↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current multimodal large language models (MLLMs) often suffer from “hallucinations,” generating inaccurate responses. Existing methods using binary preferences (superior/inferior) for reinforcement learning have limitations. This approach has a gap between levels and lacks a broader range of comparison, hindering the model’s ability to discern subtle differences and fully capture the nuances of hallucination examples.
The proposed Automated Multi-level Preference (AMP) framework tackles this by introducing multi-level preferences (superior, medium, inferior) and an automated dataset generation pipeline, creating high-quality data without human annotation. The framework also includes a new Multi-level Direct Preference Optimization (MDPO) algorithm, effectively handling complex multi-level learning. Extensive experiments demonstrate the superiority of AMP across different benchmarks, showcasing its effectiveness in reducing hallucinations and improving overall MLLM performance.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on multimodal large language models (MLLMs), particularly those focusing on reducing hallucinations. It offers a novel approach to preference learning that improves MLLM performance and opens avenues for dataset generation and algorithm development in this active research area. The introduction of a new benchmark also significantly contributes to the field.
Visual Insights#
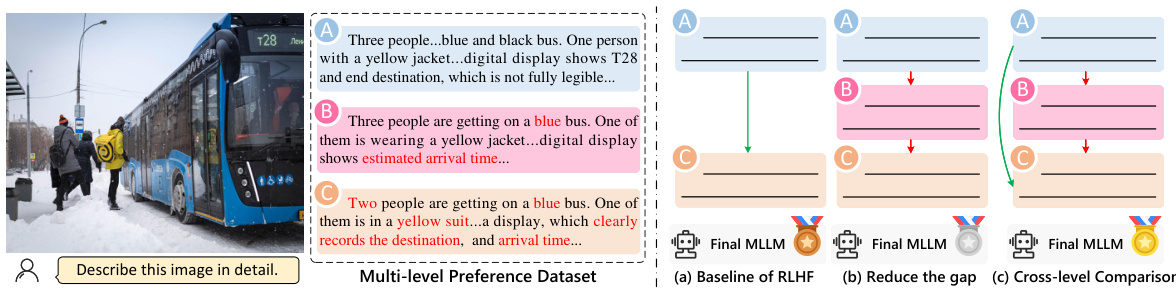
This figure illustrates the core concept of the paper: using multi-level preferences instead of binary preferences in reinforcement learning from human feedback (RLHF) for multimodal large language models (MLLMs). The left side shows an example of an image and three corresponding responses with varying levels of quality. The right side demonstrates how multi-level preferences improve RLHF. (a) shows the standard binary approach. (b) explains how to narrow the gap between quality levels by introducing intermediate responses. (c) illustrates the additional benefit of including comparisons between non-adjacent levels to incorporate a broader range of examples, especially those with hallucinations.

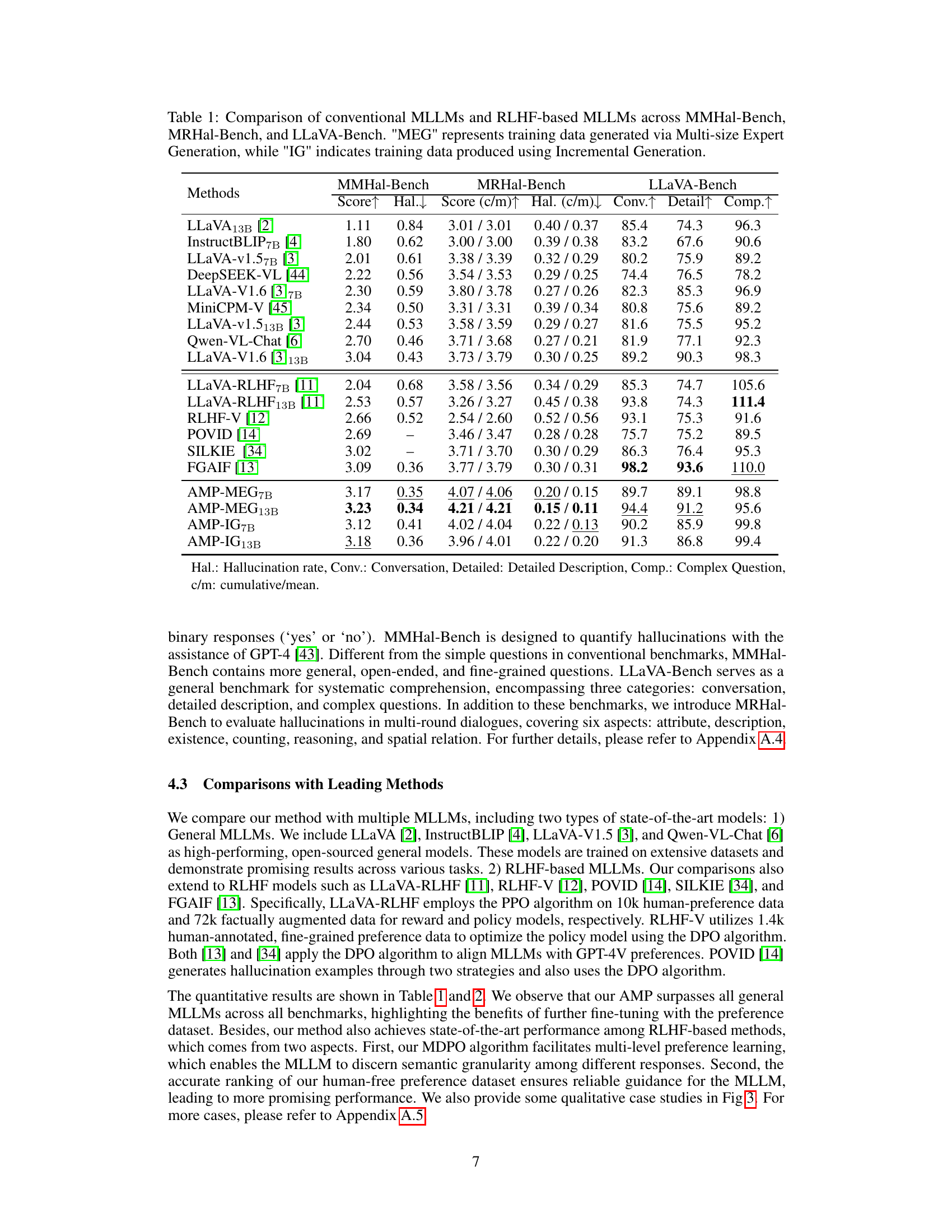
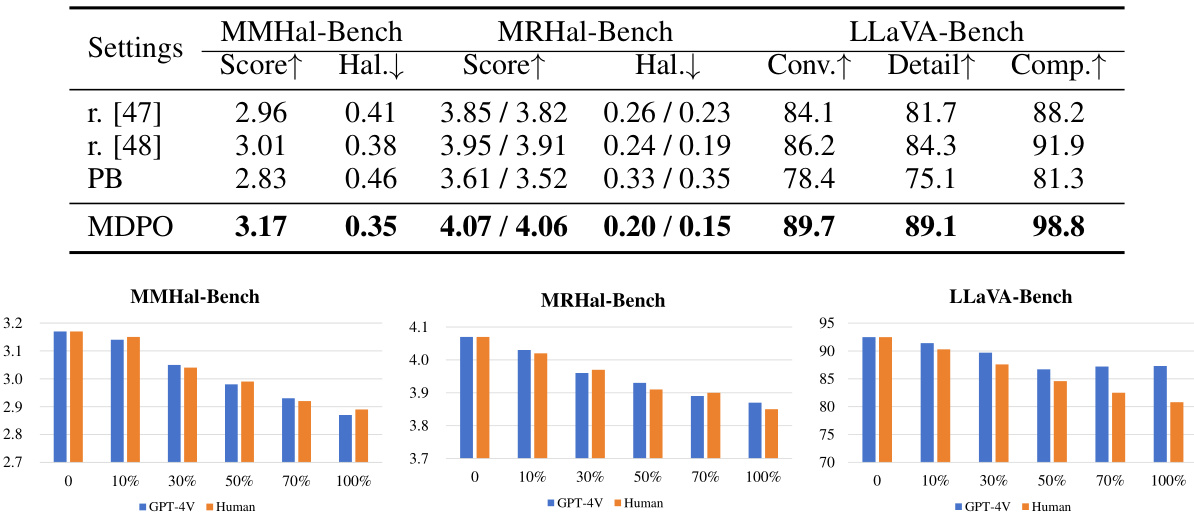
This table compares the performance of various Multimodal Large Language Models (MLLMs) on three different benchmark datasets: MMHal-Bench, MRHal-Bench, and LLaVA-Bench. It shows the scores for each model on various metrics, including hallucination rate, conversation quality, detail of descriptions, and complexity of questions. The table also differentiates between models trained with conventional methods and those fine-tuned using Reinforcement Learning from Human Feedback (RLHF), and shows the impact of two different data generation methods (Multi-size Expert Generation and Incremental Generation) on the performance of the models. Higher scores generally indicate better performance.
In-depth insights#
Multi-level RLHF#
Multi-level RLHF represents a significant advancement in reinforcement learning from human feedback (RLHF) for large language models (LLMs). Instead of relying solely on binary preferences (good/bad), multi-level RLHF incorporates nuanced rankings (e.g., excellent, good, fair, poor). This approach offers two key advantages: it reduces the gap between adjacent preference levels, making it easier for the LLM to distinguish subtle differences in response quality, and it allows for cross-level comparisons, providing richer feedback. By leveraging a wider range of preferences, multi-level RLHF enables more effective learning and can significantly mitigate the problem of response hallucinations in LLMs. The effectiveness of multi-level RLHF hinges on the quality of the preference data, emphasizing the importance of reliable annotation methods to avoid introducing bias. Automated methods for data generation become critical for scalability and to ensure objectivity. This approach promises more robust and nuanced LLMs that generate higher-quality, less hallucinated outputs.
Automated Dataset#
The concept of an ‘Automated Dataset’ in the context of a research paper is intriguing. It suggests a departure from traditional, manually-created datasets, which are often time-consuming and expensive to produce. An automated approach would likely involve using algorithms and tools to generate data, potentially leveraging existing resources. The key advantage lies in scalability and efficiency, enabling the creation of substantially larger and more diverse datasets than would be feasible manually. The paper should detail the methods used for dataset automation, including the algorithms, data sources, and any validation steps. A critical aspect will be evaluating the quality and reliability of the automatically generated data, as errors in the automated process could negatively impact research findings. Bias detection and mitigation are also crucial, as biases present in the automated approach may lead to skewed or unreliable results. The paper needs to address these aspects transparently to ensure the credibility and reproducibility of the generated dataset and subsequent research.
MDPO Algorithm#
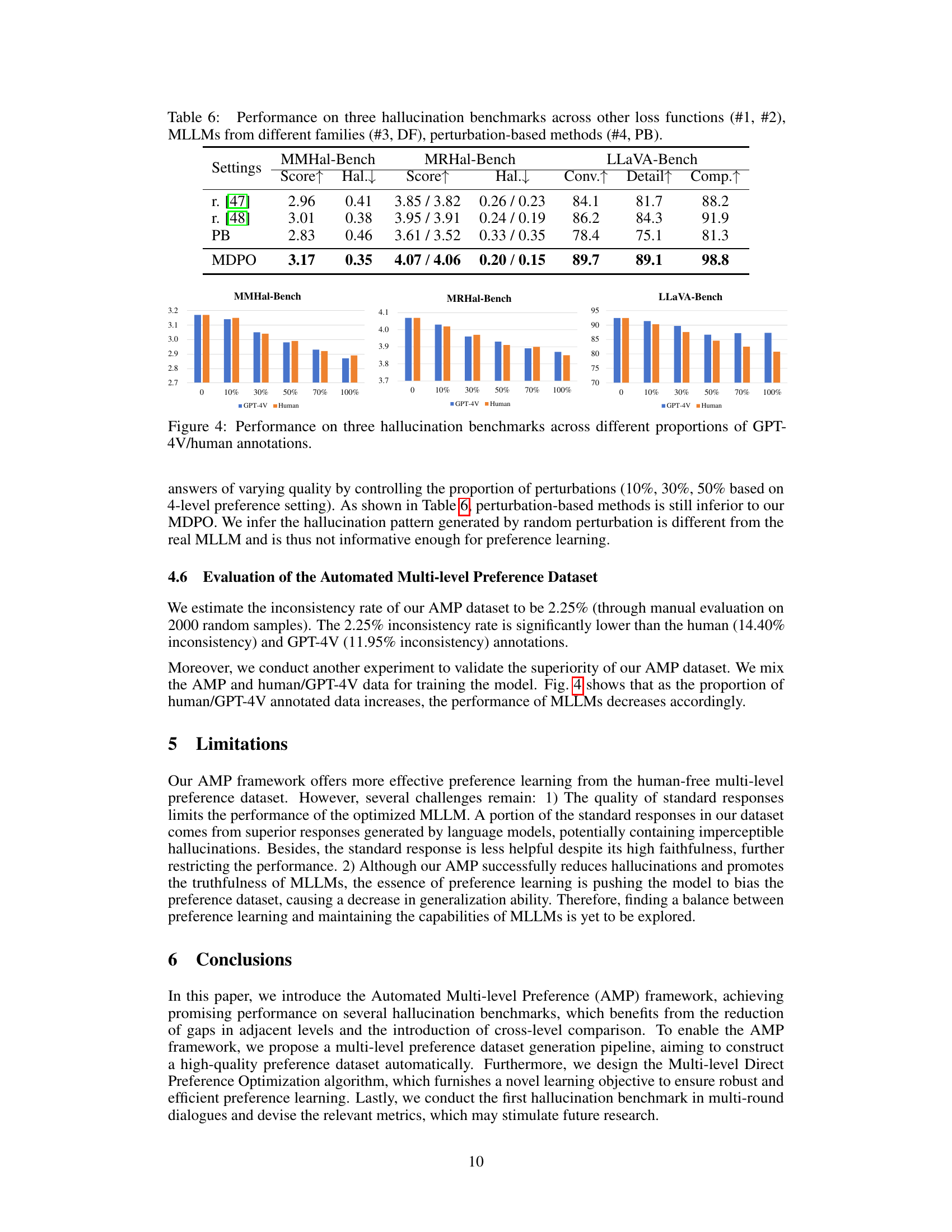
The Multi-level Direct Preference Optimization (MDPO) algorithm is a novel approach to training Multimodal Large Language Models (MLLMs) that leverages multi-level preferences, rather than the typical binary approach. MDPO refines the standard Direct Preference Optimization (DPO) algorithm by incorporating a tailored penalty term to its learning objective. This modification enhances the algorithm’s robustness and efficiency when handling complex multi-level preferences. The penalty term, specifically designed for MDPO, explicitly improves the probability of generating superior responses, mitigating the challenge of simultaneously decreasing the probabilities of both superior and inferior responses. The algorithm’s effectiveness is enhanced by reducing the gap between adjacent preference levels, encouraging the model to discern subtle differences between responses and promoting more nuanced learning. Further, the integration of cross-level comparisons (beyond adjacent levels) offers a broader range of comparisons, enabling the model to learn from a wider spectrum of examples and leading to a better understanding of subtle differences. This results in improved performance in suppressing hallucinations by leveraging both superior and inferior responses in a more sophisticated manner than previously seen in binary approaches.
Hallucination Bench#
A dedicated hallucination benchmark is crucial for evaluating large language models (LLMs), especially multimodal ones. Such a benchmark should go beyond simple accuracy metrics and delve into the types of hallucinations produced (e.g., factual inaccuracies, logical inconsistencies, or outright fabrications). It’s important to consider the context in which the hallucinations occur; a benchmark should test across various scenarios and input modalities (e.g., image captions, question answering, and dialogue). Furthermore, a robust benchmark needs to be designed to be scalable to the size and diversity of LLMs, allowing for fair and comprehensive comparison. Ideally, the benchmark should incorporate human evaluation to assess the quality and severity of hallucinations, supplementing automatic metrics to provide a more nuanced understanding of LLM performance. Bias and fairness should also be incorporated into benchmark design to ensure that evaluations are not unfairly skewed towards certain types of LLMs or datasets. Finally, regular updates to the benchmark are necessary to reflect the evolving capabilities and shortcomings of LLMs, ensuring its continued relevance and utility in the research community.
Future of MLLMs#
The future of Multimodal Large Language Models (MLLMs) is bright, but challenging. Improvements in hallucination mitigation are crucial, and the shift towards multi-level preference learning, as explored in the provided paper, is a promising direction. Automated dataset generation techniques will be vital for efficient model training and reducing reliance on expensive and potentially biased human annotation. The development of robust optimization algorithms, such as Multi-level Direct Preference Optimization (MDPO), is critical to effectively leverage complex preferences. New benchmarks, like MRHal-Bench, focusing on specific MLLM weaknesses, are needed to accurately assess progress. Furthermore, exploring methods to reduce the gap between superior and inferior responses, and integrating cross-level comparisons, will enhance the nuances of MLLM training. The ultimate goal is to develop MLLMs capable of truly understanding and accurately responding to multimodal inputs, and the ongoing research into these crucial areas promises a future of increasingly sophisticated and reliable multimodal AI systems.
More visual insights#
More on figures
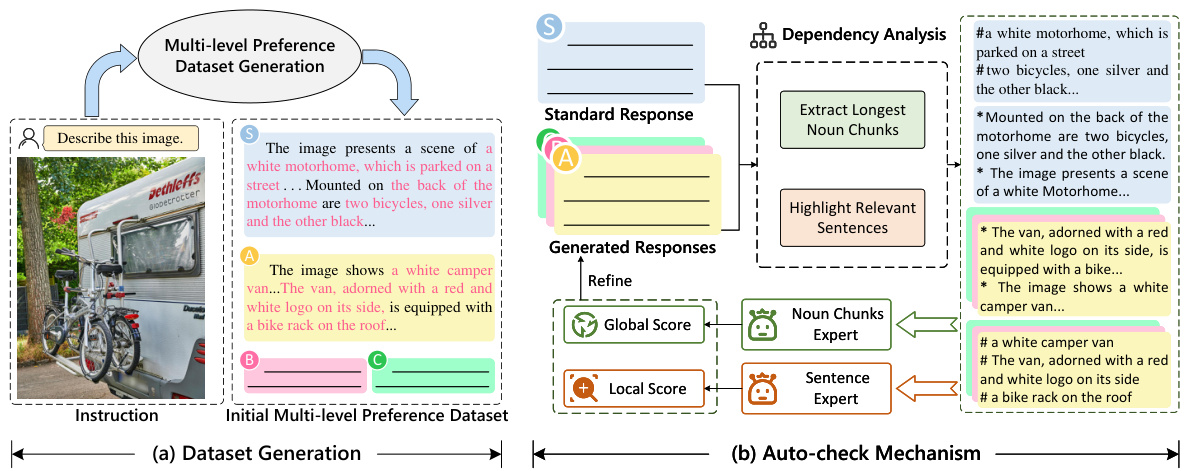
This figure illustrates the pipeline used to create a human-free multi-level preference dataset for training multi-modal language models (MLLMs). It shows two main stages: (a) Dataset Generation, which uses Multi-size Expert Generation and Incremental Generation to create an initial dataset; and (b) Auto-check Mechanism, which refines the initial dataset using global and local metrics based on sentence and noun chunk analysis to improve quality and accuracy. The goal is to generate a high-quality dataset for MLLM training without relying on human annotation.

The figure on the left shows an example of the input image, prompt, and multi-level responses generated by an MLLM. The responses are categorized into three levels (A, B, C) representing superior, medium, and inferior quality, respectively. Hallucinations in the responses are highlighted in red. The right side illustrates three strategies for improving MLLM performance using multi-level preferences: reducing the gap between adjacent levels, increasing the number of comparisons, and introducing cross-level comparisons to incorporate a wider range of response quality.
This figure illustrates the core idea of the paper: using multi-level preferences instead of binary preferences in reinforcement learning for multimodal large language models (MLLMs). The left side shows an example of a multi-level preference dataset, where responses are ranked as superior (A), medium (B), and inferior (C). The right side shows how the proposed method improves MLLM training by (b) reducing the gap between preference levels and (c) incorporating cross-level comparisons to provide a broader range of examples for learning to avoid hallucinations.

This figure illustrates the core idea of the AMP framework. The left side shows an example of a multi-level preference dataset with varying response qualities (superior, medium, inferior) and highlights hallucinated parts. The right side contrasts the traditional binary preference RLHF approach with the proposed multi-level approach, emphasizing the benefits of reducing the gap between levels and incorporating cross-level comparisons for improved MLLM training.

The figure on the left shows an example of the multi-level preference dataset used in the paper. It highlights how different responses to the same image prompt are ranked into three levels (superior, medium, inferior) based on quality and the presence of hallucinations. The figure on the right illustrates the three strategies used to improve the multi-level preference framework: reducing the gap between adjacent levels by adding medium responses; enabling cross-level comparisons to expose the model to a broader range of hallucinations; and leveraging inferior responses for better learning.

This figure illustrates the core idea of the AMP framework. The left side shows an example of a multi-level preference dataset, where responses are categorized into superior (A), medium (B), and inferior (C) based on the presence of hallucinations. The right side compares the conventional RLHF baseline (binary preference) with the proposed AMP framework. The AMP framework addresses two key challenges: reducing the gap between adjacent preference levels and incorporating cross-level comparisons to leverage a broader range of comparisons and better learn to suppress hallucinations.
More on tables
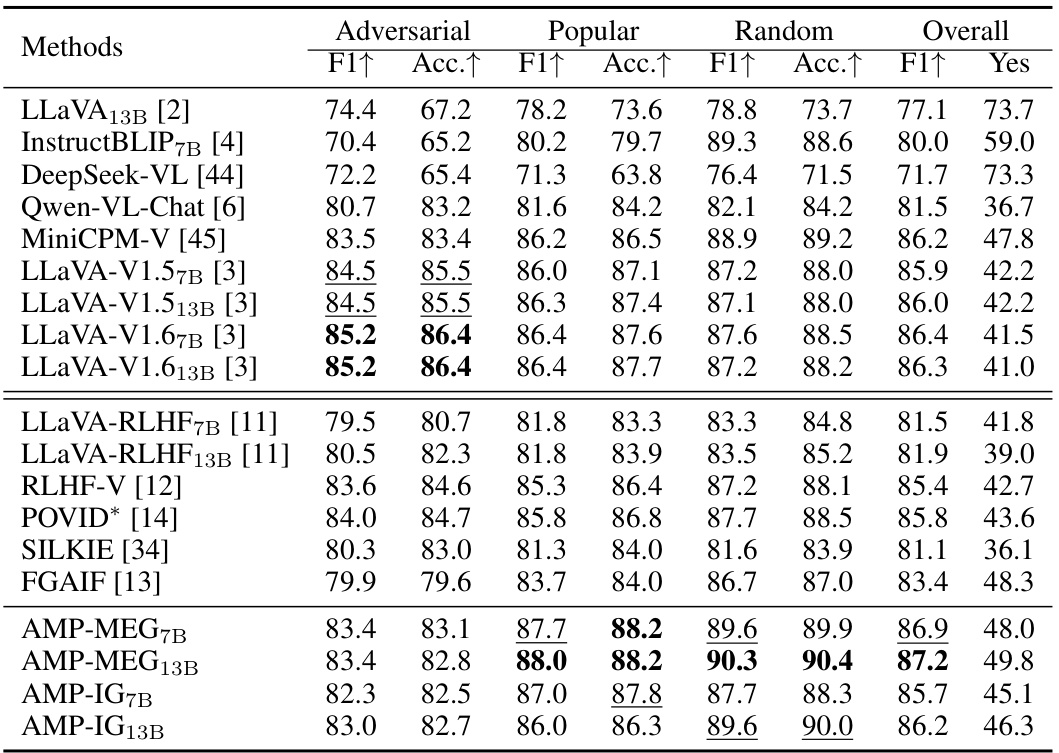
This table compares the performance of various Multimodal Large Language Models (MLLMs) across three different benchmark datasets: MMHal-Bench, MRHal-Bench, and LLaVA-Bench. The models are categorized into conventional MLLMs and those fine-tuned using Reinforcement Learning from Human Feedback (RLHF). The table shows scores for hallucination rate, conversation quality, detailed description accuracy, and complex question answering, providing a comprehensive performance comparison. Two different data generation methods (MEG and IG) are also compared for RLHF-based models.
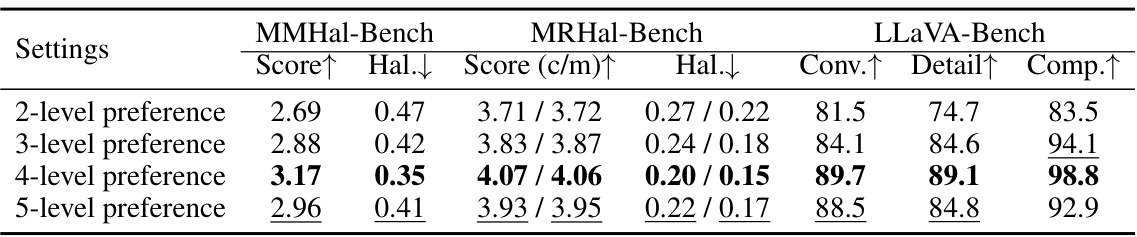
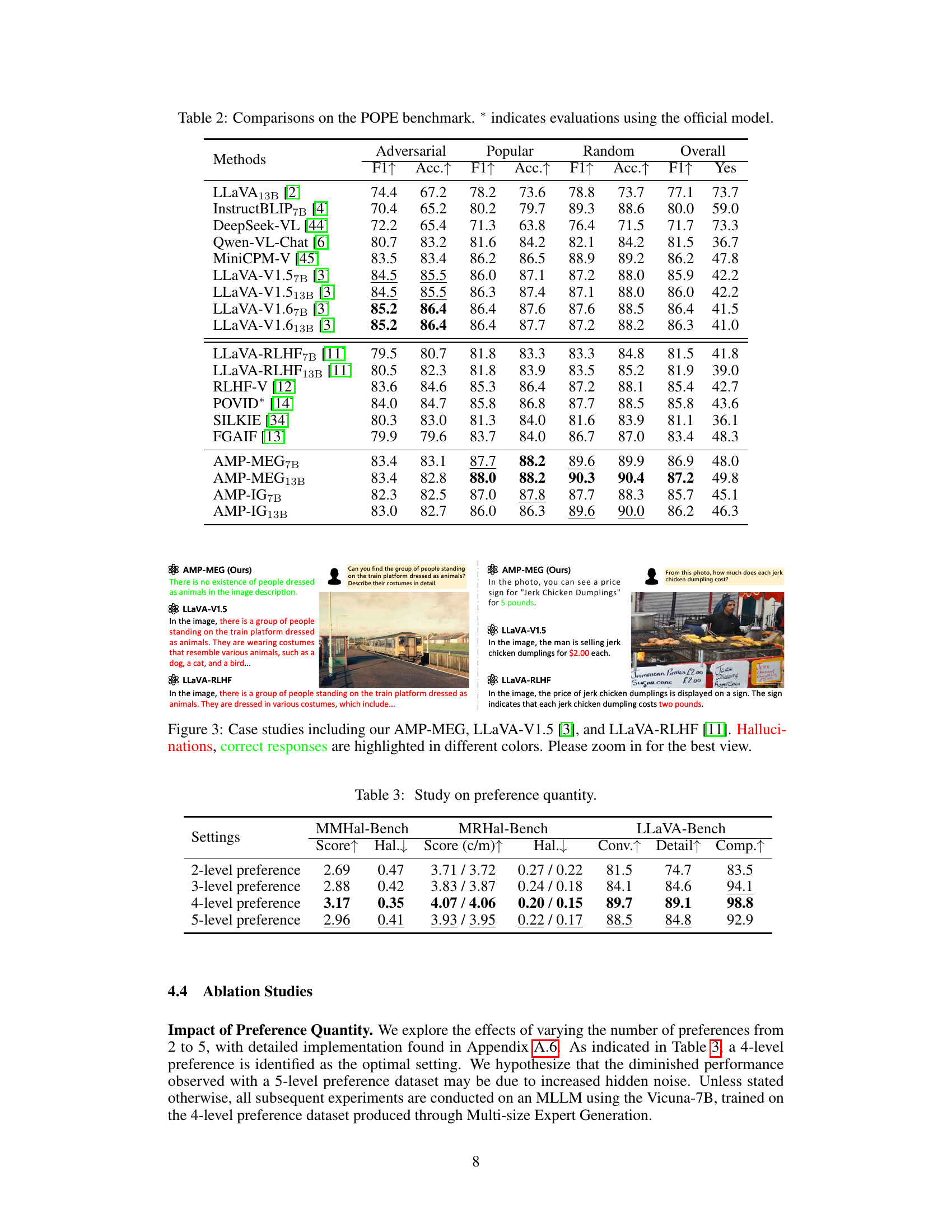
This table presents the results of an ablation study investigating the impact of varying the number of preference levels (2, 3, 4, and 5) on the performance of the model. The metrics used for evaluation are MMHal-Bench (Score, Hallucination rate), MRHal-Bench (Score (cumulative/mean), Hallucination rate), and LLaVA-Bench (Conversation, Detail, Complex). The results show that the 4-level preference setting yields the best performance across all benchmarks.
This table compares the performance of various Multimodal Large Language Models (MLLMs) on three different benchmarks: MMHal-Bench, MRHal-Bench, and LLaVA-Bench. It shows the scores for each model on metrics such as hallucination rate, conversation quality, detail in descriptions, and complexity of questions answered. The table also differentiates between models trained using conventional methods and those trained with Reinforcement Learning from Human Feedback (RLHF), and further distinguishes training data generated using two different methods (MEG and IG).

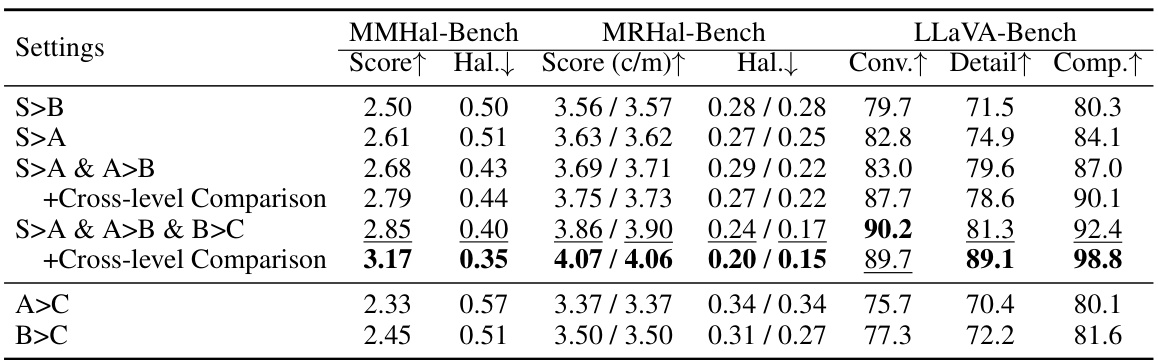
This table presents ablation studies on the human-free multi-level preference dataset. It compares the performance of the model trained with different types of annotations: AI annotations (GPT-4V), annotations refined by the Auto-check mechanism, and initial annotations generated by MEG and IG methods. The performance is evaluated across three benchmarks: MMHal-Bench, MRHal-Bench, and LLaVA-Bench, using metrics like Score, Hallucination rate, and others. This helps assess the impact of different annotation strategies on the final model’s performance.

This table compares the performance of various Multimodal Large Language Models (MLLMs) on three different benchmark datasets: MMHal-Bench, MRHal-Bench, and LLaVA-Bench. It contrasts conventional MLLMs with those fine-tuned using Reinforcement Learning from Human Feedback (RLHF). The table shows scores for hallucination rate, conversation quality, detailed description, and complex question answering. It also breaks down the results based on whether the training data was generated using the Multi-size Expert Generation (MEG) or Incremental Generation (IG) method.
Full paper#