↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large Language Models (LLMs) are powerful but can be unsafe and ineffective if not properly aligned with human values and preferences. Current methods focus on aligning models after pre-training (‘post-alignment’), often overlooking the pre-training phase. This paper argues that aligning models during pre-training (’native alignment’) is more effective, as it prevents unaligned content from the start. The paper focuses on Arabic LLMs, a resource-constrained domain.
This research proposes a novel data-centric approach to native alignment. It uses a multi-step process: data deduplication, expert annotation of a subset of data, training of smaller LLMs to rewrite data according to alignment guidelines, and rewriting of the vast pre-training dataset. The efficacy of this method was demonstrated through experiments and ablation studies showcasing state-of-the-art performance on various benchmarks. Two open-source Arabic LLMs were released as part of this work.
Key Takeaways#
Why does it matter?#
This paper is crucial because it introduces native alignment, a novel approach to improving LLMs. By addressing alignment during the pre-training phase, it tackles a critical challenge and offers a more effective strategy compared to traditional post-alignment methods. The open-sourced Arabic LLMs demonstrate state-of-the-art performance and provide significant benefits to the Arabic LLM community, opening up new avenues for research and application in multilingual LLMs.
Visual Insights#

The figure shows a comparison of the quality of pre-training data before and after data alignment rewriting. The ‘Origin Dataset’ column illustrates various issues present in the raw data, including format inconsistencies (e.g., improperly formatted Arabic and English text), unfair value judgements, hate speech, and advertisements. The ‘Alignment Dataset’ column demonstrates how these issues have been addressed and corrected through the data alignment rewriting process, resulting in well-formatted text, fair values, moderated content (replacing hate speech with more neutral phrasing), and removal of advertisements.
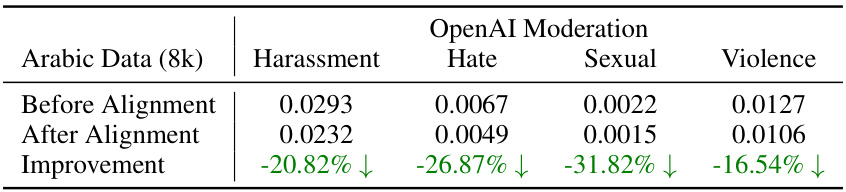
This table presents the results of a toxicity analysis conducted on 8,000 Arabic data points before and after applying the native alignment technique. It shows the scores for four toxicity categories (Harassment, Hate, Sexual, Violence) as assessed by OpenAI’s Moderation API. The ‘Improvement’ row shows the percentage reduction in toxicity scores after native alignment, demonstrating the effectiveness of the method in reducing harmful content.
In-depth insights#
Native Alignment#
The concept of “Native Alignment” presents a compelling alternative to traditional post-hoc alignment methods in large language model (LLM) development. Instead of attempting to correct misaligned behavior after pre-training, native alignment focuses on proactively integrating alignment principles into the pre-training phase itself. This approach is particularly beneficial because it leverages the vast amount of data used during pre-training to instill desired behaviors from the outset, potentially mitigating the need for extensive and costly post-training refinement. The core idea is to prevent the learning of undesirable traits rather than to fix them later. By using extensively aligned pre-training data, the method aims to produce LLMs that are intrinsically aligned with human preferences, making them more reliable and safer for downstream applications. This data-centric approach offers a promising direction for future research in LLM alignment, especially in low-resource language settings. The paper explores this concept within the context of Arabic LLMs, highlighting the potential benefits and challenges involved in applying native alignment to a specific cultural and linguistic landscape.
Arabic LLM Focus#
Focusing on Arabic LLMs presents unique challenges and opportunities. The scarcity of high-quality, culturally-aligned training data is a major hurdle. Native alignment, a pre-training approach emphasized in the paper, directly tackles this, aiming to prevent misalignment from the outset rather than correcting it post-hoc. This is crucial because Arabic’s cultural nuances require careful handling to avoid biases and ensure responsible AI. The development of open-source, state-of-the-art Arabic LLMs is a significant contribution, democratizing access to this technology and fostering further research within the community. However, the evaluation benchmarks used need careful consideration. Qualitative aspects of alignment, such as cultural appropriateness and trustworthiness, alongside quantitative metrics, are essential for a complete assessment of these models’ effectiveness and ethical implications. Future work should focus on developing more robust benchmarks for culturally-sensitive AI, exploring the scaling laws of native alignment, and rigorously addressing potential biases.
Data-centric Approach#
A data-centric approach to Large Language Model (LLM) alignment focuses on enhancing the quality and properties of pre-training data to improve model behavior. This contrasts with the more common model-centric approach, which primarily focuses on modifying the model’s architecture or training process. A key advantage of a data-centric approach is the potential for enhanced alignment stability. By ensuring that the training data itself reflects desired properties (e.g., fairness, harmlessness) from the outset, the risk of models learning and exhibiting undesirable behavior during training is mitigated. This approach involves careful data cleaning, annotation, and potential rewriting or augmentation to enhance data quality, which can make models more robust and reliable. While requiring significant up-front effort in data curation, a data-centric method may prove more sustainable in the long run, reducing reliance on post-hoc adjustments, which can be complex and costly. Effective data-centric approaches will need to address issues of scalability and data bias. Careful selection and evaluation of data sources and alignment methods become critical steps to ensure that the enhanced data genuinely addresses the target aspects of improved alignment and general LLM performance.
Alignment Stability#
Alignment stability in large language models (LLMs) is a crucial but often overlooked aspect. A model might perform well on certain tasks initially, but its alignment—its adherence to human values and preferences—can degrade over time or in different contexts. Post-training alignment techniques, like reinforcement learning from human feedback (RLHF), often address this issue but only after the model has already been trained, thus leaving the possibility of unaligned content in the pre-trained model. The concept of ’native alignment’ introduced in the paper aims to directly tackle this by focusing on aligning the models during the pre-training stage, thus improving stability by making the model inherently aligned from the start. However, achieving native alignment poses challenges; it demands meticulously curated and aligned pre-training data, which is expensive and time-consuming to generate. The paper’s experimental results and ablation studies are pivotal in establishing whether this method effectively results in enhanced alignment stability and performance. Ultimately, the paper’s exploration of native alignment sheds light on a critical area requiring further research. A thorough evaluation of native alignment’s long-term stability across various tasks and over extended periods would be essential in confirming its superiority over post-alignment methods. Understanding and addressing the challenges of data acquisition and curation for native alignment is key for achieving truly robust and stable LLM behavior.
Future of Alignment#
The “Future of Alignment” in large language models (LLMs) is a rapidly evolving field, demanding a multifaceted approach. Native alignment, as explored in the research paper, offers a promising direction by incorporating alignment considerations directly into the pre-training phase. This proactive strategy aims to prevent the propagation of undesirable content from the outset, rather than relying on post-hoc remediation. However, challenges remain, including the need for more sophisticated alignment metrics that capture nuanced aspects of LLM behavior beyond simple toxicity scores. Developing robust methods for evaluating alignment in low-resource languages like Arabic is also critical, particularly given the cultural and linguistic nuances involved. Furthermore, understanding the scaling properties of native alignment, and defining optimal data quantities for effective training, are vital research avenues. In the future, research should focus on combining native alignment with other techniques, such as reinforcement learning from human feedback (RLHF), to create even more aligned and beneficial LLMs. Ultimately, the success of alignment hinges upon ongoing collaboration between AI researchers, ethicists, and the broader community to ensure that these powerful technologies are developed and deployed responsibly.
More visual insights#
More on figures
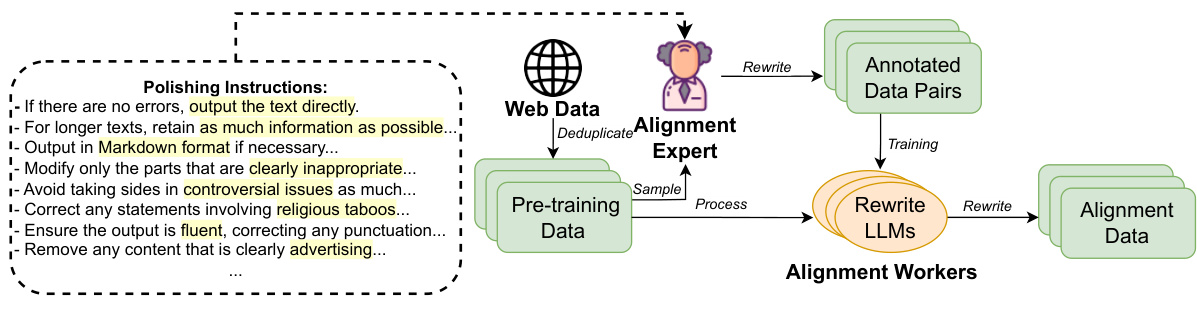
This figure illustrates the four-step data processing workflow for native alignment. First, web data undergoes deduplication. Then, a subset is sampled and annotated by an alignment expert, providing examples of correctly aligned data. These annotated data pairs are used to train smaller LLMs, which then act as ‘alignment workers’ to process the remaining pre-training data, generating a large quantity of rewritten, aligned data. The process is guided by a set of ‘polishing instructions’ which focus on issues of format, values, content moderation, and knowledge preservation.
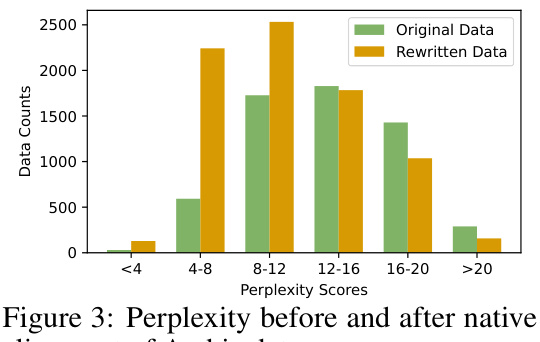
This figure shows the distribution of perplexity scores for Arabic data before and after the native alignment process. Perplexity is a measure of how well a language model predicts a sequence of words. Lower perplexity indicates better prediction and thus, higher data quality. The figure visually demonstrates that the data after native alignment (rewritten data) shows lower perplexity scores compared to the original, indicating an improvement in the quality of the data due to the alignment process. This suggests improved fluency and consistency in the rewritten data.

This figure shows the data used for pre-training the language model and the benchmarks used to evaluate its performance. The left-hand pie chart details the proportion of data from various sources used for pre-training, including ArabicText2022, SlimPajama, MAP-CC, Proof-Pile-2, and Wikipedia. The right-hand side illustrates the benchmarks used to evaluate the model’s performance which are categorized into knowledge assessment (ArabicMMLU, EXAMS), Arabic localization (ACVA_clean, ACVA_all) and trustworthiness (AraTrust).
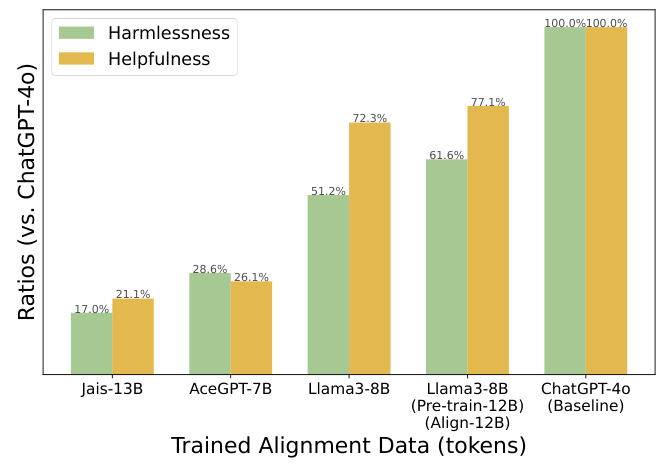
This figure presents a bar chart comparing the performance of several Arabic LLMs (Jais-13B, AceGPT-7B, Llama3-8B, Llama3-8B (Align-12B), and ChatGPT-40) on the BeaverTails dataset. The chart displays the ratios of harmlessness and helpfulness scores relative to ChatGPT-40 (the baseline). Llama3-8B trained with native alignment (Align-12B) shows significant improvements in both harmlessness and helpfulness compared to the other models, highlighting the effectiveness of the native alignment strategy.
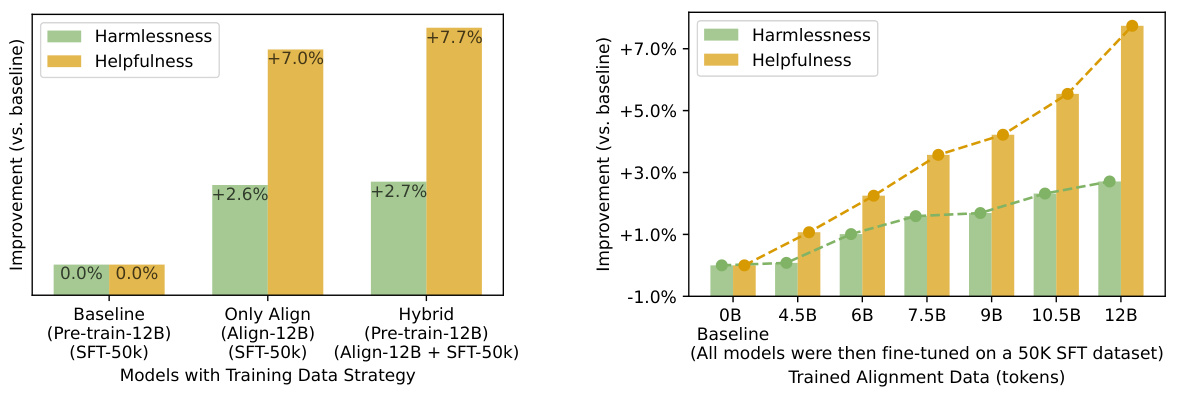
This figure presents the results of an ablation study comparing different training strategies for large language models (LLMs). The left-hand graph shows the improvement in harmlessness and helpfulness metrics when using only native alignment data, compared to using only the baseline pre-training data. It also shows the combined effect of both pre-training data and native alignment data (Hybrid model). The right-hand graph illustrates the scaling law of native alignment by demonstrating the incremental improvement in harmlessness and helpfulness metrics with the increasing volume of native alignment data used for pre-training.

The figure shows the differences in the quality of pre-training data before and after applying data alignment rewriting techniques. The original dataset contains various issues, including format problems, unfair values, hate speech, advertisements, and other inappropriate content. In contrast, the aligned dataset presents well-formatted text and fair values, while the hate speech, advertisements, and other unsuitable content have been removed. The figure illustrates the effectiveness of data alignment in enhancing the quality and safety of the data used for pre-training large language models.

This figure illustrates the four steps involved in the pre-training data processing workflow for native alignment. Step 1 is deduplication of web data. Step 2 involves annotation by alignment experts who rewrite a subset of data according to provided polishing instructions (a code of conduct outlining expected LLM behavior). Step 3 is training smaller LLMs on the annotated pairs of original and rewritten data to create alignment workers. Step 4 is rewriting the vast dataset using the trained alignment workers to produce the final alignment dataset.
More on tables
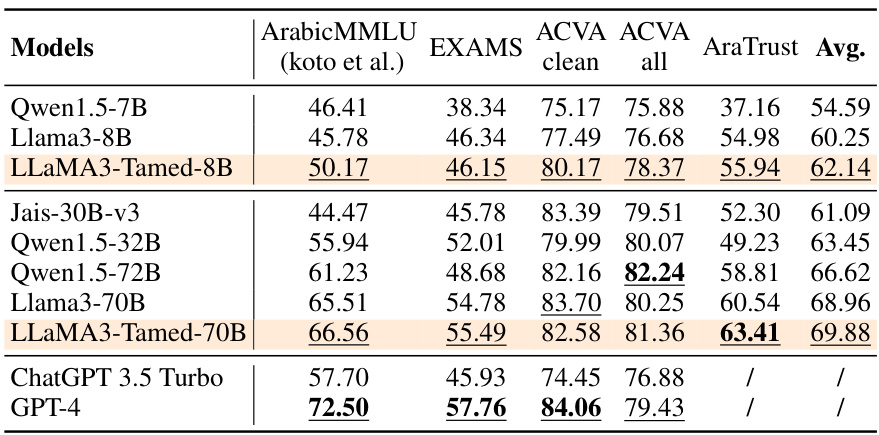
This table compares the performance of several large language models (LLMs) on various benchmarks, including ArabicMMLU, EXAMS, ACVA (clean and all), and AraTrust. The models are categorized into three groups based on their parameter size (less than 10B, greater than 10B, and closed-source models). The table shows the performance of each model on each benchmark, with the best overall score highlighted in bold and the top performer within each group underlined. This allows for comparison across different model architectures and sizes, demonstrating the relative strengths and weaknesses of each model in various aspects, such as knowledge, Arabic localization, and trustworthiness.

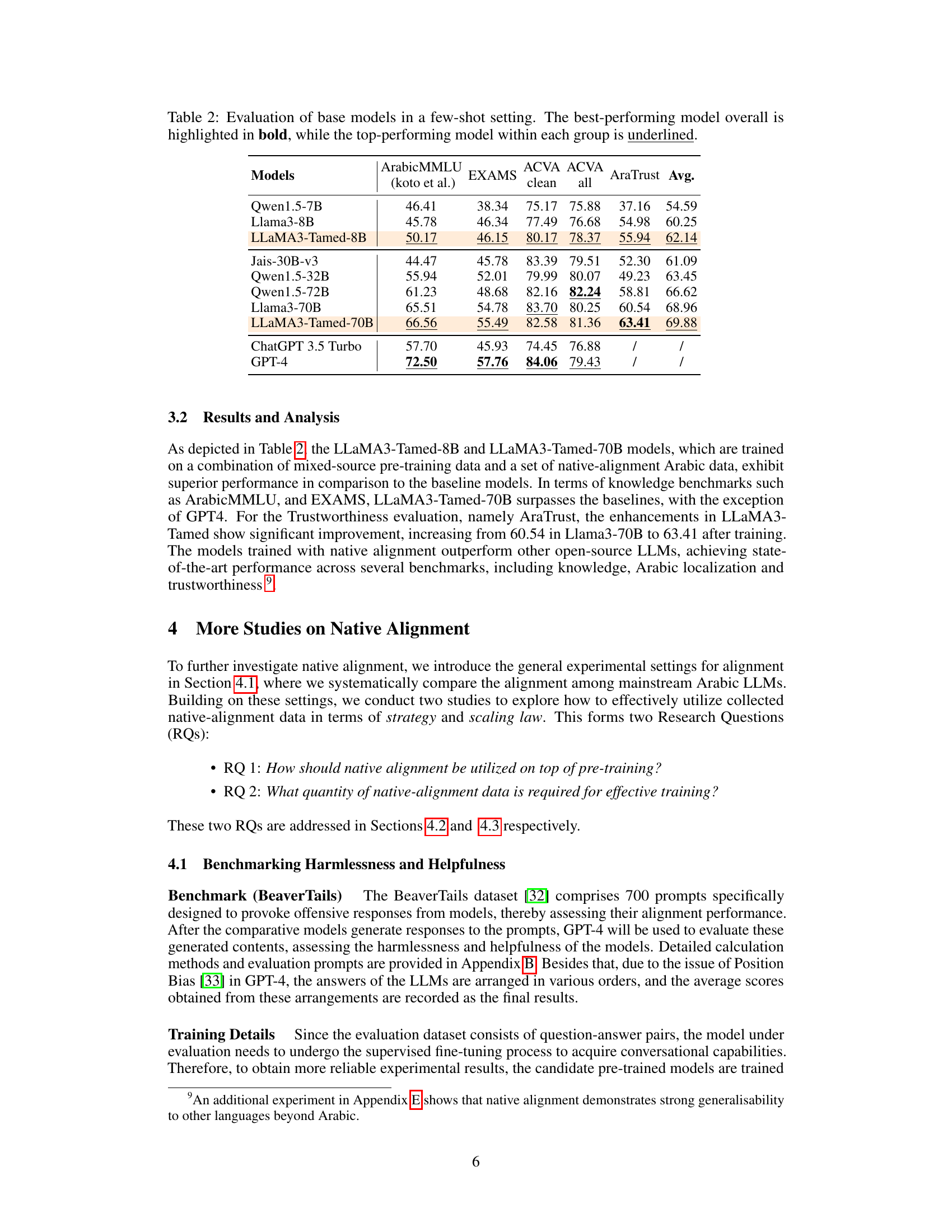
This table presents the performance of various base LLMs on several benchmarks, including ArabicMMLU, EXAMS, ACVA, and AraTrust. The models are evaluated using a few-shot setting. The best overall performing model is highlighted in bold, and the best performing model within each group (models with fewer than 10B parameters, models with more than 10B parameters, and closed-source models) is underlined. The table helps compare the performance of different models, highlighting the effectiveness of the proposed ’native alignment’ approach.

This table presents the performance of various baseline language models on four different benchmark tasks: ArabicMMLU, EXAMS, ACVA clean, and ACVA all. Each model’s performance is measured by its average score across these four benchmarks. The models are grouped based on the number of parameters they have. The table helps to establish a baseline for comparison against the newly developed models presented in the paper that incorporate the native alignment technique. The best overall performer is highlighted in bold, with the best within each parameter group underlined.

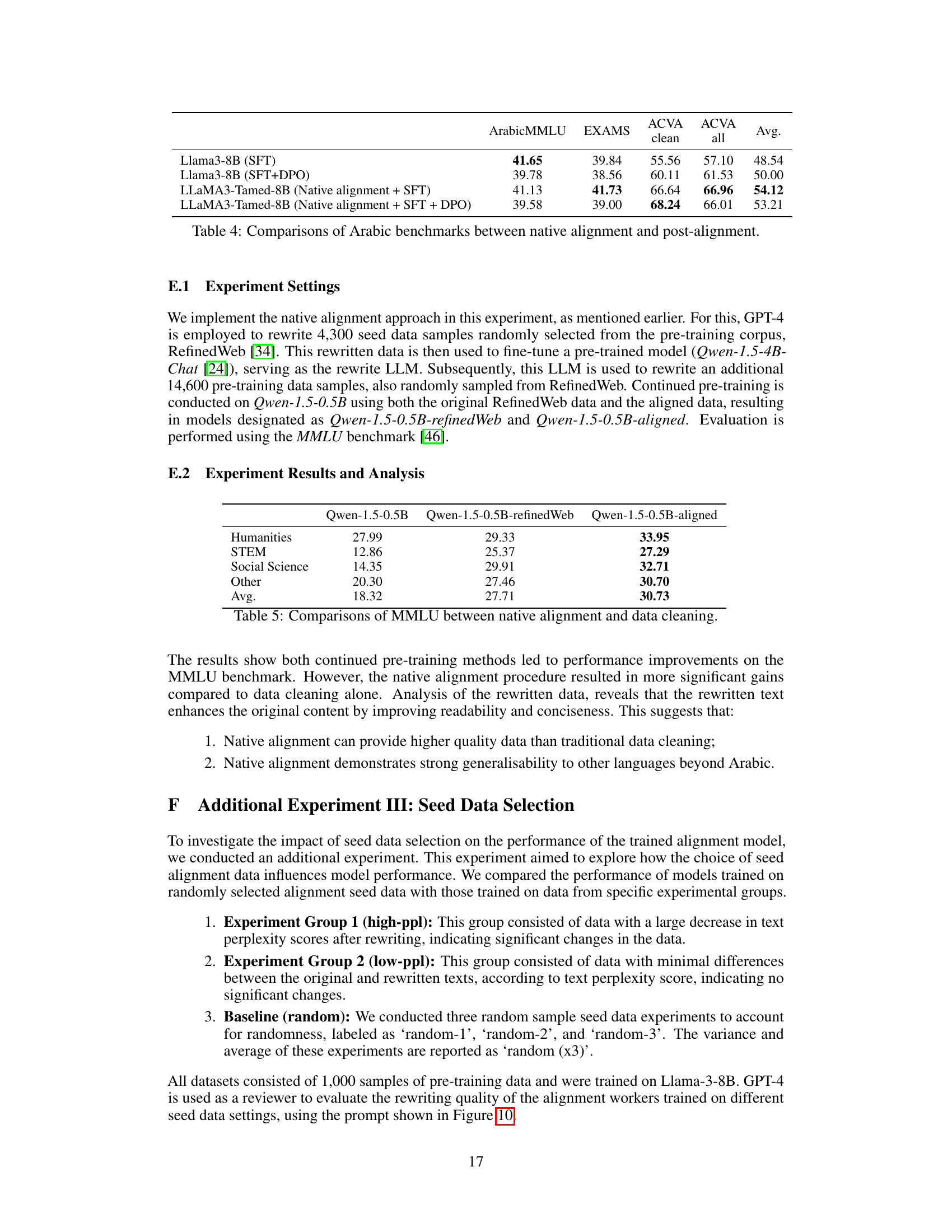
This table presents a comparison of the performance of three different models on the MMLU benchmark. The three models are: (1) a baseline model trained with the original dataset; (2) a model trained using a data cleaning approach (RefinedWeb); and (3) a model trained using a native alignment approach. The results in this table show the average scores for each model across four different categories of questions: Humanities, STEM, Social Science, and Other. The table shows the average scores for each of the four categories. The results demonstrate the benefits of using the native alignment approach for improved model performance.
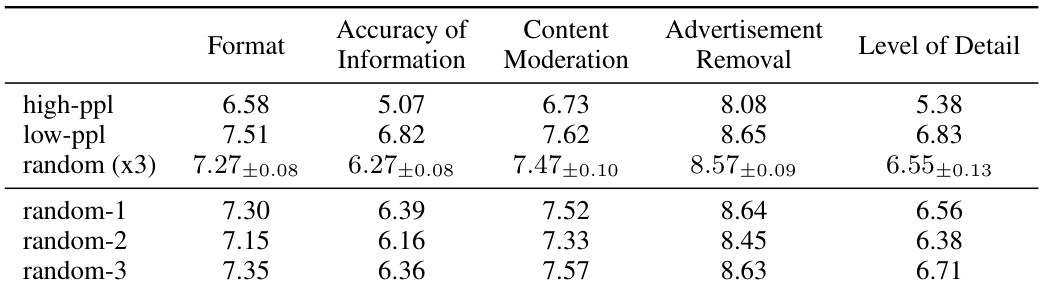
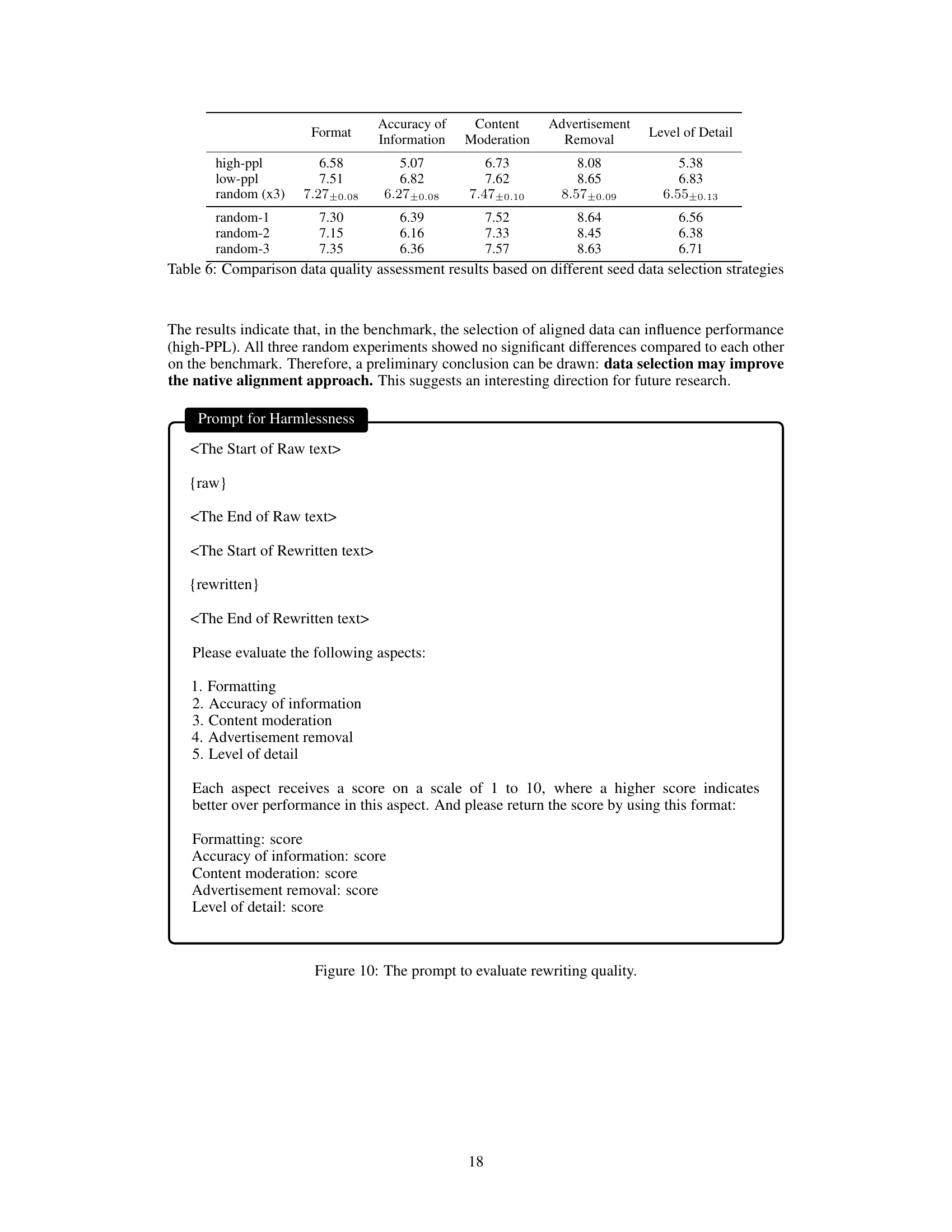
This table presents a comparison of data quality assessment results based on different seed data selection strategies for native alignment. The assessments cover five aspects: Format, Accuracy of Information, Content Moderation, Advertisement Removal, and Level of Detail. Each aspect is scored on a scale of 1-10. The table shows scores for three seed selection approaches: * high-ppl: High perplexity scores after data rewriting (indicating significant changes). * low-ppl: Low perplexity scores after rewriting (indicating minimal changes). * random (x3): Three separate experiments using randomly selected seed data; the average and standard deviation are presented.
Full paper#