↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Current methods for optimizing prompts in vision-language models often lead to overfitting and produce unintelligible prompts. This paper tackles this issue by proposing Interpretable Prompt Optimization (IPO), which employs large language models (LLMs) to generate more effective and human-understandable prompts. IPO also leverages a large multimodal model to condition on visual content, thereby improving the interaction between text and visual modalities.
IPO demonstrates improved accuracy on 11 benchmark datasets, surpassing existing gradient-descent-based methods, while maintaining human-interpretability. The use of LLMs allows for dynamic prompt generation and refinement, making it a more versatile and user-friendly approach. Furthermore, IPO reduces overfitting on base classes, enhancing its generalizability to new tasks and datasets.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on vision-language models because it introduces a novel, interpretable prompt optimization technique that addresses the limitations of current gradient-descent methods. It offers improved accuracy, increased interpretability, and reduced overfitting, opening new avenues for research in prompt engineering and enhancing the transparency and user-friendliness of vision-language models. This work is highly relevant to the current trend of leveraging large language models in AI optimization and offers valuable insights into the role of LLMs in enhancing the usability and explainability of complex AI systems.
Visual Insights#
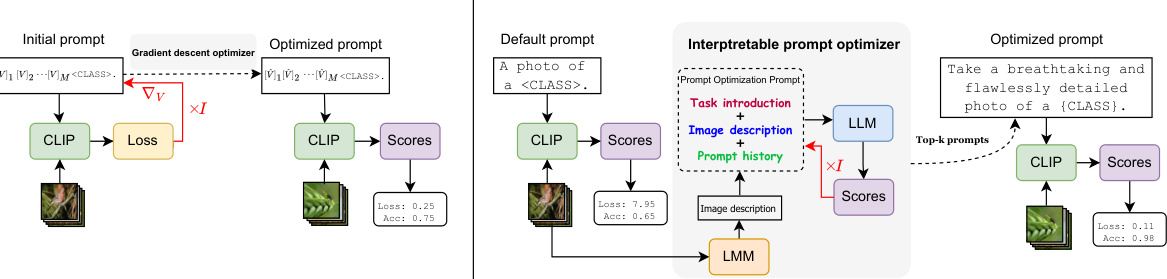
This figure compares two prompt optimization methods for vision-language models. The left panel illustrates gradient-based optimization, where the prompt is treated as a parameter and optimized using gradient descent. This often leads to prompts that are hard to interpret by humans. The right panel shows the proposed interpretable prompt optimizer, which uses large language models (LLMs) to dynamically generate human-readable and effective prompts, improving model performance and interpretability. The key difference is that gradient-based methods overfit easily on base class, while the LLMs approach does not.
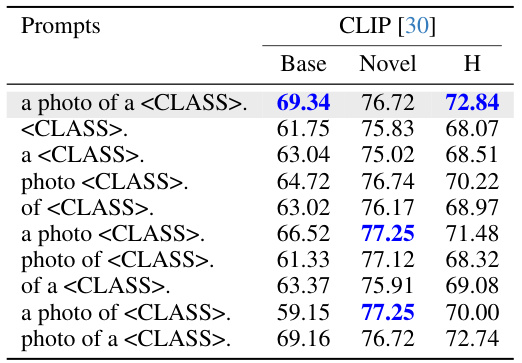
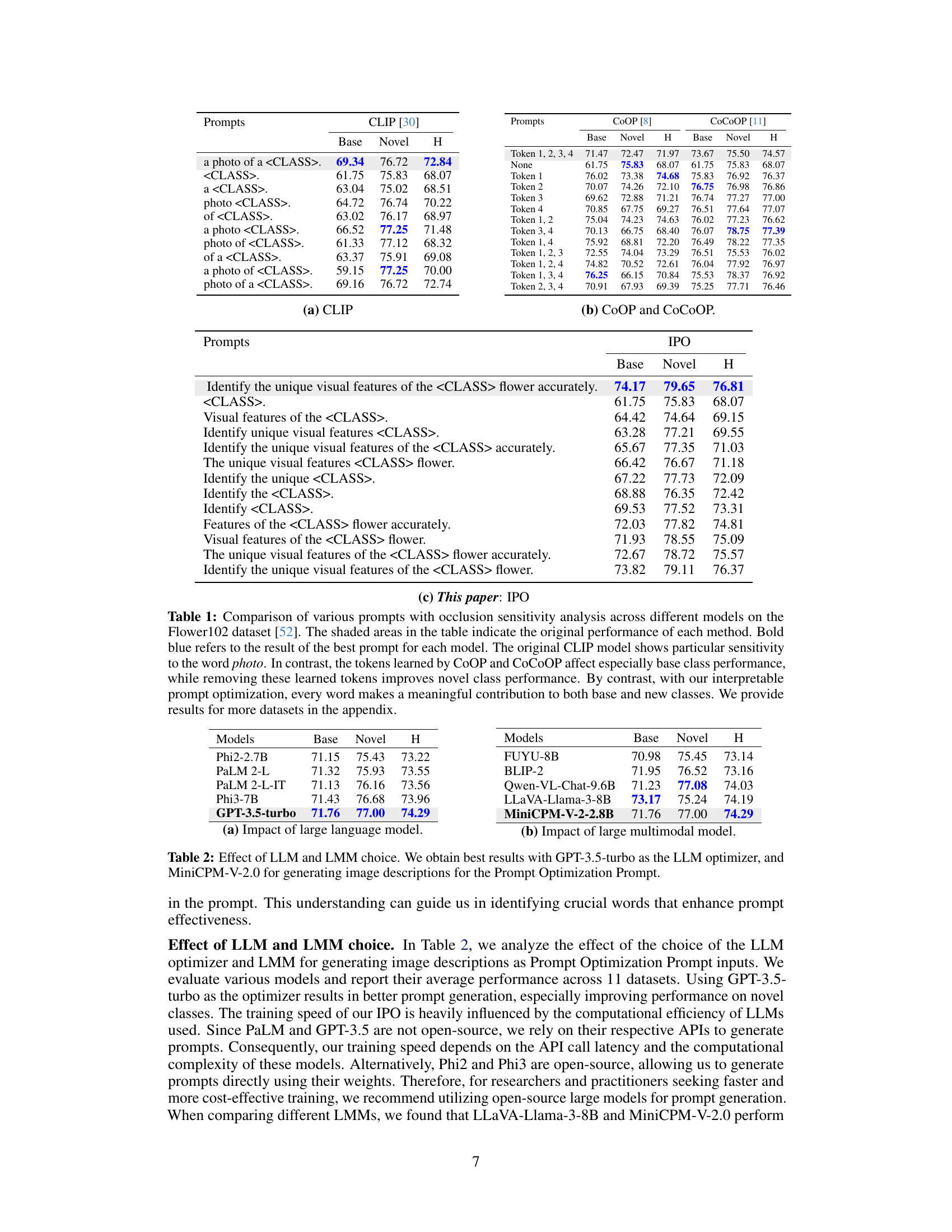
This table compares the performance of different prompt engineering methods (CLIP, CoOP, CoCoOP, and IPO) on the Flower102 dataset. It uses occlusion sensitivity analysis to determine the importance of individual words or phrases within the prompts by removing them one by one and measuring the impact on classification accuracy. The results highlight differences in the prompts learned by gradient descent methods (CoOP, CoCoOP) compared to the human-interpretable prompts generated by IPO, demonstrating the advantages of IPO’s approach.
In-depth insights#
IPO:Prompt Optimizer#
The proposed IPO:Prompt Optimizer presents a novel approach to enhance vision-language models by leveraging the capabilities of large language models (LLMs). Instead of traditional gradient-descent methods which often result in unintelligible prompts, IPO dynamically generates and refines prompts using an LLM conditioned on both textual instructions and visual content. This is achieved through a carefully designed Prompt Optimization Prompt that provides rich in-context information, including past prompts and their performance. The incorporation of a large multimodal model (LMM) further enhances the optimization process by generating image descriptions, enabling a more nuanced interaction between visual and textual modalities. IPO’s strength lies in its interpretability, generating human-understandable prompts that improve transparency and facilitate better model oversight. Extensive testing across multiple datasets demonstrates that IPO not only outperforms traditional methods in accuracy but also significantly enhances the interpretability of generated prompts, addressing a critical limitation of previous prompt optimization techniques. The resulting prompts are dataset-specific, improving generalization and reducing overfitting, marking a significant advancement in vision-language prompt engineering.
LLM-based Optimization#
LLM-based optimization represents a paradigm shift in prompt engineering for vision-language models. Instead of relying on gradient descent methods which often yield opaque and overfit prompts, this approach leverages the power of large language models (LLMs) to generate and refine prompts iteratively. The interpretability of the generated prompts is a key advantage, facilitating human understanding and oversight. By dynamically generating prompts based on visual content and past performance data, LLMs enhance generalization and reduce overfitting. This method involves prompting the LLM with a description of the task, past prompts and their performance metrics, and visual features from the images, thereby providing context for more effective prompt generation. The use of an episodic memory mechanism further enhances the LLM’s capability to learn and refine prompt suggestions. The simplicity and effectiveness of LLM-based optimization, together with its improved interpretability, presents a promising direction for improving the transparency and efficiency of prompt engineering in vision-language models.
Interpretable Prompts#
Interpretable prompts represent a significant advancement in vision-language models. Traditional prompt optimization often produces prompts that, while effective, lack human understandability, hindering transparency and trust. The core idea is to leverage large language models (LLMs) to generate prompts dynamically. This approach allows for the creation of prompts that are both effective and understandable, facilitating better human oversight. Furthermore, incorporating image descriptions generated by large multimodal models (LMMs) improves the interaction between visual and textual data. This leads to dataset-specific prompts enhancing generalization. The key innovation is the use of a ‘Prompt Optimization Prompt,’ which acts as a guide for the LLM, also storing a history of previous prompts and their performance, enhancing iterative refinement. The resulting interpretable prompts improve the accuracy of the model and are easier for humans to interpret, fostering greater transparency and control over the model’s behavior. Overall, this approach bridges the gap between performance and human comprehension, enhancing the explainability and reliability of vision-language models.
Cross-dataset Results#
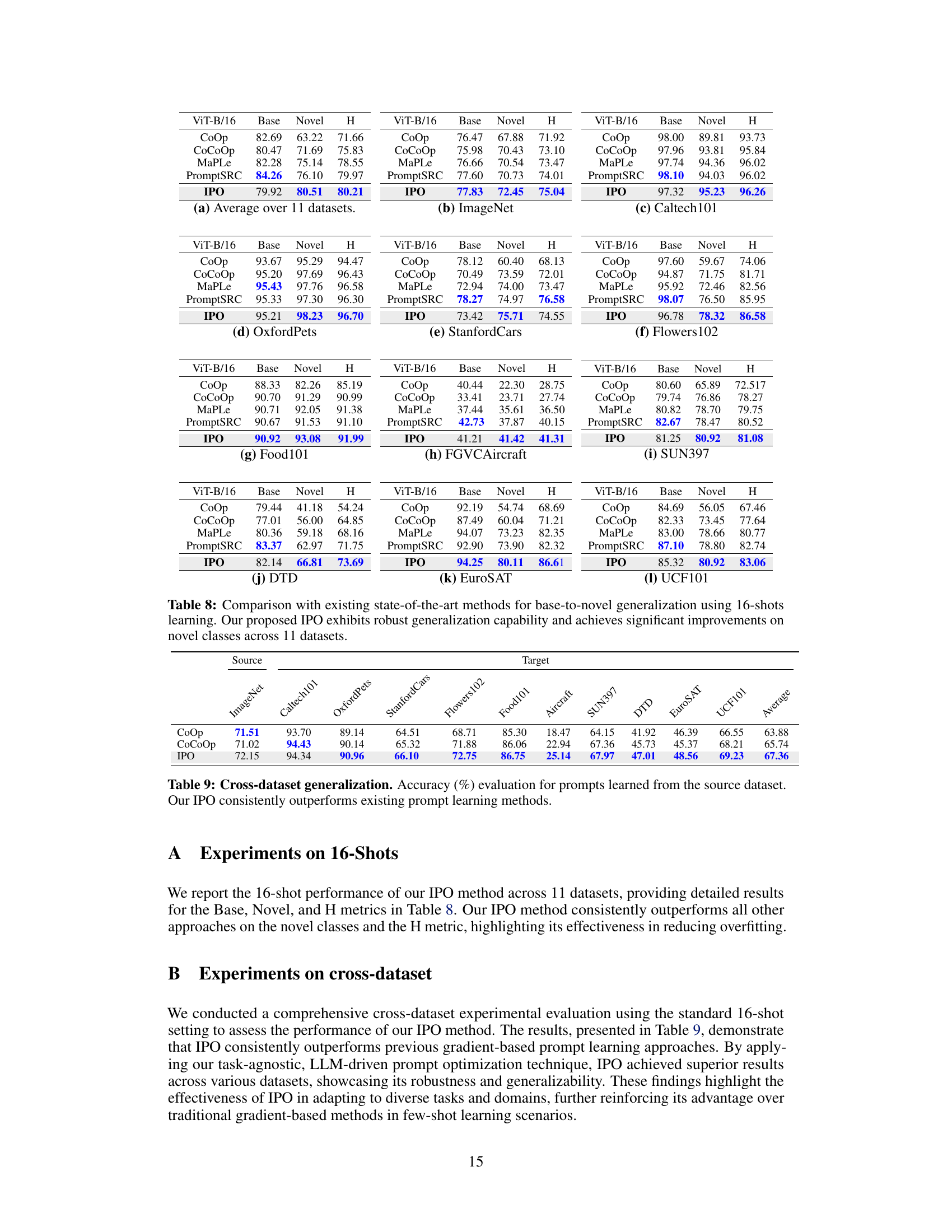
Cross-dataset generalization experiments are crucial for evaluating the robustness and adaptability of prompt learning methods. A successful approach should demonstrate consistent performance improvements across diverse datasets, indicating its ability to generalize beyond the training data. Analyzing the results requires a careful examination of both average performance metrics (harmonic mean) and individual dataset results. Significant discrepancies between datasets could point to limitations in the method’s ability to handle variations in data characteristics or task complexity. It is vital to identify which datasets exhibit higher or lower-than-average performance, as this can shed light on the method’s strengths and weaknesses. Overfitting to specific datasets should be avoided and the ability of the approach to achieve strong performance on unseen datasets, even with limited training data, is important. A detailed discussion should include a comparison with traditional methods to demonstrate the superiority of the proposed approach for transfer learning. The analysis should be comprehensive, addressing strengths and limitations of the approach to contribute new insights for developing robust and generalized prompt optimization strategies.
Future Research#
Future research directions stemming from this paper could explore several promising avenues. Extending IPO to more complex vision-language tasks beyond image classification, such as object detection, image captioning, and visual question answering, would be a significant contribution. Investigating the impact of different LLMs and their inherent biases on prompt generation and the resulting model performance is crucial. A deeper dive into understanding the interplay between visual and textual information within the IPO framework is also warranted. Finally, developing methods to reduce the computational cost associated with generating large numbers of prompts and leveraging multimodal models would make the approach more scalable and efficient for application in real-world scenarios. Further analysis on the robustness of IPO to noisy data and adversarial examples could offer important insights for improving its reliability. Additionally, a thorough investigation into the generalizability of prompts generated by IPO across various domains and datasets is necessary for broad applicability.
More visual insights#
More on figures

This figure compares two prompt optimization approaches for vision-language models. (a) shows the traditional gradient-descent method, where prompts are treated as parameters and optimized via gradient descent. This often results in prompts that are hard for humans to understand. (b) shows the authors’ proposed interpretable prompt optimization (IPO) method, which uses a Large Language Model (LLM) to generate human-readable prompts that improve accuracy. The IPO method incorporates a prompt history and image descriptions to improve prompt quality and dataset-specific performance.

The figure compares two prompt optimization methods for vision-language models: gradient-based and interpretable. The gradient-based method treats prompts as parameters and optimizes them using gradient descent, often leading to overfitting and incomprehensible prompts. In contrast, the interpretable method uses a large language model (LLM) to generate human-understandable prompts, leveraging past performance data and multimodal interaction for improved accuracy and interpretability.

This figure compares two prompt optimization methods for vision-language models: gradient-based and interpretable prompt optimization. The gradient-based method treats prompts as parameters and optimizes them using gradient descent, leading to overfitted and uninterpretable prompts. In contrast, the interpretable method uses LLMs to dynamically generate human-understandable and effective prompts. The figure illustrates the processes and results of both methods, highlighting the advantages of using LLMs for prompt optimization.

This figure compares gradient-based prompt optimization and the proposed interpretable prompt optimization (IPO). (a) shows the traditional approach where prompts are treated as learnable parameters and optimized via gradient descent, leading to overfitting and non-interpretable prompts. (b) illustrates the IPO method, which utilizes a large language model (LLM) and a large multimodal model (LMM) to dynamically generate human-interpretable prompts. The IPO method incorporates a Prompt Optimization Prompt that guides the LLM and uses episodic memory to improve performance and interpretability.

This figure compares gradient-based and interpretable prompt optimization methods for vision-language models. The gradient-based method treats prompts as parameters and optimizes them using gradient descent, often resulting in uninterpretable prompts. In contrast, the interpretable method uses a large language model (LLM) to generate and refine prompts iteratively, leading to human-understandable and effective prompts. The figure illustrates the process of each method, highlighting the differences in prompt generation and evaluation.
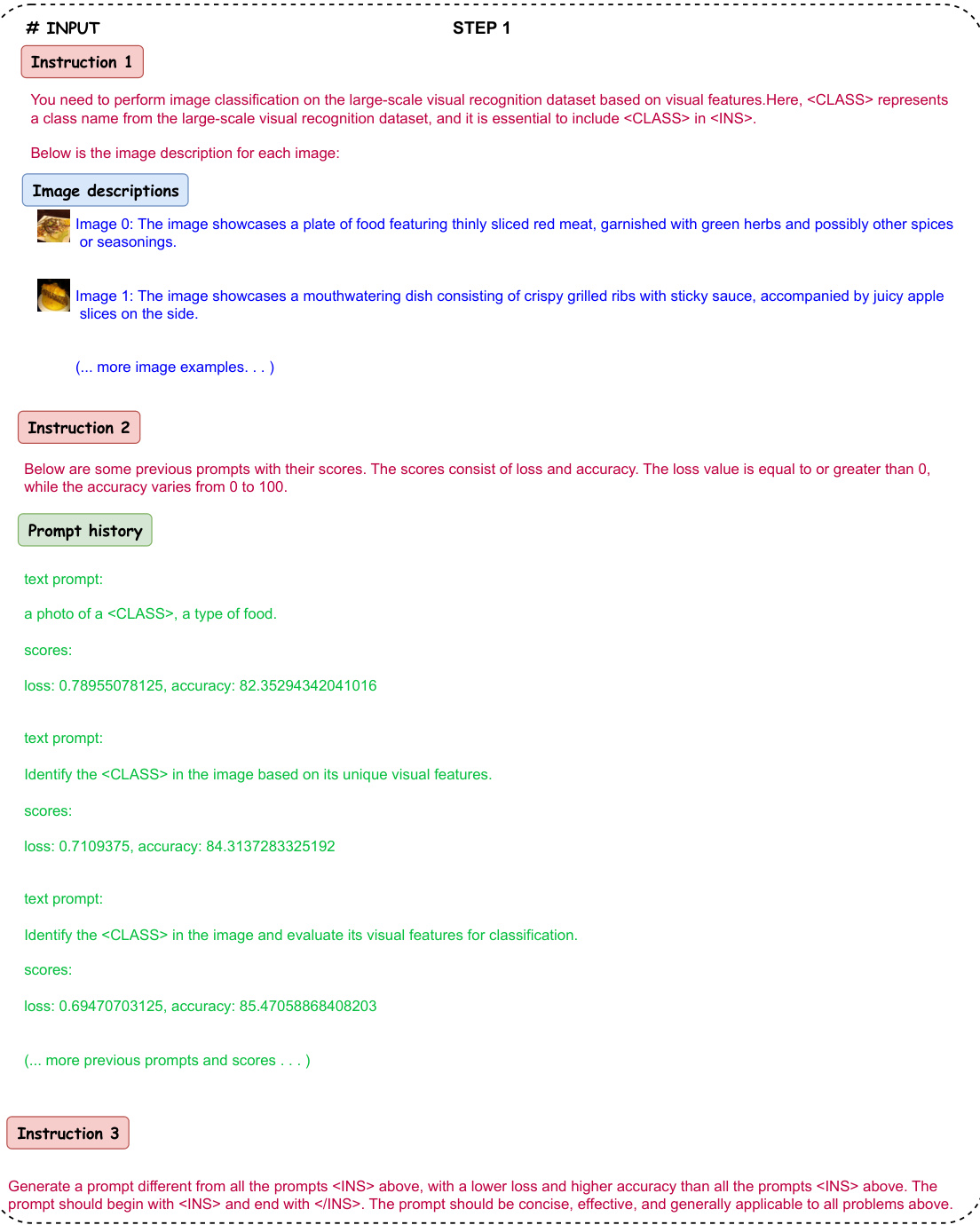
This figure compares two prompt optimization methods: gradient-based and interpretable. Gradient-based methods treat prompts as parameters, optimizing them via gradient descent. This often leads to overfitting and non-human-interpretable prompts. In contrast, the proposed interpretable method uses a large language model (LLM) to dynamically generate and refine prompts, resulting in human-understandable and effective prompts.
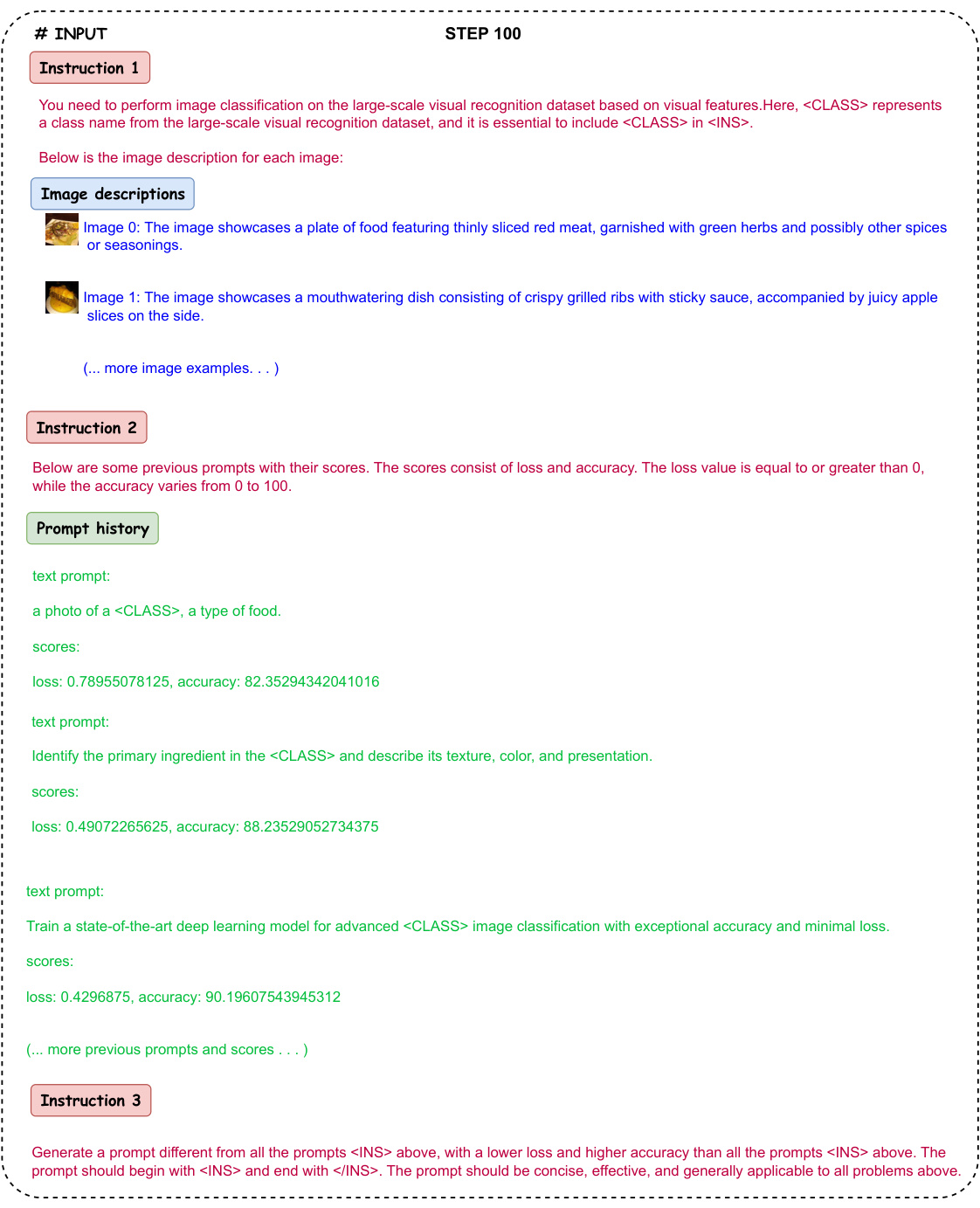
The figure compares traditional gradient-based prompt optimization with the proposed interpretable prompt optimization method. Gradient-based methods treat prompts as parameters, leading to uninterpretable results. In contrast, the proposed method uses LLMs to generate human-readable and effective prompts.

This figure compares two different prompt optimization methods for vision-language models. The traditional gradient-based method treats prompts as parameters and optimizes them using gradient descent. This often leads to uninterpretable prompts. The proposed interpretable method uses a large language model (LLM) to generate and refine prompts dynamically, resulting in prompts that are both effective and human-understandable.
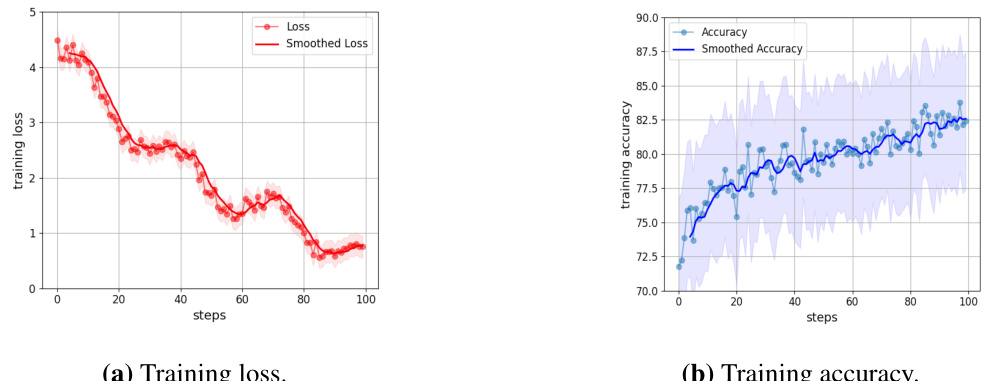
The figure compares two approaches to prompt optimization for vision-language models: gradient-based and interpretable. Gradient-based methods treat prompts as parameters, leading to overfitting and uninterpretable prompts. The interpretable approach uses LLMs to dynamically generate human-understandable prompts, improving accuracy and interpretability. The figure illustrates the process of each method through diagrams.
More on tables
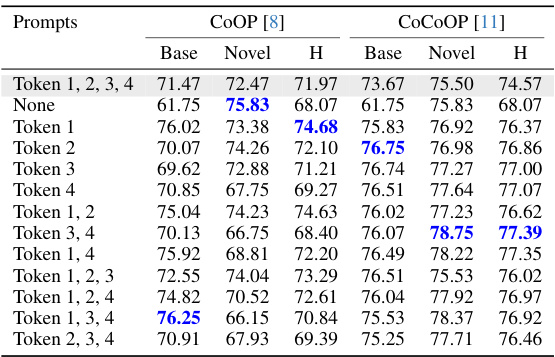
This table presents a comparison of different prompt engineering methods (CLIP, COOP, COCOOP, and IPO) on the Flower102 dataset, focusing on the impact of specific words on performance. Occlusion sensitivity analysis is performed, where words are progressively removed from prompts to assess their importance. The results highlight the differences in interpretability and generalization capabilities of different methods. The table shows the performance on base and novel classes, with IPO demonstrating better performance and interpretability.

This table compares the performance of different prompt optimization methods (CLIP, CoOP, CoCoOP, and IPO) on the Flower102 dataset. It shows the impact of using different prompts and removing individual words from the prompts on the accuracy of the models. The results highlight the strengths and weaknesses of different methods in terms of interpretability and overfitting, and the superior performance of the proposed method.
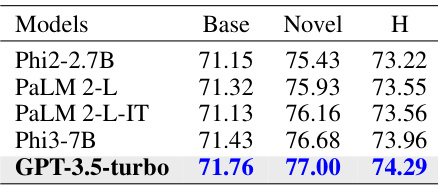
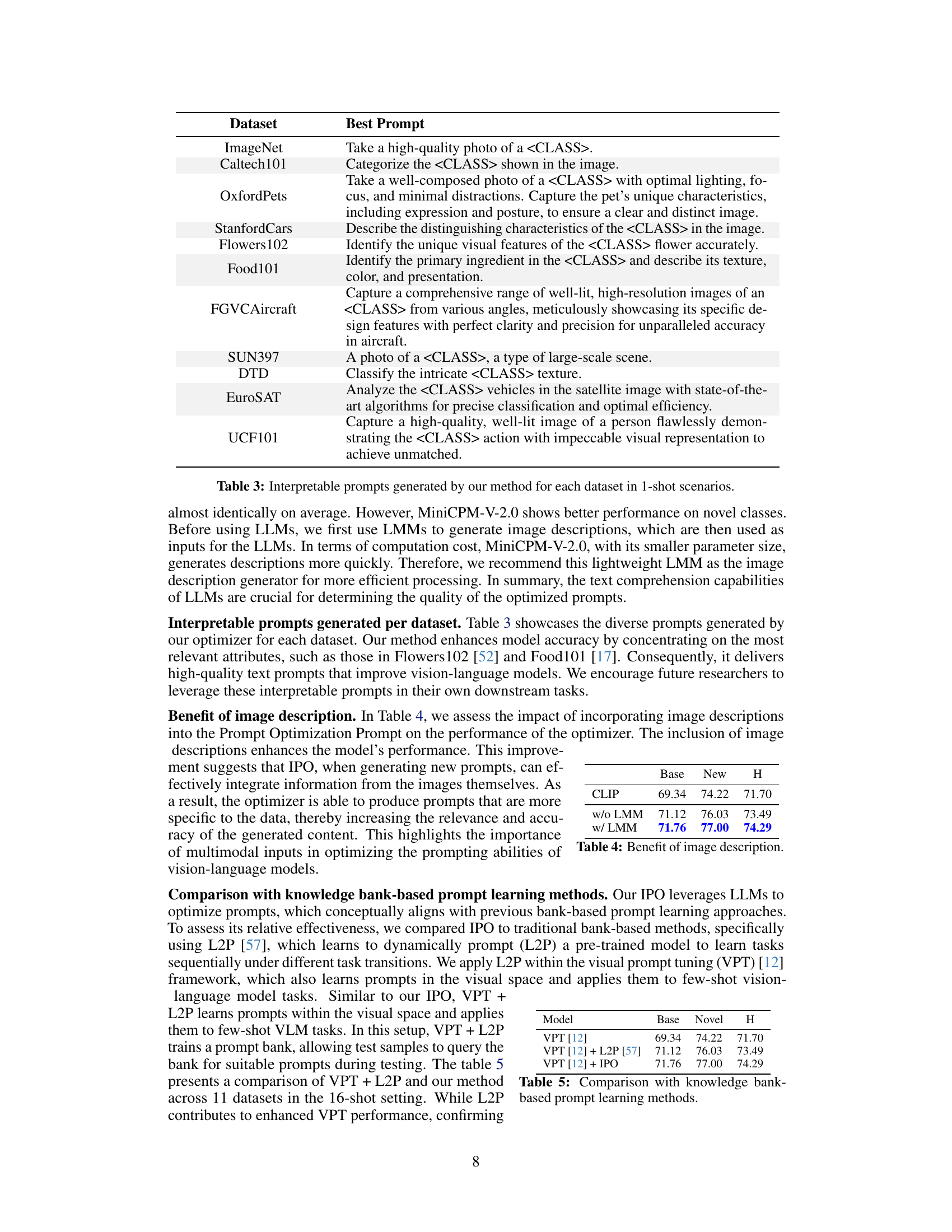
This table presents the results of experiments conducted to evaluate the impact of different Large Language Models (LLMs) and Large Multimodal Models (LMMs) on the performance of the proposed IPO method. The table shows that using GPT-3.5-turbo as the LLM optimizer and MiniCPM-V-2.0 for generating image descriptions yields the best performance. The results highlight the importance of the choice of LLM and LMM for achieving optimal results with the IPO method.
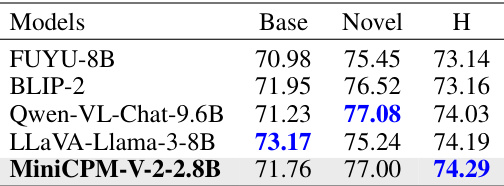
This table presents the results of experiments conducted to evaluate the impact of different Large Language Models (LLMs) and Large Multimodal Models (LMMs) on the performance of the proposed IPO method. The table shows that using GPT-3.5-turbo as the LLM optimizer and MiniCPM-V-2.0 for generating image descriptions yielded the best overall performance (H-score) on the benchmark.
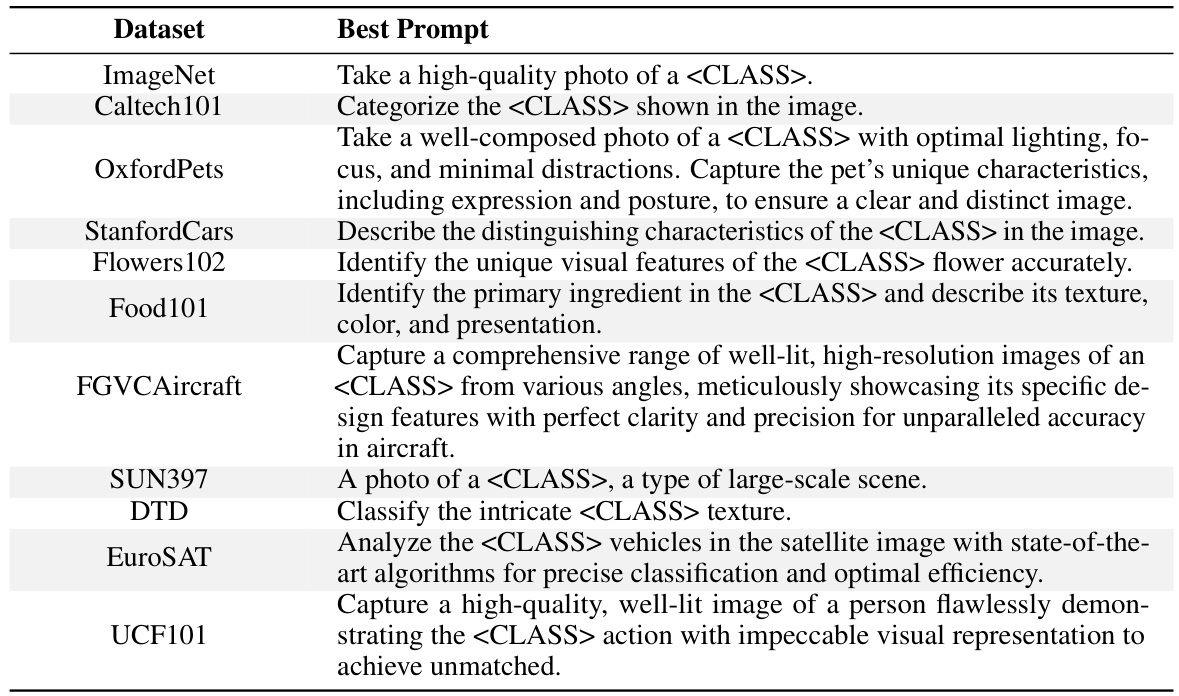
This table presents a comparison of different prompt variations across various vision-language models on the Flower102 dataset. It highlights the impact of specific words and phrases on model performance, particularly demonstrating that the original CLIP model is sensitive to the word ‘photo’. The table also illustrates the overfitting behavior of methods such as CoOP and CoCoOP, showing improvements in novel class performance when learned tokens are removed. Finally, it showcases how the interpretable prompt optimization method (IPO) ensures that all tokens contribute to the overall performance, both in base and novel classes.
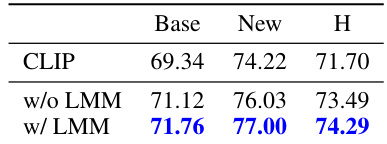
This table compares the performance of the model with and without image descriptions included in the Prompt Optimization Prompt. The results show that including image descriptions significantly improves the model’s accuracy, particularly on novel classes. This highlights the importance of incorporating multimodal information into the prompt optimization process.

This table compares the performance of the CLIP model with and without the inclusion of image descriptions generated by a Large Multimodal Model (LMM) in the Prompt Optimization Prompt. It demonstrates the improvement in the model’s performance when image information is integrated into the prompt optimization process. The results highlight the importance of multimodal inputs for enhancing prompt optimization in vision-language models.
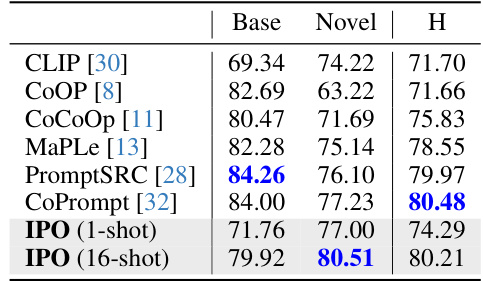
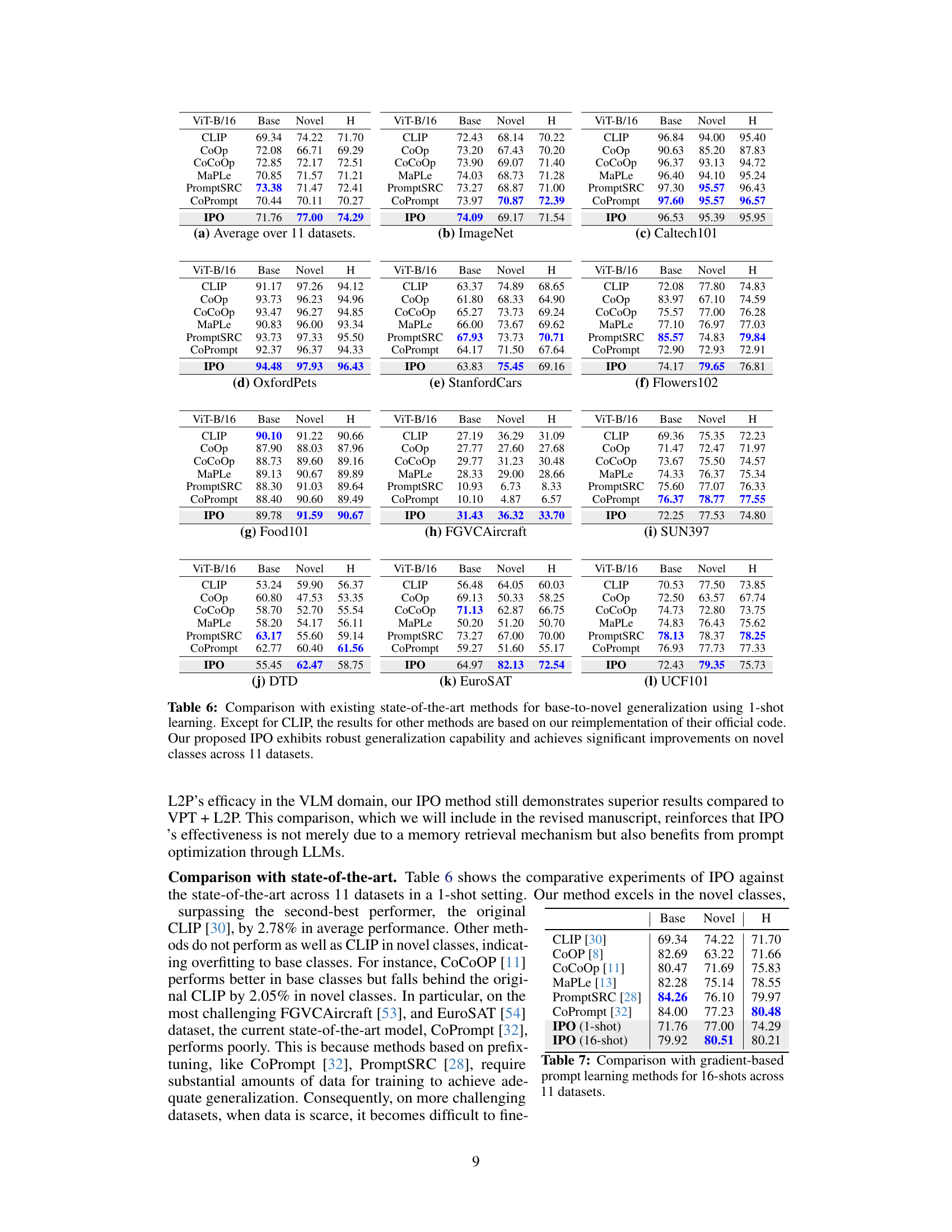
This table compares the performance of the proposed IPO method against several existing state-of-the-art methods on eleven image classification datasets. The comparison is done using a 1-shot learning setting (meaning each model is only shown one example from each class during training). The table shows the performance (harmonic mean of base and novel accuracy) of each method on each dataset, highlighting IPO’s improved performance on novel classes (classes not seen during training). Note that results for methods other than CLIP are from the authors’ re-implementation, ensuring consistent evaluation.
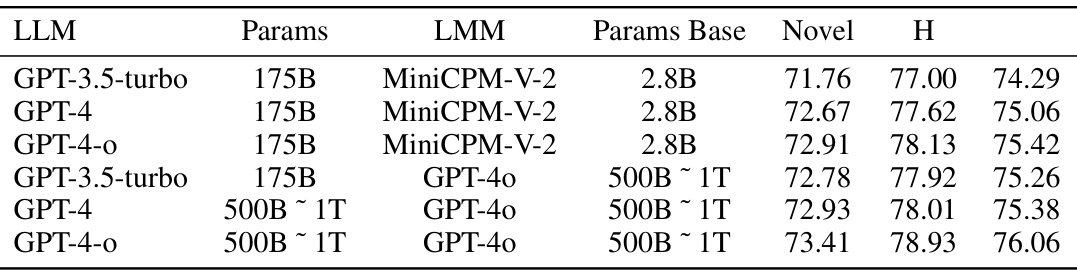
This table presents the results of experiments conducted to evaluate the impact of using different large language models (LLMs) on the performance of the proposed interpretable prompt optimizer (IPO). The table shows that using larger and more advanced LLMs generally leads to improved performance in both base and novel classes, as measured by harmonic mean (H). The results suggest that increasing LLM capacity enhances the model’s ability to generate effective and generalizable prompts.

This table shows the impact of using different LLMs (large language models) on the performance of the IPO method. The results demonstrate that using more advanced LLMs, like GPT-4 and GPT-40, leads to improved performance in both base and novel classes, particularly with the H-score (harmonic mean).

This table compares different prompt engineering methods on the Flower102 dataset, evaluating their performance on both base and novel classes. It highlights the impact of specific words in the prompts and demonstrates that the proposed method (IPO) is more robust to word removal compared to existing techniques. The table includes occlusion sensitivity analysis, highlighting the importance of different words for various methods and illustrating how IPO improves the performance and interpretability of prompts compared to gradient-based methods.

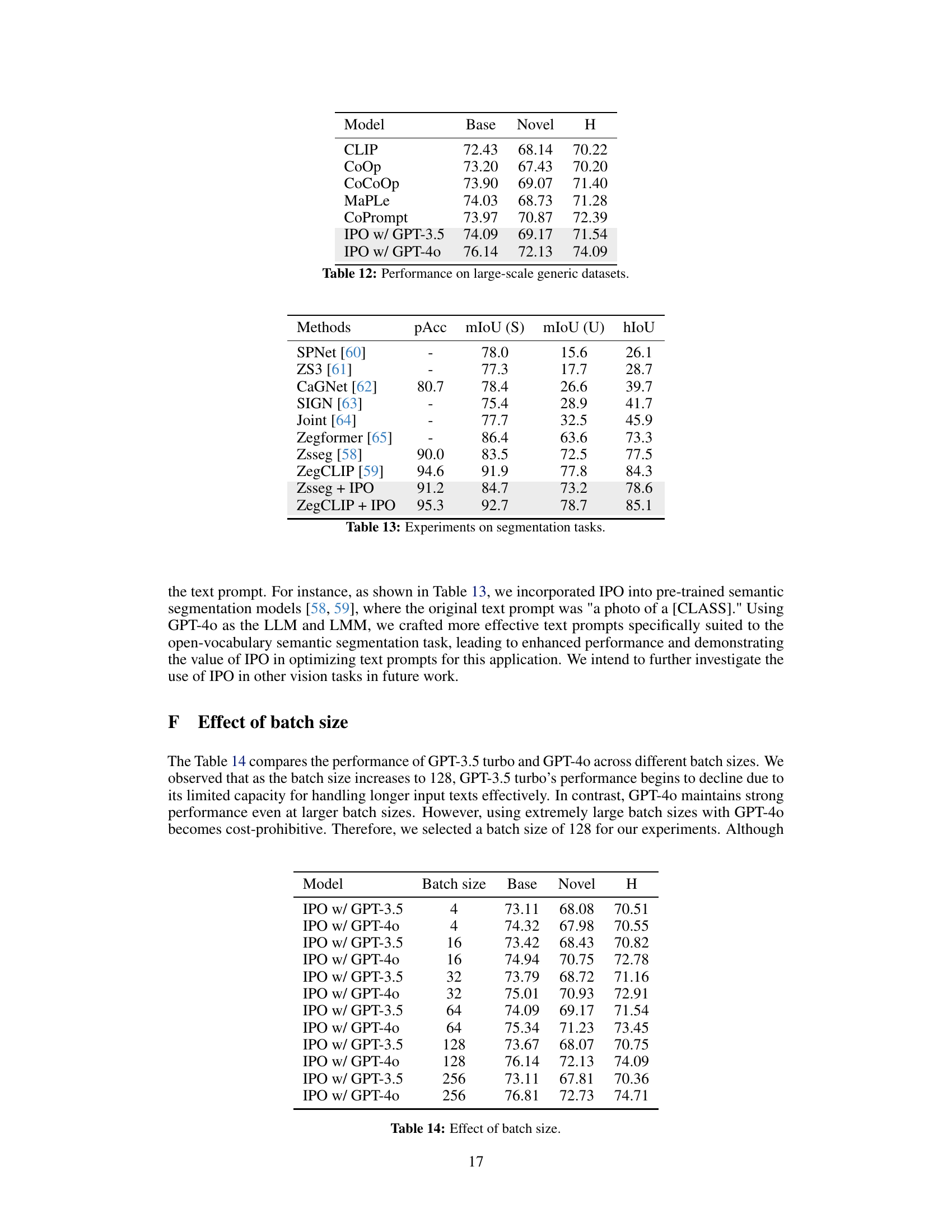
This table presents the results of experiments conducted on semantic segmentation tasks. Several methods, including SPNet, ZS3, CaGNet, SIGN, Joint, Zegformer, Zsseg, and ZegCLIP are compared against two variations that incorporate the proposed IPO method (Zsseg + IPO and ZegCLIP + IPO). The table shows performance metrics for each method, including pAcc (pixel accuracy), mIoU (S) (mean Intersection over Union for the source domain), mIoU (U) (mean Intersection over Union for the unseen domain), and hIoU (harmonic mean of mIoU (S) and mIoU (U)). The results demonstrate the performance improvements achieved by integrating the proposed IPO method into existing semantic segmentation models.

This table presents the results of experiments conducted to evaluate the impact of different batch sizes on the performance of the IPO model when using either GPT-3.5 Turbo or GPT-40 as the large language model (LLM). The table shows that while GPT-40 maintains strong performance even with larger batch sizes, the performance of GPT-3.5 Turbo begins to decline when the batch size increases beyond a certain point. This is because GPT-3.5 Turbo has a limited capacity for effectively processing longer input texts. The results highlight the trade-off between cost-effectiveness and performance when choosing a batch size.
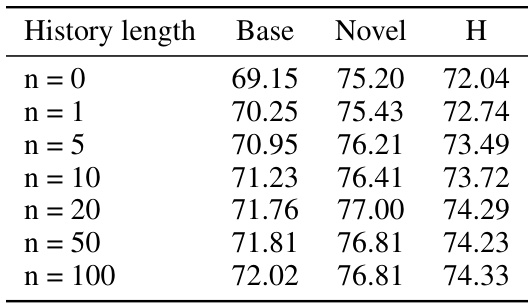
This table shows the impact of varying prompt history lengths on the model’s performance, evaluated on the base and novel classes as well as the harmonic mean. It demonstrates that including a history of previous prompts leads to improved performance, with optimal performance at 20 past prompts. While including more past prompts improves the harmonic mean, it significantly increases the computational cost, which is why 20 was chosen as the optimal balance between performance and cost.

This table compares different prompt methods (CLIP, COOP, COCOOP, and IPO) on the Flower102 dataset. It shows the accuracy for base and novel classes using different prompts, including prompts with certain words removed. The results highlight the overfitting issue of some methods and the interpretability advantage of the proposed IPO method.
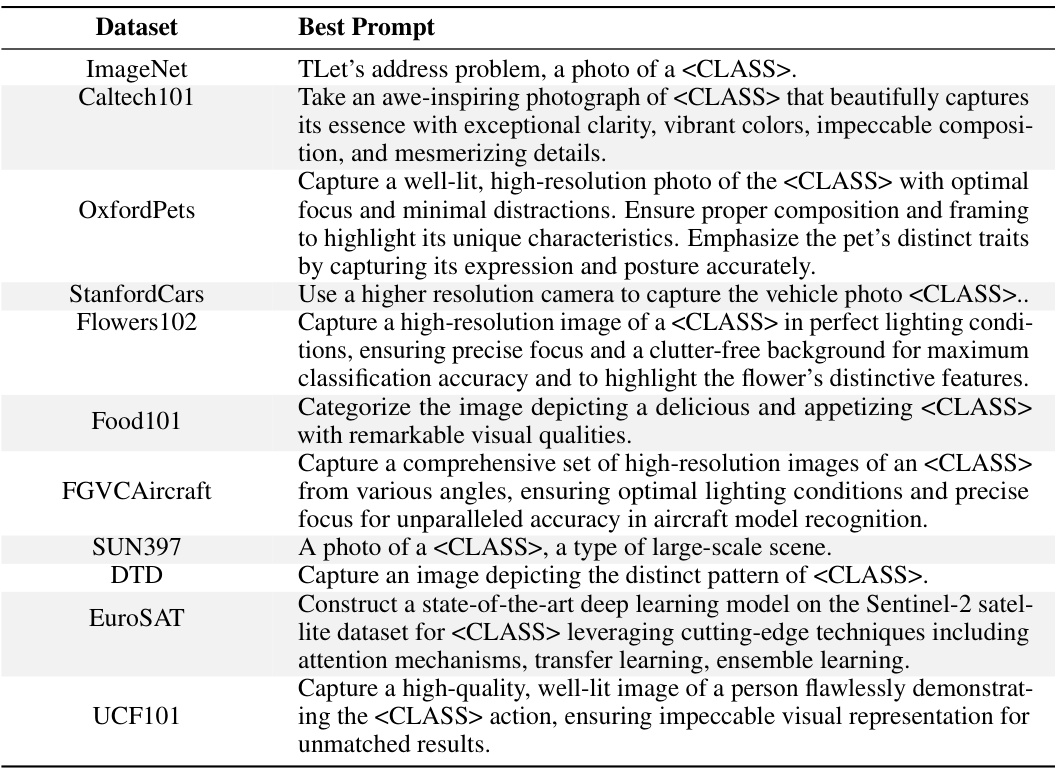
This table presents a comparison of different prompt strategies on the Flower102 dataset. It shows the performance of CLIP, CoOP, and CoCoOP models using various prompts, with and without specific words or tokens removed. The results highlight the impact of specific keywords on model performance and show that the proposed interpretable prompt optimization method (IPO) offers improvements in novel classes while addressing overfitting issues observed in other methods.

This table presents a comparison of different prompt engineering methods (CLIP, CoOP, CoCoOP, and IPO) on the Flower102 dataset. It uses occlusion sensitivity analysis to show the impact of removing words from the prompts on the accuracy of classification for both base and novel classes. The results highlight the differences in how these methods learn and generalize, with IPO demonstrating the importance of each word in its human-interpretable prompts. The shaded sections represent the original performance of each model.

This table compares different prompt engineering methods (CLIP, CoOP, CoCoOP, and IPO) on the Flower102 dataset. It shows the impact of removing words from prompts on classification accuracy for both base and novel classes. The results highlight the different strengths and weaknesses of each method, specifically showing how IPO produces more robust and interpretable prompts.

This table compares the performance of different prompt optimization methods (CLIP, CoOP, CoCoOP, and IPO) on the Flower102 dataset. It uses occlusion sensitivity analysis to evaluate the importance of individual words in the prompts. The results show that CLIP is sensitive to specific words, while CoOP and CoCoOP exhibit overfitting. In contrast, IPO generates more interpretable prompts where each word contributes to performance.

This table compares the performance of different prompt optimization methods (CLIP, COOP, CoCoOP, and IPO) on the Flower102 dataset. It shows the accuracy of each method using different prompts, including the original prompt and prompts with words removed. The results highlight the impact of specific keywords and the overfitting issues with gradient-based methods.
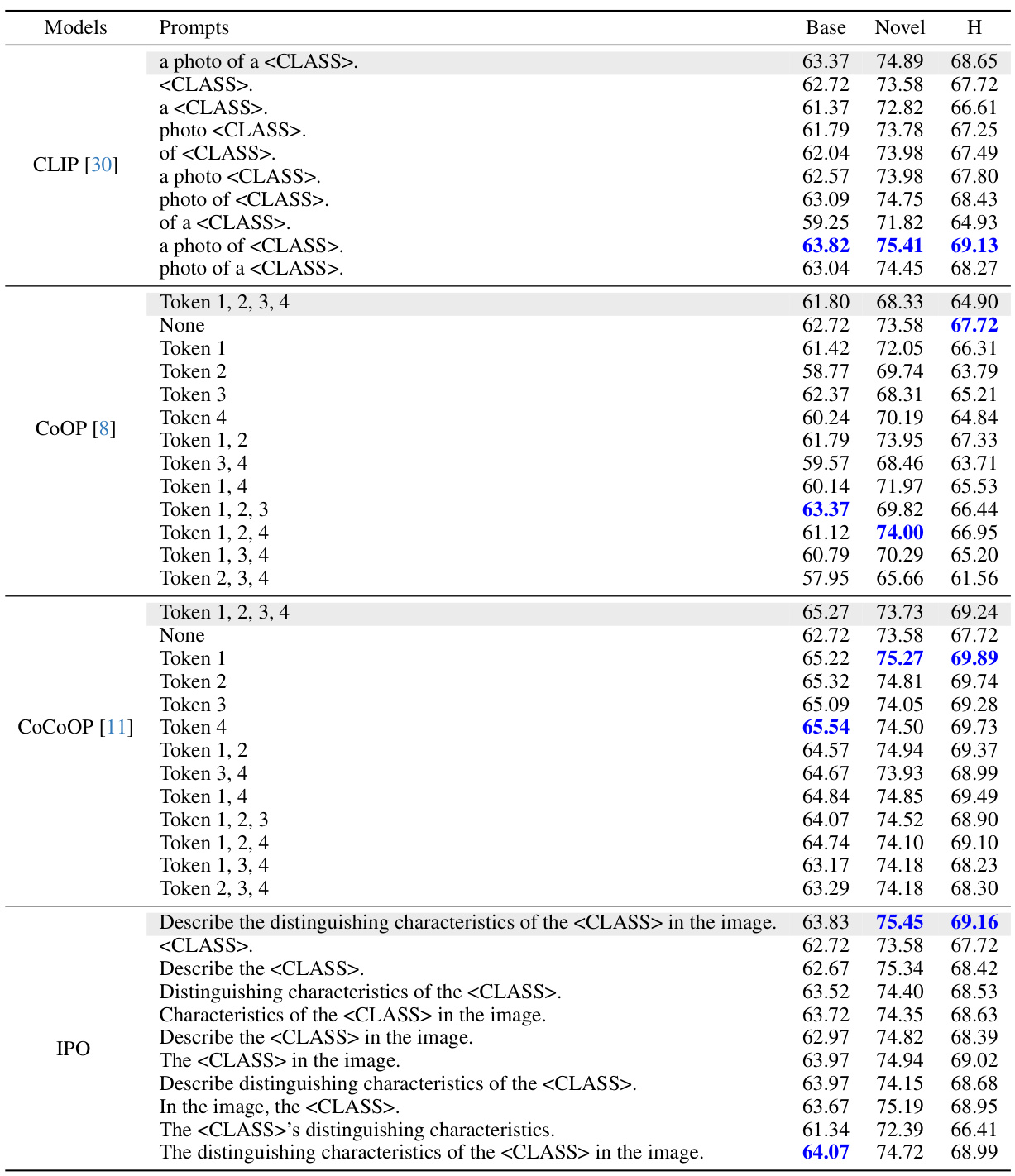
This table compares different prompt engineering methods on the Flower102 dataset, analyzing their performance on base and novel classes. It highlights the impact of removing individual words from prompts on model accuracy, revealing that traditional gradient-based methods (CoOP, CoCoOP) suffer from overfitting. In contrast, the proposed interpretable prompt optimization (IPO) demonstrates that all words in the generated prompts significantly contribute to improved performance on both base and novel classes. The results are presented using the harmonic mean (H) of base and novel class accuracies.

This table compares different prompt engineering methods (CLIP, CoOP, CoCoOP, and IPO) on the Flower102 dataset. It evaluates the performance of various prompts, including the standard prompt and prompts generated by each method. Occlusion sensitivity analysis is applied by removing individual words to determine their importance. The results highlight differences in performance and overfitting between the methods, showcasing IPO’s superior interpretability and generalization.
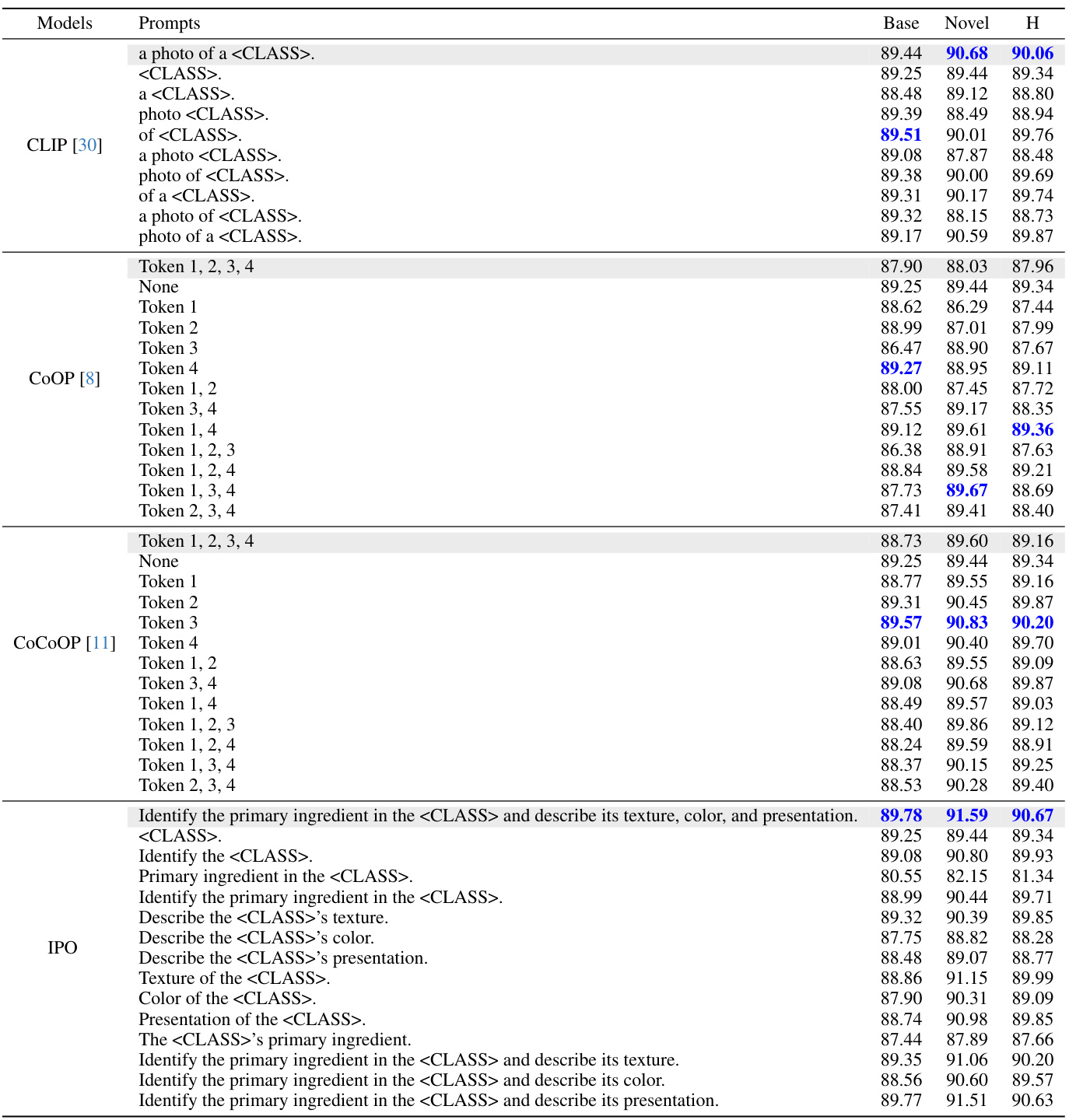
This table compares different prompt engineering methods (CLIP, CoOP, CoCoOP, and IPO) on the Flower102 dataset. It shows the accuracy on base and novel classes using various prompts, including prompts with words removed to assess their individual importance. The results highlight the different strengths of each method. CLIP is sensitive to specific words, CoOP and CoCoOP overfit to base classes, while IPO generates more interpretable and generalizable prompts.
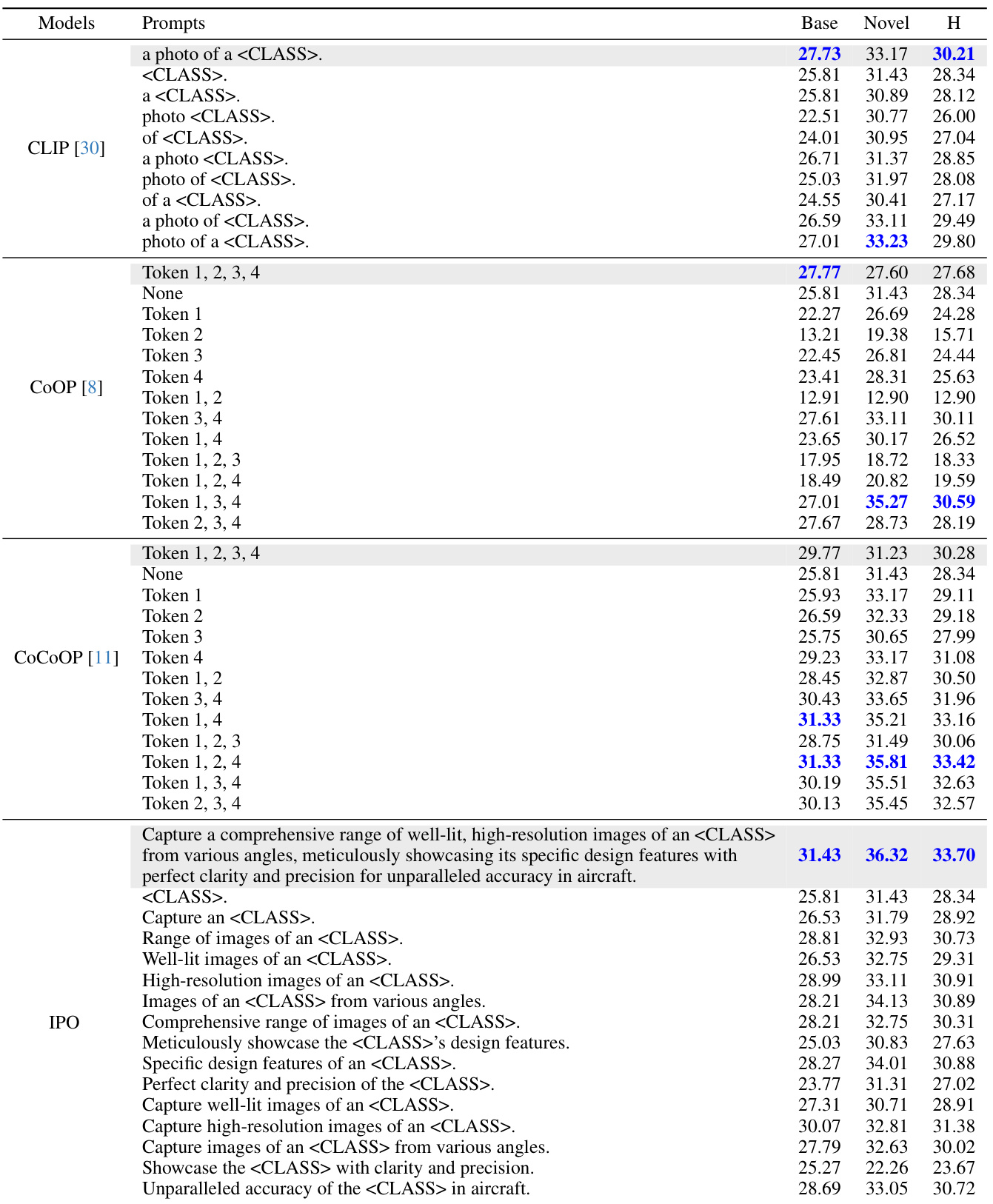
This table compares the performance of different prompt optimization methods on the Flower102 dataset. It shows the impact of removing individual words from prompts on accuracy, highlighting the importance of specific words for different models. The table contrasts traditional gradient-based methods with the proposed interpretable prompt optimizer (IPO), demonstrating IPO’s ability to generate human-understandable prompts that improve both base and novel class performance without overfitting.

This table compares the performance of different prompt engineering methods (CLIP, CoOP, CoCoOP, and IPO) on the Flower102 dataset. It shows the accuracy of different prompts on base and novel classes. Occlusion sensitivity analysis is performed to understand which words/tokens in the prompts are most impactful on performance. The results highlight the differences in how different methods handle base class overfitting and how IPO produces interpretable prompts.

This table compares different prompt engineering methods (CLIP, COOP, COCOOP, and IPO) on the Flower102 dataset. It shows the accuracy on base and novel classes for various prompts, including prompts with words removed to assess their importance. The results highlight the overfitting issues with gradient-based methods and demonstrate IPO’s improved interpretability and performance.
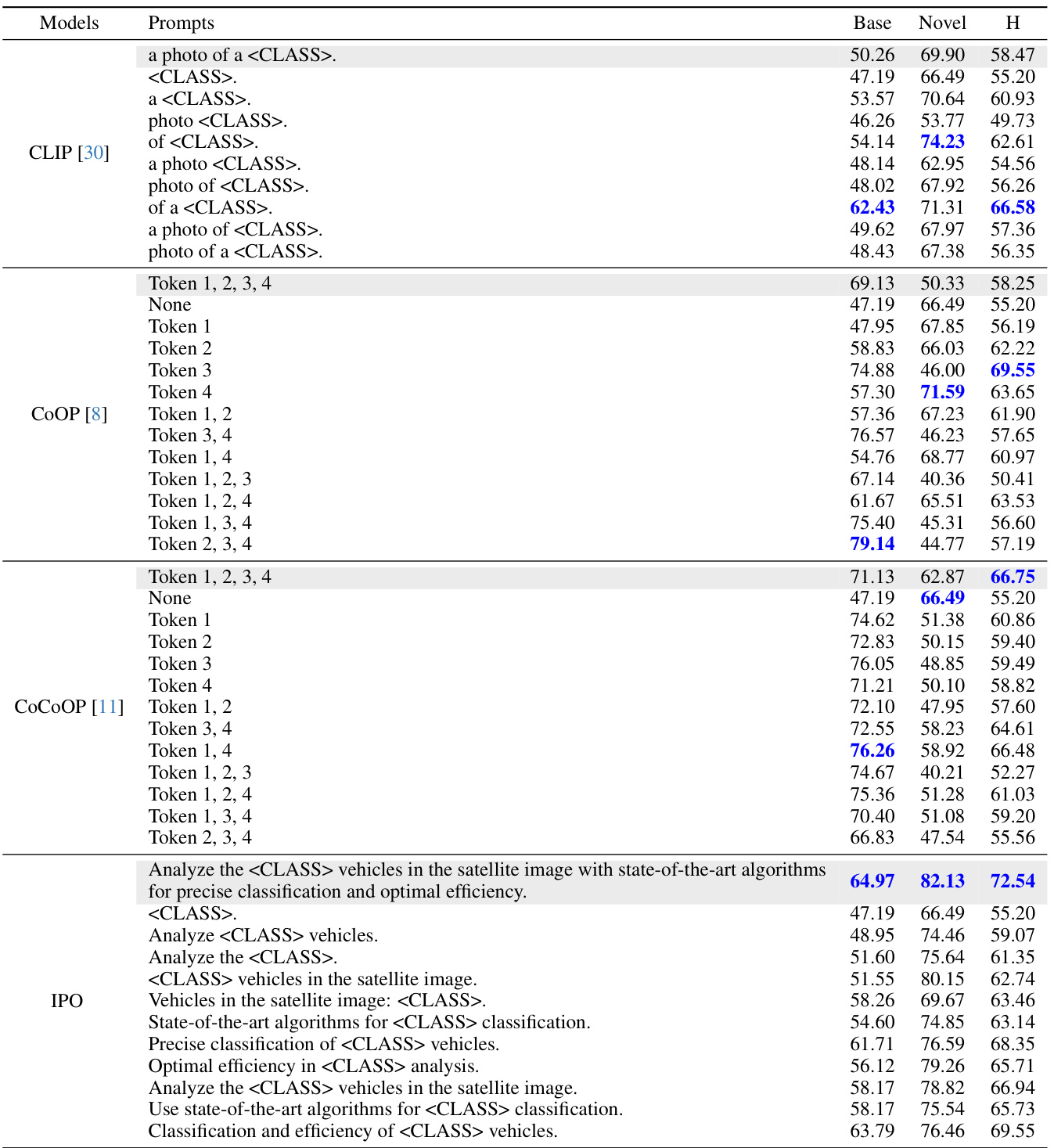
This table compares the performance of different prompt engineering methods (CLIP, CoOP, CoCoOP, and IPO) on the Flower102 dataset. It uses occlusion sensitivity analysis to evaluate the importance of individual words within prompts. The results highlight the overfitting issues of gradient-descent based methods (CoOP and CoCoOP) and the improved performance and interpretability of the proposed IPO method.
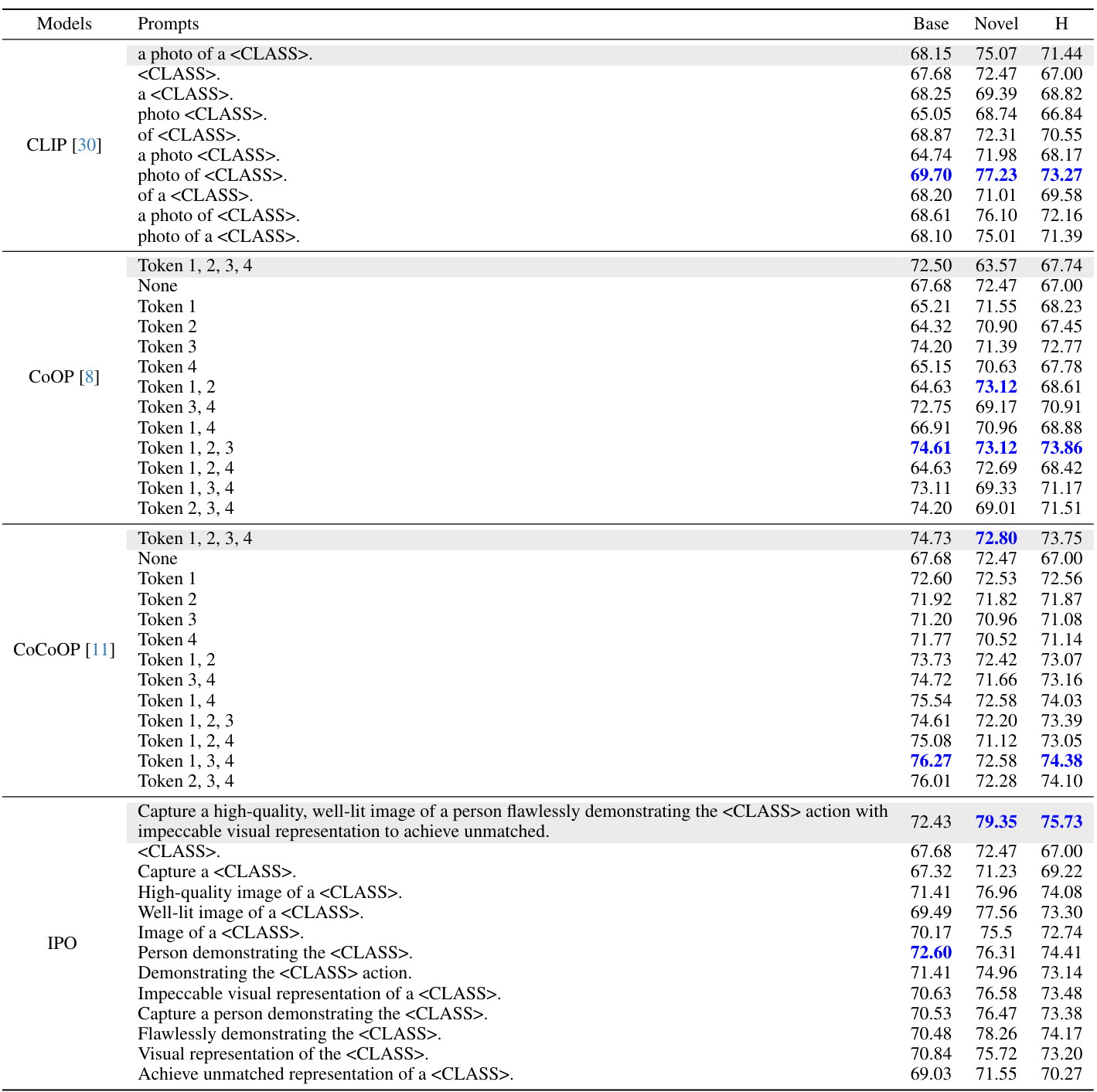
This table compares the performance of different prompt optimization methods on the Flower102 dataset. It shows how different prompts (including those generated by the proposed IPO method) affect the model’s performance on both base and novel classes. Occlusion sensitivity analysis is used to determine the importance of each word in the prompts. The results highlight the strengths and weaknesses of different approaches and illustrate the interpretability of the IPO method.
Full paper#