↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Multi-entity action recognition struggles with inconsistencies in how different entities (e.g., people in a group) are represented in skeleton data. This leads to lower accuracy in identifying group activities. Existing methods often fail to adequately address the problem of differing data distributions between entities, resulting in suboptimal performance.
The researchers introduce CHASE, a novel method that uses a learnable network to adjust the positions of skeletons, effectively normalizing the data and reducing bias. CHASE uses an additional objective function that minimizes the differences between entity distributions. Results across six datasets show significant performance improvements, highlighting CHASE’s effectiveness in adapting to various single-entity backbones and enhancing multi-entity action recognition.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in multi-entity action recognition because it addresses a critical limitation of existing models: the inherent distribution discrepancies among entity skeletons. By proposing CHASE, a novel method to mitigate these discrepancies, the research opens up new avenues for improving the accuracy and robustness of multi-entity action recognition systems, impacting applications in human-robot interaction, scene understanding, and beyond. The adaptable nature of CHASE makes it highly relevant to current research trends, enabling seamless integration with various single-entity backbones.
Visual Insights#
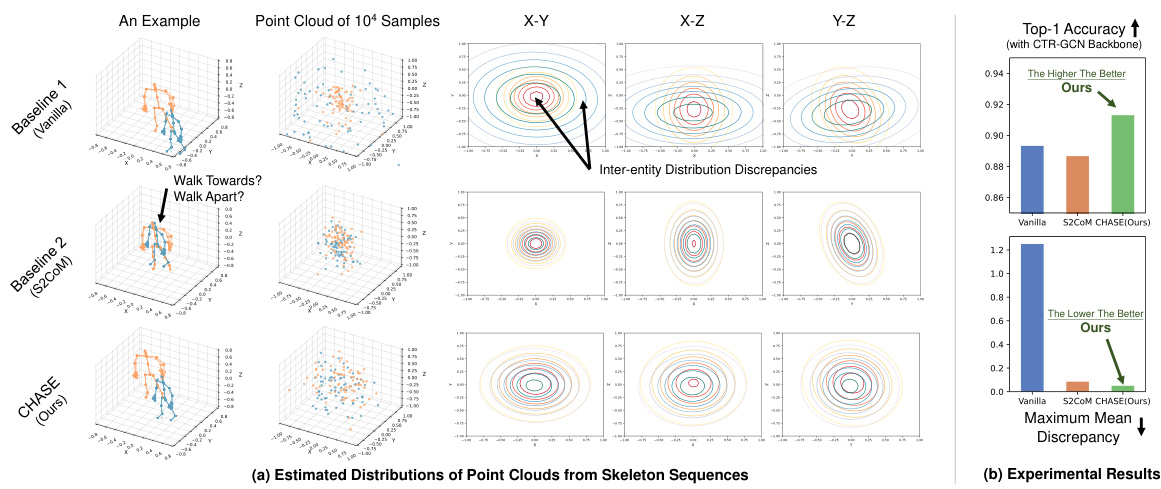
This figure compares three different approaches for multi-entity action recognition: Vanilla, S2CoM, and the proposed CHASE method. It shows that Vanilla suffers from significant inter-entity distribution discrepancies, leading to poor performance. S2CoM improves the situation but loses inter-entity information. CHASE achieves the best performance by effectively mitigating the distribution discrepancies and unbiasing the backbone model.
This table presents a comparison of the proposed CHASE method with several existing skeleton-based methods for multi-entity action recognition across six different datasets. The datasets cover various types of multi-entity actions and complexities. For each dataset and method, the table shows the top-1 accuracy, demonstrating the performance improvement achieved by incorporating CHASE into the baseline models.
In-depth insights#
Inter-entity Gaps#
The concept of “Inter-entity Gaps” in multi-entity action recognition highlights the challenges arising from discrepancies in the distribution of skeletal data across different entities. These gaps hinder the performance of models trained on individual entities because the models struggle to generalize effectively to scenarios with multiple, diverse interacting entities. The core issue lies in the non-independent and identically distributed (non-i.i.d.) nature of entity data. Methods that assume i.i.d. data, such as simple averaging of individual entity features, perform poorly due to these inherent distribution differences. Addressing these gaps is crucial for improving the accuracy and robustness of multi-entity action recognition systems. Effective solutions likely involve techniques that can model inter-entity relationships, normalize data to mitigate distribution discrepancies, or leverage more robust learning techniques that can handle data heterogeneity.
CHASE Method#
The CHASE method, designed for skeleton-based multi-entity action recognition, tackles the challenge of inherent distribution discrepancies among entity skeletons. Its core innovation is a learnable parameterized network that adaptively repositions skeleton sequences, ensuring the new coordinate system origin remains within the skeleton’s convex hull. This repositioning, guided by a coefficient learning block, mitigates inter-entity distribution gaps. Further enhancing performance is the inclusion of a mini-batch pair-wise maximum mean discrepancy as an auxiliary objective, further minimizing distribution discrepancies. CHASE acts as a sample-adaptive normalization method, effectively reducing data bias and significantly boosting the accuracy of single-entity backbones applied to multi-entity action recognition scenarios. The method’s effectiveness is demonstrated through rigorous experiments across multiple datasets, showcasing its adaptability and superior performance.
Ablation Study#
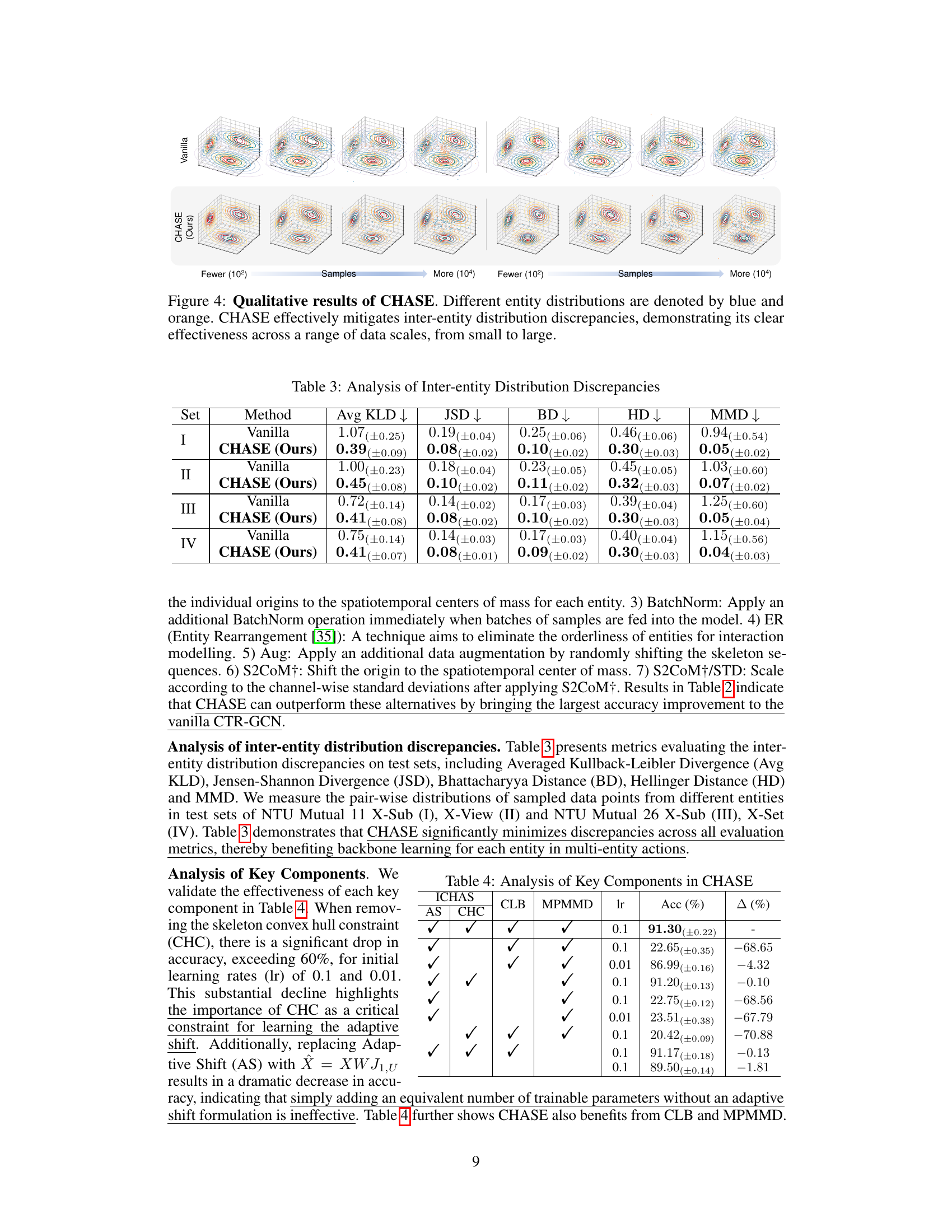
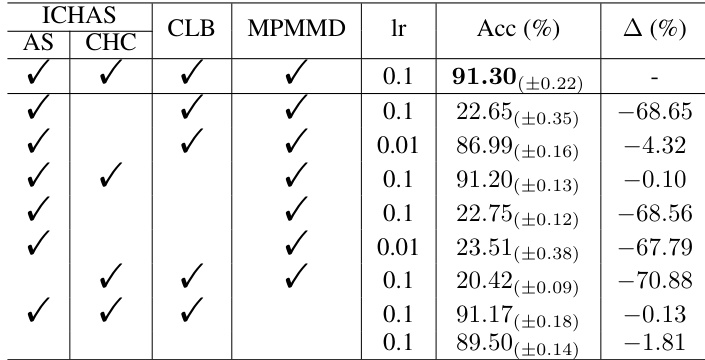
An ablation study systematically removes components of a model to assess their individual contribution. In the context of a multi-entity action recognition model, this might involve removing the proposed Convex Hull Adaptive Shift (CHAS), the Coefficient Learning Block (CLB), or the Mini-batch Pair-wise Maximum Mean Discrepancy (MPMMD) loss. By comparing the performance of the complete model to variants with these components removed, the researchers can quantify the impact of each element. Results would show the relative importance of each component to the overall accuracy and efficiency. The ablation study is crucial for demonstrating that each part of the model is necessary and contributes meaningfully. This is vital for establishing the model’s efficacy and providing a deep understanding of its inner workings. A well-designed ablation study strengthens the paper’s claims by providing empirical evidence for the design choices and helping to rule out alternative explanations for improved performance. It should show that the CHAS is not merely a coincidental improvement but a key element, and the other components are similarly necessary. By presenting these findings, the researchers build trust in their overall approach and increase the impact of their work. Finally, the ablation study can reveal potential areas for future development; for example, identifying components that are particularly impactful and therefore warrant further investigation or optimization.
Future Works#
Future work could explore extending CHASE’s adaptability to a wider variety of backbones and datasets, potentially improving its robustness and generalizability. Investigating the impact of different input modalities (e.g., RGB video, inertial data) in conjunction with skeletal data is warranted to potentially enhance performance and address limitations in scenarios with occlusions or limited visibility. A key area for future development is a more sophisticated method for handling varying numbers of entities and inter-entity interactions, moving beyond simple averaging techniques. Research into more efficient optimization strategies could reduce computational costs and enhance real-time applicability. Finally, exploring the potential of CHASE for other related tasks like group activity recognition, human-robot interaction, or abnormal behavior detection, should be explored, given CHASE’s focus on multi-entity interaction understanding. Addressing these areas would significantly advance the field of skeleton-based multi-entity action recognition.
Limitations#
A research paper’s limitations section is crucial for demonstrating critical thinking and acknowledging the study’s boundaries. It should transparently address methodological shortcomings, such as sample size limitations, the generalizability of findings to different populations, or the use of specific models or datasets that might influence results. Transparency regarding the reliability and validity of measurements and data is paramount. A robust limitations section should also discuss potential biases arising from study design, data collection, or analysis techniques, highlighting areas where the research’s conclusions might be less certain. A thoughtful exploration of these limitations adds significant value, demonstrating a mature and nuanced understanding of the research process. By openly discussing shortcomings and their potential impacts, authors enhance the credibility of their work and provide valuable insights for future research. This fosters a constructive environment for scientific advancement and reduces overstated claims that may not be fully supported by the evidence provided.
More visual insights#
More on figures
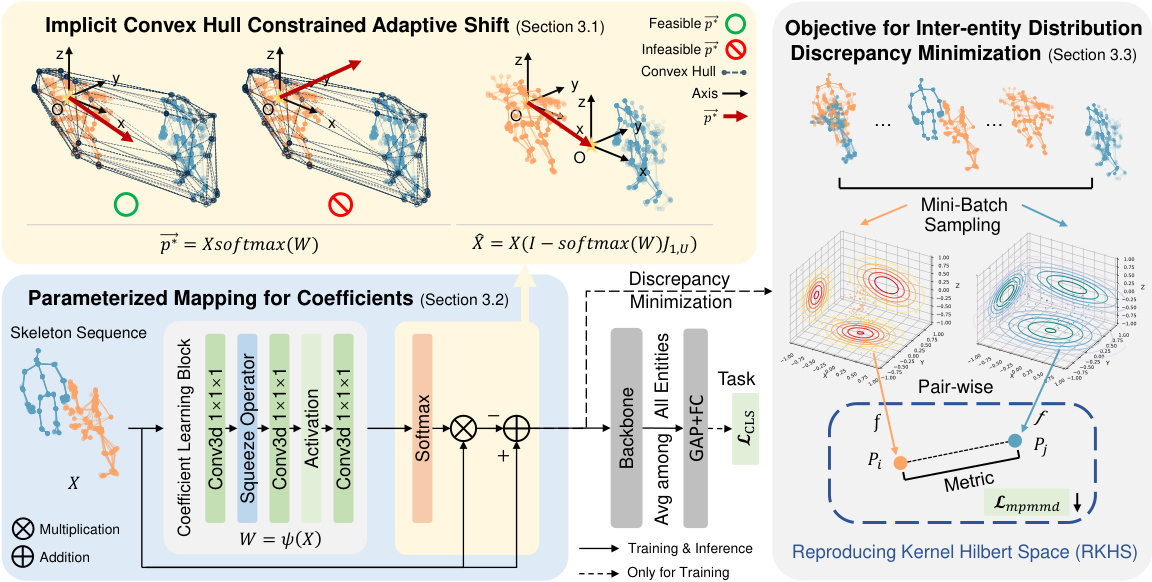
This figure illustrates the architecture of the CHASE model, which is composed of three main parts: Implicit Convex Hull Constrained Adaptive Shift, Coefficient Learning Block, and Mini-batch Pair-wise Maximum Mean Discrepancy. The Implicit Convex Hull Constrained Adaptive Shift is responsible for shifting the skeleton sequences so that the origin is within the convex hull of the skeletons. The Coefficient Learning Block is a lightweight parameterized network that learns the coefficients of the convex combinations used to calculate the shift. The Mini-batch Pair-wise Maximum Mean Discrepancy is an additional objective that is used to minimize the inter-entity distribution discrepancies.

This figure shows examples of multi-entity action samples from six different datasets used in the paper: NTU Mutual 11, NTU Mutual 26, H2O, ASB101, CAD, and VD. For each dataset, several sample sequences are displayed, along with a visualization of their skeleton convex hulls. The visualization helps to illustrate the complexity and diversity of the multi-entity actions, and the differences in the spatial distribution of the skeletons within these actions.
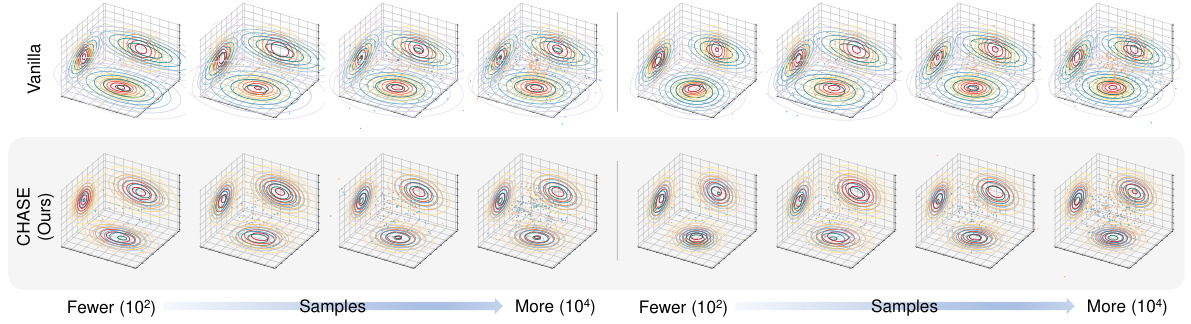
This figure shows the effectiveness of the CHASE method in mitigating inter-entity distribution discrepancies across various data scales. The top row displays visualizations of entity distributions using a standard approach (Vanilla). The bottom row displays visualizations when using CHASE. Different colors represent different entities, and the density of points corresponds to the concentration of data points. By comparing the top and bottom rows, one can see that CHASE effectively reduces discrepancies in the distribution of entities.
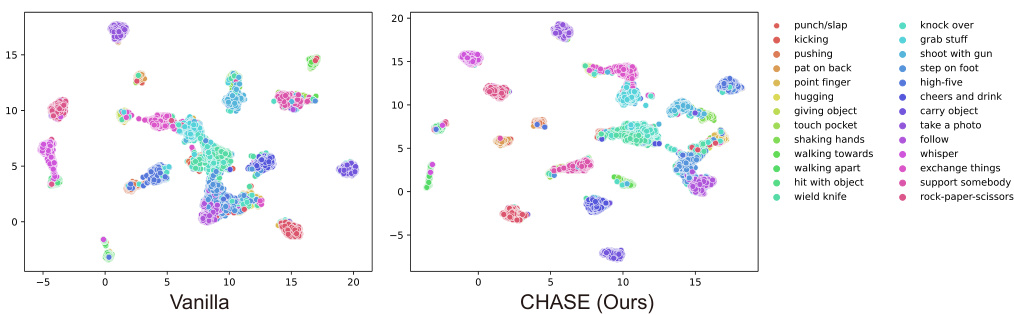
This figure shows the results of applying UMAP dimensionality reduction to multi-entity skeleton sequence representations from the NTU Mutual 26 X-Sub test set. Two UMAP plots are presented: one for a baseline method (‘Vanilla’) and one for the proposed CHASE method. The plots visually represent the learned feature embeddings. The key observation is that CHASE produces more distinct and separable clusters of data points corresponding to different action classes, compared to the Vanilla approach, indicating that CHASE helps the backbone model learn more distinctive representations for multi-entity actions.
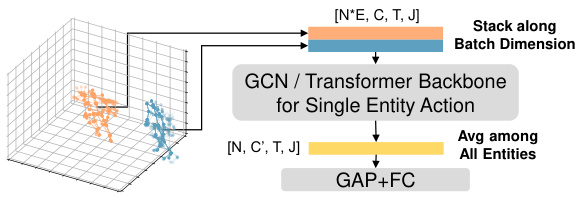
This figure illustrates a common practice in multi-entity action recognition: treating each entity independently using a single-entity backbone, and averaging their features for recognition. This method assumes entities are independent and identically distributed (i.i.d.), which is often not the case in practice. The figure shows how individual entity features are extracted, averaged, and finally processed by a global average pooling and fully connected layer. This approach can lead to suboptimal performance due to the inherent distribution discrepancies among entity skeletons.
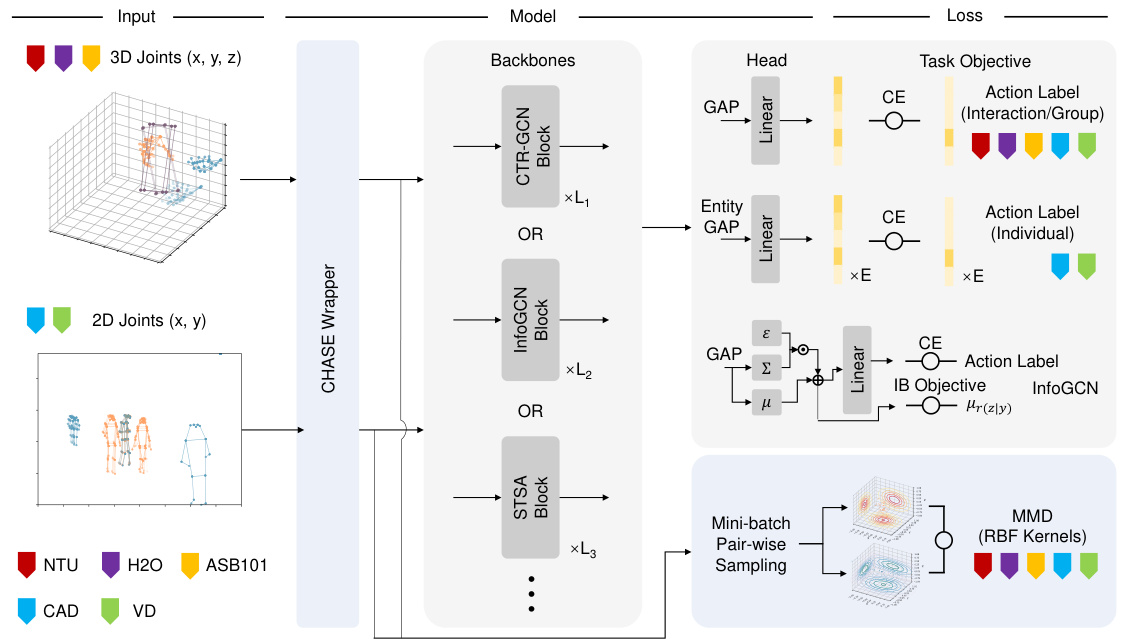
This figure illustrates the architecture of CHASE, a method for multi-entity action recognition. CHASE uses an implicit convex hull constrained adaptive shift to reposition skeleton sequences, mitigating inter-entity distribution discrepancies. A Coefficient Learning Block acts as a lightweight wrapper for the backbone network. An additional objective, based on mini-batch pairwise maximum mean discrepancy, is used to further reduce the inter-entity distribution discrepancies.

This figure shows a qualitative comparison of the effectiveness of CHASE in mitigating inter-entity distribution discrepancies across different datasets with varying sample sizes. The visualizations demonstrate how CHASE effectively reduces the discrepancies between different entities, leading to improved performance in multi-entity action recognition. The use of blue and orange to represent different entity distributions enhances the clarity of the comparison.

This figure illustrates the problem of inter-entity distribution discrepancies in multi-entity action recognition. It compares three different approaches: Vanilla (standard method), S2CoM (a baseline method), and CHASE (the proposed method). The figure shows that Vanilla has significant inter-entity distribution discrepancies, leading to poor performance. S2CoM reduces the discrepancies but loses inter-entity information, also resulting in poor performance. CHASE mitigates the discrepancies and improves performance, demonstrating its efficacy.
This figure compares three approaches for multi-entity action recognition: Vanilla, S2CoM, and CHASE. It visualizes the inter-entity distribution discrepancies in the feature space using point clouds projected onto different planes. The results show that Vanilla suffers from significant discrepancies, while S2CoM reduces them but at the cost of losing inter-entity information. CHASE achieves the lowest discrepancy and best accuracy.
More on tables

This table presents an ablation study comparing the performance of CHASE against several alternative methods on the NTU Mutual 26 benchmark. The methods compared include Vanilla (baseline), S2CoM (a simple shift to the center of mass), BatchNorm (batch normalization), ER [35] (Entity Rearrangement), Aug (data augmentation), S2CoM+/STD (S2CoM with scaling), S2CoM+ (S2CoM with other improvements), and CHASE (the proposed method). The table shows the top-1 accuracy and the percentage change in accuracy compared to the Vanilla baseline for each method.
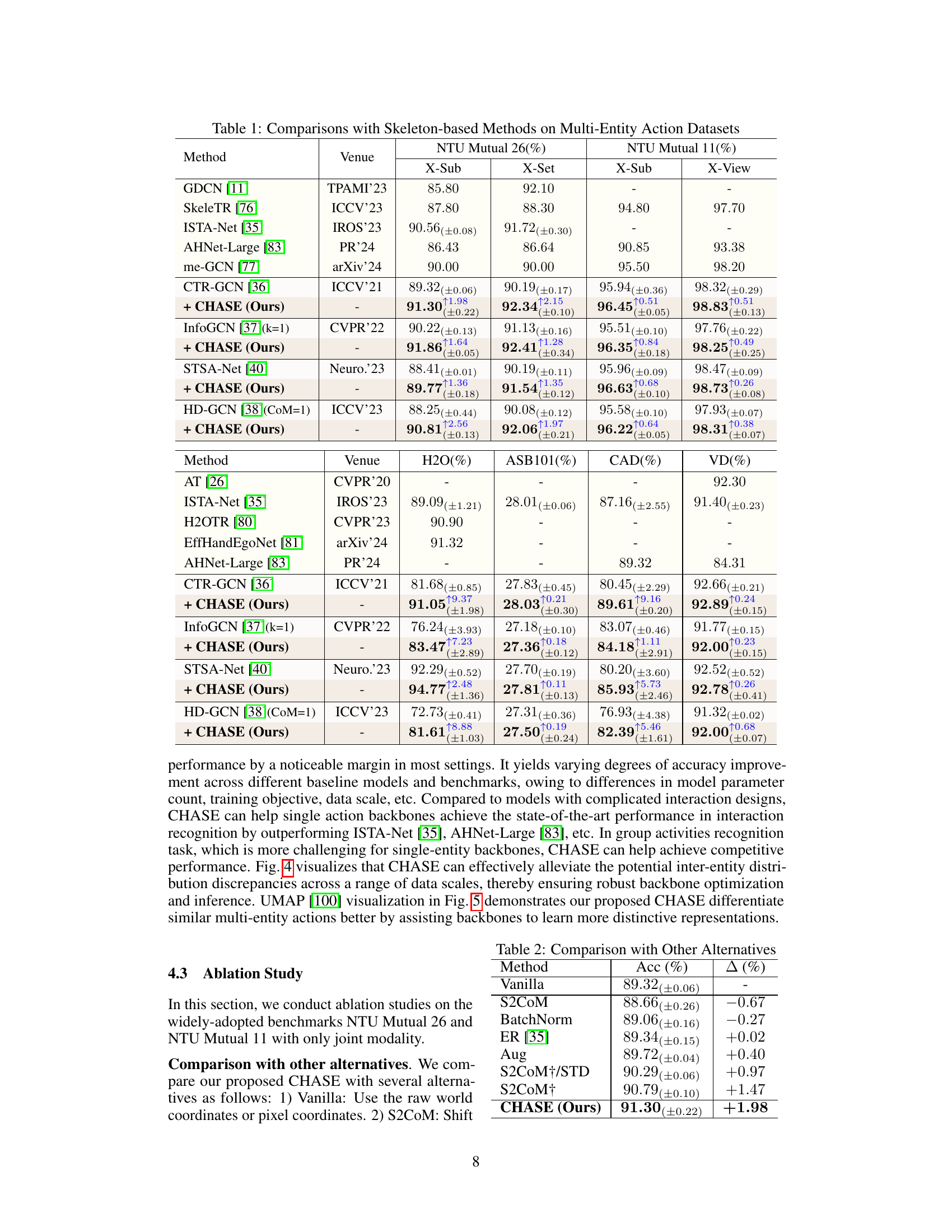
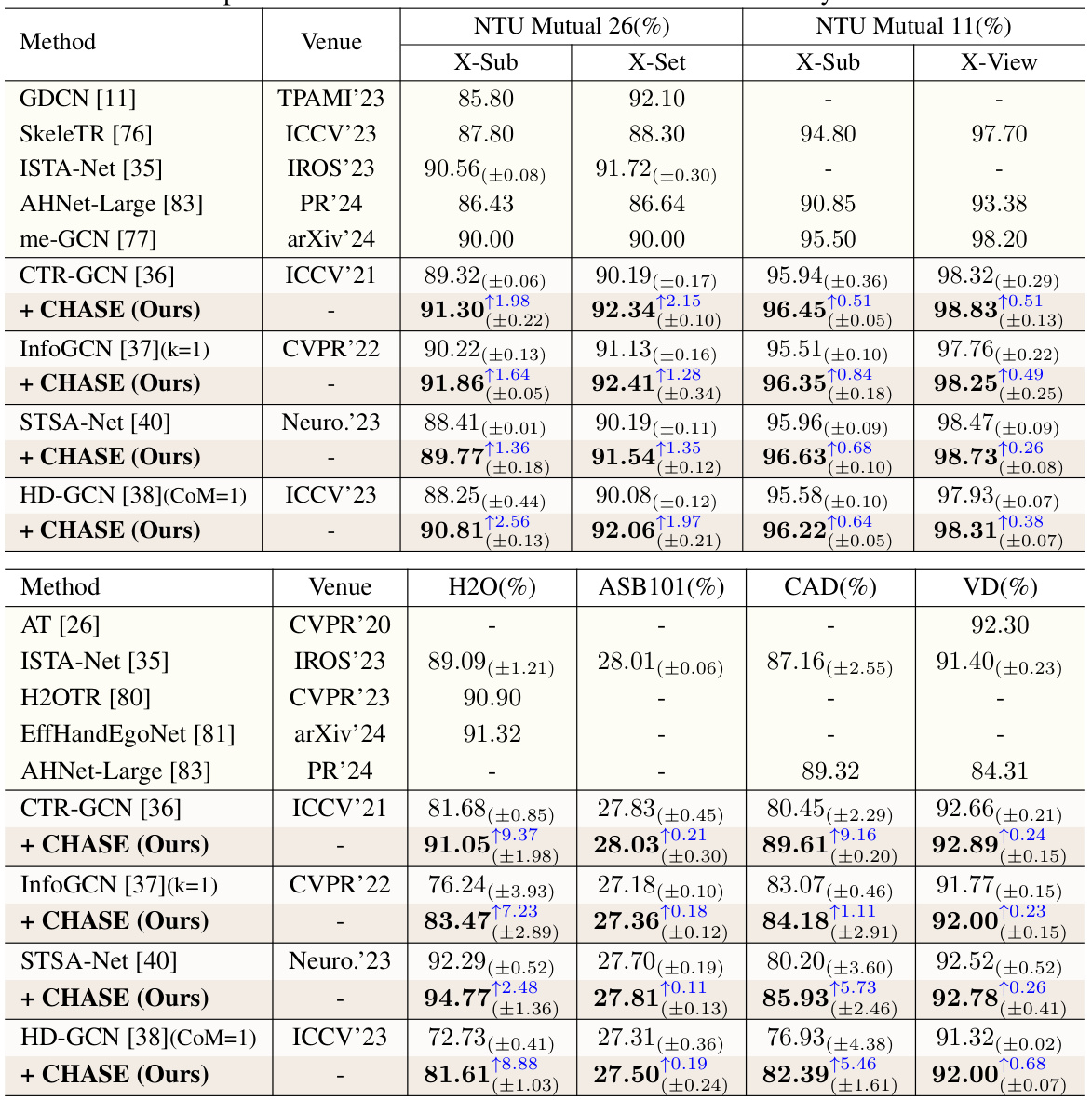
This table compares the proposed CHASE method with several existing skeleton-based methods on six multi-entity action recognition datasets (NTU Mutual 11, NTU Mutual 26, H2O, ASB101, CAD, and Volleyball). The table shows the top-1 accuracy (%) achieved by each method on each dataset, highlighting the performance improvement gained by incorporating CHASE into various baseline models. This demonstrates CHASE’s effectiveness in boosting the performance of single-entity backbones in multi-entity action recognition scenarios.

This table compares the performance of the proposed CHASE method with several existing skeleton-based methods for multi-entity action recognition across multiple datasets (NTU Mutual 11, NTU Mutual 26, H2O, ASB101, CAD, and VD). It shows the top-1 accuracy and standard deviation for each method and dataset, highlighting the improvement achieved by incorporating CHASE.

This table compares the performance of the proposed CHASE method against several existing skeleton-based methods on six multi-entity action recognition datasets. It shows the top-1 accuracy and standard deviation for each method on different subsets of the datasets (e.g., X-Sub, X-View, X-Set). The table highlights the improvements achieved by adding CHASE to various baseline models.
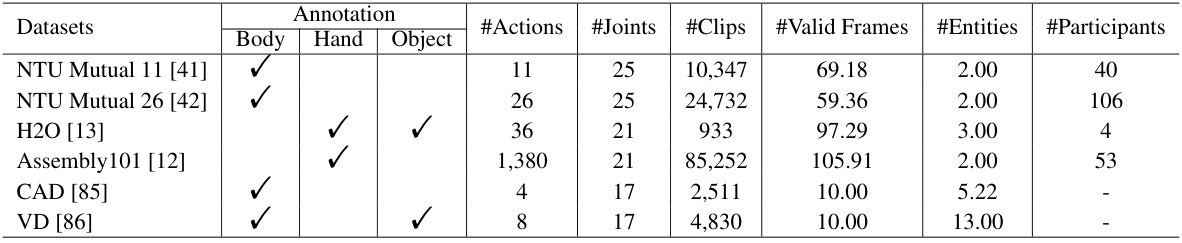
This table provides a statistical overview of six multi-entity action recognition datasets used in the paper. For each dataset, it lists the number of actions, number of joints, number of clips, number of valid frames, average number of entities, and the number of participants involved. The annotation columns indicate which type of data is available: body, hand, and object. This information is crucial for understanding the scale and characteristics of the datasets used to evaluate the proposed CHASE method.

This table compares the performance of the proposed CHASE method with several existing skeleton-based methods on six different multi-entity action recognition datasets. The results are presented as the averaged top-1 accuracy and standard deviation across multiple runs with different random initializations. The table allows for a comparison of CHASE’s performance against both vanilla counterparts (single-entity methods used in a multi-entity setting) and state-of-the-art multi-entity methods on various benchmarks.

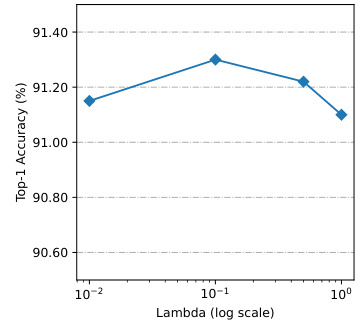
This table presents the ablation study on different segment sizes used in the squeeze operator within the Coefficient Learning Block (CLB) of the proposed CHASE method. The segment size determines the subset of points in a multi-entity action sequence to which the Implicit Convex Hull Constrained Adaptive Shift (ICHAS) is applied. The results show that using the global ICHAS with a segment size of (1, 1, 1), applying it to all points, achieves the best performance compared to other settings. This suggests that a global adaptive shift is most effective for this task.

This table presents a comparison of the proposed CHASE method with several existing skeleton-based methods on six multi-entity action recognition datasets. The results are shown as the average top-1 accuracy and standard deviation across multiple runs with different random initializations. The datasets include NTU Mutual 11, NTU Mutual 26, H2O, ASB101, Collective Activity, and Volleyball. It demonstrates the performance improvement achieved by integrating CHASE with various single-entity backbones.
Full paper#