↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Traditional assistive AI relies on inferring human intentions, a complex process particularly challenging in intricate environments. This method is often unreliable because it requires precise human intention modeling. This paper addresses these challenges by shifting the focus from intention inference to empowering the human user. Instead of trying to predict what the human wants, the AI helps the human accomplish more by increasing their influence on the environment.
The paper proposes a new framework called Empowerment via Successor Representations (ESR). ESR uses contrastive learning to efficiently estimate empowerment, even in high-dimensional environments. It is shown to outperform existing empowerment-based methods in several benchmarks, both simple and complex, demonstrating the method’s scalability and effectiveness. The theoretical foundations of ESR are also laid out, linking it to concepts in information theory and reinforcement learning. This opens the way to use this principle to more safely and effectively build AI assistance systems.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents a novel, scalable approach to building AI assistants that don’t rely on inferring human intentions. This is a significant advancement as it tackles the challenges of high-dimensional settings, a major hurdle in current AI assistance research. Its introduction of Empowerment via Successor Representations (ESR) opens doors for improved human-AI collaboration in diverse complex environments and offers a more robust and safe method for AI assistance. By connecting ideas from information theory, neuroscience, and reinforcement learning, it provides a theoretical framework for future research and promotes the development of more efficient and effective assistive agents.
Visual Insights#
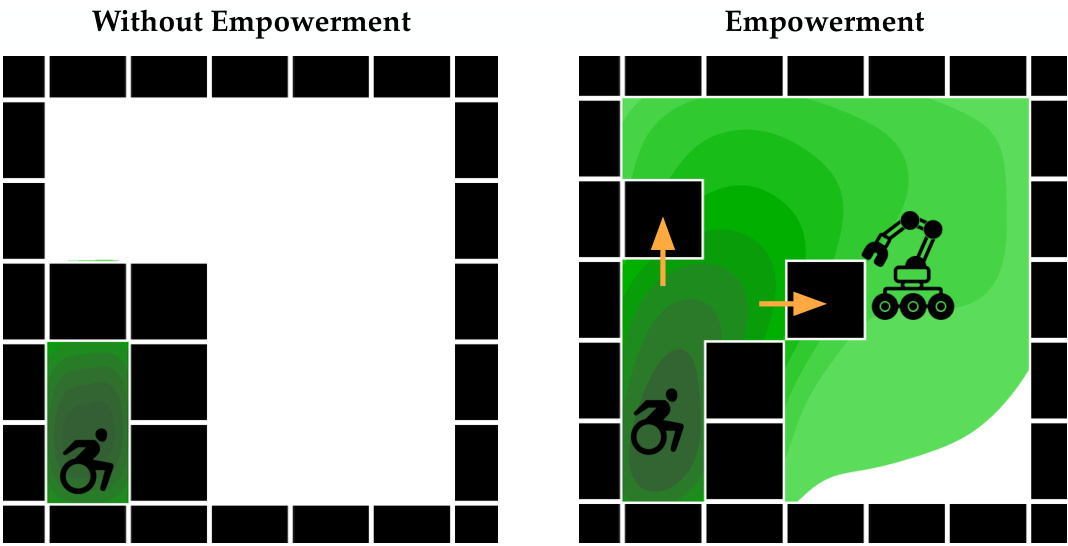
This figure is a visual representation of the core concept of the paper: empowering human users through assistive agents. The left panel (‘Without Empowerment’) shows a scenario where an assistive agent’s actions provide limited benefit to the human user, leaving the human constrained in their possible actions. In contrast, the right panel (‘Empowerment’) illustrates how the assistive agent’s actions empower the human, enabling them to achieve a wider range of outcomes, which is the goal of the proposed algorithm.

This table presents the results of experiments conducted in the Overcooked environment. It compares the performance of the proposed Empowerment via Successor Representations (ESR) method against three baselines: Reward Inference, AvE (Assistance via Empowerment), and a random agent. The comparison is done across three different layouts of the Overcooked environment: Asymmetric Advantages, Coordination Ring, and Cramped Room. The numbers represent the average reward achieved (± standard error) by each method in each layout, illustrating the effectiveness of ESR, particularly in more complex scenarios.
In-depth insights#
Empowerment’s Geometry#
The concept of “Empowerment’s Geometry” offers a compelling framework for understanding and optimizing assistive AI agents. It moves beyond traditional reward-based approaches, which often struggle with the complexities of human preferences and suboptimal behavior. By focusing on maximizing the human’s influence over the environment, empowerment emphasizes enabling the human to reach a wider range of desired outcomes. This perspective is particularly insightful as it provides an intrinsic motivation for the assistive agent, reducing reliance on potentially inaccurate human reward models. The geometrical interpretation, visualizing empowerment as the volume of the state marginal polytope, offers a valuable tool for intuitive understanding and formal analysis. This novel approach addresses scalability challenges, providing a framework for high-dimensional settings. The theoretical connection between empowerment and reward maximization, while requiring certain assumptions, lays a strong foundation for responsible and effective assistive AI development. Information geometry allows for practical computation, particularly through contrastive learning methods that efficiently estimate the empowerment objective without explicitly modeling human preferences.
Contrastive Successors#
The concept of “Contrastive Successors” in the context of assistive AI likely refers to a method using contrastive learning to learn representations, or features, that predict future states. These “successor” representations capture the influence of both the human’s and the AI agent’s actions on the future state of the environment. The “contrastive” element suggests a learning process comparing these successor representations under different actions, allowing the AI to learn which actions best empower the human user. This approach avoids explicitly modeling the human’s reward function, instead focusing on improving the human’s control over the environment. Scalability is a key advantage, as contrastive methods can handle high-dimensional state spaces, making the technique suitable for complex real-world assistive tasks such as robotic assistance or collaborative game playing. This contrasts with traditional methods of inverse reinforcement learning that infer human preferences, often encountering scalability issues. The effectiveness hinges on the quality of the learned successor features, and their ability to accurately capture the impact of actions on future states. Therefore, robust feature learning is a central challenge in effectively applying this contrastive successors approach.
Overcooked: ESR Scaled#
The heading ‘Overcooked: ESR Scaled’ suggests an experimental section in a research paper focusing on the scalability of a novel Empowerment via Successor Representations (ESR) algorithm within the complex, multi-agent environment of the Overcooked game. The use of Overcooked is crucial as it presents a high-dimensional, cooperative problem that challenges traditional reinforcement learning approaches. The researchers likely demonstrate that, unlike prior methods, their ESR model effectively scales to this complex setting, achieving significant improvements in assisting a human player. This success would highlight the robustness and scalability of the ESR algorithm, showcasing its potential to solve complex real-world assistive AI problems that demand interacting with humans in high-dimensional environments. The results likely contrast with other simpler, less scalable methods, solidifying the significance of ESR for future assistive AI applications.
Empowerment & Reward#
The core concept explored in the paper is how an AI agent can assist humans without explicitly knowing their reward function. Instead of inverse reinforcement learning (inferring human preferences), the authors propose using empowerment as an intrinsic motivation. Empowerment, in this context, means maximizing the human’s ability to influence the environment. This approach is theoretically linked to reward maximization: under certain assumptions (uniformly distributed human rewards and sufficient exploration), maximizing empowerment provides a lower bound on the average reward the human receives. The connection between empowerment and reward is crucial because it shows that assisting humans through empowerment isn’t just a heuristic, but is theoretically grounded in achieving desirable outcomes for humans. The paper further proposes a computationally efficient method, using contrastive successor representations, to estimate and maximize empowerment in high-dimensional environments, showcasing a significant improvement in scalability compared to existing methods. This scalability is key, as it makes the empowerment-based approach practically applicable to real-world scenarios beyond simple benchmarks. Thus, the paper bridges the gap between theoretical principles of empowerment and the practical considerations of reward-based assistance, suggesting a novel path for designing safe and effective AI assistants.
Assistance’s Future#
The future of assistance hinges on scalable and robust methods that go beyond inferring human preferences. Current inverse reinforcement learning approaches struggle in high-dimensional settings, highlighting the need for intrinsic motivation techniques. Empowerment, as an intrinsic objective, presents a promising alternative, enabling agents to assist humans by maximizing their capacity to affect the environment. However, the practical application of empowerment requires scalable representations, such as contrastive successor representations, which have shown potential in high-dimensional settings. Future research should focus on addressing limitations like the need for human action observability and developing methods for safe and reliable deployment in real-world scenarios. Safety and ethical considerations, particularly concerning power imbalances and potential misuse, demand careful attention to ensure assistive agents empower humans fairly and responsibly. Finally, the combination of intrinsic motivation and advanced representation learning appears key to the development of truly helpful and scalable AI assistants.
More visual insights#
More on figures

This figure illustrates the concept of empowerment using information geometry. The left panel shows the state marginal polytope, representing the possible future state distributions for different human actions given a fixed state and robot policy. The center panel illustrates mutual information as the distance between the average state distribution and the furthest achievable state distributions. The right panel shows that maximizing empowerment corresponds to maximizing the size of this polytope, enabling the human to reach a wider range of desired states.
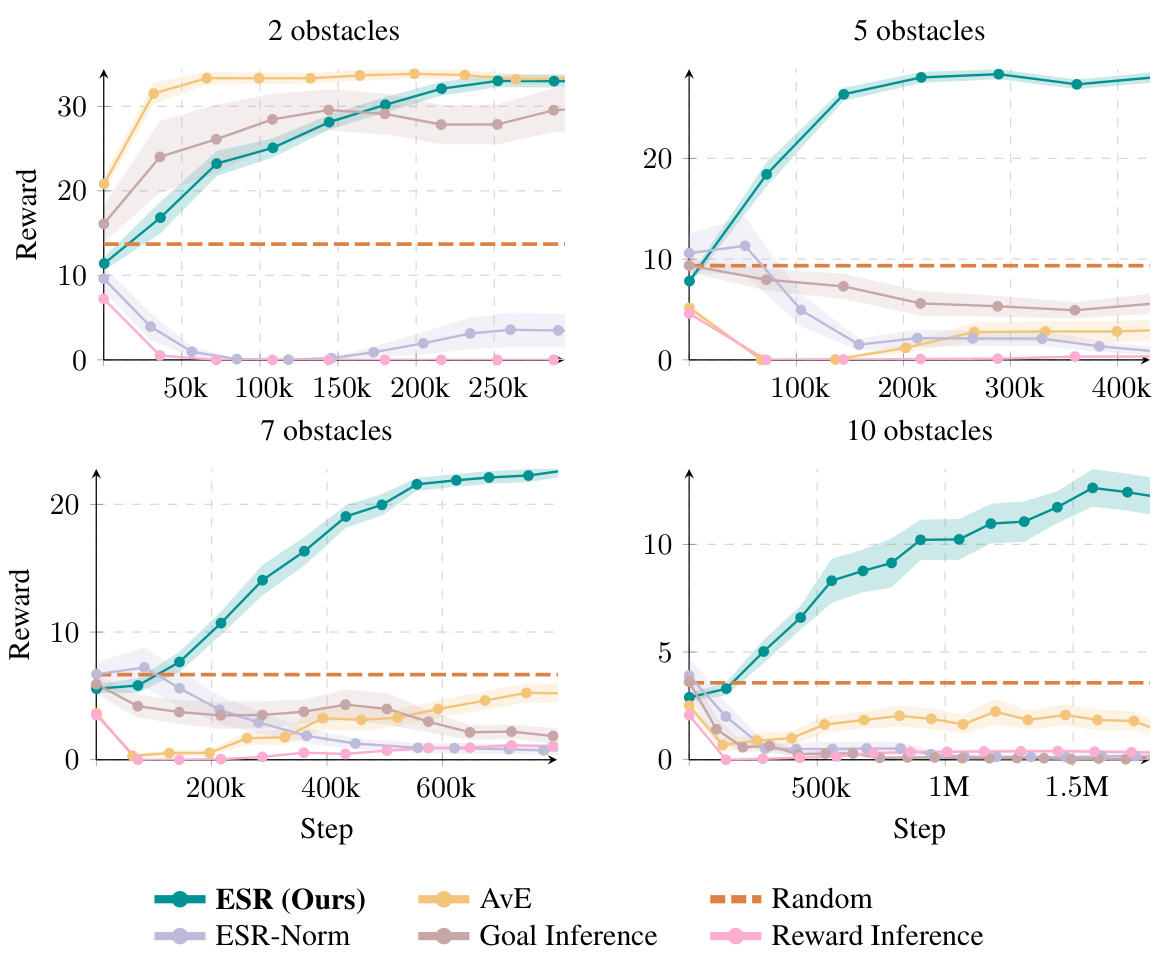
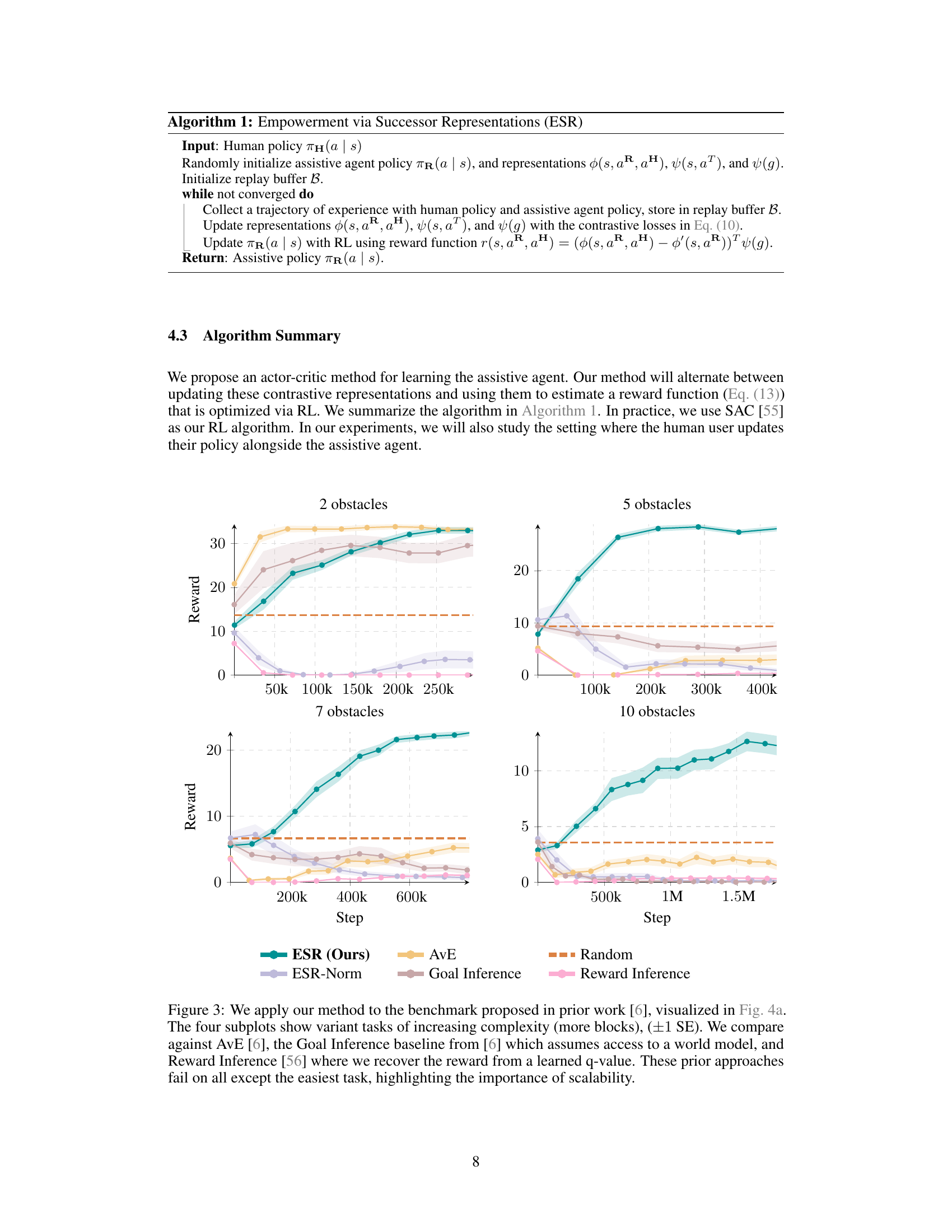
This figure compares the performance of the proposed Empowerment via Successor Representations (ESR) method against several baselines on a benchmark task with increasing difficulty. The task involves assisting a human agent in navigating an obstacle course to reach a goal. The four subplots show the results for different numbers of obstacles (2, 5, 7, and 10). The ESR method outperforms the baselines, especially as the task complexity increases, demonstrating its scalability to more challenging scenarios.

This figure shows three different experimental environments used in the paper. (a) is a modified version of the obstacle gridworld from a previous work, scaled up to 7 blocks. (b) and (c) show two different layouts of the Overcooked game environment, known for its cooperative gameplay requiring coordination between agents.
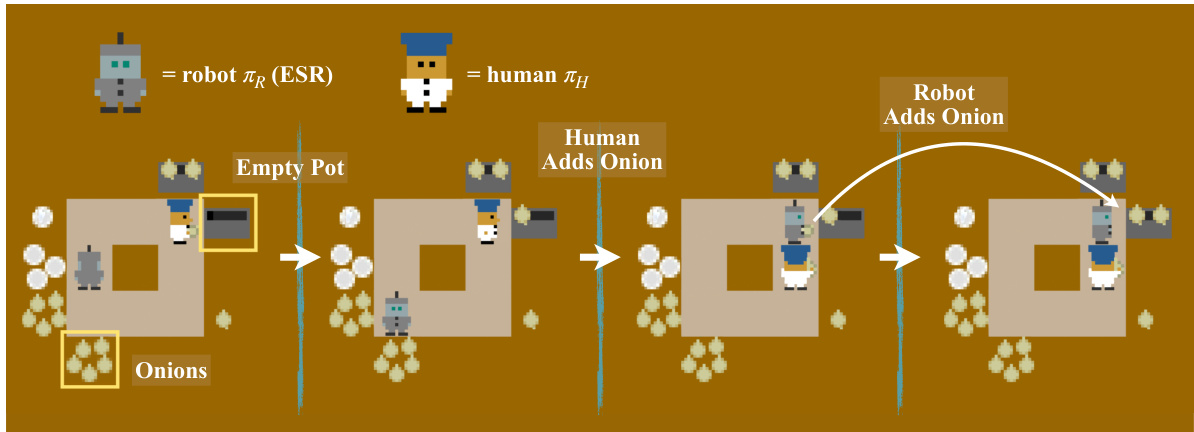
This figure shows a sequence of actions in the Overcooked Coordination Ring environment, illustrating how the ESR agent assists the human. The human and robot take turns adding onions to the pots. The key observation is that the ESR agent waits for the human to perform an action before taking its own, maximizing the impact of human action on the environment. This demonstrates the agent’s ability to learn collaborative behaviors without explicitly modeling the human’s reward.

This figure compares the performance of the proposed Empowerment via Successor Representations (ESR) method against other baseline methods (AvE, Goal Inference, Reward Inference) on a benchmark task with varying difficulty levels (2, 5, 7, and 10 obstacles). The results show that ESR significantly outperforms the baselines in more complex scenarios, demonstrating its scalability to higher-dimensional problems.

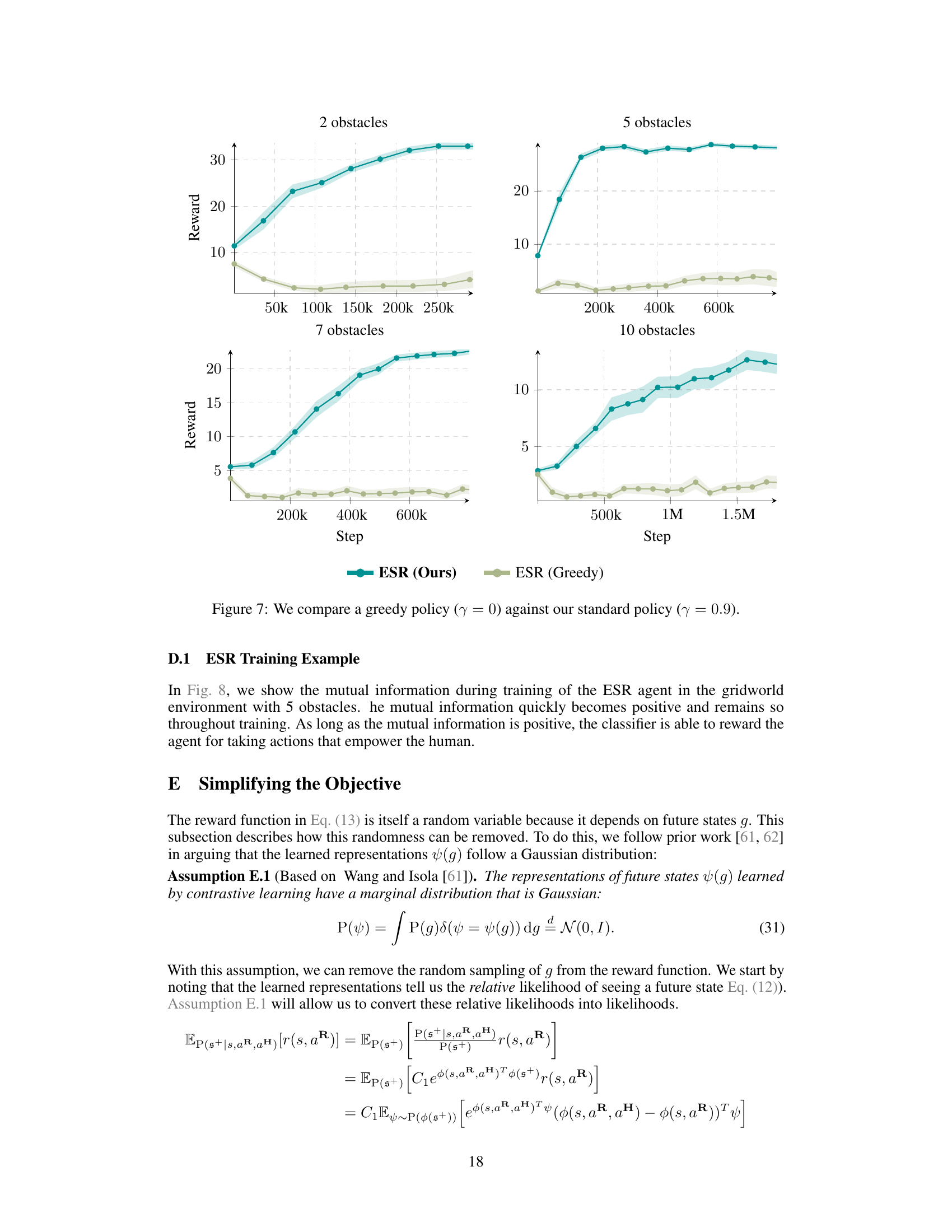
This figure compares the performance of the proposed Empowerment via Successor Representations (ESR) method against several baselines on an obstacle gridworld assistance task. The task involves a human user trying to reach a goal while avoiding obstacles, and an assistive agent helping the user. The four subplots show results for increasing numbers of obstacles. The ESR method significantly outperforms the baselines (AvE, Goal Inference, Reward Inference) as the task complexity increases. The results highlight ESR’s scalability to higher-dimensional problems compared to previous methods.
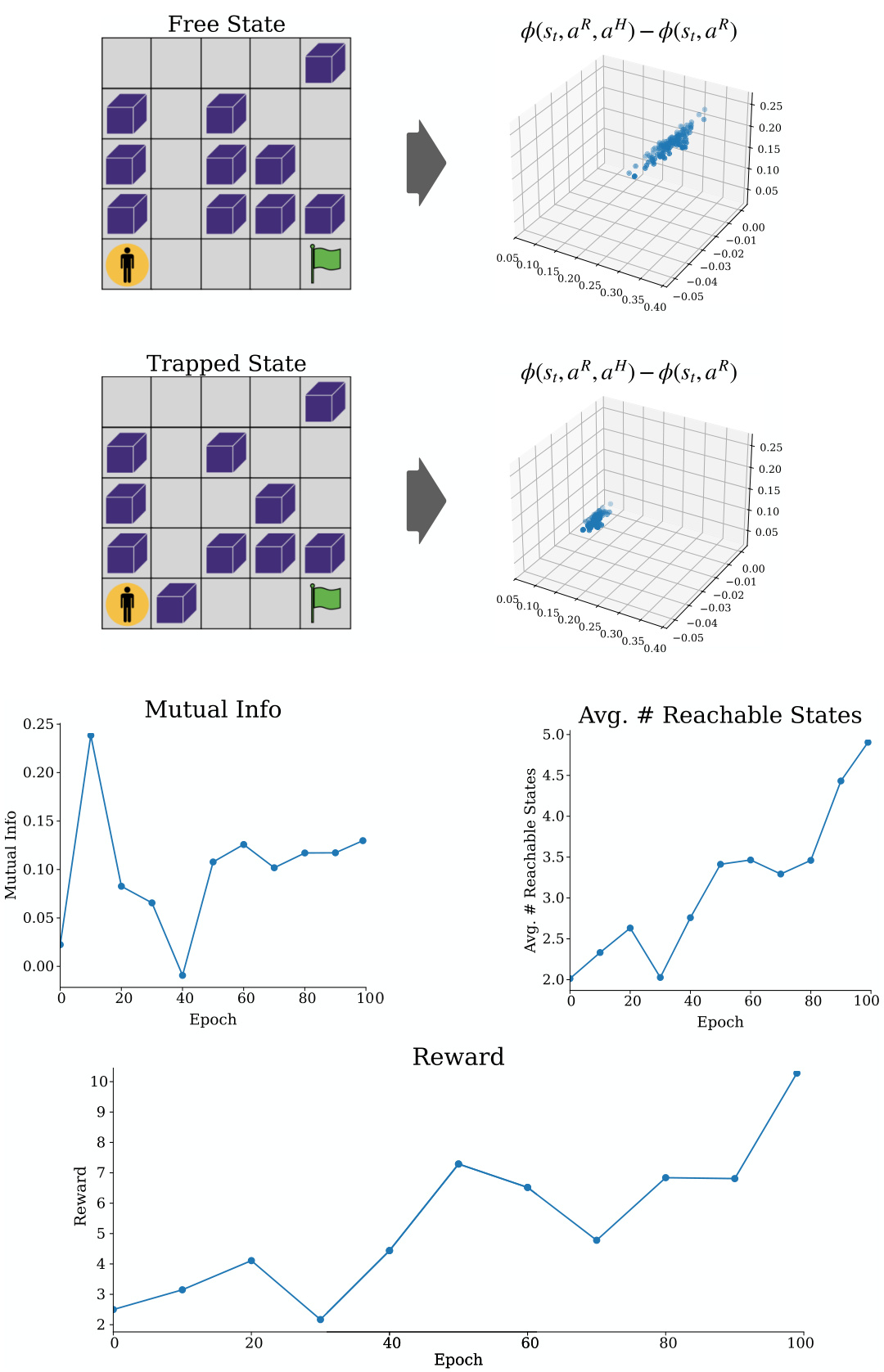
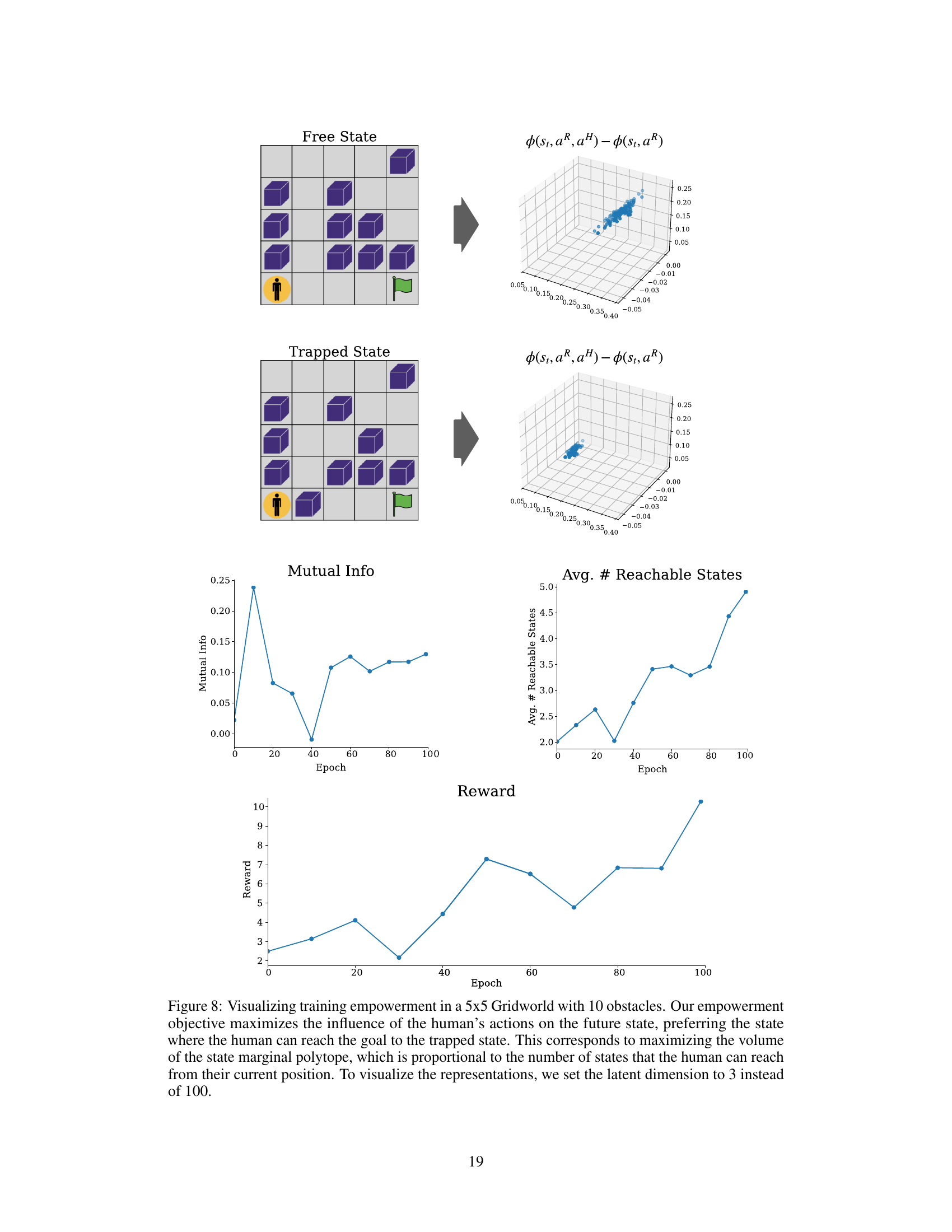
This figure visualizes how the proposed empowerment objective affects the agent’s learning process in a gridworld environment. The top part shows two scenarios: a ‘free state’ where the human can easily reach the goal and a ’trapped state’ where the human is blocked. The plots show the difference in future state distributions between these two scenarios, highlighting the agent’s ability to distinguish between states based on the human’s ability to reach the goal. The lower plots show the mutual information (a measure of empowerment), the average number of reachable states, and the overall reward achieved during training. These plots demonstrate how maximizing empowerment leads to improved performance in the task. The latent dimension is reduced for visualization purposes.
Full paper#