↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Processing long-form videos using transformer-based models is computationally expensive due to the large number of tokens. Existing solutions like token dropping or sampling cause information loss. This paper addresses this by exploring video token merging, which combines similar tokens to reduce computation. The challenge lies in deciding which tokens to merge, as relying solely on similarity ignores token saliency.
The authors propose a novel learnable VTM that dynamically merges tokens based on their saliency. This approach outperforms naive token merging methods by dynamically adjusting the merging strategy based on the importance of the tokens. Experiments on various datasets demonstrate improved accuracy and significantly reduced memory usage and increased throughput, achieving a 6.89x speedup and an 84% memory reduction. This demonstrates the effectiveness of their learnable VTM algorithm.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working with long-form videos. It offers significant improvements in efficiency and performance by introducing a novel token merging technique, directly addressing the computational bottlenecks inherent in processing such videos. This opens new avenues for research in video understanding using transformer models and large-scale video datasets.
Visual Insights#
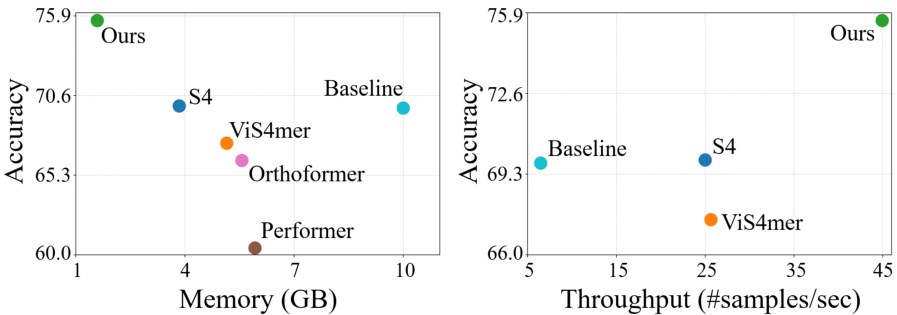
This figure compares the performance of different video understanding models (Ours, Baseline, S4, ViS4mer, Orthoformer, Performer) on the LVU dataset in terms of GPU memory usage and throughput (samples per second). The x-axis represents either memory (GB) or throughput (#samples/sec) while the y-axis shows the prediction accuracy. The results demonstrate that the proposed ‘Ours’ method achieves higher accuracy with significantly reduced memory usage and increased throughput compared to the other methods.
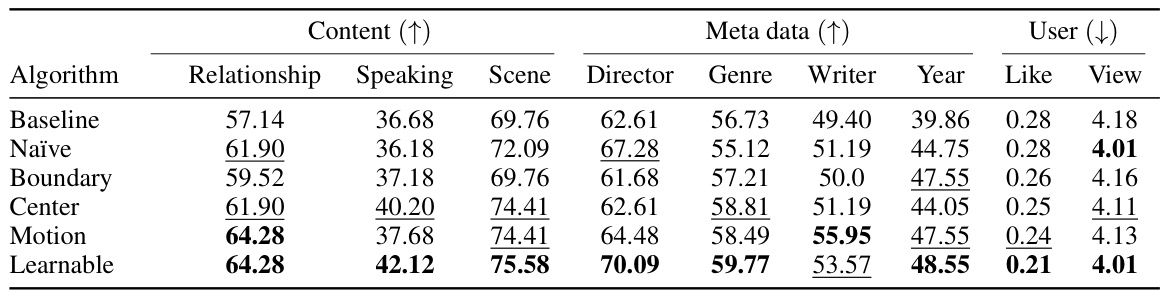
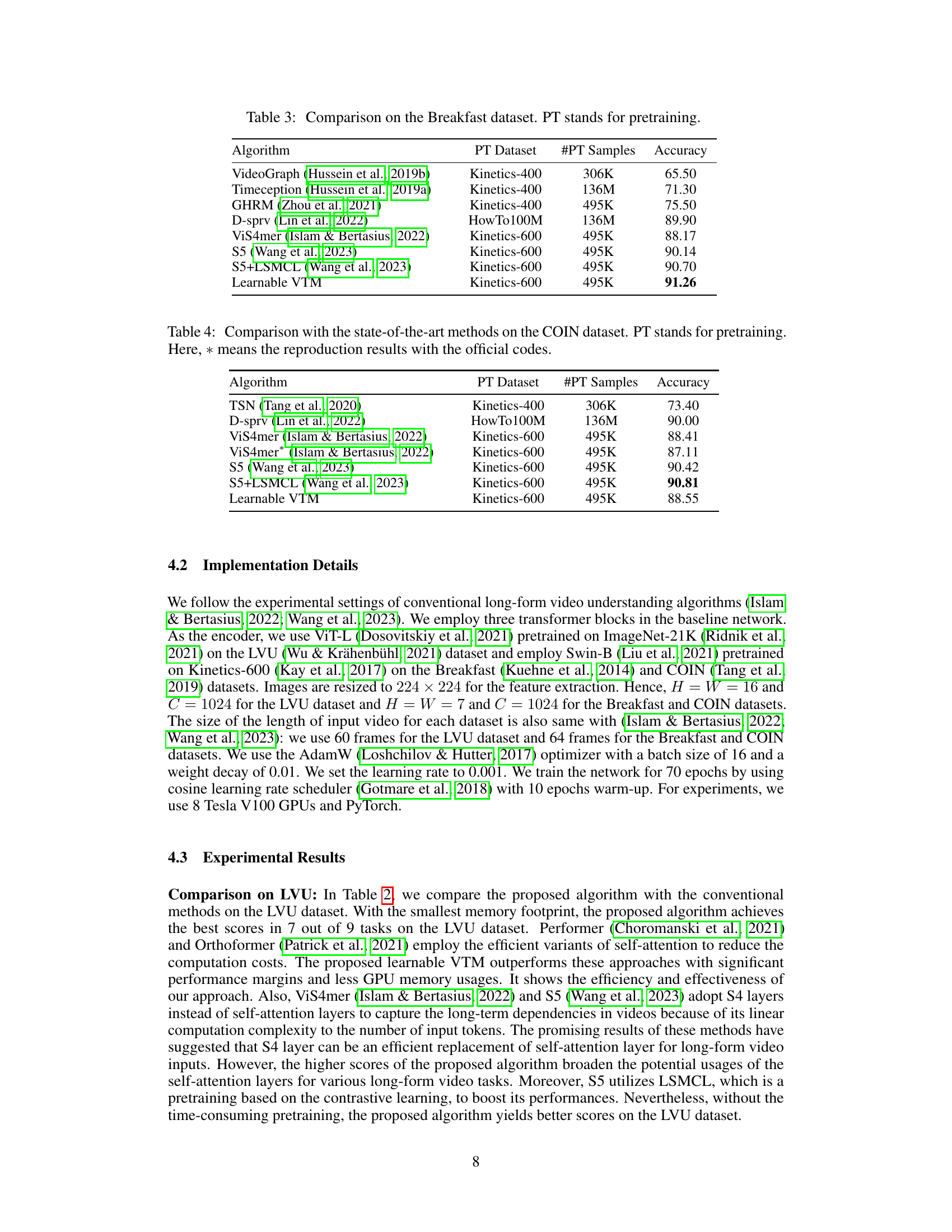
This table presents a comparison of various Video Token Merging (VTM) methods on the Large-scale Video Understanding (LVU) dataset. It shows the performance of different VTM approaches across multiple video understanding tasks, including content understanding (relationship, speaking style, scene), metadata prediction (director, genre, writer, year), and user engagement (like, view). The best results for each task are highlighted in bold, while the second-best results are underlined, providing a clear visual representation of the comparative performance of each VTM method. The baseline represents the performance without VTM.
In-depth insights#
Video Token Merge#
The concept of ‘Video Token Merging’ presents a novel approach to enhance efficiency and effectiveness in processing long-form videos within transformer-based models. Instead of relying solely on traditional methods like sampling or token dropping, which can lead to information loss, this technique merges similar video tokens, thereby reducing computational costs and memory footprint. This is particularly crucial for long videos, which often contain redundant spatiotemporal information. The key innovation lies in considering not just token similarity but also their saliency, which is crucial for distinguishing important details. This approach involves developing various merging strategies, culminating in a learnable Video Token Merging (VTM) algorithm that dynamically adjusts merging based on predicted saliency scores, further improving performance. The results demonstrate significant memory reduction and speed improvements, highlighting the potential of VTM for advancing long-form video understanding.
VTM Strategies#
The paper explores various video token merging (VTM) strategies for efficient long-form video understanding. It begins with a naïve approach, extending image-based token merging methods directly to video. However, recognizing the limitations of relying solely on token similarity, the authors progress to more sophisticated strategies. A region-concentrated VTM focuses on merging tokens in less salient regions while preserving those in the central, more informative areas. Further refinement leads to a motion-based VTM, where merging decisions are guided by motion information, prioritizing the preservation of tokens in dynamic regions. Finally, a learnable VTM is proposed, dynamically merging tokens based on learned saliency scores, offering the most adaptive and effective strategy. The learnable model uses a main path for standard self-attention and an auxiliary path to learn saliency, which is used during training only to reduce computational costs in the inference phase. The exploration of these diverse VTM strategies shows how to effectively reduce redundancy in video data for more efficient processing by transformer models.
Learnable VTM#
The proposed “Learnable VTM” represents a significant advancement in video token merging. Unlike previous methods that rely on pre-defined rules or heuristic estimations of token similarity and saliency, Learnable VTM introduces a data-driven approach that dynamically determines which tokens to merge based on learned saliency scores. This is achieved through a novel architecture incorporating two parallel paths: a main path processing spatiotemporal tokens via self-attention, and an auxiliary path estimating token saliency scores. The model’s ability to adaptively adjust merging strategies based on content allows it to significantly reduce computational costs compared to baseline methods while maintaining or even improving classification accuracy on various long-form video datasets. The introduction of a learnable component opens up exciting possibilities, potentially enabling the model to better handle diverse video styles, capturing temporal dynamics and contextual information more effectively. The effectiveness of Learnable VTM across multiple datasets strongly suggests its generalizability and robustness as a powerful technique for processing long-form video data.
Efficiency Gains#
The concept of ‘Efficiency Gains’ in a research paper likely centers on improvements in computational resource utilization. This could manifest as reduced memory footprint, allowing processing of larger datasets or more complex models within existing hardware limitations. Increased throughput, meaning faster processing speed, is another key aspect. The paper might detail how these gains were achieved, for example, by employing innovative algorithmic techniques (such as token merging) that decrease computational complexity. A quantitative analysis showcasing the magnitude of the efficiency gains, including precise figures for memory savings and throughput improvements, is crucial for demonstrating the practical value and impact of the research. The discussion would also likely include comparisons against existing baselines, highlighting the relative advantages of the proposed methods. The analysis might delve into the trade-offs involved, considering whether these gains come at the cost of accuracy or other performance metrics. Finally, it’s important to consider the generalizability of these efficiency gains, discussing whether the improvements are consistent across different datasets and hardware platforms, and what factors might influence their effectiveness.
Future Works#
Future work could explore several promising avenues. Extending the learnable VTM to other video understanding tasks beyond classification, such as action recognition or video captioning, would demonstrate broader applicability. Investigating the impact of different architectural choices on VTM’s performance is crucial, for example, by comparing its effectiveness within various transformer backbones or exploring its integration with other efficiency-enhancing techniques. A deeper dive into the theoretical underpinnings of VTM could unveil new insights and potentially lead to more robust and efficient algorithms. Benchmarking VTM against a broader range of existing methods on a wider selection of datasets is needed for comprehensive evaluation. Finally, exploring the potential of combining VTM with other token-level optimization techniques, such as token selection or pruning, could offer significant performance gains and lead to further improvements in memory efficiency and throughput.
More visual insights#
More on figures

This figure illustrates three different network architectures. (a) shows a baseline network for video processing using transformers. The input video is encoded into tokens, which then pass through multiple transformer blocks before a prediction head produces the final output. (b) zooms in on a single transformer block, detailing its internal components, such as layer normalization (LN), attention, dropout, a linear layer, and a GELU activation function. (c) shows a modified transformer block that incorporates a Video Token Merging (VTM) layer, which is the core contribution of the paper. This layer is added to increase efficiency by reducing the number of tokens before the final linear layer and GELU activation.

This figure visualizes how different video token merging (VTM) methods select target tokens for merging. (a) shows the naïve VTM, which selects tokens uniformly. (b) illustrates the center-concentrated VTM, which focuses on the central area of the video. (c) presents the motion-based VTM, which emphasizes tokens with significant motion. Finally, (d) displays the learnable VTM, which intelligently selects tokens based on saliency, prioritizing important regions over less significant backgrounds.
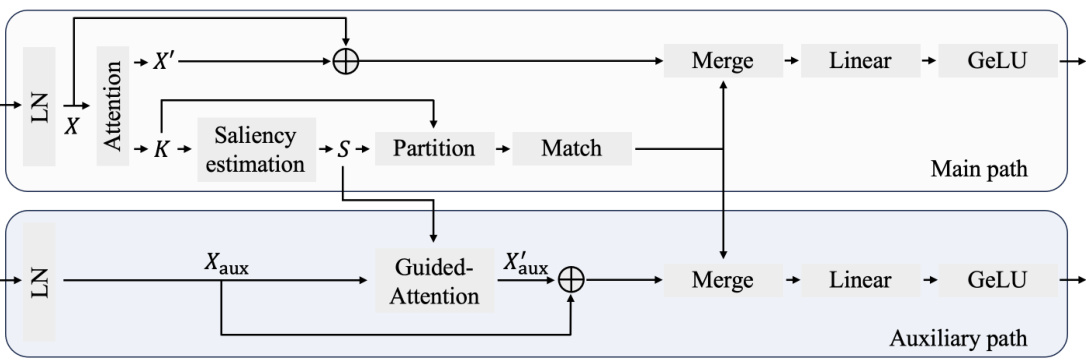
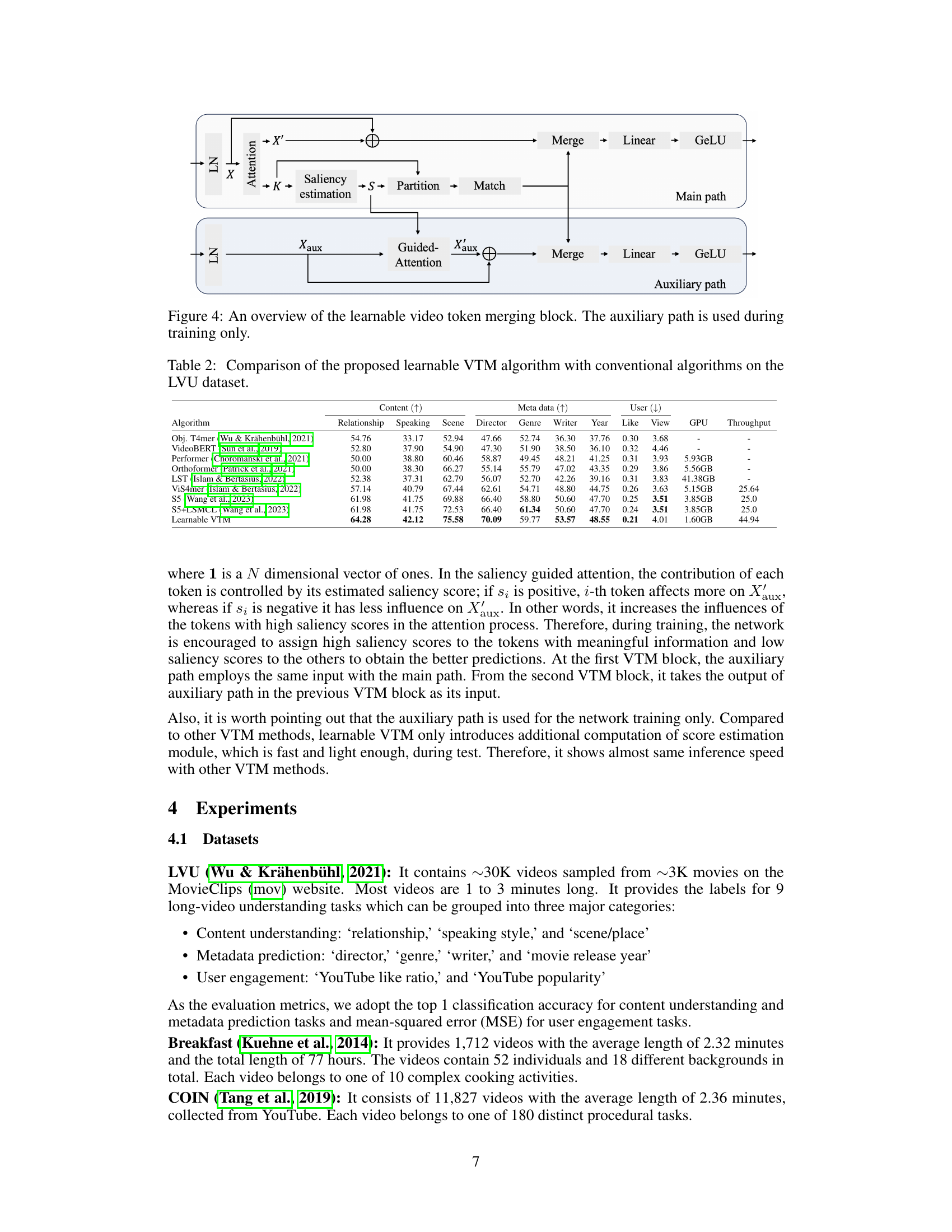
This figure shows the architecture of the learnable video token merging (VTM) block. It consists of two main paths: a main path and an auxiliary path. The main path performs standard self-attention on the input tokens and then estimates saliency scores for each token. These scores are used to partition the tokens into target and source sets. The source tokens are then matched to the most similar target tokens and merged using average pooling. The auxiliary path is used only during training. It performs saliency-guided attention on the auxiliary tokens, merging them in a similar way to the main path. The outputs of both paths are then added together to produce the final output of the VTM block.

This figure visualizes the results of video token merging on the LVU dataset using the proposed learnable VTM. The top row shows example video frames from different video clips, and the bottom row displays the corresponding token merging results. Patches (tokens) with the same inner and border colors have been merged together by the algorithm. The visualization illustrates how the algorithm groups similar visual tokens, particularly merging background or less important visual information while preserving salient and important details.
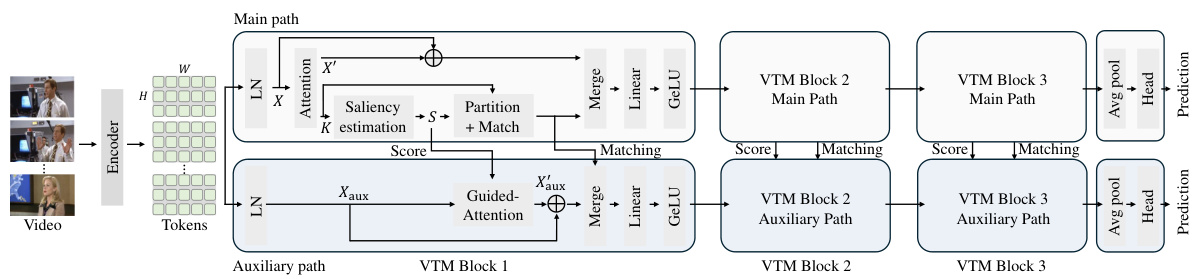
This figure illustrates the detailed architecture of the proposed learnable video token merging (VTM) method. The encoder first extracts video tokens with a channel dimension of 1024. Each VTM block reduces the channel dimension by half, resulting in a final dimension of 256 after three blocks. The figure shows the main path, responsible for standard self-attention and token merging, and the auxiliary path, used only during training to refine saliency estimation. The auxiliary path incorporates a saliency-guided attention mechanism, helping the network to assign higher saliency scores to meaningful tokens. Both paths contribute to the updated tokens, which are then used for classification. The average pooling is used before the prediction head.
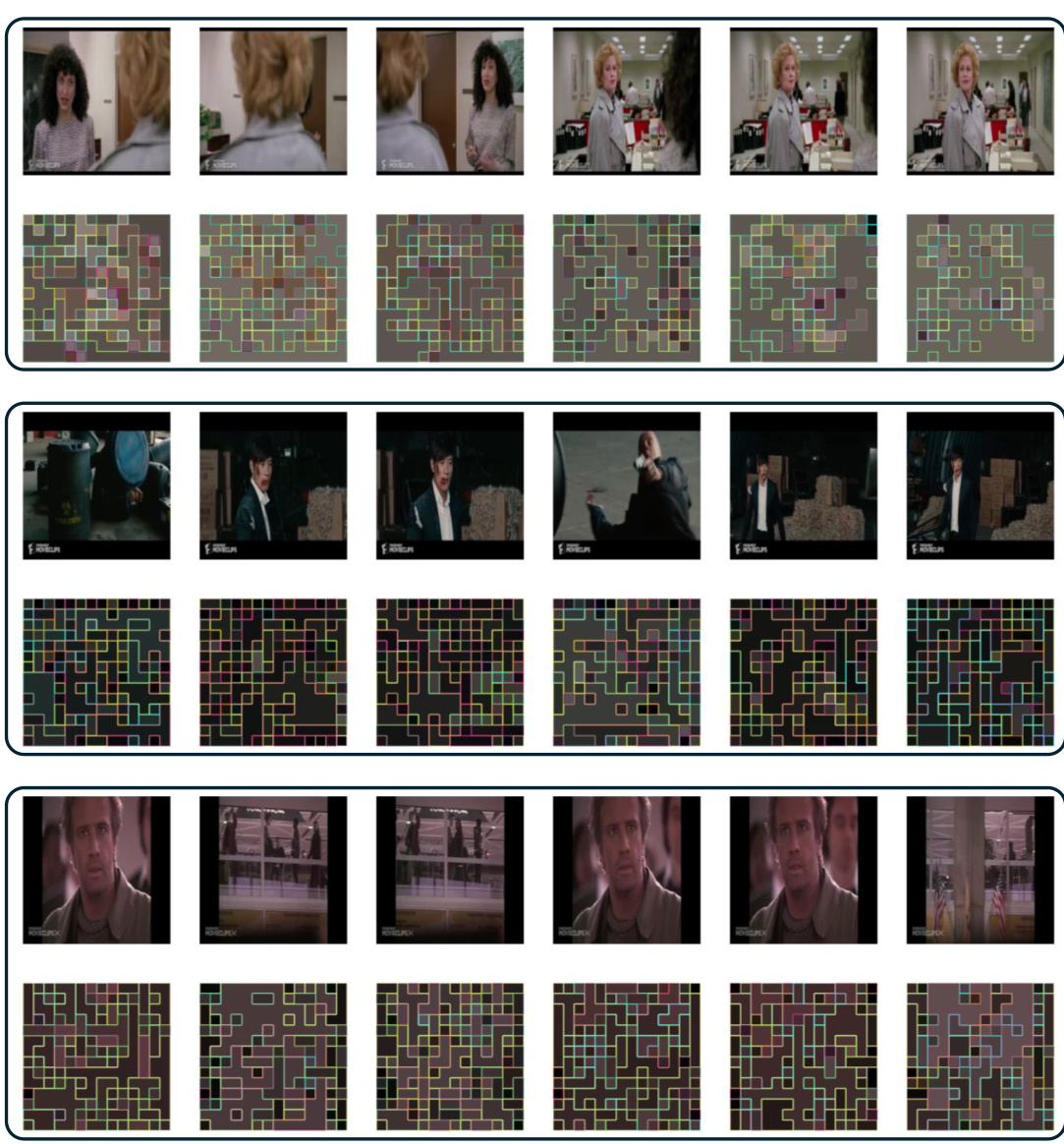
This figure shows three examples of video token merging on the LVU dataset using the proposed learnable VTM. Each row represents a different video clip. The top row displays frames from the video clip. The bottom row visualizes the merging process, where patches (tokens) with the same inner and border colors are merged together. This illustrates how the algorithm groups together semantically similar visual information into merged tokens.
More on tables
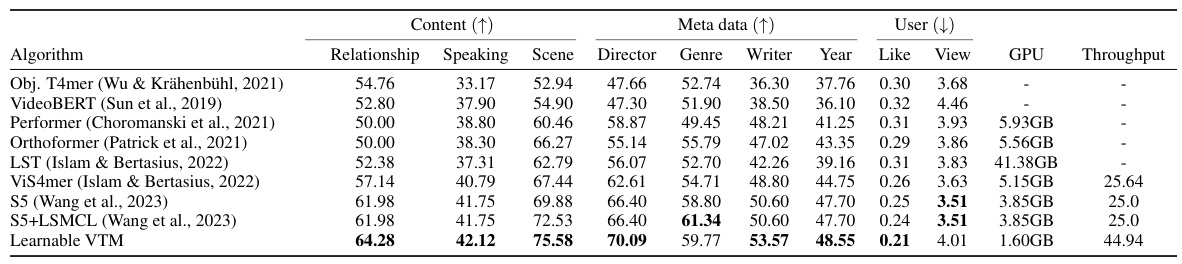
This table compares the performance of different video token merging (VTM) methods on the Large-scale Video Understanding (LVU) dataset. The methods include a baseline, naïve VTM, boundary-concentrated VTM, center-concentrated VTM, motion-based VTM, and learnable VTM. The table presents the accuracy scores for nine different video understanding tasks, categorized into content understanding, meta-data prediction, and user engagement. The best results for each task are highlighted in bold, and the second-best results are underlined. This allows for a direct comparison of the effectiveness of each VTM method in improving the accuracy of video understanding across various aspects.
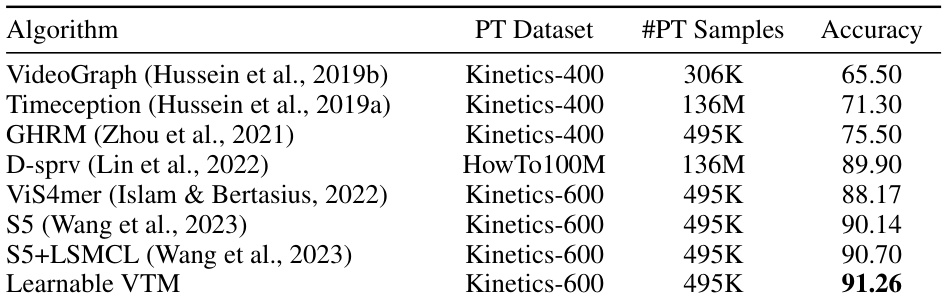
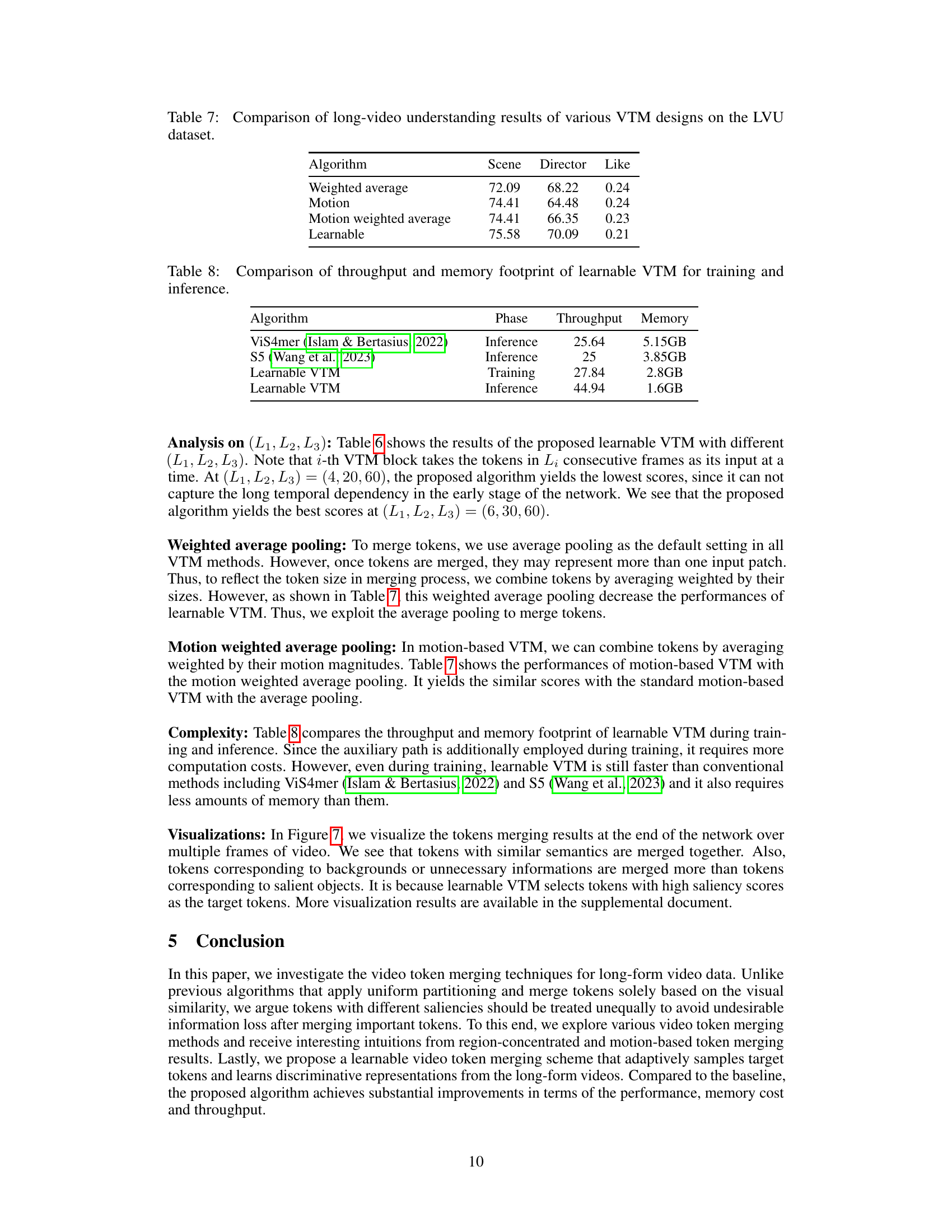
This table compares the performance of different algorithms on the Breakfast dataset, focusing on the accuracy achieved. It highlights the impact of using different pre-training datasets (PT Dataset) and the number of pre-training samples (#PT Samples) on the final accuracy of the models. The algorithms listed represent various state-of-the-art methods for video understanding. The Learnable VTM method, proposed in the paper, shows a high accuracy compared to other methods.
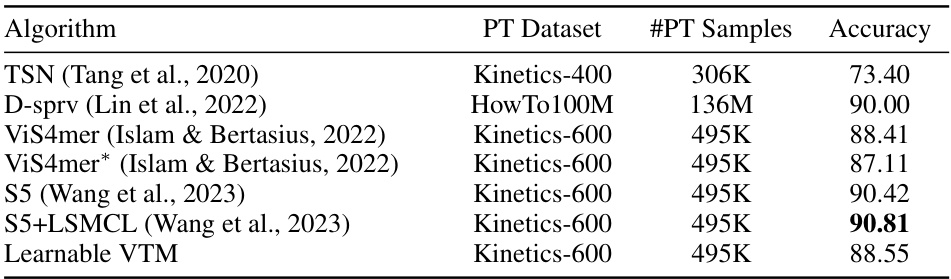
This table compares the performance of the proposed ‘Learnable VTM’ algorithm against other state-of-the-art methods on the COIN dataset for video understanding. It shows the algorithm used, the pre-training dataset used, the number of pre-training samples, and the achieved accuracy. The asterisk (*) indicates results reproduced using the official code, highlighting potential differences in implementation.

This table presents the performance comparison of the proposed learnable Video Token Merging (VTM) algorithm with different partition factors (γ) on the LVU dataset. It shows how the algorithm’s accuracy on three specific tasks (‘Scene’, ‘Director’, ‘Like’) and its throughput (samples per second) and GPU memory usage vary as the partition factor is changed from γ=2, 6, and 10. The baseline performance without VTM is also shown for comparison.
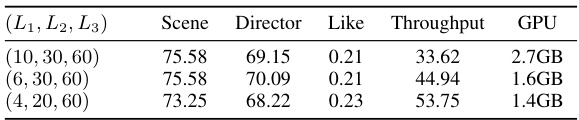
This table presents the results of the proposed learnable Video Token Merging (VTM) algorithm on the LVU dataset, showing the impact of varying the number of consecutive frames processed in each transformer block. It compares the performance (Scene, Director, Like metrics), throughput, and GPU memory usage across three different configurations: (10, 30, 60), (6, 30, 60), and (4, 20, 60). These numbers represent the number of frames processed sequentially in each of the three transformer blocks in the VTM. The results show a trade-off between throughput and accuracy as the values of L1, L2, L3 are adjusted.
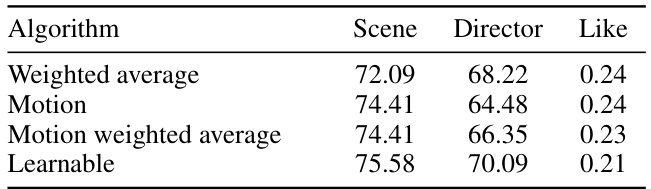
This table compares the performance of different video token merging (VTM) methods on the Long-form Video Understanding (LVU) dataset. The methods compared include a weighted average approach, motion-based merging, a motion-weighted average, and a learnable VTM. The results are presented for three specific tasks within the LVU dataset: scene classification, director prediction, and ’like’ prediction (likely referring to user engagement metrics). The learnable VTM shows the best performance across all three tasks.
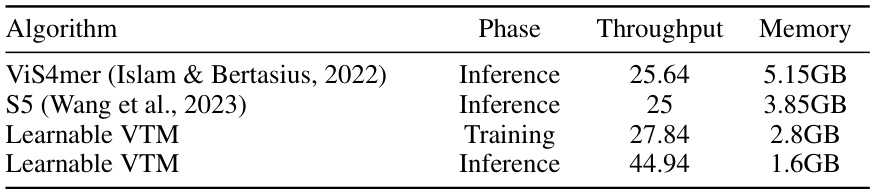
This table compares the throughput and memory usage of the proposed ‘Learnable VTM’ algorithm with two other state-of-the-art algorithms, ViS4mer and S5, during both training and inference phases. It highlights the efficiency gains achieved by the proposed method in terms of both speed and memory consumption.
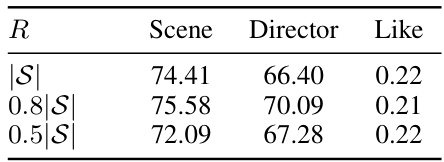
This table presents the results of the proposed algorithm with different values of R (the number of merged tokens). It shows the accuracy scores for ‘Scene’, ‘Director’, and ‘Like’ prediction tasks on the LVU dataset when varying the number of merged tokens. The results indicate that a value of R = 0.8|S| yields the best performance.
Full paper#