↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Predicting people’s next location using past data is crucial for many location-based services. However, the data often shows a long-tail distribution, meaning that some places are visited frequently, while many others are rarely visited. This makes it difficult for AI models to accurately predict visits to less popular places.
The researchers address this challenge by proposing a new framework called LoTNext. This framework uses graph adjustment techniques to reduce the influence of overly-represented data, and a loss adjustment strategy to properly balance prediction errors. In addition, the LoTNext framework incorporates auxiliary prediction tasks to help the model better understand users’ movement patterns and to improve overall prediction accuracy. Experiments show that the LoTNext framework is significantly better than other existing methods, particularly at predicting less frequently visited locations.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers working on human mobility prediction and location-based services. It directly addresses the long-tail problem, a significant challenge hindering accurate predictions of less-visited locations. By introducing novel graph adjustment and loss adjustment techniques, along with auxiliary tasks, the paper offers valuable insights and methods to improve prediction accuracy and generalizability. This research is timely and highly relevant to the growing field of LBSN, opening new avenues for personalized services and urban planning. The available code further enhances the paper’s impact, making it easier to reproduce and build upon.
Visual Insights#

This figure shows the long-tailed distribution of Point of Interest (POI) check-in frequencies in the Gowalla dataset. The x-axis represents the frequency of visits to a POI, and the y-axis shows the number of POIs with that frequency. The graph clearly shows a heavy-tailed distribution; a small number of POIs are visited very frequently (Head POIs), while a large number of POIs are visited very infrequently (Long-Tail POIs). The illustrative diagram above highlights a hypothetical scenario where a prediction model might incorrectly predict a frequent location (like McDonald’s) when the user actually visits a less common place (like a ramen restaurant), demonstrating the challenge of predicting less-visited POIs.
This table presents a comparison of the performance of various models on two real-world datasets, Gowalla and Foursquare. The performance is measured using two metrics: Accuracy@k (Acc@k) and Mean Reciprocal Rank (MRR). Acc@k indicates the percentage of times the correct next POI is among the top k predictions, while MRR provides the average rank of the correct prediction. The table compares the performance of LoTNext with ten state-of-the-art baseline methods, demonstrating LoTNext’s superior performance.
In-depth insights#
Long-Tail POI Issue#
The Long-Tail POI issue highlights the imbalance in the distribution of Point-of-Interest (POI) visitations, where a few popular POIs receive a disproportionately high number of visits while the vast majority of POIs receive very few. This poses a significant challenge for human mobility prediction models, as they tend to perform well on predicting frequent visits to popular POIs (head POIs), but struggle to accurately predict infrequent visits to less popular POIs (long-tail POIs). The scarcity of data for long-tail POIs leads to biased model training, hindering their ability to capture the complex spatial-temporal dynamics associated with these less-visited locations. Addressing this issue requires advanced techniques such as graph adjustment, logit scaling, and sample re-weighting, to properly balance the model’s focus across all POIs and improve prediction accuracy for long-tail POIs.
LoTNext Framework#
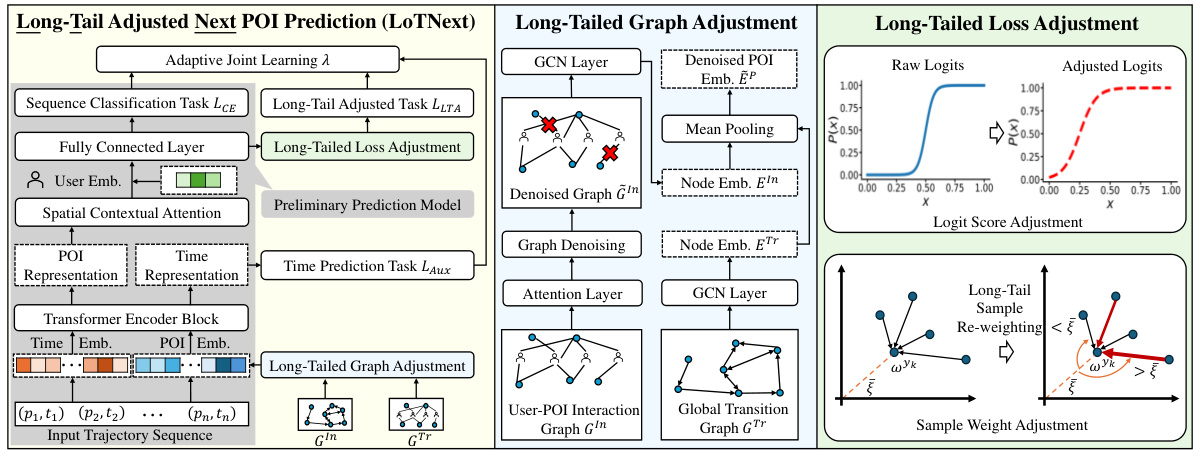
The LoTNext framework tackles the long-tail problem in human mobility prediction by combining innovative graph and loss adjustment techniques. Long-Tailed Graph Adjustment reduces the influence of less-visited Points of Interest (POIs) by denoising the user-POI interaction graph, focusing the model on more informative relationships. The framework also employs Long-Tailed Loss Adjustment, which dynamically weighs the loss function to balance the impact of frequently and infrequently visited POIs, preventing the model from being overly biased towards popular locations. Furthermore, LoTNext integrates an auxiliary prediction task, enhancing generalization and accuracy by incorporating temporal information. This multi-faceted approach, focusing on graph refinement, loss balancing, and enhanced context, significantly improves prediction accuracy, particularly for the long-tail POIs often missed by traditional methods. The framework demonstrates a significant advancement in handling the inherent data imbalance in human mobility datasets.
Graph Adjustment#
The concept of ‘Graph Adjustment’ within the context of a research paper likely refers to techniques for modifying or enhancing a graph structure to improve the performance of a machine learning model. This is often crucial when dealing with real-world data, which frequently contains noise, biases, and incomplete information. Graph adjustment methods aim to reduce the negative impact of these issues on model accuracy and efficiency. Common approaches may involve removing noisy edges or nodes, weighting edges based on their significance, or adding new edges to reflect relationships not explicitly captured in the original data. The specific type of graph adjustment used would depend on the nature of the graph and the goals of the research, potentially incorporating techniques such as graph filtering, graph embedding, or graph neural networks. A key consideration is the trade-off between simplification (removing noise) and preservation of essential structural information. Successful graph adjustment leads to a refined, more informative graph, enabling the machine learning model to better capture patterns, predict outcomes, and generalize well to new, unseen data. The paper likely provides justification for the chosen method and demonstrates its effectiveness through experimental evaluation.
Loss Adjustment#
In the context of long-tailed human mobility prediction, loss adjustment is crucial for mitigating the class imbalance problem where some points of interest (POIs) are visited far more frequently than others. Standard cross-entropy loss functions are insufficient, as they predominantly focus on the high-frequency (head) POIs, neglecting the less-visited (tail) POIs. Therefore, effective loss adjustment methods aim to re-weight the loss contributions of different POIs, giving more emphasis to the tail POIs to prevent the model from being biased toward the head POIs. This often involves modifying the loss function by either adjusting the logits or sample weights. Logit adjustment directly manipulates the prediction scores before the softmax layer, boosting the scores of under-represented classes. Sample weight adjustment, on the other hand, changes the importance of each data point in the loss calculation, assigning higher weights to tail samples. Combining both techniques can be particularly powerful, enabling a more balanced learning process that yields better prediction accuracy across all POIs, especially for the frequently overlooked tail POIs.
Future Works#
The paper’s core contribution is LoTNext, a framework addressing the long-tail problem in human mobility prediction. Future work could explore several avenues to enhance LoTNext. Firstly, incorporation of real-time, dynamic factors such as weather, traffic conditions, and events is crucial to improve prediction accuracy in diverse and unpredictable scenarios. Secondly, improving the model’s robustness to noisy or incomplete data is essential; strategies like data augmentation or more sophisticated noise handling techniques could be investigated. Thirdly, exploring alternative graph structures or embedding methods beyond the current GCN approach might yield further performance gains. Finally, a thorough privacy-preserving approach must be developed to responsibly utilize the vast amounts of location data required, potentially involving techniques like federated learning or differential privacy. Addressing these areas would significantly advance human mobility prediction.
More visual insights#
More on figures

This figure compares the performance of LoTNext and Graph-Flashback on the Gowalla dataset, focusing on the prediction accuracy for both long-tailed and head POIs. Subfigure (a) shows the accuracy at rank 1 (Acc@1) for both types of POIs, indicating that LoTNext outperforms Graph-Flashback in both cases. Subfigure (b) presents the mean reciprocal rank (MRR), a metric reflecting the average ranking of correct predictions, with LoTNext again showing a clear advantage. Finally, subfigure (c) illustrates the proportion of predicted POIs that are long-tailed versus head POIs for both models, demonstrating LoTNext’s greater propensity to predict long-tailed POIs.
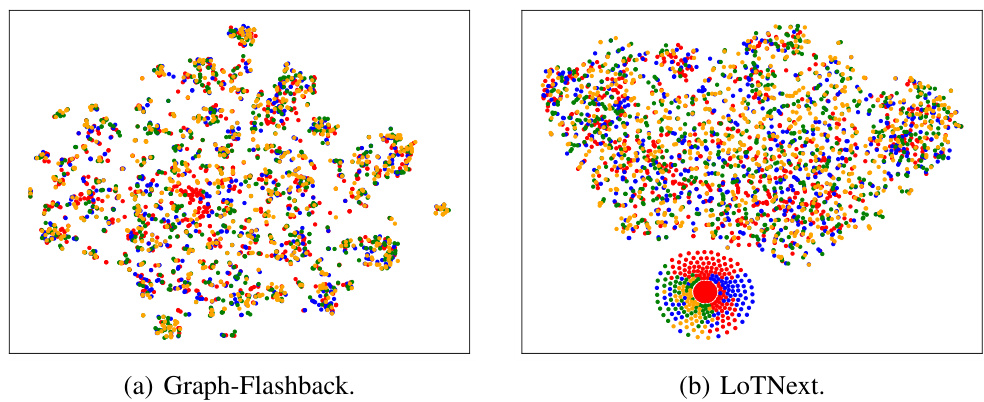
This figure compares the t-SNE visualization of the embeddings for the four least frequently occurring POIs on the Gowalla dataset using two different models: Graph-Flashback and LoTNext. The visualization shows how well each model can distinguish between the embeddings of these infrequently visited locations. Graph-Flashback shows significant overlap and less distinct clusters for these low-frequency POIs, suggesting difficulty in differentiating between them. LoTNext, in contrast, shows more distinct and well-separated embeddings, indicating its superior ability to capture the unique characteristics of even rarely visited locations. The color of each point corresponds to the frequency of visits for each POI.

This figure displays a visual comparison of sample predictions made by the Graph-Flashback and LoTNext models on a trajectory from the Gowalla dataset. It highlights a case where LoTNext accurately predicts a less frequently visited POI (long-tail POI), while Graph-Flashback incorrectly predicts a more frequently visited POI (head POI), showcasing LoTNext’s ability to handle long-tail data effectively.

This figure compares the performance of LoTNext and Graph-Flashback on the Gowalla dataset, specifically focusing on the prediction accuracy for long-tailed (less frequently visited) and head (frequently visited) POIs. It presents three sub-figures: (a) Acc@1: Compares the top-1 accuracy of both models for head and long-tailed POIs. (b) MRR: Compares the Mean Reciprocal Rank of both models for head and long-tailed POIs. (c) Proportion of Predicted POIs: Shows the percentage of predicted POIs that are long-tailed versus head POIs for both models. This illustrates the relative ability of each model to accurately predict less common locations. The results demonstrate that LoTNext outperforms Graph-Flashback in all aspects, showing a greater propensity for predicting long-tailed POIs.
More on tables

This table presents a comparison of the Gowalla and Foursquare datasets used in the paper. For each dataset, it shows the duration of data collection, the number of unique users and points of interest (POIs), the total number of check-ins, the total number of trajectories (sequences of check-ins), the density (a measure of the sparsity of check-ins), and the percentage of POIs visited fewer than 200 times and fewer than 100 times. This information is crucial for understanding the characteristics of the data and the challenge of the long-tail problem in human mobility prediction.
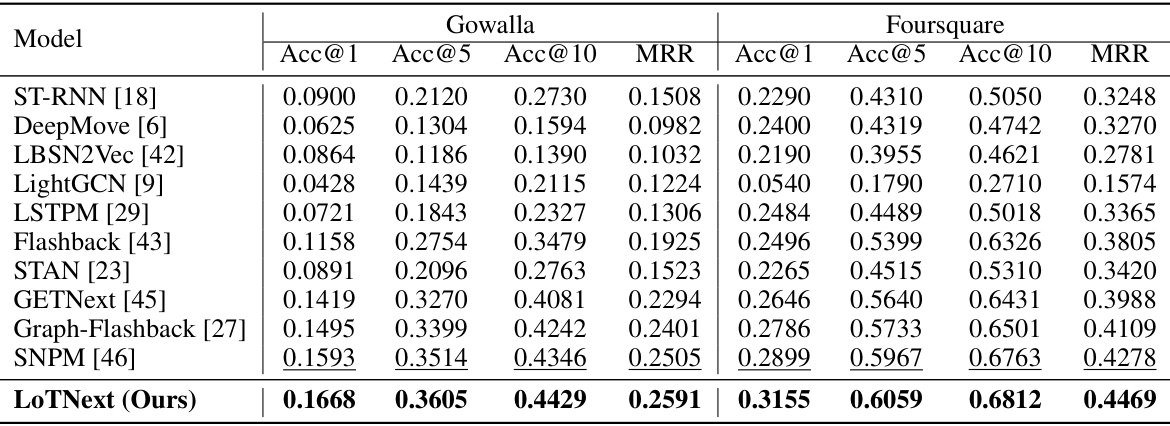
This table presents the performance comparison of the proposed LoTNext model against ten state-of-the-art baseline methods for next POI prediction. The comparison is conducted on two real-world LBSN datasets, Gowalla and Foursquare, using two evaluation metrics: Accuracy@k (Acc@k) and Mean Reciprocal Rank (MRR). Acc@k measures the accuracy of predicting the true next POI within the top k predictions, while MRR quantifies the average rank of the true POI among all predictions. The results demonstrate the superior performance of LoTNext across various metrics and datasets, highlighting its effectiveness in handling the long-tail distribution problem in human mobility prediction.
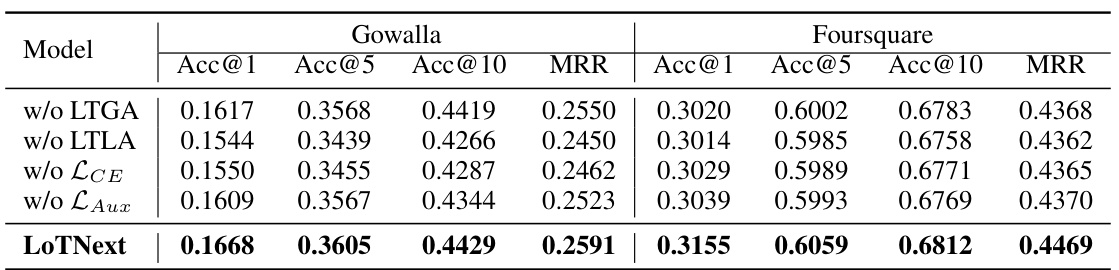
This table presents the ablation study results comparing the performance of the LoTNext model with variants where key components were removed: Long-Tailed Graph Adjustment (LTGA), Long-Tailed Loss Adjustment (LTLA), the cross-entropy loss (LCE), and the auxiliary time prediction task (LAux). The results show the impact of each component on Acc@1, Acc@5, Acc@10, and MRR for both the Gowalla and Foursquare datasets. The full LoTNext model consistently outperforms the variants where components are missing.

This table presents a comparison of the performance of various models (including the proposed LoTNext model) on two benchmark datasets, Gowalla and Foursquare. The performance is evaluated using two metrics: Accuracy@k (Acc@k) and Mean Reciprocal Rank (MRR). Acc@k measures the percentage of times the correct next Point of Interest (POI) is among the top k predictions, while MRR provides an average ranking score for the correct POI. The table shows the Acc@1, Acc@5, and Acc@10 values along with the MRR for each model on each dataset, allowing for a comprehensive comparison of their predictive abilities.

This table presents a comparison of the performance of various models, including LoTNext, on two real-world datasets: Gowalla and Foursquare. The models are evaluated using two metrics: Accuracy@k (Acc@k), which measures the accuracy of predicting the correct next Point of Interest (POI) within the top k predictions, and Mean Reciprocal Rank (MRR), which measures the average rank of the correct POI across all predictions. The table shows the Acc@1, Acc@5, and Acc@10 scores, along with the MRR for each model on each dataset, allowing for a comprehensive comparison of their performance.
Full paper#



















