↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Contrastive learning excels in training Vision Transformers (ViTs), but its high computational demands hinder practical applications. Existing acceleration methods offer limited improvements and aren’t tailored for ViTs’ unique structure. This poses a significant challenge for researchers seeking to leverage the power of ViTs in various domains.
This research introduces a novel acceleration framework to tackle this computational challenge. It employs sequence compression strategies like randomized token dropout and flexible patch scaling, reducing the cost of gradient estimation and accelerating convergence. A novel procedure identifies an optimal acceleration schedule, ensuring efficient training without sacrificing accuracy. The approach achieves substantial speed-ups (4x for MoCo, 3.3x for SimCLR, and 2.5x for DINO) on ImageNet.
Key Takeaways#
Why does it matter?#
This paper is important because it addresses the significant computational cost of contrastive learning for Vision Transformers. By introducing novel acceleration strategies and an optimization schedule, it offers substantial efficiency gains, enabling wider adoption of these powerful models. It also provides valuable insights into the trade-offs between acceleration and performance, guiding future research in efficient self-supervised learning.
Visual Insights#

This figure demonstrates the effectiveness of the proposed accelerated MoCo-v3 method. It shows that the accelerated version achieves comparable performance to the standard MoCo-v3 model, but using significantly less training time (1/5 for ImageNet-100 and 1/3 for ImageNet-1k). The x-axis represents the training budget in millions of forward passes, and the y-axis represents the accuracy.
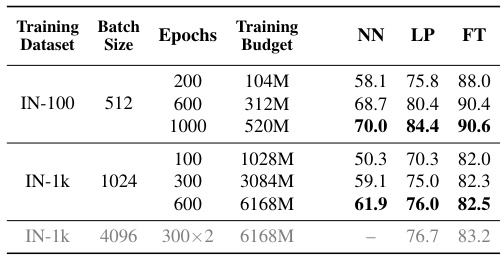
This table presents the results of non-accelerated MoCo-v3 experiments conducted on ImageNet-100 and ImageNet-1k datasets. It shows the Nearest Neighbor (NN), Linear Probe (LP), and Fine-tuning (FT) accuracies achieved under varying training budgets (measured in millions of forward passes). The last row provides a comparison with the publicly available MoCo-v3 model, noting that the number of training epochs is effectively doubled due to the use of a symmetric loss in the official implementation.
In-depth insights#
ViT Augmentation#
Vision Transformers (ViTs) process images by dividing them into patches, embedding each patch into a vector, and then processing the sequence of patch embeddings through self-attention layers. Augmentations applied to ViTs would thus focus on manipulating these patches and their sequence. Methods such as randomized token dropout, which randomly removes tokens from the input sequence, and flexible patch scaling, which changes the size of the patches before embedding, are both effective acceleration techniques. The impact of augmentations on gradient estimation error must be carefully considered. Aggressive augmentations may initially speed up training but could introduce bias in the gradient estimates as the model converges, potentially hindering downstream performance. Therefore, a dynamically adjusted augmentation strategy, adapting the augmentation strength to the training progress, is crucial to optimize both speed and accuracy. The analysis of the cost-adjusted bias-variance trade-off helps determine the optimal balance between acceleration and accuracy at various stages of training.
Gradient Acceleration#
The core idea behind gradient acceleration in the paper is to leverage the unique architectural properties of Vision Transformers (ViTs) to reduce computational costs without significantly sacrificing performance. The authors cleverly exploit ViTs’ ability to generalize across varying input sequence lengths by implementing two key strategies: randomized token dropout and flexible patch scaling. These techniques effectively compress the input sequence, leading to faster gradient estimation and quicker convergence. The method’s brilliance is not just in the compression strategies themselves, but also in the novel procedure introduced to determine an optimal acceleration schedule. By analyzing the gradient estimation error and its impact on downstream tasks, the authors dynamically adjust the compression ratios throughout training, ensuring efficient training without incurring excessive bias. This approach demonstrates significant speed improvements across different self-supervised learning algorithms and large-scale datasets, showcasing the effectiveness and generalizability of the proposed framework for accelerating ViT pretraining.
Sequence Compression#
The core idea of “Sequence Compression” in this context revolves around reducing the computational cost of processing long input sequences, particularly within Vision Transformers (ViTs). The authors cleverly exploit ViTs’ ability to generalize across varying sequence lengths by implementing two main strategies: randomized token dropout and flexible patch scaling. Token dropout randomly removes tokens from the input sequence, while patch scaling increases the size of the input patches, effectively reducing the number of patches that need to be processed. The key is finding an optimal balance: aggressive compression speeds up training but risks introducing significant gradient estimation biases, impacting downstream performance. Therefore, a novel, adaptive scheduling mechanism is proposed to dynamically adjust the compression ratio throughout training, ensuring efficiency without sacrificing accuracy. This intelligent approach highlights the importance of managing the trade-off between computational speed and the preservation of crucial information during training.
Optimal Schedules#
The concept of ‘optimal schedules’ in the context of accelerating augmentation invariance pretraining for Vision Transformers (ViTs) centers on dynamically adjusting the sequence compression ratios (token dropout and patch scaling) throughout the training process. Instead of a static compression rate, an optimal schedule adapts to the training progress. This dynamic approach is crucial because aggressive compression, while beneficial early in training to speed up convergence, can introduce significant estimation biases as the model nears convergence. The proposed method utilizes a cost-adjusted Mean Squared Error (MSE) to identify the optimal compression strategy at each training stage, balancing the reduction in computational cost with the need for accurate gradient estimates. This framework allows the model to leverage high compression early to accelerate training, then gradually shift towards less aggressive compression as the model improves, maximizing both speed and performance.
Broader Impacts#
The research paper’s “Broader Impacts” section would thoughtfully discuss how its efficient training methods for self-supervised learning models, particularly Vision Transformers, could significantly benefit the field. Reduced computational costs are a major advantage, making advanced model training accessible to researchers with limited resources and potentially accelerating progress in various AI applications. However, the potential for misuse must be acknowledged. The faster training could lower the barrier for malicious actors to develop sophisticated AI systems. Ethical considerations surrounding the deployment and use of these powerful models should be addressed, including potential biases in datasets and the responsible development of applications that minimize societal harm. The paper should advocate for open-source tools and transparency to promote ethical development and facilitate collaboration to address potential risks.
More visual insights#
More on figures
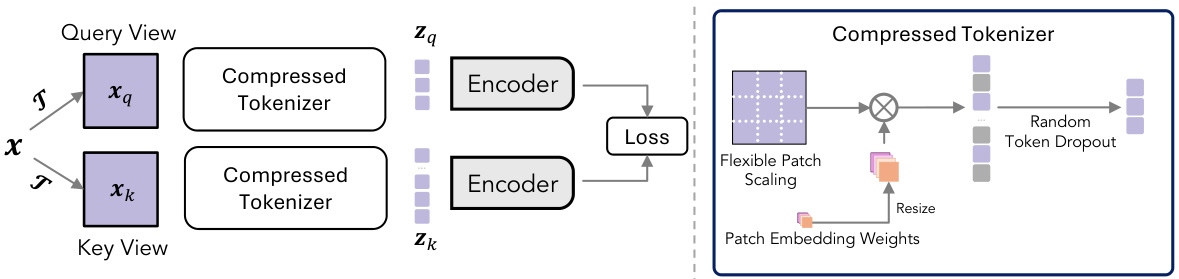
This figure illustrates the proposed framework for accelerating augmentation invariance pre-training in Vision Transformers (ViTs). It shows how two compression strategies – randomized token dropout and flexible patch scaling – reduce the input sequence length, thereby speeding up training. The framework also incorporates gradient error analysis to determine an optimal acceleration schedule.

This figure showcases the training efficiency gains of the proposed accelerated MoCo-v3 model. The plots compare the standard MoCo-v3 model with the accelerated version across two image datasets, ImageNet-100 and ImageNet-1k. The x-axis represents the training budget (time normalized by the forward pass of the base model), while the y-axis shows the model’s performance. The results demonstrate significant speedups (4x on ImageNet-100 and 3.3x on ImageNet-1k) while maintaining comparable performance to the non-accelerated model.
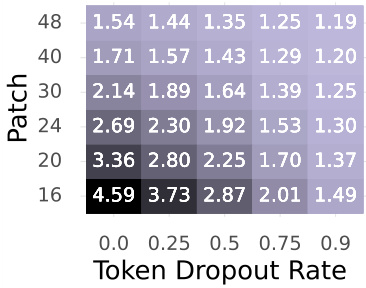
This figure shows the sample costs for the accelerated MoCo-v3 model with different combinations of token dropout rates and patch sizes. The x-axis represents the token dropout rate, ranging from 0 to 0.9, while the y-axis represents the patch size, ranging from 16 to 48. Each cell in the heatmap shows the sample cost (a normalized measure of computation time) for a specific combination of dropout rate and patch size. The heatmap illustrates the trade-off between compression level and computational cost; higher compression (larger dropout rates and larger patch sizes) results in lower sample costs, but potentially at the expense of accuracy.

This figure visualizes the trade-off between bias and variance of gradient estimates at different training stages using various acceleration strategies (different token dropout rates and patch sizes). The top panel shows the cost-adjusted mean squared error (CA-MSE), the middle panel shows the squared bias, and the bottom panel shows the cost-adjusted variance. Each panel shows the error at five different stages (0%, 25%, 50%, 75%, and 100%) of the training process. The figure helps in identifying the optimal acceleration strategy at each stage by minimizing the CA-MSE.
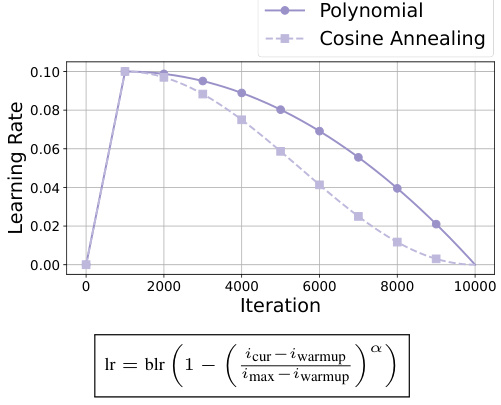
This figure compares two different learning rate decay schedules: cosine annealing and polynomial decay (with α = 2). The x-axis represents the training iteration, and the y-axis shows the learning rate. The graph illustrates how the learning rate decreases over the course of training for both methods, with the polynomial schedule maintaining a higher learning rate for a longer period than cosine annealing. This difference in learning rate decay impacts the training process and the model’s performance, especially in scenarios with constrained training budgets.
This figure visualizes the impact of different acceleration strategies on gradient estimation at various stages of training. It shows the cost-adjusted mean squared error (CA-MSE), bias, and variance of the gradient estimates. Each panel shows these measures across different acceleration strategies (varying levels of token dropout and patch size) and training progress (0%, 25%, 50%, 75%, and 100%). It helps to understand the trade-offs between acceleration (lower computation cost) and accuracy (lower error in gradient estimation).
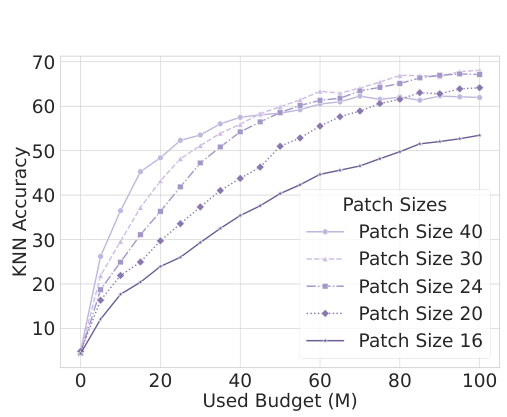
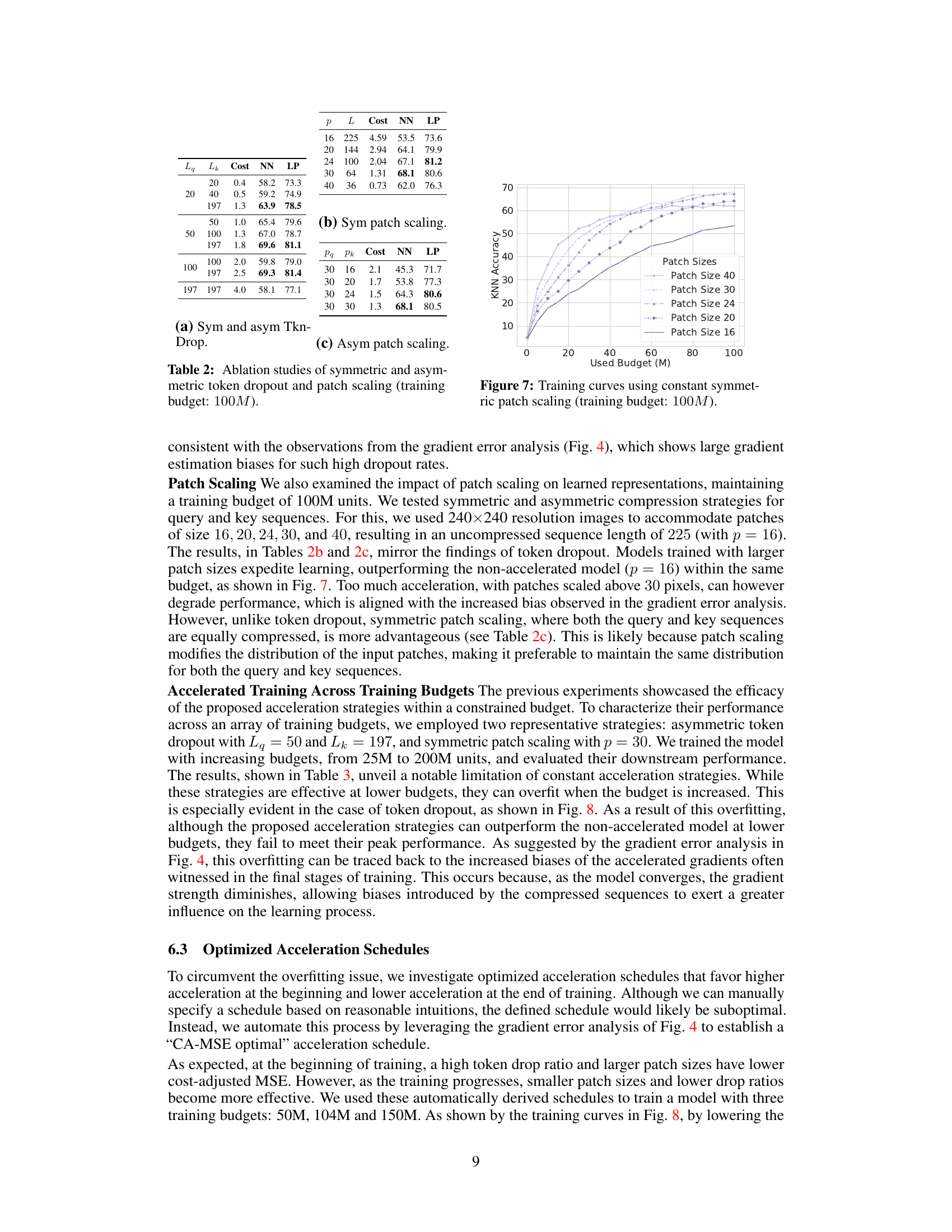
This figure shows the training curves obtained using constant symmetric patch scaling with a training budget of 100 million units. The x-axis represents the training budget used (in millions), while the y-axis shows the KNN accuracy achieved. Different colored lines represent experiments using different patch sizes (16, 20, 24, 30, and 40). The plot visually demonstrates how different patch sizes affect model training performance within the given budget constraint.

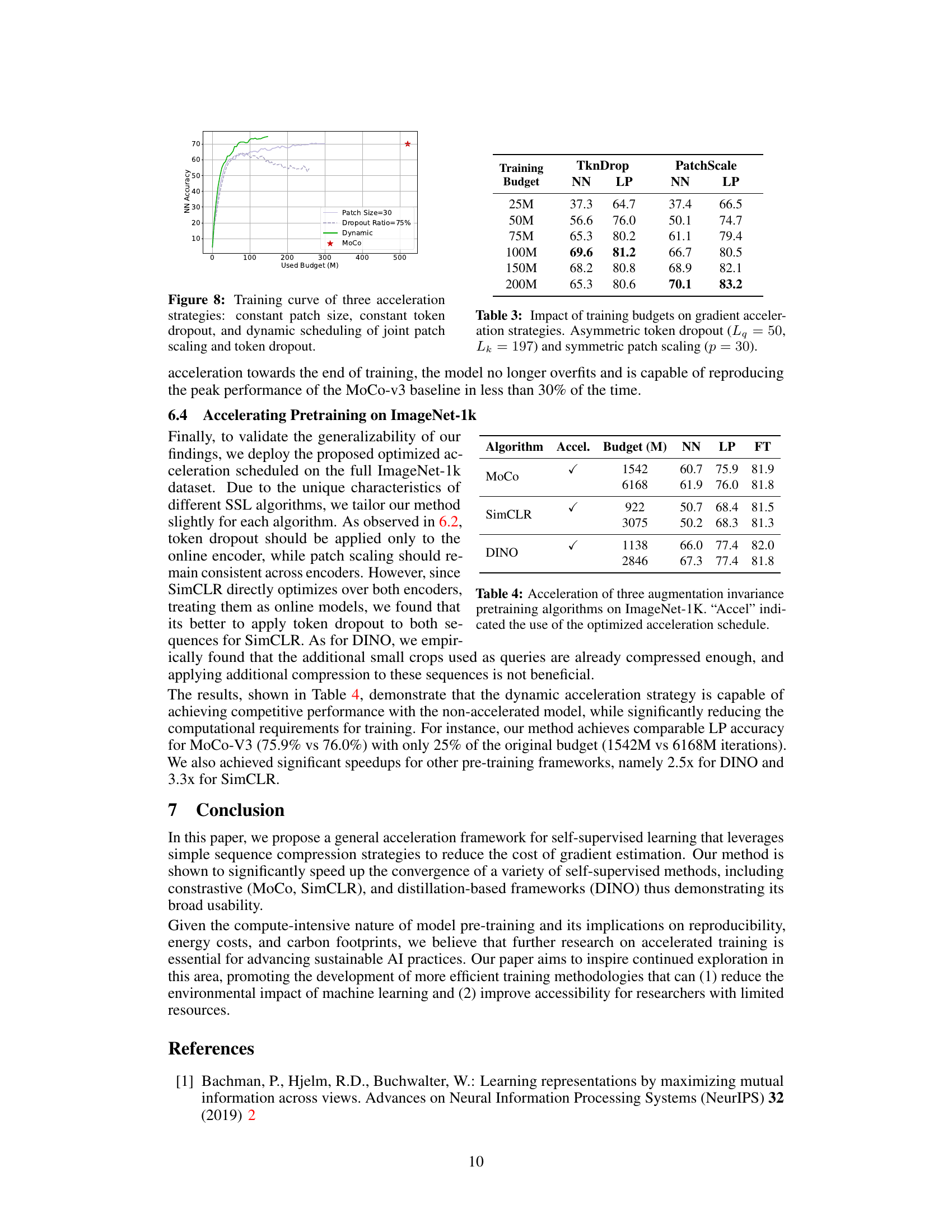
This figure compares three different acceleration strategies for training a model: using a constant patch size, a constant token dropout ratio, and a dynamic schedule that adjusts both patch size and token dropout ratio over time. The x-axis represents the training budget (in millions of units), and the y-axis shows the Nearest Neighbor (NN) accuracy achieved. The dynamic schedule outperforms the constant strategies, achieving higher accuracy with a lower budget. A star also marks the NN accuracy of the baseline MoCo model.
More on tables

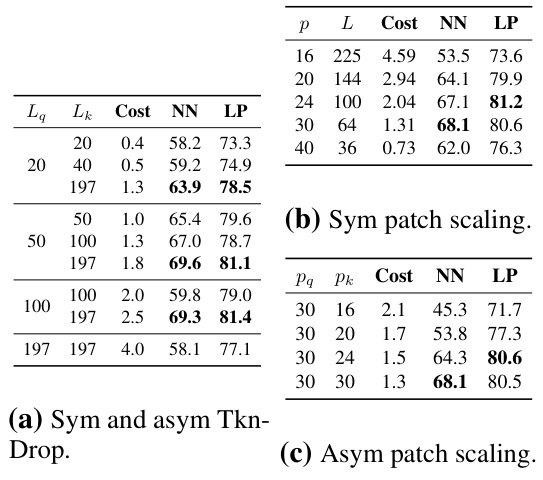
This table shows the effect of different training budgets on two gradient acceleration strategies: asymmetric token dropout and symmetric patch scaling. The results (Nearest Neighbor (NN) accuracy and Linear Probe (LP) accuracy) are presented for various budgets ranging from 25M to 200M units. The table highlights how the effectiveness of constant acceleration strategies can vary depending on the training budget, particularly concerning overfitting at higher budgets.
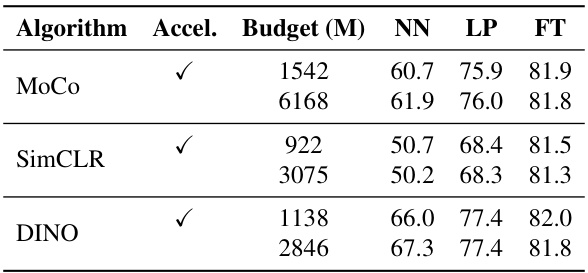
This table presents the results of applying the proposed optimized acceleration schedule to three different self-supervised learning algorithms (MoCo, SimCLR, and DINO) on the ImageNet-1K dataset. For each algorithm, it shows the Nearest Neighbor (NN) accuracy, Linear Probe (LP) accuracy, and full Fine-tuning (FT) accuracy achieved with both the accelerated and non-accelerated training approaches. The ‘Budget (M)’ column indicates the training budget in millions of forward pass units. The results demonstrate the effectiveness of the acceleration techniques, showing improvements in training speed without significant performance degradation.
Full paper#