↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Reinforcement learning (RL) typically assumes agents act before observing the consequences. However, many real-world applications provide ’lookahead’ information—immediate reward or transition details before action selection. Existing RL methods often fail to effectively use this lookahead, limiting their performance. This research addresses this critical gap by focusing on episodic tabular Markov Decision Processes (MDPs).
This paper introduces novel, provably efficient algorithms to incorporate one-step reward or transition lookahead. The algorithms utilize empirical distributions of observations rather than estimated expectations, achieving tight regret bounds compared to a baseline that also has access to lookahead. The analysis extends to reward and transition lookahead scenarios. Importantly, the approach avoids computationally expensive state space augmentation, making it suitable for practical applications.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in reinforcement learning because it tackles the often-overlooked problem of lookahead information in decision-making. By providing provably efficient algorithms that leverage this information, it advances the theoretical understanding and practical application of RL, particularly in settings with immediate feedback like transaction-based systems or navigation. It opens new avenues for exploring more complex planning approaches and handling uncertainty, impacting various real-world RL applications.
Visual Insights#
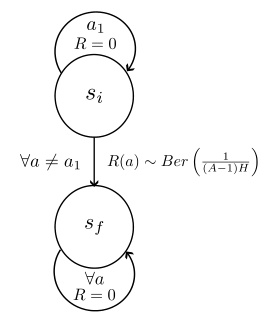
This figure depicts a two-state Markov Decision Process (MDP) to illustrate the benefit of reward lookahead. The agent starts in state si. Action a1 keeps the agent in si with zero reward. Other actions move the agent to a terminal state sf with a reward sampled from a Bernoulli distribution with a probability of success equal to 1/((A-1)H). The terminal state yields zero reward. The key insight is that with reward lookahead, the agent observes the reward distribution for each action before making a decision; this drastically increases its expected reward, highlighting the advantages of using lookahead information.
Full paper#



















