↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large language models (LLMs) are powerful but prone to generating factually incorrect information, a problem known as ‘hallucinations’. This significantly limits their reliability and trustworthiness, especially in applications requiring accurate factual information. Existing calibration methods have shown limitations in effectively addressing this issue.
This research introduces IDK-tuning, a novel calibration method that uses a special token ‘[IDK]’ (I don’t know) to explicitly model uncertainty in the model’s predictions. The method modifies the training objective function to increase the probability of assigning the ‘[IDK]’ token to incorrect predictions. Experiments across multiple LLMs demonstrated that IDK-tuning substantially increases the model’s factual precision (correctly identifying when it doesn’t know the answer) with only a small reduction in factual recall (missing correct answers). Ablation studies analyzed different components of the method and revealed that the improvements were robust and consistently effective across diverse model architectures.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on large language models (LLMs) because it directly addresses the prevalent issue of hallucinations. By introducing a novel calibration method using a special [IDK] token, the research offers a practical solution to mitigate factual inaccuracies, a significant concern in current LLM development. Furthermore, the extensive ablation studies and detailed analysis provide valuable insights for future research into improving LLM reliability and trustworthiness. The work opens new avenues for exploring uncertainty modeling in LLMs, impacting broader applications of this technology.
Visual Insights#
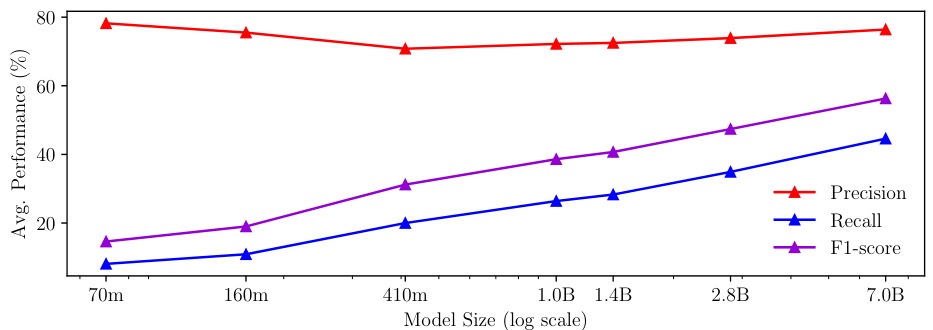
This figure shows the relationship between the size of the language model and the performance on factual sentence completion tasks after applying IDK-tuning. It plots the average precision, recall, and F1-score across multiple datasets for models ranging in size from 70 million parameters (pythia-70m) to 7 billion parameters (Mistral-7B). The results demonstrate that larger models tend to achieve better overall performance (higher F1-scores) after IDK-tuning, although recall improves more significantly with model size than precision.

This table presents the results of the Mistral-7B-v0.1 model on various factual closed-book sentence completion datasets. It compares the performance of the IDK-tuned Mistral-7B-v0.1 model against several baselines, including a confidence-threshold baseline, a P(True) baseline, a semantic entropy baseline, and a version of the model further trained on The Pile dataset. The metrics used are precision (P), recall (R), and F1-score, showing that IDK-tuning improves precision while maintaining relatively high recall.
In-depth insights#
IDK Token Tuning#
The proposed “IDK Token Tuning” method presents a novel approach to handling uncertainty in large language models (LLMs). By introducing a special [IDK] token, the model explicitly expresses uncertainty when it’s unsure about a prediction. This is achieved by modifying the cross-entropy loss function to shift probability mass towards the [IDK] token for incorrect predictions, effectively calibrating the model’s confidence. The method’s effectiveness is demonstrated across multiple model architectures and factual downstream tasks, showing a significant improvement in factual precision with only a minor decrease in recall. This suggests a valuable tradeoff between accuracy and the avoidance of hallucinations. The paper also performs extensive ablation studies, highlighting the importance of adaptive uncertainty factors and regularization techniques for optimization stability, revealing crucial details about the method’s design and its impact on overall language modeling abilities. While requiring a continued pretraining phase, the approach doesn’t rely on labeled data and allows for fine-tuning on specific tasks. Despite impressive results, further investigation into the effect of model size and handling potential collapse issues in smaller models is necessary to make the method robust. The research underscores the value of explicitly modeling uncertainty, enhancing the reliability and trustworthiness of LLM outputs.
Uncertainty Modeling#
The core concept of the research paper revolves around enhancing the reliability of Large Language Models (LLMs) by explicitly addressing their inherent uncertainty. The authors introduce a novel approach, which involves incorporating a dedicated ‘[IDK]’ token representing ‘I don’t know’. This ingenious method allows the model to express uncertainty when faced with ambiguous or factually challenging situations, thus mitigating the risk of generating hallucinations or confidently producing incorrect information. The effectiveness of this method is thoroughly investigated through various experiments demonstrating that it significantly improves the precision of LLMs. The ‘[IDK]’ token acts as a safeguard, preventing the model from producing false information when its confidence is low. Despite a minor decrease in recall, the overall F1-score demonstrates a positive impact. The paper also explores several variations of the approach with different hyperparameters to examine the tradeoffs and optimal settings for uncertainty modeling. It demonstrates that uncertainty modeling is particularly beneficial for larger LLMs, indicating a need for further research exploring its impact on different scales. The research highlights a nuanced understanding of the balance between precision and recall in achieving reliable and trustworthy LLM outputs.
Factual Precision#
The concept of “Factual Precision” in the context of large language models (LLMs) is crucial. It measures the LLM’s ability to generate factually correct information. High factual precision is essential for trustworthy and reliable LLM applications, especially in scenarios requiring accurate information. The paper explores methods to improve factual precision, such as using an “I don’t know” token ([IDK]) to identify instances where the model lacks certainty. This strategy significantly improves factual precision by reducing the number of incorrect factual claims generated by the model. The trade-off between recall and precision is also explored: improving factual precision may lead to a decrease in recall (i.e., the model may not answer some questions it could answer correctly), highlighting the need for a balanced approach that optimizes both aspects. The effectiveness of various model sizes and architectures on factual precision is also investigated, demonstrating the importance of choosing an appropriate model for desired performance. The results offer valuable insights into improving factual precision in LLMs, but further research is needed to fully address this challenge and avoid unwanted side-effects.
Model Calibration#
Model calibration in large language models (LLMs) is crucial for reliability. Poorly calibrated models may produce factually incorrect outputs with high confidence, hindering their usability. Calibration methods aim to align a model’s confidence scores with its actual accuracy. Various techniques exist, including temperature scaling and ensemble methods, each with its own strengths and weaknesses. A key challenge is balancing calibration with maintaining the model’s performance on its primary tasks. Over-calibration can lead to overly cautious predictions and a loss of useful information. Therefore, a successful calibration strategy should optimize for a balance between confidence accuracy and the preservation of the model’s knowledge representation and predictive power. The research area is very active, exploring novel methods and improved evaluation metrics to better quantify and understand model uncertainty, and to provide more reliable LLM outputs.
Future Directions#
Future research could explore expanding the IDK token’s functionality beyond factual uncertainty. Investigating its application in handling subjective questions or those requiring nuanced opinions would be valuable. Further research should also focus on improving the IDK token’s integration into different model architectures and sizes, particularly smaller models where the current approach showed instability. Addressing the computational cost of IDK-tuning is crucial for wider adoption, potentially exploring more efficient training strategies or focusing the objective on specific tokens within a given context. Finally, a comprehensive analysis of bias in the IDK token’s performance across various datasets and demographics is necessary, along with mitigating strategies for any discovered biases. Ultimately, refining and broadening the IDK token’s scope could significantly advance LLM trustworthiness and reliability.
More visual insights#
More on figures
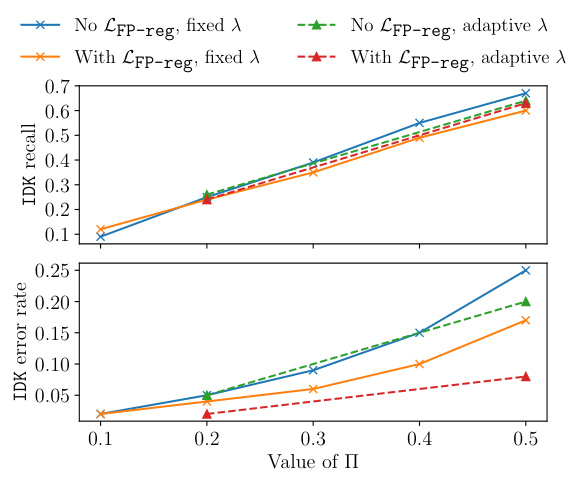
This figure shows the trade-off between IDK recall and IDK error rate for different hyperparameter settings (Π, lambda, and LFP-reg) of the IDK-tuning objective. It demonstrates how the choice of hyperparameters affects the model’s ability to correctly identify situations where it lacks knowledge ([IDK] recall), while simultaneously minimizing incorrect [IDK] predictions (IDK error rate). The adaptive lambda results generally yield improved recall and reduced error rates compared to using fixed lambda. The inclusion of LFP-reg further refines this trade-off by lowering the IDK error rate.

This figure shows the trade-off between IDK recall and IDK error rate for different parameter combinations used in the IDK-tuning method. The x-axis represents the IDK error rate (the proportion of instances where the model incorrectly predicted the [IDK] token when the base model correctly predicted the target), while the y-axis represents the IDK recall (the proportion of instances where the model correctly predicted the [IDK] token when the base model failed to predict the target). Different lines represent different combinations of hyperparameters: using or not using the LFP-reg regularization and using a fixed or adaptive uncertainty factor (λ). Each data point on the lines is annotated with the value of Π, a hyperparameter that controls the influence of the objective function. The figure helps to understand the impact of the hyperparameters on the model’s ability to express uncertainty effectively.
More on tables

This table presents the performance of the proposed IDK-tuning method on the 1m-eval-harness benchmark, a comprehensive evaluation suite for assessing multiple-choice question answering capabilities of language models. The table compares the precision, recall, and F1-score of the IDK-tuned Mistral-7B-v0.1 model against several baseline methods, including a confidence-threshold based approach and the P(True) baseline, showcasing the improved performance of IDK-tuning in terms of factual precision while maintaining reasonable recall on the benchmark.

This table presents the results of the IDK-tuning method on the bert-base-cased model. It compares the precision, recall, and F1-score achieved by the bert-base-cased model alone, with the confidence threshold baseline, and with the IDK-tuning method applied. The results are shown for three different datasets: LAMA Google-RE, LAMA T-Rex, and LAMA SQUAD, each assessing factual knowledge in different ways. The table demonstrates the impact of IDK-tuning on factual precision, showcasing a substantial improvement over the baseline methods at the cost of a slight decrease in recall.

This table presents the ROUGE-L scores achieved by three different models on three summarization tasks: Legal Plain English, TLDR, and SPEC5G. The three models are: the base Mistral-7B-v0.1 model, the Mistral-7B-v0.1 model further trained on The Pile dataset (to evaluate impact of additional data), and the Mistral-7B-v0.1 model that underwent IDK-tuning on The Pile. The results show the effect of IDK-tuning on the model’s summarization capabilities, comparing its performance against both the base model and the model trained with additional data.
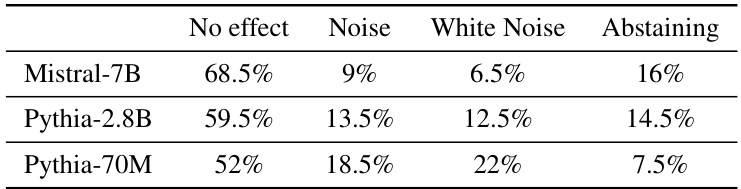
This table presents the breakdown of error types observed in 200 incorrect predictions made by the IDK-tuned models across three different sizes: Pythia-70M, Pythia-2.8B, and Mistral-7B. Each error is categorized into one of four types: No effect (the IDK-tuned model made the same incorrect prediction as the original model), Noise (the original model was correct, but the IDK-tuned model was incorrect), White Noise (both models were incorrect, but they made different predictions), and Abstaining (the IDK-tuned model did not provide a factual answer). The percentages represent the proportion of each error type within the 200 incorrect predictions.
Full paper#



















