↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Traditional adversarial attacks focus on minimal geometric perturbations to deceive classifiers. However, these methods are easily countered by modern defenses. Furthermore, these minimal changes often result in unnatural-looking adversarial examples.
This paper proposes a probabilistic approach, which models semantic meaning as a distribution. By using probabilistic generative models, the researchers inject subjective semantic understanding or leverage pre-trained models to create adversarial examples. This approach leads to adversarial examples with significant pixel modifications that still preserve overall semantics, making them more difficult to detect by both classifiers and humans. The empirical results show the proposed methods outperform traditional methods in terms of success rates against adversarial defenses and transferability.
Key Takeaways#
Why does it matter?#
This paper is important because it introduces a novel probabilistic perspective to adversarial attacks, improving their effectiveness against adversarial defenses while maintaining semantic meaning. This opens avenues for developing more robust and natural-looking adversarial examples and improves the understanding of adversarial attacks’ transferability. Researchers can leverage this probabilistic approach to develop more advanced adversarial attacks and more effective defense mechanisms.
Visual Insights#
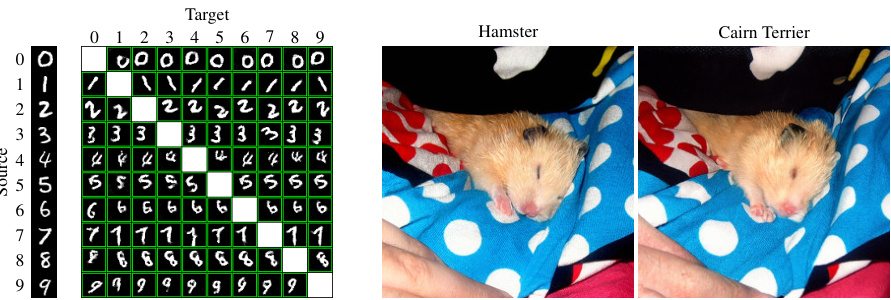
This figure showcases examples of adversarial examples generated by the proposed method. The left side shows MNIST digits that have been modified while maintaining their semantic meaning (i.e., they are still recognizable as the same digit), even with transformations like scaling or rotation. The right side presents an example of a hamster image that has been substantially altered, but still retains its natural appearance and semantic content.
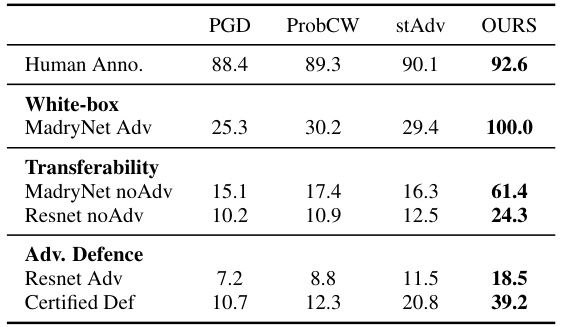
This table presents the success rates of various adversarial attack methods on the MNIST dataset. The methods compared are Projected Gradient Descent (PGD), Probabilistic Certified Adversarial examples (ProbCW), Strong Adversarial examples (stAdv), and the proposed method from the paper. Success rates are shown for several scenarios: human annotation (to assess the perceptibility of the adversarial examples), white-box attacks against the MadryNet classifier (both adversarially and non-adversarially trained), transferability to other classifiers (ResNet, both adversarially and non-adversarially trained), and attacks against certified defenses. The proposed method demonstrates higher success rates in all scenarios.
In-depth insights#
Prob. Adversarial Attacks#
Probabilistic adversarial attacks represent a significant advancement in adversarial machine learning. They move beyond traditional methods that rely solely on geometric distance metrics, instead incorporating a probabilistic model of semantic meaning into the generation of adversarial examples. This allows for the creation of examples that are visually similar to the originals, yet still fool the target classifier, making them more difficult to detect by humans and more transferable across different models. The core idea is to define adversarial examples as samples from a probability distribution that incorporates the victim classifier’s decision boundary (victim distribution) and a measure of semantic similarity to the original sample (distance distribution). This framework enables the use of probabilistic generative models, like energy-based models or diffusion models, to create the necessary distributions. The ability to leverage subjective semantic understanding in defining these distributions is a key strength, though careful consideration must be given to the potential for misuse of this methodology. The approach is principled and grounded in a well-defined optimization problem, offering a theoretical foundation beyond many existing heuristic methods. This results in higher success rates in deceiving even robust classifiers while maintaining a degree of naturalness in the adversarial examples.
Semantic-Aware Models#
Semantic-aware models represent a significant advancement in the field of artificial intelligence by integrating semantic understanding into the model’s architecture. Unlike traditional models that rely solely on low-level features, semantic-aware models leverage higher-level contextual information to improve performance and robustness. This is achieved through techniques such as incorporating knowledge graphs, word embeddings, or other semantic representations. The primary benefit of this approach is enhanced interpretability, as the model’s decision-making process becomes more transparent. Furthermore, by grounding the model in a rich semantic space, performance improves significantly across various tasks. However, challenges remain in effectively representing and incorporating complex semantic relationships. The development of robust and efficient semantic representations continues to be an active area of research. Ultimately, semantic-aware models offer a path towards creating AI systems that are not only powerful but also understandable and explainable.
PGM-Based Approach#
A PGM-based approach for generating semantics-aware adversarial examples leverages the power of probabilistic generative models. Instead of relying solely on geometric constraints, this approach embeds subjective semantic understanding into the process, allowing for more natural and less detectable alterations. This is achieved by using the PGM to model the distribution of semantically equivalent variations of the original image, thereby defining a data-driven notion of semantic similarity. The choice of PGM significantly impacts the effectiveness and realism of the generated examples, with models like energy-based models and diffusion models offering different tradeoffs between efficiency and image quality. Fine-tuning pre-trained PGMs on the original image further enhances the ability to capture image-specific semantic variations, leading to adversarial examples that better preserve the natural appearance of the original data, while still effectively deceiving classifiers.
Transferability Analysis#
A robust transferability analysis is crucial for evaluating the practical effectiveness of adversarial example generation methods. It assesses how well an adversarially trained model generalizes to unseen classifiers or datasets. This is important because real-world applications rarely involve the exact same target model used during the adversarial training process. A thorough transferability analysis would involve testing the generated adversarial examples on multiple classifiers, potentially including those with different architectures, training data, or defense mechanisms. Metrics like attack success rate across various target models directly quantify the robustness and generalizability of the approach. Moreover, the analysis should investigate the underlying factors affecting transferability, such as the similarity between the source and target model architectures, the diversity of the training data, and the type of adversarial defense employed. High transferability indicates a more potent attack method because the generated examples successfully deceive a broad range of classifiers, suggesting inherent vulnerabilities rather than model-specific weaknesses. Conversely, low transferability suggests the method’s effectiveness might be limited, depending heavily on the specific target. Ideally, the analysis also includes a qualitative examination of the adversarial examples to ascertain whether they maintain semantic meaning, which impacts both their effectiveness and their detection by humans. The extent of the visual alterations and the preservation of semantic consistency are significant factors in real-world implications and should be carefully assessed.
Future Research Needs#
Future research should explore more sophisticated adversarial defenses that go beyond simple geometric constraints and consider semantic understanding. Investigating adaptive defense mechanisms that learn and react to evolving attack strategies is crucial. The scalability of proposed methods for larger datasets and higher-resolution images needs further evaluation, alongside a deeper analysis of the trade-off between attack success rates and human-perceptibility. Ethical considerations around adversarial attacks require extensive research, focusing on responsible development and deployment practices to mitigate potential misuse. Finally, research should delve into hybrid approaches, combining various techniques (e.g., incorporating generative models with robust classifiers) to enhance overall security and robustness against adversarial examples.
More visual insights#
More on figures

This figure shows samples drawn from different distributions to illustrate the probabilistic perspective on adversarial examples. (a) and (b) demonstrate samples from the victim distribution (Pvic) with a non-adversarially trained and adversarially trained classifier, respectively. (c) shows samples from the distance distribution (Pdis) using the L2 norm. (d) displays transformations applied to an original image, showcasing the semantic-preserving transformations used to define Pdis. Finally, (e) presents samples from the adversarial distribution (Padv), highlighting successful (green) and failed (red) adversarial examples.
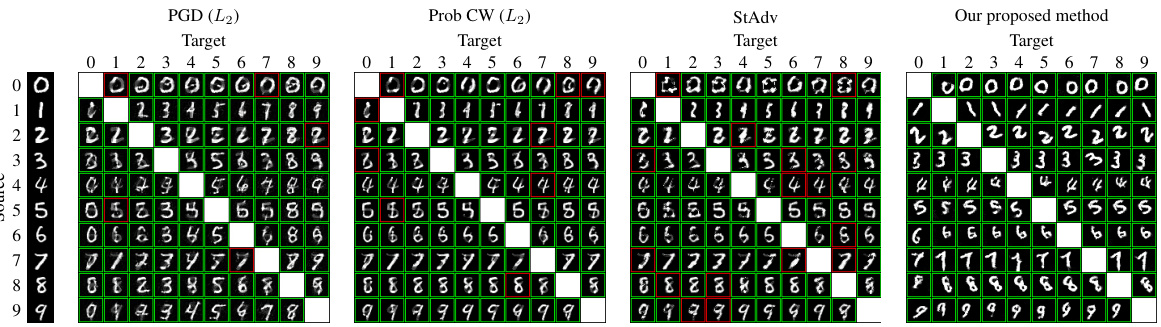
This figure compares the performance of four different methods (PGD, ProbCW, StAdv, and the proposed method) in generating adversarial examples on the MNIST dataset. The comparison focuses on the visual appearance of the generated examples and their ability to successfully fool a MadryNet classifier (a classifier trained to be robust against adversarial attacks). A green border around an image indicates a successful white-box attack (meaning the adversarial example fooled the classifier), while a red border means the attack failed. The figure visually demonstrates how the proposed method produces adversarial examples that maintain more of the original image’s semantic information than other techniques, making them more difficult to distinguish from real examples.

This figure compares the visual results of several adversarial example generation methods on the ImageNet dataset. The methods compared include NCF, cAdv, ACE, ColorFool, and the authors’ proposed method. The goal is to show how each method modifies an original image to create an adversarial example, and how these modifications differ visually. ResNet50 is used as the victim classifier. The figure highlights the relatively natural-looking results of the authors’ method compared to other state-of-the-art methods.
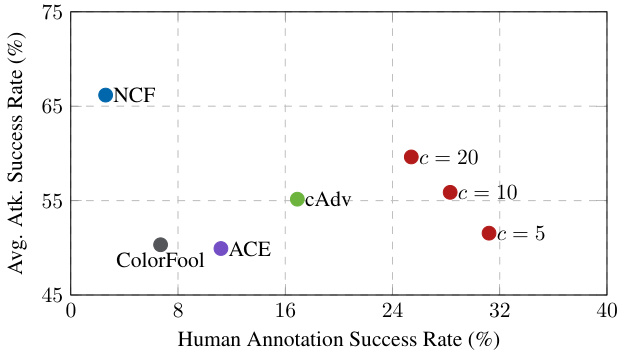
This figure visualizes the trade-off between the attack success rate and the human’s ability to detect the adversarial examples. It compares different methods (NCF, cAdv, ACE, ColorFool, and the proposed method with varying parameter ‘c’) on their average attack success rates and the corresponding human annotation success rates (how often humans fail to recognize the adversarial example). This demonstrates that higher attack success rates often correlate with greater difficulty for humans to distinguish the original image from its adversarial counterpart.
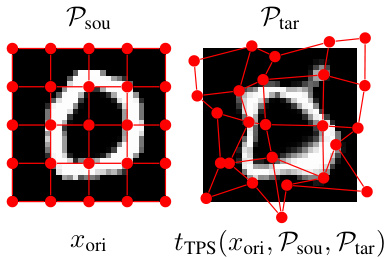
This figure illustrates the Thin Plate Splines (TPS) deformation used for data augmentation. The left panel shows the original image (xori) with a 5x5 grid of control points (Psou) overlaid. The right panel displays the transformed image after applying TPS, where the original control points have been mapped to new target points (Ptar). The TPS transformation creates a smooth deformation that minimally alters the image’s overall structure while introducing localized changes, which helps maintain semantic meaning during augmentation.
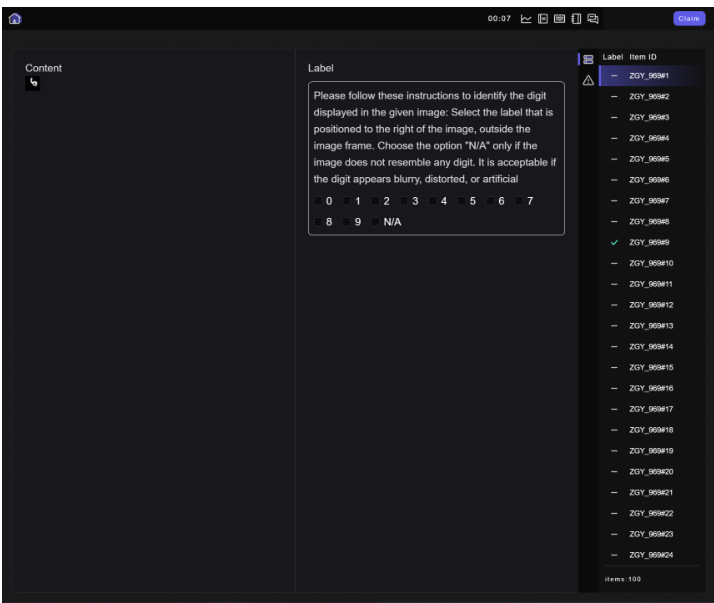
This figure shows the interface used by human annotators in a user study to identify digits in images. The interface displays an image and a set of labels (0-9 and N/A). Annotators had 10 seconds to select the label that best matched the digit shown, even if the digit was blurry, distorted, or artificial. The design of the interface aimed to make the assessment of image interpretability more robust.
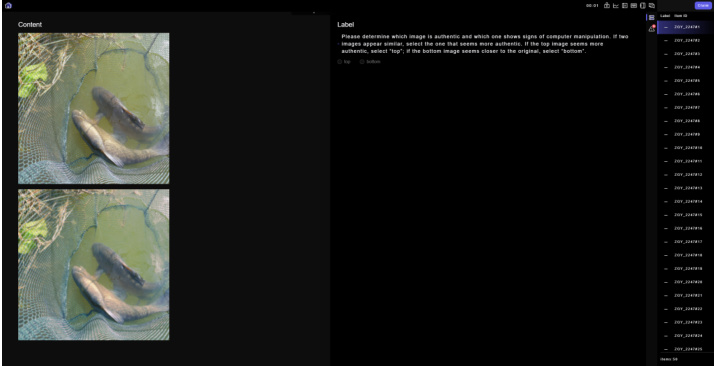
This figure shows the interface used in a user study for comparing image pairs. The annotators were asked to determine which image appeared authentic and which showed signs of computer manipulation. If the images looked similar, they were instructed to select the image that seemed more authentic. They were given 10 seconds to make a judgment.

This figure compares the visual results of several semantics-aware adversarial attacks methods, including NCF, cAdv, ACE, ColorFool, and the proposed method from the paper. The goal is to show how each method modifies the original image (shown in the ‘Origin’ column) while aiming to deceive a ResNet50 classifier. The figure highlights that the proposed method produces adversarial examples that maintain more of the original image’s visual integrity compared to the other methods, which often introduce more significant and unnatural changes to the image’s appearance.
Full paper#



















