↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current universal segmentation methods excel at pixel-level understanding but lack text-based control and reasoning abilities. Conversely, large vision-language models excel at reasoning but struggle with pixel-level detail. This creates a need for a unified model that combines both capabilities.
OMG-LLaVA elegantly addresses this by using a universal segmentation model as a visual encoder, integrating image data, perception priors, and visual prompts. The LLM then processes this information to produce text responses and pixel-level segmentation results, achieving superior image-level, object-level, and pixel-level reasoning and understanding in a single, efficient model. The model’s simplicity, coupled with its state-of-the-art performance on multiple benchmarks, makes it a significant contribution to the field.
Key Takeaways#
Why does it matter?#
This paper is crucial because it presents OMG-LLaVA, a novel framework that significantly advances multimodal learning by seamlessly integrating image-level, object-level, and pixel-level reasoning. This unified approach tackles limitations of existing models and opens new avenues for research in visual understanding and reasoning. Its elegant design, using a single encoder, decoder, and LLM, makes it a valuable resource for the community, leading to more efficient and effective MLLMs. Researchers will find the comprehensive evaluations across multiple benchmarks particularly valuable, providing a strong benchmark for future work.
Visual Insights#

This figure demonstrates the various capabilities of the OMG-LLaVA model. It showcases examples of pixel-level tasks such as reasoning segmentation and interactive segmentation; object-level tasks such as region-level captioning and referring segmentation; and image-level tasks such as image captioning and image-level conversation. The figure visually represents the model’s ability to integrate multiple levels of understanding and reasoning within a unified framework.

This table compares the capabilities of various Multimodal Large Language Models (MLLMs), focusing on their ability to handle image-level, object-level, and pixel-level tasks. It highlights the unique features of OMG-LLaVA, which is the proposed model in the paper, emphasizing its comprehensive capabilities and simpler architecture compared to other models.
In-depth insights#
Unified MLLM Design#
A unified Multimodal Large Language Model (MLLM) design presents a significant advancement in AI by integrating diverse modalities seamlessly. The core idea is to break down the traditional silos between image-level, object-level, and pixel-level understanding, creating a single, unified architecture that processes and reasons across all these levels simultaneously. This contrasts sharply with previous approaches which often involved separate models or complex pipelines for each level. A key advantage of this unification is improved efficiency and reduced computational cost. By processing the data holistically, the unified MLLM can leverage contextual information across modalities to make more accurate predictions and inferences. Furthermore, it simplifies model design and training, leading to a more streamlined approach that’s easier to manage and update. The challenge, however, lies in effectively fusing these diverse levels of representation. Effective fusion strategies are crucial to avoiding information loss or interference. Finding optimal ways to integrate pixel-level detail with object-level and image-level context requires innovative architectural designs and training techniques. The successful realization of a unified MLLM design will pave the way for more robust, adaptable, and contextually intelligent AI systems that can handle a wider range of tasks and applications.
Perception Prior#
The concept of ‘Perception Prior’ in the context of a vision-language model is crucial for bridging the gap between raw visual input and higher-level semantic understanding. It represents the model’s pre-existing knowledge or assumptions about the visual world, influencing how it interprets incoming data. Effectively integrating perception priors enhances the model’s ability to reason and understand images, especially in complex scenarios with ambiguities or incomplete information. This prior knowledge can stem from various sources including: pre-training on large-scale datasets, which exposes the model to a vast range of visual patterns and contexts; inherent biases within the model architecture, which might favor certain types of object recognition or scene interpretations; and explicitly provided visual prompts, allowing users to guide the model towards specific areas of interest. The success of a perception prior approach hinges on its ability to both guide the model’s attention to relevant features while avoiding the introduction of biases that lead to inaccurate or unfair interpretations. A well-designed perception prior mechanism should demonstrably improve accuracy and efficiency of visual reasoning, handling ambiguous situations more robustly than models without this mechanism. Careful design and evaluation are critical to ensure the prior does not overwhelm the data-driven aspects of the model and leads to a truly synergistic combination of pre-existing knowledge and new observations.
Visual Prompt Fusion#
Visual prompt fusion, in the context of multimodal large language models (MLLMs), presents a crucial challenge and opportunity. The core idea is to effectively integrate diverse visual cues—points, bounding boxes, and segmentation masks—with textual instructions to enable sophisticated visual reasoning and generation. A naive approach might simply concatenate these inputs; however, a more effective strategy would involve a fusion mechanism that weighs and combines the different modalities based on their relevance to the specific task. This might involve attention mechanisms that prioritize certain visual cues based on the textual instructions or more advanced approaches such as multimodal transformers that learn complex interactions between text and visual data. Successful visual prompt fusion should lead to improved performance on various visual reasoning tasks, including image captioning, visual question answering, referring expression segmentation, and visual grounding. Key challenges include handling variable visual input sizes and formats, ensuring efficient computation, and learning robust feature representations that are suitable for a variety of visual inputs and text instructions. Furthermore, effective fusion requires carefully designed model architectures that are capable of capturing the nuanced relationships between visual and textual information. This could involve using specialized transformer layers or exploring techniques like cross-modal attention. The ultimate goal is a system that can seamlessly integrate diverse visual prompts to achieve a level of visual understanding and reasoning capability exceeding that of individual modalities alone. Evaluation of the fusion process should be comprehensive, going beyond accuracy metrics to include qualitative analyses that assess the model’s ability to perform complex reasoning tasks based on combined visual and textual inputs.
Multi-level Reasoning#
Multi-level reasoning in vision-language models represents a significant advancement, moving beyond the limitations of single-level approaches. By integrating image-level, object-level, and pixel-level reasoning, these models gain a much richer understanding of visual data. Image-level reasoning focuses on holistic scene interpretation, while object-level reasoning delves into individual objects and their relationships. Pixel-level reasoning provides the finest-grained analysis, enabling precise segmentation and detailed feature extraction. The combination of these levels allows for complex tasks like referring expression segmentation and visual question answering. The challenge lies in effectively integrating these diverse levels of reasoning into a unified framework, a problem addressed by advanced architectures that leverage the power of large language models and sophisticated attention mechanisms to capture contextual information across different levels of granularity. This ability to perform multi-level reasoning is crucial for creating more robust and versatile vision-language systems capable of understanding and responding to nuanced visual prompts.
Future Enhancements#
Future enhancements for OMG-LLaVA could involve several key areas. Improving the model’s reasoning abilities is crucial, particularly for complex scenarios requiring multi-step inferences. This might involve exploring more advanced reasoning techniques or incorporating external knowledge bases. Addressing limitations in pixel-level understanding is another important aspect. While OMG-LLaVA shows promising results, further improvements to accuracy and detail, especially in handling challenging visual contexts or ambiguous visual prompts, are needed. Enhancing the handling of visual prompts would expand the model’s capabilities and user interaction. Exploring novel ways to incorporate diverse visual cues, such as sketches or 3D models, could lead to more flexible and intuitive interaction. Scaling the model to handle higher-resolution images and longer sequences would dramatically improve performance on complex tasks. Investigating efficient architectures and training strategies to address the computational costs associated with larger inputs is vital. Finally, thorough evaluation and benchmarking across broader datasets and tasks are crucial for ensuring robustness and generalizability. More detailed quantitative analysis, along with comprehensive qualitative evaluations, are necessary to fully understand the model’s strengths and weaknesses.
More visual insights#
More on figures
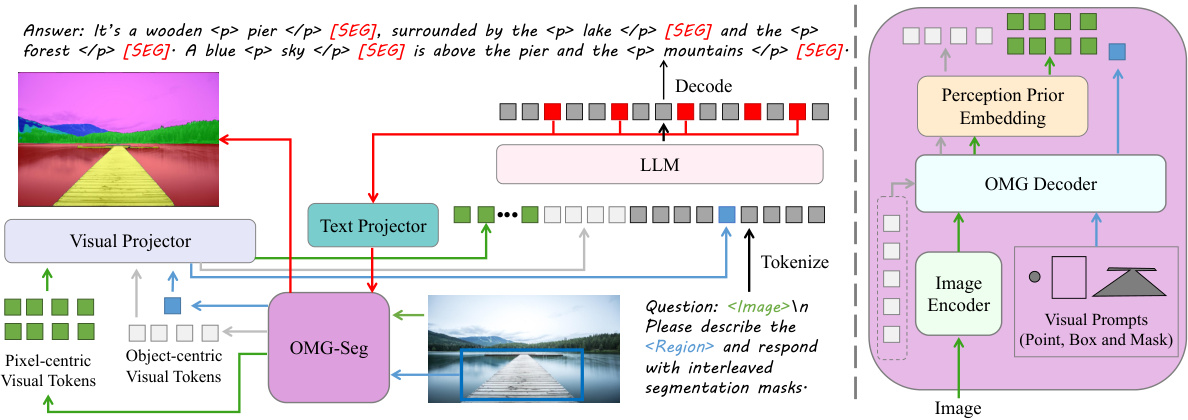
This figure illustrates the architecture of OMG-LLaVA, which combines the OMG-Seg model and a large language model (LLM). The OMG-Seg model processes the image to create pixel-centric and object-centric visual tokens. These tokens are provided to the LLM along with textual instructions. The LLM generates a text response and object-centric tokens, which the OMG-Seg then uses to create the final segmentation mask. The OMG-Seg model itself remains frozen during the process.
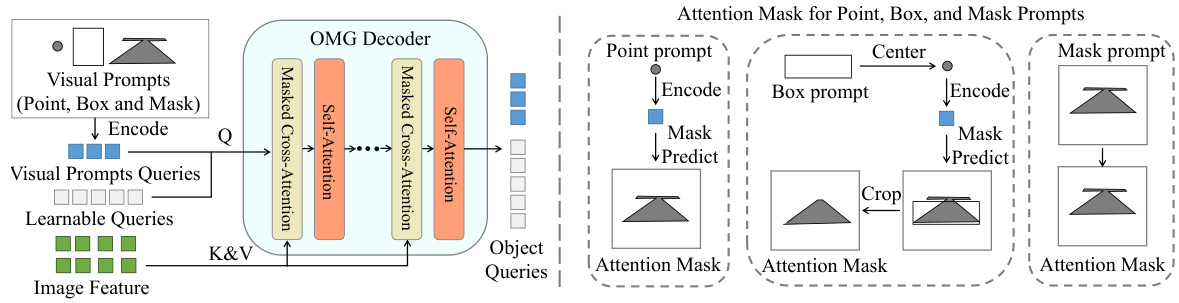
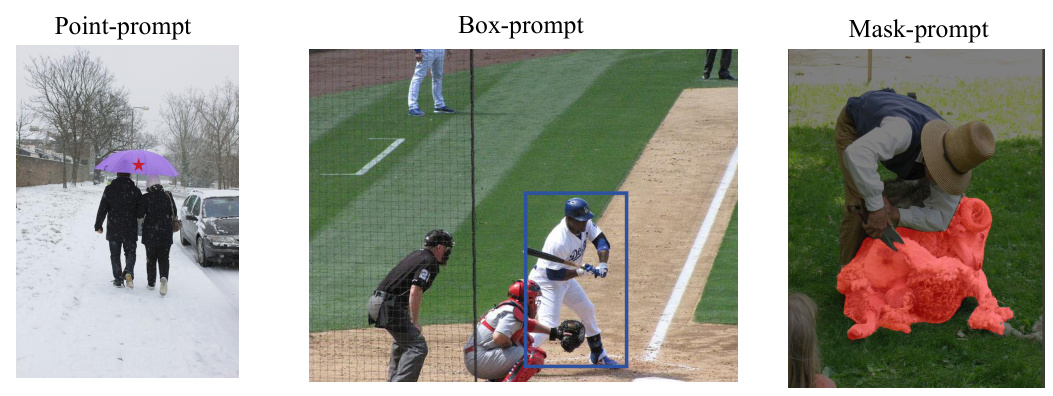
The OMG decoder takes in image features, learnable queries, and visual prompt queries (point, box, and mask). A novel attention mask generation strategy is employed. This strategy uses the spatial information inherent in box and mask prompts to create attention masks, ensuring that only relevant features contribute to the generation of object queries. These object queries are then decoded into pixel-level segmentation masks. The diagram illustrates the process and shows how the attention masks focus the decoder’s attention to the relevant regions based on the type of prompt.

The figure illustrates the process of perception prior embedding, a strategy to integrate object queries into image features using segmentation priors. It shows how mask scores derived from object queries are used to weight the object queries before adding them to image features, producing pixel-centric visual tokens. These, along with object-centric visual tokens (foreground object queries), are then fed into the LLM.

This figure demonstrates the various capabilities of the OMG-LLaVA model, showcasing its ability to perform pixel-level, object-level, and image-level reasoning and understanding tasks. It highlights the model’s flexibility in handling different types of visual and textual prompts, including descriptions, questions, instructions, and visual prompts, and generating corresponding responses and segmentations. The examples illustrate tasks such as image captioning, grounded conversation, referring and reasoning segmentations, and panoptic segmentation.

This figure demonstrates the versatility of the OMG-LLaVA model in handling various tasks across different levels of image understanding. It showcases examples of pixel-level tasks (semantic and instance segmentation, interactive segmentation), object-level tasks (referring segmentation, reasoning segmentation, region-level captions), and image-level tasks (image captioning, image-level conversations). Each example features the task instruction given to the model and the corresponding result, highlighting the model’s ability to integrate image information, perception priors, and visual prompts to generate accurate and detailed responses.

This figure demonstrates the various tasks that OMG-LLaVA can perform. It showcases examples of pixel-level tasks (e.g., semantic segmentation, reasoning segmentation, interactive segmentation), object-level tasks (e.g., region-level captioning, referring segmentation), and image-level tasks (e.g., image captioning, image-level conversation). The figure highlights OMG-LLaVA’s ability to integrate image, object, and pixel-level information for comprehensive visual understanding and reasoning.

This figure demonstrates the various capabilities of the OMG-LLaVA model. It showcases examples of pixel-level tasks (reasoning segmentation, interactive segmentation), object-level tasks (region-level caption, instance segmentation, referring segmentation), and image-level tasks (image-level caption, image-level conversation, multi-visual prompt description). The figure highlights OMG-LLaVA’s ability to perform a wide range of visual understanding and reasoning tasks across different levels of granularity.

This figure showcases the various tasks that OMG-LLaVA can perform. It highlights the model’s ability to handle tasks at different levels of granularity: pixel-level (semantic segmentation, interactive segmentation, etc.), object-level (referring segmentation, reasoning segmentation, etc.), and image-level (image captioning, image-based conversations, etc.). It demonstrates the model’s versatility and power in understanding and reasoning about images in a comprehensive manner.

This figure showcases the various tasks that OMG-LLaVA can perform across three levels: pixel-level, object-level, and image-level. It demonstrates the model’s ability to handle a wide range of visual understanding and reasoning tasks, including image captioning, visual question answering, referring segmentation, reasoning segmentation, interactive segmentation, and grounded conversation generation. The figure visually represents the comprehensive capabilities of the model, highlighting its capacity to process and interpret visual information at various levels of detail and granularity.

This figure shows an ablation study comparing three different versions of the model. The left image shows the baseline model without any of the proposed improvements. The middle image shows the model with perception prior embedding added, and the right image shows the model with both perception prior embedding and object query input added. This figure demonstrates the improvement in performance that results from adding each of the proposed strategies.

This figure demonstrates the versatility of the OMG-LLaVA model in handling various types of visual understanding and reasoning tasks. It showcases examples of pixel-level tasks (reasoning segmentation, interactive segmentation, semantic segmentation, etc.), object-level tasks (region-level caption, instance segmentation, etc.), and image-level tasks (image-level conversation, image captioning, etc.). The figure highlights OMG-LLaVA’s ability to perform complex tasks that require integrating information from multiple levels of visual representation, demonstrating its comprehensive capabilities.

This figure showcases the various capabilities of the OMG-LLaVA model across different levels of visual understanding and reasoning. It demonstrates its ability to handle pixel-level tasks (such as semantic, instance, and panoptic segmentation), object-level tasks (such as referring and reasoning segmentation, and region-level captioning), and image-level tasks (such as image captioning and conversation). The examples shown highlight the flexibility and diversity of the tasks that OMG-LLaVA is able to perform, emphasizing its unified approach to multimodal reasoning.

This figure showcases the diverse capabilities of the OMG-LLaVA model, highlighting its ability to perform various tasks across different levels of visual understanding. It demonstrates tasks ranging from simple image-level captioning and conversation to complex pixel-level segmentation, object-level reasoning, and region-level captioning. The examples illustrate the model’s capacity to understand user instructions and visual prompts, generating both text and segmentation masks as responses.

This figure showcases the various tasks that OMG-LLaVA can perform. It demonstrates the model’s capabilities across different levels of visual understanding: pixel-level (e.g., semantic and instance segmentation), object-level (e.g., object detection, referring expression segmentation), and image-level (e.g., image captioning, visual question answering). The examples highlight the model’s ability to handle diverse visual and textual prompts, making it a versatile tool for various image understanding applications.

This figure demonstrates the wide range of tasks that OMG-LLaVA can perform. It shows examples across three levels: pixel-level (e.g., semantic and instance segmentation), object-level (e.g., referring segmentation, object-level captioning), and image-level (e.g., image captioning, image-based conversation, visual question answering). The figure highlights OMG-LLaVA’s ability to integrate these different levels of understanding and reasoning into a single, unified framework.

This figure showcases the various capabilities of the OMG-LLaVA model. It demonstrates the model’s ability to perform tasks at three levels: pixel-level (e.g., semantic and instance segmentation), object-level (e.g., object detection and region-level captioning), and image-level (e.g., image captioning and image-based conversation). The examples provided illustrate the model’s flexibility in handling different types of visual prompts and text instructions, demonstrating its comprehensive reasoning and understanding abilities.

This figure demonstrates the various capabilities of the OMG-LLaVA model. It showcases examples of pixel-level tasks (semantic and instance segmentation, reasoning segmentation, interactive segmentation), object-level tasks (region-level caption, visual prompt-based conversation, referring segmentation), and image-level tasks (image caption, grounded conversation generation). The examples highlight the model’s ability to integrate image, object, and pixel-level information for a comprehensive understanding of the visual input and the user’s instructions.

This figure demonstrates the various capabilities of the OMG-LLaVA model by showcasing its performance on different tasks across three levels: pixel-level, object-level, and image-level. It highlights tasks such as reasoning segmentation, referring segmentation, interactive segmentation, region-level captioning, grounded conversation generation, image-level conversation, and image-level captioning. The examples illustrate the model’s ability to understand and respond to various visual and text prompts, demonstrating a comprehensive understanding of images at different granularities.

This figure demonstrates the various tasks that OMG-LLaVA can perform. It showcases the model’s ability to handle pixel-level tasks (like semantic segmentation), object-level tasks (such as referring segmentation), and image-level tasks (like image captioning and visual question answering). The examples illustrate the flexibility of the model in accepting different types of prompts (visual and text) and generating corresponding responses, demonstrating its comprehensive capabilities in bridging image-level, object-level, and pixel-level reasoning and understanding.

This figure demonstrates the versatility of the OMG-LLaVA model in handling various tasks across different levels of image understanding: pixel-level (semantic, instance, panoptic segmentation and interactive segmentation), object-level (object-centric tasks like region-level captioning and referring segmentation), and image-level (image-centric tasks like captioning and image-based conversations). It showcases the model’s ability to reason and answer questions about the image content at various levels of granularity, highlighting its multi-level reasoning capabilities.
This figure shows an ablation study comparing three versions of the OMG-LLaVA model on a referring expression segmentation task. The left image shows the baseline model, the middle image shows the model with perception prior embedding added, and the right image shows the model with both perception prior embedding and object query input. The results demonstrate that adding these components improves the accuracy of segmentation.
More on tables

This table compares the capabilities of various Multimodal Large Language Models (MLLMs) focusing on image-level, object-level, and pixel-level understanding and reasoning. It highlights the unique capabilities of OMG-LLaVA, which achieves comprehensive capabilities with a simpler architecture than comparable models.
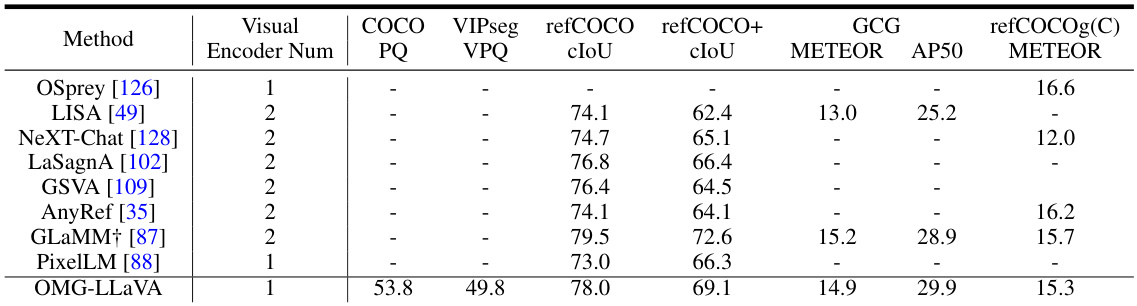
This table compares the performance of OMG-LLaVA against other state-of-the-art multimodal large language models (MLLMs) on various tasks, including pixel-level and object-level understanding and reasoning. It highlights OMG-LLaVA’s comprehensive capabilities, showing its performance on multiple benchmarks (COCO, VIPSeg, refCOCO, refCOCO+, refCOCOg, GCG) and noting the number of visual encoders each model uses. The table also indicates which models used the larger GranD dataset for pre-training.
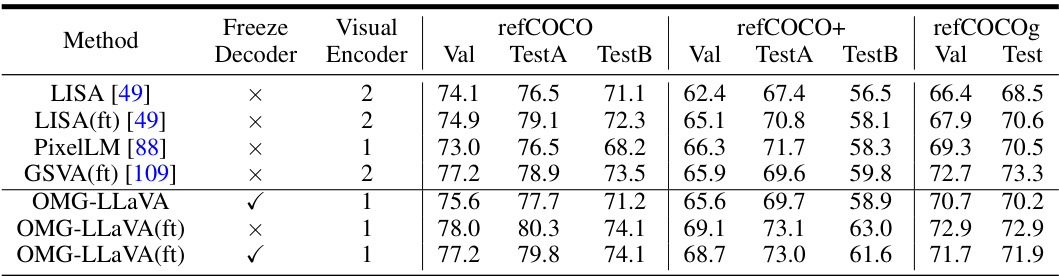
This table presents the performance of different models on three referring expression segmentation datasets: refCOCO, refCOCO+, and refCOCOg. The models’ performance is measured using the cIoU (Intersection over Union) metric. The table also indicates whether the model was fine-tuned (‘ft’) specifically on these datasets, showing the impact of dataset-specific training. A higher cIoU score indicates better performance.

This table compares the performance of different methods on the grounded conversation generation (GCG) task. It shows the METEOR, CIDEr, AP50, and mIOU scores for each method. The ‘ft’ column indicates whether the method was fine-tuned on the GranDf dataset, and the † symbol indicates whether the method used the GranD dataset for pre-training. The results demonstrate the relative performance of OMG-LLaVA and other models on this specific task.

This table presents the ablation study results on the referring expression segmentation (RES) and grounded conversation generation (GCG) datasets. It shows the impact of different modifications to the model architecture (perception prior embedding and object query input) on the performance metrics (cIoU, gIoU, METEOR, mIoU) for both tasks across multiple datasets (refCOCO, refCOCO+, refCOCOg). The results demonstrate how these modifications improve the overall performance of the model.
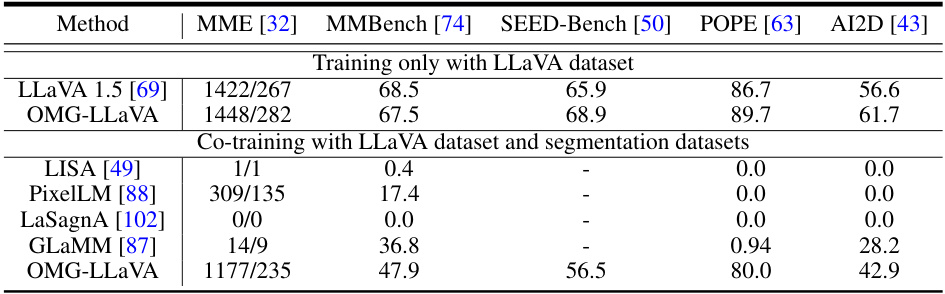
This table compares the capabilities of various Multimodal Large Language Models (MLLMs) focusing on their ability to handle image-level, object-level, and pixel-level tasks. It highlights that OMG-LLaVA stands out by possessing all three levels of understanding and reasoning with a simpler system architecture than its counterparts (e.g., only one visual encoder).

This table compares the performance of OMG-LLaVA using three different LLMs: Phi-3 3.8B, InternLM2-7B, and Qwen2-7B. The performance metrics include cIoU and GIoU for refCOCO and refCOCO+ datasets, perception and reasoning scores for the MME dataset, and various other scores for SEED-Bench, POPE, AI2D, MMStar, and SQA benchmarks. It shows how the choice of LLM affects the overall performance of the OMG-LLaVA model across different tasks and datasets.

This table presents the ablation study results focusing on the vision projector used for object-centric visual tokens. It compares different configurations, including using cross-attention and individual MLPs, and evaluates their impact on various metrics such as cIoU, gIoU, and METEOR across different datasets (refCOCO, refCOCO+, refCOCOg, and refCOCOg(C)). The results show the effect of different projector designs on the model’s performance, helping to understand the contribution of the object-centric visual tokens in the proposed architecture.

This table shows the ablation study results for two different answer formats used in referring expression segmentation (RES) and grounded conversation generation (GCG) tasks. The first row uses a fixed answer format, while the second row uses a more flexible format where the segmentation mask is enclosed within expression tags. The results show the impact of the answer format on the performance metrics (cIoU, gIoU, METEOR, AP50, mIoU).

This table presents the performance of different methods on three referring expression segmentation datasets: refCOCO, refCOCO+, and refCOCOg. The evaluation metric used is the cIoU (Intersection over Union). The table shows the performance with and without fine-tuning (ft) on the referring expression datasets, indicating whether the model was specifically trained for this task or used pre-trained weights.
Full paper#