↗ OpenReview ↗ NeurIPS Homepage ↗ Chat
TL;DR#
Addressing the shortage of pediatricians and the limitations of existing LLMs in pediatric applications, this paper introduces PediatricsGPT. The paper highlights the challenges of applying LLMs to the medical field, particularly pediatrics, due to the scarcity of high-quality data and the complexity of the domain. Inadequate training data and methodologies lead to suboptimal performance of existing LLMs. The lack of specialized data and the vulnerabilities in current training procedures hinder the development of effective pediatric consultation systems.
To overcome these challenges, the researchers created PedCorpus, a comprehensive dataset comprising over 300,000 multi-task instructions from pediatric textbooks, guidelines, and knowledge graphs. Using this dataset, they developed PediatricsGPT, employing a novel hybrid instruction pre-training mechanism to enhance model adaptability and a direct following preference optimization technique to ensure humanistic responses. Extensive evaluation shows that PediatricsGPT significantly outperforms existing Chinese medical LLMs, demonstrating the effectiveness of their proposed approach. The project and data are publicly released to promote further research and development in this vital area.
Key Takeaways#
Why does it matter?#
This paper is crucial for researchers in AI-powered healthcare and natural language processing. It introduces a novel approach to building pediatric LLMs, which is a significant advancement given the scarcity of pediatric medical data and the unique challenges in this domain. The proposed training pipeline and dataset, PedCorpus, provide a valuable resource for future research, enabling the development of more effective and reliable medical assistants. Furthermore, the paper’s detailed analysis of various training methodologies contributes to a broader understanding of LLM training optimization.
Visual Insights#
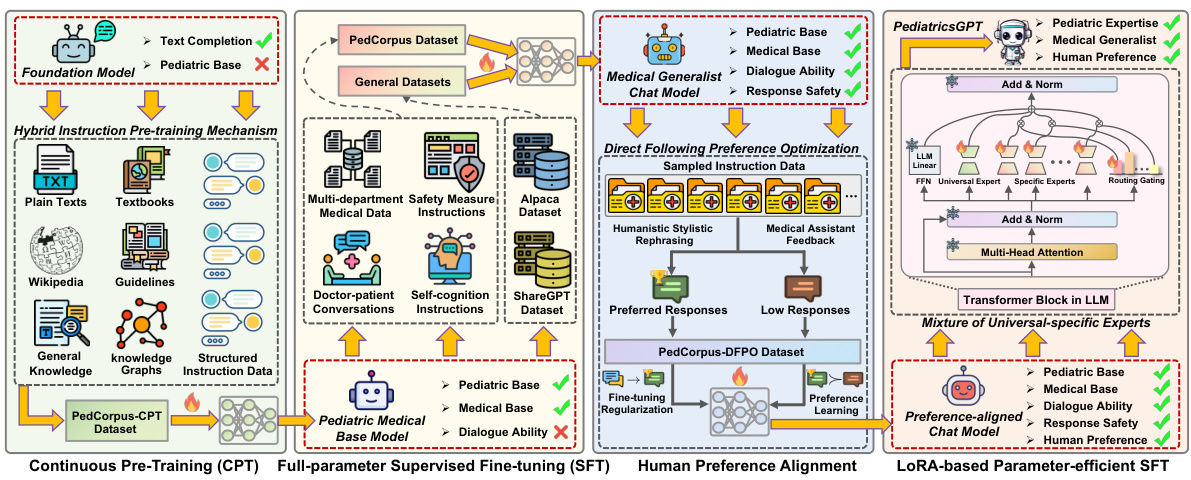
This figure illustrates the training pipeline of PediatricsGPT, highlighting the key steps: 1) Continuous Pre-training (CPT) using a hybrid instruction mechanism to incorporate medical and world knowledge; 2) Full-parameter Supervised Fine-tuning (SFT) to enhance instruction following for medical generalists; 3) Direct Following Preference Optimization (DFPO) to align model behavior with human preferences; and 4) LoRA-based Parameter-efficient SFT with a mixture of universal-specific experts to address conflicts between pediatric expertise and general medical knowledge. The figure visually depicts the data used at each stage, such as PedCorpus and its sub-datasets, and how they contribute to the final model.
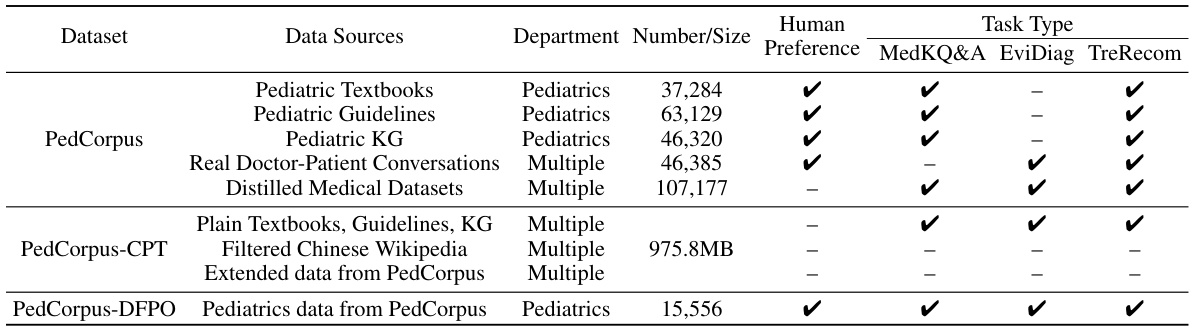
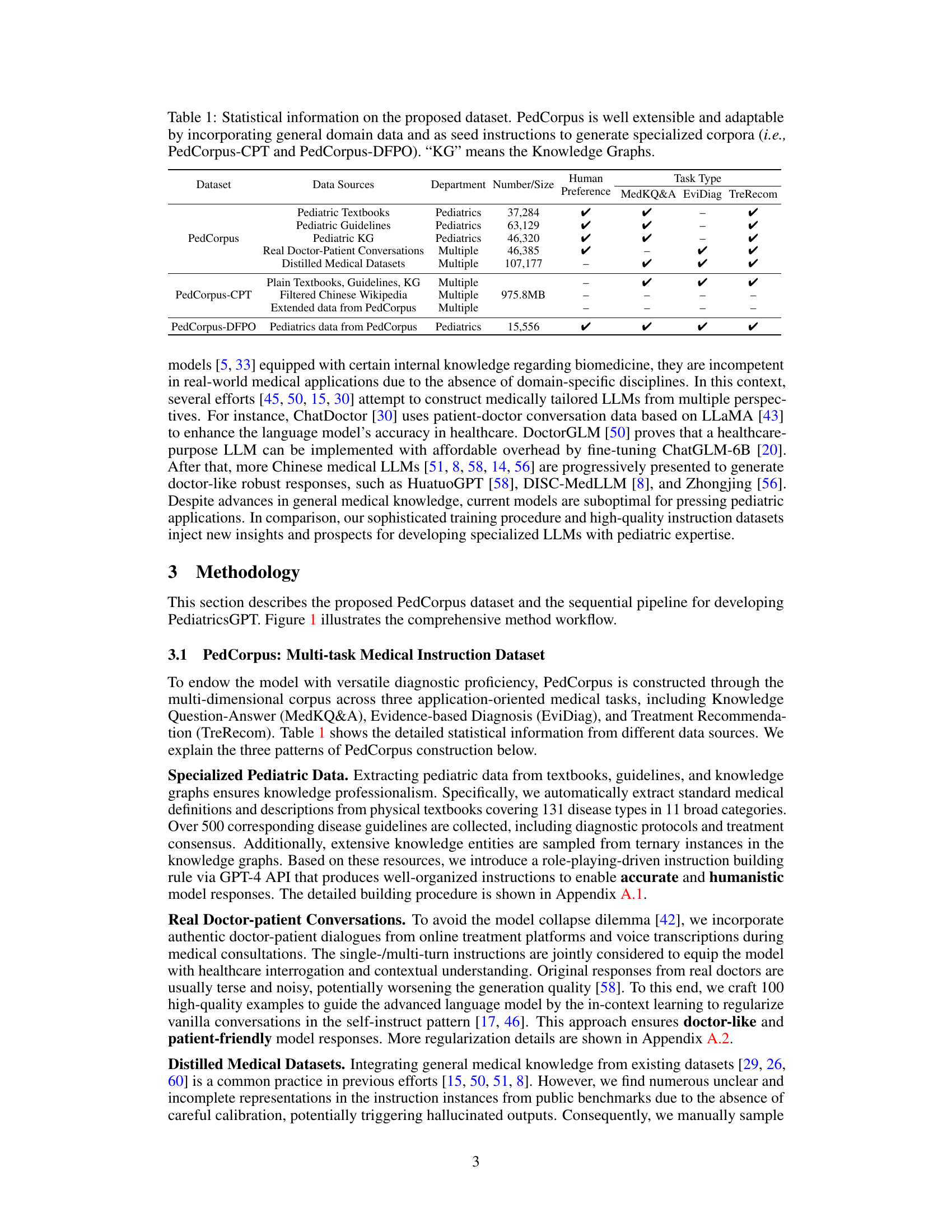
This table presents a statistical overview of the PedCorpus dataset, including its size, sources, and task types. It also highlights the extensibility of the dataset through the incorporation of additional data sources.
In-depth insights#
Pediatric LLMs#
The field of Pediatric LLMs represents a significant advancement in AI-powered healthcare, addressing the critical need for improved pediatric care, especially in resource-constrained settings. These models offer the potential to revolutionize pediatric diagnosis and treatment by leveraging large language models (LLMs) trained on comprehensive pediatric datasets. This approach can improve diagnostic accuracy, personalize treatment plans, and provide readily accessible medical information to both medical professionals and parents. However, the development of effective Pediatric LLMs requires careful consideration of several key factors, including data quality, model training methodologies, ethical considerations, and bias mitigation. Ensuring the models are trained on high-quality, diverse, and unbiased data is paramount. Robust training pipelines that incorporate human feedback and safety measures are crucial for producing reliable and trustworthy outputs. Addressing potential biases in training data is critical to prevent the perpetuation of health disparities. Furthermore, rigorous testing and validation are essential to ensure the accuracy and reliability of these models before widespread deployment. The ethical implications, including patient privacy and data security, must be meticulously addressed. Overall, Pediatric LLMs hold immense promise for improving global healthcare access and quality, but their development and deployment require a thoughtful and multidisciplinary approach.
Hybrid Training#
The concept of “Hybrid Training” in the context of large language models (LLMs) for medical applications, particularly pediatrics, is a crucial advancement. It suggests a training paradigm that overcomes the limitations of solely relying on either continuous pre-training or supervised fine-tuning. Continuous pre-training helps LLMs absorb vast amounts of general knowledge, while supervised fine-tuning allows them to specialize in a specific domain. However, simply combining these methods may lead to “catastrophic forgetting” where the model loses previously learned knowledge. A hybrid approach could involve a structured, multi-stage training process. This could begin with continuous pre-training on a massive dataset, followed by stages that strategically incorporate smaller, highly curated, and task-specific datasets. This could be followed by techniques like parameter-efficient fine-tuning, focusing on adapting specific model components to new data, minimizing interference with previously acquired knowledge. Careful selection of data across the training stages is vital to ensure consistency and prevent knowledge conflict within the model’s internal representations. Data augmentation and cleansing play important roles in generating high-quality, consistent instruction sets. Finally, methods to mitigate model bias, such as incorporating diverse datasets and employing techniques for preference alignment, are essential considerations. The effectiveness of hybrid training hinges on achieving a balance between general knowledge acquisition, domain specialization, and maintaining the overall integrity of the LLM’s knowledge base. This approach holds significant promise for future LLM development in various specialized fields.
PedCorpus Dataset#
The PedCorpus dataset represents a crucial contribution to the field of pediatric AI, addressing a critical need for high-quality, domain-specific training data. Its multi-task design, encompassing knowledge question-answering, evidence-based diagnosis, and treatment recommendation, makes it highly versatile. The inclusion of data from diverse sources like pediatric textbooks, guidelines, knowledge graphs, real doctor-patient conversations, and distilled medical datasets ensures a rich and nuanced representation of pediatric medical knowledge. The systematic approach to data construction, incorporating mechanisms to address knowledge inconsistencies and response hallucination, is a significant methodological advancement. The dataset’s scalability, demonstrated by its extensibility and adaptability, highlights its potential for broader use and future expansion. The sheer scale of the dataset, containing over 300,000 instructions, further strengthens its value as a training resource for advanced AI models. Ultimately, PedCorpus’s focus on improving diagnostic and treatment capabilities for children makes it a valuable asset with significant implications for enhancing healthcare access and outcomes, particularly in resource-constrained environments.
Multi-Expert LLM#
The concept of a “Multi-Expert LLM” points towards a significant advancement in large language model (LLM) architecture. Instead of relying on a single, monolithic model, a multi-expert system leverages several specialized LLMs, each trained on a specific domain or task. This approach offers enhanced performance and robustness by allowing each expert to focus on its area of expertise, thus achieving higher accuracy and avoiding the limitations of general-purpose LLMs that may struggle with nuanced tasks. The key is how these experts are integrated; a well-designed system will facilitate seamless transitions between them based on the input context, ensuring a cohesive and coherent response. Effective routing mechanisms are essential for efficiently directing queries to the most appropriate expert, while addressing potential competency conflicts between experts remains a significant challenge. This necessitates sophisticated methods for managing knowledge overlap and resolving conflicting outputs, potentially involving techniques like voting, weighting, or hierarchical structures. Ultimately, the success of a Multi-Expert LLM hinges on carefully curating the expertise of each model and creating robust orchestration mechanisms for optimal performance. This approach presents exciting opportunities to build more specialized, powerful, and reliable LLMs that can handle diverse and complex tasks.
Future Work#
The ‘Future Work’ section of a research paper on PediatricsGPT, a large language model for pediatric applications, would ideally outline several key directions. Enhancing security against model manipulation is paramount, necessitating advanced input validation techniques and robust safety filters to prevent malicious use and generation of unsafe content. Expanding language support is crucial for global accessibility, requiring model retraining with diverse linguistic datasets, thus broadening its reach beyond Chinese speakers. Further development should focus on addressing the current limitations, including the reliance on specific datasets and the current inability to process non-textual data. Integrating multimodal data (images, audio) could significantly enhance the system’s diagnostic capabilities, moving beyond text-based analysis to a richer diagnostic picture. Finally, the authors should emphasize the ongoing need for rigorous ethical considerations, transparently addressing biases within the data, ensuring data privacy, and promoting responsible use of the technology to prevent unintended consequences.
More visual insights#
More on figures
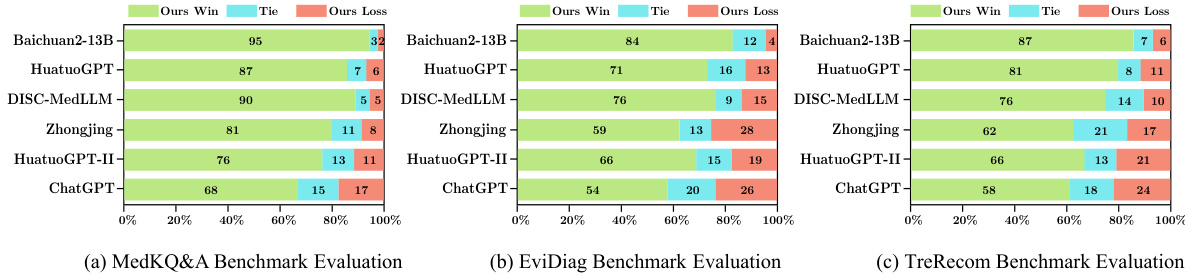
This figure presents a comparison of the performance of PediatricsGPT-13B against other baseline models using GPT-4 evaluation. It shows the win rate, tie rate, and loss rate for PediatricsGPT-13B against each of the other models across three different pediatric medical benchmarks: MedKQ&A, EviDiag, and TreRecom. The results are presented visually using bar charts, allowing for easy comparison of the model’s performance on different tasks.

This figure presents the results of a comparative analysis between PediatricsGPT-13B and several other baseline models using GPT-4 as an evaluation tool. It visually represents the win rate, tie rate, and loss rate for each model across three different pediatric medical benchmarks: MedKQ&A, EviDiag, and TreRecom. The color-coded bars offer a quick comparison of the performance of each model, allowing for easy identification of the best-performing model for each benchmark.

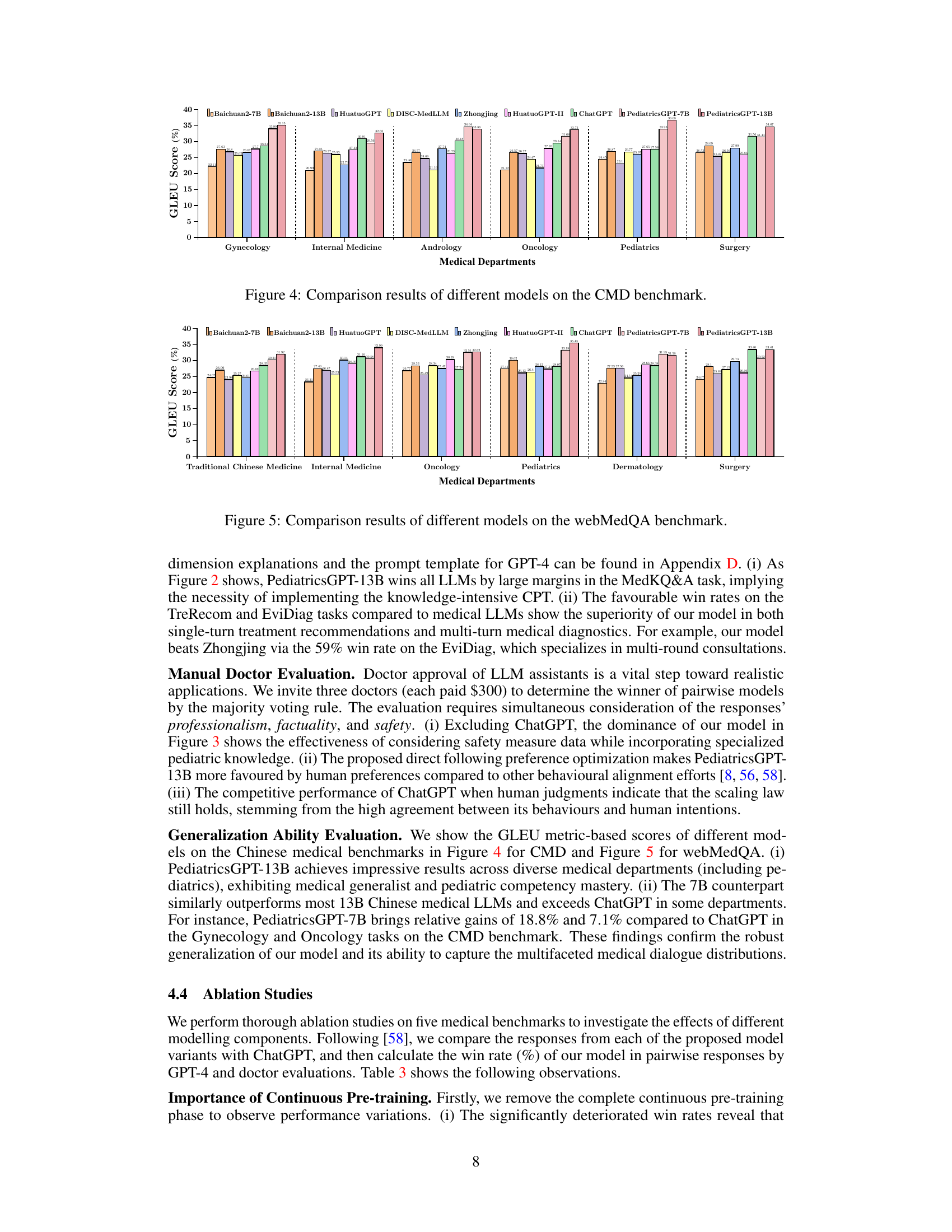
The figure shows a bar chart comparing the GLEU scores achieved by various large language models (LLMs) across different medical departments. The LLMs are tested on the Chinese Medical Dialogue (CMD) benchmark. The chart shows the performance of PediatricsGPT-7B and -13B compared to other LLMs, such as Baichuan2-7B, Baichuan2-13B, HuatuoGPT, DISC-MedLLM, Zhongjing, HuatuoGPT-II, and ChatGPT. Each bar represents an LLM’s performance in a specific medical department (Gynecology, Internal Medicine, Andrology, Oncology, Pediatrics, and Surgery). The height of the bar represents the GLEU score, a metric measuring the quality of the model’s generated text. The results demonstrate the superior performance of PediatricsGPT models in multiple medical domains.
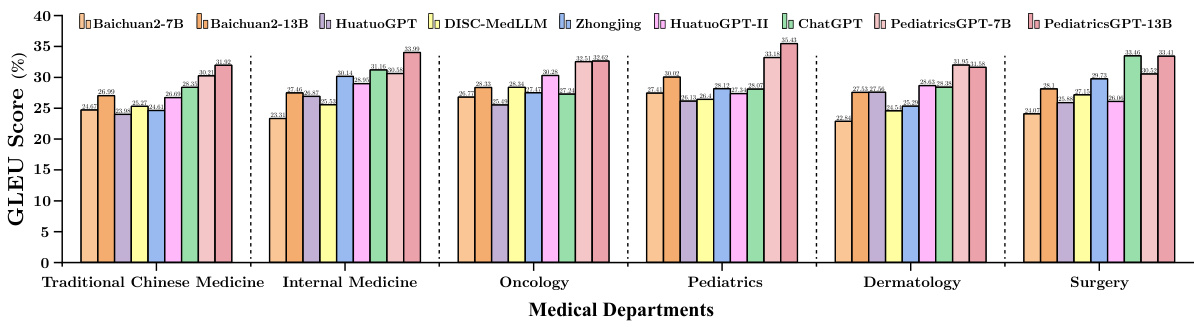
The figure shows a bar chart comparing the GLEU scores of various LLMs across different medical departments within the CMD benchmark. The LLMs compared include Baichuan2-7B, Baichuan2-13B, HuatuoGPT, DISC-MedLLM, Zhongjing, HuatuoGPT-II, ChatGPT, PediatricsGPT-7B, and PediatricsGPT-13B. The x-axis represents the different medical departments (Traditional Chinese Medicine, Internal Medicine, Oncology, Pediatrics, Dermatology, and Surgery), and the y-axis represents the GLEU score (%). The chart visually displays the performance of each LLM across various medical specializations, highlighting the relative strengths and weaknesses of each model in different domains.

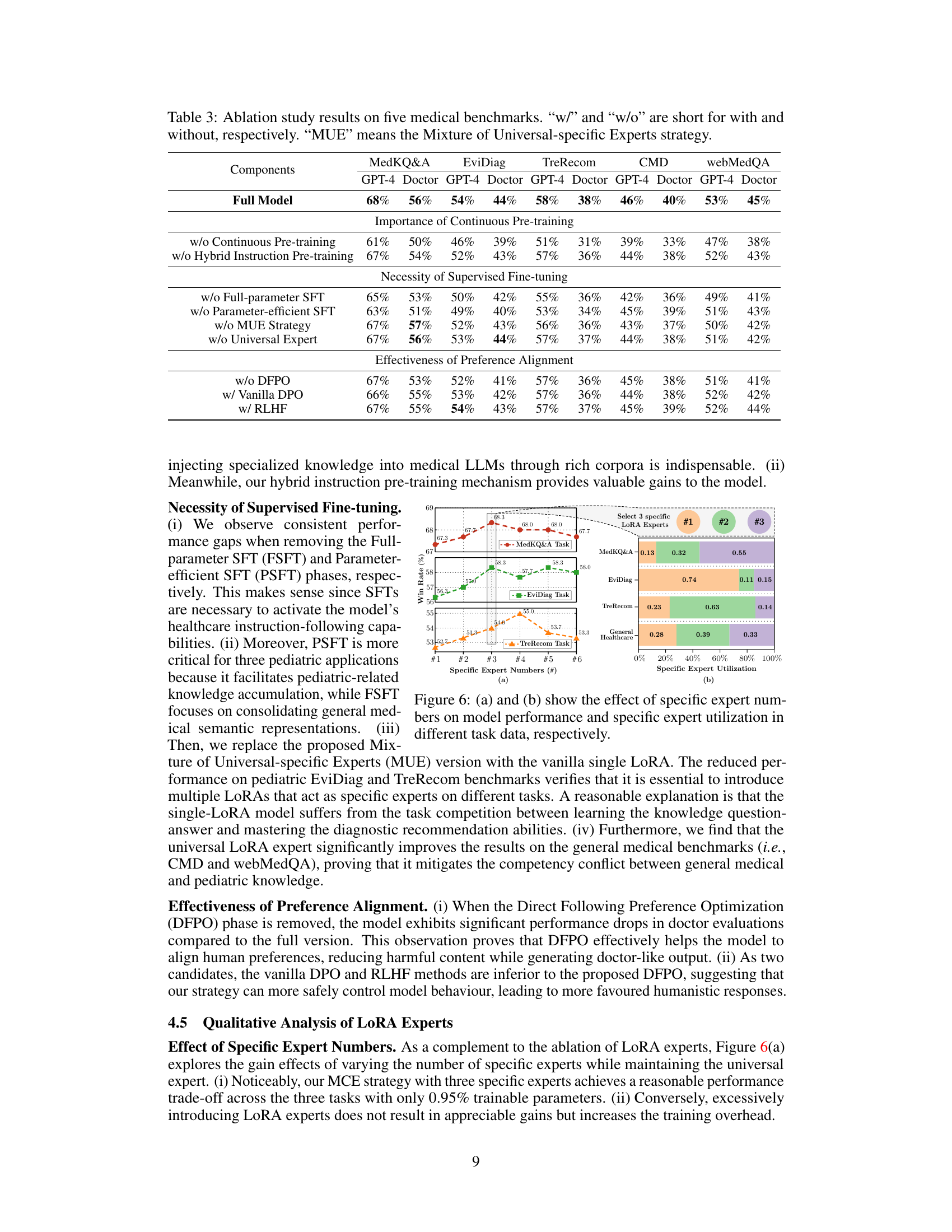
This figure shows two subfigures. Subfigure (a) presents the effect of using different numbers of specific LoRA experts on the model’s performance across three pediatric tasks (MedKQ&A, EviDiag, and TreRecom) and a general healthcare task. It illustrates that using three specific LoRA experts offers an optimal balance between performance and training efficiency. Subfigure (b) visualizes the normalized weights assigned to each specific LoRA expert during the routing process for each task. It showcases how the task type influences the utilization of different LoRA experts.
More on tables
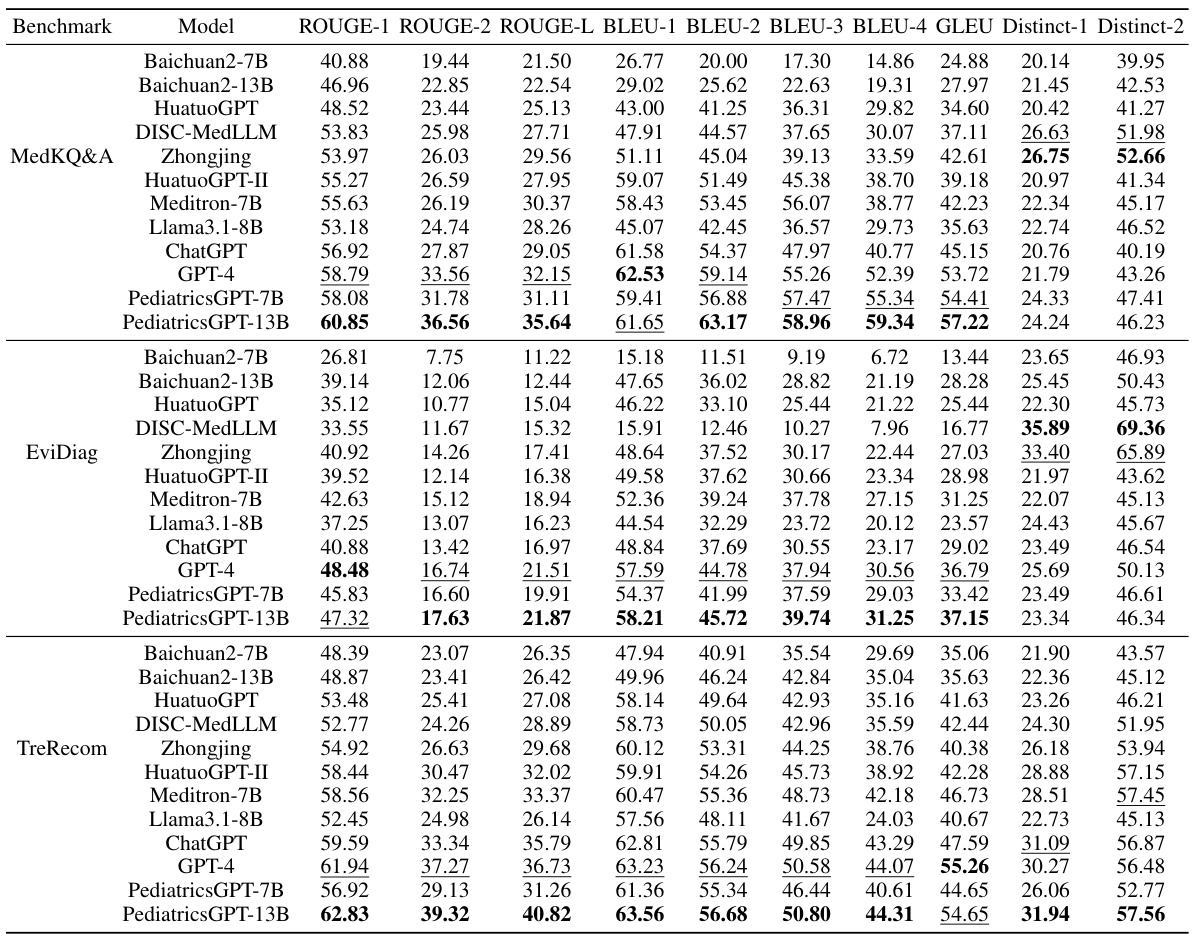
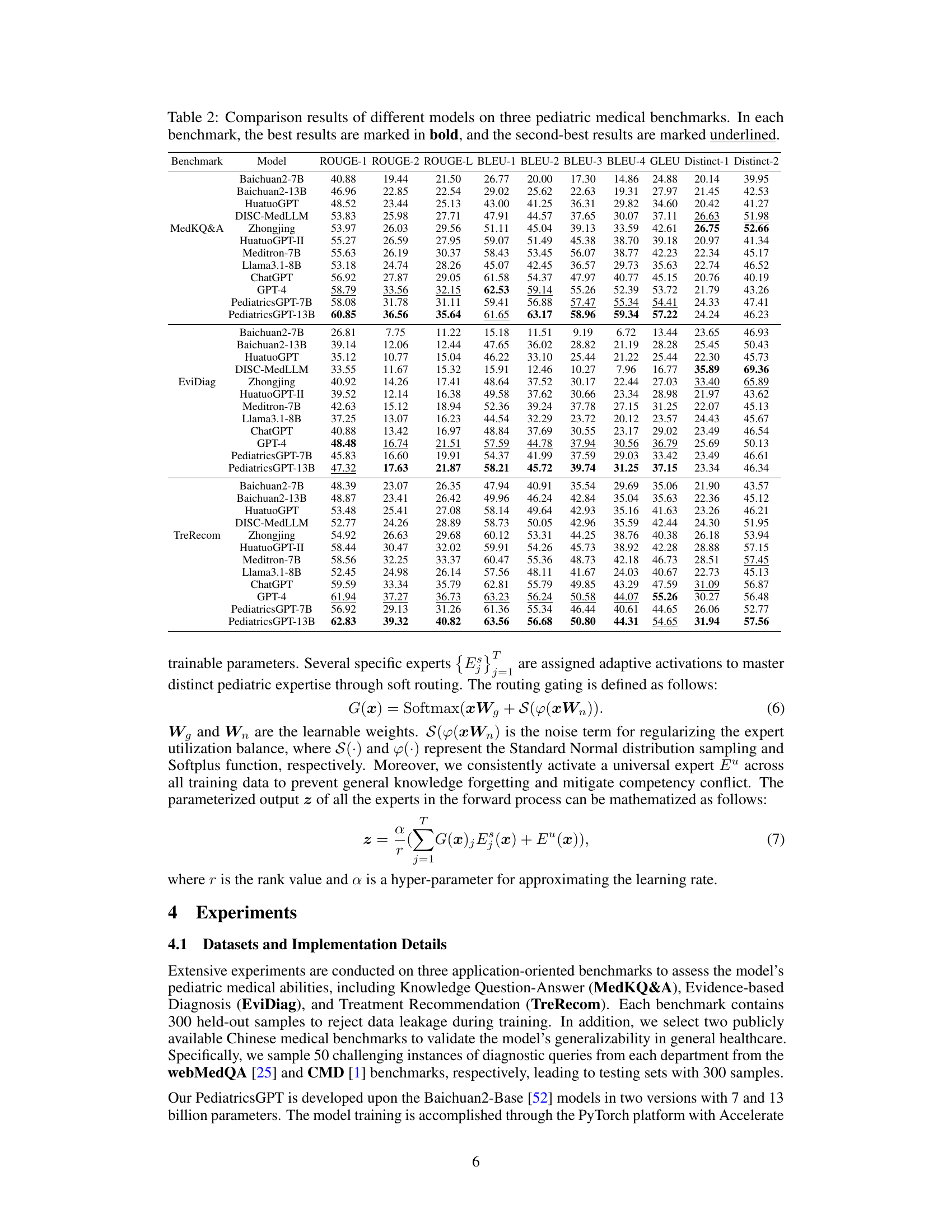
This table presents a quantitative comparison of various large language models (LLMs) on three benchmark tasks related to pediatric medicine: MedKQ&A (Medical Knowledge Question and Answering), EviDiag (Evidence-based Diagnosis), and TreRecom (Treatment Recommendation). The performance of each model is evaluated using multiple metrics (ROUGE, BLEU, GLEU, Distinct-n), providing a comprehensive view of their capabilities in different aspects of language generation and medical knowledge reasoning. The best and second-best performing models for each benchmark are highlighted for easy comparison.

This table presents a comparison of various large language models (LLMs) on three distinct pediatric medical benchmarks: MedKQ&A, EviDiag, and TreRecom. The performance of each model is evaluated using multiple metrics, including ROUGE, BLEU, GLEU, and Distinct-n scores. The table highlights the best-performing model for each benchmark and metric, offering a quantitative comparison of the models’ abilities in pediatric medical applications.
Full paper#