↗ OpenReview ↗ NeurIPS Homepage ↗ Hugging Face ↗ Chat
TL;DR#
Current LLM serving systems often use simple First-Come-First-Serve (FCFS) scheduling, leading to inefficiencies like Head-Of-Line (HOL) blocking and reduced throughput. Predicting the exact output length of each request is difficult. This paper proposes a new approach that focuses on ranking the relative output lengths of a batch of requests, instead of trying to accurately predict the exact length for each request. This is computationally cheaper and proves to be more robust.
The authors developed a novel scheduler that leverages learning to rank to approximate the shortest-job-first (SJF) schedule. They integrated this scheduler into a state-of-the-art LLM serving system and demonstrated significant performance improvements. Specifically, they achieved a 2.8x reduction in latency for chatbot serving and a 6.5x increase in throughput for synthetic data generation. The method is simple, efficient, and easily integrable into production systems, offering a valuable solution to enhance LLM performance. The code is publicly available, allowing other researchers to reproduce the findings and build upon this work.
Key Takeaways#
Why does it matter?#
This paper is highly important for researchers working on large language model (LLM) serving systems. It introduces a novel and efficient scheduling method that significantly improves LLM performance, addressing a critical challenge in deploying LLMs for real-world applications. The findings could inspire further research into improving the efficiency and scalability of LLM serving systems, opening up new possibilities for optimizing the user experience and system throughput. The practical implications are significant, as the proposed learning-to-rank approach is relatively simple to implement and integrate into existing systems.
Visual Insights#
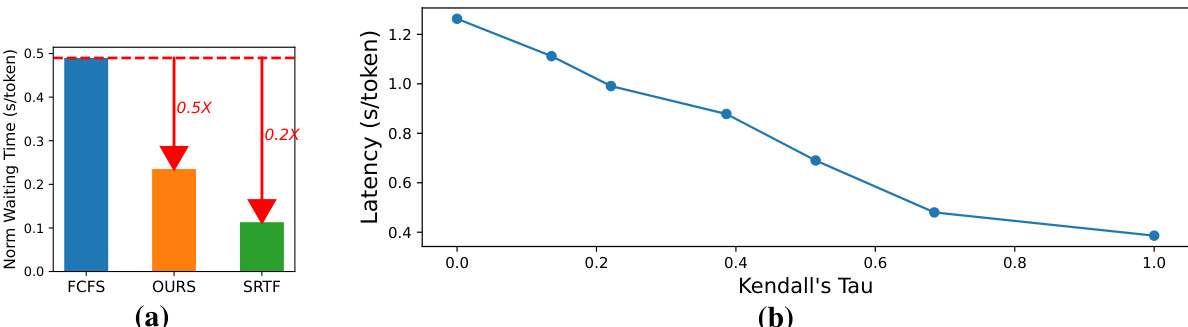
This figure shows the results of an experiment comparing different scheduling policies for LLM requests. Subfigure (a) demonstrates the reduction in HOL blocking achieved by using SRTF (Shortest Remaining Time First) compared to FCFS (First Come First Served). Subfigure (b) displays the correlation between Kendall’s Tau (a measure of rank correlation) and the latency. The higher the Kendall’s Tau, the closer the predicted schedule is to the optimal SRTF schedule, resulting in lower latency. This demonstrates the effectiveness of using learning to rank for LLM scheduling.

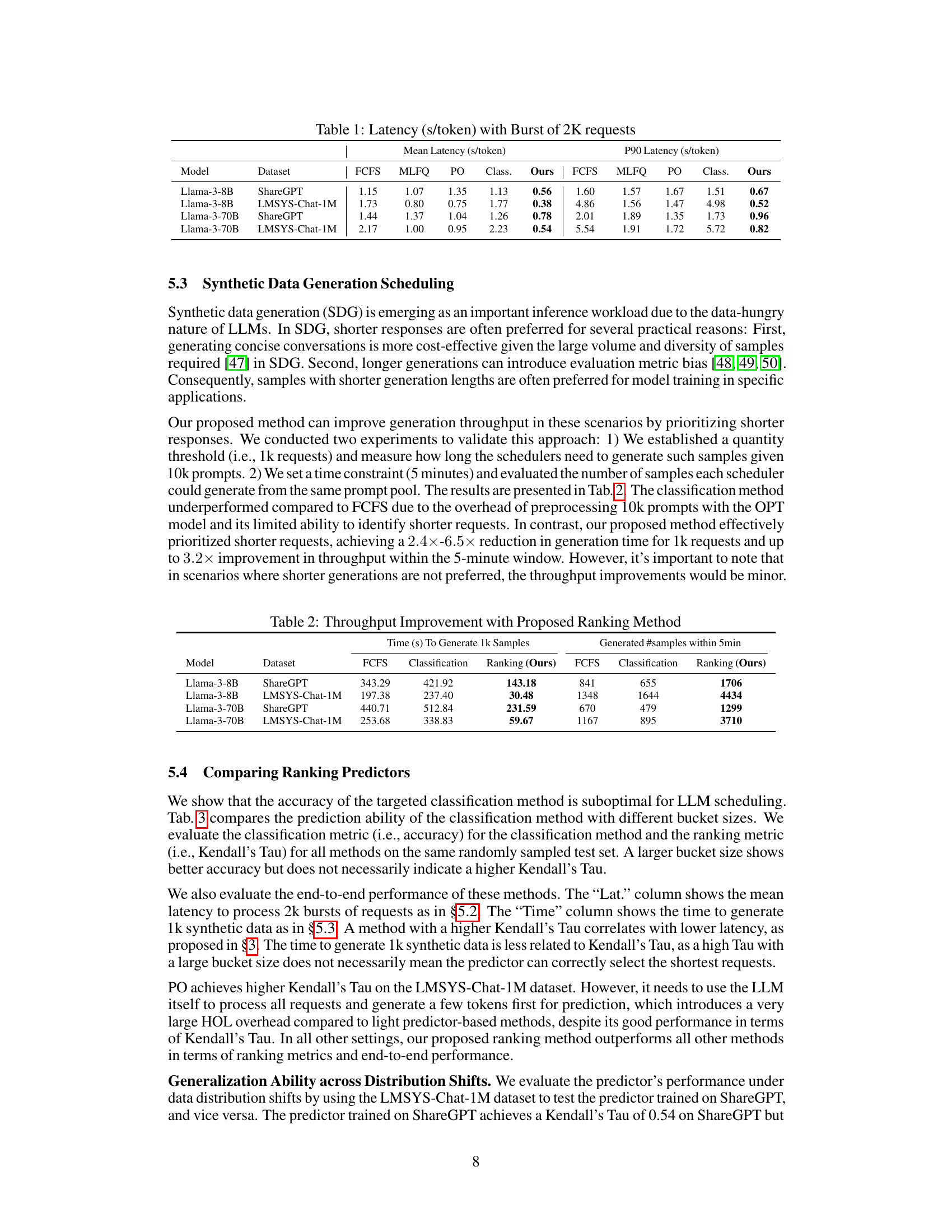
This table presents the mean and p90 latency in seconds per token for different scheduling methods (FCFS, MLFQ, PO, Classification, Ours) under a burst of 2000 requests. The latency is measured for two different Llama-3 models (8B and 70B parameters) on two different datasets (ShareGPT and LMSYS-Chat-1M). The ‘Ours’ column represents the results of the proposed ranking-based scheduling method.
In-depth insights#
LLM Scheduling#
LLM scheduling is a critical area of research in optimizing large language model (LLM) serving systems. Traditional scheduling methods, such as First-Come-First-Serve (FCFS), often lead to significant Head-of-Line (HOL) blocking and reduced performance. The paper explores the limitations of predicting exact LLM output lengths and proposes a novel approach that leverages learning to rank to approximate the Shortest-Job-First (SJF) schedule. This approach uses an auxiliary model to predict the relative rankings of output lengths within a batch of requests. The ranking information guides request scheduling, significantly improving performance. The use of Kendall’s Tau to measure ranking similarity and ListMLE loss for training the ranking model are crucial contributions. While the paper demonstrates significant improvement in latency and throughput, it also acknowledges the limitations of the ranking metric and the need for further work, especially in handling starvation of long requests. The proposed starvation prevention mechanism adds to the scheduler’s robustness. The overall approach is efficient, simple and readily integrated into existing LLM serving systems, making it potentially impactful for real-world applications.
Learning to Rank#
The concept of “Learning to Rank” in the context of LLM scheduling offers a powerful approach to approximate shortest-job-first (SJF) scheduling without explicitly predicting the exact generation length of each request. This is crucial because precise length prediction remains computationally expensive and unreliable. Instead, the focus shifts to learning the relative ranking of requests based on their generation lengths. This is achieved by training a ranking model which is significantly simpler to implement compared to those trying to predict the exact length. By employing Kendall’s Tau to assess the quality of generated rankings, the approach directly optimizes towards the desired SJF behavior. The use of a listwise ranking loss function, like ListMLE, further enhances the accuracy and robustness of this ranking. This method offers a significant advantage in improving the overall efficiency of LLM serving systems, demonstrably reducing latency and increasing throughput. The simplicity of this technique makes integration into existing LLM serving frameworks easier and more practical. Moreover, the approach’s reliance on relative rankings rather than absolute values contributes to its robustness against various input distributions.
Kendall’s Tau Metric#
The Kendall’s Tau metric, a valuable tool for measuring the correlation between two rankings, offers crucial insights into the efficiency of LLM scheduling. Its strength lies in its ability to assess the agreement between a predicted schedule and an optimal schedule (like Shortest Job First), without relying on the precise prediction of job lengths. This is particularly important in LLM contexts where accurately predicting the length of a response beforehand is often computationally expensive or infeasible. By focusing on the relative rankings of job lengths, Kendall’s Tau provides a robust metric that aligns well with the practical goal of minimizing latency and maximizing throughput in LLM serving systems. A higher Kendall’s Tau score indicates a stronger correlation between the predicted and optimal rankings, implying better performance. However, it’s vital to note that Kendall’s Tau’s insensitivity to the magnitude of rank differences could be a limitation. While it provides a valuable overall measure of rank agreement, it may not fully capture the performance impact of small deviations in rank for specific requests. Therefore, while Kendall’s Tau serves as an effective measure for evaluating LLM schedulers, it should be considered in conjunction with other relevant performance metrics for a holistic assessment.
Starvation Prevention#
The concept of starvation prevention in the context of LLM scheduling addresses a crucial weakness of shortest-job-first (SJF) and similar algorithms. While SJF excels at minimizing average latency, it can lead to long requests being perpetually delayed, a phenomenon known as starvation. The proposed solution introduces a mechanism to monitor request wait times, specifically focusing on the maximum waiting time a user experiences (max_waiting_time). This metric balances fairness and performance, as longer waiting times negatively impact user satisfaction. By tracking a request’s starvation count, the algorithm strategically boosts the priority of those requests that have waited beyond a predefined threshold, ensuring they get processed and preventing indefinite delays. The clever introduction of a ‘quantum’ of execution time provides a way to temporarily prioritize a starving request without completely derailing the SJF-like behavior of the system. This mechanism carefully balances fairness with efficiency, avoiding drastic deviations from optimal scheduling while still addressing the starvation issue. Starvation prevention is thus a key element in making the algorithm robust and suitable for practical real-world deployment.
Future Directions#
Future research could explore several promising avenues. Improving the accuracy and robustness of the generation length ranking predictor is crucial; exploring alternative ranking models or incorporating additional features beyond prompt text could enhance performance. Investigating the interaction between the proposed scheduler and other LLM serving optimizations, such as different batching strategies or memory management techniques, would reveal potential synergistic effects. Extending the scheduler to handle more complex scenarios, like real-world bursty traffic patterns or supporting multi-round conversations, is also essential for practical deployment. Finally, a rigorous evaluation across a wider range of LLMs and datasets, focusing on different performance metrics beyond latency and throughput, is needed to assess generalizability and identify potential limitations.
More visual insights#
More on figures
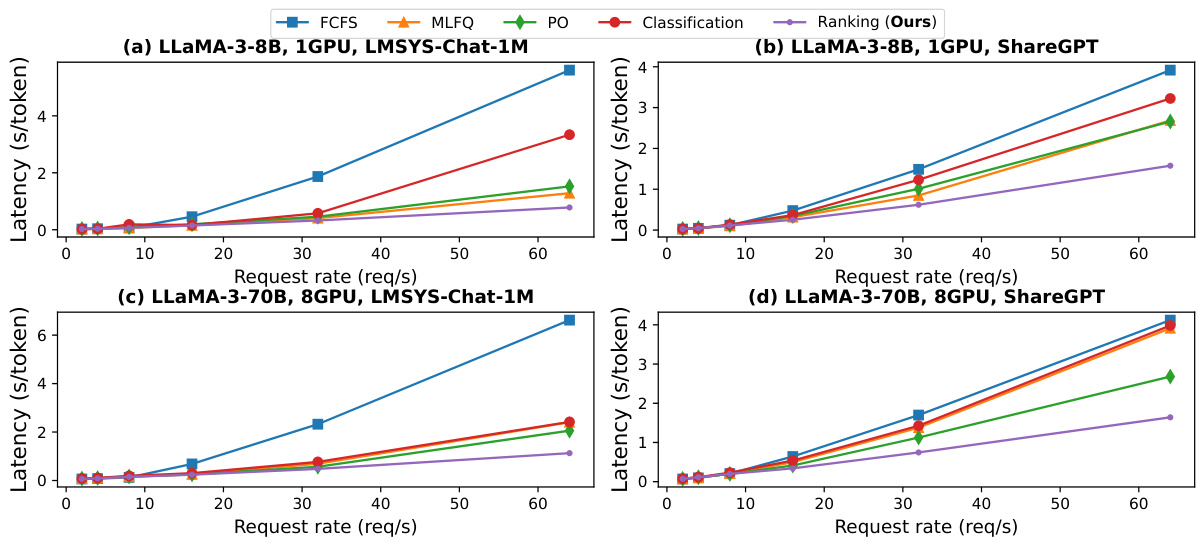
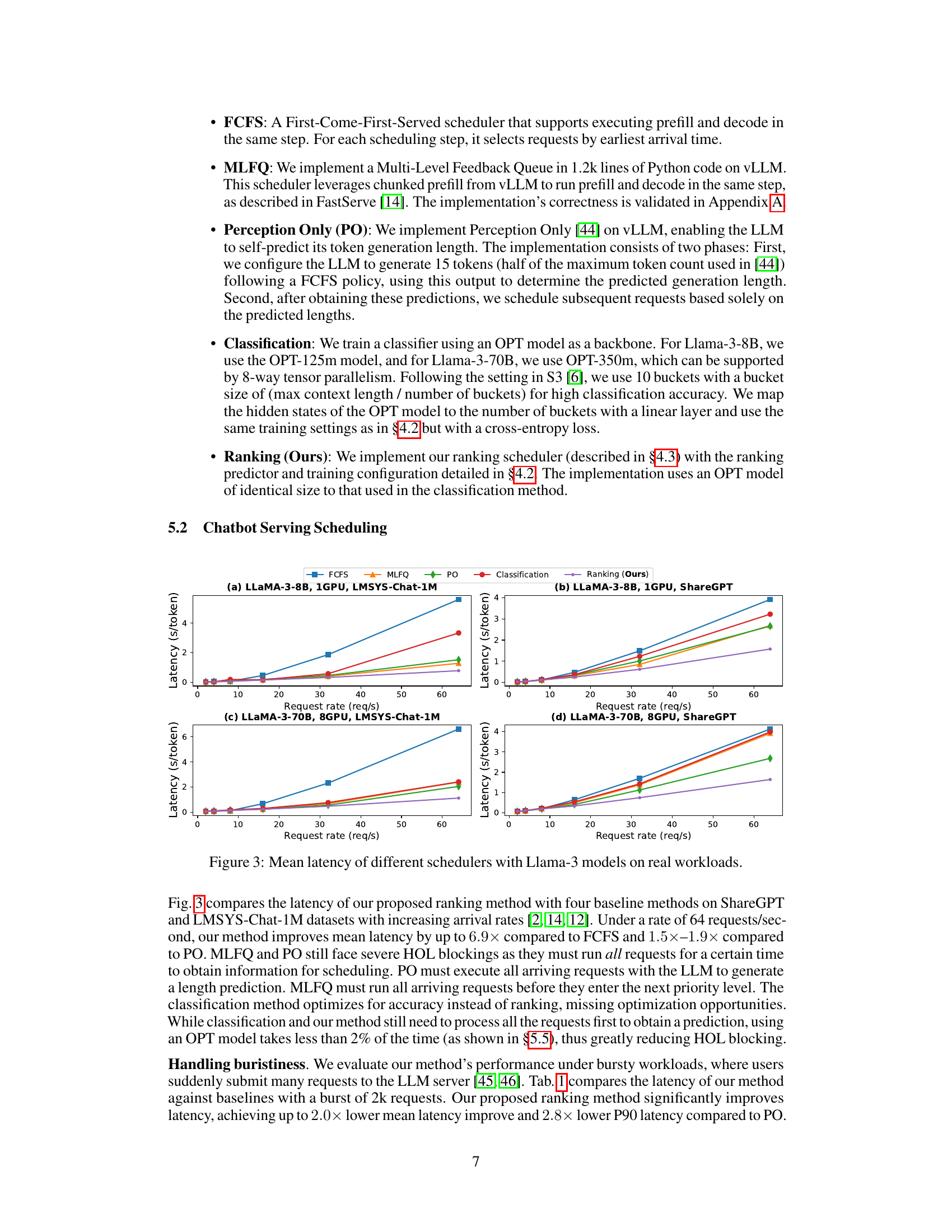
This figure compares the mean latency of different request scheduling methods (FCFS, MLFQ, Perception Only, Classification, and the proposed Ranking method) using Llama-3 language models (8B and 70B parameters) on two real-world datasets (ShareGPT and LMSYS-Chat-1M). The x-axis represents the request rate (requests per second), and the y-axis shows the mean latency in seconds per token. The results demonstrate the effectiveness of the proposed ranking method in reducing latency compared to the baselines, especially at higher request rates where head-of-line blocking becomes more significant. The 70B parameter model shows greater improvements compared to the 8B model, which is expected given the increased capacity.

This figure compares the average maximum waiting time experienced by users across different scheduling methods (FCFS, Ranking, and Ranking with Starvation Prevention) under varying request rates. It visualizes the impact of each scheduling strategy on user-perceived latency, particularly highlighting the effectiveness of the proposed ranking method, especially when combined with starvation prevention, in mitigating longer wait times for individual requests.

This figure compares the mean latency of four different request scheduling methods (FCFS, MLFQ, Perception Only, and Ranking (the proposed method)) using two different Llama-3 language models (8B and 70B parameters) and two real-world datasets (ShareGPT and LMSYS-Chat-1M). The x-axis represents the request rate (requests per second), and the y-axis shows the mean latency (seconds per token). The results show that the proposed ranking method significantly outperforms the other methods in terms of latency, especially at higher request rates, demonstrating its effectiveness in reducing latency in real-world LLM serving scenarios.

This figure shows the relationship between the finish time and output lengths of requests when using the MLFQ scheduler in the vLLM system. The x-axis represents the output lengths, and the y-axis represents the finish times. The plot shows distinct rectangular blocks, where the lengths of the blocks grow exponentially with the quantum growth rate. These blocks represent requests that were completed within queues of different priorities. When requests from higher-priority queues fail to occupy the entire sliding window, requests from lower-priority queues are then processed, resulting in the adjacent blocks. The plot also shows a linear increase in output lengths over time, representing requests that finished and left the system. Additionally, there are clear horizontal lines in the figure, which illustrate when batches of requests time out and are demoted simultaneously due to reaching multiples of the base quantum.
Figure 2(a) compares the Head-of-Line (HOL) blocking of FCFS and SRTF scheduling policies across 1000 requests, showing that SRTF significantly reduces blocking. Figure 2(b) shows a strong correlation between Kendall’s Tau (a measure of rank correlation) and latency using Llama-3-8B on the ShareGPT dataset. Higher Kendall’s Tau values, indicating better alignment with an optimal (SRTF-like) schedule, result in lower latency.
More on tables

This table presents the results of experiments comparing the throughput of the proposed ranking-based scheduling method with the FCFS (First-Come, First-Served) method for synthetic data generation. It shows the time taken to generate 1000 samples and the total number of samples generated within a 5-minute time limit for different LLM models (Llama-3-8B and Llama-3-70B) and datasets (ShareGPT and LMSYS-Chat-1M). The results demonstrate a significant improvement in throughput for the ranking-based method compared to FCFS, highlighting its effectiveness in optimizing the generation of shorter LLM responses.

This table compares the performance of different methods for predicting the ranking of LLM generation lengths, using various bucket sizes for classification and the proposed ranking method. It shows the accuracy, Kendall’s Tau correlation, mean latency in chatbot serving (processing 2k burst requests), and time to generate 1k synthetic data samples for each method. Optimal Prediction serves as a baseline representing the best achievable performance with perfect generation length knowledge.

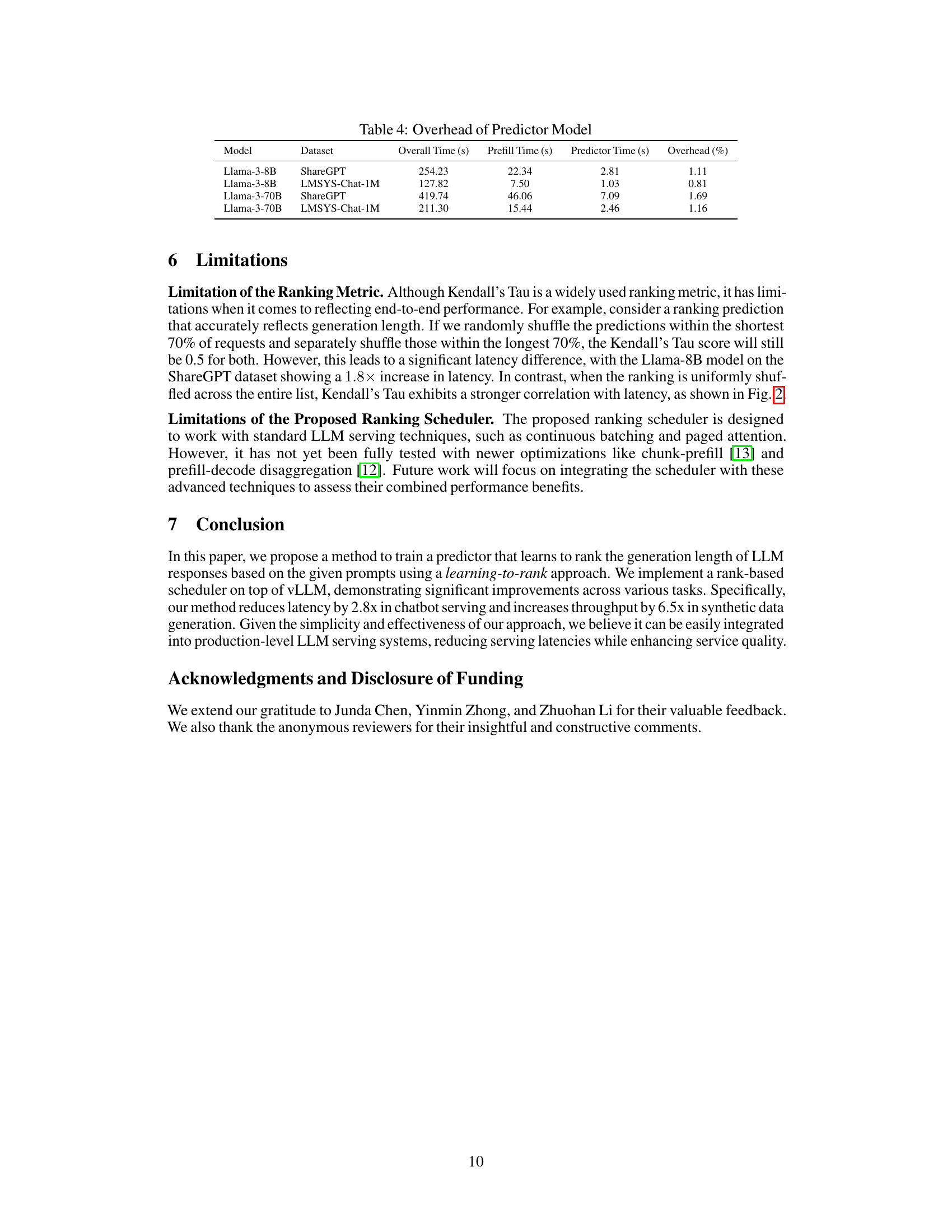
This table presents the overhead introduced by the ranking predictor model in processing 1000 requests. It compares the overall time to process the requests to the time spent on the prefill stage (without the predictor) and the time taken by the predictor alone. The final column shows the percentage of overhead introduced by the predictor relative to the overall processing time.
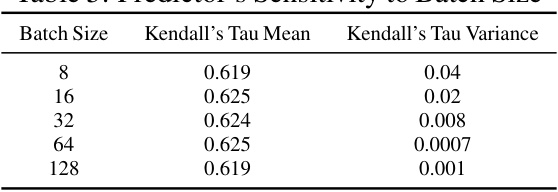
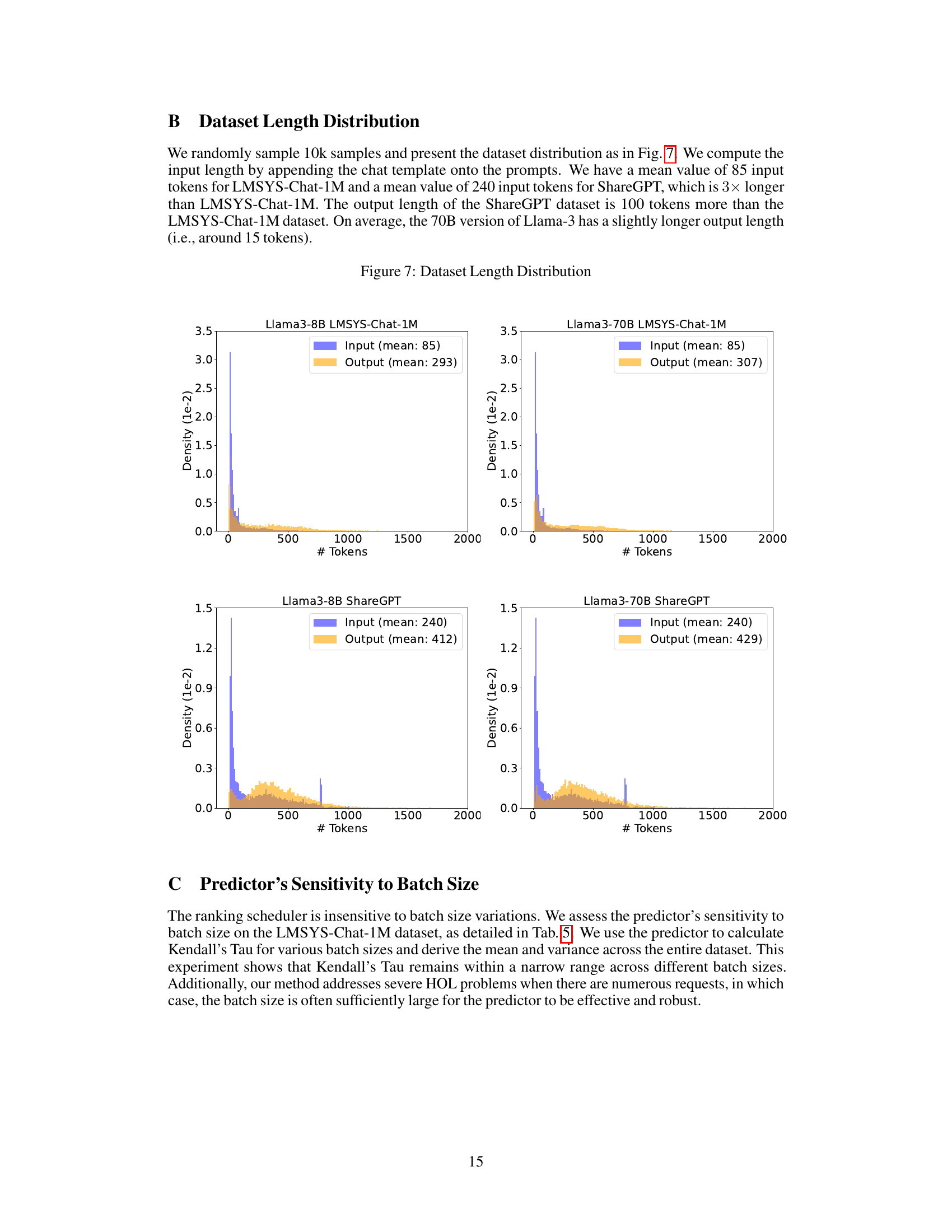
This table shows the mean and variance of Kendall’s Tau values obtained using different batch sizes for the ranking predictor model. The results indicate that the predictor’s performance is relatively insensitive to the batch size, maintaining consistent accuracy across various batch sizes.

This table shows the correlation between the ListMLE loss and Kendall’s Tau during the training process of the ranking predictor model. It demonstrates that as the ListMLE loss decreases (indicating improved model performance), Kendall’s Tau tends to increase (indicating better correlation between predicted and actual rankings). This supports the claim that minimizing ListMLE loss leads to a better approximation of the ideal SJF/SRTF schedule.

This table compares the performance of the proposed ranking method against the Oracle and the FCFS baseline. The Oracle represents the ideal scenario with perfect knowledge of generation lengths. The table shows Kendall’s Tau, a measure of ranking correlation, and the resulting latency (in seconds per token). The results demonstrate that the proposed method achieves a high correlation with the Oracle’s ranking and significantly lower latency than FCFS.
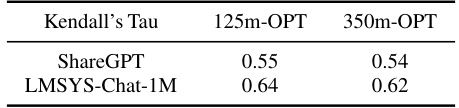
This table shows the Kendall’s Tau correlation coefficient achieved by using two different sizes of OPT models (125 million and 350 million parameters) as ranking predictors for the ShareGPT and LMSYS-Chat-1M datasets. The Kendall’s Tau score reflects the correlation between the predicted ranking of generation lengths and the actual ranking. A higher score indicates a better prediction.
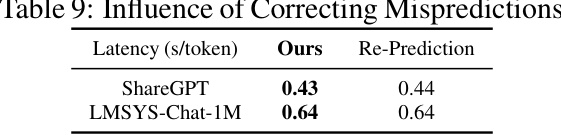
This table compares the latency (in seconds per token) of the proposed ranking-based scheduling method with and without dynamically correcting mispredictions. The results show minimal improvement from re-prediction, suggesting that the initial prediction is sufficiently accurate and that the overhead of re-prediction does not outweigh the benefit.
Full paper#