↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Large language models (LLMs) exhibit impressive in-context learning (ICL) abilities, but their computational cost remains high. This paper investigates the effect of SVD-based weight pruning, a model compression technique, on ICL performance. Previous research has shown that model compression can significantly reduce storage and computational costs without affecting accuracy, but the relationship between model compression and ICL has not been well explored. This work addresses this gap by examining whether and how pruning weights in LLMs affects their ICL capabilities.
The researchers discovered that SVD-based weight pruning significantly enhances ICL performance. Surprisingly, pruning weights in deeper layers often leads to more stable performance improvements compared to shallower layers. To understand this phenomenon, they presented a theoretical analysis using implicit gradient descent and provided mutual information based generalization bounds for ICL. Based on this analysis, they proposed a derivative-free algorithm that enhances ICL inference for downstream tasks. Experiments show that this simple algorithm improves model performance on various benchmark datasets and open-source LLMs. This demonstrates the potential of using SVD-based weight pruning to improve efficiency and performance in LLMs.
Key Takeaways#
Why does it matter?#
This paper is crucial because it reveals a surprising finding: SVD-based weight pruning enhances in-context learning in LLMs, especially in deeper layers. This opens new avenues for model compression and efficiency improvements in LLMs, a critical area of current research. The theoretical framework offers a deeper understanding, guiding future algorithmic developments.
Visual Insights#
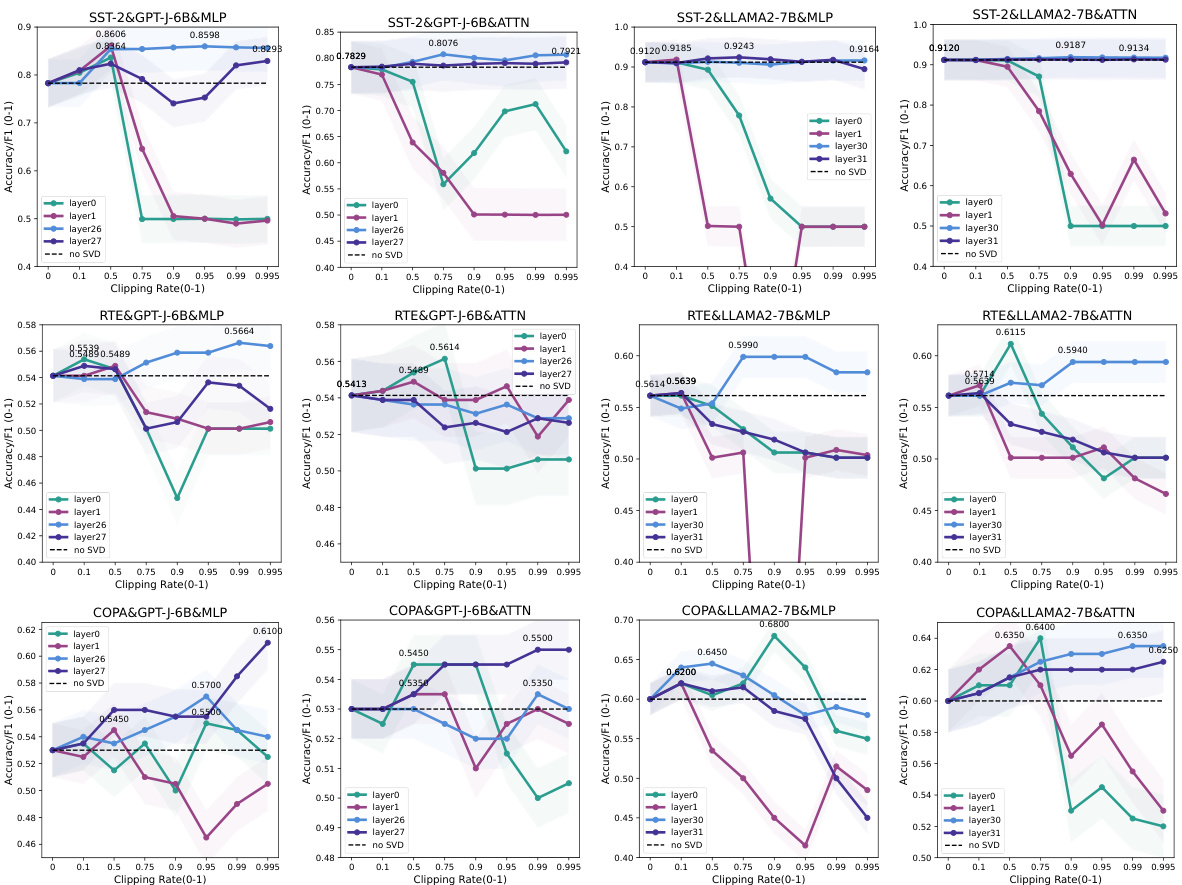
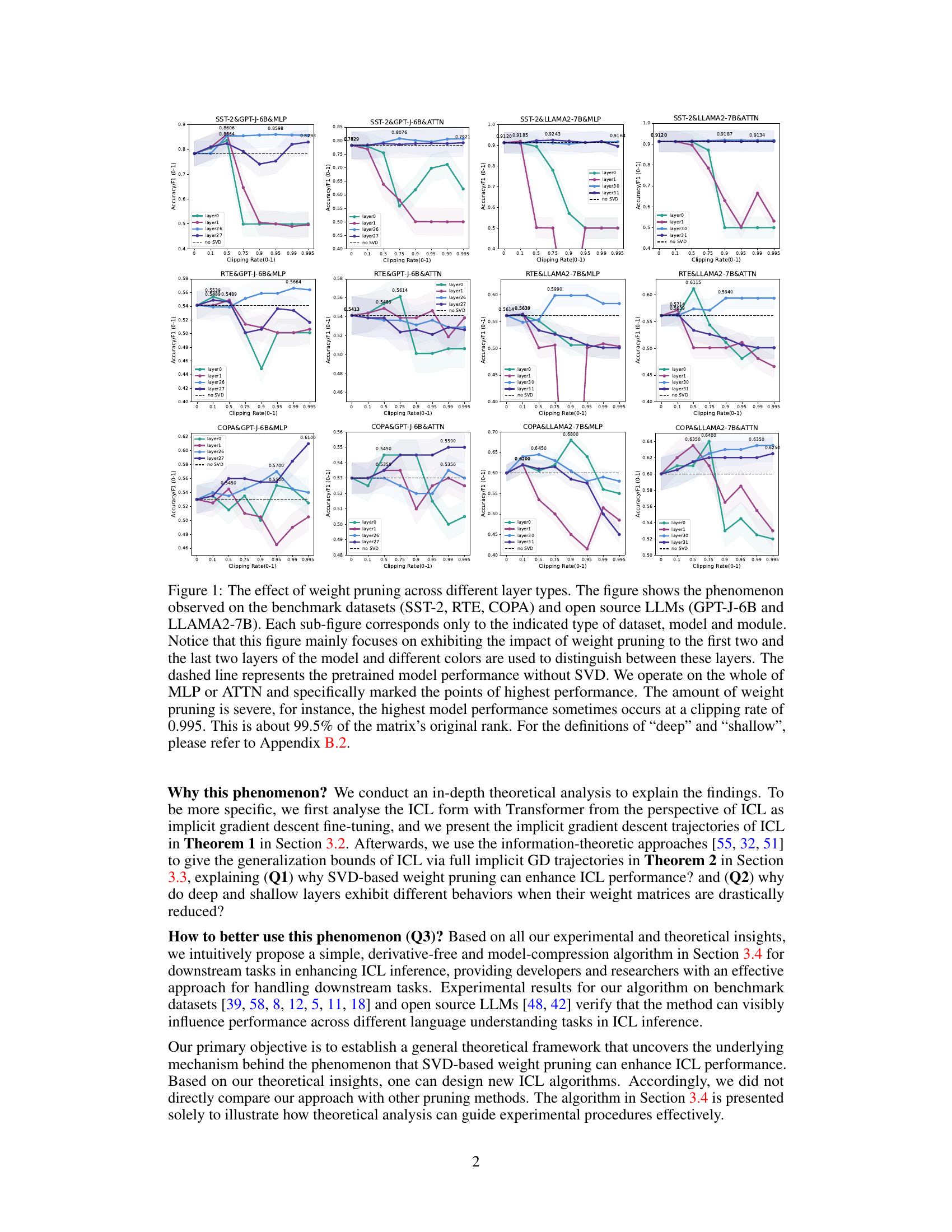
This figure shows the results of applying SVD-based weight pruning to different layers of transformer models (GPT-J-6B and LLAMA-2-7B) on three benchmark datasets (SST-2, RTE, COPA). It demonstrates that SVD-based pruning enhances in-context learning (ICL) performance, and that pruning deeper layers is more effective and stable than pruning shallower layers. Each subplot shows the performance (Accuracy/F1 score) against the pruning rate for a specific dataset, model, and module (MLP or ATTN) with different layers highlighted.
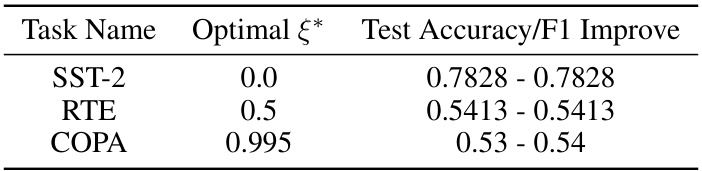
This table presents the results of applying Algorithm 1, a method for enhancing ICL inference through SVD-based weight pruning, to the SST-2 dataset. It shows the optimal clipping rate (ξ*) determined for different modules (MLP and ATTN) of two different LLMs (GPT-J-6B and LLAMA2-7B) and the corresponding test accuracy/F1 scores along with the improvement achieved compared to the baseline ICL performance. The optimal clipping rate signifies the degree of weight pruning that yielded the best performance on the validation set before testing on the held-out test set.
In-depth insights#
SVD Pruning ICL#
The concept of “SVD Pruning ICL” combines singular value decomposition (SVD)-based pruning with in-context learning (ICL) in large language models (LLMs). SVD pruning reduces model size and computational cost by selectively removing less important singular vectors from weight matrices. Applying this to ICL, which involves LLMs predicting outputs from input-output examples without parameter updates, is particularly interesting because it might improve efficiency and robustness. The core idea is that SVD pruning, especially when targeted at deeper layers, surprisingly enhances ICL performance. This counter-intuitive finding suggests the presence of a considerable degree of redundancy in LLMs, which is surprisingly beneficial for ICL. The authors explore the theoretical implications of SVD-pruning ICL and propose a novel algorithm based on their findings. Further research is needed to fully explain the underlying mechanism and extend the approach to other LLMs and downstream tasks. Overall, “SVD Pruning ICL” presents a promising avenue for improving LLM efficiency and ICL capabilities, warranting further investigation and experimentation.
Implicit GD ICL#
The concept of “Implicit GD ICL” (Implicit Gradient Descent In-Context Learning) proposes a novel perspective on how large language models (LLMs) learn during in-context learning. Instead of explicit parameter updates, the process is framed as an implicit gradient descent, where the model’s internal weights are subtly adjusted based on the provided examples, guiding the model towards accurate predictions without direct training. This framework provides a more nuanced understanding of the underlying mechanism of ICL, potentially explaining why LLMs can generalize well despite the absence of explicit optimization. The implicit gradient itself is not directly computed, but rather inferred through the model’s behavior, highlighting a unique aspect of this learning paradigm. This conceptualization offers fertile ground for future research, especially in developing efficient ICL algorithms and further unraveling the intricacies of how LLMs learn and generalize.
ICL Generalization#
In exploring in-context learning (ICL) generalization, a crucial aspect is understanding how a model’s performance on seen examples translates to unseen data. Key challenges lie in the inherent variability of ICL, where subtle prompt variations can significantly impact results. This makes evaluating generalization difficult, requiring careful experimental design and robust metrics. Theoretical analysis using information-theoretic bounds can provide valuable insights into generalization error. By connecting ICL to implicit gradient descent, it becomes possible to derive generalization bounds that relate to the properties of the learned parameters (model weights) and the distribution of input data. Analyzing implicit gradient trajectories, potentially via Singular Value Decomposition (SVD), can shed light on the factors affecting generalization. The effect of weight pruning on generalization, particularly when targeting different layers of the model, offers insights into how model complexity influences ICL’s ability to generalize. Ultimately, research in ICL generalization strives to find a balance between model capacity and generalization capability, addressing the inherent challenges of evaluating and understanding ICL’s behavior on unseen data.
Derivative-Free Alg#
A derivative-free algorithm is a significant advancement in optimization because it bypasses the need to calculate gradients, which can be computationally expensive or impossible to obtain in certain contexts. This is particularly relevant for complex models such as large language models (LLMs) where calculating gradients is challenging. A derivative-free algorithm could provide an efficient solution for fine-tuning LLMs in in-context learning tasks. The algorithm’s simplicity and model-compression properties make it a practical choice for resource-constrained environments. However, a key area to investigate would be its generalizability across various LLM architectures and datasets. Robustness to noise is another crucial aspect to explore as implicit gradient descent in LLMs is often susceptible to noise and approximation errors, and the algorithm’s performance compared to gradient-based methods needs thorough benchmarking. Despite the advantages, careful consideration should be given to the potential trade-off between accuracy and computational efficiency.
Future ICL Research#
Future research in In-context Learning (ICL) should prioritize a deeper investigation into the implicit learning mechanisms within large language models (LLMs). This includes exploring how LLMs represent and process demonstrations, the role of architectural choices (e.g., attention, MLP layers), and the influence of model size and training data on ICL performance. A crucial area is developing theoretical frameworks that can accurately predict and explain ICL behavior, potentially building upon information-theoretic bounds and implicit gradient descent analysis. Furthermore, research should focus on robustness and generalization, aiming to improve the consistency of ICL across diverse tasks and datasets. This includes investigating the impact of various data augmentations and exploring methods to reduce sensitivity to the order of demonstrations. Finally, there’s a need for practical advancements, such as efficient algorithms for ICL inference and novel techniques that leverage ICL to improve the efficiency of downstream tasks. Model compression techniques applied to LLMs could play an important role here.
More visual insights#
More on figures

This figure shows the results of applying SVD-based weight pruning to different layers of Transformer models (GPT-J-6B and LLAMA2-7B) on three benchmark datasets (SST-2, RTE, COPA). It demonstrates that SVD-based pruning enhances in-context learning (ICL) performance, and that pruning deeper layers is often more effective and stable than pruning shallower layers. Each sub-plot represents a specific dataset, model, and module (MLP or Attention), showing the accuracy/F1 score against the clipping rate (percentage of weights pruned). The dashed line represents the baseline performance without pruning.
This figure displays the results of applying SVD-based weight pruning to different layers (shallow vs. deep) and modules (MLP vs. ATTN) of two LLMs (GPT-J-6B and LLAMA2-7B) across three benchmark datasets (SST-2, RTE, COPA). It demonstrates that SVD-based pruning enhances ICL performance, and that pruning deeper layers often yields more stable improvements than pruning shallow layers. The x-axis represents the clipping rate (proportion of weights removed), and the y-axis shows the accuracy/F1 score. The dashed lines represent the baseline performance without pruning.
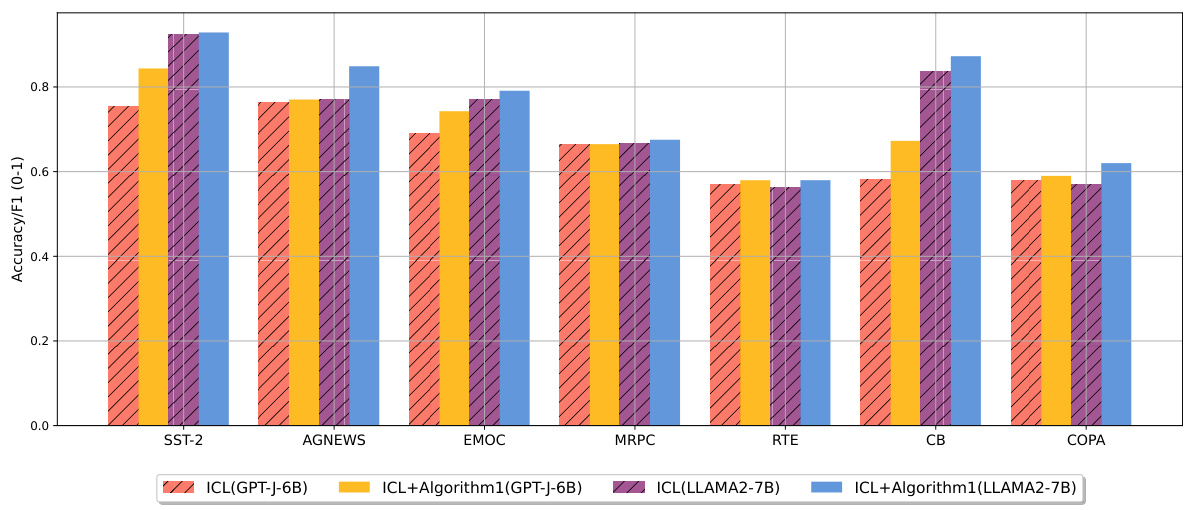
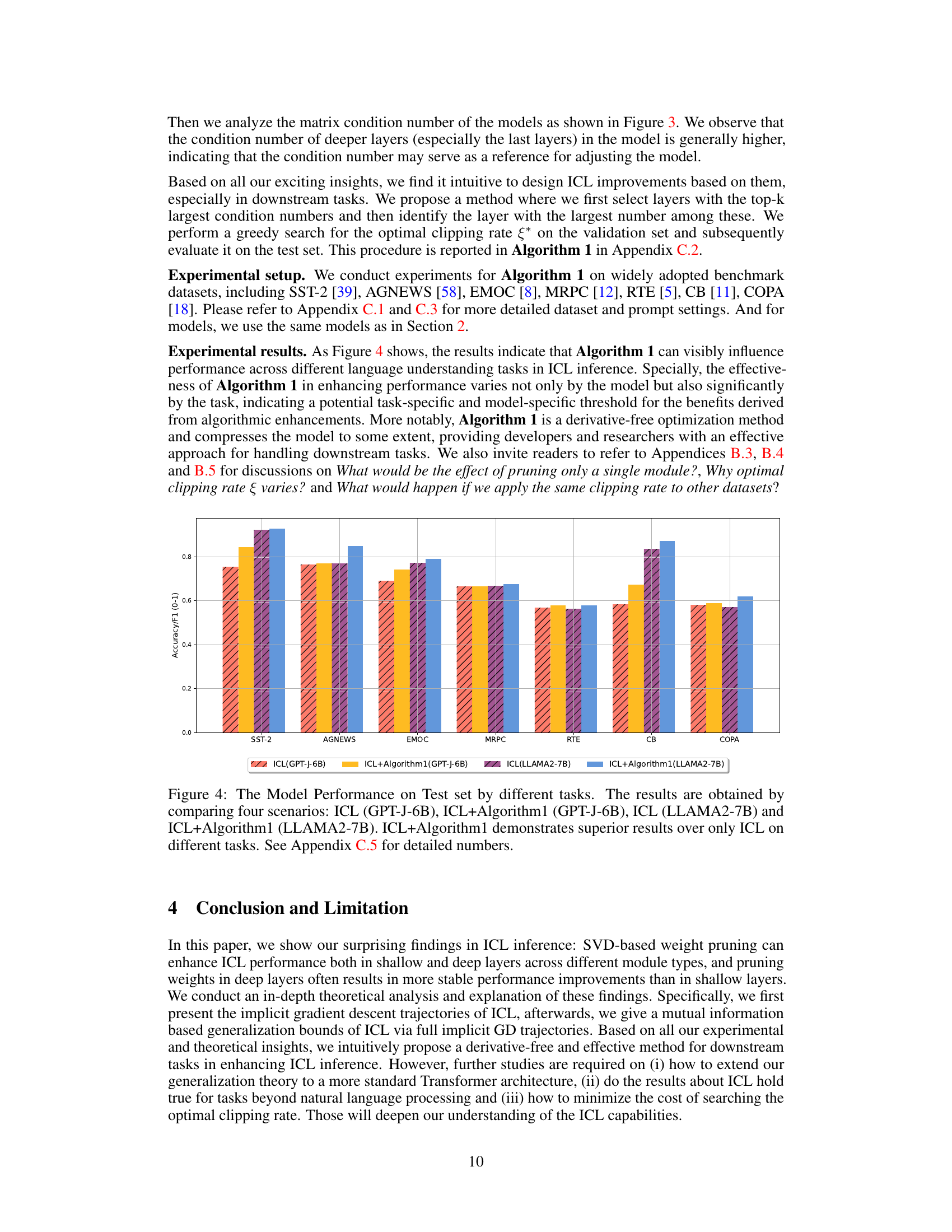
This figure shows the performance of the proposed Algorithm 1 compared to standard ICL on eight different downstream tasks. Two different LLMs (GPT-J-6B and LLAMA2-7B) are used. Each bar represents the accuracy or F1 score for a given task and model. The results indicate that Algorithm 1 consistently improves performance across these diverse tasks.
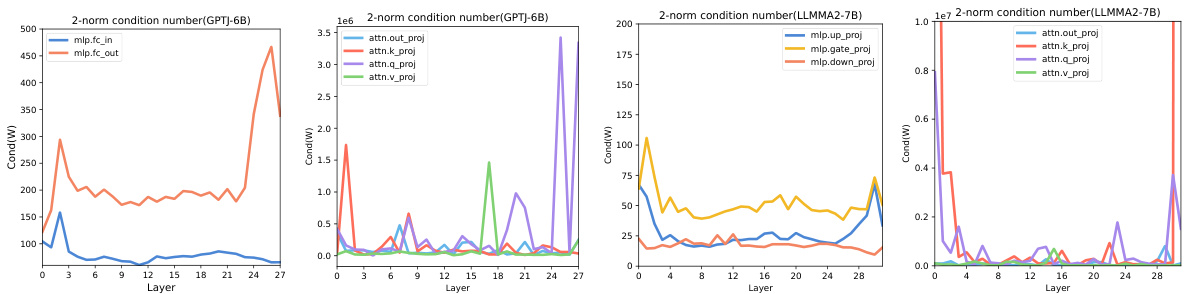
This figure shows the impact of SVD-based weight pruning on the performance of different layers in LLMs during in-context learning. The results are shown for three benchmark datasets (SST-2, RTE, COPA) and two LLMs (GPT-J-6B and LLAMA2-7B). The plots illustrate that pruning can enhance performance, with deeper layers often showing more stable improvements than shallower layers, even with very aggressive pruning.
More on tables

This table shows the prompts used for each dataset in the experiments. It specifies the type of task (classification or multiple-choice) and provides a template showing how the input data from each dataset was formatted into a prompt for the model. The table helps understand how the input data was prepared for the in-context learning experiments.

This table presents the results of applying Algorithm 1, a novel method for enhancing in-context learning (ICL) performance via SVD-based weight pruning, to the SST-2 dataset. It shows the model name (GPT-J-6B and LLAMA2-7B), the number of layers considered, the module type (MLP or ATTN), the optimal clipping rate (ξ*) found by the algorithm, and the resulting test accuracy and improvement compared to the baseline ICL performance. The results demonstrate the effectiveness of Algorithm 1 in improving ICL performance on this specific dataset.

This table presents the results of applying Algorithm 1, a novel method for enhancing ICL inference, to the SST-2 dataset. It shows the model name, layer number, module type (MLP or ATTN), the optimal clipping rate (ξ*) found by Algorithm 1, and the improvement in test accuracy achieved compared to the baseline ICL performance. The upward or downward arrow indicates whether the accuracy increased or decreased after applying Algorithm 1.

This table presents the results of applying Algorithm 1, a novel method for enhancing In-context Learning (ICL) performance through SVD-based weight pruning, to the AGNEWS dataset. It shows the model name (GPT-J-6B and LLAMA2-7B), layer number, module type (MLP or ATTN), the optimal clipping rate (ξ*) determined by Algorithm 1, and the resulting test accuracy improvement compared to the baseline ICL performance. Positive values indicate improvement, while negative values indicate a decrease in performance.

This table presents the results of applying Algorithm 1, which is a method for enhancing ICL inference by using SVD-based weight pruning, on the EmoC dataset. The table shows the model name, layer number, module type (MLP or ATTN), optimal clipping rate (ξ*), and the improvement in test accuracy. The results indicate the effectiveness of Algorithm 1 for enhancing performance on this dataset, although some layers and modules show no improvement or even a slight decrease.

This table presents the results of applying Algorithm 1, a method for enhancing in-context learning (ICL) performance using SVD-based weight pruning, to the MRPC dataset. The table shows the model name (GPT-J-6B and LLAMA2-7B), the layer number (26, 27, and 30), the module name (MLP and ATTN), the optimal clipping rate (ξ*) determined by the algorithm, and the resulting change in test accuracy. Positive values in the ‘Test Acc Improve’ column indicate an improvement in accuracy after applying the algorithm, while negative values show a decrease.

This table presents the results of applying Algorithm 1, a method for enhancing ICL inference using SVD-based weight pruning, to the CommitmentBank (CB) dataset. It shows the test accuracy improvements achieved for different models (GPT-J-6B and LLAMA2-7B) and module types (MLP and ATTN) at various layers. The ‘Optimal ξ*’ column indicates the clipping rate that yielded the best performance for each configuration. Positive values in the ‘Test Acc Improve’ column denote performance improvement compared to the baseline ICL model.

This table presents the results of applying Algorithm 1, a method for enhancing in-context learning (ICL) performance via SVD-based weight pruning, to the COPA dataset. The table shows the model name (GPT-J-6B and LLAMA2-7B), the layer number (26, 27, 30), the module name (MLP and ATTN), the optimal clipping rate (ξ*) determined by Algorithm 1, and the resulting improvement in test accuracy/F1 score. The improvement is shown as the difference between the original performance and the performance after applying the algorithm. A positive value indicates an improvement, while a negative value indicates a decrease in performance.

This table presents the results of applying Algorithm 1, a method for enhancing in-context learning (ICL) performance via SVD-based weight pruning, to the COPA dataset. For both GPT-J-6B and LLAMA2-7B models, the algorithm was applied to both MLP and ATTN modules at specific layers. The table shows the optimal clipping rate (ξ*) found by the algorithm for each model and module, and the resulting test F1 score improvement (or reduction) compared to the baseline ICL performance.
Full paper#