↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Training deep Spiking Neural Networks (SNNs) is challenging due to the complexity of Backpropagation Through Time (BPTT), the dominant training method. BPTT requires significant memory and computational resources, particularly when dealing with long temporal dependencies inherent in SNNs. This limits the scalability and applicability of SNNs, especially in resource-constrained environments.
This paper introduces rate-based backpropagation, a novel training method designed to overcome these limitations. By focusing on average firing rates (rate coding) rather than precise spike timings, the new approach streamlines the computational graph and reduces memory and time demands. The researchers demonstrate through theoretical analysis and extensive experiments that rate-based backpropagation achieves comparable performance to BPTT while substantially improving training efficiency. Their findings pave the way for training larger and more complex SNNs, expanding the potential applications of this biologically inspired computing paradigm.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in neuromorphic computing and machine learning. It offers a novel training method that significantly improves the efficiency of deep spiking neural networks (SNNs), a field currently attracting considerable attention due to SNNs’ energy efficiency and potential for hardware implementation. The proposed approach addresses the limitations of existing training methods, opening new avenues for building larger and more complex SNNs for various applications.
Visual Insights#
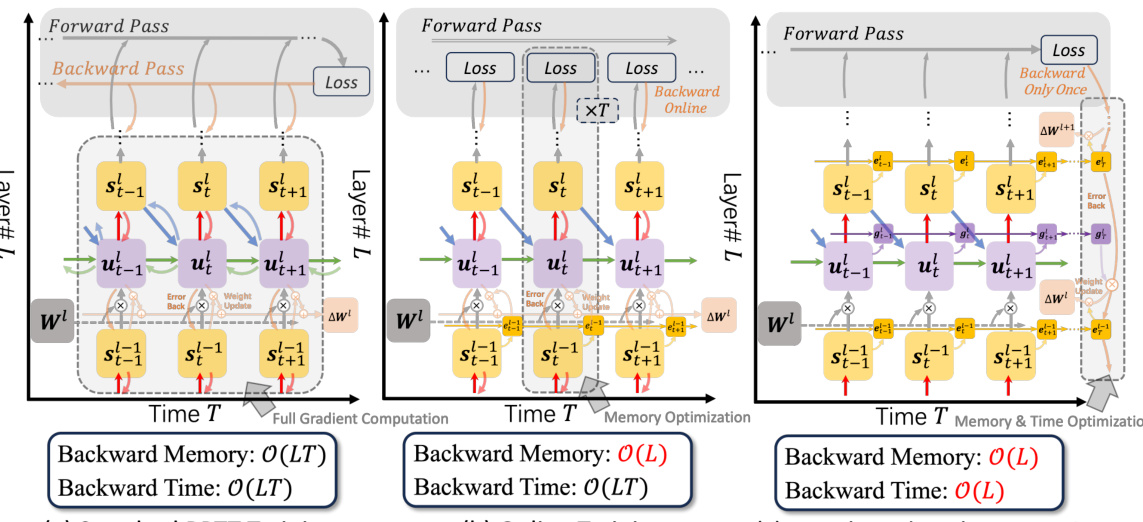
This figure compares three different training methods for spiking neural networks (SNNs): standard backpropagation through time (BPTT), online training, and the proposed rate-based backpropagation. It visually depicts the forward and backward passes for each method, highlighting the differences in memory and computational complexity. Standard BPTT requires storing all temporal activations, leading to high memory and time costs. Online methods reduce memory demands but still require iterative computations, increasing training time complexity. In contrast, rate-based backpropagation streamlines the computational graph by focusing on averaged dynamics, minimizing reliance on detailed temporal derivatives. This reduces memory and computational demands, making training SNNs more efficient. The figure illustrates the memory and time complexities of each method using Big O notation.
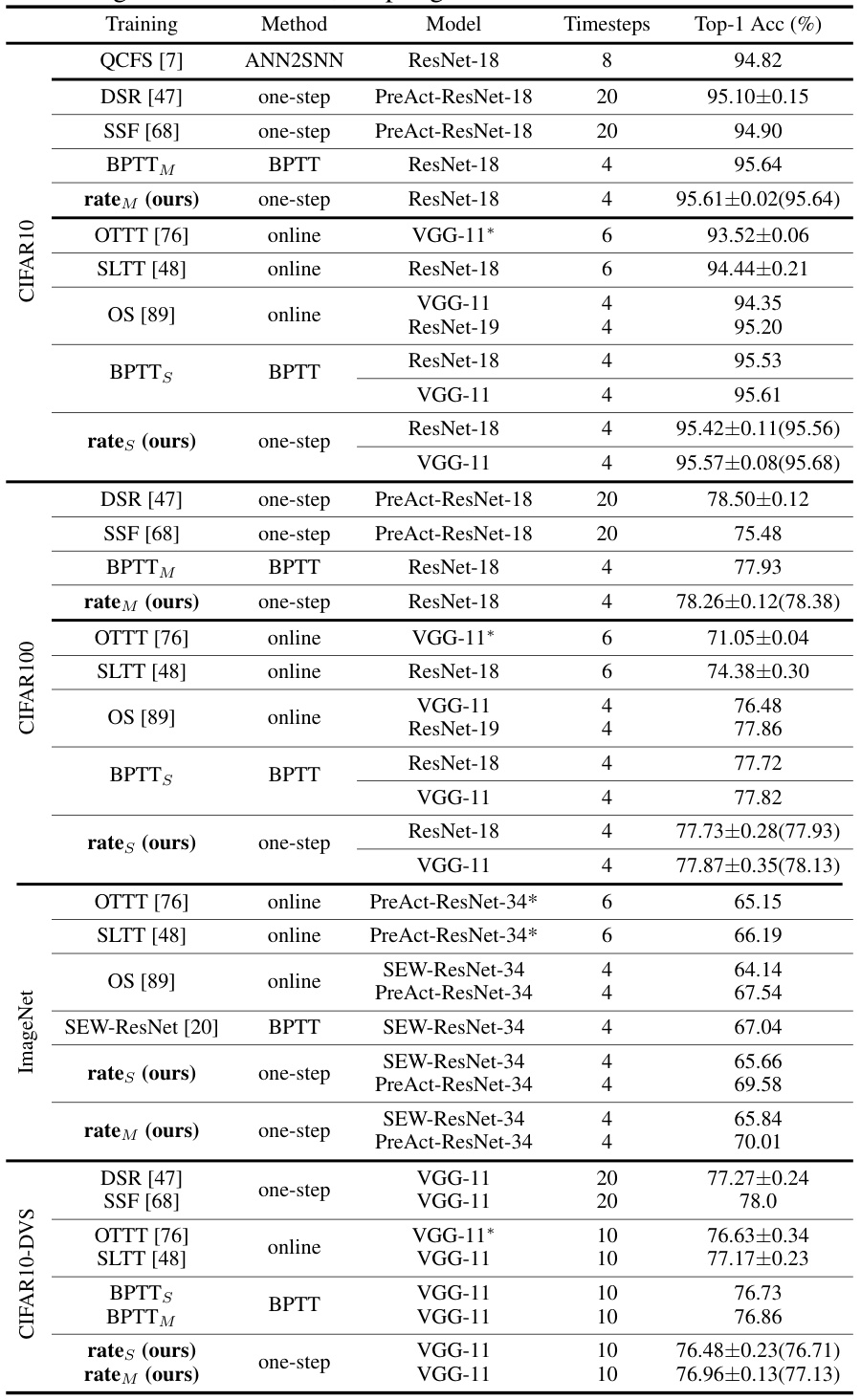
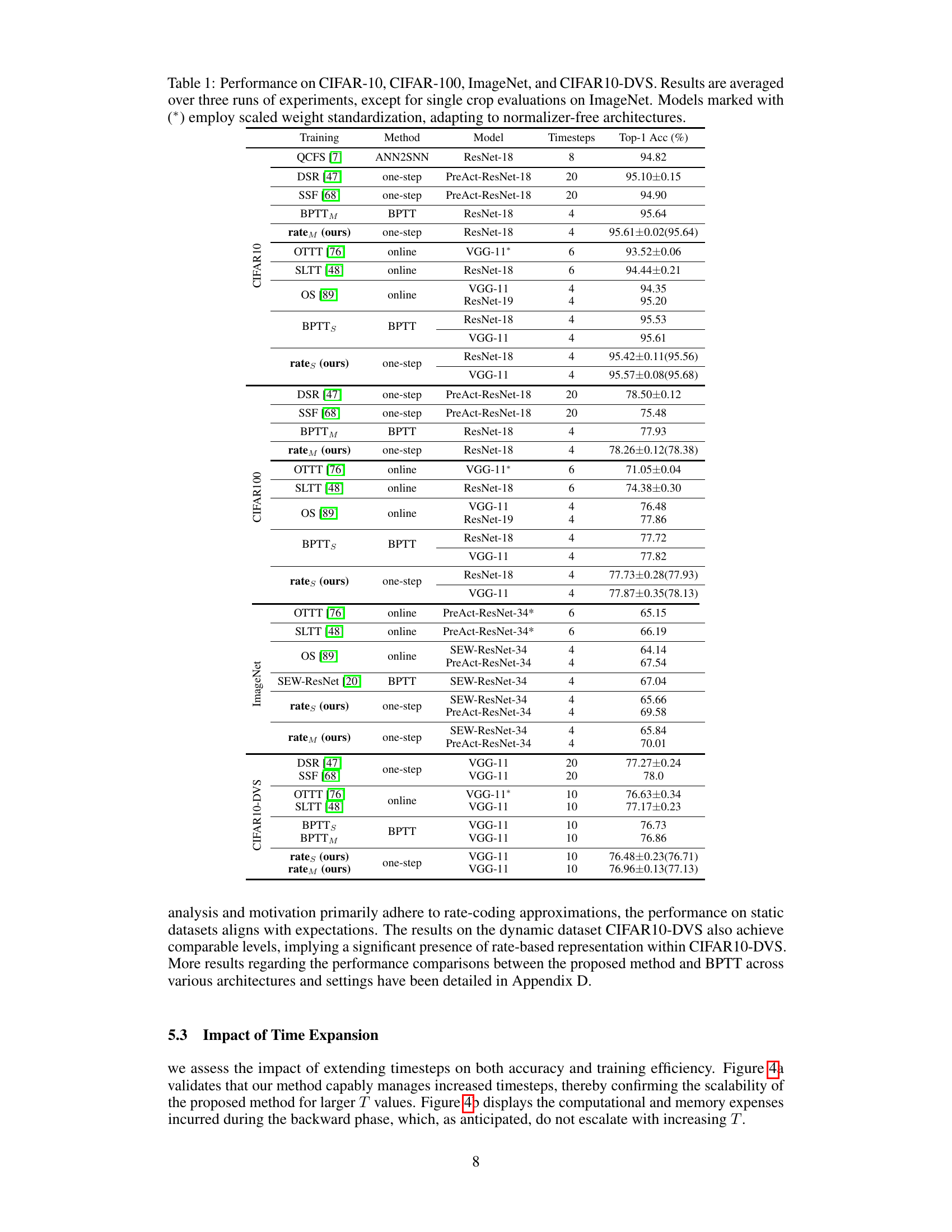
This table presents a comparison of the proposed rate-based backpropagation method with other state-of-the-art SNN training methods across four benchmark datasets: CIFAR-10, CIFAR-100, ImageNet, and CIFAR10-DVS. The results show the top-1 accuracy achieved by each method on various network architectures with different numbers of timesteps. It highlights the comparable or superior performance of the proposed method while using less computational resources.
In-depth insights#
Rate-Coding in SNNs#
Rate-coding, a prominent neural coding scheme, encodes information through the average firing rate of neurons, irrespective of precise spike timing. In the context of Spiking Neural Networks (SNNs), this contrasts with temporal coding, which utilizes precise spike timing for information representation. The paper highlights that rate-coding is a dominant form of information representation in SNNs trained using surrogate gradient-based Backpropagation Through Time (BPTT). This observation is bolstered by the fact that BPTT-trained SNNs exhibit strong representational similarities to their ANN counterparts, underscoring the significance of rate-based representations. Furthermore, the prevalence of rate coding is reinforced by its crucial role in enhancing the robustness of SNNs against adversarial attacks. The study emphasizes that this understanding motivates a novel training strategy focusing on rate-based information to improve efficiency and scalability of SNNs training.
Backprop Efficiency#
Backpropagation, crucial for training deep neural networks, often presents a computational bottleneck. This paper tackles this ‘Backprop Efficiency’ challenge by focusing on spiking neural networks (SNNs) and their inherent rate coding properties. The core idea is to leverage rate coding to reduce the complexity of traditional backpropagation through time (BPTT), thereby improving training speed and memory efficiency. This is achieved by minimizing reliance on detailed temporal derivatives and instead concentrating on averaged neural activities, simplifying the computational graph significantly. The authors support their approach through theoretical analysis demonstrating gradient approximation and extensive experiments showcasing comparable performance to BPTT with substantially lower resource consumption. This approach offers a compelling alternative to existing efficient training techniques for SNNs and holds promise for enabling larger-scale SNN training in resource-constrained environments. However, the trade-off between accuracy and simplification needs further analysis, particularly with respect to complex temporal dependencies potentially lost through the rate-coding approximation.
Gradient Approx#
A section titled ‘Gradient Approx’ in a research paper would likely detail the approximation methods used for calculating gradients, especially relevant when dealing with non-differentiable functions or complex models. The core of this section would involve justifying the chosen approximations. This might include a theoretical analysis comparing the approximated gradients to the true gradients, potentially using error bounds or convergence proofs to demonstrate the validity of the approximation. The authors would likely support their theoretical claims with empirical evidence, showcasing results demonstrating comparable model performance between using the exact gradients and the approximation. A crucial aspect would be discussing the trade-offs between accuracy and computational efficiency; approximations are often employed to improve training speed or reduce memory requirements. Therefore, a strong ‘Gradient Approx’ section would provide a clear understanding of how the approximation works, why it’s valid, and what implications it has on the overall results.
Benchmark Results#
A dedicated ‘Benchmark Results’ section would ideally present a comprehensive evaluation of the proposed method against established state-of-the-art techniques. Quantitative metrics such as accuracy, precision, recall, F1-score, and efficiency (e.g., training time, memory usage) should be meticulously reported across multiple relevant datasets. The choice of benchmarks should be justified, reflecting the diversity and representativeness of the problem domain. Error bars or confidence intervals are crucial to demonstrate statistical significance and the reliability of the reported results. A detailed analysis of the results, including comparisons across different model architectures and hyperparameter settings, would provide valuable insights into the strengths and weaknesses of the proposed approach, and reveal potential areas for future improvements. The visualization of results using tables and figures should be clear, concise, and easy to interpret.
Future of SNNs#
The future of spiking neural networks (SNNs) is bright, driven by their inherent energy efficiency and biological plausibility. Hardware advancements in neuromorphic computing will be crucial for realizing the full potential of SNNs, enabling faster and more efficient training and inference. Algorithmic innovations are needed to overcome current limitations in training deep SNNs, potentially focusing on hybrid approaches that leverage the strengths of both SNNs and artificial neural networks (ANNs). New learning paradigms beyond backpropagation through time (BPTT), such as those inspired by biological learning mechanisms, are essential for scaling SNNs to larger and more complex tasks. Furthermore, bridging the gap between SNNs and ANNs will facilitate the development of more robust and scalable training methods. Addressing challenges related to spike coding schemes and the interpretation of SNN outputs will be important for broader adoption. Ultimately, the future of SNNs likely involves a synergy of hardware and software advancements, leading to more efficient and powerful AI systems that are more energy-efficient and biologically inspired.
More visual insights#
More on figures
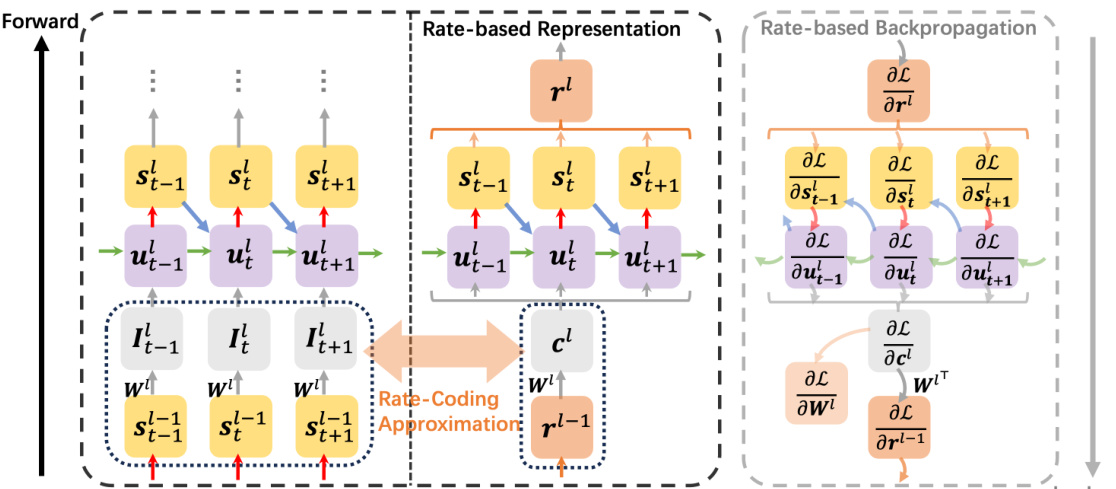
The figure illustrates the core idea of the proposed rate-based backpropagation method. The left side shows the standard forward pass in a spiking neural network (SNN) where the inputs are spike trains (st) that are processed to produce membrane potentials (ut) and then spike outputs (st). The middle section illustrates the core of the new rate-based approach: calculating the average firing rate (r) over time for each neuron, approximating the average input (c) to the next layer by simply using the weighted average of the previous layer’s firing rate, and using this average input to determine the output firing rate of the layer. Finally, the right side shows the backpropagation process, where the error (∂L/∂r) is backpropagated through the rate-based representations, simplifying the computation and reducing memory usage compared to traditional backpropagation through time (BPTT).
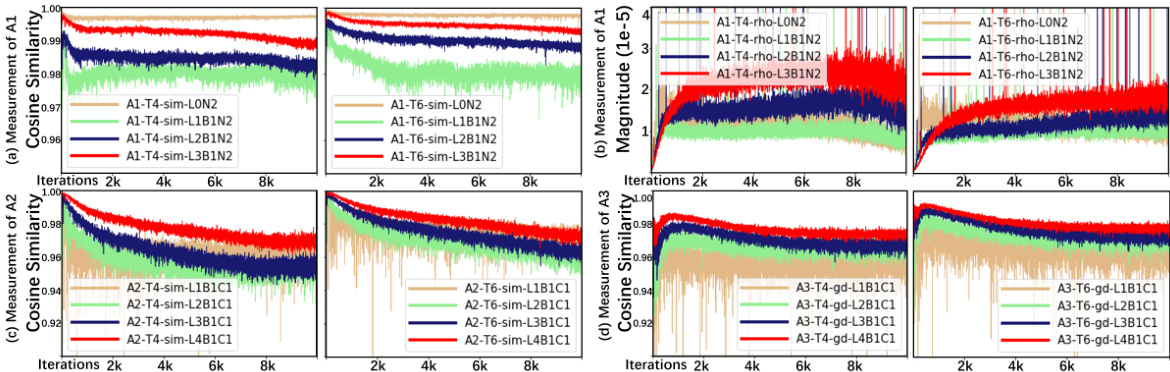
This figure shows empirical results supporting the theoretical analysis in the paper. Subplots (a), (b), and (c) present measurements of different quantities (A1, A2, A3) to demonstrate the relative independence of certain variables in the training process, particularly concerning the assumptions of rate coding and the approximation of gradients. Subplot (d) visually compares the gradient descent directions between rate-based backpropagation and BPTT. This provides empirical evidence that the proposed method effectively approximates the behavior of BPTT, especially as the number of timesteps increases.
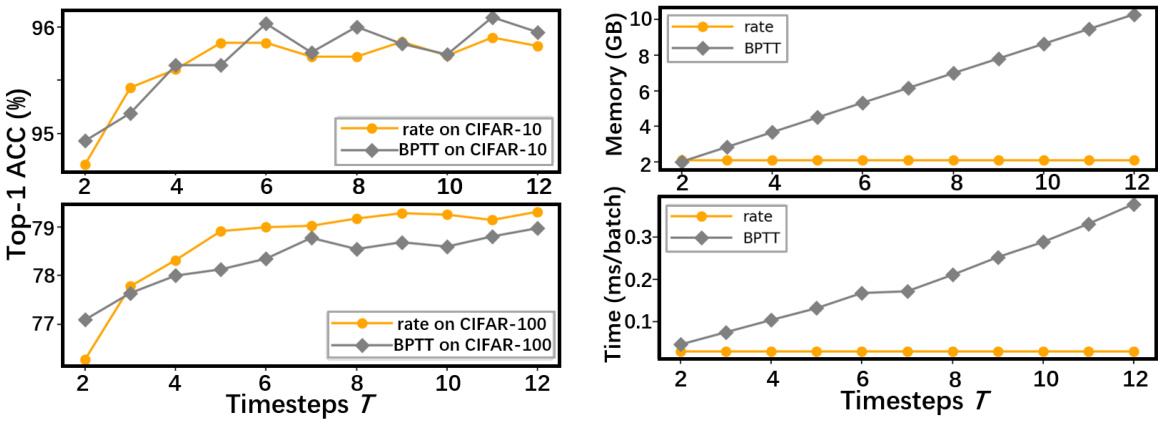
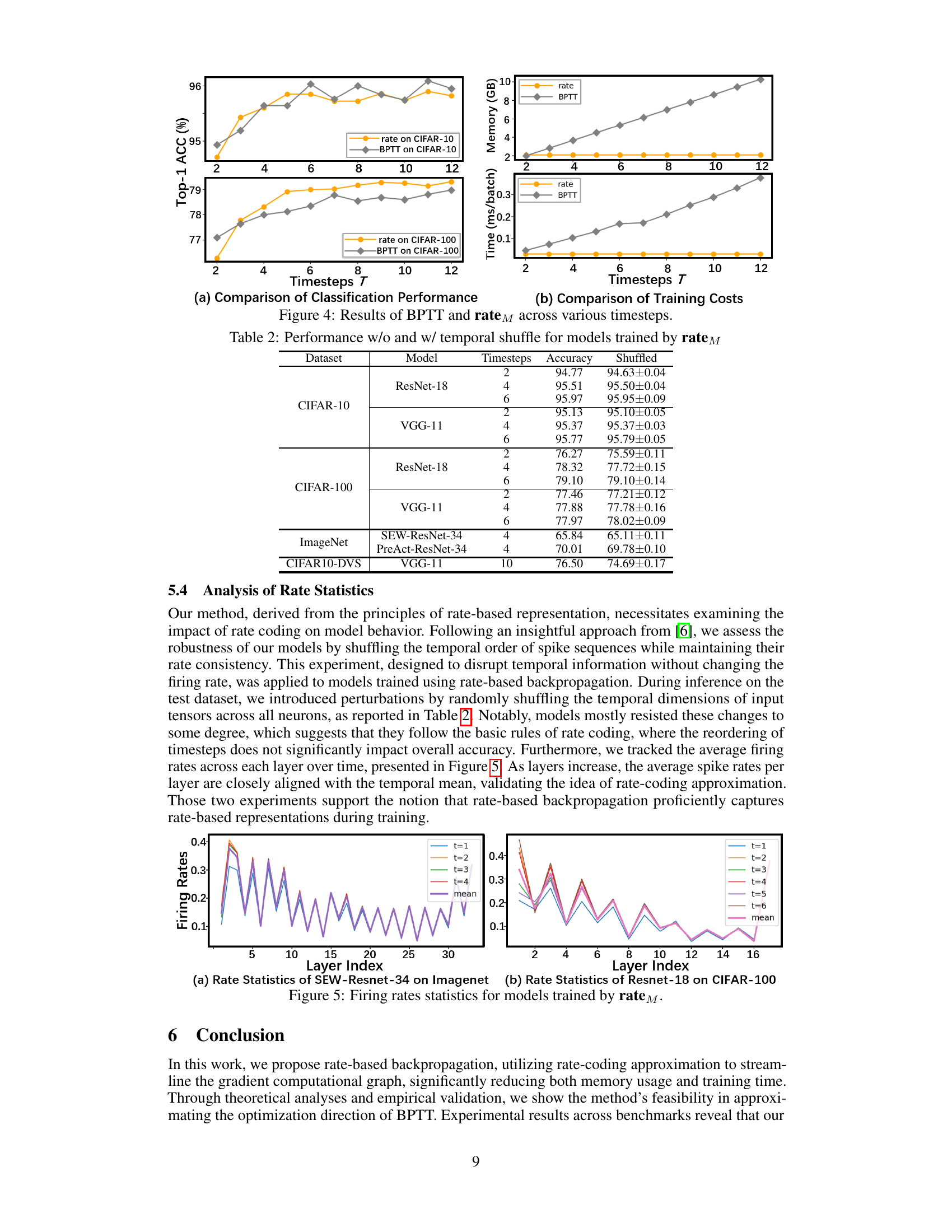
This figure shows a comparison of the classification performance and training costs between BPTT and the proposed rate-based backpropagation method (ratem) across different numbers of timesteps (T). The top-left plot shows that both methods achieve comparable accuracy, with a slight edge for BPTT at lower timesteps and ratem showing better scalability. The top-right plot demonstrates that memory usage increases linearly with timesteps for both methods, but ratem consistently uses less memory. The bottom-left plot shows that the training time for ratem remains nearly constant across different timesteps, whereas BPTT’s training time increases linearly. This indicates the superior efficiency of the rate-based method in terms of memory and computational time.
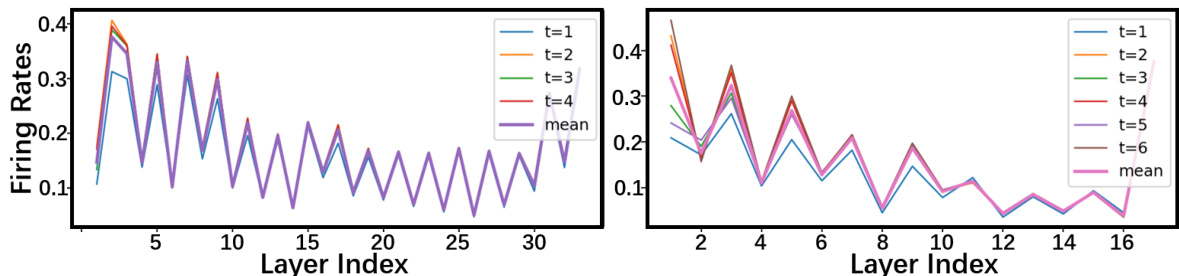
This figure visualizes the average firing rates across different layers of a spiking neural network (SNN) trained using the proposed rate-based backpropagation method. The left panel shows the firing rates for different timesteps (t=1 to t=4) in a ResNet-34 model trained on the ImageNet dataset. The right panel displays a similar analysis for a ResNet-18 model trained on the CIFAR-100 dataset, but with an extended time range (t=1 to t=6). The purple line in each panel represents the average firing rate across all timesteps (mean), highlighting the rate-coding nature of the trained models. The convergence of the firing rates towards the mean supports the method’s effectiveness in leveraging rate coding for efficient training.

This figure presents the results of empirical measurements conducted on the training procedure of Backpropagation Through Time (BPTT). The experiments used the CIFAR-100 dataset and ResNet-18 architecture. Each subplot shows the results of a specific test, with labels indicating the test number, number of timesteps, target variable (A1-A3), layer and block number, number of LIF neurons, or number of convolutional layers. The subplots visualize the cosine similarity and magnitude of variables to demonstrate the relative independence between certain variables. These tests were conducted to support the claims made in the paper about the independence of certain variables used in rate-based backpropagation.
More on tables
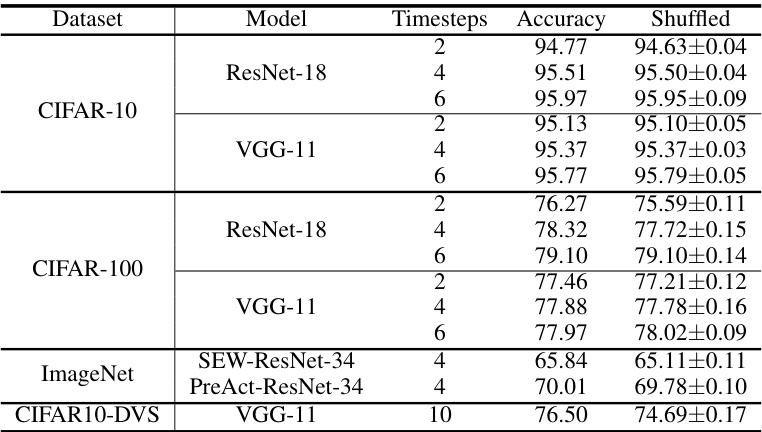
This table presents a comparison of the proposed rate-based backpropagation method against several state-of-the-art SNN training methods across four benchmark datasets: CIFAR-10, CIFAR-100, ImageNet, and CIFAR10-DVS. The table shows the top-1 accuracy achieved by each method on each dataset, along with the model architecture and number of timesteps used. Note that some methods use scaled weight standardization (*).
This table compares the performance of the proposed rate-based backpropagation method against several state-of-the-art SNN training methods across four benchmark datasets: CIFAR-10, CIFAR-100, ImageNet, and CIFAR10-DVS. The table shows the top-1 accuracy achieved by each method using different network architectures (ResNet-18, ResNet-19, VGG-11) and various numbers of timesteps. It highlights the comparable or superior performance of the proposed method.
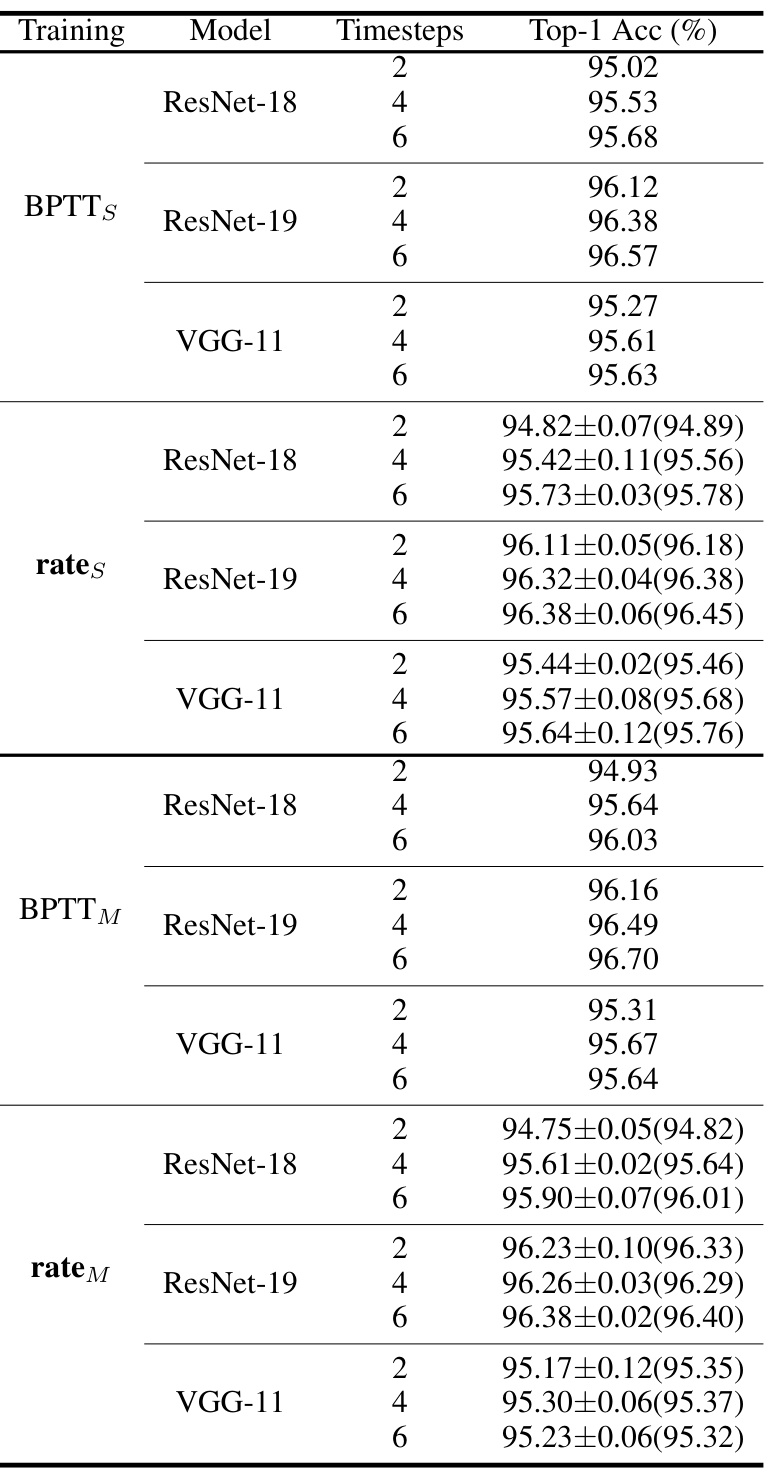
This table presents the classification accuracy results of different deep spiking neural network (SNN) training methods on four benchmark datasets: CIFAR-10, CIFAR-100, ImageNet, and CIFAR10-DVS. The table compares the performance of the proposed rate-based backpropagation methods (‘rates’ and ‘ratem’) against several state-of-the-art SNN training techniques, including BPTT (standard and modified versions), OTTT, SLTT, and OS. The results show the top-1 accuracy achieved by each method on each dataset. Note that some methods use scaled weight standardization (*) to adapt to normalizer-free architectures.

This table presents a comparison of the Top-1 accuracy achieved by different SNN training methods (including the proposed rate-based backpropagation) on four benchmark datasets: CIFAR-10, CIFAR-100, ImageNet, and CIFAR10-DVS. The results are averaged across three independent runs for most experiments, except for ImageNet (single crop). Some models use scaled weight standardization to work with normalizer-free architectures. The table allows readers to compare the performance of the proposed method against state-of-the-art SNN training techniques.
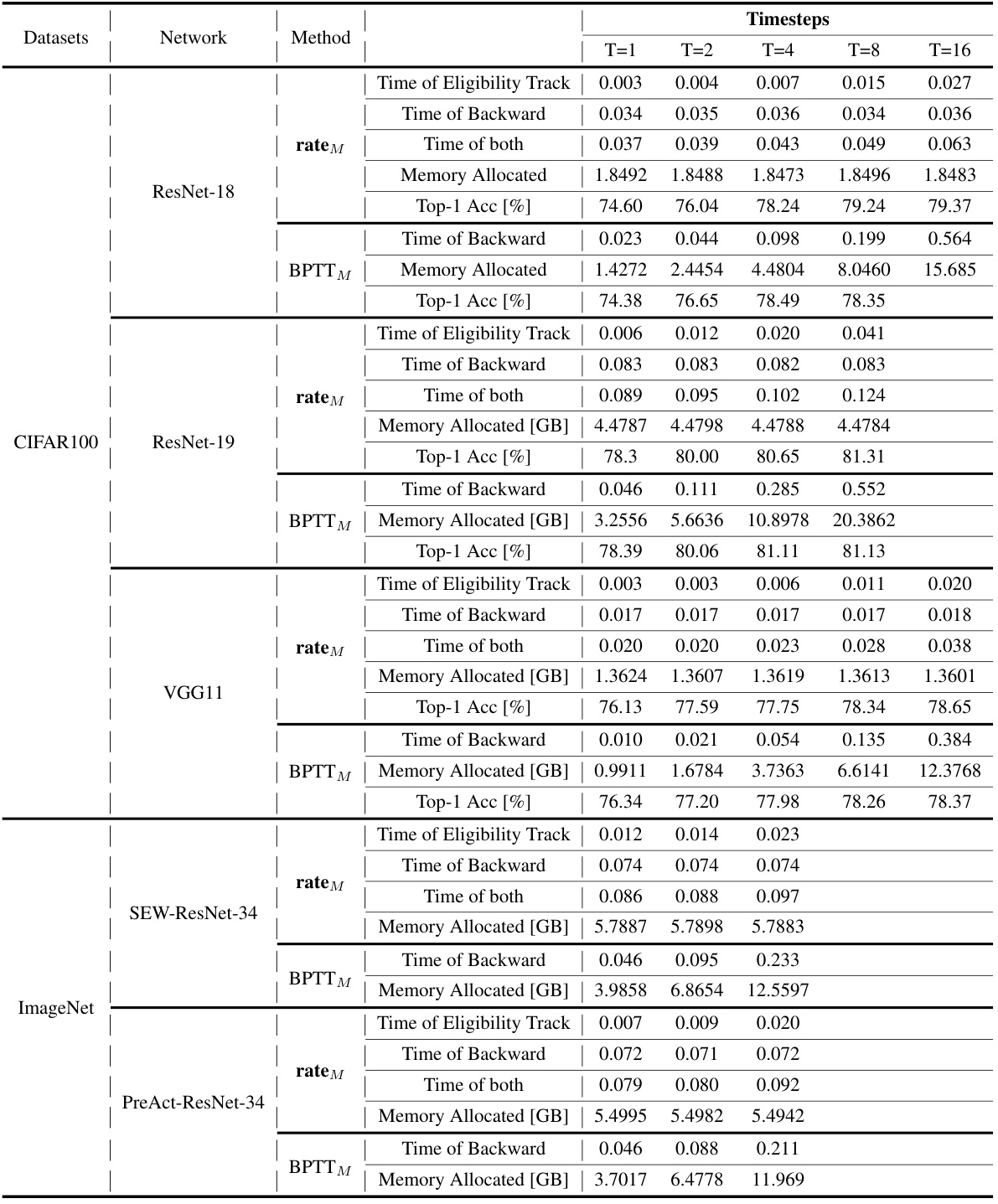
This table presents the top-1 accuracy results achieved by different SNN training methods (including the proposed rate-based backpropagation) on four benchmark datasets: CIFAR-10, CIFAR-100, ImageNet, and CIFAR10-DVS. It compares the performance of the proposed method to several state-of-the-art efficient training techniques and the standard BPTT training method on various network architectures. Note that some models use scaled weight standardization.
Full paper#