↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current reinforcement learning models often rely on large, computationally expensive neural networks. This has raised concerns about the environmental and financial costs associated with training and deploying such models. This research aims to address these issues by focusing on energy efficiency.
The proposed method, called Data Adaptive Pathway Discovery (DAPD), aims to identify and train smaller, more efficient sub-networks within a larger neural network, effectively creating “neural pathways”. The researchers evaluate DAPD on several continuous control tasks, demonstrating that these small pathways can achieve performance comparable to much larger models using less than 5% of the parameters. They showcase this in both online and offline settings and also successfully demonstrate training multiple pathways within the same network for solving multiple tasks concurrently. This significantly reduces the energy consumed during training and inference.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers striving for energy-efficient AI. It introduces a novel method to discover sparse, yet high-performing neural networks, significantly reducing computational costs and carbon footprint. The findings are highly relevant to current sustainability concerns in the AI field and open new research avenues for optimization techniques and hardware design.
Visual Insights#
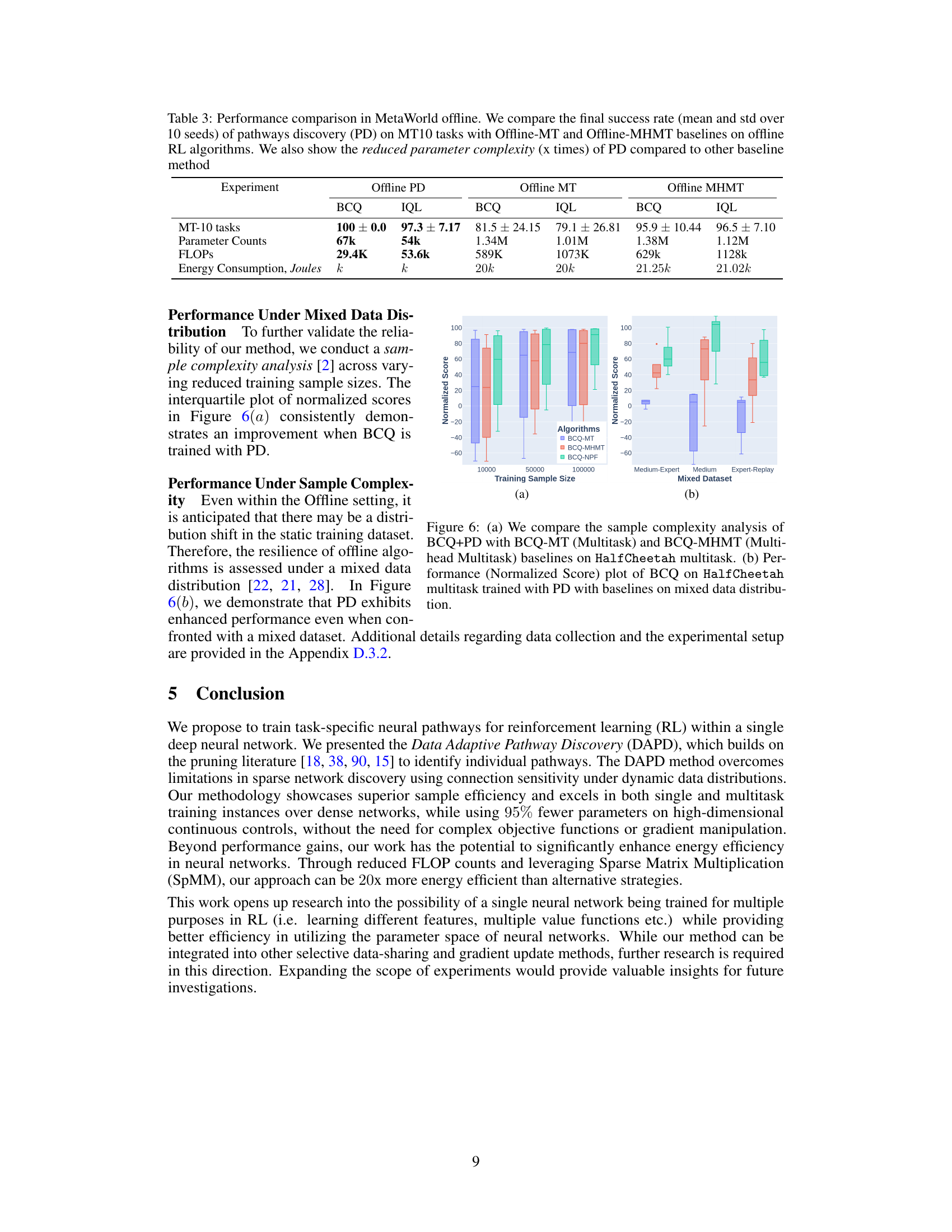
This figure illustrates the core concept of the proposed method. For each task, a specific subset of the neural network’s weights (a neural pathway) is activated. The rest of the network is essentially masked off, making the process more efficient. The figure shows multiple tasks (Task 1 to Task N), each with its own pathway, all sharing the same underlying network. A ‘Mask’ is used to select the active pathway for each task, separating the tasks and potentially saving computational resources.

This table compares the performance of the proposed Data Adaptive Pathway Discovery (DAPD) method against several baseline methods on four different continuous control tasks from the MuJoCo simulator. The comparison is made at 95% sparsity, meaning that only 5% of the network’s parameters are used. The average episodic return is calculated over the last 10 evaluation episodes across 5 different random seeds, after 1 million training steps. The baseline methods include standard SAC with a dense network (SAC-Dense), RiGL, and RLx2.
In-depth insights#
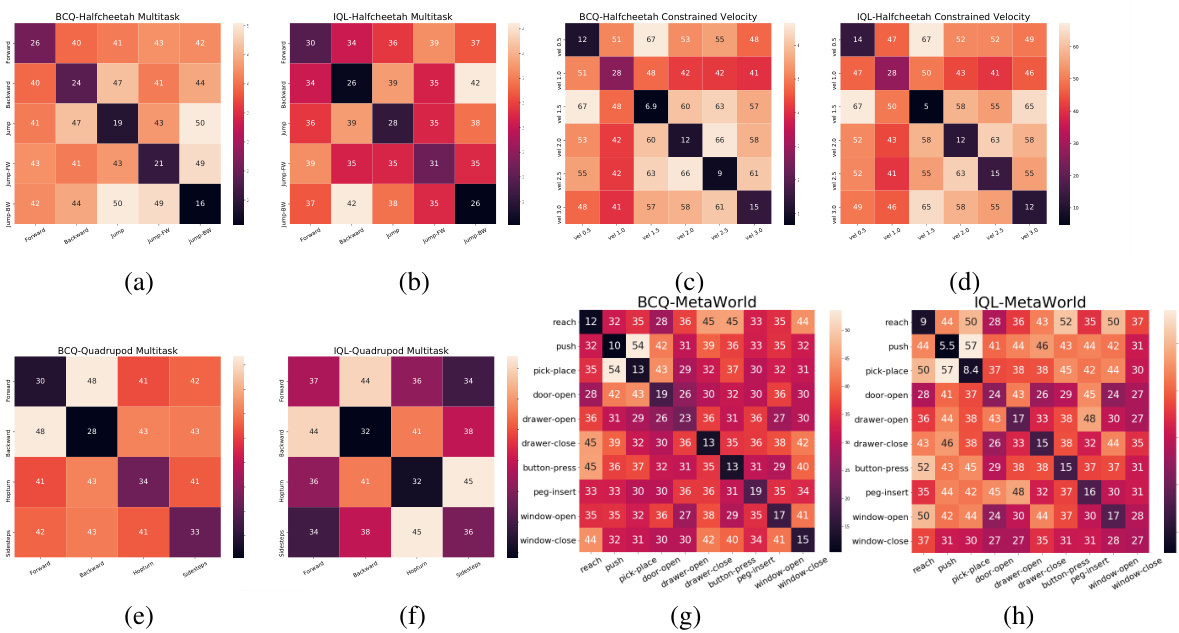
Sparse Network RL#
Sparse Network RL explores the intersection of sparse neural networks and reinforcement learning. By employing sparse networks, which only use a small fraction of the total possible parameters, this approach aims to reduce computational costs and energy consumption associated with training large models. This is particularly crucial in reinforcement learning, where training can be computationally expensive and environmentally taxing. The core idea is to identify and train only the most relevant connections within a larger network, effectively creating “neural pathways” for efficient learning. This approach not only offers efficiency but also potentially improves sample efficiency and generalization. Data Adaptive Pathway Discovery (DAPD), proposed in the paper, is a key innovation, allowing for the dynamic adaptation of the sparse network during training to overcome challenges associated with data distribution shifts in online reinforcement learning. However, challenges remain, including addressing limitations concerning sparsity levels and the ability to maintain performance across diverse tasks and environments. Further research might investigate the theoretical guarantees for convergence, explore the impact of different sparsity levels on various RL algorithms and evaluate the effectiveness of DAPD in real-world applications. The overall goal is to develop more sustainable and efficient reinforcement learning agents.
Pathways Discovery#
The core concept of “Pathways Discovery” within the research paper revolves around identifying and training sparse sub-networks, or neural pathways, within a larger neural network for enhanced efficiency in reinforcement learning. The method aims to address the computational and environmental costs associated with large models, a critical aspect often overlooked. This is achieved by strategically selecting a small subset of the network’s parameters to form specialized pathways for each task, rather than training an entire, overparameterized network. Key to this is the discovery process itself, determining which connections are vital and eliminating unnecessary ones. The paper explores both online and offline adaptations of pathway discovery, highlighting the crucial role of data distribution in achieving successful training, especially in online scenarios. This innovative approach holds significant potential for reducing energy consumption and carbon footprint associated with large-scale deep learning model training, making the method suitable for deployment in resource-constrained environments.
Multi-task RL#
The heading ‘Multi-task RL’ in the context of a research paper likely refers to the application of reinforcement learning (RL) techniques to scenarios involving multiple tasks. This presents significant challenges compared to single-task RL due to gradient interference, where the updates for different tasks might conflict, hindering overall learning. The paper likely explores various strategies to address this issue, such as constraining gradient updates, modularizing the network to share components across tasks, or exploiting task similarities to better coordinate learning. A key focus might involve the efficiency of multi-task learning and the potential to reduce computational costs, environmental impact, or other resource constraints. Different approaches for finding optimal network architectures that efficiently handle multiple tasks might be compared and contrasted. In essence, this section would delve into novel methods designed to make multi-task RL more efficient and scalable, and potentially address problems of catastrophic forgetting if the tasks are learned sequentially. The discussion would likely involve a detailed analysis of various algorithms, their performance in different multi-task environments, and comparisons to single-task RL baselines.
Energy Efficiency#
The research paper significantly emphasizes energy efficiency as a crucial factor in the development and deployment of reinforcement learning models. It highlights the substantial environmental and financial costs associated with training large neural networks. The core idea revolves around discovering sparse sub-networks, termed ’neural pathways,’ within a larger network to achieve comparable performance with drastically reduced computational needs. This approach focuses on improving both sample efficiency and energy efficiency by using a much smaller fraction of parameters than traditional dense networks. The authors demonstrate significant energy savings in both online and offline settings across various multitask continuous control scenarios. Furthermore, sparse matrix multiplication (SpMM) is suggested as an efficient technique to further enhance energy efficiency and facilitate model deployment on low-resource devices. Overall, the paper strongly advocates for a more sustainable approach to RL by prioritizing model efficiency without compromising solution quality, promoting environmentally responsible AI. The exploration of this approach opens up interesting avenues for future research in resource-constrained applications.
Future Work#
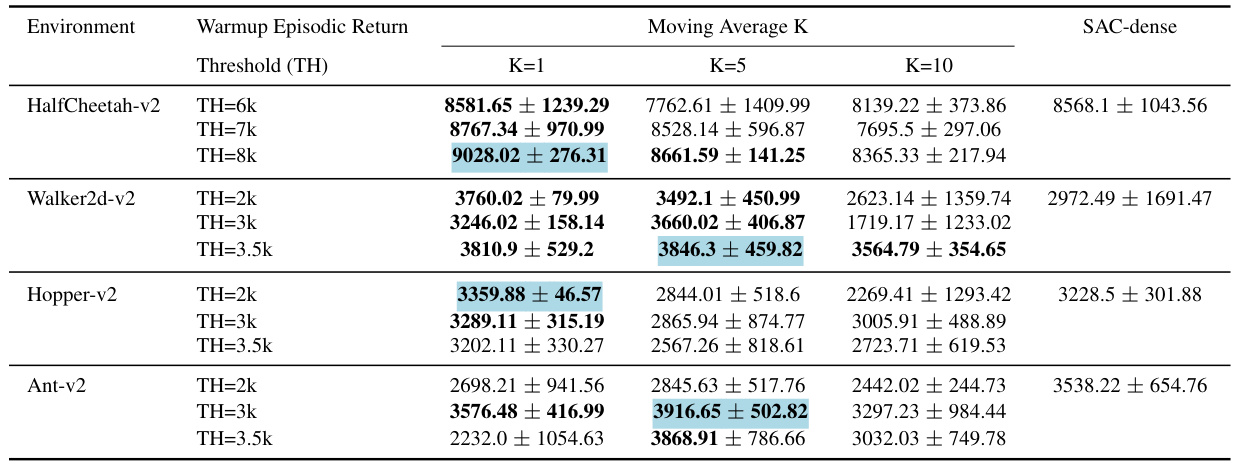
The authors mention several avenues for future research. Extending the scope of experiments to a wider variety of tasks and environments is crucial to validate the generalizability of the proposed method. Investigating the impact of different network architectures and training paradigms on pathway discovery is also important. Exploring the theoretical underpinnings of pathway convergence and its relationship to the underlying network structure is a significant challenge warranting further investigation. Developing more sophisticated methods for addressing gradient interference in multi-task settings is key to improving performance. Lastly, the integration of DAPD with other multi-task learning techniques is essential to fully exploit the potential of this approach. This involves exploring various optimization strategies and architectural designs to achieve even greater efficiency.
More visual insights#
More on figures
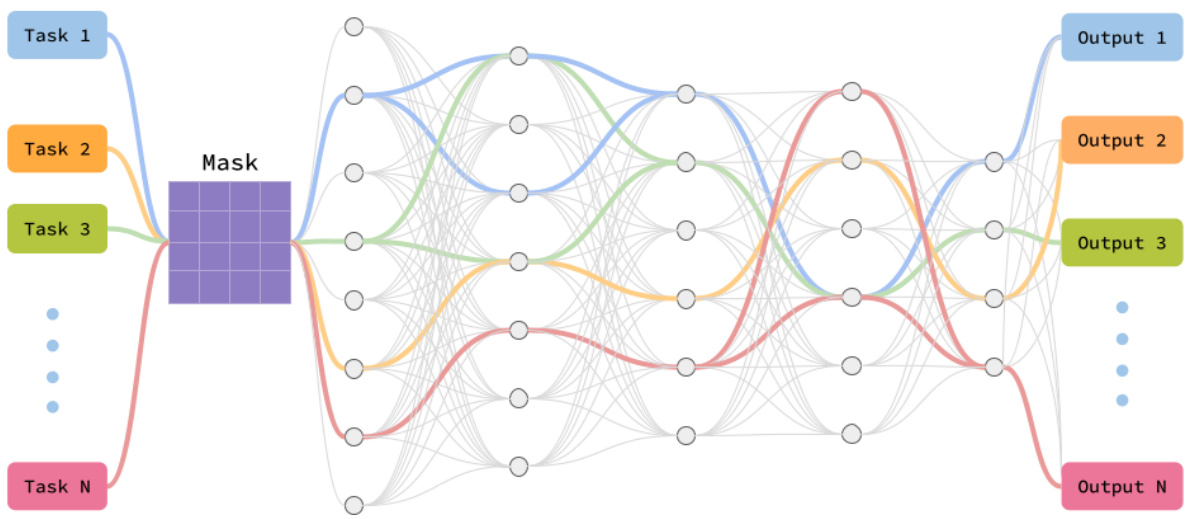
This figure compares the performance of the proposed Data Adaptive Pathway Discovery (DAPD) method with several baseline methods for a single-task online reinforcement learning experiment on the HalfCheetah-v2 environment. Subfigure (a) shows the learning curves of the different algorithms, illustrating their progress over 1 million gradient updates at a sparsity level of 95%. Subfigure (b) displays the final episodic return achieved by each algorithm across a range of sparsity levels (70% to 95%), highlighting the impact of sparsity on performance. Finally, subfigure (c) presents an ablation study of the DAPD method, demonstrating the importance of the warmup and freeze phases in its efficacy.

This figure compares the performance of the proposed Data Adaptive Pathway Discovery (DAPD) method against several baseline methods on the HalfCheetah-v2 continuous control task. Subfigure (a) shows learning curves illustrating the episodic return over training steps. (b) shows how performance varies with different sparsity levels and (c) presents ablation studies showing impact of different components of the DAPD method.

This figure compares the performance and energy consumption of different multi-task reinforcement learning algorithms on the MetaWorld benchmark. The performance is normalized to highlight the trade-off between performance gain and energy consumption. SAC-DAPD shows a significant improvement in energy efficiency compared to other methods while maintaining competitive performance.
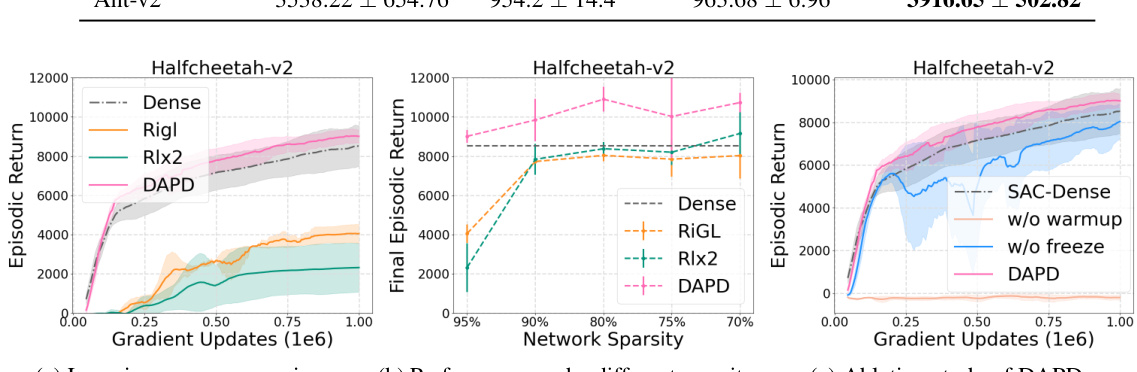
This figure compares the sample complexity and performance robustness of BCQ with pathway discovery (BCQ+PD) against multi-task (BCQ-MT) and multi-head multi-task (BCQ-MHMT) baselines under different conditions. Panel (a) shows a boxplot comparing performance across varying training sample sizes. Panel (b) presents a boxplot showing robustness to different data distributions (Medium-Expert Mix, Medium, Expert-Replay). The results illustrate that BCQ+PD exhibits superior sample efficiency and better resilience to distributional shift than the other baselines.
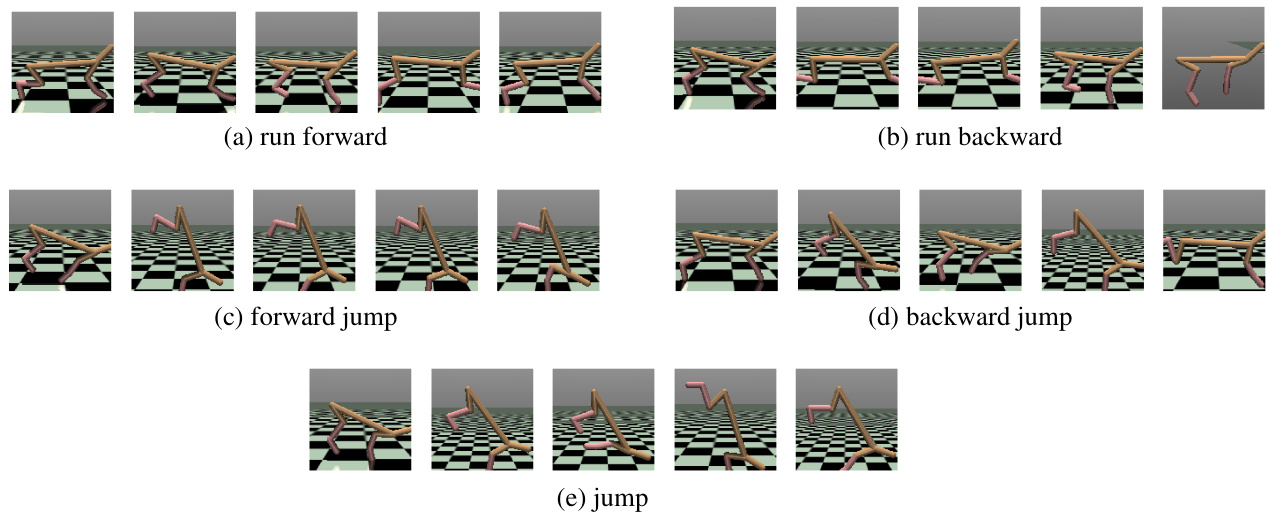
The figure shows a series of snapshots of a trained HalfCheetah agent performing five different tasks: running forward, running backward, performing a forward jump, performing a backward jump, and simply jumping. Each sequence of images displays a series of poses from the agent’s movements during each task. This figure serves to visually illustrate the diverse capabilities of the trained model for various locomotion tasks.

This figure shows the performance of a trained policy for the HalfCheetah environment under four different constrained velocities (0.5, 1.0, 2.0, and 3.0). Each subfigure displays a sequence of images showing the HalfCheetah’s movement at a specific velocity. The images illustrate how the trained policy adapts its movements to achieve the desired velocity while maintaining stability and control.

This figure shows a series of snapshots from a trained policy for a quadrupedal robot performing four different tasks: (a) pace forward, (b) pace backward, (c) hopturn, and (d) sidestep. Each row represents one of the four tasks, and each column shows a frame from a short video sequence of the robot executing that task. This visualization helps to illustrate the robot’s learned behaviors for each task.

This figure shows snapshots of the ten different tasks included in the MetaWorld MT10 benchmark. The tasks involve a robotic arm manipulating objects in a variety of ways, such as reaching for an object, pushing an object, picking and placing objects, opening doors and drawers, pressing buttons, inserting pegs, and opening and closing windows. These tasks represent a diverse set of challenges in robotic manipulation and are used to evaluate the performance of multi-task reinforcement learning algorithms.

This figure shows the results of an experiment designed to investigate the existence of multiple equally effective lottery sub-networks in online reinforcement learning. After an initial warm-up phase where the mask is periodically adjusted, three different sub-networks are sampled. A Venn diagram illustrates the overlap between these sub-networks and the previous sub-network from the warm-up phase. The close similarity of learning curves in the three sampled sub-networks supports the idea that multiple equally effective solutions exist within the overall network, supporting the lottery ticket hypothesis.

The figure shows a comparison of the learning curves for RiGL and Rlx2 at different sparsity levels (90%/75% and 95%/95%). The results highlight that RiGL and Rlx2 perform poorly at 95% sparsity, unlike the proposed DAPD method.

This figure compares the performance of the proposed Data Adaptive Pathway Discovery (DAPD) method with three other baseline methods (SAC-Dense, RiGL, and Rlx2) on four different MuJoCo continuous control tasks. The sparsity level is fixed at 95%, meaning only 5% of the network parameters are used. The y-axis represents the episodic return (a measure of performance), and the x-axis represents the number of gradient updates (a measure of training progress). The figure shows the learning curves for each method across the four tasks, illustrating DAPD’s superior performance and stability compared to the baselines.

This figure compares the performance of the proposed Data Adaptive Pathway Discovery (DAPD) method with other baseline methods (SAC-Dense, RiGL, and Rlx2) on four different MuJoCo continuous control tasks (HalfCheetah-v2, Walker2d-v2, Hopper-v2, and Ant-v2). The results are shown as learning curves for each task at a sparsity level of 95%. The x-axis represents the number of gradient updates, and the y-axis represents the average episodic return over 10 evaluations across different seeds. The figure demonstrates that DAPD consistently outperforms the baseline methods in terms of final episodic return.

This figure compares the sample efficiency of a 95% sparse network trained using the Data Adaptive Pathway Discovery (DAPD) method against a dense SAC network. The results show that the DAPD method achieves comparable or better performance than the dense network, even with significantly fewer parameters, across multiple continuous control tasks (HalfCheetah-v2, Walker2d-v2, Hopper-v2, and Ant-v2). This suggests that the DAPD method is more sample efficient and potentially requires less training data to achieve good results.

The figure demonstrates the concept of lottery tickets in online reinforcement learning. After an initial warm-up phase, the algorithm identifies multiple sub-networks (pathways) within a larger network that achieve similar performance. The Venn diagram illustrates the overlap in parameter space between these sub-networks, supporting the hypothesis that many equally effective sub-networks exist.
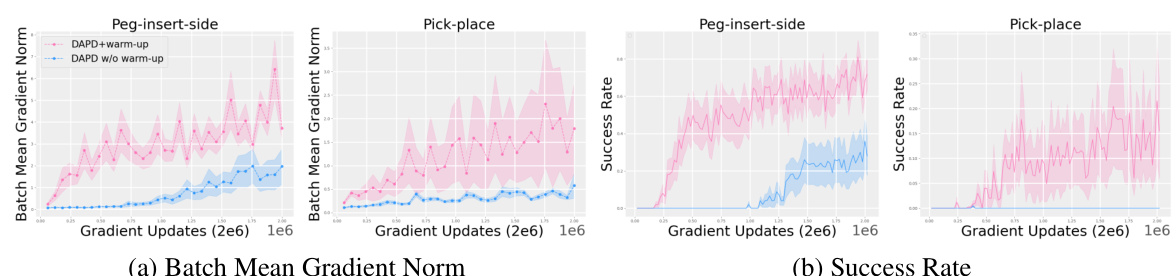
This figure shows the batch mean gradient norm and success rate for two MetaWorld tasks (Peg-insert-side and Pick-place) with and without a warm-up phase in the DAPD algorithm. The results indicate that the warm-up phase significantly improves the learning process and ultimately enhances performance.

This figure compares the sample efficiency of a 95% sparse neural network trained using the Data Adaptive Pathway Discovery (DAPD) method to a dense network, both using Soft Actor-Critic (SAC). The x-axis represents the number of training steps, and the y-axis represents the average episodic return. The plot shows that even with significantly fewer parameters, the DAPD method achieves comparable or better performance than the dense network, demonstrating superior sample efficiency.

The figure compares the sample efficiency of a 95% sparse network trained using the proposed Data Adaptive Pathway Discovery (DAPD) method against a dense SAC network across four MuJoCo continuous control tasks (HalfCheetah-v2, Walker2d-v2, Hopper-v2, and Ant-v2). The plots show the average episodic return over 10 evaluations and 5 random seeds at various training steps (250k, 500k, 750k, and 1M). It demonstrates that DAPD achieves comparable or better performance with significantly fewer parameters, showcasing its improved sample efficiency.
This figure illustrates the core concept of the proposed method, which involves activating specific sub-networks (neural pathways) within a larger neural network for different tasks. Each task utilizes a unique pathway, represented by the different colored nodes and connections. The mask indicates which parts of the network are activated for a specific task.
More on tables

This table presents a performance comparison of the proposed Data Adaptive Pathway Discovery (DAPD) method against several baseline algorithms on four different single-task continuous control environments from the MuJoCo simulator. The comparison focuses on the average episodic return achieved over the final 10 evaluation episodes after 1 million training steps, with results averaged across 5 different random seeds. The sparsity level is fixed at 95% for all methods except for the SAC-Dense baseline (which uses the full network).

This table compares the performance of SAC-DAPD with other baselines on the MetaWorld 10 benchmark. It shows the success rate (percentage of tasks successfully completed), the number of parameters, the number of floating point operations (FLOPs), and the estimated energy consumption for each method. The results highlight the efficiency of SAC-DAPD in terms of reduced parameters and energy consumption while maintaining competitive performance compared to other methods.

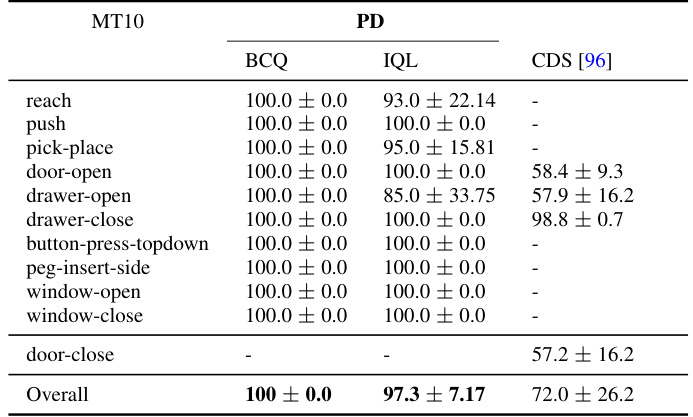
This table compares the performance of the proposed Data Adaptive Pathway Discovery (DAPD) method against several baselines on the MetaWorld MT10 benchmark for offline reinforcement learning. It shows the success rate (mean and standard deviation over 10 seeds) for each method. It also highlights the reduced parameter counts, FLOPs (floating-point operations), and energy consumption of DAPD compared to the baselines, demonstrating its efficiency.

This table presents a comparison of the proposed Data Adaptive Pathway Discovery (DAPD) method against several baseline algorithms in single-task reinforcement learning experiments using MuJoCo continuous control environments. The comparison focuses on the average episodic return achieved over the last 10 evaluation episodes, averaged over 5 different random seeds, after 1 million training steps. The sparsity level for all methods is fixed at 95%, meaning only 5% of the network parameters are used. The baselines include a dense network (SAC-Dense), RiGL, and RLx2.

This table presents a comparison of the proposed Data Adaptive Pathway Discovery (DAPD) method with several baseline algorithms on four continuous control tasks from the MuJoCo simulator. The comparison focuses on performance at 95% sparsity (meaning only 5% of the network parameters are used). The average episodic return over the final 10 evaluations across 5 different random seeds is reported for each algorithm and task after 1 million training steps. This allows for an assessment of the relative performance of DAPD compared to other approaches at a high level of sparsity.
This table presents a comparison of the proposed Data Adaptive Pathway Discovery (DAPD) method with several baseline algorithms for single-task reinforcement learning using MuJoCo continuous control environments. The performance metric used is the average episodic return over the final 10 evaluation episodes, averaged across 5 different random seeds. The table shows the results for four different environments (HalfCheetah-v2, Walker2d-v2, Hopper-v2, and Ant-v2) and demonstrates the relative performance of DAPD compared to baseline methods (SAC-Dense, RiGL, and RLx2) at a high sparsity level of 95%.

This table presents a comparison of the proposed Data Adaptive Pathway Discovery (DAPD) method against several baseline methods for single-task reinforcement learning using continuous control environments from MuJoCo. The comparison focuses on the average episodic return achieved after 1 million training steps, considering the last 10 evaluations and averaging results across 5 different random seeds. The sparsity level is fixed at 95% for all methods except the ‘SAC-Dense’ baseline, which represents a fully connected network. This table highlights the performance improvement of DAPD over other sparse training methods and also shows its comparative performance versus a dense network.

This table compares the performance of the proposed Data Adaptive Pathway Discovery (DAPD) method with several baseline methods on four different MuJoCo continuous control tasks. The comparison is done at 95% sparsity, meaning that only 5% of the network parameters are used. The table shows the average episodic return over the last 10 evaluation episodes, averaged over 5 different random seeds, after 1 million training steps. The baselines include a standard dense SAC network (SAC-Dense), RiGL, and RLx2. The results demonstrate the effectiveness of DAPD in achieving comparable or better performance than the dense model while using significantly fewer parameters.

This table presents the results of single-task experiments conducted using MuJoCo continuous control environments. The experiments compare the performance of the proposed Data Adaptive Pathway Discovery (DAPD) method against several baseline algorithms at 95% sparsity. The metric used for comparison is the average episodic return over the final 10 evaluations, averaged across 5 different random seeds. Each experiment was run for 1 million training steps.

This table presents a comparison of the proposed Data Adaptive Pathway Discovery (DAPD) method against several baseline methods in single-task reinforcement learning experiments using MuJoCo continuous control environments. The comparison focuses on the average episodic return achieved after 1 million training steps across 5 different random seeds, considering only the last 10 evaluation episodes for each seed. The table highlights DAPD’s performance relative to a dense network (SAC-Dense) and two existing sparse training methods (RiGL and Rlx2) at a sparsity level of 95%.
This table presents the results of offline multi-task reinforcement learning experiments on the MetaWorld MT10 benchmark. It compares the success rate (averaged over 10 seeds) of the proposed Data Adaptive Pathway Discovery (DAPD) method against two baseline methods: Offline MT (a single dense network for multiple tasks) and Offline MHMT (multiple independent heads on a dense network). It also shows the significant reduction in the number of parameters achieved by DAPD compared to the baselines.

This table compares the average episodic return of the DAPD method with other baselines (SAC-Dense, RiGL, and Rlx2) across four different MuJoCo continuous control tasks (HalfCheetah-v2, Walker2d-v2, Hopper-v2, and Ant-v2). All methods were tested at a 95% sparsity level. The results are averaged over the last 10 evaluation episodes and across 5 different random seeds, after training for 1 million steps.

This table compares the average episodic return of the DAPD method with several baseline methods (SAC-Dense, RiGL, and Rlx2) across four different MuJoCo continuous control tasks (HalfCheetah-v2, Walker2d-v2, Hopper-v2, and Ant-v2). The experiments were conducted with a network sparsity of 95%, meaning only 5% of the network parameters were used. The results are averaged over the last 10 evaluations and 5 random seeds after 1 million training steps.
Full paper#