↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current machine learning methods for tabular data prediction rely on task-specific models trained on data from the same distribution as that of the task, limiting flexibility and efficiency. Transfer learning paradigms haven’t had similar success in the tabular domain as in language modeling and computer vision. This paper addresses this by introducing a novel method for tabular prediction.
The authors fine-tune a large language model (LLM) on a large, high-quality dataset created by filtering TabLib (a web-scale corpus of tables). They introduce a novel packing and attention scheme, Row-Causal Tabular Masking (RCTM), specifically designed for tabular prediction. This model, TABULA-8B, outperforms existing state-of-the-art methods on several benchmark datasets, demonstrating superior performance in zero-shot and few-shot scenarios. The model, code, and data are publicly released.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers because it bridges the gap between the success of foundation models in other domains and their limited impact on tabular data. It introduces a novel approach to tabular data prediction that is both highly accurate and efficient, paving the way for numerous future research avenues. The open-source nature of the model and data further enhances its impact and facilitates collaboration.
Visual Insights#
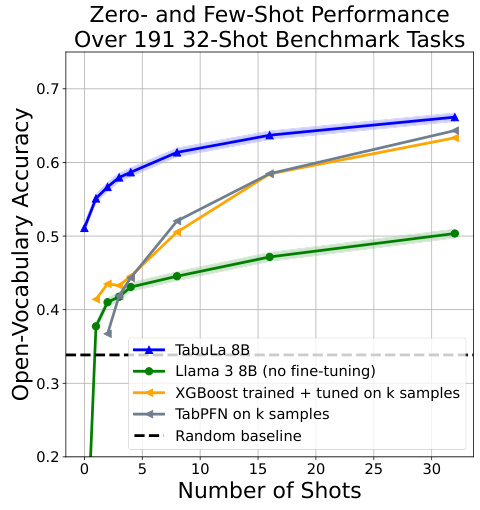
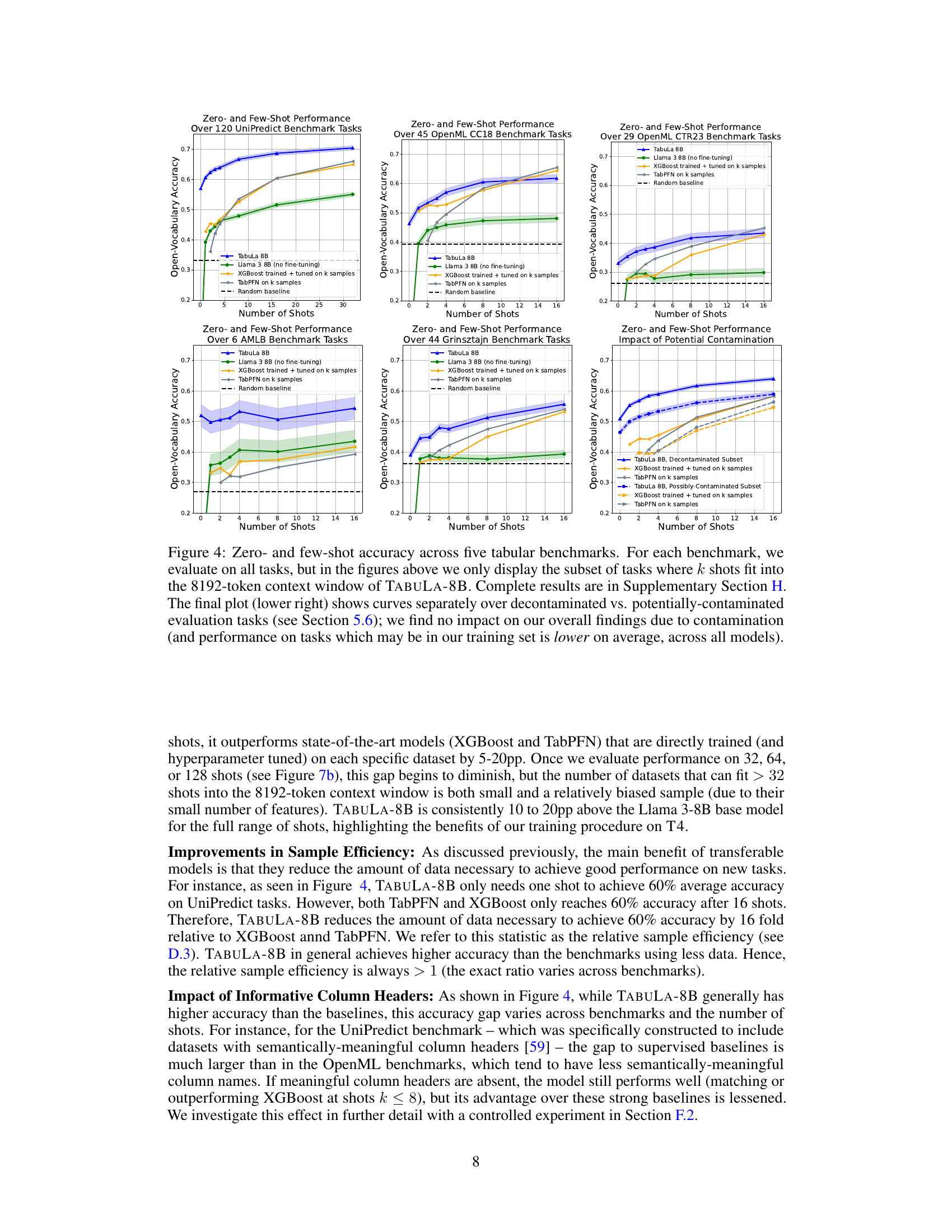
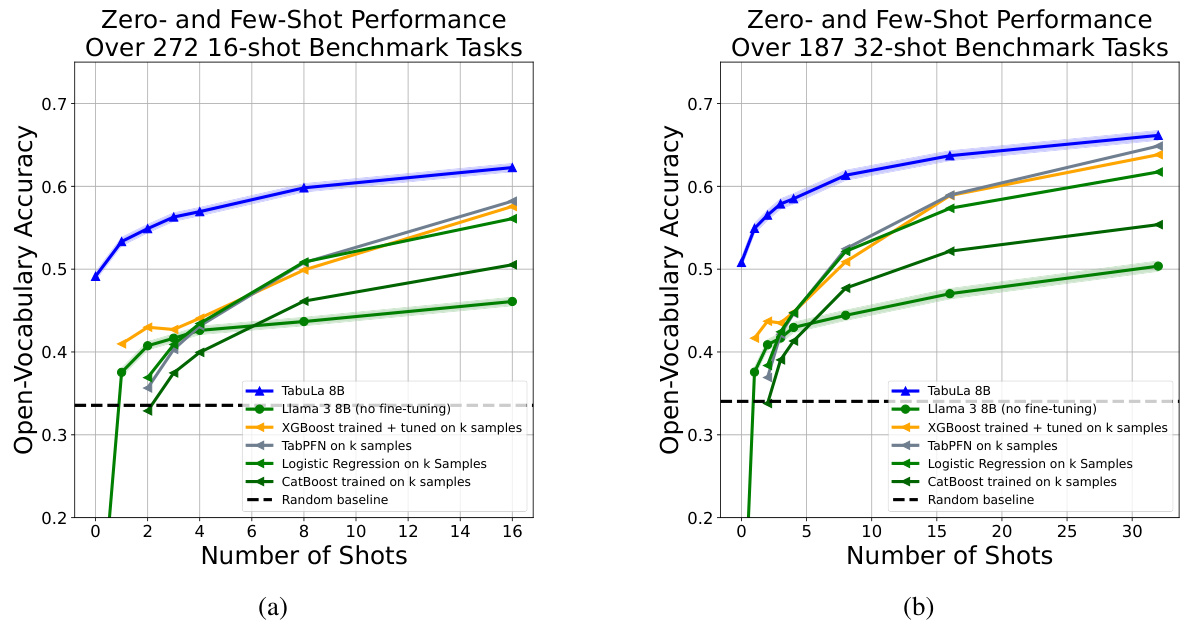
The figure shows the zero-shot and few-shot performance of TABULA-8B compared to several state-of-the-art tabular prediction models (Llama 3 8B, XGBoost, TabPFN) across five benchmark datasets. The x-axis represents the number of shots (training examples), and the y-axis represents the open-vocabulary accuracy. TABULA-8B consistently outperforms the baselines, demonstrating its effectiveness in transfer learning for tabular data. The improvement is particularly noticeable in the few-shot setting (1-32 shots), where TABULA-8B significantly surpasses models that have been explicitly trained on the target data.
This table visually summarizes the results of the experiments described in the paper. It shows a comparison of the zero-shot and few-shot performance of TABULA-8B against other state-of-the-art tabular prediction models (Llama 3-8B, XGBoost, TabPFN) across five benchmark datasets. The x-axis represents the number of shots, and the y-axis shows the accuracy. The figure clearly demonstrates that TABULA-8B significantly outperforms all other models, especially in the zero-shot and few-shot learning settings.
In-depth insights#
Tabular Transfer#
The concept of “Tabular Transfer” in machine learning focuses on leveraging the knowledge gained from training models on large-scale tabular datasets to improve performance on smaller, target datasets. This approach is particularly valuable when the target dataset is limited, as it mitigates the need for extensive training data. Transfer learning techniques are crucial here, employing methodologies that enable models to adapt and generalize knowledge from the source datasets to new, unseen tasks and domains. The success of tabular transfer hinges significantly on data representation; effective encoding and packing schemes are vital for efficiently handling the diverse nature of tabular data and facilitating effective knowledge transfer. Challenges remain, notably in addressing the heterogeneity of tabular data (mixed data types, missing values, varied scales). Further research should investigate how bias in training data impacts transfer performance across various tasks and datasets. Moreover, improving techniques for generalizing knowledge across different tabular structures is key for enabling more robust and effective transfer learning solutions.
LLM for Tables#
Applying Large Language Models (LLMs) to tabular data presents a unique opportunity to leverage the power of transfer learning in a domain traditionally dominated by tree-based methods. The core idea involves representing tabular data as text, enabling LLMs to perform prediction tasks such as classification and regression. This approach bypasses the need for extensive task-specific feature engineering, a significant advantage in low-resource scenarios. However, challenges remain, such as handling heterogeneous data types, missing values, and variable table structures. Effective serialization of tabular data into a suitable text format is crucial for LLM performance, and innovative attention mechanisms may be necessary to capture the relationships between rows and columns within a table. Moreover, the potential impact of dataset bias and contamination on LLM performance requires careful consideration and mitigation strategies. While current approaches show promise, further research is necessary to fully unlock the potential of LLMs for tabular data, particularly in handling complex, real-world datasets.
T4 Dataset#
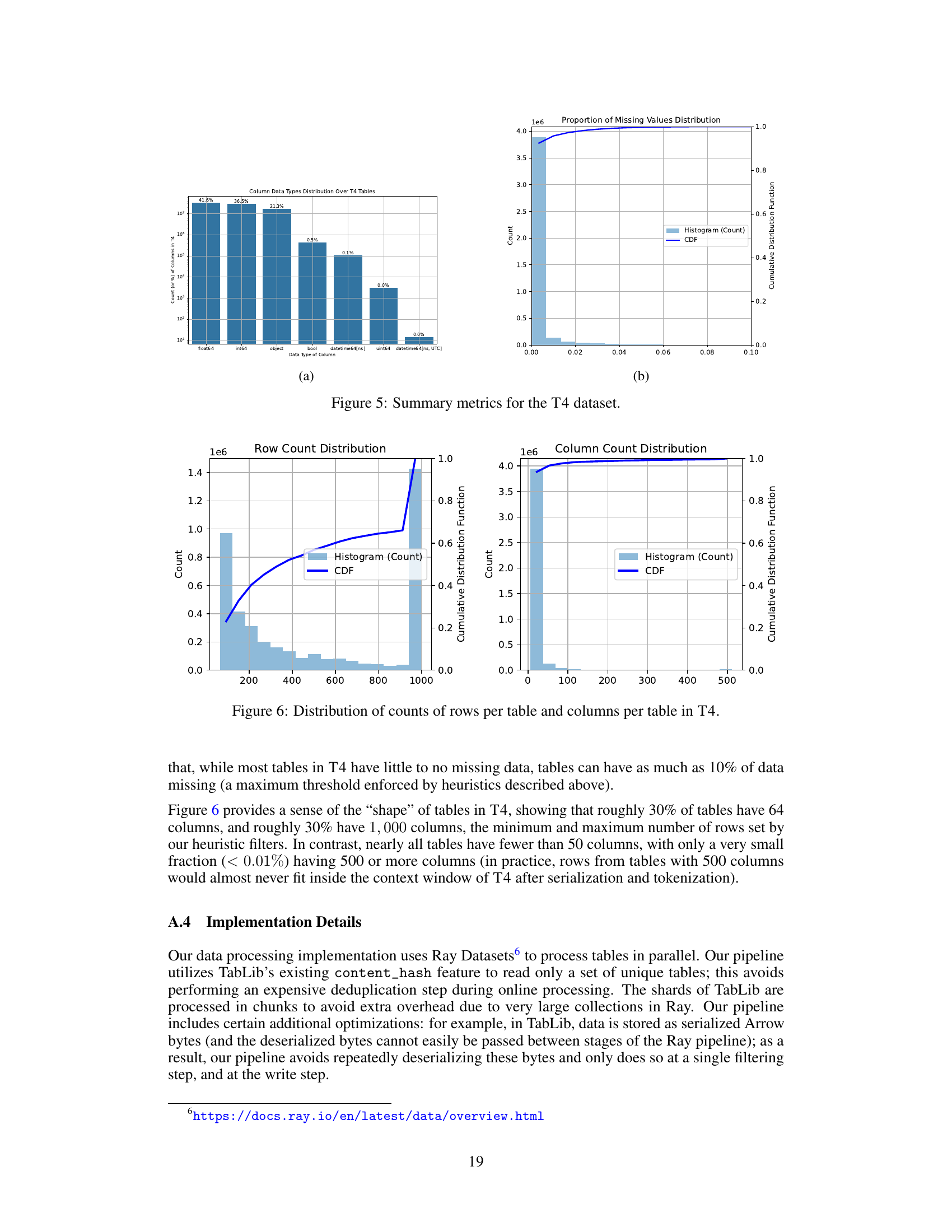
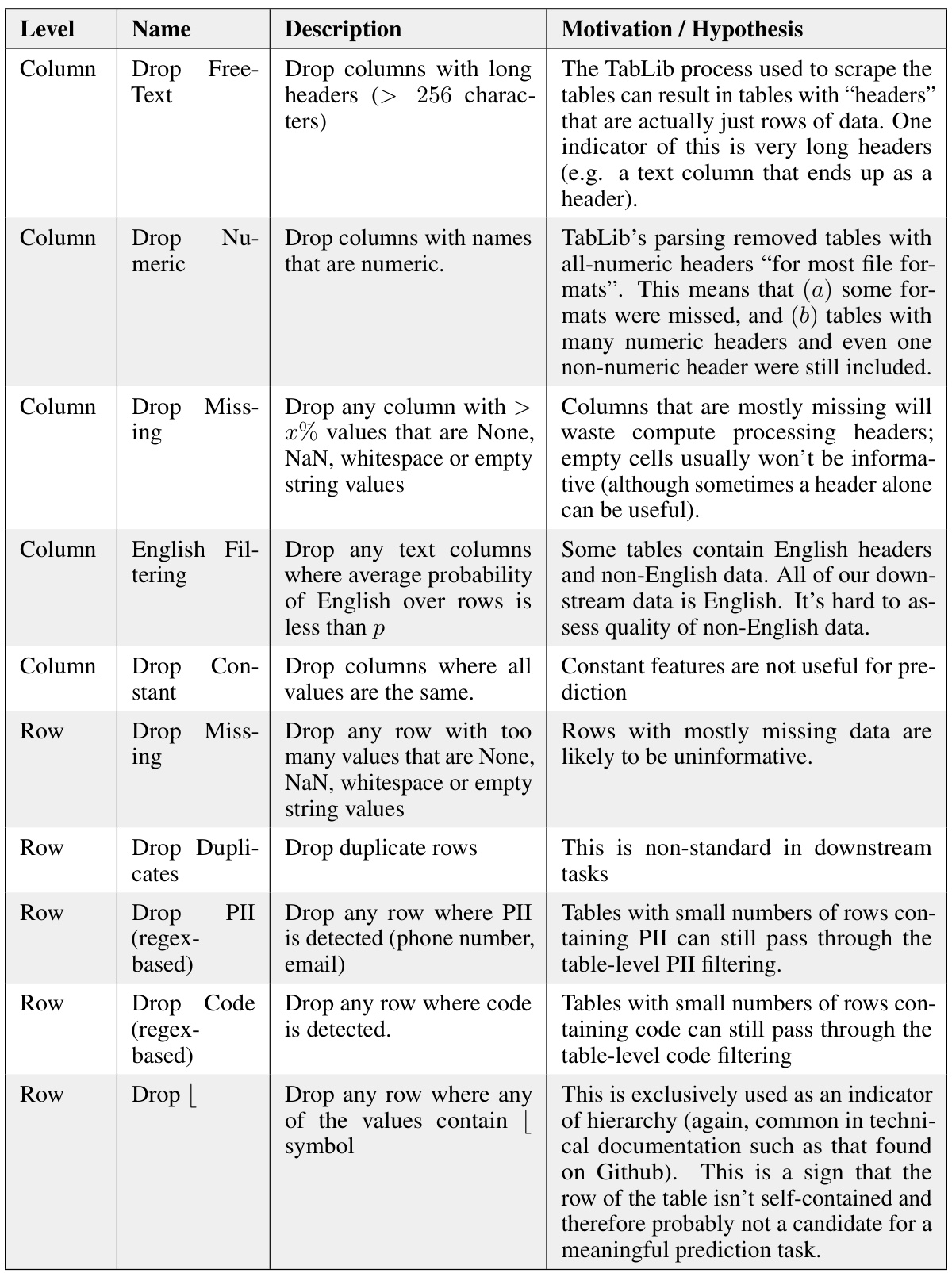
The T4 dataset, a crucial component of the research, represents a significant advancement in tabular data for machine learning. Its creation involved a multi-stage process starting with the TabLib corpus, a massive compilation of web-scraped tables. Rigorous filtering techniques were employed to remove low-quality data, ensuring high data quality. This filtering focused on removing tables with non-standard formats or incomplete data. This meticulous curation yielded a refined dataset comprising over 4.2 million unique tables and exceeding 2.1 billion rows. The sheer scale of T4 is a key differentiator, allowing for the training of much larger and more performant models than previously possible, directly addressing a major bottleneck in tabular transfer learning. Furthermore, T4’s construction incorporated novel methods for unsupervised prediction target selection, significantly improving efficiency and enabling larger-scale training. The release of this dataset, coupled with the model and code, is expected to accelerate future research in the field, fostering advancements in transfer learning for tabular data.
RCTM Attention#
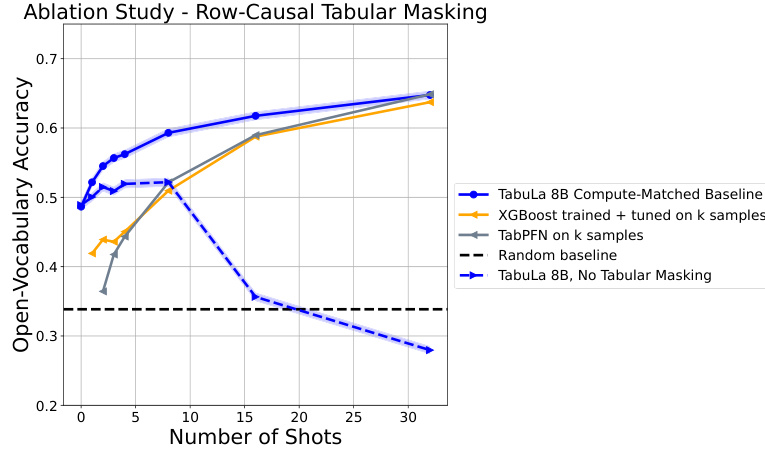
Row-Causal Tabular Masking (RCTM) attention is a novel approach designed for handling tabular data within the context of large language models (LLMs). RCTM addresses the challenge of training LLMs on tabular data, which often involves variable-length sequences and the need for efficient attention mechanisms. Traditional attention mechanisms struggle with this due to computational costs associated with long sequences and the complex relationships between rows within tables. RCTM overcomes these limitations by employing a row-causal masking scheme. This scheme allows attention only within the rows of a given table, preventing cross-contamination between different tables during training. This approach is particularly beneficial in few-shot learning scenarios as it enables the model to learn from multiple examples within a table while avoiding interference from unrelated data points. By focusing attention within individual tables, RCTM enhances sample efficiency and facilitates the extraction of relevant patterns from limited data. This ultimately improves the accuracy of few-shot predictions on new, unseen tabular data. The effectiveness of RCTM highlights the significant potential of LLMs in the tabular data domain, particularly for applications where data is scarce.
Future Work#
The paper’s “Future Work” section suggests several promising avenues. Improving data filtering is crucial, potentially leveraging advancements in unsupervised techniques to identify high-quality tabular data more effectively at scale. Scaling the model itself, through increased model size and potentially longer training runs, is highlighted as a key area for enhancement. The authors also identify the need for exploring inference-time strategies to further boost prediction performance, such as self-consistency or prompt ensembling. Beyond these direct improvements, the paper calls for deeper investigations into the foundational properties of tabular foundation models. This includes analyzing potential biases in existing models trained on large datasets, addressing the specific challenges of dealing with small-sample scenarios, and exploring the model’s potential beyond prediction tasks, such as data generation, explanation, and data transformation. The authors emphasize that making these advancements accessible through high-quality, open-source implementations is vital.
More visual insights#
More on figures

The figure displays a graph comparing the performance of TABULA-8B against other state-of-the-art tabular prediction models (Llama 3 8B, XGBoost, TabPFN) across different numbers of shots (from zero-shot to 32-shot). The x-axis represents the number of shots, and the y-axis shows the open-vocabulary accuracy. The graph demonstrates that TABULA-8B consistently outperforms the other models, especially in the zero-shot and few-shot scenarios, highlighting its superior transfer learning capabilities.

The figure shows a comparison of the performance of TABULA-8B against several state-of-the-art (SOTA) tabular prediction models across different numbers of shots (from zero-shot to 32-shot). The x-axis represents the number of shots (training examples provided), and the y-axis represents the open-vocabulary accuracy. TABULA-8B consistently outperforms XGBoost and TabPFN, demonstrating superior transfer learning capabilities, even with limited training data. The plot includes curves for Llama 3-8B (without fine-tuning), highlighting the effectiveness of the TABULA-8B fine-tuning process.
The figure shows a comparison of the performance of TABULA-8B against other state-of-the-art (SOTA) tabular prediction models across different numbers of shots (from zero-shot to 32-shot). The x-axis represents the number of shots, which indicates the amount of labeled training data provided to the models. The y-axis represents the open-vocabulary accuracy. The plot demonstrates that TABULA-8B consistently outperforms the other models, achieving significantly higher accuracy with minimal labeled data, highlighting its effective transfer learning capabilities.
The figure compares the performance of TABULA-8B against other state-of-the-art (SOTA) tabular prediction models on zero-shot and few-shot tasks. It shows that TABULA-8B significantly outperforms the other methods, especially when the number of training examples is limited. The graph displays the open-vocabulary accuracy of each method across different numbers of shots (from 0 to 32). The five tabular benchmarks used are also indicated in the legend.
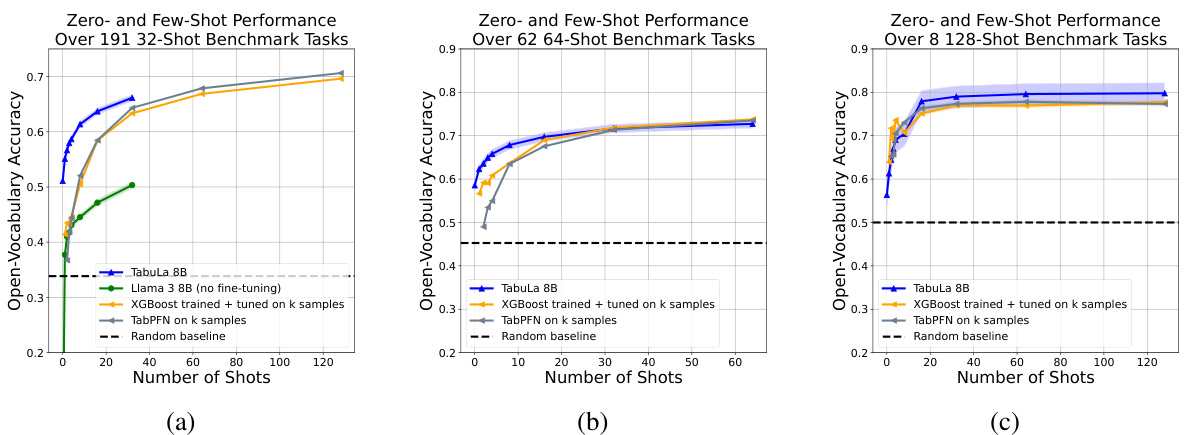
The figure shows the performance comparison of TABULA-8B against state-of-the-art (SOTA) tabular prediction models (XGBoost and TabPFN) across different numbers of shots (0-32) on five tabular benchmarks. The x-axis represents the number of shots (training examples provided to the model), and the y-axis represents the open-vocabulary accuracy. The plot demonstrates that TABULA-8B consistently outperforms the SOTA baselines, especially in the zero-shot (no training examples) and few-shot scenarios. This showcases TABULA-8B’s ability to effectively transfer knowledge from a large-scale training dataset to new, unseen tabular prediction tasks.
This figure compares the zero-shot and few-shot performance of TABULA-8B against several baselines across five tabular benchmarks. Each plot shows the accuracy for a given number of shots (examples provided to the model). The plots display the model’s ability to generalize to unseen data, highlighting its performance relative to other models trained explicitly on larger datasets. The bottom-right plot specifically examines the impact of potential data contamination, concluding that it doesn’t significantly affect the results.
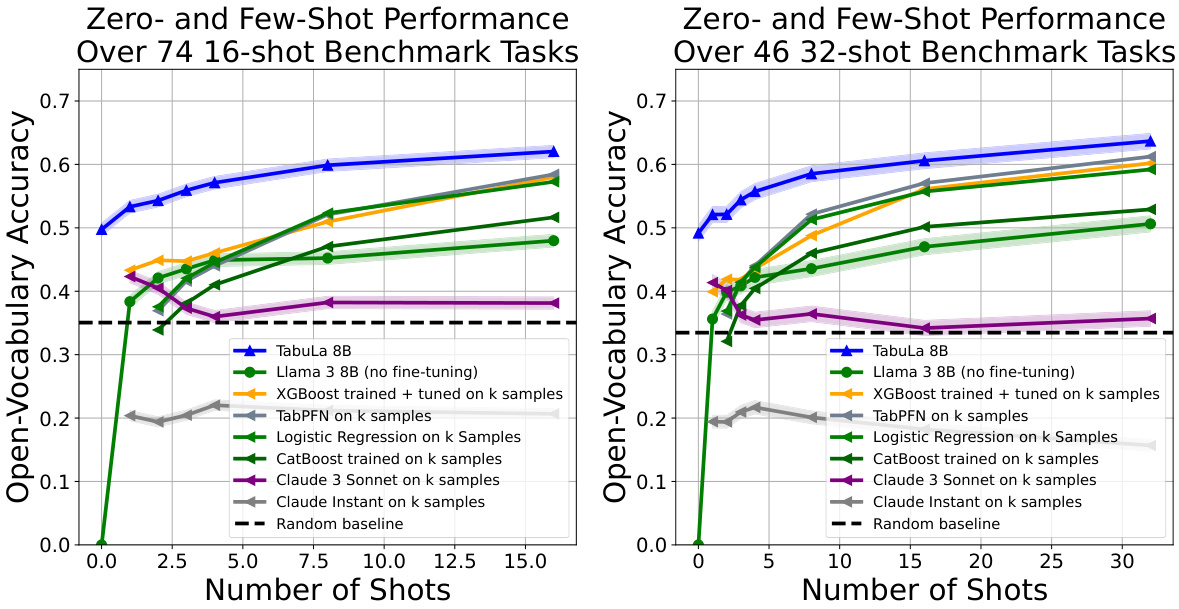
This figure compares the performance of TABULA-8B against other state-of-the-art tabular prediction models (XGBoost, TabPFN) across a range of different shots (0-32). It shows that TABULA-8B consistently outperforms other models, particularly in the zero-shot and few-shot scenarios, demonstrating the model’s ability to perform well with limited training data. The figure highlights TABULA-8B’s superior transfer learning capabilities.
This figure compares the performance of TABULA-8B against other state-of-the-art (SOTA) tabular prediction models across a range of shot settings (from zero-shot to 32-shot). It shows that TABULA-8B consistently outperforms the other models, demonstrating its ability to achieve high accuracy with limited training data. The five tabular benchmarks used in the comparison represent diverse datasets and prediction tasks.
The figure displays the zero-shot and few-shot learning performance of the TABULA-8B model across five different tabular datasets. It compares TABULA-8B’s performance against several state-of-the-art baselines such as XGBoost and TabPFN. The results are visualized using line graphs that show accuracy as a function of the number of shots (examples) provided to the model. A key finding highlighted is TABULA-8B’s superior performance, especially in low-shot scenarios, and its robustness to potential data contamination.
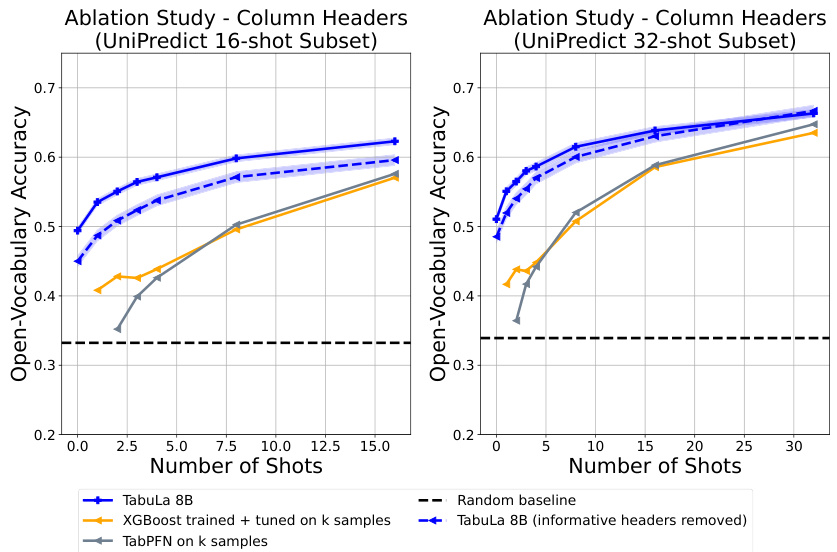
The figure shows the performance of TABULA-8B compared to other state-of-the-art models across different shot settings (0-32 shots). It demonstrates that TABULA-8B outperforms existing models even without fine-tuning on the specific tasks (zero-shot) and significantly improves with a small number of training examples (few-shot). The comparison includes XGBoost and TabPFN, which are commonly used in tabular prediction. The results are shown across five benchmark datasets, indicating consistent improvement across different tabular datasets.
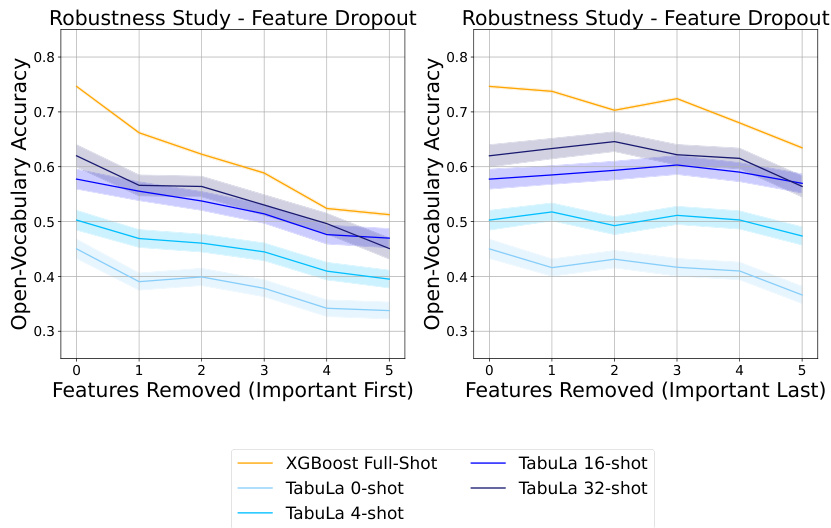
The figure shows the zero-shot and few-shot performance of TABULA-8B compared to other state-of-the-art tabular prediction models (Llama 3-8B, XGBoost, TabPFN) across five tabular benchmarks. The x-axis represents the number of shots (examples provided to the model), and the y-axis represents the open-vocabulary accuracy. TABULA-8B consistently outperforms the other models, particularly in the zero-shot and few-shot settings, demonstrating its superior transfer learning capabilities.
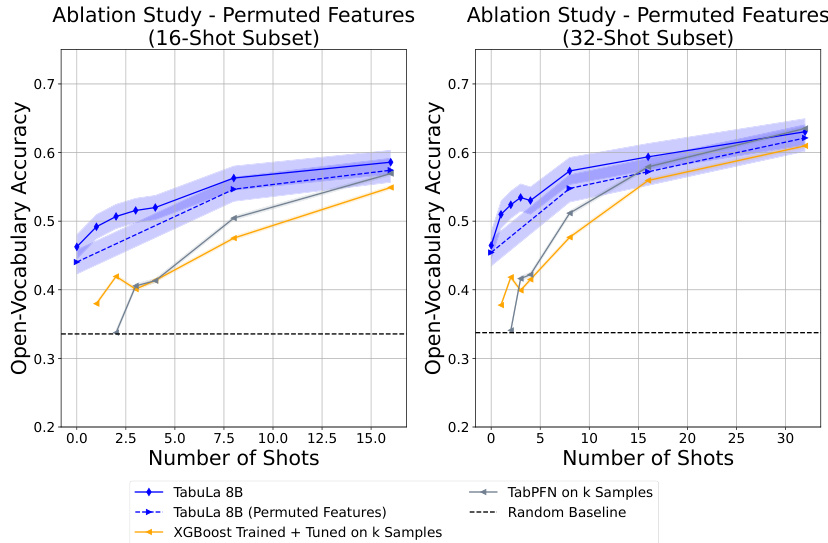
The figure compares the performance of TABULA-8B against other state-of-the-art (SOTA) tabular prediction models across various shot settings (0-32 shots). It shows that TABULA-8B consistently outperforms these baselines (XGBoost and TabPFN), achieving higher accuracy even without any fine-tuning on the target datasets (zero-shot). This demonstrates TABULA-8B’s strong transfer learning capabilities on tabular data.
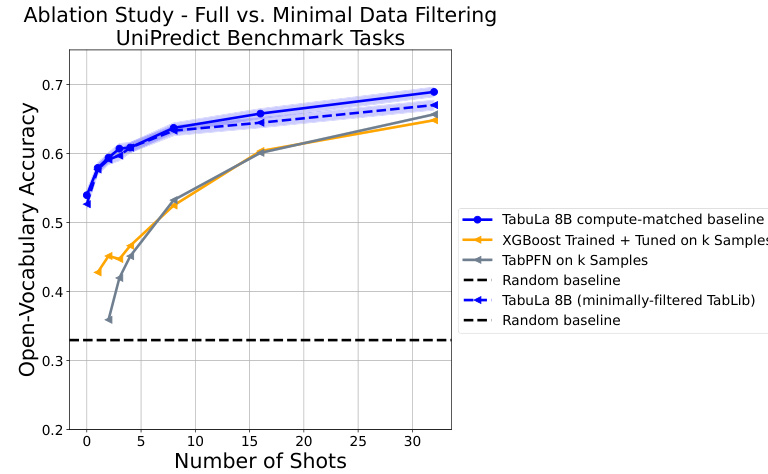
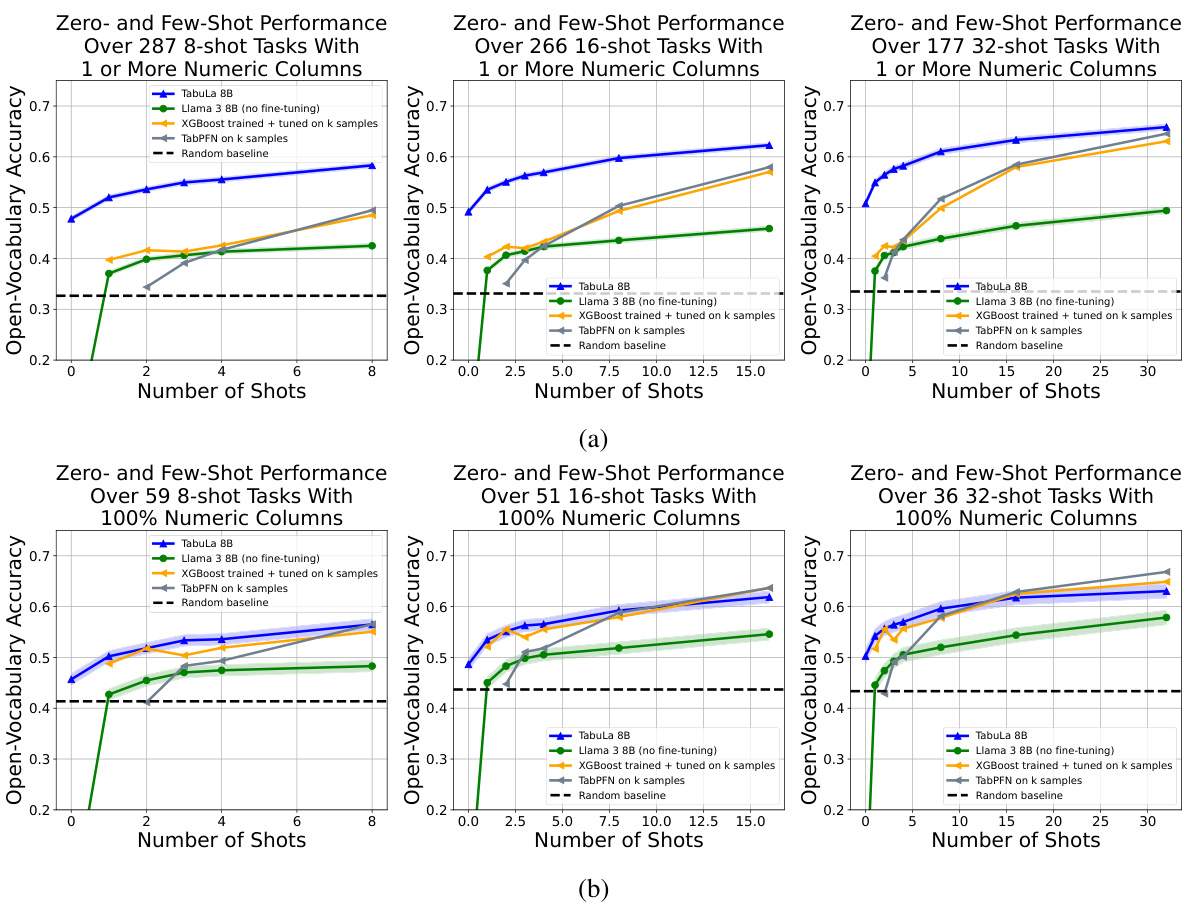
This figure compares the zero-shot and few-shot performance of TABULA-8B against several state-of-the-art baselines across five benchmark datasets. Each plot shows accuracy across different numbers of training examples (shots). The lower right plot specifically isolates results on tasks where contamination (overlapping datasets) may have occurred, showing this has minimal impact on performance.

This figure displays the performance of TABULA-8B and several baseline models on five different tabular datasets. It showcases the zero-shot (no training examples) and few-shot (small number of training examples) learning capabilities across various benchmark datasets. The results highlight TABULA-8B’s superior performance compared to traditional methods, especially in zero-shot and few-shot scenarios. The final subplot analyzes the model’s robustness to potential data contamination.
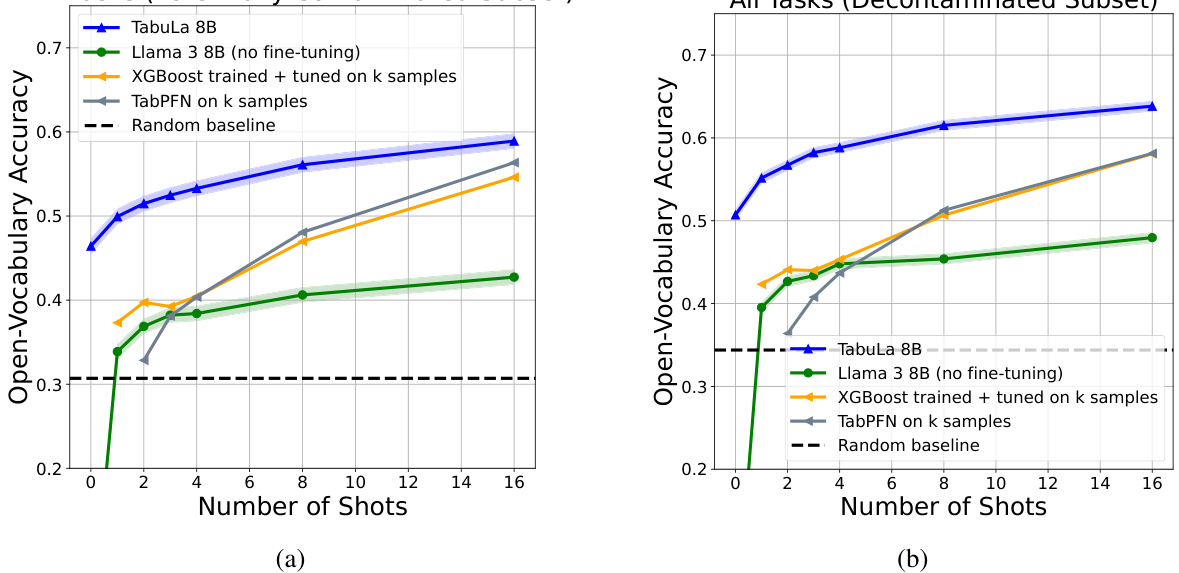
The figure shows a comparison of the zero-shot and few-shot performance of TABULA-8B against several state-of-the-art tabular prediction models (XGBoost, TabPFN) across five benchmark datasets. The x-axis represents the number of shots (examples provided to the model), and the y-axis represents the open-vocabulary accuracy. The figure demonstrates that TABULA-8B significantly outperforms the other models, especially in the zero-shot setting (0 shots) where it achieves an accuracy considerably higher than random guessing. In the few-shot settings, TABULA-8B maintains a consistent lead over the baselines, showcasing its strong transfer learning capabilities.

The figure displays a graph showing the zero-shot and few-shot performance of TABULA-8B against other state-of-the-art tabular prediction models (Llama 3-8B, XGBoost, and TabPFN). The x-axis represents the number of shots (training examples), and the y-axis represents the open-vocabulary accuracy. The graph demonstrates that TABULA-8B significantly outperforms the baselines across all shot settings, especially in the zero-shot scenario (0 shots). The superior performance highlights TABULA-8B’s ability to effectively transfer learning to unseen tabular datasets.
More on tables
This table presents a graph comparing the zero-shot and few-shot performance of TABULA-8B against other state-of-the-art tabular prediction models (Llama 3-8B, XGBoost, and TabPFN) across five benchmark datasets. The x-axis represents the number of shots (examples) provided to the model, while the y-axis shows the open-vocabulary accuracy. The graph demonstrates that TABULA-8B consistently outperforms other methods, achieving higher accuracy even with zero shots.

This table displays the results of experiments comparing the performance of TABULA-8B against other state-of-the-art tabular prediction models across five different benchmarks. The x-axis represents the number of shots (examples) provided to the model, while the y-axis shows the open-vocabulary accuracy. The results demonstrate that TABULA-8B significantly outperforms existing models, especially in zero-shot and few-shot settings.

This table summarizes the zero-shot and few-shot performance of TABULA-8B against other state-of-the-art tabular prediction models across five benchmark datasets. It visually represents the open-vocabulary accuracy of different models at varying numbers of shots (training examples). The results showcase TABULA-8B’s superior performance, particularly in zero-shot and few-shot scenarios, highlighting its ability to achieve high accuracy with limited or no training data on unseen tables.
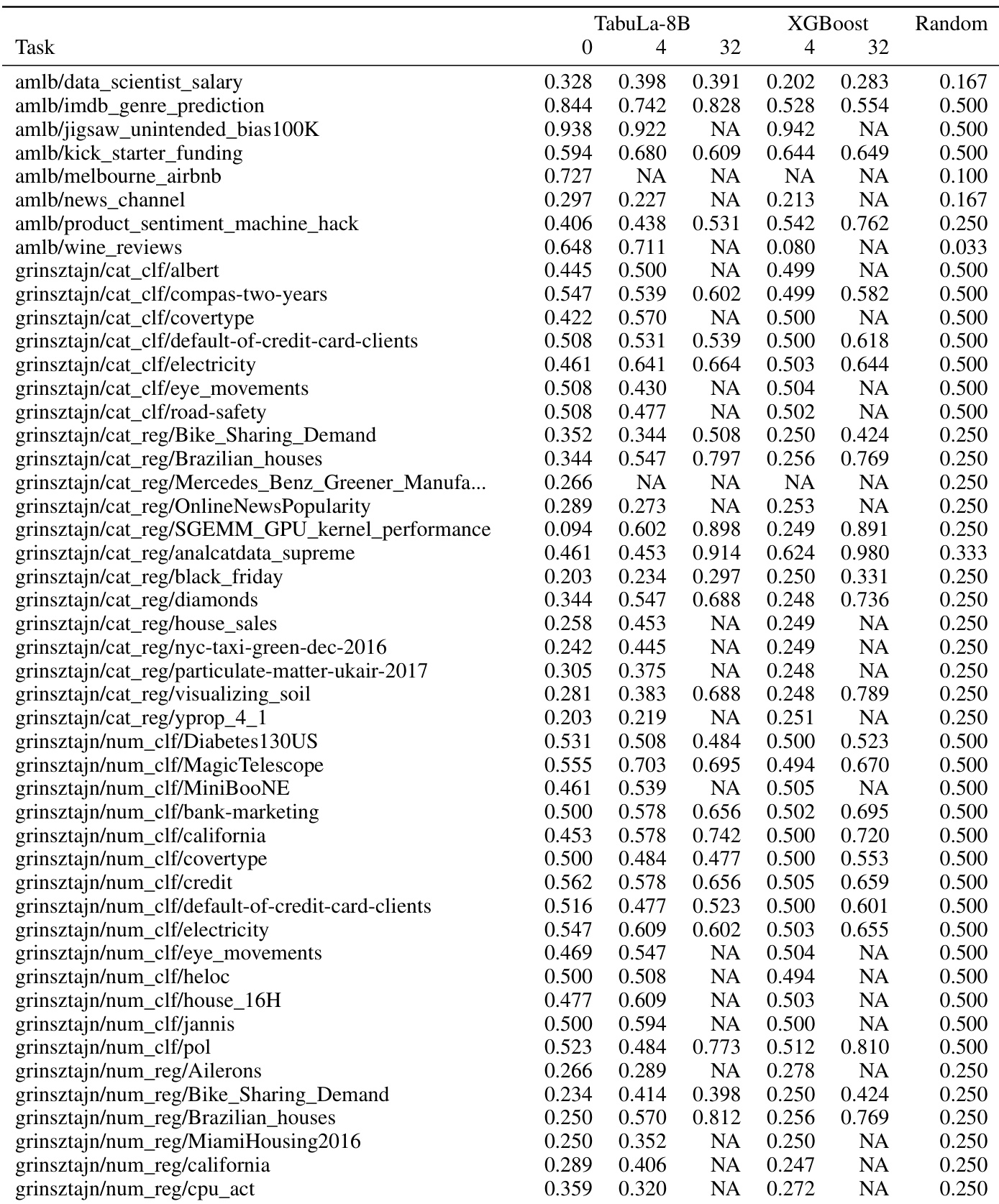
This table presents the results of a comparative study evaluating the performance of TABULA-8B against state-of-the-art tabular prediction models across five benchmark datasets. The comparison includes zero-shot (no training examples) and few-shot (1-32 training examples) scenarios, illustrating TABULA-8B’s ability to perform well even with limited training data.

This table displays a graph showing the zero-shot and few-shot performance of TABULA-8B against other state-of-the-art (SOTA) tabular prediction models, namely Llama 3-8B, XGBoost, and TabPFN. The x-axis represents the number of shots (training examples), while the y-axis shows the accuracy. The graph illustrates TABULA-8B’s superior performance, particularly in the zero-shot scenario (no training examples) and few-shot settings, across multiple benchmark datasets.
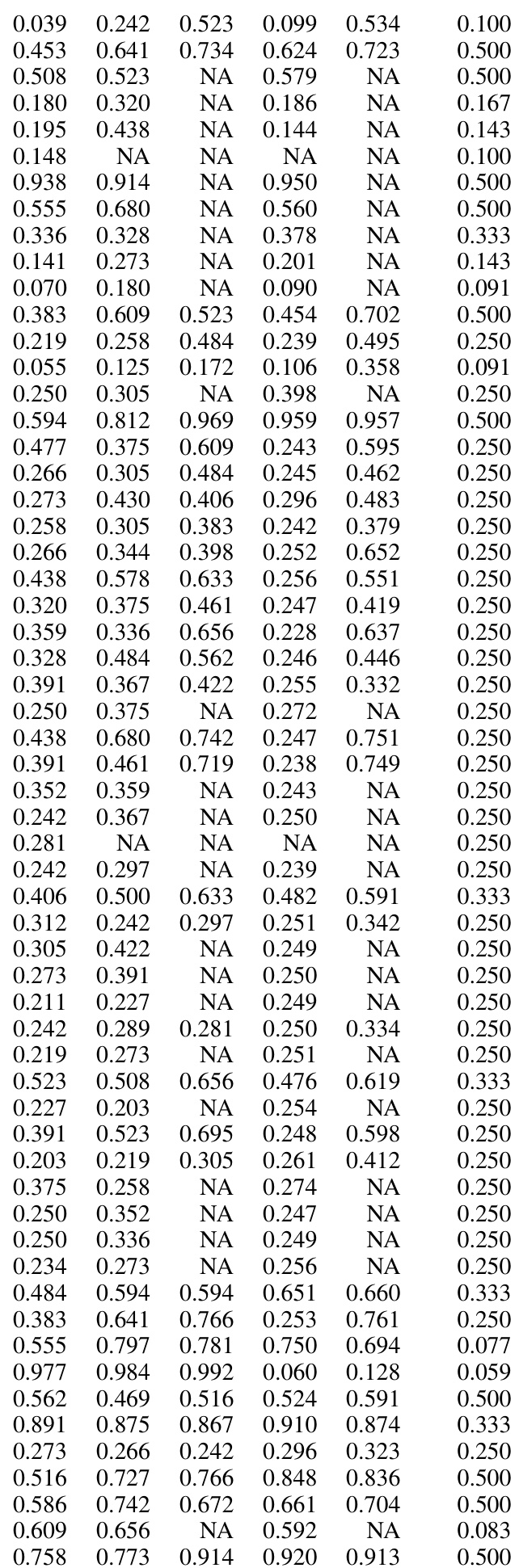
This table displays the zero-shot and few-shot performance of TABULA-8B compared to other state-of-the-art tabular prediction models (Llama 3-8B, XGBoost, TabPFN) across five benchmark datasets. The x-axis represents the number of shots (training examples provided), and the y-axis shows the open-vocabulary accuracy. The figure demonstrates that TABULA-8B consistently outperforms other methods, especially in the zero-shot and few-shot settings.

This table displays the zero-shot and few-shot performance of TABULA-8B against other state-of-the-art tabular prediction models (Llama 3-8B, XGBoost, and TabPFN) across five different benchmarks. The x-axis represents the number of shots (training examples) provided to the models, and the y-axis represents the open-vocabulary accuracy. The figure showcases that TABULA-8B significantly outperforms existing models, especially in the zero-shot and few-shot settings. The five benchmarks used are UniPredict, OpenML CC18, OpenML CTR23, AMLB, and Grinsztajn, which assess the model’s performance in different scenarios and with varied data characteristics.
This table presents a visual comparison of the performance of TABULA-8B against other state-of-the-art (SOTA) tabular prediction models across a range of benchmark tasks with varying numbers of training examples. It highlights TABULA-8B’s superior performance, especially in zero-shot and few-shot scenarios.

This table displays the zero-shot and few-shot performance of TABULA-8B, Llama 3 8B, XGBoost, and TabPFN across five tabular benchmarks. It highlights the superior performance of TABULA-8B, especially in the few-shot setting, demonstrating its ability to transfer knowledge effectively to unseen tasks with limited examples.
Full paper#