↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Monocular 3D object detection is crucial for autonomous systems but struggles with object occlusions, significantly impacting the accuracy of depth, dimension, and orientation predictions. Existing methods often ignore or inadequately address this challenge, leading to performance degradation, especially in complex scenes with frequent occlusions.
To mitigate this, the paper proposes MonoMAE, a novel approach that leverages masked autoencoders. MonoMAE incorporates a depth-aware masking strategy to selectively mask portions of non-occluded objects during training, simulating the effect of occlusions. A lightweight query completion network then reconstructs these masked features, enabling the model to learn robust representations that are less sensitive to occlusions. Experiments demonstrate that MonoMAE significantly outperforms existing methods, particularly in scenarios with high occlusion rates. This showcases its effectiveness in handling real-world conditions and advancing the state-of-the-art in monocular 3D object detection.
Key Takeaways#
Why does it matter?#
This paper is important because it tackles the pervasive issue of object occlusion in monocular 3D object detection, a significant challenge in autonomous driving and robotics. By introducing a novel depth-aware masking and reconstruction technique, it significantly improves the accuracy of 3D object detection, especially for occluded objects. This opens new avenues for research in robust 3D perception, advancing the development of more reliable and safer autonomous systems. The generalizable nature of the proposed method also makes it highly relevant to broader computer vision research.
Visual Insights#
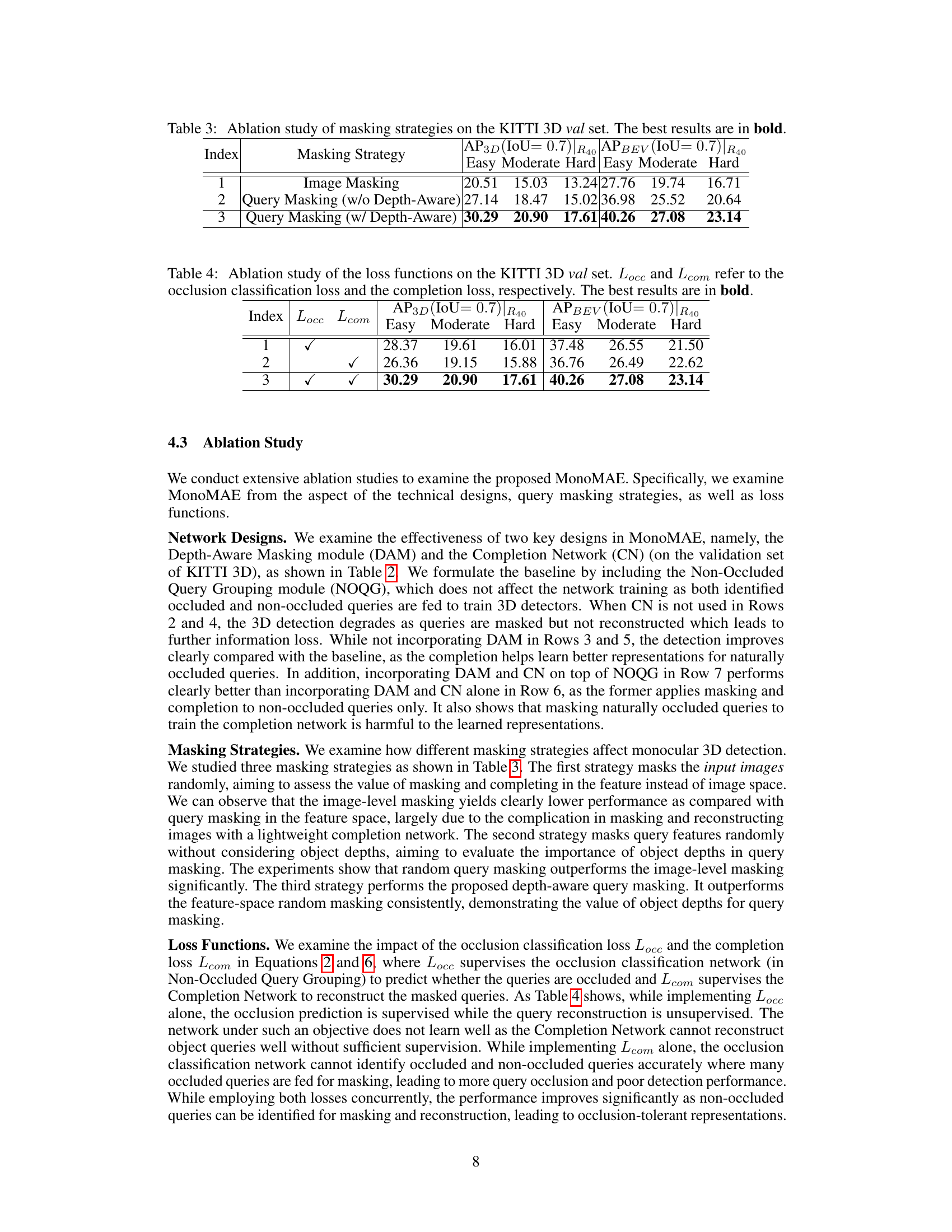
This figure shows the impact of object occlusion on monocular 3D object detection. Subfigure (a) illustrates the prevalence of occlusion in the KITTI dataset, highlighting that a significant portion of cars are occluded. Subfigure (b) presents a performance comparison of existing methods (GUPNet and MonoDETR) and the proposed MonoMAE on both occluded and non-occluded objects in 3D and bird’s-eye-view (BEV) perspectives. The results demonstrate that MonoMAE significantly outperforms existing methods, particularly in handling occluded objects.
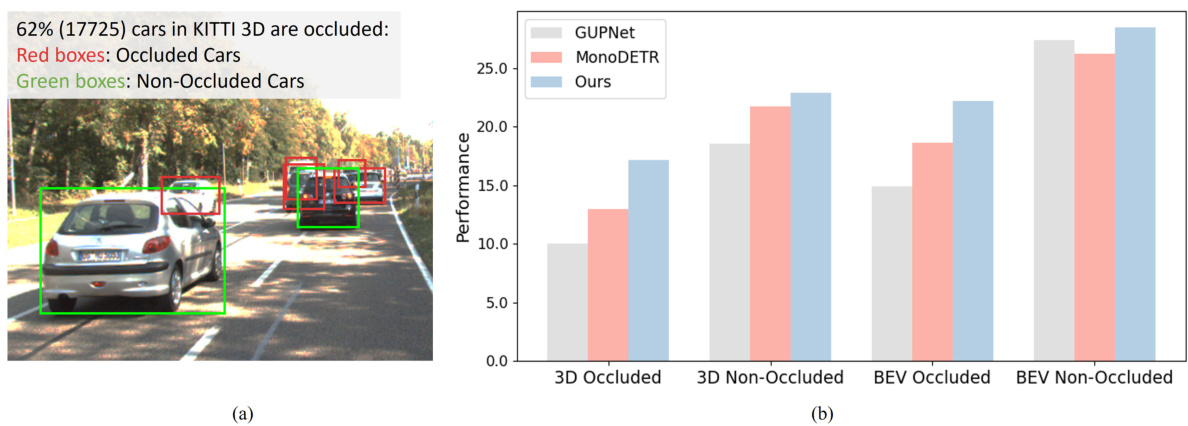
This table presents a comparison of the proposed MonoMAE method against several state-of-the-art monocular 3D object detection methods on the KITTI 3D test set. The performance is evaluated using the Average Precision (AP) at Recall 40 (R40) metric with an Intersection over Union (IoU) threshold of 0.7. The results are shown separately for easy, moderate, and hard difficulty levels, and for both 3D and Bird’s Eye View (BEV) object detection. The best performing method for each metric is highlighted in bold, and the second-best is underlined.
In-depth insights#
Depth-Aware Masking#
Depth-aware masking, a crucial technique in MonoMAE, intelligently addresses the challenge of object occlusion in monocular 3D object detection. Instead of randomly masking features, as in traditional masked autoencoders, it leverages depth information to adaptively mask non-occluded object queries. This approach is particularly insightful because it simulates real-world occlusions more effectively. Objects closer to the camera are more likely to be partially occluded, thus this method ensures these are masked with a higher ratio, balancing masked and preserved query portions. This adaptive masking process generates training samples that better reflect the complexities of real-world visual data, improving the model’s robustness to occlusion. By focusing on a feature-space approach rather than directly manipulating the input image, MonoMAE avoids the computational challenges of image-space reconstruction and facilitates the learning of more generalized and occlusion-tolerant representations.
Occlusion Handling#
The paper tackles the pervasive issue of object occlusion in monocular 3D object detection. MonoMAE, the proposed method, directly addresses occlusions in the feature space rather than the image space, a significant departure from existing techniques. This approach avoids the complexity of reconstructing occluded regions in raw image data. Instead, depth-aware masking selectively masks portions of non-occluded object queries based on depth information, effectively simulating occluded queries during training. A lightweight query completion network then learns to reconstruct these masked queries, resulting in more robust and occlusion-tolerant representations. This two-pronged approach, combining depth-aware masking and completion, allows MonoMAE to learn more comprehensive 3D features, leading to improved performance on both occluded and non-occluded objects. The strategy shows promise in enhancing the generalizability of monocular 3D object detectors.
MonoMAE Framework#
The MonoMAE framework innovatively tackles the pervasive issue of object occlusion in monocular 3D object detection. It leverages a masked autoencoder approach, but instead of masking image pixels directly, it operates in the feature space. This is a key distinction, offering computational efficiency during inference. The framework introduces depth-aware masking, intelligently masking non-occluded object queries based on their depth information to simulate occlusions. This adaptive masking is combined with a lightweight query completion network that reconstructs the masked features, thereby learning occlusion-robust representations. The entire framework is designed to improve the accuracy of 3D object detection, particularly for occluded objects, while maintaining computational efficiency making it a promising advancement in the field.
Ablation Experiments#
Ablation experiments systematically remove components of a model to assess their individual contributions. In this context, the authors likely investigated the impact of key components, such as the depth-aware masking module, the completion network, and different masking strategies, on the overall performance. By removing these parts one at a time and measuring the resulting performance drop, they could quantify the impact of each component and highlight the importance of each design choice. Results would show whether the proposed depth-aware masking significantly improved accuracy compared to random masking and whether the completion network effectively reconstructed occluded regions to improve robustness. The ablation study also sheds light on whether the individual components work synergistically or independently, offering valuable insights into the design’s effectiveness. Analyzing the quantitative results of these experiments helps to understand which model choices are the most critical for achieving superior performance. This rigorous experimental methodology strengthens the paper’s claims and provides strong evidence for the model’s effectiveness.
Future Directions#
Future research directions for MonoMAE could explore more sophisticated masking strategies that better simulate real-world occlusions. Instead of relying solely on depth, incorporating contextual information, such as object segmentation or relative object positions, could create more realistic and challenging training scenarios. Additionally, exploring alternative network architectures, such as transformers with more advanced attention mechanisms, or hybrid approaches that integrate convolutional and transformer components, could improve the model’s efficiency and performance. Another key area of focus should be enhancing generalization across different domains and datasets. This could involve training on larger, more diverse datasets or developing domain adaptation techniques to transfer knowledge effectively to new environments. Finally, investigating methods to improve inference speed and reduce computational complexity is crucial for real-world applications. This might involve exploring lightweight networks or efficient attention mechanisms. Addressing these future directions will lead to a more robust and versatile monocular 3D object detection system.
More visual insights#
More on figures

This figure illustrates the training process of the MonoMAE model. It starts with a single image input, which is processed by a 3D backbone to generate a sequence of 3D object queries. These queries are then classified into occluded and non-occluded groups. The non-occluded queries are masked using a depth-aware masking technique, simulating the effect of occlusion. A completion network reconstructs these masked queries. Finally, both the completed (reconstructed) and originally occluded queries are used to train a 3D detection head, allowing the model to learn from both occluded and non-occluded objects.
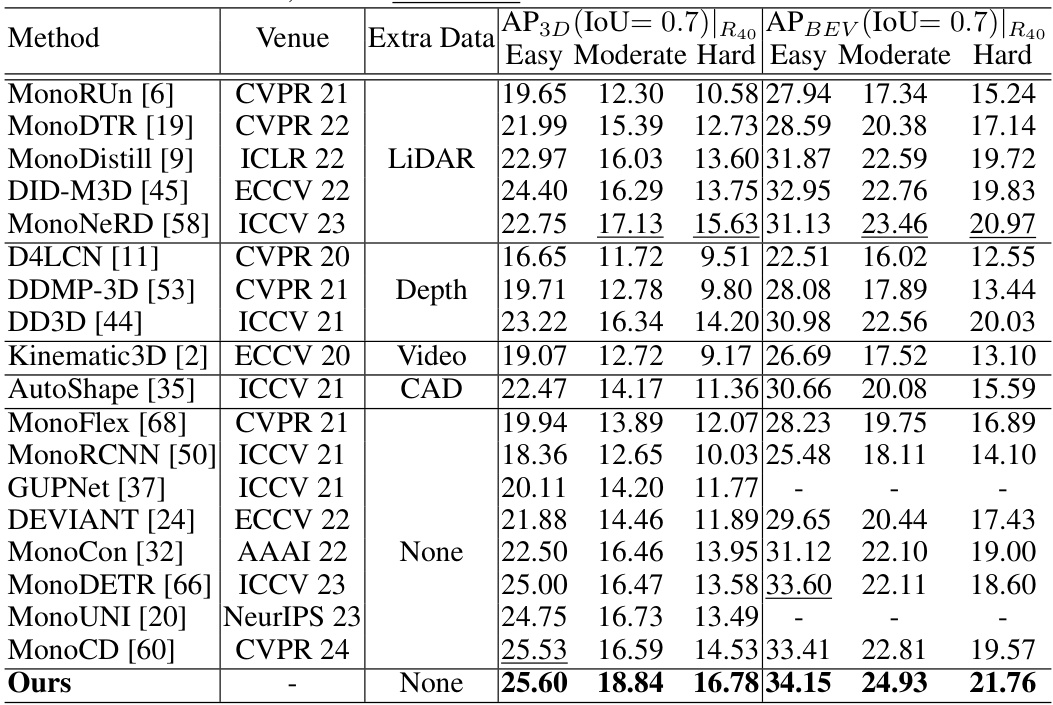
This figure illustrates the Depth-Aware Masking mechanism used in MonoMAE. Panel (a) shows a 3D visualization of objects at varying distances from the camera, highlighting how objects farther away appear smaller and contain less visual information. Panel (b) details how the masking process works: non-occluded object queries are masked adaptively based on their depth; closer objects have a larger mask ratio applied to simulate occlusion. This adaptive masking compensates for the information loss associated with distant objects.

This figure compares the detection results of MonoMAE against two state-of-the-art methods (GUPNet and MonoDETR) on the KITTI validation dataset. It shows example images (top row) and their corresponding bird’s-eye-view (BEV) representations (bottom row) for two different cases. Red boxes indicate ground truth annotations, green boxes show MonoMAE’s predictions, and blue boxes are for the other two methods. Red arrows highlight objects where the predictions of the different models significantly differ, illustrating the superior performance of MonoMAE in handling object occlusion. Note that the LiDAR point cloud is used for visualization only and isn’t part of the MonoMAE training process.
More on tables
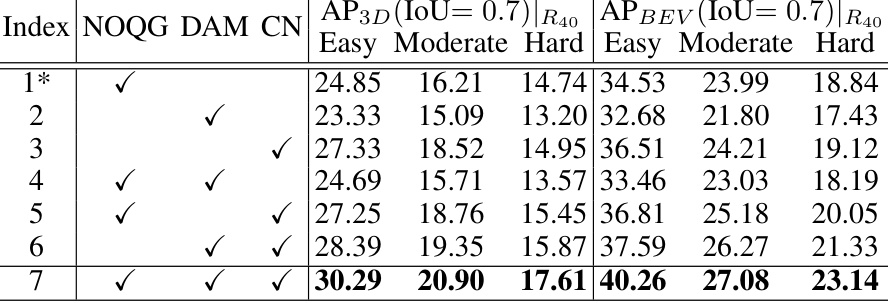
This table presents the ablation study results on the KITTI 3D validation set to analyze the impact of different components of MonoMAE. It shows the performance (AP3D and APBEV) under various configurations of the model, including with and without the Non-Occluded Query Grouping (NOQG), Depth-Aware Masking (DAM), and Completion Network (CN). The baseline model (*) includes only NOQG. The results help to understand the contribution of each component to the overall performance.

This table presents the results of an ablation study that examines the effectiveness of different masking strategies used in the MonoMAE model. Three masking strategies are compared: Image Masking, Query Masking (without Depth-Aware), and Query Masking (with Depth-Aware). The table shows the Average Precision (AP) for different levels of object occlusion (Easy, Moderate, Hard) in both 3D and Bird’s Eye View (BEV) perspectives. The results demonstrate that Depth-Aware Query Masking significantly improves the performance of the model compared to the other methods.

This table shows the ablation study results on the KITTI 3D validation set by varying the loss functions used in MonoMAE. It compares the performance (AP3D and APBEV) with different combinations of the occlusion classification loss (Locc) and the completion loss (Lcom). Row 3 shows the best overall performance, indicating that using both loss functions is crucial for optimal results.

This table compares the inference time in milliseconds (ms) of five different monocular 3D object detection methods: GUPNet [37], MonoDTR [19], MonoDETR [66], MonoMAE without the Completion Network (Ours*), and MonoMAE with the Completion Network (Ours). The results show that MonoMAE (with or without the completion network) generally has a faster inference speed than the other methods.
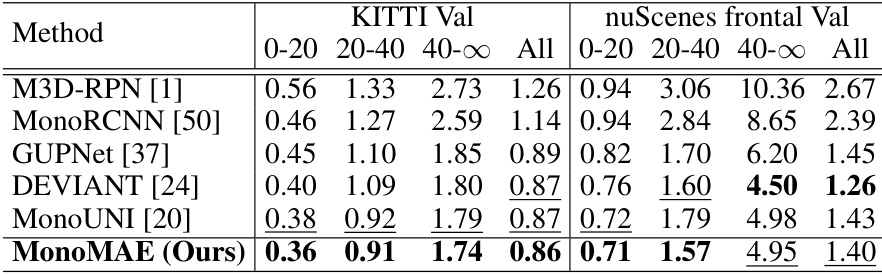
This table presents the results of cross-dataset evaluations, where the model is trained on the KITTI dataset and tested on both KITTI validation and nuScenes frontal validation sets. The evaluation metric used is the mean absolute depth error, with lower values indicating better performance. The table compares the performance of MonoMAE against several other state-of-the-art monocular 3D object detection methods, categorized by depth range (0-20m, 20-40m, 40-∞m) and overall performance across all depth ranges.
Full paper#