↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Accurately inferring 3D structure and camera poses from a limited set of images is a challenging problem in computer vision. Traditional methods often struggle with sparse views, where the available information is insufficient for reliable estimation. This leads to errors in both 3D reconstruction and pose estimation, hindering applications that rely on precise 3D understanding. This paper introduces SparseAGS, a novel method that tackles this issue by integrating generative priors and a robust outlier removal process.
SparseAGS leverages analysis-by-synthesis and incorporates generative priors to improve the quality of the inferred 3D and camera poses. The use of generative priors helps to constrain the solution space, preventing overfitting to noisy or incomplete data. The method also explicitly addresses outliers (images with significant errors in pose estimation), iteratively identifying and correcting them to improve overall accuracy. Experiments on real-world datasets demonstrate that SparseAGS significantly outperforms state-of-the-art baselines in terms of pose accuracy and 3D reconstruction quality, highlighting its robustness and effectiveness in challenging scenarios.
Key Takeaways#
Why does it matter?#
This paper is important because it presents SparseAGS, a novel approach that significantly improves the accuracy of both 3D reconstruction and camera pose estimation, especially in challenging sparse-view settings. This has broad implications for various applications, such as robotics, augmented reality, and computer vision, where accurate 3D understanding is crucial. The introduction of generative priors and a robust outlier handling mechanism are key innovations that contribute to the method’s success, opening up new avenues for research in this field. The framework’s ability to leverage off-the-shelf pose estimators makes it particularly useful for real-world applications.
Visual Insights#

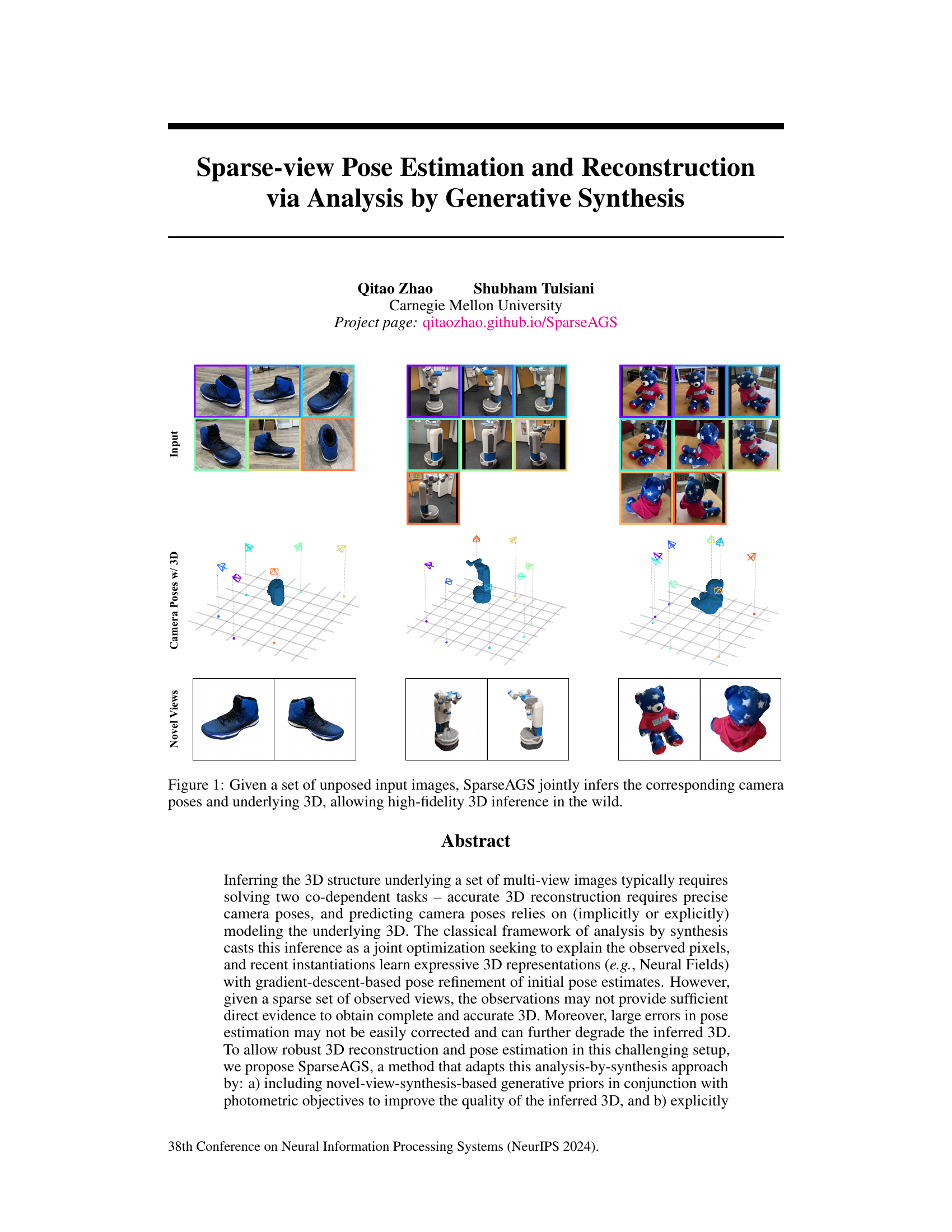
This figure shows the input images of three different objects (shoes, a robot arm, and a teddy bear) in different viewpoints. The middle row displays the inferred camera poses and a 3D representation of the objects. The bottom row shows the novel views generated by the model based on the inferred 3D model and poses. This illustrates the key capability of SparseAGS: accurately estimating 3D models and camera poses from a sparse set of input images.
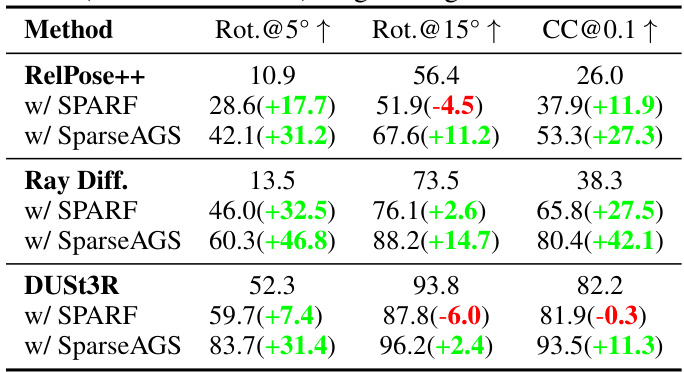
This table compares the camera pose accuracy of three different methods: RelPose++, Ray Diffusion, and DUSt3R, each with and without the SPARF and SparseAGS methods. The accuracy is measured using rotation error at 5 and 15-degree thresholds and camera center error at a threshold of 0.1 of the scene scale. The results show improvements in accuracy when SparseAGS is used with each of the baselines. The experiment used eight images per object.
In-depth insights#
Sparse Pose Estimation#
Sparse pose estimation tackles the challenge of recovering 3D camera poses from a limited number of images, a problem particularly relevant in scenarios with occlusion or limited viewpoints. Traditional methods struggle in such sparse settings, often relying on dense correspondences that are unavailable. The core issue lies in the inherent ambiguity of reconstructing poses with insufficient data. Recent advancements leverage deep learning, introducing generative priors or incorporating other constraints (e.g., scene consistency) to address data sparsity and improve robustness. These methods often involve joint optimization of both pose and scene structure, with generative models sometimes providing probabilistic estimates to handle uncertainty. Analysis-by-synthesis approaches are frequently used, refining initial estimates by iteratively comparing rendered views with the sparse observations. Despite progress, robustness to significant initial pose errors and handling of outliers remain key challenges. Future work should focus on improved outlier rejection and more effective handling of scene complexity to allow for more accurate and reliable pose estimation in challenging real-world conditions.
Generative Priors#
The concept of “Generative Priors” within the context of sparse-view 3D reconstruction is crucial. It leverages the power of generative models, specifically diffusion models, to inform and regularize the 3D reconstruction process. Unlike traditional methods that rely solely on observed data, generative priors introduce prior knowledge about the likely structure and appearance of 3D objects. This is particularly valuable in sparse-view settings, where the observed data is limited, making the reconstruction process prone to ambiguity and overfitting. By incorporating generative priors, the model can fill in missing information and produce more plausible and complete 3D reconstructions. This is achieved by formulating an objective function that includes both a data-fidelity term and a generative prior term. The generative prior guides the reconstruction towards 3D shapes that are consistent with the learned distribution of 3D objects, thus improving the quality and robustness of the results. The approach also handles uncertainties in initial pose estimation by explicitly modeling potential errors, and by using a combined continuous and discrete optimization strategy to refine camera poses and correct outliers. This synergy between generative models and robust optimization techniques is a key strength of the proposed method.
Outlier Robustness#
Outlier robustness is a crucial aspect of any real-world computer vision system, and the SparseAGS method addresses it effectively. The iterative outlier identification process is particularly insightful, cleverly leveraging the impact of individual images on overall reconstruction accuracy to identify problematic outliers. By removing these outliers temporarily and using a discrete search to refine pose estimates, SparseAGS avoids scenarios where bad data points skew the results, improving the quality of the inferred 3D structure and camera poses. This iterative process is significant because it directly tackles the co-dependency between pose accuracy and 3D reconstruction. Incorrect poses hinder the reliability of 3D reconstruction and vice-versa, creating a vicious cycle. SparseAGS breaks this cycle by explicitly handling outlier images. The approach is not solely focused on eliminating outliers; it also attempts to correct them, underscoring the method’s commitment to comprehensive and robust performance. This methodology demonstrates that explicitly managing outlier data leads to significantly better results in sparse-view scenarios, ultimately achieving greater fidelity in the final 3D model.
6DoF Adaptation#
The heading ‘6DoF Adaptation’ suggests a crucial modification to a system initially limited to 3 degrees of freedom (DoF) for camera pose estimation. This upgrade is vital because 3DoF models often struggle to accurately represent real-world camera positions, which possess six degrees of freedom (rotation around three axes and translation along three axes). The adaptation likely involves modifying existing neural networks or designing new ones that can effectively handle this increased dimensionality. This would require adjustments to the network architecture, possibly adding new layers or altering existing layers to accommodate the 6DoF input data (including focal length and principal point, in addition to pose). A key challenge in 6DoF adaptation is handling the significantly larger search space in comparison to 3DoF. The success of this adaptation likely hinges on robust training procedures and appropriate loss functions to effectively optimize the increased number of parameters while preventing overfitting. Furthermore, the adapted system would benefit from testing across diverse real-world datasets, demonstrating improved accuracy and robustness in challenging scenarios with complex lighting, occlusions, and significant variations in viewpoints.
Future Directions#
Future research could explore several promising avenues. Improving robustness to challenging real-world conditions such as severe occlusions, significant viewpoint changes, and varied lighting conditions is crucial. This would involve developing more sophisticated outlier detection and handling mechanisms, potentially leveraging advanced data augmentation techniques during training. Exploring alternative generative models beyond diffusion models, or investigating hybrid approaches that combine the strengths of multiple generative architectures could further enhance performance and efficiency. Furthermore, incorporating other modalities like depth sensors or point clouds, along with multi-view images, would provide richer input for 3D reconstruction and pose estimation, potentially leading to more accurate and robust results. Finally, extending the approach to larger-scale scenes or dynamic environments would be a valuable step towards more practical applications. Investigating strategies for efficient handling of increased computational complexity and memory requirements in such settings would be critical.
More visual insights#
More on figures
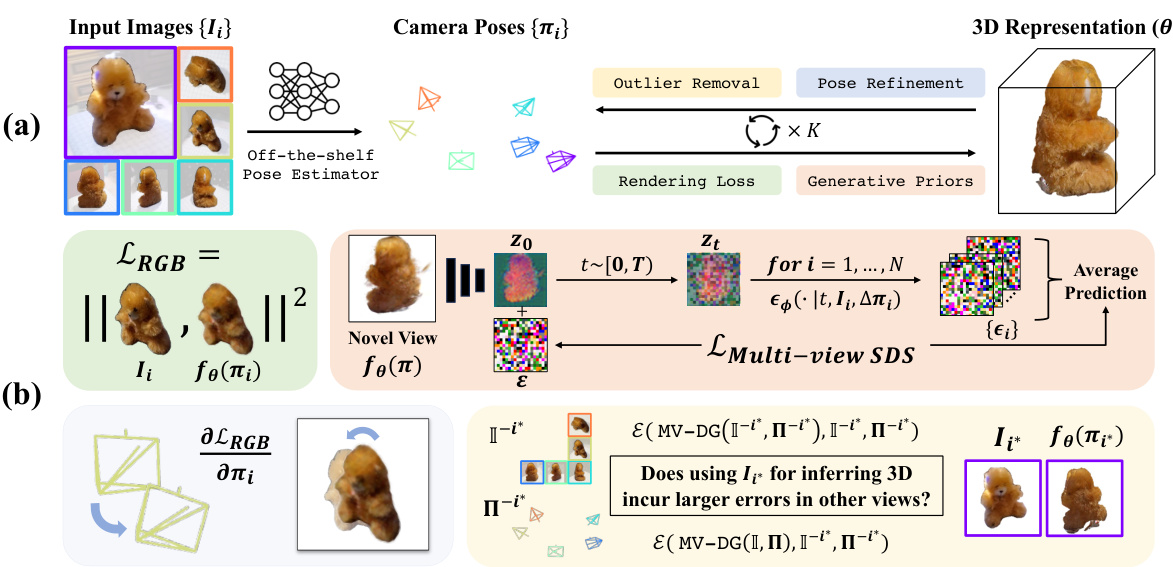
This figure provides a detailed overview of the SparseAGS framework. Part (a) shows the overall pipeline, starting with input images and off-the-shelf camera pose estimations and ending with a refined 3D model and poses. Part (b) breaks down the individual components, highlighting the iterative process of 3D reconstruction and pose refinement, the use of rendering loss and multi-view score distillation sampling (SDS) loss, and how outlier views are identified and handled. This iterative process aims to improve the accuracy of camera pose and 3D reconstruction by iteratively refining both.

This figure compares the camera pose accuracy of three different methods: SPARF, SparseAGS, and the initial poses from three different off-the-shelf pose estimation methods (DUSt3R, Ray Diff, and RelPose++). The results show that SparseAGS significantly improves upon the initial poses and outperforms SPARF in terms of aligning estimated camera positions to ground truth.

This figure compares the novel view synthesis capabilities of SparseAGS against LEAP, using two different pose estimation baselines (Ray Diffusion and DUSt3R). SparseAGS demonstrates superior performance in preserving details and achieving higher fidelity in novel view generation, particularly when initialized with more accurate camera poses. The zoomed-in sections highlight these differences.

This figure shows a qualitative comparison of novel view synthesis results between SparseAGS and the baseline method LEAP, using two different pose estimation methods (Ray Diffusion and DUSt3R) for initialization. SparseAGS demonstrates better preservation of details from the input images and improved performance when initialized with more accurate camera poses. The comparison is presented for multiple objects (a toy chicken racer, a toy bull, and others), visually showcasing the quality differences.

This figure compares the 3D reconstruction results with and without using Score Distillation Sampling (SDS) for generative priors. It shows that including SDS leads to more consistent and coherent 3D models, especially when generating novel views. The comparison is performed on eight input images (N=8). The results are presented for both novel views and normal views, demonstrating the benefit of SDS across different viewing conditions.

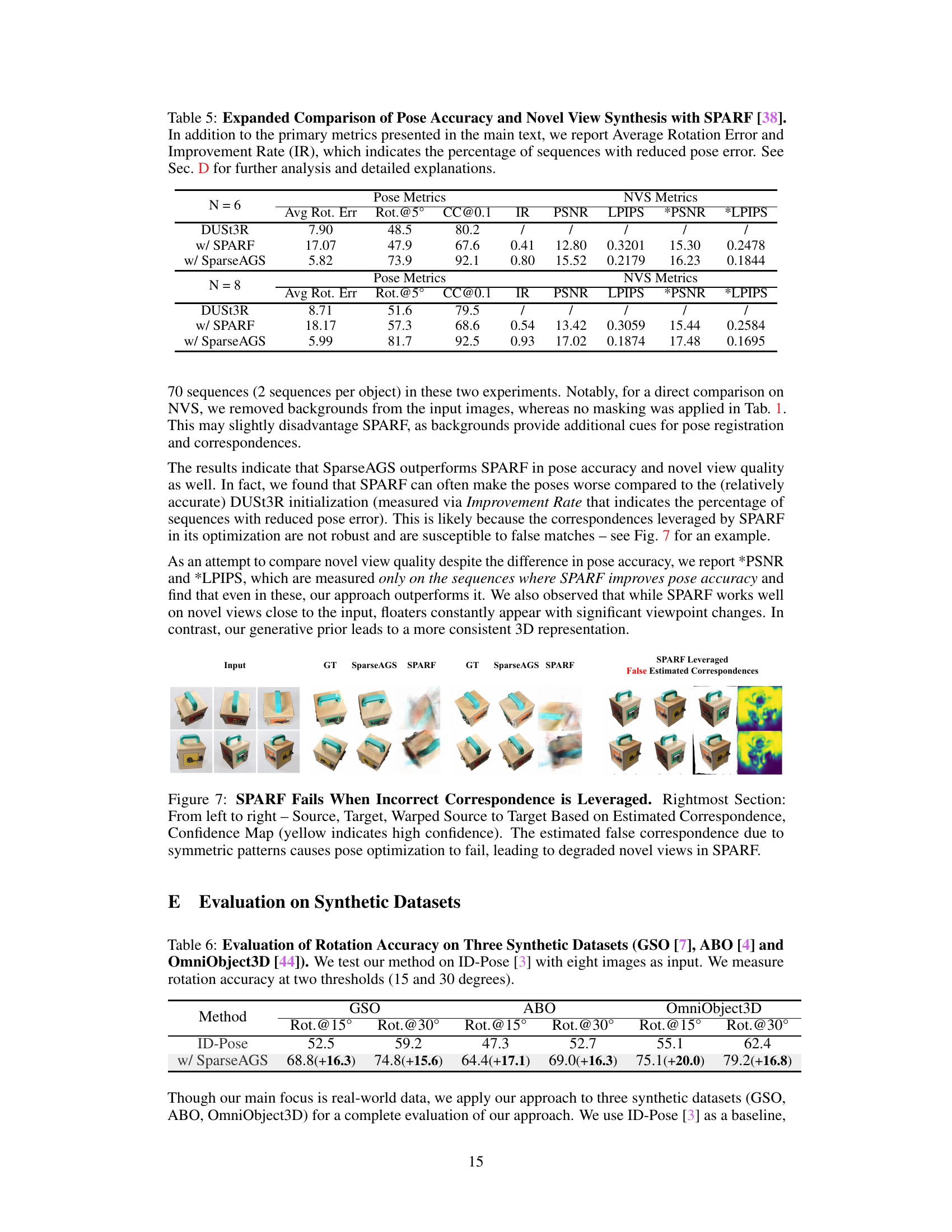
This figure demonstrates a failure case of the SPARF method, where incorrect correspondences between images lead to inaccurate pose estimation and poor novel view synthesis. The figure shows a comparison between the ground truth, SparseAGS results, and SPARF results for novel view synthesis. The rightmost section highlights the false correspondences identified by SPARF, which are marked in yellow on the confidence map. These false correspondences are caused by symmetric patterns in the input images, leading to errors in the pose estimation and ultimately degrading the quality of the novel views generated by SPARF.

This figure compares the camera pose accuracy of SparseAGS against three baselines (DUSt3R, Ray Diffusion, and RelPose++) and SPARF. For each method, initial camera poses are estimated using the baselines. Then, the poses are further refined either by SPARF or SparseAGS. The refined poses are visually compared to ground truth to show improvements. The alignment is done by using an optimal similarity transform. The black dots represent ground truth camera locations.

This figure compares the novel view synthesis results of SparseAGS against LEAP, using two different pose estimation baselines. It demonstrates that SparseAGS better maintains details from the original input images and achieves improved performance when initialized with more accurate camera poses.
More on tables
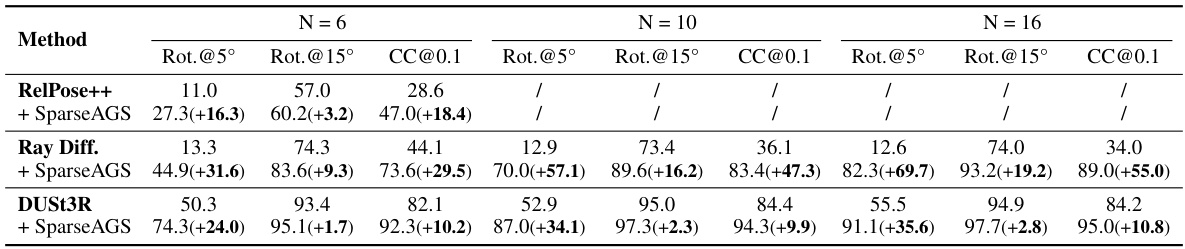
This table presents a quantitative comparison of camera pose accuracy using different numbers of input images (N=6, 10, 16). Three different baseline pose estimation methods (RelPose++, Ray Diff., DUSt3R) are used, each combined with SparseAGS. The results show rotation accuracy at 5° and 15° thresholds, and camera center accuracy at a 0.1 threshold of the scene scale. The improvements provided by SparseAGS over the baselines are highlighted, indicating increased accuracy with more images.
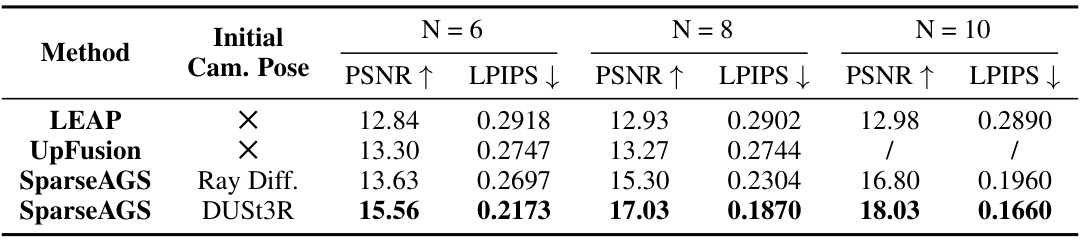
This table presents a quantitative comparison of 3D reconstruction performance on the NAVI dataset. It compares the proposed SparseAGS method against two baselines (LEAP and UpFusion) using different numbers of input images (N=6, 8, 10). The evaluation metrics are Peak Signal-to-Noise Ratio (PSNR) and Learned Perceptual Image Patch Similarity (LPIPS), and two different initial camera pose estimations (Ray Diffusion and DUSt3R) are used as input to SparseAGS.

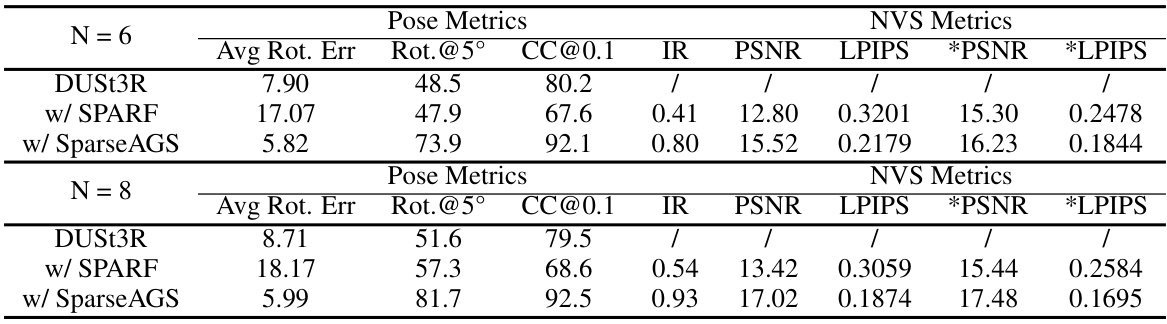
This table presents the results of an ablation study conducted to evaluate the contribution of each component in the SparseAGS framework. The study uses initial poses from Ray Diffusion [47] and eight input images. The table shows the impact of each component on camera pose accuracy (Rotation accuracy at 5° and 15° thresholds, Camera center accuracy at 0.1 threshold), 3D reconstruction quality (PSNR and LPIPS), and F1 score at a threshold of 0.01. The components evaluated are: Pose-3D co-optimization without SDS, adding vanilla Zero-1-to-3 SDS, using the proposed 6-DoF Zero-1-to-3 SDS, and finally, adding outlier removal and correction. By comparing the results across rows, one can assess the individual contributions of each component to the overall performance of the SparseAGS system.
This table compares the camera pose accuracy of SparseAGS against three baseline methods (RelPose++, Ray Diffusion, DUSt3R) and SPARF, using eight images. It measures rotation accuracy at 5 and 15-degree thresholds and camera center accuracy within 10% of the scene scale. The results show improvements in pose accuracy when SparseAGS is used with the baselines.

This table presents a quantitative comparison of the rotation accuracy achieved by the proposed SparseAGS method and the baseline ID-Pose method on three synthetic datasets: GSO, ABO, and OmniObject3D. The evaluation uses eight input images and measures rotation accuracy at two thresholds (15 and 30 degrees). The results show improvements in rotation accuracy when using SparseAGS compared to ID-Pose across all datasets and thresholds. The numbers represent the percentage of samples with errors less than the specified threshold.
Full paper#