↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current multi-view 3D reconstruction methods struggle with noisy camera poses, affecting the accuracy of neural field optimization. Existing techniques often rely on pixel matching, which is sensitive to noise and may not fully utilize geometric information. This creates challenges for generating high-quality novel views and accurate 3D models.
CRAYM addresses these limitations by leveraging camera ray matching instead of pixel matching. Camera rays inherently encapsulate 3D spatial information, enabling more robust geometric constraints during optimization. The method integrates ray matching confidence into the joint optimization, further enhancing its accuracy and efficiency. Experiments demonstrate that CRAYM outperforms state-of-the-art alternatives in terms of both novel view synthesis and geometry reconstruction, particularly when dealing with noisy camera poses or sparse views.
Key Takeaways#
Why does it matter?#
This paper is crucial because it tackles the challenge of noisy camera poses in 3D reconstruction, a persistent problem hindering the accuracy and reliability of many existing methods. By introducing a novel camera ray matching technique, CRAYM significantly improves the quality of both novel view synthesis and 3D geometry reconstruction. This opens up new avenues for research in neural field optimization and related areas, especially for applications with limited or unreliable camera data. The enhanced accuracy and robustness of CRAYM could pave the way for improved applications in robotics, AR/VR, and other fields reliant on accurate 3D scene understanding.
Visual Insights#
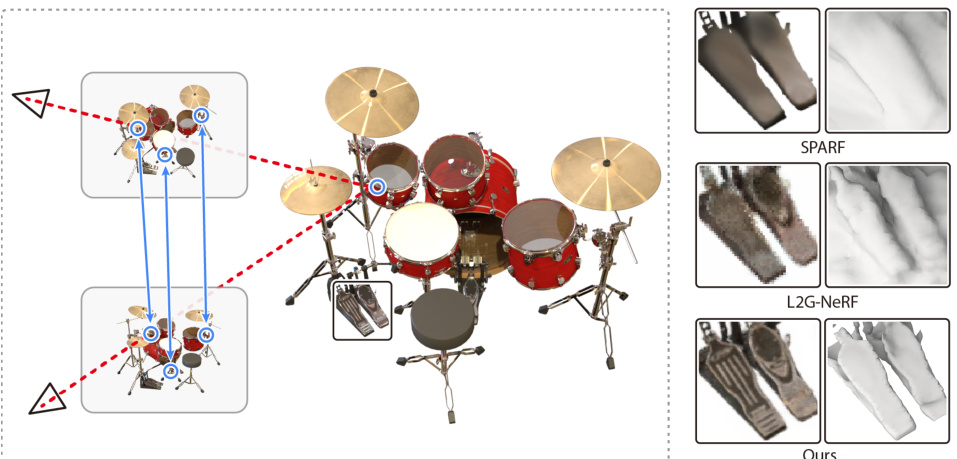
This figure compares the results of three different methods for neural field optimization with noisy camera poses: SPARF, L2G-NeRF, and the proposed CRAYM method. The results are shown for the ‘Drums’ model from the NeRF-Synthetic dataset. CRAYM is shown to produce superior results, particularly in the details. The zoom-in sections highlight the improved detail and color consistency of the CRAYM model compared to the others.

This table presents the results of pose registration error evaluation on the LEGO scene from the NeRF-Synthetic dataset. It compares four different methods (BARF, SPARF, L2G-NeRF, and CRAYM) in terms of rotation error (in degrees) and translation error. Lower values indicate better pose estimation accuracy.
In-depth insights#
Ray Matching#
Ray matching, in the context of neural field optimization, presents a powerful technique for improving the accuracy and efficiency of 3D reconstruction and novel view synthesis from multi-view images. Unlike pixel-based methods, ray matching leverages the 3D spatial information inherent in camera rays, enabling the integration of both geometric and photometric constraints into the optimization process. This allows for physically meaningful constraints to be imposed, improving the quality of both geometric reconstruction and photorealistic rendering. By focusing on camera rays passing through keypoints, the method enhances efficiency and accuracy of scene correspondences. Furthermore, accumulated ray features provide a means to discount erroneous ray matching, making the approach more robust. The effectiveness of ray matching is demonstrated through qualitative and quantitative comparisons to state-of-the-art alternatives across varying view settings, showcasing its advantages in handling noisy camera poses and achieving superior results particularly in capturing fine details.
Neural Field Optimization#
Neural field optimization is a powerful technique that leverages the representational power of neural networks to model and manipulate 3D scenes. Its core idea is to represent a scene as a continuous function, often an implicit function or a radiance field, that is learned by a neural network. This function can then be queried to generate novel views, reconstruct 3D geometry, or perform other tasks. The optimization process involves training the neural network to minimize the difference between rendered views and real images or other ground truth data. A key challenge lies in efficiently and accurately optimizing these high-dimensional neural fields, often requiring sophisticated techniques such as differentiable rendering and specialized loss functions. This area is particularly vibrant, with ongoing research exploring improved network architectures, optimization strategies, and ways to incorporate geometric constraints for more robust and physically realistic results. Applications extend beyond novel view synthesis, encompassing tasks such as 3D object reconstruction, scene completion, and even robotic manipulation. Ongoing research is further improving robustness to noise and incomplete data, pushing the boundaries of realism and efficiency in representing and manipulating 3D scenes.
Multi-view Consistency#
Multi-view consistency, in the context of 3D reconstruction from multiple images, refers to the principle of ensuring that information derived from different viewpoints is compatible and coherent. Successful multi-view consistency significantly improves the accuracy and robustness of the final 3D model. Methods achieving this often involve techniques like ray matching, which aligns corresponding rays across various cameras, or pixel-wise consistency losses, which penalize discrepancies between projected pixels from different views. A key challenge is handling noisy or inaccurate camera poses, which can disrupt consistency. Advanced techniques address this by jointly optimizing camera poses and the 3D scene representation, incorporating geometric constraints to enforce physically plausible relationships between views. The effectiveness of a multi-view consistency approach hinges on factors like feature matching reliability, the choice of geometric loss functions, and the ability to robustly handle outliers and occlusions. Achieving a high degree of multi-view consistency is crucial for generating detailed and accurate 3D models, especially in challenging scenarios with noisy data or limited viewpoints.
Geometric Priors#
Geometric priors, in the context of 3D reconstruction from images, leverage pre-existing knowledge about the structure and relationships of objects in the scene. They act as constraints or regularization terms within optimization processes, improving accuracy and robustness, especially when dealing with noisy or ambiguous data. Effective geometric priors can significantly reduce the search space and alleviate issues stemming from ill-posed problems. Common types include enforcing epipolar geometry, enforcing consistent camera pose estimates across multiple views, or using known object shapes or symmetries. The choice of geometric prior depends on the available data and the specific characteristics of the scene. A critical aspect is balancing the strength of the prior with the risk of overfitting or imposing unrealistic constraints. Strong priors can lead to over-regularization, hindering the model’s ability to capture fine details or unexpected variations in the scene. Conversely, weak priors might not provide sufficient guidance to overcome challenges posed by image noise or occlusions. The optimal geometric prior incorporates domain-specific knowledge to achieve a balance between reliable constraint imposition and flexibility for accurately representing complex scenes. Therefore, selecting and designing appropriate geometric priors is essential to a successful and accurate 3D reconstruction pipeline.
Ablation Study#
An ablation study systematically removes components of a model to assess their individual contributions. In the context of a research paper, this would involve isolating specific modules or parameters and observing the impact on overall performance. A well-designed ablation study provides strong evidence for the necessity and effectiveness of each component. By carefully controlling which elements are removed and observing the resulting changes in metrics like precision, recall, F1-score, or other relevant measures, researchers can build a strong case for the design choices and demonstrate a clear understanding of their model. Furthermore, a thorough ablation study helps to identify potential weaknesses in the model that could be further investigated or improved upon in future work. It also helps to highlight the relative importance of different components, allowing researchers to focus future development efforts on the areas that will yield the biggest return. Ideally, the ablation study should be designed with the use of controlled experiments and carefully chosen baselines to minimize bias and ensure that the observations are reliable and generalizable.
More visual insights#
More on figures
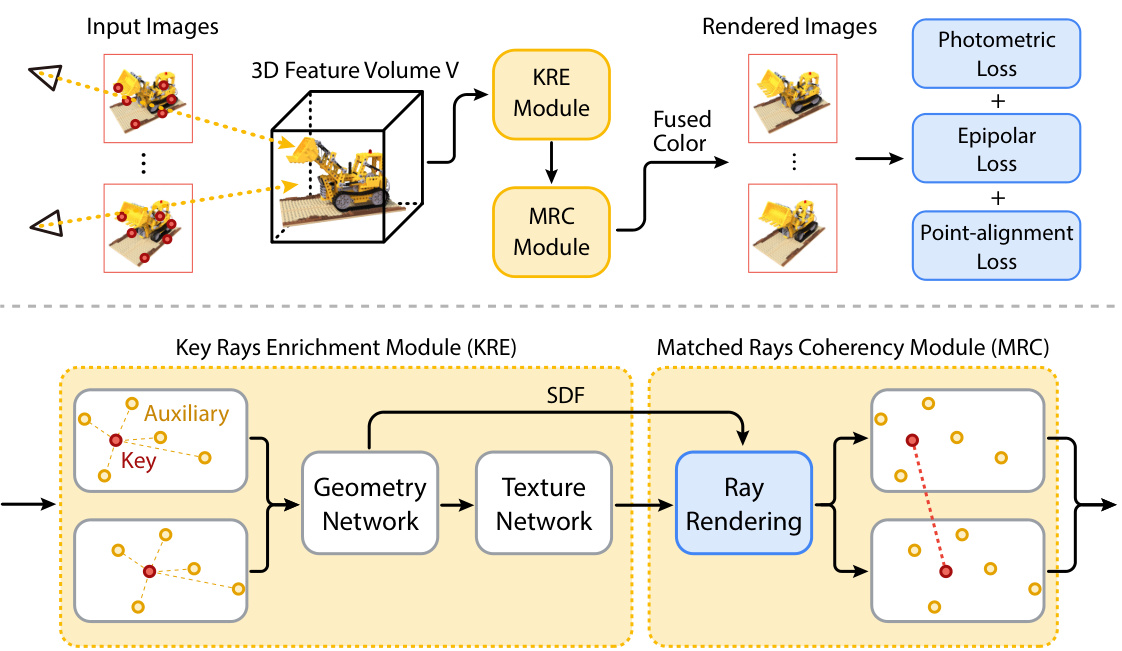
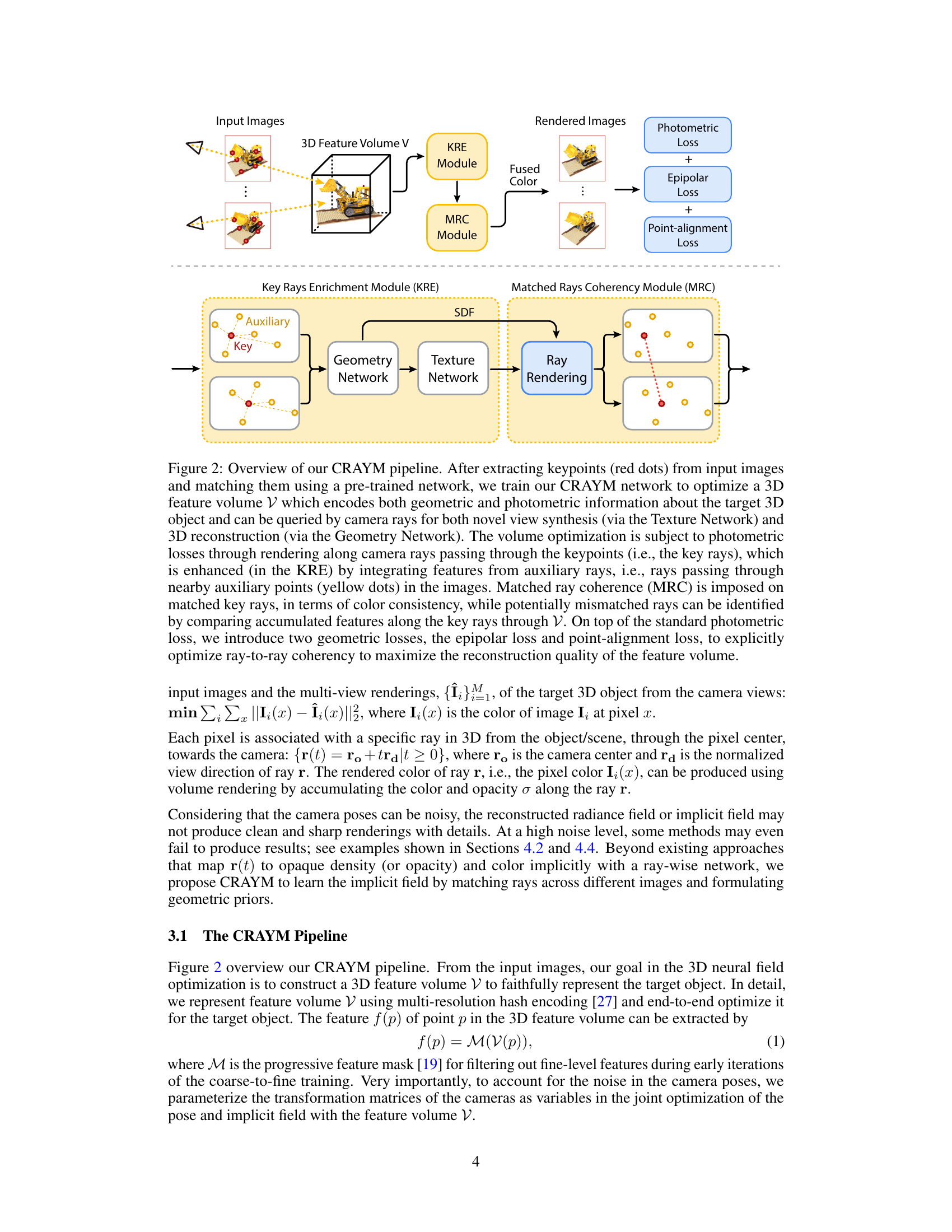
This figure illustrates the CRAYM pipeline, which optimizes a 3D feature volume using key and auxiliary rays extracted from input images. The pipeline incorporates photometric and geometric losses to refine both the feature volume and camera poses. The Key Rays Enrichment Module (KRE) improves robustness by incorporating contextual information from surrounding auxiliary rays. The Matched Rays Coherency Module (MRC) maintains coherence between matched rays, while identifying potential mismatches. The overall goal is to enhance the quality of novel view synthesis and 3D reconstruction.

This figure illustrates the two geometric losses used in the CRAYM method: epipolar loss and point-alignment loss. The epipolar loss ensures that the projection of a keypoint in one image onto the epipolar line in another image is consistent with the camera poses. The point-alignment loss further refines the accuracy by aligning the 3D points corresponding to matched keypoints, improving depth estimation and geometric consistency. Both losses work together to enhance the optimization process by enforcing geometric constraints and improving the accuracy of the camera poses and 3D scene reconstruction.

This figure visualizes the initial and optimized camera poses for the LEGO scene from the NeRF-Synthetic dataset. Purple points represent the ground truth poses, while blue points show both the initial and optimized camera poses obtained through different methods (BARF, L2G-NeRF, and the authors’ method). Red lines connect the initial and optimized poses, illustrating the translation errors between them. The visualization helps to understand the effectiveness of different methods in refining initial noisy camera pose estimates to better match the ground truth.
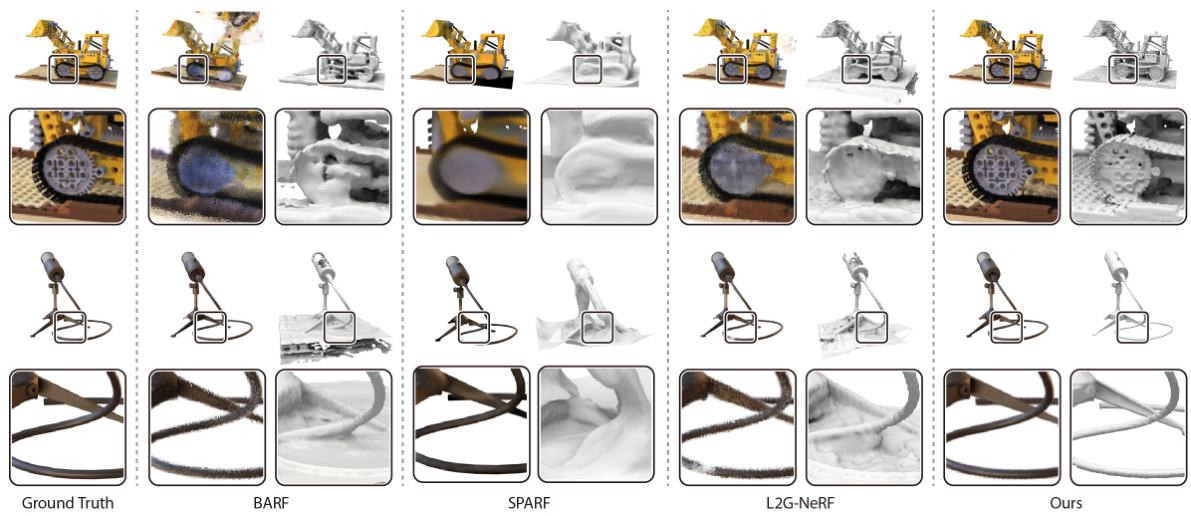
The figure shows a qualitative comparison of novel view synthesis and surface reconstruction results on synthetic objects. It compares the results of four different methods: BARF, SPARF, L2G-NeRF, and the authors’ proposed method, CRAYM. For each method, the figure displays several novel views and their corresponding 3D surface reconstructions, allowing for a visual comparison of the quality and details achieved by each approach. The Ground Truth is also shown for reference.

This figure presents a qualitative comparison of novel view synthesis and surface reconstruction results between different methods (BARF, SPARF, L2G-NeRF, and CRAYM) on synthetic objects. Each method is shown rendering various viewpoints of several objects. The visual comparison demonstrates CRAYM’s ability to produce superior results, particularly regarding fine details and overall sharpness, in comparison to existing state-of-the-art methods.

This figure compares the results of CRAYM against SPARF and L2G-NeRF on a drum model rendered from multiple views. CRAYM’s superior performance is highlighted by zoomed-in sections showing more detail and better handling of noisy camera poses. The key advantage of CRAYM is its use of camera ray matching rather than pixel matching, allowing for the integration of both geometric and photometric information for improved accuracy.
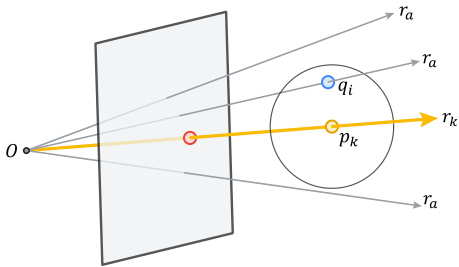
This figure illustrates the concept of Key Ray Enrichment Module (KRE). A key ray (yellow) and its neighboring auxiliary rays (gray) are shown. The key ray originates from the camera’s perspective and passes through a keypoint in the image. Due to potential inaccuracies in camera pose estimation, the intersection of the key ray with the 3D surface may not be perfectly accurate. To improve robustness, KRE incorporates features from the surrounding auxiliary rays, enriching the key ray’s features and improving the stability and accuracy of the optimization process.

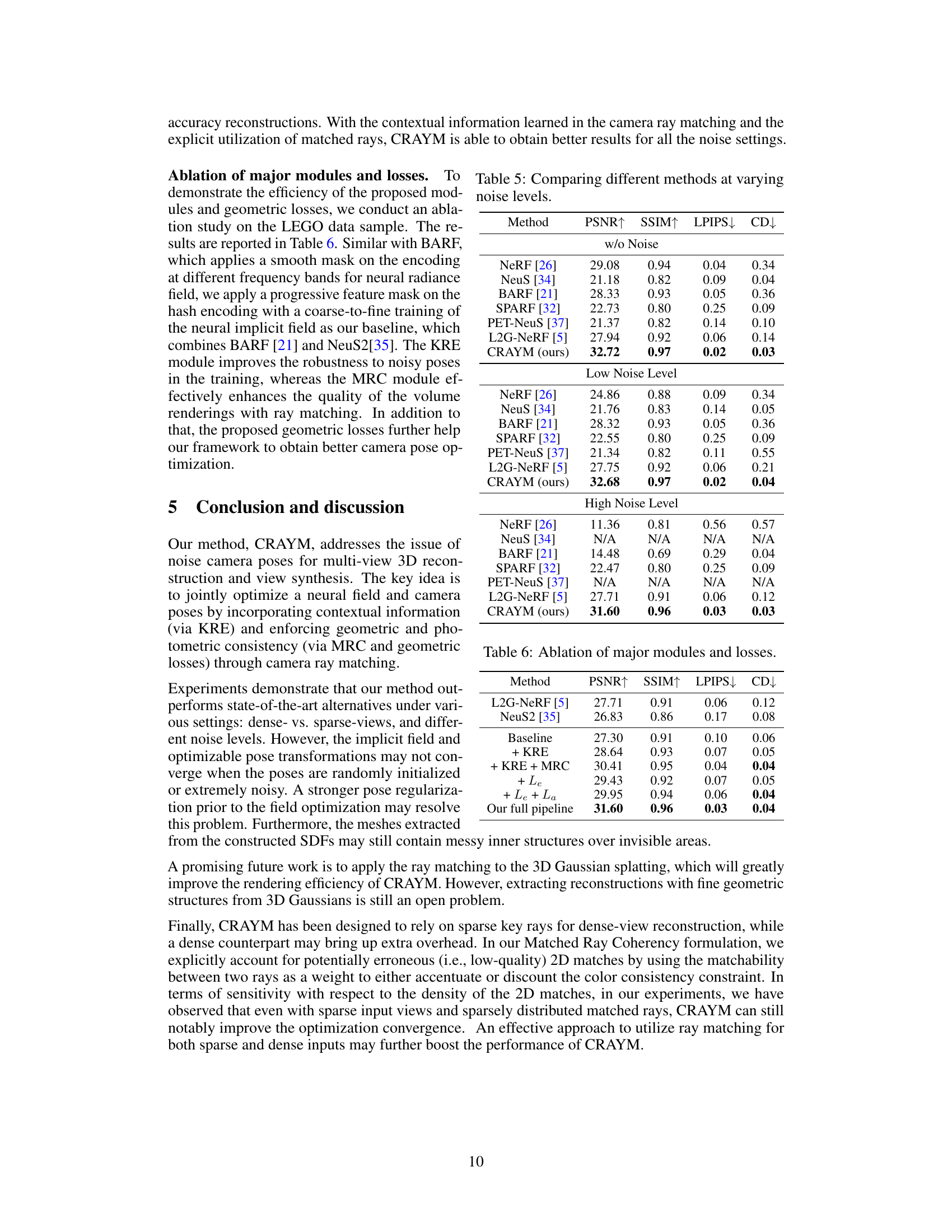
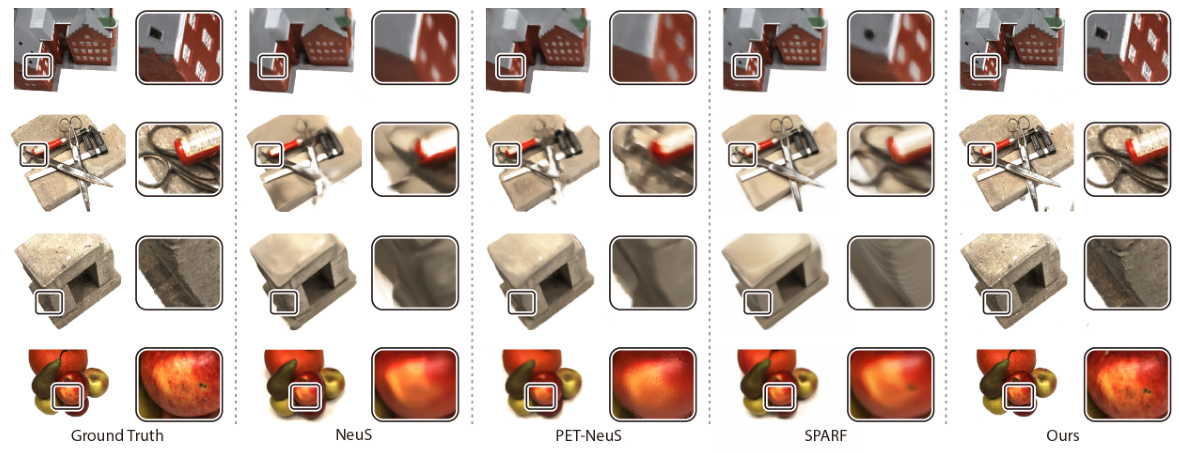
This figure showcases a qualitative comparison of novel view synthesis and 3D surface reconstruction results on real-world scenes. The results are compared between ground truth images, results from NeuS, PET-NeuS, and the authors’ CRAYM method. The comparison highlights the ability of CRAYM to produce superior results, especially in terms of detail and surface reconstruction, compared to existing methods. The images show that CRAYM generates more accurate and detailed reconstructions with fewer artifacts.

This figure presents a qualitative comparison of novel view synthesis and surface reconstruction results on real-world scenes. The results from three different methods (NeuS, PET-NeuS, and the authors’ CRAYM method) are shown alongside the ground truth. Each column shows the ground truth image, a zoomed-in section, the 3D reconstruction from the respective method, and another zoomed-in section of the 3D reconstruction. The comparison highlights the superior performance of the CRAYM method in capturing fine details and producing more accurate and realistic reconstructions compared to the other two methods.
This figure shows a qualitative comparison of novel view synthesis and surface reconstruction results on synthetic objects. It visually compares the results of four different methods: Ground Truth, BARF, SPARF, L2G-NeRF and CRAYM (the authors’ method). For each object, the figure displays multiple views, allowing for a direct comparison of the quality and details of the generated images and 3D reconstructions. The goal is to highlight the superior performance of the CRAYM method, particularly in terms of fine details and overall image quality.
More on tables
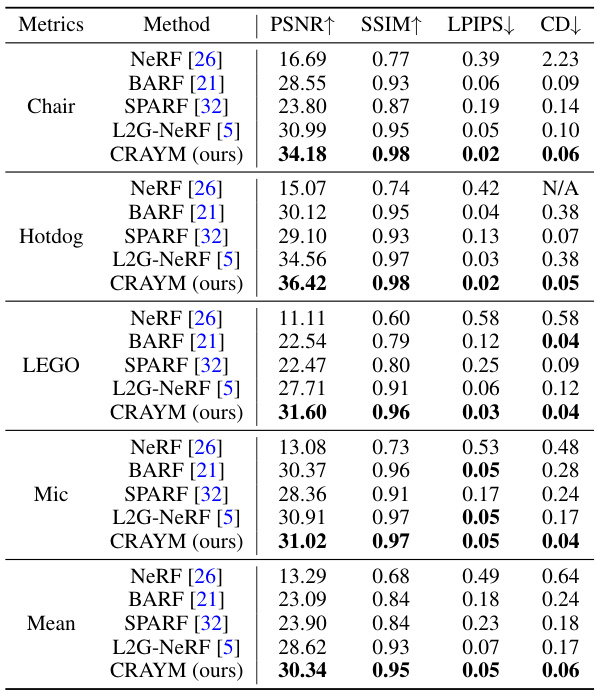
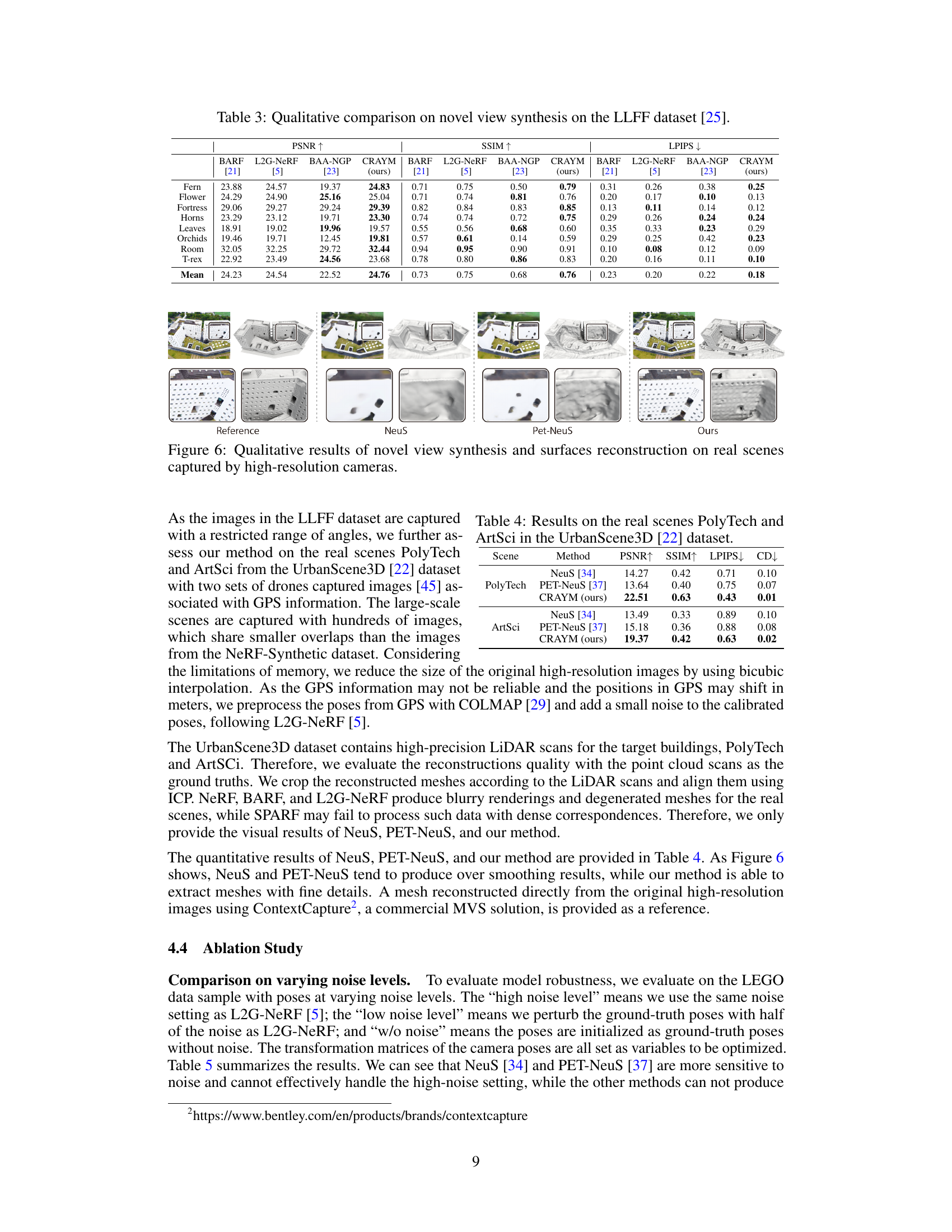
This table presents a quantitative comparison of the proposed CRAYM method against several state-of-the-art techniques on the NeRF-Synthetic dataset. Metrics include PSNR, SSIM, LPIPS, and Chamfer Distance (CD), evaluated across eight different synthetic scenes. The results highlight CRAYM’s superior performance in terms of image quality and 3D reconstruction accuracy.

This table presents the quantitative results of the proposed method (CRAYM) compared to NeuS and PET-NeuS on two real-world scenes: PolyTech and ArtSci. The metrics used are PSNR, SSIM, LPIPS, and Chamfer Distance (CD). These metrics evaluate the quality of novel view synthesis and 3D reconstruction, respectively. Lower CD values indicate better 3D reconstruction accuracy. The results show that CRAYM significantly outperforms the baselines on both scenes.
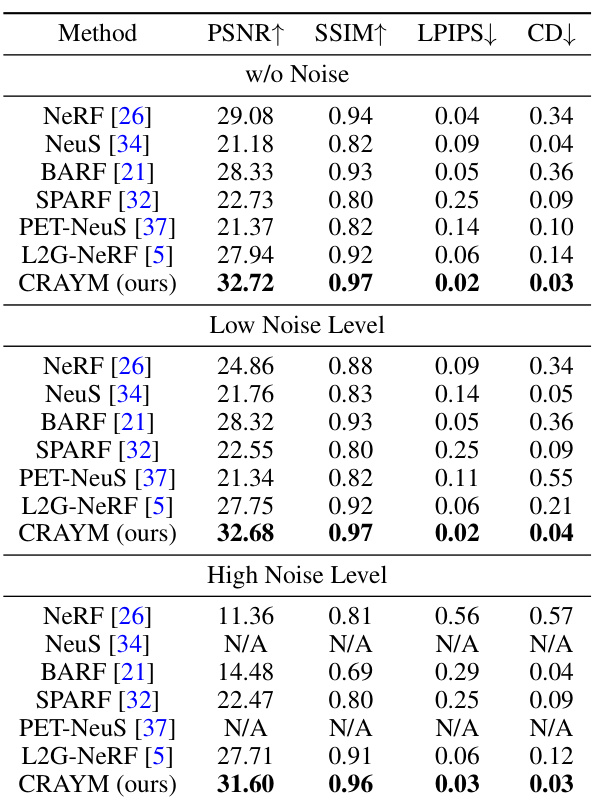
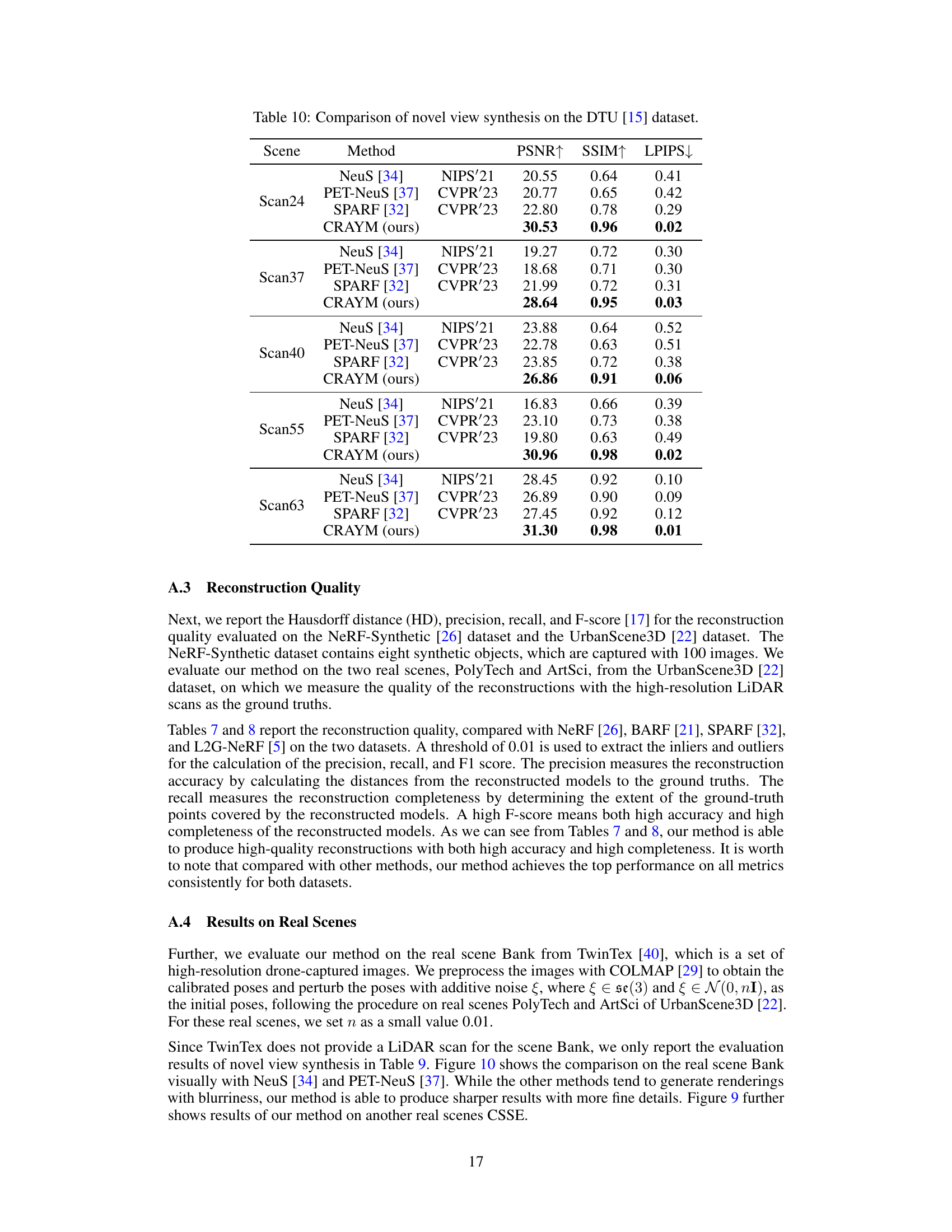
This table presents a comparison of different neural radiance field methods (NeRF, NeuS, BARF, SPARF, PET-NeuS, L2G-NeRF, and CRAYM) under three noise levels: without noise, low noise level, and high noise level. The comparison is based on PSNR, SSIM, LPIPS, and CD metrics, providing a quantitative assessment of each method’s performance in handling noisy camera poses. The results highlight the robustness of the proposed CRAYM method, especially in high-noise scenarios.
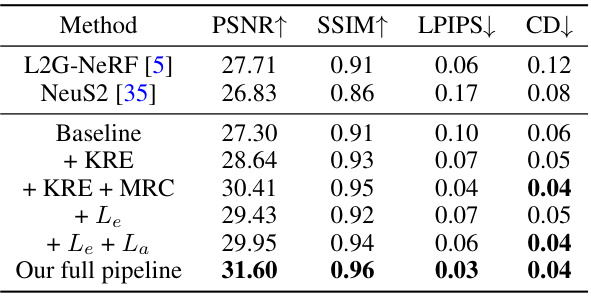
This table presents the ablation study results, comparing the performance of different model configurations on the LEGO dataset. It shows the impact of adding the Key Rays Enrichment (KRE) module, the Matched Rays Coherency (MRC) module, and the geometric losses (Le and La) to the baseline model. The results demonstrate the effectiveness of each component in improving the overall performance, measured by PSNR, SSIM, LPIPS, and Chamfer distance (CD).
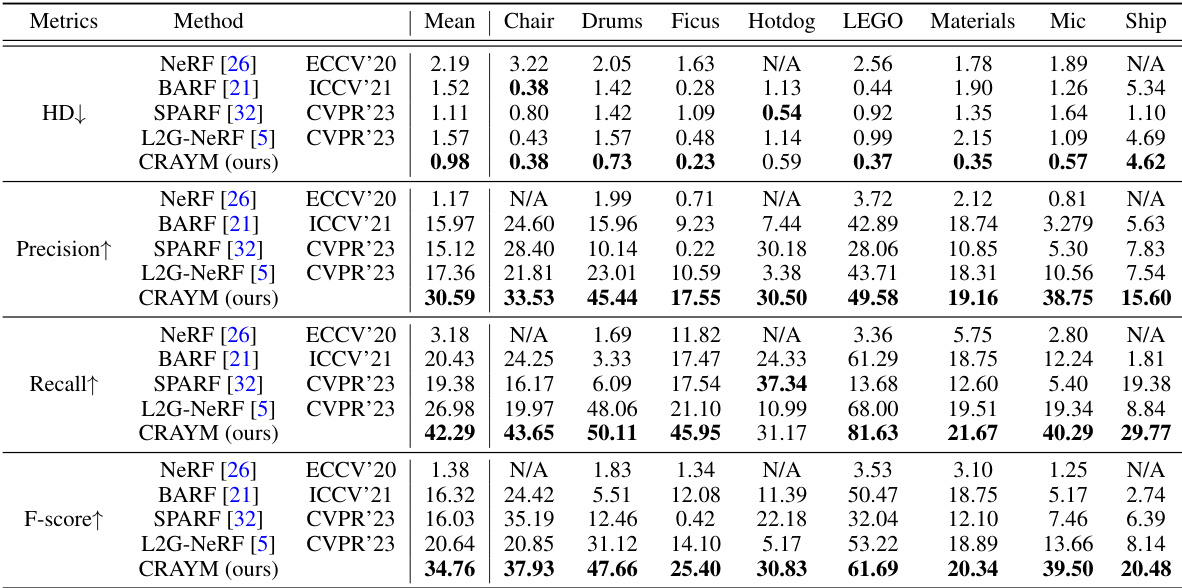
This table presents a quantitative comparison of the reconstruction quality achieved by different methods on the NeRF-Synthetic dataset [26]. The metrics used for comparison include Hausdorff distance (HD), precision, recall, and F-score. The results are broken down by object category (Chair, Drums, Ficus, Hotdog, LEGO, Materials, Mic, Ship) and aggregated into a mean value. Lower HD values indicate better reconstruction quality, while higher values for precision, recall, and F-score are desirable.

This table presents a quantitative comparison of the 3D reconstruction quality achieved by three different methods (NeuS, PET-NeuS, and CRAYM) on two real-world scenes: PolyTech and ArtSci. The metrics used for evaluation are Hausdorff Distance (HD), Precision, Recall, and F-score. Lower HD indicates better reconstruction accuracy, while higher Precision, Recall, and F-score represent improved model performance.

This table presents a quantitative comparison of novel view synthesis results on the real scene Bank from the TwinTex dataset [40]. Three methods, NeuS [34], PET-NeuS [37], and CRAYM (the authors’ method), are compared using three metrics: PSNR, SSIM, and LPIPS. The results show that CRAYM significantly outperforms the other two methods in terms of all three metrics, indicating its superior performance in novel view synthesis for real-world scenes.

This table presents a quantitative comparison of novel view synthesis results on the DTU dataset [15], comparing the proposed CRAYM method against NeuS [34], PET-NeuS [37], and SPARF [32]. The metrics used for comparison are PSNR (Peak Signal-to-Noise Ratio), SSIM (Structural Similarity Index), and LPIPS (Learned Perceptual Image Patch Similarity). The results are shown for five different scan scenes (Scan24, Scan37, Scan40, Scan55, Scan63) from the DTU dataset. The table highlights the superior performance of CRAYM in terms of PSNR, SSIM, and LPIPS, indicating significantly improved visual quality compared to the other methods.

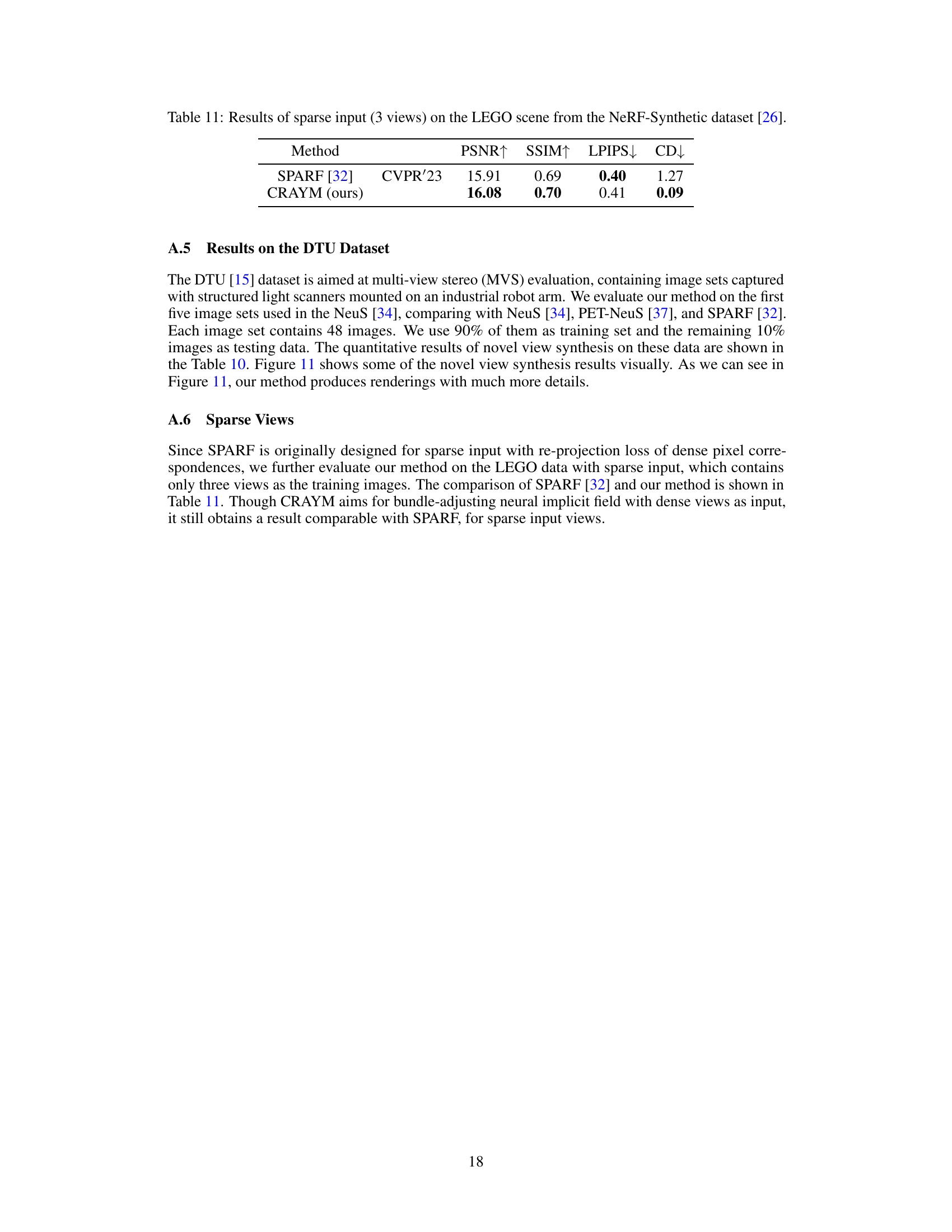
This table shows the quantitative results of novel view synthesis on the LEGO scene from the NeRF-Synthetic dataset using only 3 input views. It compares the performance of the proposed CRAYM method against the SPARF method, highlighting the PSNR, SSIM, LPIPS, and Chamfer Distance (CD) metrics. The results demonstrate CRAYM’s ability to produce comparable results even with significantly limited input views.
Full paper#