↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Federated learning (FL) faces challenges with heterogeneous data across clients, leading to unstable training. Personalized federated learning (PFL) aims to solve this by training individual models for each client, but existing methods struggle with the bias-variance trade-off, especially under data scarcity and distribution shifts. This often results in poor generalization and suboptimal performance.
The paper introduces pFedFDA, a novel PFL algorithm that addresses these issues. pFedFDA leverages a generative modeling approach to learn a shared representation that captures commonalities across clients while allowing for individual model adaptation. By estimating global and local feature distributions, pFedFDA effectively adjusts for distribution shifts. The experiments on image classification datasets demonstrate that pFedFDA consistently outperforms existing methods in scenarios with data scarcity and covariate shift, achieving over 6% improvement in accuracy in multiple benchmarks.
Key Takeaways#
Why does it matter?#
This paper is important because it presents pFedFDA, a novel personalized federated learning method that significantly improves model accuracy in challenging scenarios with covariate shift and data scarcity. It offers a new generative modeling perspective, enhancing the understanding and handling of data heterogeneity in federated learning, opening avenues for further research in addressing bias-variance trade-offs and improving personalization techniques. Its practical impact lies in enabling the development of more robust and accurate FL systems for real-world applications.
Visual Insights#

This figure illustrates the two main stages of the pFedFDA algorithm. The left panel shows the global representation learning phase where heterogeneous clients collaboratively train representation parameters using a generative classifier based on a global estimate of class feature distributions. The right panel depicts the local distribution adaptation, where, at test time, each client adapts the global generative classifier to its own local feature distribution to generate personalized classifiers. The visual representation effectively shows how the global model is adapted to the unique characteristics of individual clients.

This table presents the average test accuracy and standard deviation achieved by different federated learning methods on CIFAR10-S and CIFAR100-S datasets under varying proportions of training data (100%, 75%, 50%, 25%). It demonstrates the performance of these methods under conditions of covariate shift (simulated image corruptions) and data scarcity. The results highlight the relative performance gains of pFedFDA, especially in data-scarce settings.
In-depth insights#
pFedFDA Algorithm#
The pFedFDA algorithm presents a novel approach to personalized federated learning (PFL), effectively addressing the challenges posed by non-i.i.d. data and data scarcity. It cleverly frames representation learning as a generative modeling task, utilizing a global generative classifier to learn a shared representation across clients. This global model helps to mitigate bias, while simultaneously maintaining the crucial balance of variance. The algorithm then personalizes this shared representation by adapting the global generative classifier to each client’s unique local feature distribution. This adaptation step is crucial for leveraging global knowledge while avoiding overfitting to limited local data. Local-global interpolation is further introduced to optimize the balance between local and global knowledge, adjusting for diverse dataset sizes and distributions across different clients. The algorithm’s effectiveness is validated through extensive experiments on several benchmark datasets. demonstrating significant improvements in accuracy, especially in challenging scenarios involving covariate shifts and limited data.
Generative Modeling#
Generative modeling, in the context of personalized federated learning (PFL), offers a powerful approach to address the inherent challenges of data heterogeneity and scarcity. By framing representation learning as a generative task, the model learns a shared representation guided by a global feature distribution, capturing commonalities across clients. This approach mitigates the bias-variance trade-off that frequently plagues PFL, as the global model provides a robust foundation, reducing overfitting to individual, limited datasets. The choice of the generative model (e.g., a class-conditional Gaussian) is crucial, influencing the effectiveness of representation learning and the tractability of personalization. The paper’s use of a generative model allows for efficient adaptation of the global classifier to individual client data distributions through local-global parameter interpolation, effectively creating personalized classifiers while maintaining strong generalization capabilities. This strategy is particularly effective for computer vision tasks where data scarcity and covariate shift frequently occur. Overall, the use of generative modeling in this work demonstrates a significant improvement over traditional methods, addressing both bias and variance problems simultaneously and pushing the boundaries of PFL effectiveness.
Bias-Variance Tradeoff#
The bias-variance tradeoff is a central challenge in personalized federated learning (PFL), particularly when dealing with heterogeneous data distributions and limited local datasets. The core problem is balancing the need for personalized models that accurately reflect individual client data (low variance) with the risk of overfitting to noisy or limited local data (high variance). Simultaneously, there’s a need to leverage global knowledge to prevent individual models from diverging too far from a generalizable model (low bias), while avoiding overly general models that fail to capture the unique characteristics of each client’s data (high bias). The authors address this by framing representation learning as a generative modeling task, using a global feature distribution to guide representation learning (reducing bias) and then adapting these global classifiers to local feature distributions (reducing variance). This approach, pFedFDA, employs a local-global interpolation scheme that intelligently balances the influence of global and local information for optimal performance. Their method effectively navigates the bias-variance tradeoff, showing consistent improvements in model accuracy across several computer vision benchmarks with varying levels of data scarcity and covariate shift.
Data Heterogeneity#
Data heterogeneity in federated learning (FL) presents a significant challenge, as it undermines the fundamental assumption of independent and identically distributed (i.i.d.) data. Non-i.i.d. data distributions across participating clients lead to model divergence, hindering the convergence of global models trained with federated averaging (FedAvg). This necessitates personalized federated learning (PFL) techniques to cater to diverse data distributions. The paper highlights the issues of client drift, where distinct local objectives result in model divergence, and suboptimal local performance, where models fail to generalize effectively to individual clients’ unique contexts. Addressing this heterogeneity requires robust techniques that balance global knowledge with local adaptations, to avoid the bias-variance trade-off inherent in PFL approaches. The authors’ proposed method, pFedFDA, directly tackles the data distribution challenge by framing representation learning as a generative modeling task, enhancing generalization and achieving significant improvements over current state-of-the-art methods.
Future Work#
The authors suggest several avenues for future research. Extending pFedFDA’s applicability to a wider range of neural network architectures is crucial, as the current Gaussian distribution assumption might not generalize well to all activation functions. Investigating more sophisticated feature distribution models beyond the Gaussian, perhaps incorporating neural network architecture-specific knowledge, is a promising direction. Exploring the cluster structure inherent in many real-world federated learning datasets could lead to more efficient and accurate feature distribution estimation, potentially improving the method’s robustness to heterogeneous data. Finally, a comprehensive analysis of pFedFDA’s scalability is warranted, addressing computational and communication complexities in large-scale deployments. This would involve investigating more efficient local-global interpolation techniques and optimizing the parameter server aggregation strategy. Addressing these points would significantly enhance the practical impact and widespread applicability of pFedFDA.
More visual insights#
More on figures

This figure shows the average learned beta (β) values across clients in the CIFAR10-S dataset with different types of corruptions. Each bar represents a specific corruption type applied to the client’s training data, and the height of the bar indicates the average β value. Error bars show standard deviation. The x-axis shows the various corruption types applied to the client datasets, and the y-axis shows the learned β values. The results suggest that the severity of corruption is correlated with the β value, showing higher β values where more severe corruptions were present. In simpler terms, this graph displays how the model adjusts (β) to the presence of different levels of corruption or noise in the data.

This figure illustrates the two main stages of the pFedFDA algorithm. The left panel shows the global representation learning phase, where heterogeneous clients collaborate to train shared representation parameters using a generative classifier based on a global feature distribution estimate. The right panel depicts the local distribution adaptation phase, where each client adapts the global generative classifier to its local feature distribution to produce personalized classifiers.

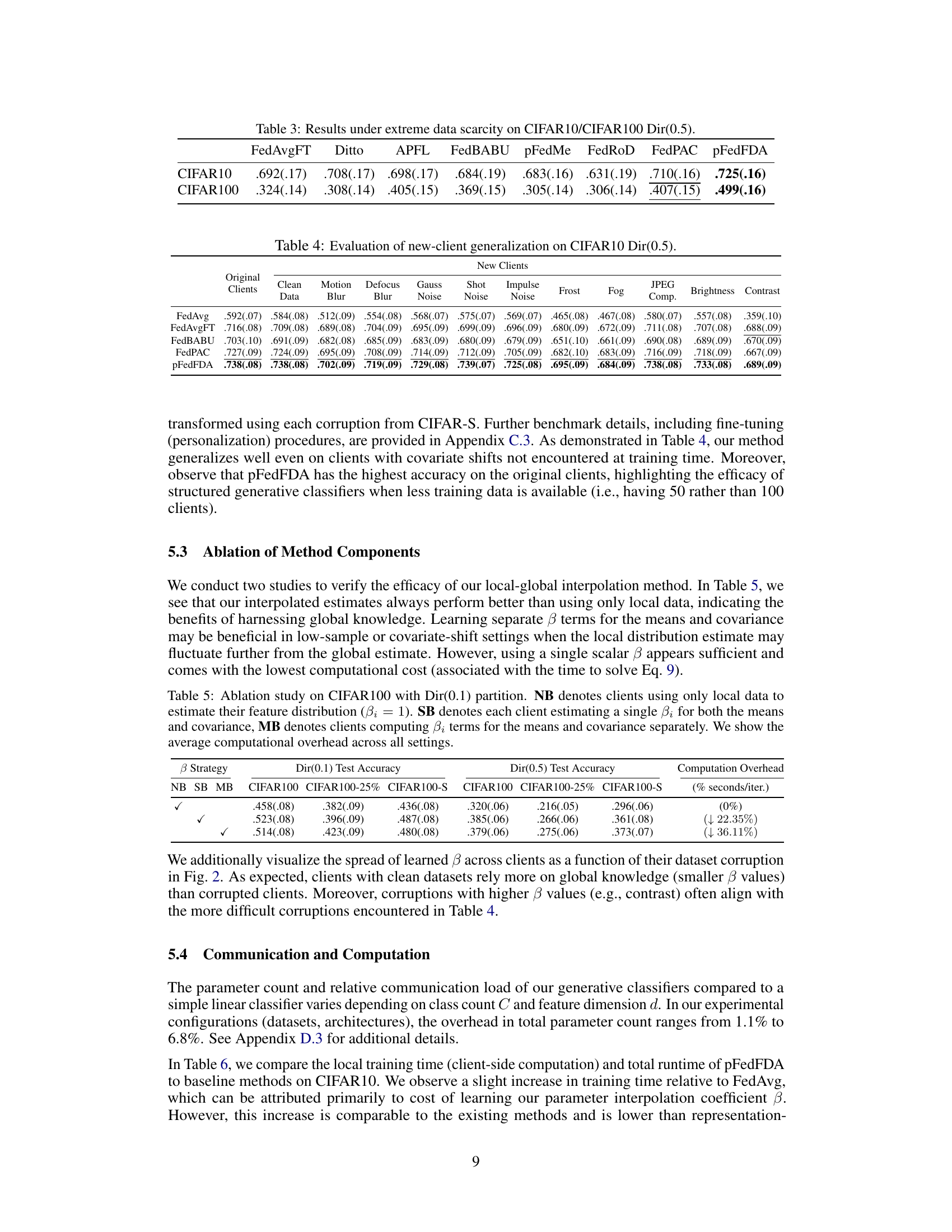
The figure shows the average test accuracy of FedAvgFT and pFedFDA on CIFAR100 and CIFAR100-S (with 25% of the training data) for different numbers of local epochs. It illustrates how the performance of both methods changes as the number of local training epochs increases. pFedFDA generally outperforms FedAvgFT, particularly with fewer local epochs, indicating its faster convergence and higher accuracy.
More on tables
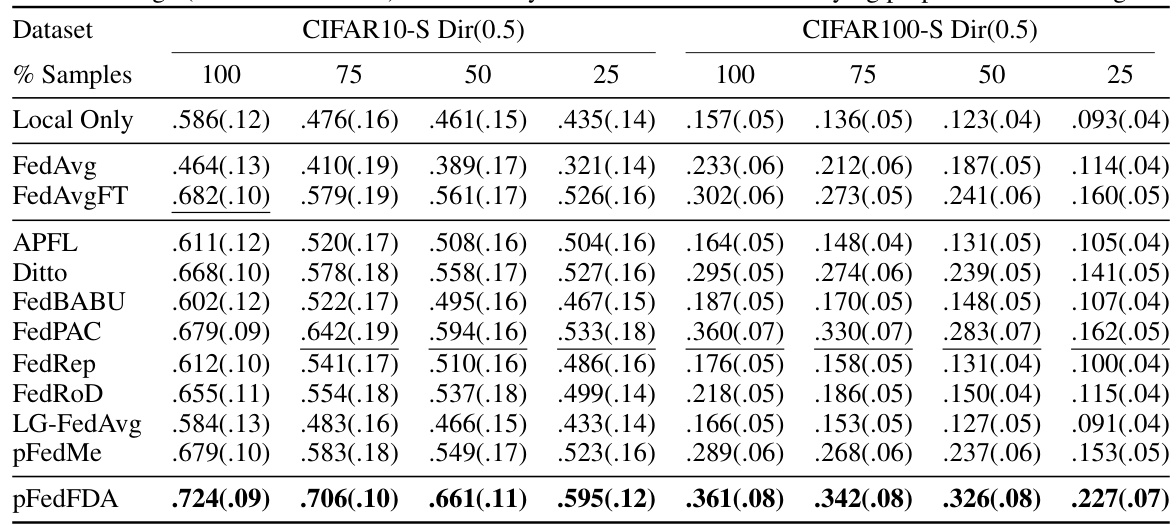
This table presents the average and standard deviation of test accuracy achieved by various federated learning methods on CIFAR10-S and CIFAR100-S datasets. The results are broken down by the percentage of training data used (100%, 75%, 50%, 25%) to show the impact of data scarcity on model performance. The table allows for comparison of different algorithms under varying data constraints and highlights the relative performance in data-scarce scenarios.
This table presents the average test accuracy and standard deviation achieved by various federated learning methods on the CIFAR10 and CIFAR100 datasets under different data scarcity conditions (100%, 75%, 50%, and 25% of training data). The datasets are modified to simulate covariate shift by introducing image corruptions. The results show how different methods perform with varying amounts of available data under conditions of data heterogeneity.

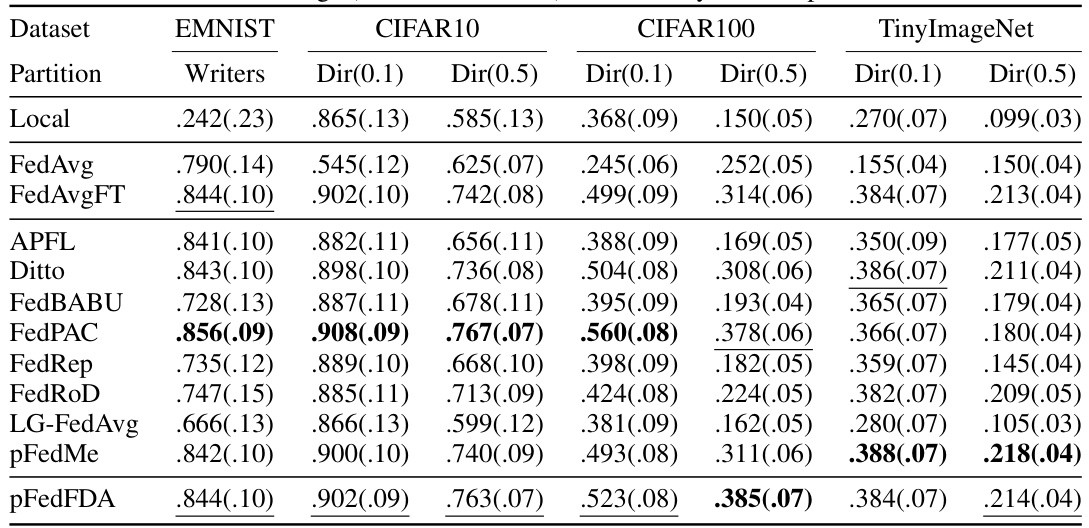
This table presents the average test accuracy and its standard deviation for CIFAR10 and CIFAR100 datasets with covariate shift, using different percentages of training data (100%, 75%, 50%, 25%). The results are shown for various federated learning algorithms, including the proposed pFedFDA, allowing comparison of their performance under different data scarcity levels.
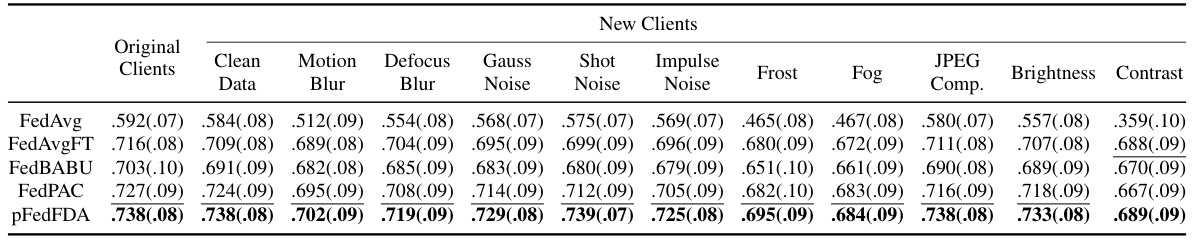
This table presents the results of evaluating the model’s ability to generalize to new clients not seen during training. It shows the average test accuracy for several federated learning methods on CIFAR10 dataset with Dir(0.5) partitioning, across both original clients and new clients subjected to various image corruptions. The results highlight the performance of different models on unseen data and with different data quality issues.

This table presents the ablation study of the pFedFDA algorithm, specifically focusing on the impact of different strategies for estimating the interpolation coefficient βi which balances local and global knowledge for feature distribution adaptation. It compares three methods: using only local data (NB), using a single βi for both mean and covariance (SB), and using separate βis for mean and covariance (MB). The results are shown for different data scarcity scenarios (CIFAR100, CIFAR100-25%, CIFAR100-S) under two different data distribution settings (Dir(0.1) and Dir(0.5)). The table also includes the computation overhead for each method.

This table compares the local training time (client-side computation) and total runtime of pFedFDA to baseline methods on CIFAR10. It shows that pFedFDA has a slightly increased training time compared to FedAvg, mainly due to the cost of learning the parameter interpolation coefficient. However, this increase is comparable to other methods and is lower than representation-learning methods.

This table presents the results of the multi-domain DIGIT-5 experiment with varying data volumes. The DIGIT-5 dataset is a domain generalization benchmark where data is drawn from five different datasets. The experiment uses 20 clients with full participation, 4 assigned to each domain. The Dirichlet(0.5) partitioning strategy is used to distribute data to each client. The table shows the average test accuracy and improvement for each method (Local, FedAvg, FedAvgFT, Ditto, FedPAC, and pFedFDA) at 25%, 50%, 75%, and 100% data volume.

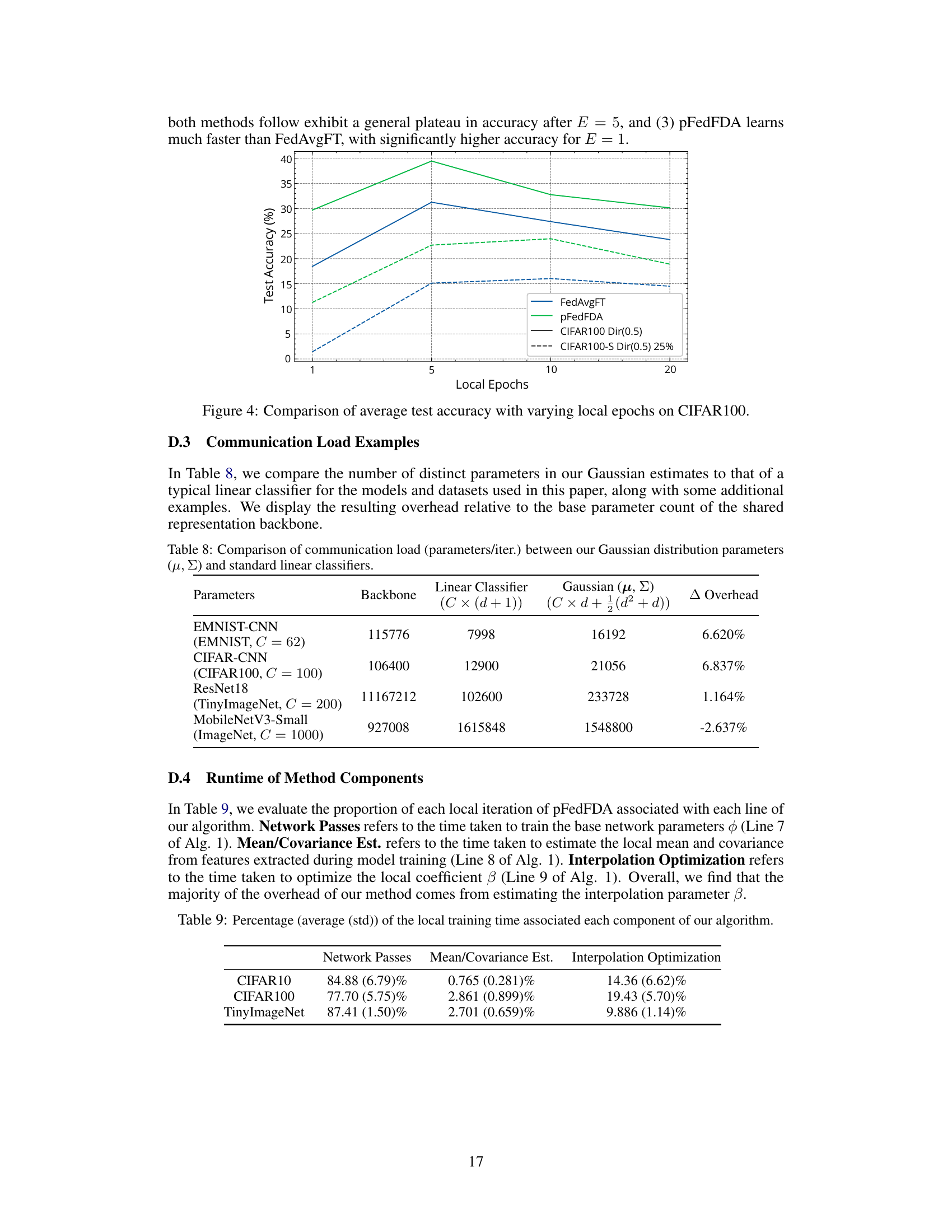
This table compares the number of parameters required for the Gaussian generative classifiers used in pFedFDA against the parameter count of a standard linear classifier. It demonstrates the relative overhead introduced by the generative model for different datasets and network architectures. A negative overhead indicates that the generative classifier uses fewer parameters than the standard linear classifier.

This table shows the proportion of the local training time spent on different parts of the pFedFDA algorithm. It breaks down the time spent on network passes (training the shared feature extractor), mean/covariance estimation (estimating local feature distribution parameters), and interpolation optimization (optimizing the interpolation coefficient beta). The percentages are shown for CIFAR10, CIFAR100, and TinyImageNet datasets.
Full paper#