↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Federated learning (FL) often assumes continuous client availability, which is unrealistic. Existing FL algorithms struggle with communication efficiency and data heterogeneity under more practical, periodic participation patterns. These algorithms either rely on unrealistic assumptions or fail to achieve both linear speedup and reduced communication rounds, particularly in non-convex settings.
This paper introduces Amplified SCAFFOLD, a novel algorithm that addresses these issues. It uses amplified updates and long-range control variates to achieve linear speedup, reduced communication, and robustness to data heterogeneity simultaneously, even under periodic and non-i.i.d. client participation. The theoretical analysis supports these claims, showcasing its effectiveness over existing methods in non-convex settings, particularly for cyclic participation, where it outperforms previous best communication round complexity. Experimental results using real-world and synthetic datasets further validate its effectiveness.
Key Takeaways#
Why does it matter?#
This paper is crucial for Federated Learning (FL) researchers as it tackles the critical issue of communication efficiency and data heterogeneity in realistic scenarios with periodic client participation. The proposed Amplified SCAFFOLD algorithm significantly reduces communication rounds compared to existing methods, offering a more practical approach to FL. Its implications are far-reaching and pave the way for more efficient and robust FL systems.
Visual Insights#

This figure shows the comparison of the performance of different federated learning algorithms on synthetic data and CIFAR-10 dataset. The left panel shows that both Amplified SCAFFOLD and SCAFFOLD reach the global minimum, but Amplified SCAFFOLD is significantly faster. The right panel shows that Amplified SCAFFOLD achieves the best results compared to other methods, while FedAvg and FedProx perform similarly and poorly.
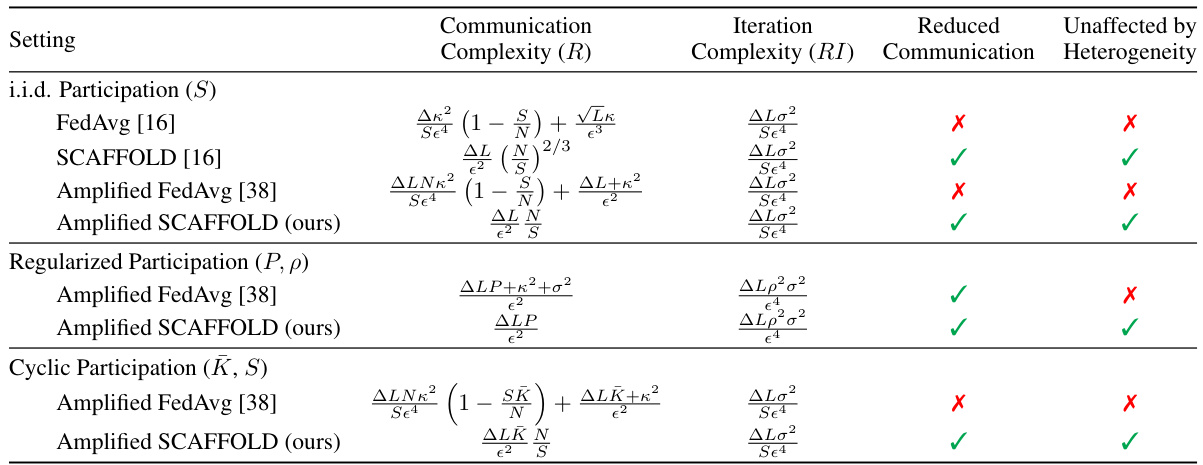
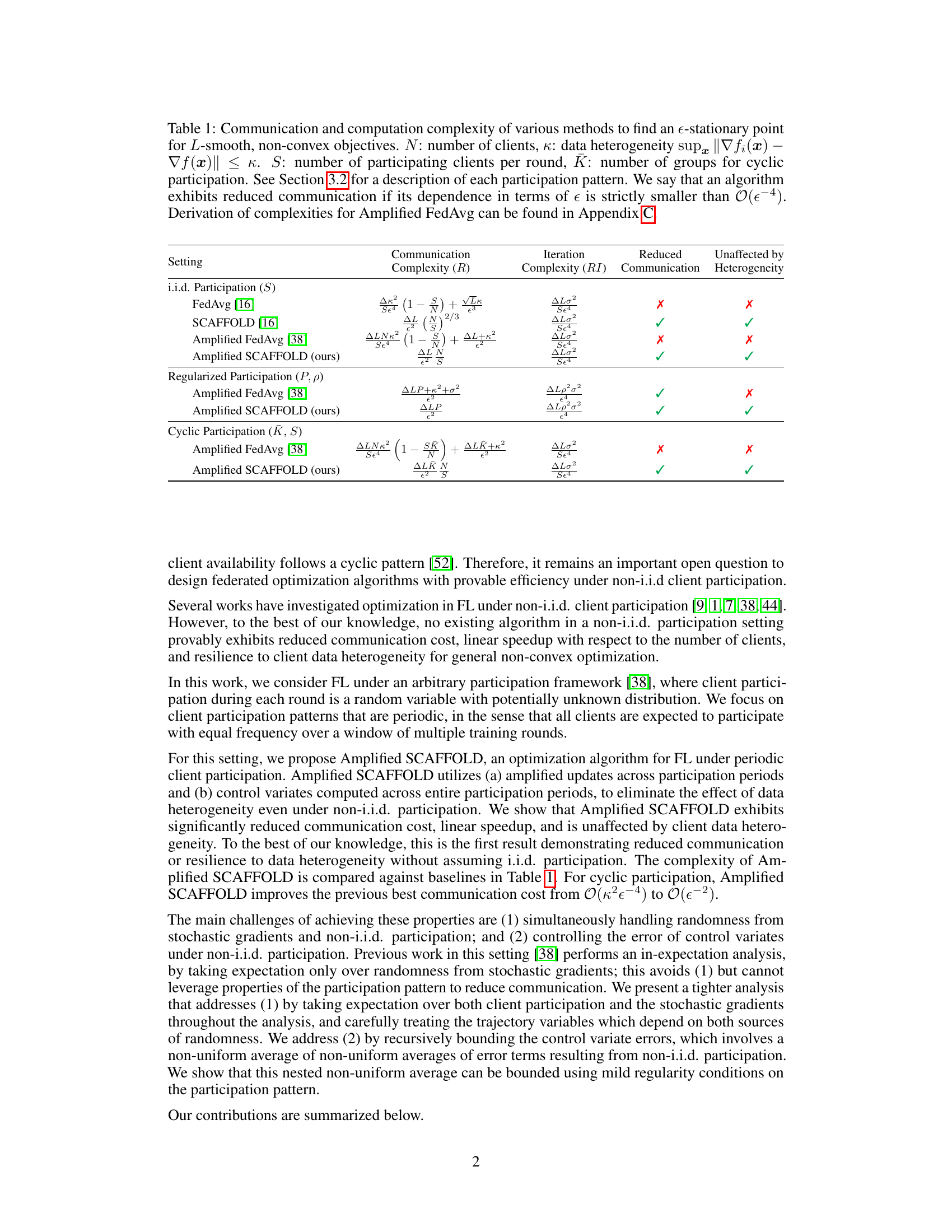
This table compares the communication and computation complexities of different federated learning algorithms in achieving an ϵ-stationary point for non-convex objectives. It considers three scenarios for client participation: i.i.d. (independent and identically distributed), regularized (clients participate almost surely within a fixed window), and cyclic (clients participate in rounds). The table shows the complexity in terms of the number of clients (N), data heterogeneity (κ), number of participating clients per round (S), and number of groups in cyclic participation (K). The ‘Reduced Communication’ column indicates whether the algorithm’s complexity improves over the naive O(ϵ⁻⁴) bound. The ‘Unaffected by Heterogeneity’ column indicates whether the algorithm’s complexity is independent of the data heterogeneity.
In-depth insights#
Periodic FL#
Periodic Federated Learning (FL) addresses the practical limitations of continuous client availability in traditional FL. Instead of assuming constant participation, periodic FL models scenarios where clients periodically join and leave the training process. This mirrors real-world situations where devices might have intermittent connectivity or limited battery life. Research in this area focuses on developing algorithms that are robust to these interruptions, maintaining convergence despite the inconsistent participation of clients. Key challenges involve designing effective strategies to aggregate updates from clients that participate at different times, and ensuring that the learning process is not significantly hampered by periods of inactivity. The goal is to achieve efficiency in communication and computation, while still guaranteeing convergence and accuracy. Current research explores different participation patterns (cyclic, arbitrary) and proposes algorithms that leverage control variates or amplified updates to handle the non-uniformity in data contributions. Provable convergence guarantees under various non-i.i.d. data heterogeneity assumptions are a significant focus of ongoing research. Overall, periodic FL seeks to bridge the gap between theoretical models and the realities of deploying FL systems in real-world settings.
Amplified Updates#
Amplified updates represent a crucial strategy in federated learning (FL) algorithms designed to handle the challenges posed by intermittent client participation and data heterogeneity. The core idea is to scale the updates from a group of clients across multiple rounds or epochs, mitigating the adverse effects of infrequent or inconsistent participation. This scaling factor often amplifies the impact of each participant, ensuring that their contribution isn’t lost in the noise of irregular availability. This is particularly important in scenarios with non-i.i.d. data, where the distribution of data varies significantly across clients. Amplified updates help reduce the bias introduced by the uneven availability of clients and help achieve faster convergence by effectively utilizing all data available across all clients. The amplification factor is usually carefully tuned or adapted to ensure convergence. The effectiveness of amplified updates ultimately depends on the design of the specific algorithm, particularly in how it interacts with other techniques like control variates, which help compensate for the effects of noisy and heterogeneous data.
Control Variates#
Control variates are a crucial technique in variance reduction, particularly valuable in settings with high variance, such as those encountered in stochastic optimization. They aim to reduce the variance of an estimator by leveraging the correlation between the estimator and other variables whose expectations are known. In federated learning, where the heterogeneity of local data distributions and the intermittent participation of clients introduce substantial noise, control variates offer a powerful mechanism for enhancing the stability and speed of convergence. The effectiveness of control variates hinges on the accuracy of the control variate estimates and their correlation with the target variable. The selection of appropriate control variates is crucial and often problem-specific, requiring a deep understanding of the underlying data distribution and training dynamics. The Amplified SCAFFOLD algorithm presented incorporates long-range control variates, meaning these estimates are computed across entire periods of client participation rather than at each individual step. This approach proves particularly beneficial in handling the non-stationarity of periodic client availability, thereby improving the reliability and efficiency of the overall estimation process. However, accurate estimation of long-range control variates becomes increasingly challenging with growing levels of data heterogeneity. Therefore, a fine-grained analysis of these errors, including an in-depth treatment of the nested dependencies between client participation and control variate errors, is necessary to derive tight theoretical guarantees. The improved convergence rates achieved in the paper showcase the significant potential of sophisticated control variate strategies in addressing the challenges of federated learning under realistic participation patterns.
Heterogeneity Robustness#
The concept of “Heterogeneity Robustness” in federated learning addresses the challenge of effectively training a shared model across diverse client datasets exhibiting varying data distributions. A robust algorithm should mitigate the negative impact of data heterogeneity, preventing performance degradation or model bias. This robustness is crucial because real-world federated learning scenarios often involve non-i.i.d. data, where clients’ local datasets are not independently and identically distributed (i.i.d.). Key aspects of achieving heterogeneity robustness include algorithmic design choices that reduce the dependence on data heterogeneity, such as the use of control variates or variance reduction techniques. Analysis demonstrating robustness typically involves bounding the impact of heterogeneity in convergence proofs. Amplified SCAFFOLD, for example, showcases this property. Empirical evaluations on real-world datasets, including experiments with varying degrees of data heterogeneity, are also essential to validate a model’s heterogeneity robustness claims. The experimental validation section should include sufficient detail to reproduce the results. This includes data preprocessing, hyperparameter selection, evaluation metrics, and analysis of the results under different heterogeneity levels.
Future Directions#
Future research could explore several promising avenues. Extending the algorithm to handle more complex participation patterns, such as those with time-varying probabilities or dependencies between client availability, would enhance real-world applicability. Investigating the algorithm’s robustness under different levels of data heterogeneity and exploring adaptive strategies to handle unknown or non-stationary distributions are key areas for improvement. Developing theoretical guarantees for non-convex settings beyond the current framework would further strengthen the theoretical foundation. Finally, empirical evaluation on a broader range of real-world datasets and across diverse application domains will validate its effectiveness and identify potential limitations. The impact of network dynamics and communication constraints on convergence is another area deserving further attention.
More visual insights#
More on figures

This figure shows the experimental results for a synthetic objective function and the CIFAR-10 dataset. The left panel compares the convergence speed of five different federated learning algorithms: FedAvg, FedProx, SCAFFOLD, Amplified FedAvg, and Amplified SCAFFOLD. It demonstrates that Amplified SCAFFOLD converges to the global minimum significantly faster than the other algorithms, especially SCAFFOLD, while FedAvg and FedProx show very similar performance. The right panel focuses on the CIFAR-10 dataset and highlights the superior performance of Amplified SCAFFOLD in achieving the best solution compared to the other algorithms.
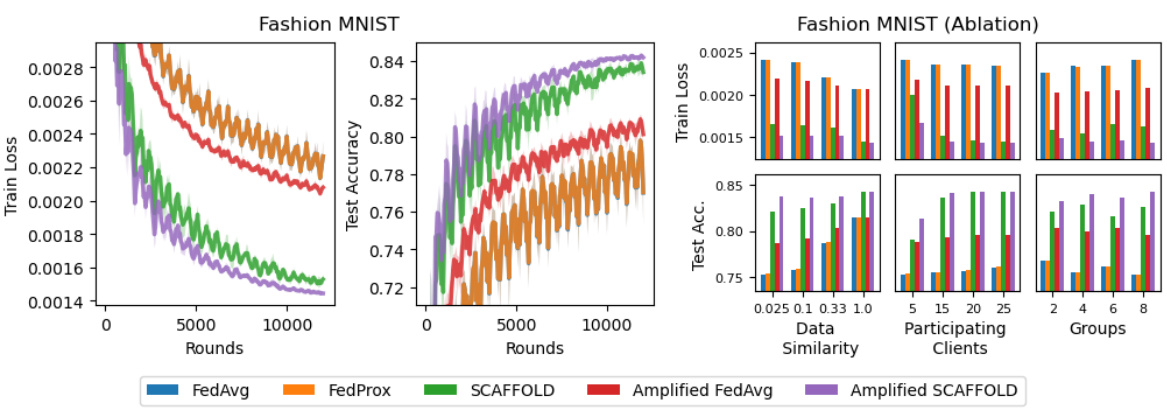
The left panel shows the training and testing performance of five algorithms on the Fashion-MNIST dataset. Amplified SCAFFOLD converges faster than other algorithms and achieves the lowest loss and highest accuracy. The right panel shows ablation studies where data heterogeneity, number of participating clients per round, and number of client groups are varied to test the robustness of the five algorithms. Amplified SCAFFOLD consistently achieves the best performance across all settings.
The left plot shows the training loss and test accuracy for different federated learning algorithms on the Fashion-MNIST dataset. Amplified SCAFFOLD demonstrates superior performance compared to baselines (FedAvg, FedProx, SCAFFOLD, Amplified FedAvg). The right plot illustrates the robustness of Amplified SCAFFOLD to variations in data heterogeneity (data similarity), number of participating clients per round, and number of client groups in a cyclic participation pattern. Amplified SCAFFOLD consistently achieves the best solution across these variations.
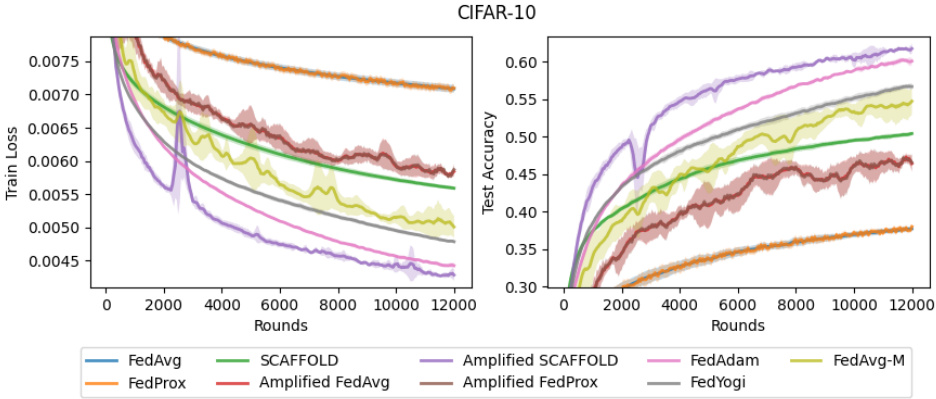
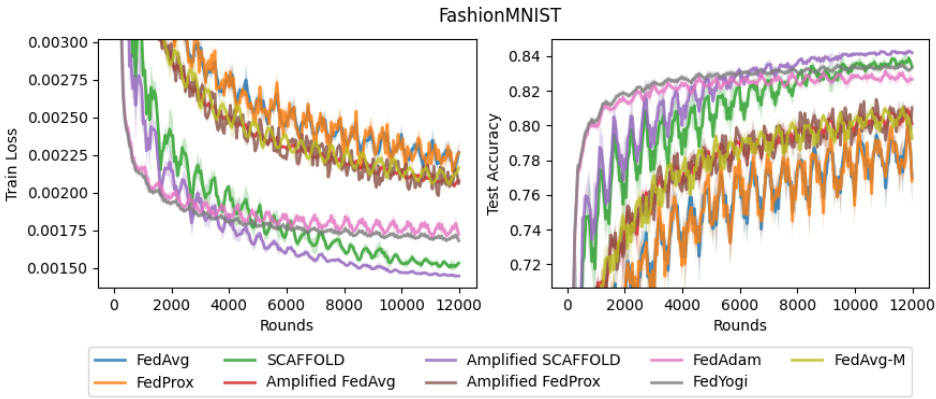
This figure shows the results of training a CNN on CIFAR-10 with nine different federated learning algorithms. The algorithms include five algorithms from the main paper (FedAvg, FedProx, SCAFFOLD, Amplified FedAvg, Amplified SCAFFOLD), and four additional baselines (FedAdam, FedYogi, FedAvg-M, and Amplified FedProx). Amplified SCAFFOLD consistently achieves the best performance (lowest training loss and highest test accuracy). FedAdam shows competitive performance, while the other algorithms show significantly worse performance. The results highlight the superior performance of Amplified SCAFFOLD compared to existing baselines in terms of convergence speed and final accuracy.

This figure shows the training loss and test accuracy for different federated learning algorithms on the CIFAR-10 dataset under a stochastic cyclic availability client participation pattern. The x-axis represents the number of communication rounds, and the y-axis shows the training loss (left panel) and test accuracy (right panel). Nine different algorithms are compared, including FedAvg, FedProx, SCAFFOLD, Amplified FedAvg, Amplified SCAFFOLD, Amplified FedProx, FedAdam, FedYogi, and FedAvg-M. The results demonstrate that Amplified SCAFFOLD consistently achieves the lowest training loss and highest test accuracy, converging significantly faster than other algorithms.
Full paper#