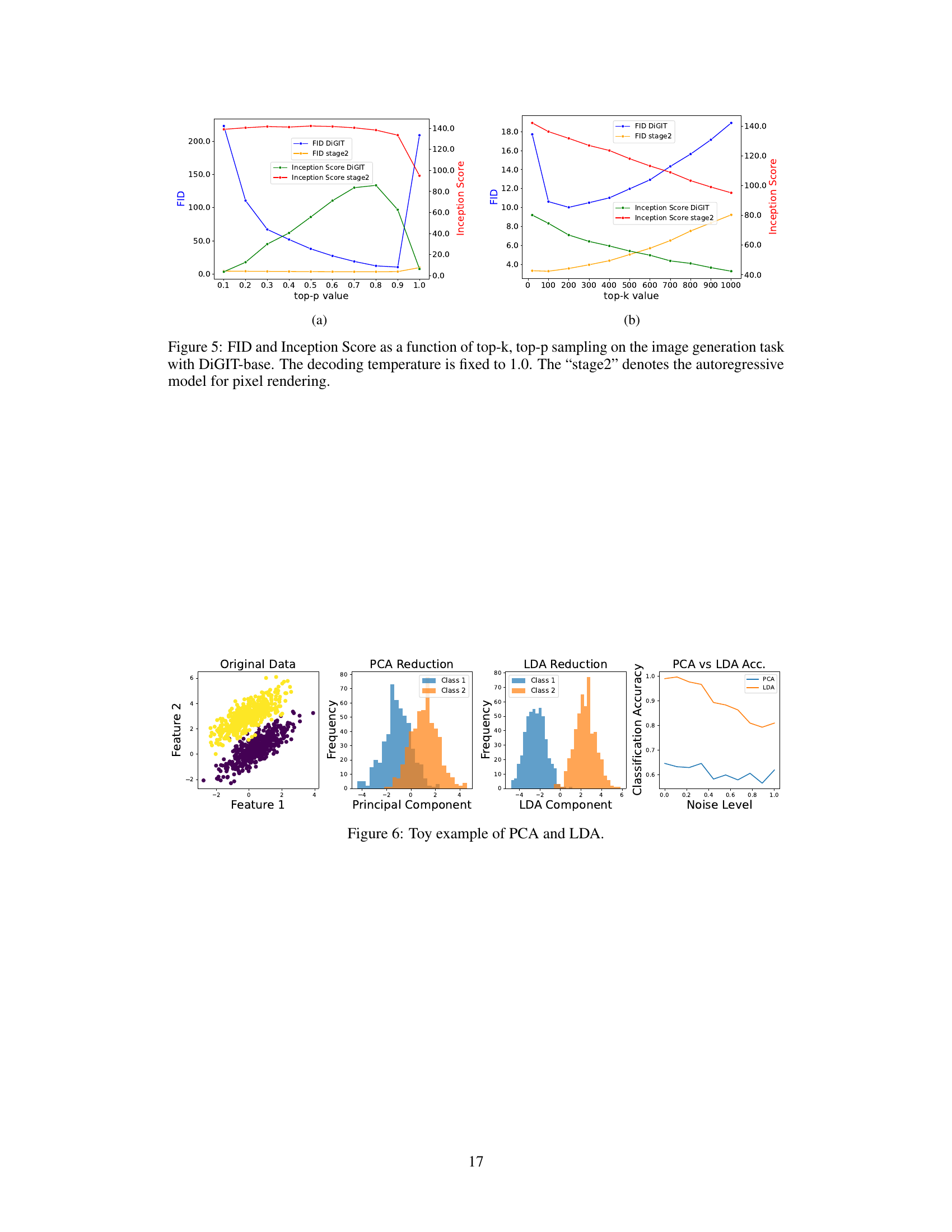
This figure shows the impact of top-k and top-p sampling techniques on the FID and Inception Score metrics during image generation using the DiGIT-base model. The decoding temperature is held constant at 1.0. The results show how different sampling strategies affect the quality of the generated images, with ‘stage2’ referring to a separate autoregressive model used for pixel rendering.

This figure shows a comparison of Principal Component Analysis (PCA) and Linear Discriminant Analysis (LDA) on a toy dataset with two classes. The leftmost panel displays the original two-dimensional data, clearly showing two overlapping clusters. The middle panels show the one-dimensional projections obtained using PCA and LDA, respectively. The PCA projection attempts to maximize variance, leading to a considerable amount of overlap between the two classes. The LDA projection, on the other hand, prioritizes maximizing the separation between the classes. The rightmost panel illustrates this clearly by showing classification accuracy under increasing levels of added Gaussian noise to the data; LDA consistently outperforms PCA in terms of classification accuracy as noise increases.

This figure showcases the results of class-unconditional image generation using the DiGIT model on the ImageNet dataset. The images are generated at a resolution of 256x256 pixels. The figure displays a grid of diverse images generated by the model, demonstrating its ability to generate a wide range of objects and scenes.
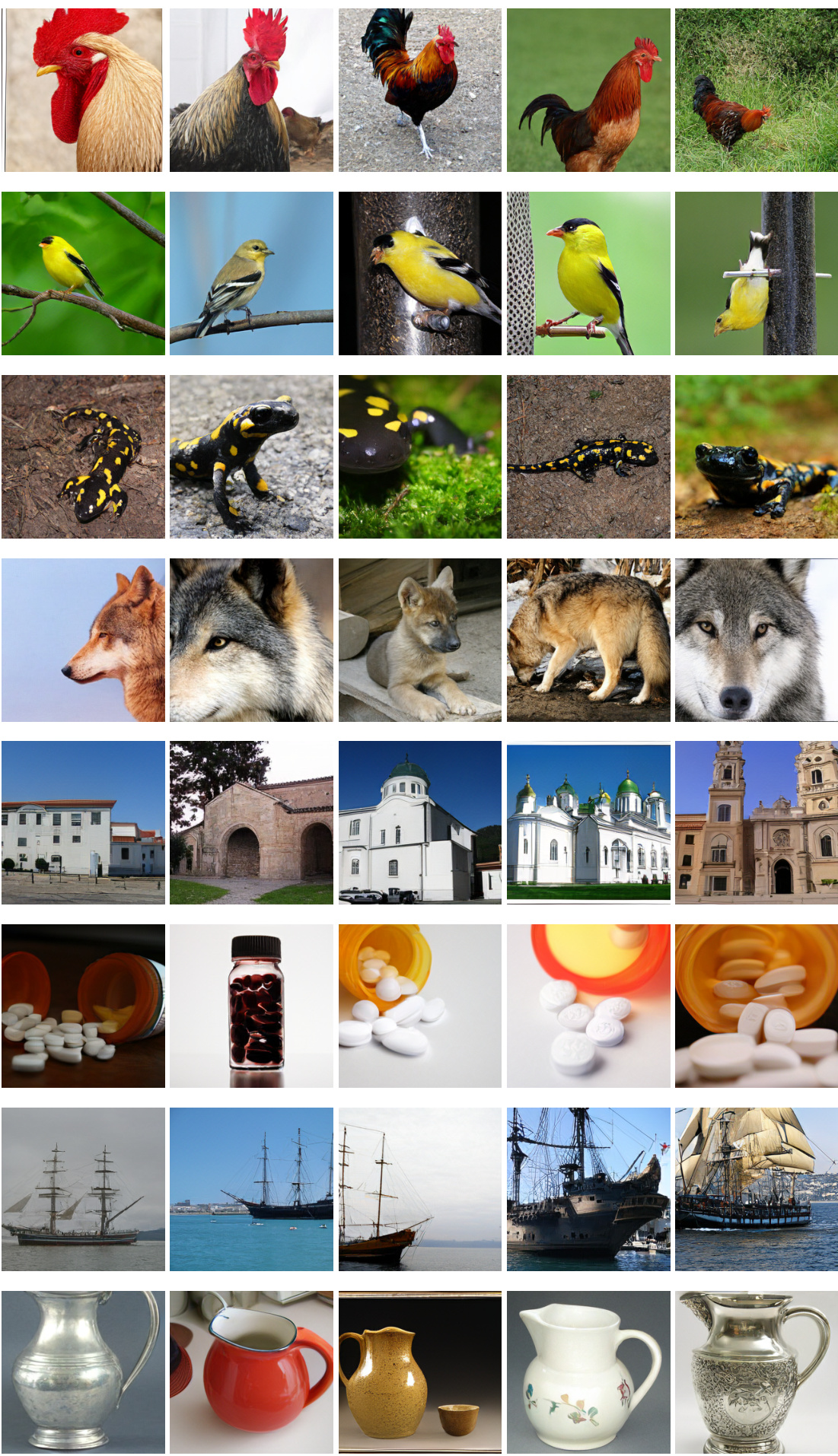
This figure shows the results of class-conditional image generation using the DiGIT model on the ImageNet dataset. Each row displays images generated from the same class label. It demonstrates the model’s ability to generate diverse and realistic images within a given class.
More on tables
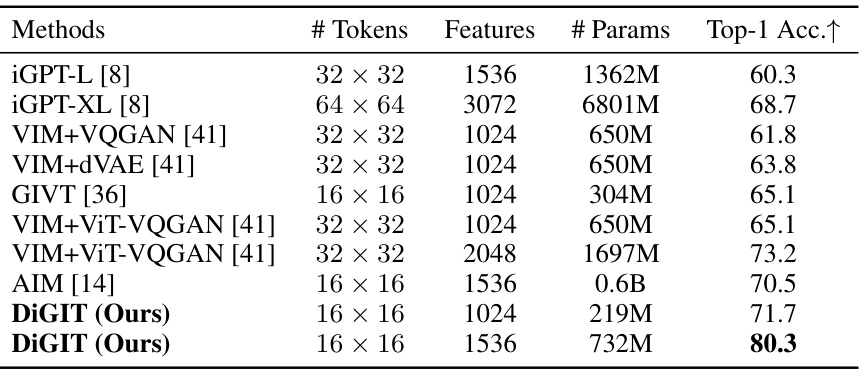
This table compares the linear probing accuracy of various image autoregressive generative models on the ImageNet dataset. The models are evaluated based on their ability to learn semantic features using a linear probe classifier. The table shows the number of tokens, features, parameters, and the resulting top-1 accuracy for each model. This demonstrates the models’ performance in image understanding tasks, showing that higher parameter counts do not always correlate with better performance.
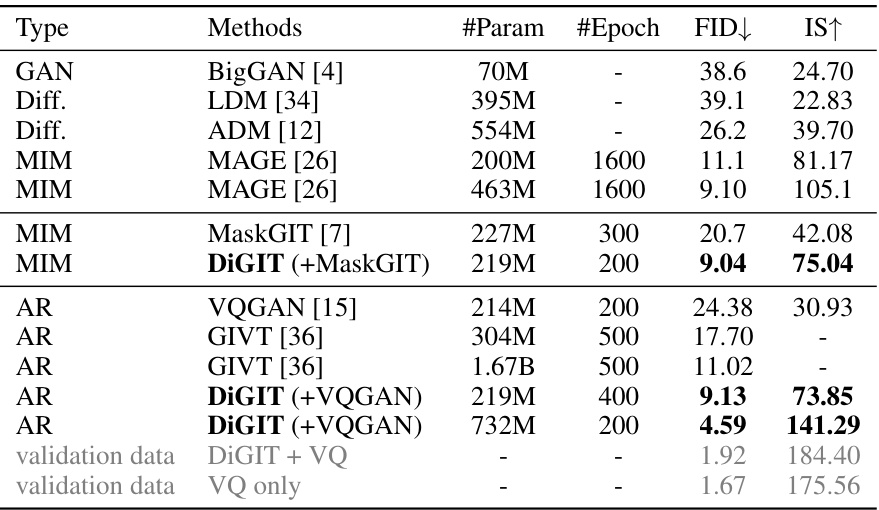
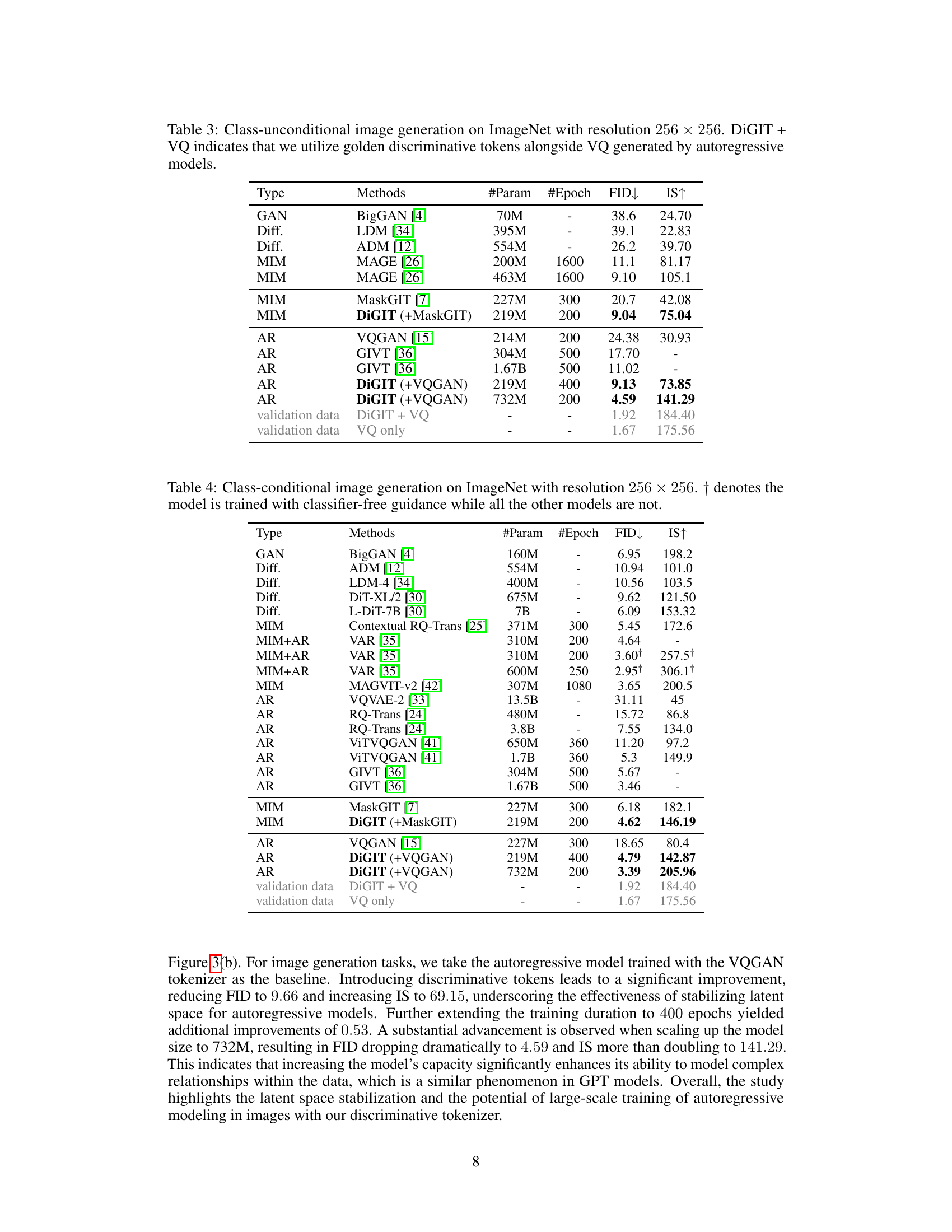
This table presents a comparison of different image generation models on the ImageNet dataset, focusing on class-unconditional image generation. The table includes the model type (GAN, Diffusion, MIM, or Autoregressive), the method used, the number of parameters, the number of training epochs, the Fréchet Inception Distance (FID) score (lower is better), and the Inception Score (IS) (higher is better). DiGIT models are highlighted, demonstrating improved FID and IS scores, particularly with larger model sizes.
This table presents a comparison of different image generation methods on the ImageNet dataset, focusing on class-unconditional image generation with a resolution of 256x256 pixels. The table includes various model types (GAN, Diffusion, MIM, AR), methods, the number of parameters, the number of training epochs, and the resulting Fréchet Inception Distance (FID) and Inception Score (IS) values. Lower FID and higher IS scores indicate better image quality. The table also highlights results from the proposed DiGIT model, showcasing its performance both alone and in conjunction with other methods (VQGAN and MaskGIT).
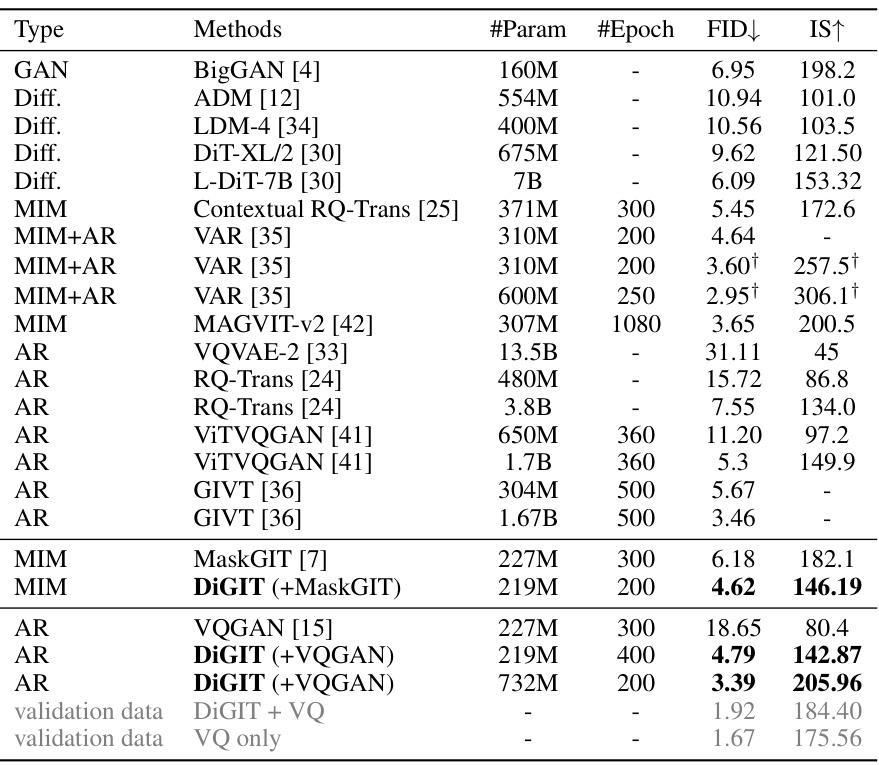
This table presents the results of class-conditional image generation experiments on the ImageNet dataset with images of size 256x256. Different generative model types (GAN, Diffusion, MIM, AR) and specific models are compared using Fréchet Inception Distance (FID) and Inception Score (IS) metrics, lower FID and higher IS indicating better generation quality. The ‘†’ symbol indicates that a specific model was trained with classifier-free guidance, a technique that influences generation.
Full paper#