↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Federated learning (FL) enables collaborative model training while keeping data decentralized. However, data heterogeneity across clients and the presence of malicious (Byzantine) clients pose challenges. Standard FL methods often fail in such scenarios, and personalization—tailoring models to individual clients—is explored as a solution. However, even personalized FL is susceptible to adversarial behavior.
This paper tackles these issues by proposing a novel interpolated personalized FL framework. It introduces a collaboration parameter to control the level of collaboration among clients. The researchers provide theoretical guarantees on the framework’s performance in the presence of adversaries and determine how this parameter should be adjusted according to data heterogeneity and the acceptable fraction of adversarial clients. Experimental results on mean estimation and image classification support their findings, demonstrating the benefits of fine-tuning personalization.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in federated learning and distributed machine learning. It directly addresses the critical issue of Byzantine robustness in personalized federated learning, a rapidly growing field with significant real-world applications. The findings on optimal collaboration levels in heterogeneous settings, supported by both theoretical analysis and empirical validation, provide practical guidelines for designing more resilient and effective personalized FL systems. The work also opens avenues for future research into adaptive collaboration strategies and improved robustness techniques against sophisticated adversarial attacks.
Visual Insights#
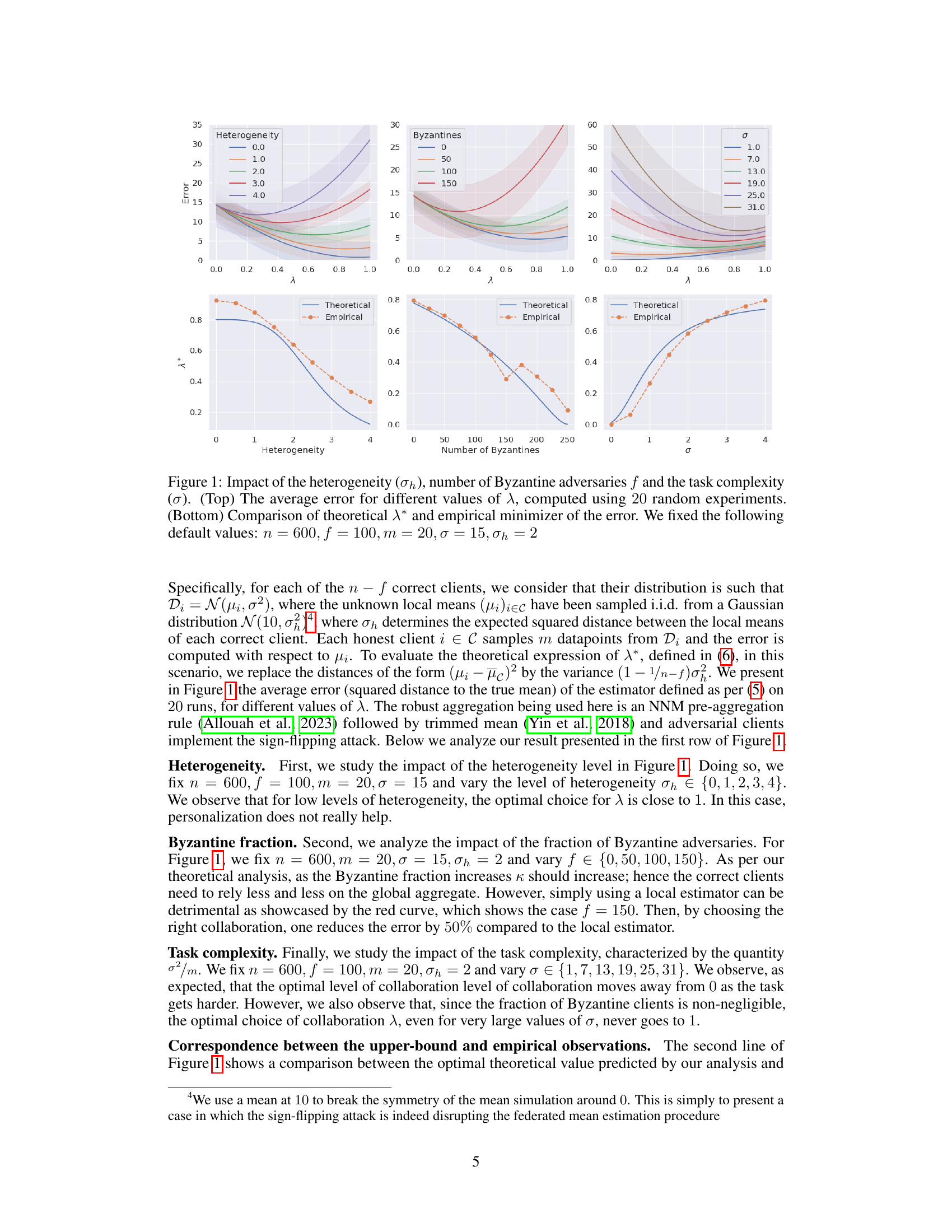
This figure displays the results of experiments on Byzantine-robust federated mean estimation. The top row shows how the average error of the mean estimation changes with different levels of collaboration (λ) under varying conditions of data heterogeneity (σh), number of Byzantine adversaries (f), and task complexity (σ). The bottom row compares the theoretical optimal collaboration level (λ*) with the empirically observed optimal level. The results show that the optimal collaboration level decreases with increasing heterogeneity and number of Byzantine adversaries. Also, the optimal level of collaboration is affected by task complexity, with higher complexity leading to higher collaboration levels.
In-depth insights#
Adversarial FL#
Adversarial Federated Learning (FL) presents a significant challenge to the robustness and reliability of collaborative machine learning. Malicious clients can inject corrupted data or manipulated model updates, degrading the overall model accuracy and potentially compromising the integrity of the learned model for all participants. Mitigating adversarial attacks in FL is crucial, and various defense mechanisms are being explored, including robust aggregation techniques (e.g., trimmed mean, median), outlier detection methods, and techniques based on model verification. However, these approaches often come with trade-offs. For example, robust aggregation can reduce the influence of malicious updates but may also reduce the overall model accuracy if the data distribution is heterogeneous. Understanding the interplay between adversarial attacks, data heterogeneity, and model personalization is key to developing effective defenses. Moreover, future research should focus on developing adaptive and computationally efficient defense strategies that can effectively handle various adversarial attacks in dynamic and realistic FL environments.
Personalized FL#
Personalized federated learning (FL) addresses the inherent heterogeneity in standard FL by tailoring models to individual clients’ unique data distributions. Instead of aiming for a single global model, personalized FL allows each client to have a customized model while still leveraging the collective knowledge from other clients’ data. This approach is crucial because standard FL often produces models that generalize poorly to some clients due to data variations. The core idea is to balance local model optimization with collaborative learning. Various techniques, including interpolation of global and local losses, regularization between models, or model splitting, can achieve this balance. A key challenge, however, lies in ensuring robustness to adversarial clients who might inject malicious data or models, thus compromising the overall model quality. Therefore, research in personalized FL also needs to focus on designing robust algorithms capable of mitigating the impact of such adversaries to make the approach practically feasible. Effective personalization strategies often rely on the level of collaboration, which needs to be carefully tuned; too much collaboration can amplify the effects of malicious actors, while too little collaboration limits the benefits of collaboration. Thus, research into optimal collaboration levels that maintain both model accuracy and robustness is paramount.
Robustness Analysis#
A robust system should gracefully handle various unexpected situations. In the context of federated learning, robustness analysis often centers on how well the model performs when dealing with adversarial clients or noisy data. This analysis usually involves evaluating model performance across different scenarios involving data corruption, network issues, or malicious behavior from participating clients. A key aspect is determining the impact of these factors on model accuracy and convergence. The analysis also considers the trade-off between robustness and performance: while increased robustness can improve resilience, it might negatively impact the model’s overall effectiveness under ideal conditions. Therefore, a thorough robustness analysis is crucial for assessing the practical utility of a federated learning system, and it plays a vital role in designing and deploying reliable and resilient models in real-world settings. Key metrics frequently used include accuracy, generalization error, and convergence speed under various stress tests. The goal is to establish the bounds of acceptable conditions within which a model reliably learns and generalizes.
Collaboration Limits#
The concept of “Collaboration Limits” in federated learning (FL) is crucial because it addresses the trade-off between the benefits of collaboration and its potential drawbacks, especially in adversarial settings. Full collaboration, where all clients contribute equally to model training, can be detrimental in the presence of malicious actors (Byzantine adversaries). These adversaries can inject faulty data or gradients, poisoning the model and degrading performance for legitimate clients. Therefore, limiting collaboration (fine-tuned personalization) becomes necessary to mitigate the adverse effects of such attacks. The optimal level of collaboration depends on several factors, including the heterogeneity of data across clients, the fraction of adversarial clients, and the complexity of the learning task. High data heterogeneity can make collaboration less beneficial, as the aggregated model may not generalize well to individual clients. A higher fraction of malicious clients necessitates reducing collaboration to maintain accuracy. Conversely, a simple learning task allows for more collaboration before adverse effects are observed. Hence, a thorough understanding and careful management of “Collaboration Limits” are essential for robust and effective FL systems.
Future Work#
The authors thoughtfully outline avenues for future research, acknowledging limitations and suggesting improvements. They highlight the need for more communication-efficient algorithms to address scalability challenges in high-dimensional settings, suggesting that current methods might be too computationally expensive. Investigating alternative personalization strategies beyond simple interpolation, such as regularization or clustering techniques, is also proposed to broaden the applicability and potentially improve the performance of their approach. Finally, they suggest that a deeper investigation into the interplay between the optimization error, generalization gap, and the level of collaboration could lead to more refined and effective personalization strategies. Exploring the impact of different adversarial attack strategies and expanding to more complex scenarios (beyond binary classification) would further strengthen the robustness and generalizability of the proposed framework. This demonstrates a forward-looking perspective focused on improving efficiency and expanding the scope of the work.
More visual insights#
More on figures

This figure shows the impact of data heterogeneity, the number of Byzantine adversaries, and task complexity on the performance of the federated mean estimation algorithm. The top row displays the average error for different collaboration levels (λ) under varying conditions. The bottom row compares the theoretical optimal collaboration level (λ*) with the empirically observed optimal level. The results illustrate how the optimal level of collaboration depends on these factors.
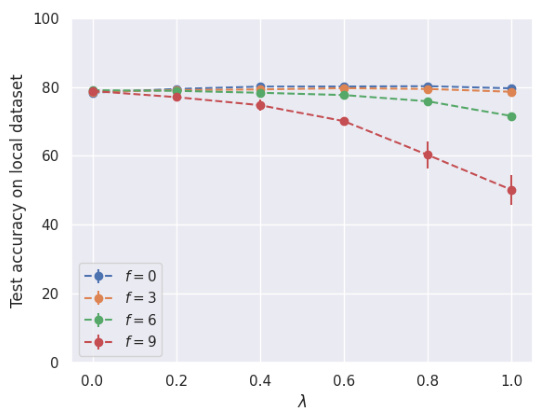
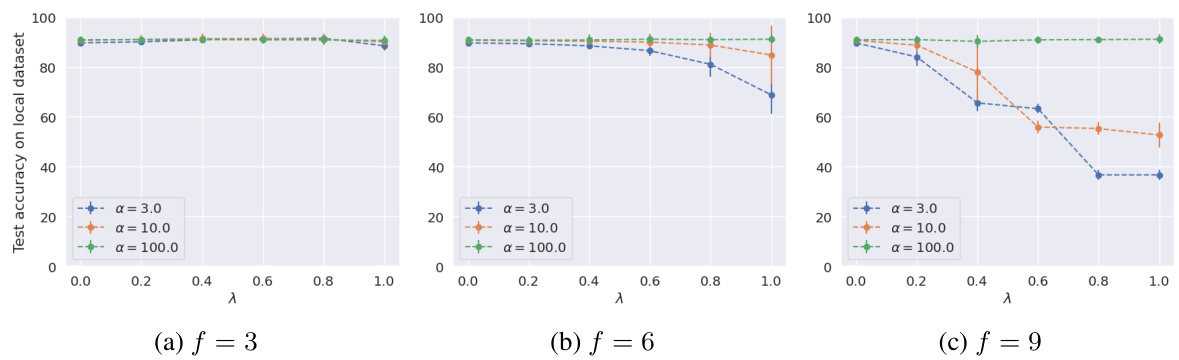
This figure analyzes the impact of adversarial clients and data heterogeneity on the performance of the proposed personalized federated learning algorithm for two datasets: Phishing and MNIST. The top row shows results for the Phishing dataset using logistic regression, while the bottom row presents results for the MNIST dataset using a convolutional neural network. Each row displays test accuracy on local datasets for various collaboration levels (λ), with different numbers of adversarial clients (f) and levels of heterogeneity (α). The α = ∞ case represents a homogeneous setting (no heterogeneity). The figure demonstrates how the optimal collaboration level changes depending on the adversarial fraction and heterogeneity, highlighting situations where full collaboration is not optimal.
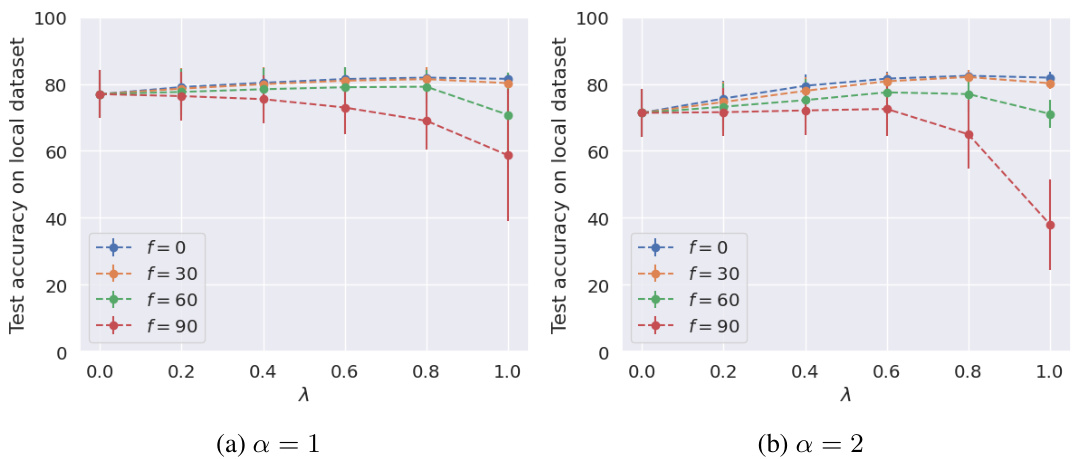
This figure shows the impact of both the fraction of Byzantine adversaries and the level of heterogeneity on the test accuracy for the binary MNIST dataset using logistic regression. The x-axis represents the collaboration level (λ), while the y-axis shows the test accuracy. Different lines represent different fractions of Byzantine clients (f). The subfigures (a) and (b) correspond to different levels of heterogeneity (α). The results show that the optimal collaboration level depends on both the number of adversarial clients and heterogeneity, and that in some cases, not collaborating at all is better than full collaboration.
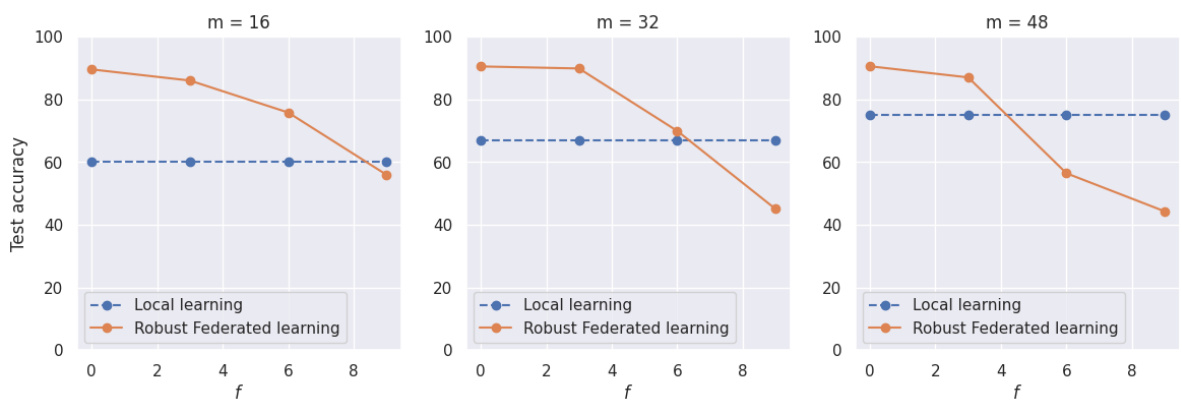
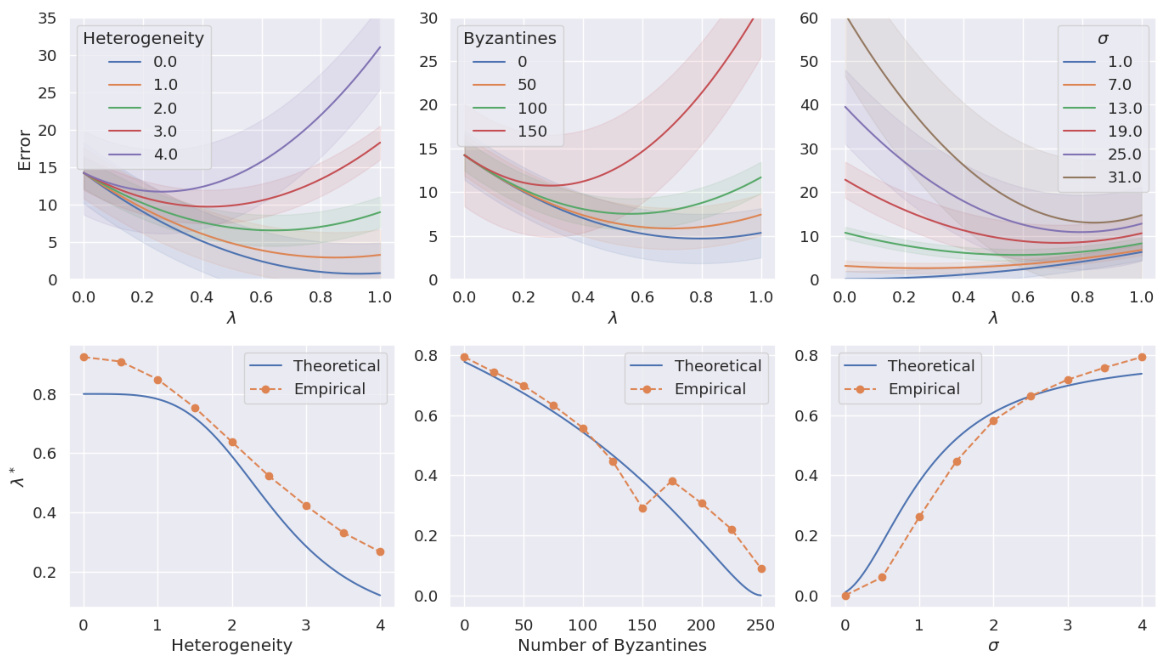
This figure compares the performance of local learning and robust federated learning on a phishing dataset for different numbers of Byzantine (adversarial) clients. The x-axis shows the number of Byzantine clients, and the y-axis represents the test accuracy. Three different local dataset sizes (m=16, 32, 48) are shown. The figure demonstrates that as the amount of local data increases, the point at which local learning outperforms robust federated learning shifts towards fewer Byzantine clients. This highlights the importance of local data size in mitigating the negative effects of adversarial clients in federated learning scenarios.
The figure displays the impact of different factors (adversarial fraction, heterogeneity, and local sample size) on the test accuracy of two datasets: Phishing and MNIST. The top row shows the results for the Phishing dataset using logistic regression with 20 clients and a heterogeneity parameter α of 3. The bottom row shows the results for the MNIST dataset using a Convolutional Neural Network with 20 clients and a heterogeneity parameter α of ∞ (homogeneous setting). Each subfigure presents the test accuracy against the collaboration parameter λ for various levels of adversarial clients (f).
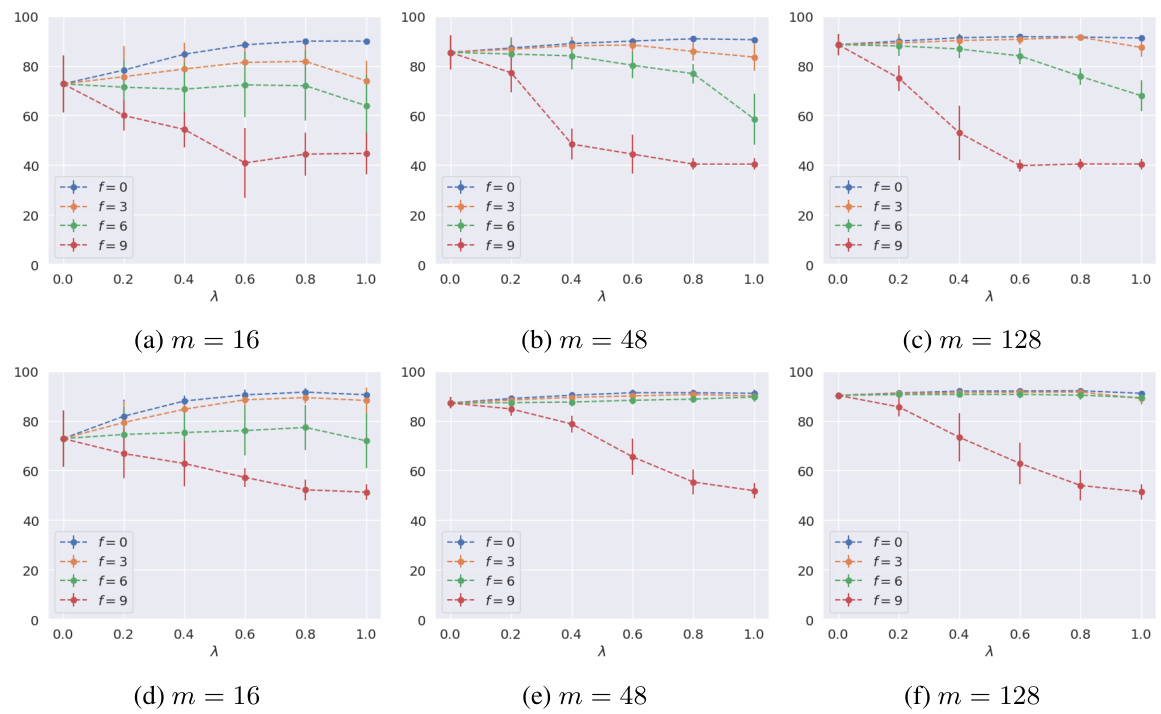
This figure shows the results of experiments conducted on a phishing dataset using logistic regression. The experiments vary the number of adversarial clients (f), the size of the local dataset (m), and the level of data heterogeneity (α). The top row shows results for α = 3, while the bottom row shows results for α = 10. Each subplot displays the test accuracy on the local dataset as a function of the collaboration level (λ) for different values of f and m. The results illustrate how the optimal collaboration level and the impact of adversarial clients change depending on dataset size and heterogeneity.
Full paper#