↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current transformer-based methods for reinforcement learning struggle with the quadratic complexity of attention mechanisms, especially when dealing with long-term dependencies. This makes them computationally expensive for long-horizon tasks. The Mamba model, known for its efficient processing of long-term dependencies, offers a potential solution.
This paper proposes Decision Mamba-Hybrid (DM-H), a novel method that combines Mamba and transformer models. DM-H leverages Mamba to generate high-value sub-goals from long-term memory, which are then used to prompt the transformer for high-quality predictions. The results demonstrate that DM-H achieves state-of-the-art performance on various benchmark tasks while being significantly faster than transformer-based baselines. This shows the effectiveness of combining Mamba and transformers for solving long-term RL problems.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in reinforcement learning (RL) and sequence modeling because it introduces a novel hybrid model (DM-H) that significantly improves the efficiency and effectiveness of in-context RL for long-term tasks. This addresses a major limitation of current transformer-based approaches, paving the way for more efficient and powerful RL agents.
Visual Insights#
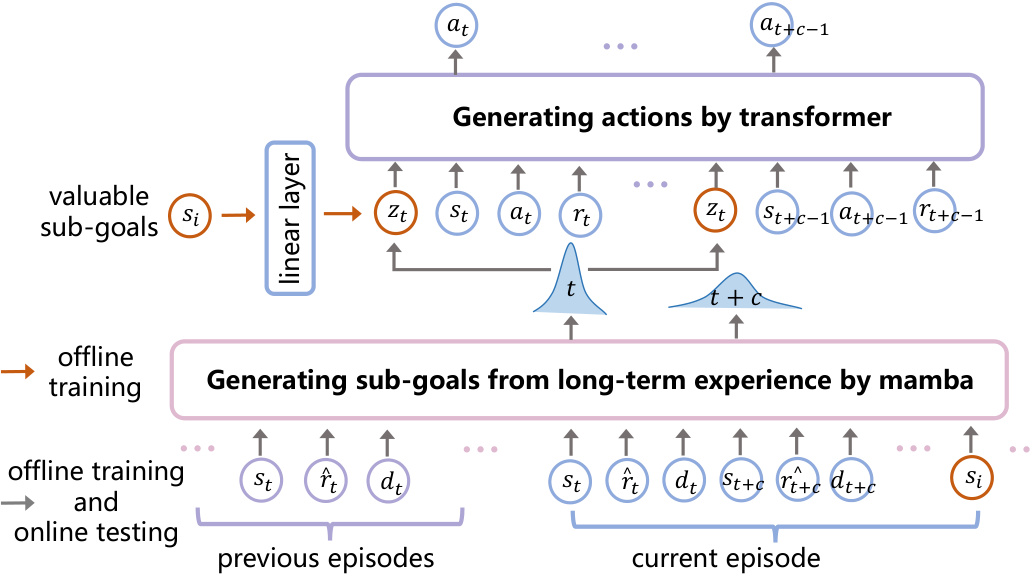
This figure illustrates the architecture of the Decision Mamba-Hybrid (DM-H) model. The model consists of two main components: a Mamba module for processing long-term dependencies and a Transformer module for generating high-quality predictions. During offline training, the Mamba module extracts valuable sub-goals from historical trajectories. These sub-goals are then fed into the Transformer module along with short-term context, allowing the model to make better predictions. The linear layer combines the sub-goals with transformer output. During online testing, DM-H uses the learned model to generate actions and improves its performance iteratively without needing gradient updates.

This table compares the performance of Mamba and Transformer models on several D4RL datasets. It shows the effectiveness (average return) and efficiency (training time in hours) for both models across different datasets and environment variations (Med-Expert, Medium, Med-Replay). The results highlight that while Transformer models generally achieve higher effectiveness, Mamba models demonstrate significantly improved efficiency, indicating a trade-off between performance and computational cost.
In-depth insights#
Mamba’s RL Prowess#
An exploration of “Mamba’s RL Prowess” would delve into the unique capabilities of the Mamba model within the reinforcement learning (RL) domain. Mamba’s inherent ability to process long sequences with linear computational complexity offers a significant advantage over transformer-based approaches, which struggle with the quadratic complexity of attention mechanisms in long-horizon tasks. The core question becomes how Mamba’s efficiency translates into effectiveness: Does this efficiency come at the cost of performance? A key insight would examine the trade-offs between speed and accuracy. The hybrid approach of combining Mamba with transformers, a potential strategy, warrants careful analysis. How does the synergy between Mamba’s long-term memory and the transformer’s precision impact RL agent performance? This analysis should look at various benchmarks, considering both short and long-term tasks and sparse-reward environments. The evaluation should go beyond simple performance metrics, measuring sample efficiency and generalization ability to understand the full impact of Mamba’s architecture on RL.
Hybrid Model Fusion#
A hybrid model fusion approach in a research paper would likely involve combining the strengths of different models to improve performance. The key is identifying models with complementary strengths and weaknesses. For example, one model might excel at capturing short-term dependencies while another is adept at long-term contextual understanding. The fusion method would need to be carefully designed, as a naive combination might not yield significant benefits and could even harm performance. Effective fusion strategies often involve weighting the outputs of individual models or using more sophisticated techniques like ensemble methods or attention mechanisms. These strategies could be trained using data-driven approaches to learn the optimal weighting scheme or attention maps. The success of such a fusion heavily depends on several factors including the types of models being integrated, the quality of data available for training, and the skill in designing an effective fusion strategy. Evaluation metrics should assess the improvement achieved by fusion against individual models to justify the added complexity. It is also important to discuss potential challenges, such as computational cost or potential overfitting and how these challenges were addressed.
Long-Term Context#
The concept of “Long-Term Context” in the provided research paper is crucial for effective decision-making, especially in reinforcement learning scenarios. The challenge lies in efficiently processing and utilizing information from past experiences that are temporally distant. Traditional methods struggle with the quadratic complexity of attention mechanisms in transformer models when dealing with extensive sequences. This necessitates novel approaches to selectively model and retain relevant past information. The paper addresses this by proposing a hybrid model that combines the strengths of transformers for high-quality prediction and Mamba for its ability to handle long sequences efficiently. Mamba’s linear computational cost is a significant advantage over transformer’s quadratic complexity, enabling it to extract valuable sub-goals from long-term contexts, thereby informing the transformer’s decision-making process. The integration of high-value sub-goals from the Mamba model acts as a form of structured memory recall, focusing the transformer’s attention on the most critical aspects of the past experience. This hybrid approach aims to balance effectiveness in capturing the essence of long-term interactions with efficiency, a substantial improvement over existing methods that struggle with computational limitations for tasks with extended time horizons.
DM-H Efficiency#
The efficiency of DM-H, a hybrid model combining Mamba and transformer architectures for reinforcement learning, is a key advantage. DM-H leverages Mamba’s linear time complexity for processing long sequences, significantly reducing computational costs compared to transformer-only baselines, especially in long-horizon tasks. This efficiency stems from Mamba’s data-dependent selection mechanism, contrasting with the quadratic complexity of transformer attention. The paper highlights a 28x speedup in online testing compared to transformer-based approaches on long-term tasks. However, the efficiency gains aren’t uniform across all tasks. While superior in long-term scenarios, Mamba’s efficiency advantage might diminish in shorter tasks where the computational cost of the transformer is less dominant. The choice of hyperparameter ‘c’, determining the frequency of Mamba’s sub-goal generation, also impacts efficiency. Smaller ‘c’ values increase the frequency, potentially affecting the balance between long-term memory recall (Mamba’s strength) and short-term contextual prediction (transformer’s strength), thus impacting the overall efficiency. Further investigation of the optimal ‘c’ value for different task types would refine understanding of DM-H’s efficiency profile.
Future of DM-H#
The future of Decision Mamba-Hybrid (DM-H) looks promising, building upon its demonstrated success in long-term reinforcement learning. Improving efficiency further is a key area; while DM-H significantly outperforms baselines in speed, exploring more efficient attention mechanisms or alternative architectures could enhance performance even more, particularly for extremely long sequences. Extending DM-H to more complex environments with richer state spaces and more nuanced reward functions is crucial for broader applicability. Addressing the sensitivity to hyperparameters, specifically the ‘c’ parameter which controls the interplay between Mamba and the transformer, is vital for robust deployment across various tasks. Research into methods for automatic or adaptive tuning of ‘c’ could substantially increase DM-H’s usability. Finally, investigating the theoretical underpinnings of DM-H’s success is a significant research avenue. A deeper theoretical understanding could help guide improvements, inform the design of novel architectures, and allow for more reliable generalization to unseen tasks.
More visual insights#
More on figures

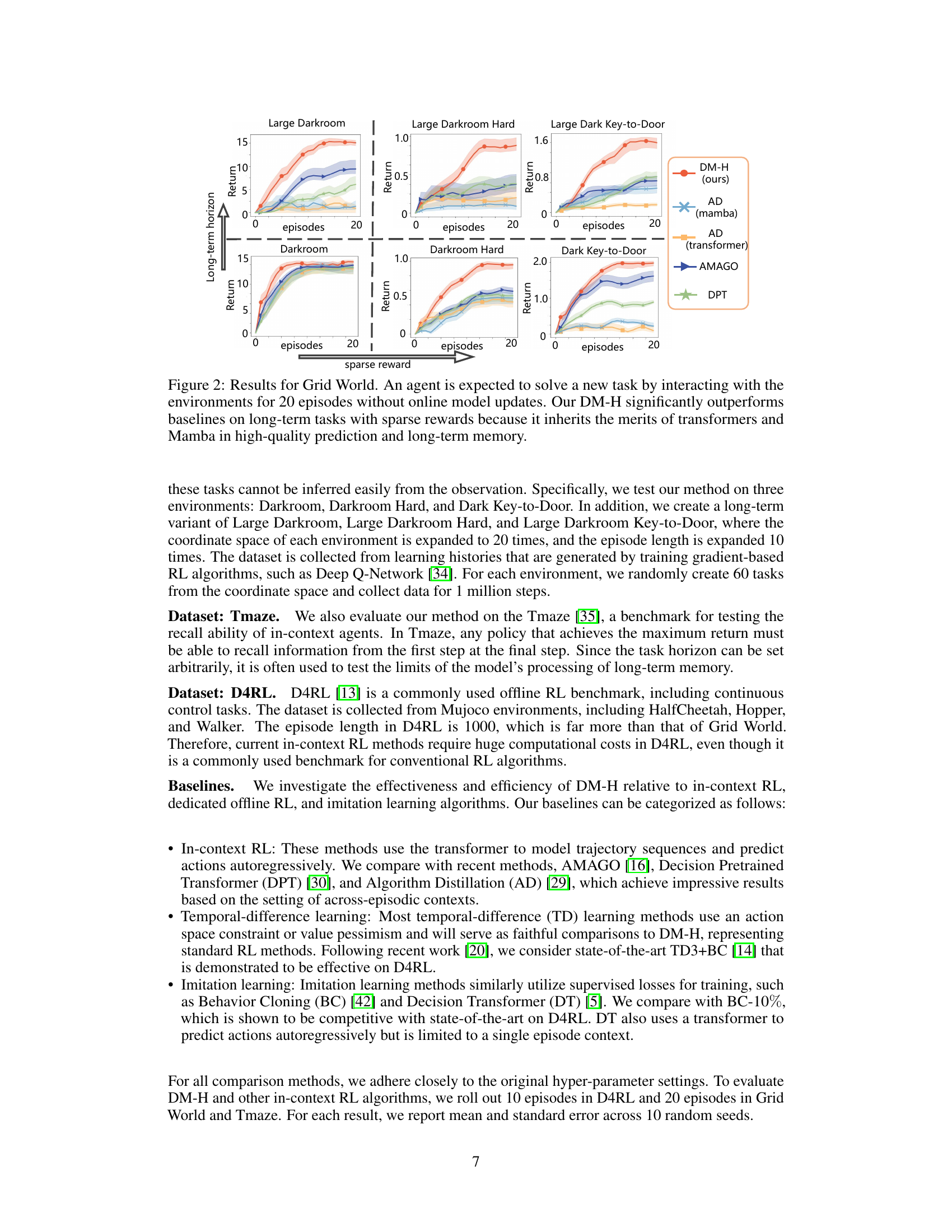
This figure presents the results of the Grid World experiments, comparing DM-H’s performance against other baselines. The experiments tested the ability of different agents to solve unseen tasks within a limited number of episodes (20), without any online model updates. The results show that DM-H significantly outperforms the baselines, particularly in long-term tasks with sparse rewards. This superiority is attributed to the hybrid approach of DM-H combining the strengths of transformers for high-quality predictions and Mamba for efficient long-term memory processing.
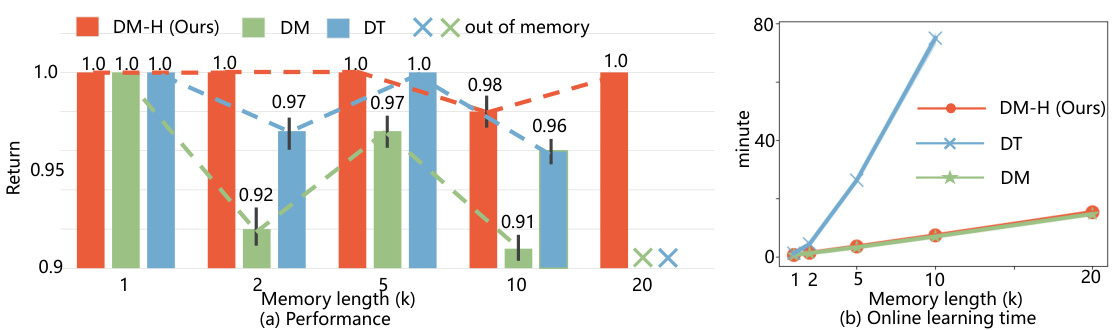
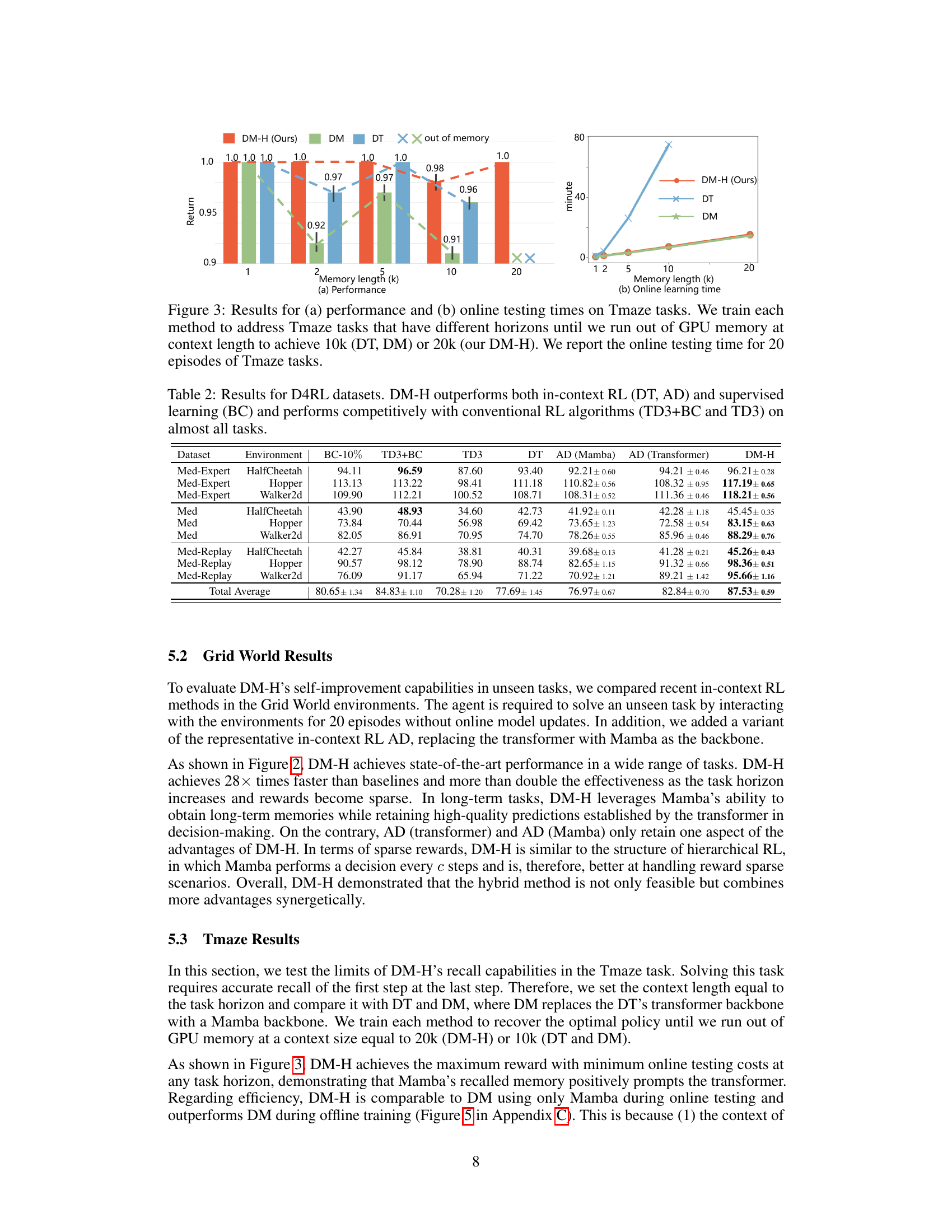
This figure shows the performance and online testing time for the Tmaze task using three different methods: DM-H (ours), DM, and DT. The x-axis represents the memory length (k), which is the length of the context. The left subplot (a) displays the average return (performance) for each method as memory length increases. DM-H outperforms DM and DT, maintaining high performance even with longer memory lengths. The right subplot (b) shows the online learning time for each method; DM-H is significantly faster than both DM and DT as the memory length increases. The figure demonstrates the efficiency and effectiveness of DM-H for the Tmaze task.
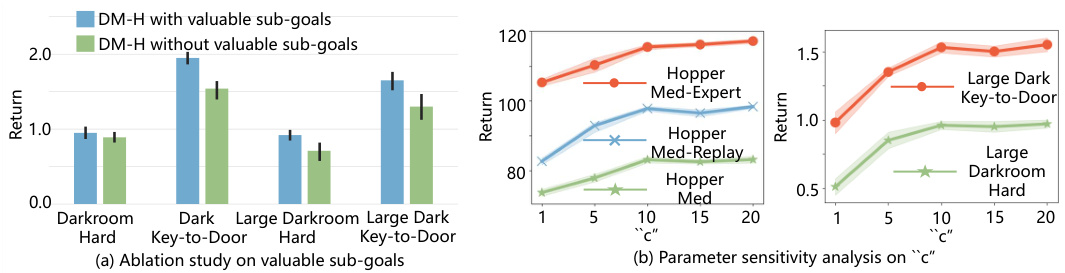
The figure presents the results of two experiments. In (a), an ablation study compares the performance of the Decision Mamba-Hybrid (DM-H) model with and without valuable sub-goals. The results are shown for several GridWorld tasks, demonstrating the benefit of incorporating valuable sub-goals. In (b), the parameter sensitivity analysis explores how changing the hyperparameter ‘c’ (which controls the number of steps of actions for one sub-goal) impacts DM-H’s performance. The results are shown for several D4RL tasks, illustrating the range of ‘c’ that yields good performance.
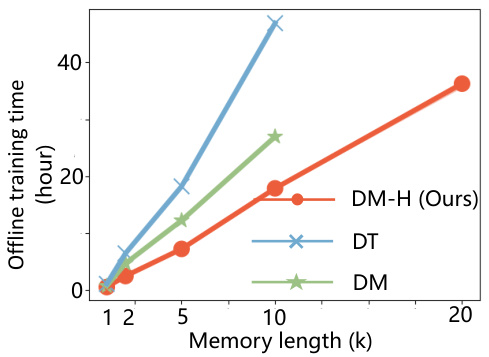
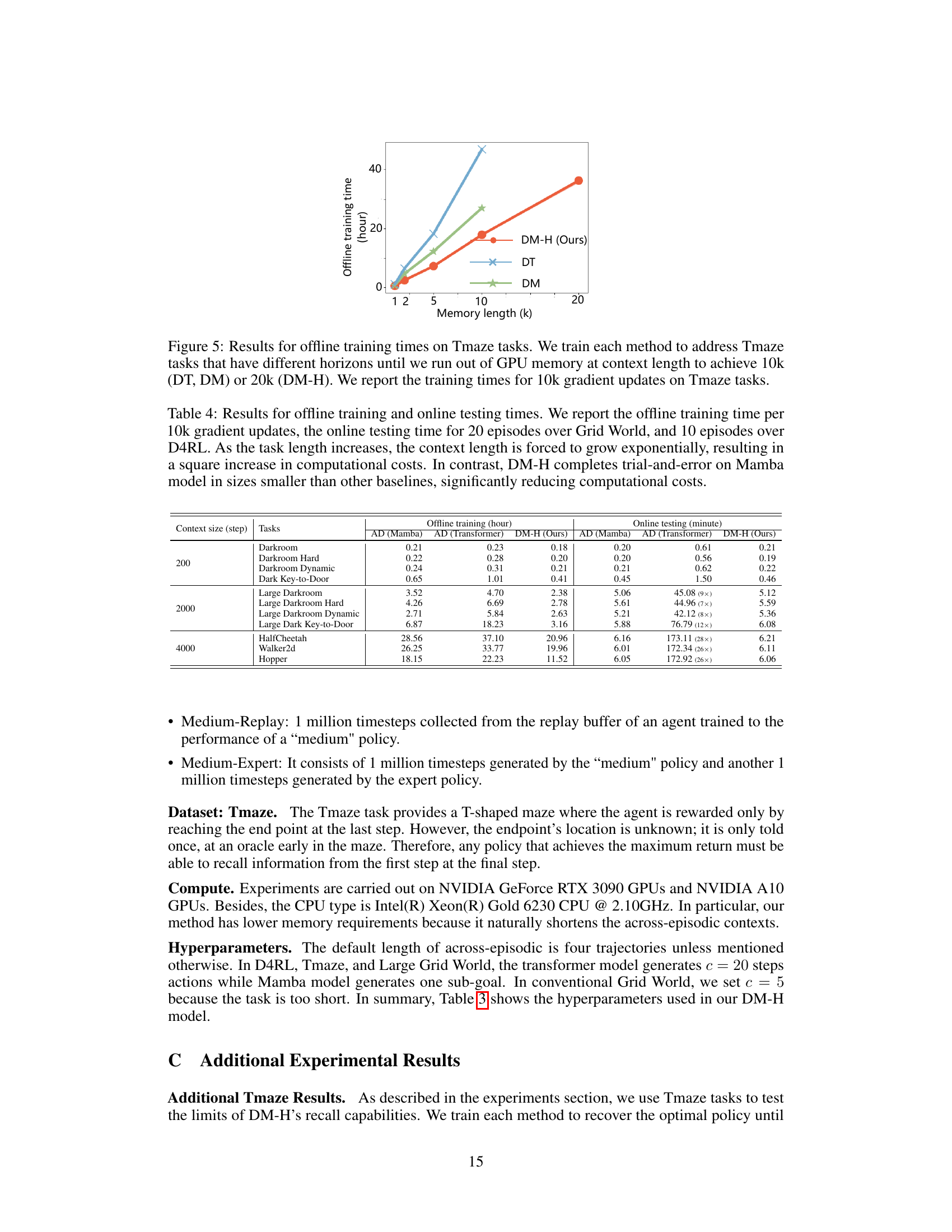
This figure shows the offline training time for different methods (DM-H, DT, and DM) on Tmaze tasks with varying memory lengths. It highlights the efficiency gains of DM-H, which scales more favorably with increasing memory length (task horizon) compared to DT and DM, likely due to the inherent linear time complexity of Mamba.
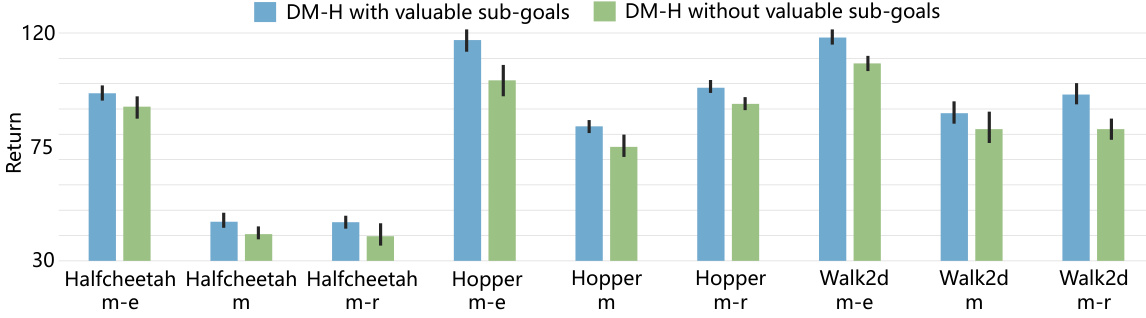
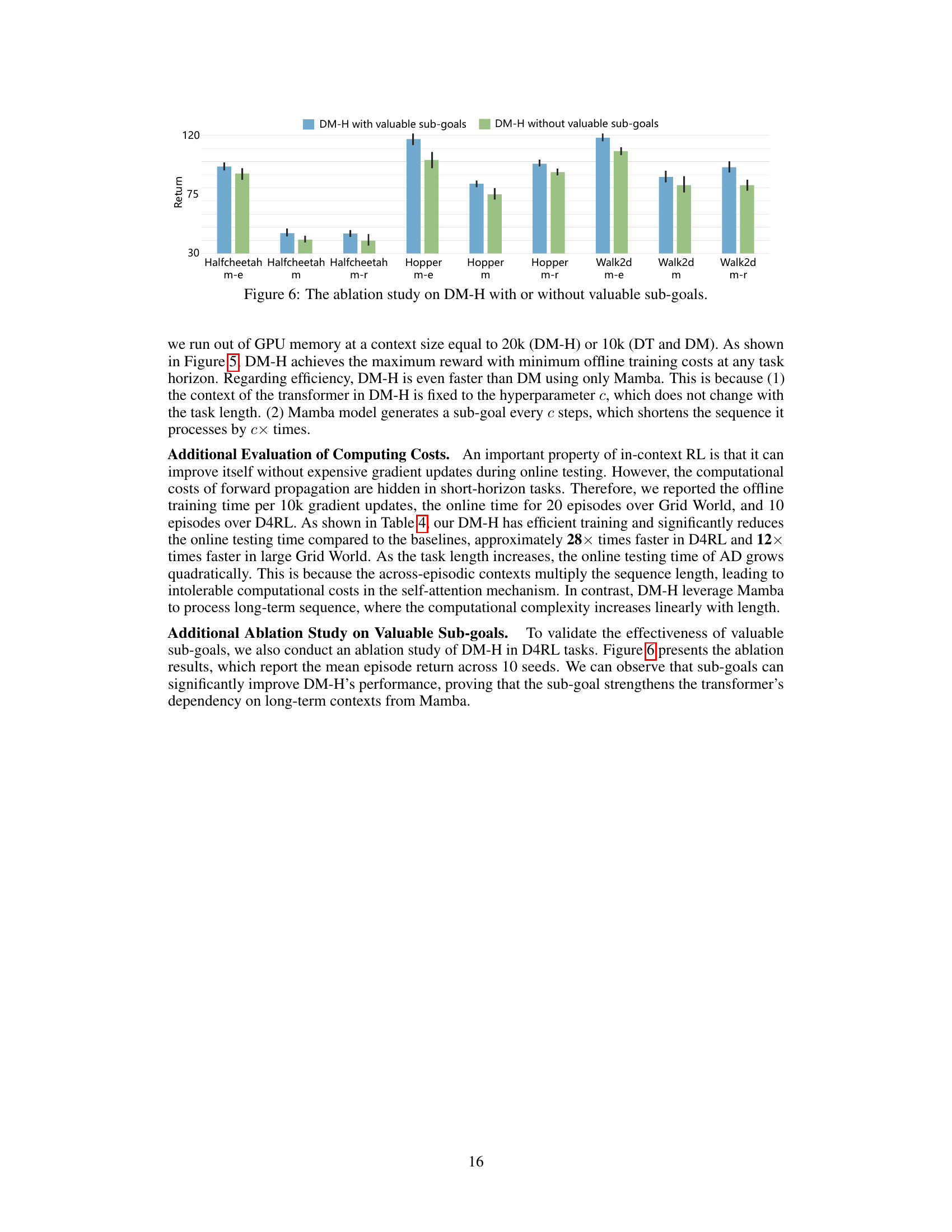
This figure shows the ablation study comparing the performance of Decision Mamba-Hybrid (DM-H) model with and without valuable sub-goals. The results are presented for three different D4RL environments (HalfCheetah, Hopper, Walker2d) and three different dataset variations (m-e: medium-expert, m: medium, m-r: medium-replay). Each bar represents the average return, and error bars indicate standard deviation across multiple runs. The comparison demonstrates the significant positive impact of incorporating valuable sub-goals in improving DM-H’s performance across various settings.
More on tables
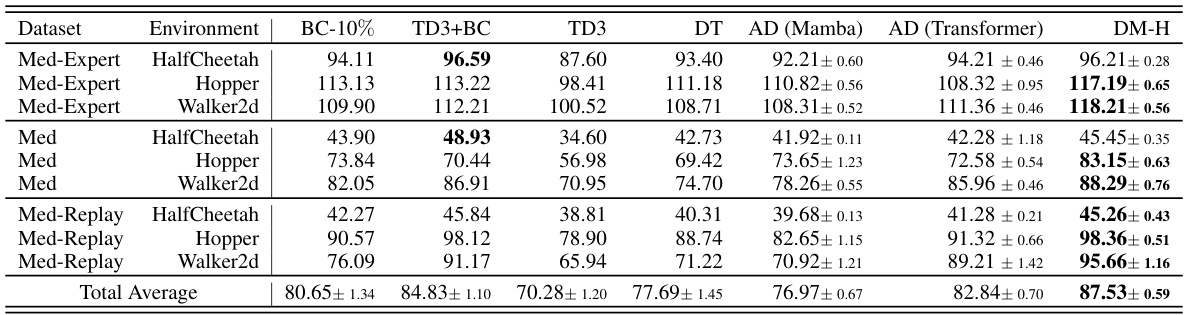
This table compares the performance of Mamba and Transformer models on several D4RL datasets. It shows the effectiveness (average return) and efficiency (training time in hours) of each model across different environments and dataset variations (Med-Expert, Med, Med-Replay). The results demonstrate that while Transformer models generally achieve higher effectiveness, Mamba models offer significantly improved efficiency.

This table compares the performance of Mamba and Transformer models on various D4RL datasets. It shows the effectiveness (average return) and efficiency (training time in hours) of both models across different datasets and difficulty levels (e.g., Med-Expert, Medium, Med-Replay). The results indicate that while Transformers show slightly better effectiveness, Mamba offers significantly improved efficiency, especially for complex datasets.
This table compares the performance of Mamba and Transformer models on several D4RL datasets, measuring both effectiveness (the average return achieved) and efficiency (the training time in hours). The results show that while the Transformer model generally achieves higher returns, the Mamba model offers significantly faster training times.

This table compares the performance of Mamba and Transformer models on several D4RL datasets. It shows both effectiveness (average return) and efficiency (training time in hours) for each model on different datasets and reward settings (Medium, Med-Expert, Med-Replay). The results indicate that while Transformer models generally exhibit higher effectiveness, Mamba models offer significantly better efficiency, particularly when considering training time.
Full paper#