↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large language models (LLMs) excel at text generation but struggle with domain-specific tasks, often lacking access to relevant knowledge embedded within latent spaces. This research introduces the Embedding-Aligned Guided Language (EAGLE) agent, a reinforcement learning framework that addresses this issue. EAGLE treats a pre-trained LLM as an environment and trains an agent to guide the LLM’s generation towards optimal regions in latent embedding spaces based on a predefined criteria, such as user preferences or content gaps. The study uses MovieLens and Amazon Review datasets to showcase EAGLE’s ability to generate content that meets latent user demands.
EAGLE’s effectiveness is demonstrated by its ability to surface content gaps—previously unaddressed content that could improve system welfare. The research shows that optimizing the action set, the possible changes an agent can make to the text, enhances efficiency. Using G-optimal design for action selection, EAGLE efficiently explores the latent space, improves the quality and creativity of generated text. The study provides a new paradigm for using LLMs in various applications requiring controlled generation and alignment with existing data representations. This is highly relevant to researchers in natural language processing, reinforcement learning, and recommendation systems, where latent embeddings are commonly used.
Key Takeaways#
Why does it matter?#
This paper is significant because it introduces a novel framework for aligning large language models (LLMs) with latent embedding spaces, enabling more controlled and grounded text generation. This addresses a key challenge in LLM applications, where domain-specific knowledge is often encoded in latent spaces. The proposed EAGLE agent offers a powerful technique for guiding LLM generation based on predefined criteria, opening new avenues for creative content creation, personalized recommendations, and various other controlled text generation tasks. The research also contributes novel techniques for designing efficient action sets in reinforcement learning, advancing the state-of-the-art in LLM control and generation.
Visual Insights#
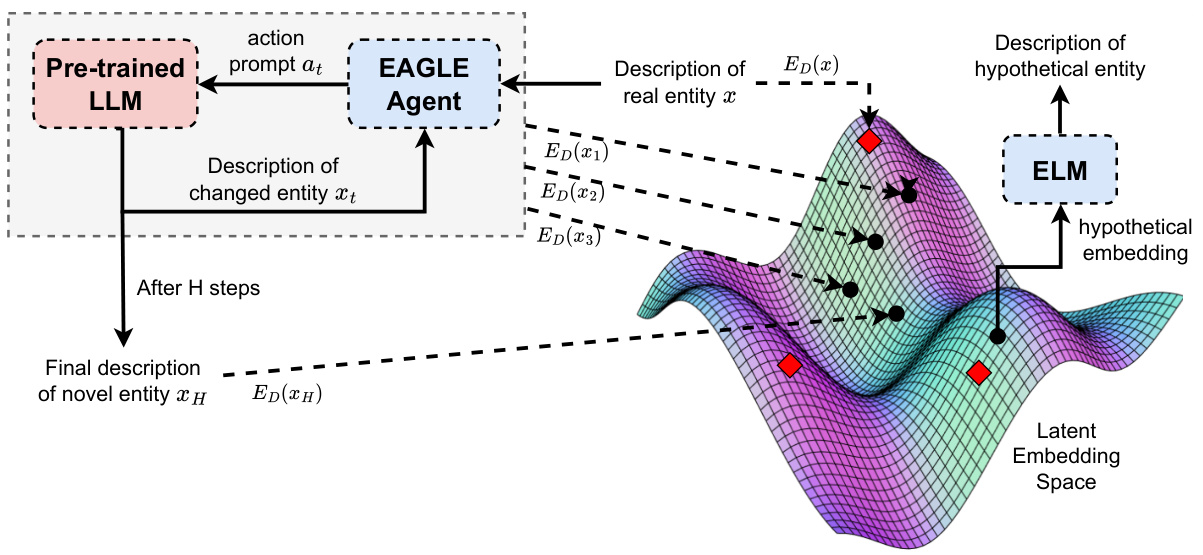
This figure compares the ELM and EAGLE methods for generating descriptions of novel entities. ELM uses a decoder to map from an optimal point in the latent embedding space to a description, whereas EAGLE uses an RL agent to iteratively steer an LLM’s generation towards that optimal point.

This table provides a glossary of terms and symbols used in the paper. It includes definitions for key concepts such as the ambient space (e.g., descriptions of movies), latent embedding space, action space (e.g., changes to a movie plot), latent dimension, ambient metric, latent metric, utility function, latent encoder, reference policy, and reference policy distribution. These terms are fundamental to understanding the EAGLE model and its application.
In-depth insights#
Embedding Alignment#
Embedding alignment, in the context of large language models (LLMs), presents a powerful paradigm for bridging the gap between symbolic reasoning and learned representations. It involves aligning the LLM’s outputs with a pre-defined latent embedding space, often reflecting domain-specific knowledge or user preferences. This alignment enables controlled and grounded text generation, ensuring that the LLM’s output remains consistent with the underlying data representation, and satisfies specific criteria. Reinforcement learning (RL) is a common approach for embedding alignment, using the LLM as an environment and training an agent to steer the LLM’s generation toward optimal regions within the embedding space. A critical aspect is the design of the action space, which directly affects the efficiency of the RL process. G-optimal design is a particularly promising method for creating efficient action spaces by strategically sampling within the latent space. Embedding alignment has vast potential for various applications, including content creation, question answering, and personalized recommendations, where aligning outputs with specific latent needs and contexts is highly beneficial.
RL-Driven LLM Control#
Reinforcement learning (RL) offers a powerful paradigm for controlling Large Language Models (LLMs). RL-driven LLM control leverages the ability of RL agents to learn optimal policies that guide LLM text generation toward desired outcomes. By framing the LLM as an environment, RL agents can learn to manipulate prompts and parameters to steer generation, shaping the generated text’s content, style, and factual accuracy. Key advantages include the ability to incorporate domain-specific knowledge and constraints directly into the reward function, allowing for finer control than traditional fine-tuning. However, challenges exist: designing effective reward functions can be complex, computationally expensive training is often required, and ensuring safety and alignment remains paramount. The exploration-exploitation trade-off is also crucial; efficiently finding high-reward areas of the LLM’s vast output space is a significant hurdle. Further research should focus on developing more efficient and robust RL algorithms, more principled methods for reward function design, and techniques for ensuring the safety and reliability of RL-controlled LLMs.
G-Optimal Action Design#
G-optimal action design is a crucial aspect of the EAGLE framework, addressing the challenge of creating a diverse and unbiased action space for efficiently exploring the latent embedding space. The core idea is to leverage the generative capabilities of LLMs to create a large set of candidate actions, then select a subset that optimally balances exploration and exploitation. This subset, determined using G-optimal design, minimizes the maximum variance of the expected embeddings, ensuring that the search for optimal entities is comprehensive and not limited to specific directions or regions within the embedding manifold. G-optimal design helps prevent bias in the search, which is particularly crucial when working with complex, high-dimensional spaces like those encountered in language modeling. By strategically choosing actions that cover a wide range of embedding space directions, EAGLE avoids getting stuck in local optima and is more likely to find novel and creative entities satisfying predefined criteria.
EAGLE Agent#
The EAGLE agent, as described in the research paper, is a reinforcement learning (RL) framework designed to align large language models (LLMs) with latent embedding spaces. This approach is novel because it uses a pre-trained LLM as the environment for RL training, allowing the agent to iteratively steer the LLM’s text generation toward optimal embedding regions as defined by a predetermined criterion. The core innovation lies in directly using latent embeddings to define the RL objective function, bypassing the need for explicit decoding from embedding space to the ambient space. This iterative process allows EAGLE to generate novel content that not only aligns with the specified criteria but also maintains consistency with the domain-specific knowledge represented in the embeddings. State-dependent action sets, designed using a combination of LLMs and G-optimal design, optimize EAGLE’s efficiency, ensuring a comprehensive search of the embedding space. The framework’s effectiveness was demonstrably proven across datasets, showcasing its potential for controlled and grounded text generation in diverse domains. Overall, the EAGLE agent presents a powerful and flexible method for leveraging LLMs in controlled content creation tasks.
Future Research#
Future research directions stemming from this Embedding-Aligned Guided Language (EAGLE) framework are multifaceted. Extending EAGLE to diverse modalities beyond text, such as images, audio, and video, presents a significant challenge and opportunity. This would require adapting the action space and reward function to suit the specific characteristics of each modality. Further investigation into more sophisticated action space designs is crucial. While the G-optimal design offers improved efficiency, exploring alternative approaches, potentially incorporating expert knowledge or human feedback, could yield even better results. Addressing the generalizability challenge remains vital, particularly in ensuring robustness to variations in dataset quality and latent space metrics. Finally, rigorous analysis of the ethical implications is paramount, especially concerning bias amplification and potential misuse in content generation. Thorough examination of these areas would significantly strengthen the EAGLE framework and broaden its applicability.
More visual insights#
More on figures
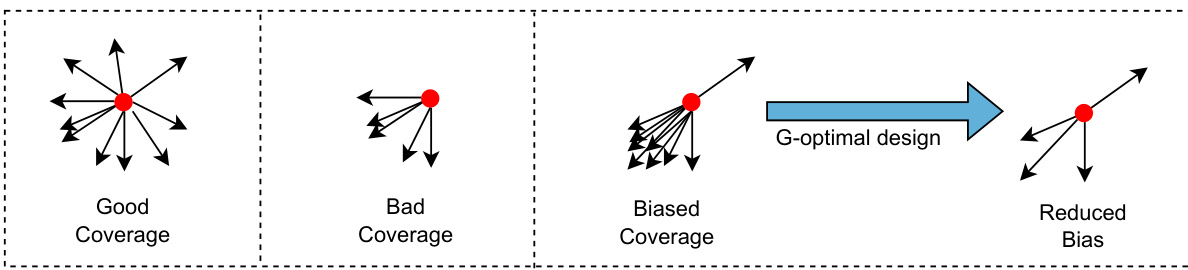
This figure illustrates different scenarios of action space coverage and bias in an embedding space. The leftmost panel depicts a scenario with good coverage where the action space spans multiple directions in the latent space. The next panel shows poor coverage, concentrating only in a small area of the space. The middle panel exhibits biased coverage, where actions cluster in specific directions. The rightmost panel shows reduced bias, implying improved and more balanced coverage of the latent space, achieved by using a G-optimal design to select the actions.

This figure illustrates the difference between ELM and EAGLE in generating descriptions of novel entities. ELM uses a pre-trained decoder to map from an optimal point in the latent embedding space to a description in the ambient space. EAGLE uses a pre-trained LLM as an environment and an RL agent iteratively to steer LLM generations toward better regions in the latent embedding space based on some predefined criteria. The latent space is visualized as a 3D surface with existing entities shown as red points and hypothetical entities as black points.

This figure compares two methods for generating descriptions of novel entities: ELM and EAGLE. ELM uses a pre-trained decoder to map from latent space to ambient space, maximizing a utility function in latent space. EAGLE uses a pre-trained LLM as an environment and reinforcement learning to iteratively refine an entity’s description, using an encoder to map from ambient space to latent space. The latent embedding space is shown as a 3D surface; red points represent existing entities, and black points represent hypothetical entities.

This figure compares the ELM and EAGLE methods for generating descriptions of novel entities. ELM uses a pre-trained decoder to map an optimal point in latent embedding space to a description in ambient space. EAGLE uses a pre-trained LLM as an environment and iteratively refines a description using RL until it reaches an optimal area in the latent embedding space. The figure visually represents the latent embedding space as a complex surface, highlighting existing and hypothetical entities.

This figure illustrates the difference between the ELM and EAGLE methods for generating descriptions of novel entities. ELM uses a pre-trained decoder to map an optimal point in latent embedding space to a description. In contrast, EAGLE uses a pre-trained LLM as an environment and iteratively refines a description through reinforcement learning, guided by an objective function defined in the latent embedding space. The figure highlights the key difference: ELM requires a decoder while EAGLE leverages the LLM directly for generation, only requiring an encoder to map the generated descriptions to latent space.

This figure illustrates the difference between ELM and EAGLE in generating descriptions of novel entities. ELM uses a pre-trained decoder to map an optimal latent embedding to a description. In contrast, EAGLE uses a pre-trained LLM as an environment and iteratively refines an existing entity’s description through RL, guided by latent embeddings and a reward signal to maximize utility.

This figure compares the methods of ELM and EAGLE in generating descriptions for novel entities. ELM uses a pre-trained decoder to map an optimal latent embedding to a description. Conversely, EAGLE iteratively uses a pre-trained LLM as an environment to generate descriptions, guided by reinforcement learning to maximize utility in the latent embedding space.

This figure compares and contrasts the ELM and EAGLE methods for generating descriptions of novel entities. ELM uses a pre-trained decoder to map an optimal latent embedding to a description. Conversely, EAGLE uses a pre-trained LLM as an environment and iteratively refines a description using reinforcement learning, guided by an objective function defined in the latent embedding space. The figure uses a 3D surface to represent the latent embedding space, illustrating how both methods aim to identify optimal points within that space, but use different approaches to do so.
This figure compares the two methods of generating novel entities, ELM and EAGLE. ELM uses a decoder to translate an optimal point in the latent embedding space to a description in the ambient space. EAGLE uses a pre-trained LLM as an environment and iteratively refines a description using reinforcement learning, guided by the latent embedding space and a utility function.
More on tables

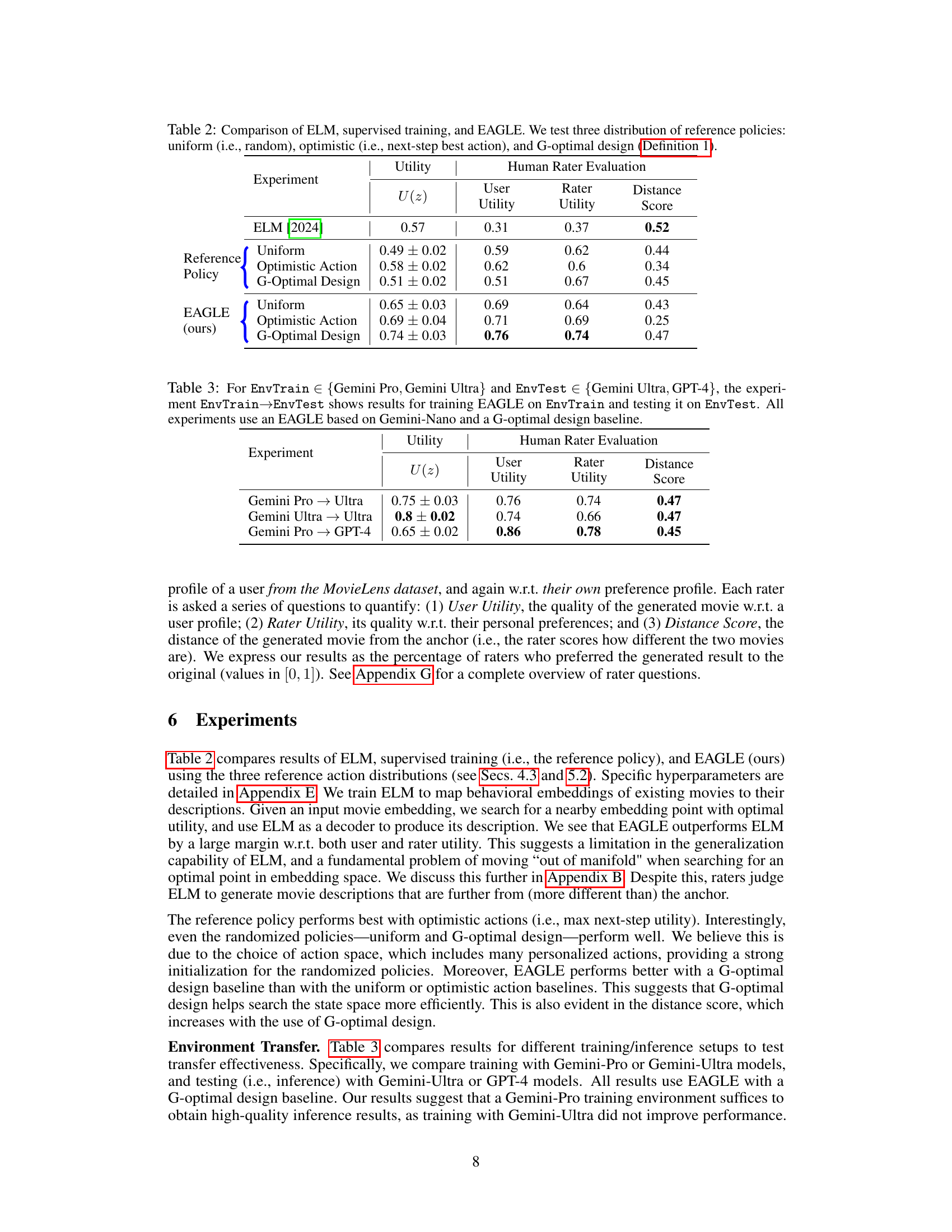
This table compares the performance of three different methods for generating novel entities that align with a latent embedding space: ELM, supervised training using a reference policy, and the proposed EAGLE agent. Three different reference policy distributions are tested with each method: uniform (random), optimistic (choosing the action with the highest expected immediate reward), and G-optimal design (a method for choosing actions to maximize exploration and minimize variance). The results are evaluated based on utility scores (measuring how well the generated entities meet the predefined criteria), user utility (ratings from human evaluators about how well the generated entities satisfy user needs), rater utility (ratings from human evaluators reflecting their personal preference for the generated content), and distance (measuring how different the generated content is from the existing content).
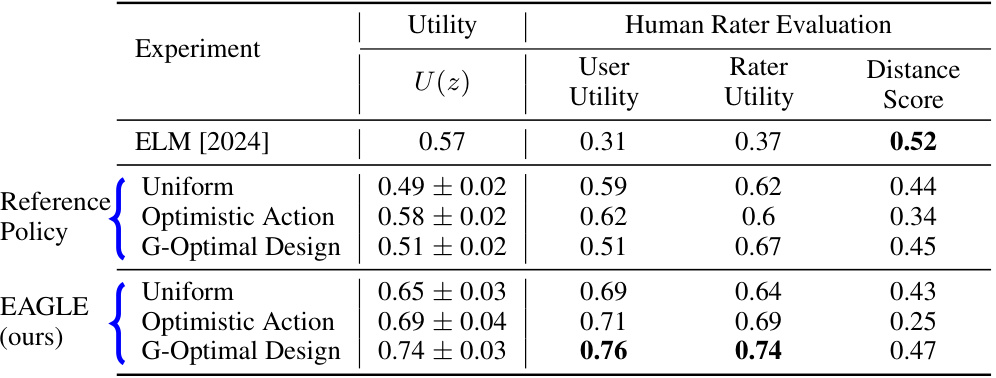
The table compares the performance of three different methods for generating novel entities that adhere to an underlying embedding space: ELM (Embedding Language Models), supervised training using different reference policies (uniform, optimistic, and G-optimal design), and EAGLE (Embedding-Aligned Guided Language). The results show the utility of the generated entities, as well as human rater evaluations of user utility, rater utility, and distance from the original entity. EAGLE generally outperforms the other methods, particularly when using the G-optimal design policy.
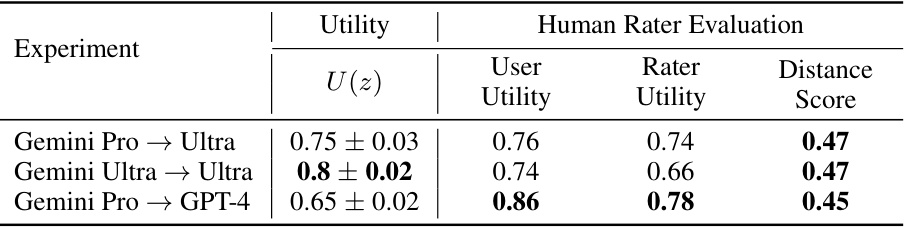
This table presents the results of experiments designed to test the transferability of EAGLE across different LLM environments. It shows how well EAGLE, trained on either Gemini Pro or Gemini Ultra, performs when tested on either Gemini Ultra or GPT-4. All experiments used a Gemini-Nano based EAGLE agent and a G-optimal design baseline. The metrics reported include the utility score (U(z)), user utility, rater utility, and distance score. This evaluation assessed the transferability of the trained model to different LLMs.
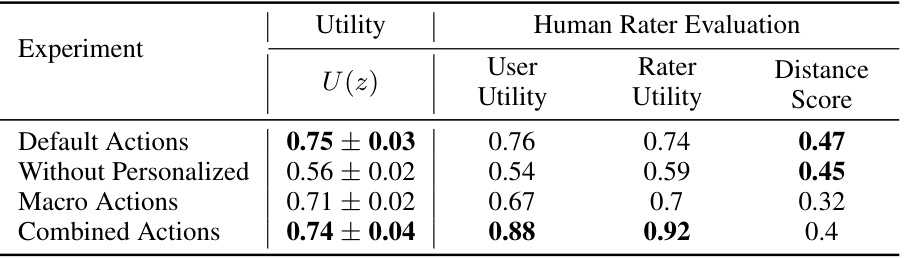
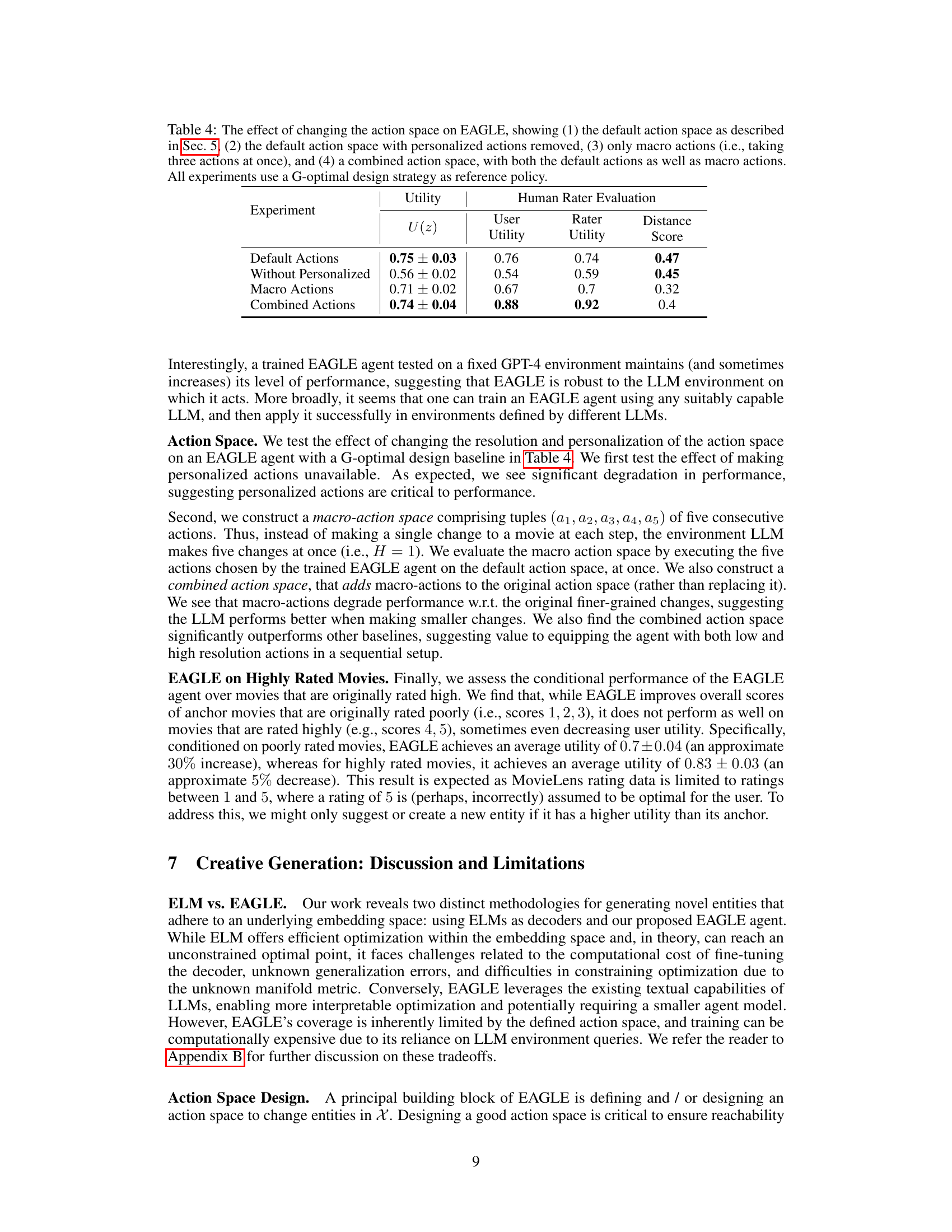
This table presents the results of experiments evaluating the impact of different action space designs on the performance of the EAGLE agent. It compares four different action space configurations: the default action space, the default action space without personalized actions, a macro-action space (three actions at once), and a combined action space (default + macro actions). All configurations utilize a G-optimal design as the reference policy. The metrics reported include utility scores (U(z)) and human rater evaluation scores across different aspects (User Utility, Rater Utility, Distance).

This table compares the performance of three different methods for generating novel entities that adhere to a latent embedding space: ELM (Embedding Language Model), supervised training with three different reference policies (uniform, optimistic, and G-optimal design), and the proposed EAGLE (Embedding-Aligned Guided Language) method. The results are evaluated using utility scores and a human rater evaluation. The table shows the utility, user utility, rater utility, and distance scores for each method and reference policy. The G-optimal design generally outperforms other methods.

This table shows the hyperparameters used for training the reference policy in the EAGLE agent. The hyperparameters include the number of training steps, batch size, learning rate, and dropout probability. These parameters are important for controlling the training process and achieving good performance in reinforcement learning.
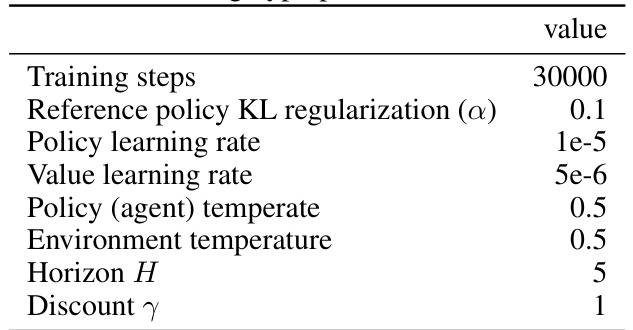
This table lists the hyperparameters used for training the EAGLE agent. It shows the values used for training steps, KL regularization, learning rates for the policy and value functions, temperature for the agent and environment, the horizon, and the discount factor.

This table presents the results of the EAGLE agent on a subset of the Amazon review dataset focused on clothing, shoes, and jewelry. It compares the performance of EAGLE against a reference policy using three metrics: Utility (measuring the overall value of the generated items), User Utility (measuring the value to a specific user), and Distance Score (measuring how different the generated item is from the original). The results demonstrate that EAGLE significantly outperforms the reference policy in terms of Utility and User Utility, suggesting its effectiveness in generating high-quality and user-relevant content.
Full paper#