↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Creating simulations for training AI agents is expensive and time-consuming. Existing methods only generate parts of simulations, such as reward functions, failing to generate the whole simulation from natural language input. This limitation hinders the scalability of using simulations for training robust agents that generalize well to unseen environments.
FACTORSim is a novel framework that generates complete, coded simulations from natural language descriptions. It leverages the inherent modularity of coded simulations by adopting a factored partially observable Markov decision process representation. By breaking down the generation process into steps, and only selecting the relevant context for each step, FACTORSim effectively reduces context dependence, improving the accuracy and zero-shot transfer abilities of generated simulations. Evaluated on a new generative simulation benchmark, FACTORSim outperforms existing methods and demonstrates effectiveness in generating robotic tasks.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the significant challenge of automated simulation generation for AI agent training. It introduces FACTORSim, a novel framework that addresses the limitations of existing methods by using a factored representation and Chain-of-Thought prompting to efficiently generate simulations from text descriptions. This is relevant to the current trend of using simulations to train agents for complex real-world tasks, where creating simulations manually is costly and time-consuming. Furthermore, the proposed generative simulation benchmark provides a valuable tool for evaluating future research in this area.
Visual Insights#

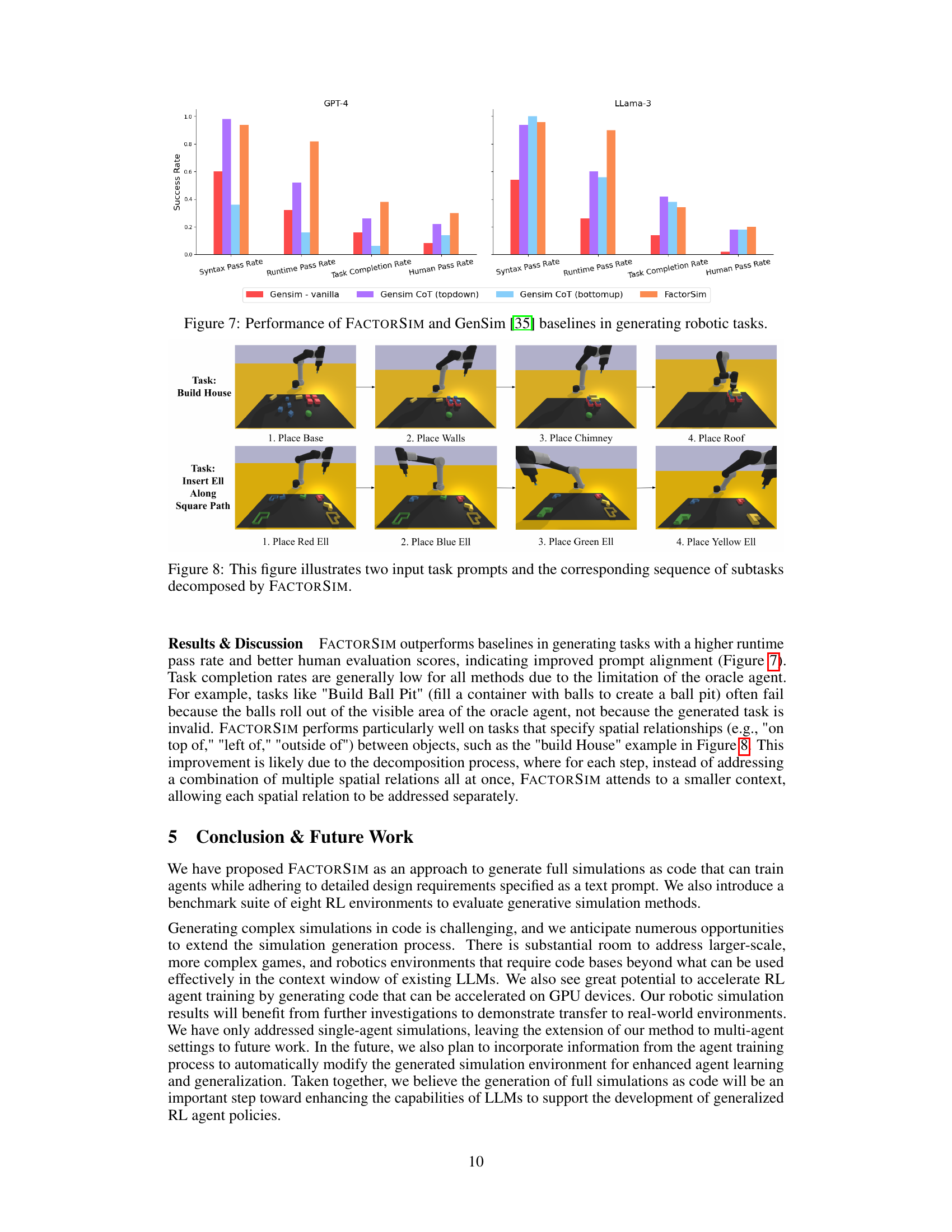
This figure provides a high-level overview of the FACTORSIM framework. It shows how the system takes language documentation as input, uses chain-of-thought reasoning to break down the task into smaller steps, utilizes a factored POMDP representation for efficient context management, trains reinforcement learning agents on the generated simulations, and finally evaluates the performance of the trained agents on unseen environments. The diagram visually depicts the flow of information and processes within the FACTORSIM pipeline, highlighting key components and their interactions.

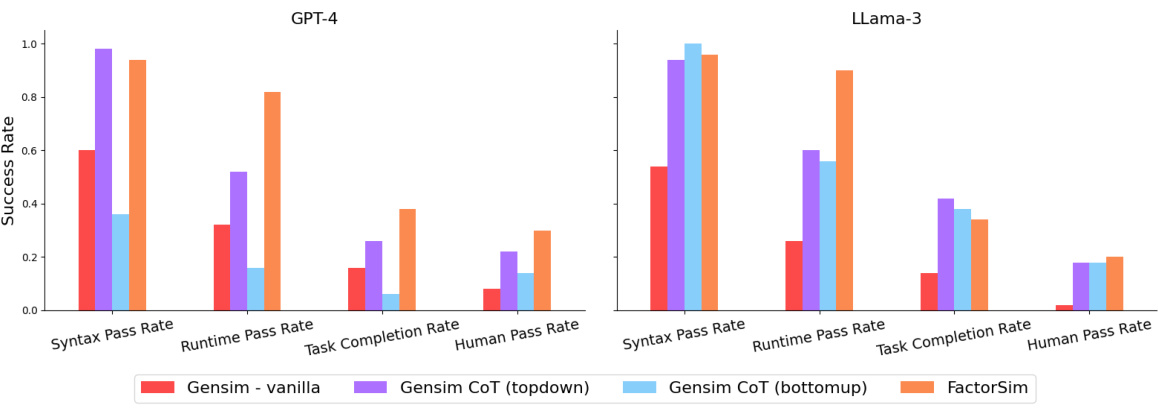
This table presents the success rate (percentage of system tests passed) achieved by various LLMs and methods in generating code for eight different 2D reinforcement learning games. The methods include using LLMs without any additional techniques, using LLMs with self-debugging, using LLMs with Chain-of-Thought prompting, and using LLMs in combination with the proposed FACTORSIM approach. The table compares the performance of different LLMs such as Llama-3 and GPT-4, highlighting the effectiveness of FACTORSIM in improving code generation accuracy.
In-depth insights#
Factorized POMDPs#
Factorized Partially Observable Markov Decision Processes (POMDPs) offer a powerful approach to managing the complexity inherent in many real-world problems. By decomposing the state space into a set of independent or weakly dependent factors, factorized POMDPs significantly reduce computational demands associated with traditional POMDP solution methods, particularly relevant when dealing with high-dimensional state spaces. This factorization allows for more efficient representation and inference, as algorithms can focus on updating and reasoning about individual factors rather than the entire, potentially vast, joint state space. This modularity also facilitates greater interpretability, as the influence of each factor on decision-making becomes clearer. However, the effectiveness of a factorized POMDP hinges on the choice of factorization and the relationships between factors. Poorly chosen factorizations can lead to suboptimal results, even increased computational costs if dependencies are not carefully considered. Therefore, a key challenge lies in finding effective, efficient, and relevant factorizations for specific application domains, frequently needing domain expertise to identify suitable factors.
LLM-based Sim Gen#
LLM-based Sim Gen represents a significant advancement in automated simulation creation. By leveraging the power of large language models (LLMs), this approach moves beyond manually coding simulations, reducing development time and costs. The ability to generate simulations directly from natural language descriptions opens up exciting possibilities for various fields. However, challenges remain. Accuracy and reliability of LLM-generated simulations are crucial concerns, requiring careful evaluation and potentially incorporating verification mechanisms. Furthermore, the scope of LLM-based Sim Gen is currently limited by the capabilities of existing LLMs; they may struggle with complex or nuanced specifications. Addressing these limitations is essential for broader adoption. Future directions could involve developing hybrid approaches combining LLMs with other AI techniques to enhance both accuracy and complexity, along with research into robust evaluation metrics for LLM-generated simulations.
Benchmarking Sim#
A robust benchmarking suite for evaluating generative simulation models is crucial. A comprehensive benchmark should include diverse tasks spanning various domains (robotics, games, physics) and complexities, assessing both the accuracy and generalizability of generated simulations. Key metrics should encompass code correctness (system tests), zero-shot transfer performance (agent training and evaluation on unseen environments), and human evaluations (playability, adherence to specifications). The selection of baseline models should be carefully considered, representing a range of approaches in generative AI. Results should be meticulously reported with error bars and statistical significance testing to ensure reliability and enable meaningful comparisons. Ideally, the benchmark would be openly accessible and easily extensible to encourage community contribution and foster continuous improvement in generative simulation techniques.
Zero-Shot Transfer#
Zero-shot transfer, a critical aspect of evaluating the generated simulations, assesses the ability of agents trained on a set of generated simulations to generalize to unseen environments. This is crucial for real-world applicability, as it demonstrates the robustness and generalization capabilities of the learned policies. Success in zero-shot transfer is a strong indicator of the simulation’s quality and alignment with the intended task, showing that the simulated environments faithfully reflect the characteristics of the target environments. The benchmark design incorporates held-out environments that adhere to the specified design criteria, providing a rigorous evaluation of generalization. Strong zero-shot transfer performance in the experiments validates the effectiveness of the proposed method in generating robust and generalizable simulations, enabling more efficient and effective agent training.
Future of SimGen#
The future of SimGen (Simulation Generation) is bright, promising significant advancements in AI agent training and robotics. Current methods, while showing promise, are limited by the complexity of generating comprehensive simulations from natural language descriptions. Future research should focus on improving the scalability and efficiency of SimGen techniques to handle more intricate and detailed simulations. Addressing the challenge of prompt ambiguity and context dependence is crucial; methods like factored POMDPs offer a pathway towards more robust and aligned simulation generation. Furthermore, incorporating interactive feedback mechanisms and techniques like reinforcement learning to refine and adapt simulations based on agent performance will be key. The integration of multi-agent simulations and the incorporation of physics-based simulation engines will also be necessary for generating realistic and truly effective training environments. Finally, exploring diverse applications across fields such as autonomous vehicles, medicine, and environmental modeling will unlock SimGen’s full potential.
More visual insights#
More on figures
This figure illustrates the overall process of FACTORSIM. It starts with language documentation as input, which is processed using Chain-of-Thought reasoning to break down the task into smaller, manageable steps. Each step involves selecting relevant context from a factored Partially Observable Markov Decision Process (POMDP) representation, simplifying the generation process. FACTORSIM then uses this information to generate code for the simulation. The generated simulations are then used to train reinforcement learning (RL) agents, which are subsequently tested on unseen environments to evaluate the zero-shot transfer capabilities of the generated simulations.

This figure illustrates the overall process of FACTORSIM. It starts with language documentation as input, uses Chain-of-Thought reasoning to break down the task into smaller steps. A factored POMDP representation is used to manage the complexity of context selection during simulation generation. The generated simulation code is then used to train reinforcement learning agents. Finally, the trained policy is evaluated on unseen environments to assess the generalization ability of the generated simulations.
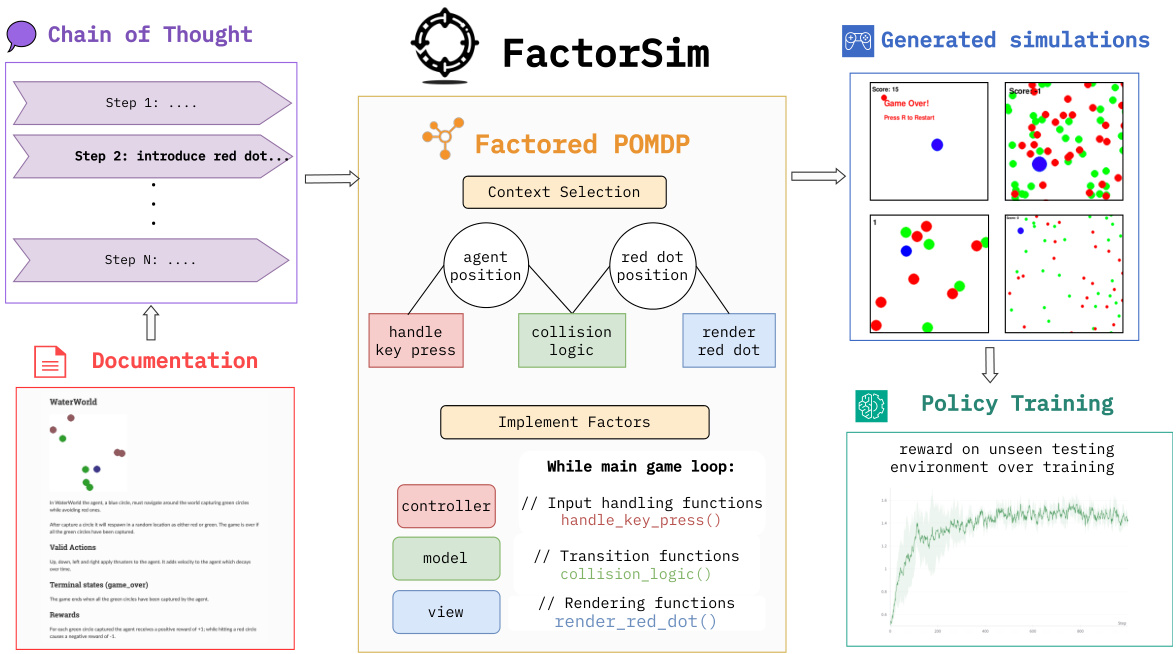
This figure illustrates how the five main prompts in the FACTORSIM framework correspond to the steps of Algorithm 1. It demonstrates the process of decomposing a complex task into smaller, manageable modules. The figure shows how relevant states and functions are identified and utilized in each step to generate new code based on the factored POMDP representation. It highlights the iterative nature of the process and how the selection of context from the current codebase helps reduce the complexity for the LLM at each step. Specifically, it showcases how the ‘red_puck_respawn’ function, identified in Prompt 2 as modifying the relevant ‘red_puck_position’ state variable, is reused as part of the context for Prompts 3, 4, and 5, to efficiently update the code.
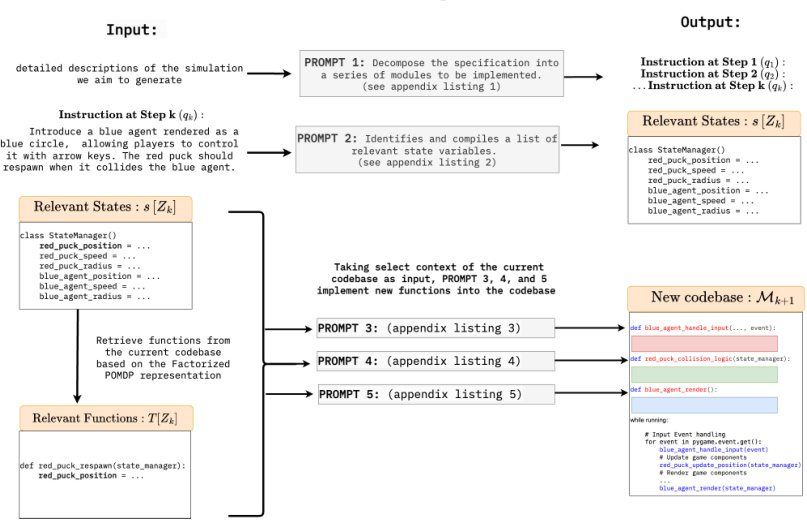
This figure presents a comparison of different methods using GPT-4 for generating reinforcement learning games. It shows the relationship between the percentage of successfully passed system tests (a measure of code correctness) and the number of tokens used by each method. The methods compared include vanilla GPT-4, GPT-4 with self-debugging, GPT-4 with Chain-of-Thought and self-debugging, and GPT-4 with FactorSim. Ellipses represent 90% confidence intervals, indicating the variability of performance across different games. The results show FactorSim’s superior performance and efficiency in generating correct code compared to other baselines.
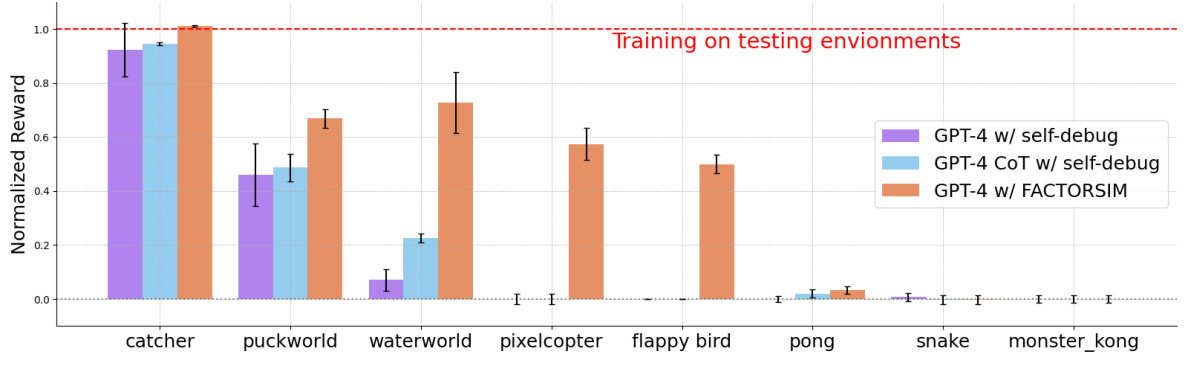
This figure displays the results of a zero-shot transfer experiment. Three different methods of generating simulations (GPT-4 with self-debugging, GPT-4 CoT with self-debugging, and GPT-4 with FactorSim) were used to train reinforcement learning agents. The agents were then tested on unseen environments from the original RL benchmark (PyGame Learning Environment). The normalized reward is plotted for each game in the benchmark, with error bars indicating the variability of performance. The figure shows that FactorSim significantly outperforms the baseline methods in the zero-shot transfer setting, indicating the generated simulations better generalize to unseen environments.

This figure provides a visual representation of the robotics task generation experimental setting. The left side illustrates the process, which involves taking a task description as input, verifying syntax and runtime feasibility, checking for task completion using an oracle agent, and finally, conducting a human verification to ensure that the generated demonstration aligns with the original prompt. The right side showcases examples of tasks successfully generated by the FACTORSIM model, tasks that other baseline methods were unable to generate successfully, highlighting the advanced capabilities of the proposed model.

This figure compares the performance (percentage of system tests passed) and token usage of different methods for generating 2D RL games using the GPT-4 language model. The methods compared include the vanilla GPT-4 approach, GPT-4 with self-debugging, GPT-4 with Chain-of-Thought reasoning and self-debugging, and GPT-4 combined with the FACTORSIM framework. The ellipses represent 90% confidence intervals for each method’s performance across all eight games in the benchmark.
This figure compares the performance (percentage of system tests passed) and token usage of different GPT-4 based methods for generating 2D reinforcement learning games. The methods include the vanilla approach (no decomposition), self-debugging, Chain-of-Thought reasoning with self-debugging, and FactorSim. The ellipses represent 90% confidence intervals, showing the variability in performance and token usage across different games. The figure highlights that FactorSim achieves the best balance between high accuracy and moderate token usage.
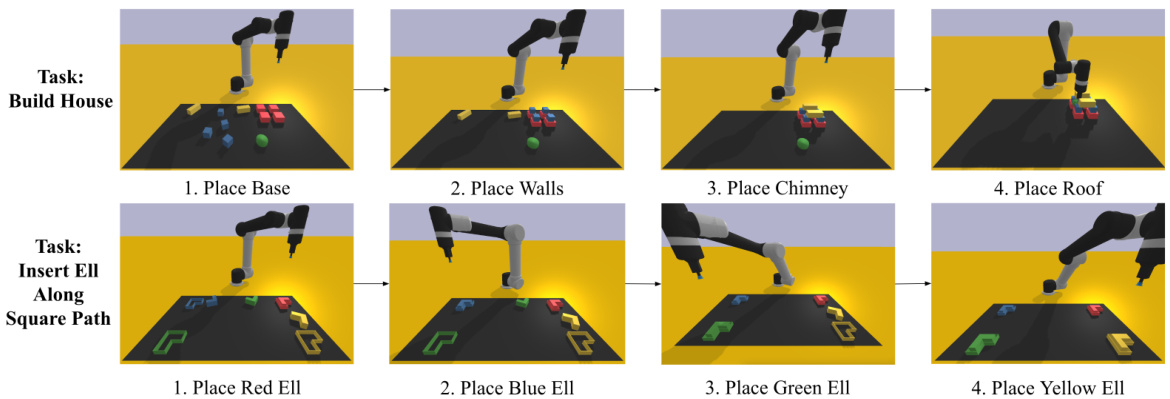
The figure showcases the experimental setup for robotics task generation using the proposed FACTORSIM method. The left side provides a flowchart illustrating the process: a task is specified in natural language, decomposed into subtasks, and each subtask is generated into code using FACTORISM. The code undergoes syntax correctness and runtime verification checks before being used to train a robot to complete the task. The right side presents examples of successful task generations using FACTORSIM, demonstrating tasks that other baseline methods failed to produce correctly.
This figure shows the performance (percentage of system tests passed) and token usage of different methods for generating 2D RL games using the GPT-4 language model. It compares the vanilla approach (no additional techniques), self-debugging, Chain-of-Thought with self-debugging, and FactorSim. The ellipses represent the 90% confidence intervals, indicating the variability of the results across the eight different RL games. FactorSim demonstrates the best balance of high performance and relatively low token usage, highlighting its efficiency.
This figure compares the performance (percentage of system tests passed) and token usage of different GPT-4 based methods for generating 2D reinforcement learning games. The methods include the vanilla method (no special techniques), self-debugging, Chain-of-Thought reasoning with self-debugging, and FactorSim. The ellipses represent 90% confidence intervals, showing the variability in performance and token usage across the eight games tested. The results indicate that FACTORSim achieves the best balance of high accuracy and relatively low token usage.
This figure compares the performance (percentage of passed system tests) and token usage of different methods for generating 2D RL games using the GPT-4 language model. The methods include a vanilla approach, self-debugging, Chain-of-Thought reasoning with self-debugging, and the proposed FACTORSIM approach. The ellipses represent 90% confidence intervals, showing the variability in performance and token usage across different games. FACTORSIM is shown to achieve high accuracy with modest token usage, indicating its efficiency in generating simulations.
This figure compares the performance (percentage of passed system tests) and token usage of various methods using GPT-4 for generating 2D RL games. The vanilla method uses the fewest tokens but achieves moderate accuracy. Combining Chain-of-Thought (CoT) reasoning with self-debugging results in the highest token usage but only marginally improves accuracy. FACTORSIM achieves the highest accuracy with modest token usage, suggesting that task decomposition reduces the need for extensive debugging.
This figure compares the performance (percentage of passed system tests) and token usage of different methods for generating 2D RL games using GPT-4. It shows that while the vanilla method uses the fewest tokens, it has lower accuracy. Combining Chain-of-Thought (CoT) reasoning with self-debugging results in the highest token usage, but only marginally improves accuracy. In contrast, FACTORSIM achieves the highest accuracy with modest token usage, suggesting that decomposition of tasks reduces the need for extensive iterative debugging.

This figure shows the performance (percentage of system tests passed) and token usage of different methods for generating 2D RL games using GPT-4. It compares the vanilla GPT-4 approach, GPT-4 with self-debugging, GPT-4 with Chain-of-Thought (CoT) and self-debugging, and GPT-4 with the proposed FACTORSIM method. The ellipses represent 90% confidence intervals, indicating the variability of the results across different games. FACTORSIM demonstrates a good balance between high accuracy and low token usage, suggesting its efficiency in generating simulation code.
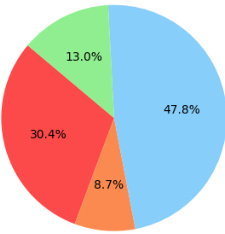
This figure compares the performance (in terms of percentage of passed system tests) and token usage of different methods for generating 2D RL games using the GPT-4 language model. The methods compared include the vanilla approach (no decomposition), self-debugging, Chain-of-Thought (CoT) with self-debugging, and FactorSim. Ellipses around each data point represent the 90% confidence intervals, showing the variability in performance across different games for each method. It demonstrates FactorSim’s superior performance with modest token usage compared to other methods.
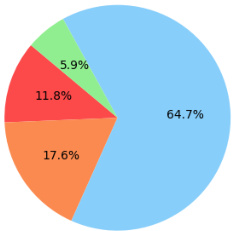
This figure compares the performance (percentage of passed system tests) and token usage of different methods for generating 2D RL games using GPT-4. It shows that while the vanilla method uses the fewest tokens, it has lower accuracy. Combining Chain-of-Thought (CoT) reasoning with self-debugging increases both token usage and accuracy, but FACTORSIM achieves the best balance of high accuracy and relatively low token usage. The ellipses represent 90% confidence intervals, averaged across all eight games in the benchmark.
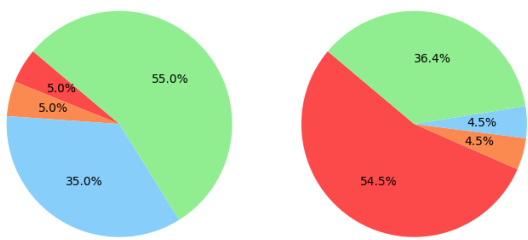
This figure compares the performance (percentage of system tests passed) and token usage of various GPT-4-based methods for generating 2D reinforcement learning games. It shows that FACTORSIM achieves high accuracy with relatively low token usage compared to other methods, including those using Chain-of-Thought reasoning and self-debugging. The ellipses represent 90% confidence intervals, indicating the variability in performance and token usage across the different games.
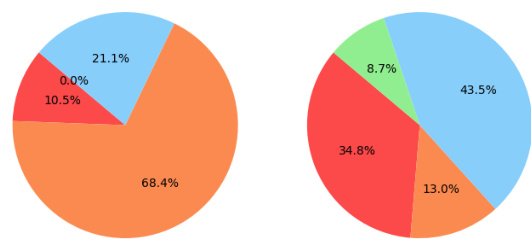
This figure compares the performance (percentage of passed system tests) and token usage of different methods for generating 2D RL games using GPT-4. It shows that while the vanilla method uses the fewest tokens, it achieves lower accuracy. Combining Chain-of-Thought (CoT) reasoning with self-debugging results in the highest token usage but only marginally improves accuracy. FACTORSIM achieves the highest accuracy with modest token usage, suggesting that its decomposition of tasks reduces the need for extensive iterative debugging.
The figure shows a screenshot of the user interface used in the human study. The interface allows users to select a game, generate a game using the FACTORSIM model, and replay the game. The generated game is displayed in a separate window, showing the game’s score and the current state of the game. The prompt used to generate the game is displayed above the game window.
Full paper#