↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
The learnware paradigm promotes model reuse, but protecting developers’ training data is critical. Current learnware systems rely on RKME (Reduced Kernel Mean Embedding) specifications to characterize models without accessing training data, but their data preservation ability lacked theoretical analysis. This creates a challenge in balancing the need to identify helpful models with the need to protect developer privacy.
This paper addresses this gap by providing a theoretical analysis of RKME’s ability to protect training data. It uses geometric analysis on manifolds to show that RKME effectively conceals original data and resists common inference attacks. The analysis demonstrates that RKME’s data protection improves exponentially as its size decreases, while maintaining sufficient information for effective model identification. The findings provide a crucial theoretical foundation for designing more secure and practical learnware systems.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in machine learning and data privacy. It provides a theoretical framework for analyzing the privacy-preserving capabilities of RKME specifications, a key component in the emerging learnware paradigm. This work is significant because it addresses a critical challenge in sharing and reusing machine learning models—balancing the need for model identification with the preservation of sensitive training data. The findings offer valuable insights for developing more robust and privacy-conscious learnware systems and inspire further research into privacy-preserving synthetic data generation techniques.
Visual Insights#
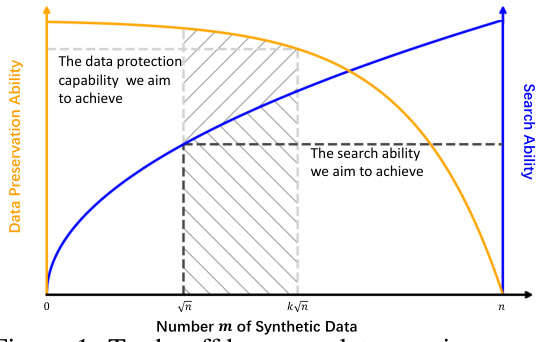
This figure illustrates the trade-off between data preservation and search ability in the learnware paradigm. The x-axis represents the number of synthetic data points (m) in the RKME specification. The y-axis shows the data preservation ability (blue curve) and search ability (orange curve). The blue curve indicates that as the number of synthetic data points decreases, the risk of data leakage diminishes. However, the search ability (orange curve) also decreases as m decreases, indicating a trade-off between these two aspects. The shaded area represents a practical range for m where both data preservation and search ability are satisfactory.
This table visually represents the trade-off between data privacy (data consistency preservation) and search ability in the learnware system. The x-axis represents the number of synthetic data points (m) used in the RKME specification. The y-axis shows both data preservation ability and search ability. As the number of synthetic points increases, the search ability improves (approaching the ideal ability), but the data protection decreases (approaching zero protection). The shaded area indicates a practical range of m where both data privacy and search are reasonably well-balanced.
Full paper#



















